基于深度图像的带式输送机煤量检测方法
2023-11-02张乐群刘明辉
刘 飞,张乐群,蒋 伟,刘明辉
(1.西安科技大学 电气与控制工程学院,陕西 西安 710054;2.陕西省矿山机电装备智能监测重点实验室,陕西 西安 710054;3.天地(常州)自动化股份有限公司,江苏 常州 213014)
0 引 言
带式输送机作为煤矿生产的主要运输设备,能长时间不间断地将煤从地下运至地面[1-2]。在矿山工作时,带式输送机所耗能源占整个矿山工作能源消耗的60%[3]。因煤料分布不均带式输送机经常在轻载或空载状态下长时间全速运行,造成电能的浪费[4],导致带式输送机各个运行部分的无效磨损,缩短设备使用寿命。根据带式输送机上的煤量来调速,可以节约能源,延长设备使用时间[5-7]。
传统的动态煤量计量方式有3种,分别为机械式皮带秤[8]、电子皮带秤、核子皮带秤。机械式皮带秤和电子皮带秤的精度会受到皮带自重以及运动惯性的影响。虽然核子秤精度较高但其校准十分复杂,同时放射性材料会严重危害到工人的生命健康。由于传统测量方法存在各种弊端,学者们开始研究基于机器视觉的非接触式煤量检测方法[9]。李纪栋等利用图像边缘检测能够求解煤炭宽度,利用知识库模糊计算,求解出运输量[10]。贺杰等提出一种基于图像处理技术的皮带煤量测量方法,提取煤堆的骨架,获取煤轮廓,根据带煤截面积与带速的关系,测量输送带上煤流体积[11]。王宗省等提出一种基于窗口阈值的滤波方法,用于解决反光问题导致试验结果不准确的问题,该方法能去除噪声同时保留边界信息,并使用不同反射程度的模板进行EMD匹配,解决边界对比度低和光源不稳定等问题。通过腐蚀和膨胀后,使用改进的自适应阈值算法进行分割。同时,使用帧间差分法对一次输送带的运行状态进行识别,以协调控制能耗[12]。王桂梅等以深度学习为基础提出一种新的检测方法,提出改进的FF-CNN(Feed Forward Neural Network)网络,将带式输送机的煤量进行分类,实现煤量的检测[13]。
作为基于机器视觉的煤量检测方法唯一的研究对象,样本图像的质量对最终煤量检测结果的精确度有很大影响。而井下昏暗、复杂的环境会使获取的样本图像无法达到检测的要求。
现有的煤量检测方法还包括线激光测量以及双目立体视觉测量[14-15]。线激光测量使用激光扫描煤流获取煤量,但矿井中的粉尘会严重影响激光扫描的效果,而且其高昂的成本限制了激光扫描的普及。双目立体视觉测量使用两台面阵相机来实现物体的三维测量。但由于井下昏暗的环境,以及补光灯造成的多光源效应,给双目立体视觉测量的核心算法双目立体匹配算法造成了巨大影响。
与上述方法不同的是,深度图像的获取使用的是深度相机[16],深度相机通过近红外激光器,将具有一定结构特征的光线投射到被拍摄物体上,再由专门的红外摄像头进行采集。这种具备一定结构的光线照射在被摄物体上的不同深度区域并被反射回去,深度相机会采集被反射回来的结构光信息,然后通过运算单元将这种结构光的变化换算成深度信息。由于深度相机是主动发出结构光,因而适合在光照不足甚至无光的场景使用。
因此,文中提出一种基于深度图像的煤量检测方法,这种方法可以在昏暗的井下环境实时检测带式输送机的负载煤量且使用成本低,有利于推广。
1 煤量检测方法
基于深度图像的煤量检测方法由搭建合适的煤量检测网络进行模型训练、对训练好的模型进行验证2部分组成。
模型训练流程如图1所示。首先使用深度相机获取胶带机负载煤流深度图像,并将采集到的煤流深度图像进行双边滤波,在滤除噪声的同时保留图像信息,然后将深度图像按照少煤量、中煤量、多煤量3个类别分别放在不同的文件夹,构建数据集。最后,将数据集导入搭建的DID-CNN(Depth Image Detection Convolutional Neural Network)网络进行训练得到煤量检测模型。
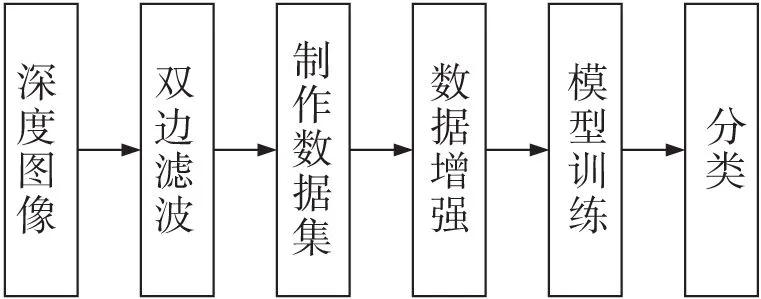
图1 模型训练流程Fig.1 Flow of model training
模型验证:将验证集的数据导入训练得到的煤量检测模型进行分类,检测模型的精确度和检测速度。
2 煤量检测模型
将带式输送机上负载煤量按照所占满载煤量的百分比划分为3个类别:0%~30%为“少煤量”、30%~60%为“中煤量”、60%~100%为“多煤量”,把它们作为网络输出的结果。 在卷积神经网络中,选取VGG网络(Visual Geometry Group Network)[17]作为基础网络构建适用于煤量检测的深度学习网络DID-CNN。
2.1 DID-CNN网络
DID-CNN网络如图2所示,在第一次7×7卷积后加入CBAM模块,然后将4个CSPResNet模块加入网络。使用全连接层将特征空间映射样本标记空间,输入Softmax函数得到最终输出[18]。
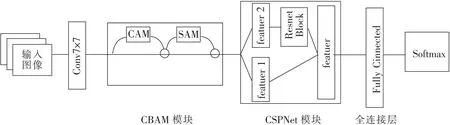
图2 DID-CNN网络Fig.2 DID-CNN network
2.2 CSPResNet模块
深层网络会带来大量计算,使训练参数大幅度增加。这就造成模型训练的效率降低和内存成本提高的问题。使用CSPNet模块不仅能够增强CNN的学习能力,而且能够在轻量化网络的同时保持准确性,降低计算瓶颈,降低内存成本[19]。
2.3 CBAM模块
使用深度图像作为数据集,其背景信息为传送带,在少量及中等煤量时背景信息所占比重过大。为了提高模型的检测精度,在第一次卷积之后加入卷积注意力模块(Convolutional Block Attention Module,CBAM)对特征输入进行加权再输出,希望网络关注到的地方给较大的权重,不希望网络注意的地方给较小的权重,以此来提高模型的学习效率[20]。
2.4 BN层
为提高煤量的检测精度和检测速度,DID-CNN网络在输入层后加入残差块防止梯度消失[21]。在卷积层之间加入BN(Batch Normalization)层,加快网络的训练和收敛速度。
3 试验和验证
3.1 深度图像
使用深度相机获取深度图像,将深度信息转换为颜色信息,不同的深度用不同的颜色代表,其原理如图3所示。
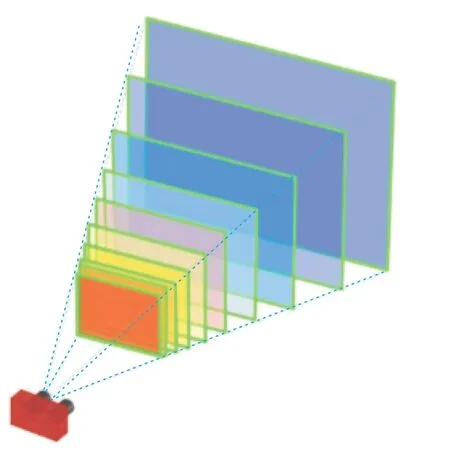
图3 深度与颜色对照Fig.3 Contrast of depth and color
图4为不同类别煤量的深度图像,深度图像中该点的颜色代表了该点距离深度相机的距离。因此可以根据深度图像中不同颜色的面积大小来区分煤量类别。
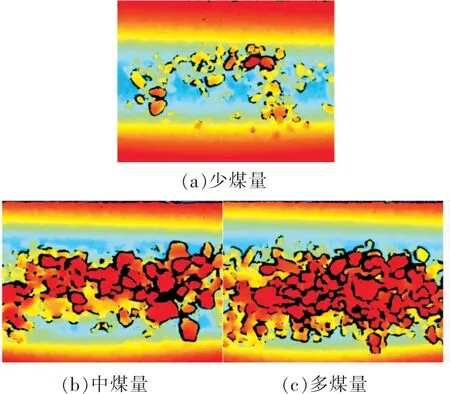
图4 不同类别煤量的深度图像Fig.4 Depth images of different categories of coal
3.2 数据集制作
使用深度相机采集不同煤量的深度图像,选取不同煤量的深度图像存放在不同的文件夹下,文件夹名为对应的煤量类别的标签。其标签设置见表1。
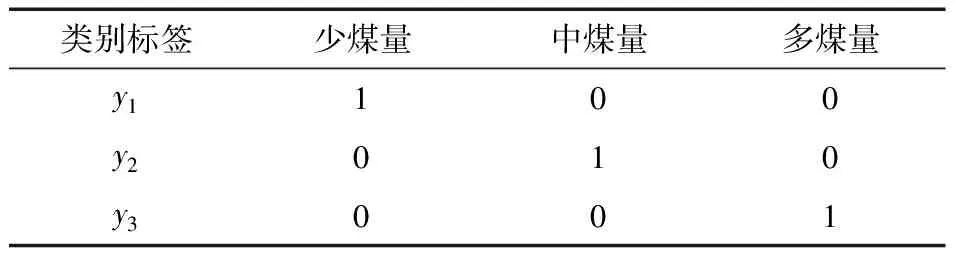
表1 煤量类别标签设置
将数据导入网络训练之前先将数据集的数据随机打乱,然后分别抽取其中的五分之一作为测试集和验证集,剩下的五分之三作为训练集。
3.3 图像的预处理
图像的预处理是图像识别过程中重要的一环。图像预处理不仅能够滤除图像的干扰信息如噪声信号等,还能够加强图像的有用信息[22]。使用适当的预处理方法能够有效地提升图像识别的精度。
通过深度相机采集的煤量深度图像含有大量噪声,因此需要对深度图像做滤波处理。这里对深度图像分别进行了均值滤波、高斯滤波、以及双边滤波,滤波后效果如图5所示。均值滤波的噪声滤除效果不理想且模糊了图像;高斯滤波的噪声滤除效果很好,但是模糊了边缘信息;双边滤波不仅滤除了噪声还保留了边缘信息。考虑到需要提取深度图像的深度特征和边缘特征,在比对均值滤波、高斯滤波、以及双边滤波的效果之后,选择双边滤波。
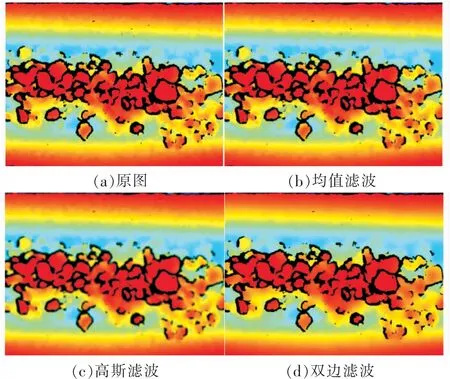
图5 滤波效果Fig.5 Filtering effects
3.4 数据增强
数据增强能够增加数据集图片的数量,提高检测模型的泛化能力[23]。此次试验使用的数据增强方法有:翻转、旋转、平移等。
数据增强还能够降低模型对图像的敏感度,提升检测模型的鲁棒性。此次试验通过给数据集添加高斯噪声来实现此目的。
3.5 正则化
使用正则化是为了减少模型的复杂度,并降低过拟合的风险[24]。在神经网络中,常用的正则化技术有L1正则化、L2正则化和Dropout。
L1正则化:将L1范数作为正则化项加入到损失函数中,使得模型权重的绝对值之和最小化,从而实现特征选择的效果,减少无用权重的影响[25]。
L2正则化:将L2范数作为正则化项加入到损失函数中,使得模型权重的平方和最小化,从而防止权重过大,降低过拟合的风险[26]。
Dropout:在训练时,以一定的概率随机将一些神经元的输出置为0,从而强制模型学习到更加鲁棒的特征。
L1正则化是一种从改变模型结构的角度,减少模型参数的数量,解决过拟合的方式。而L2正则化则是为了使模型尽量不依赖于某几个特殊的特征,从而使得每个特征得到尽量均衡的权重,以此来解决过拟合的问题。因此,此次试验选择在训练模型时加入L2正则化和Dropout。为了最大化正则化的效果,在损失函数中加入惩罚项。其损失函数见式(1)
Tloss=Closs+L2loss
(1)
式中Closs为交叉熵损失[27];L2loss为L2正则化损失。
3.6 试验环境
数据采集平台由运输煤流的胶带机和获取深度图像的深度相机组成,如图6所示。

图6 数据采集平台Fig.6 Data collection platform
硬件环境:CPU(AMD Ryzen 75800H),16 GB内存NVIDIA GTX3060Ti显卡,KBA18(D)矿用本安型深度相机。
3.7 模型训练
在训练之前设置网络的超参数学习率α=0.000 1,将训练的迭代次数设置为40次,然后将数据集导入DID-CNN网络训练。随着训练的迭代,训练损失和测试损失变化曲线如图7所示,从图7可以看出,随着迭代次数增加,训练损失和测试损失不断下降,模型在逐渐收敛,经过36次迭代后训练损失和测试损失稳定在0.005左右,准确率达到99.3%。

图7 训练和测试损失变化Fig.7 Variation curves of training and test loss
3.8 模型验证
3.8.1 检测速度
使用训练得到的煤量检测模型对煤量深度图像进行检测,为了准确地测试出模型检测一张图像的时间,分别向模型中导入200张、500张和1 000张图像,获取各自的检测时间,重复试验10次求平均值。试验结果见表2。

表2 检测时间
由表2可知,煤量检测模型检测每张图像的时间是0.024 3 s。
3.8.2 模型评估
F1值(F1 score):是精确度和召回率的调和平均值,是精确度和召回率的综合评价指标,被用来综合评价一个模型在精确度和召回率两个指标下的表现的指标[28]。其计算方法见式(2)
(2)
式中P为模型预测为正例中,实际为正例的比例;R为模型在所有正例中,正确预测为正例的比例。
F1 Score的取值范围为0~1,数值越大表示模型的性能越好。当P和R都很高时,F1 Score会更接近于1。
对训练后得到的模型进行验证,结果见表3。
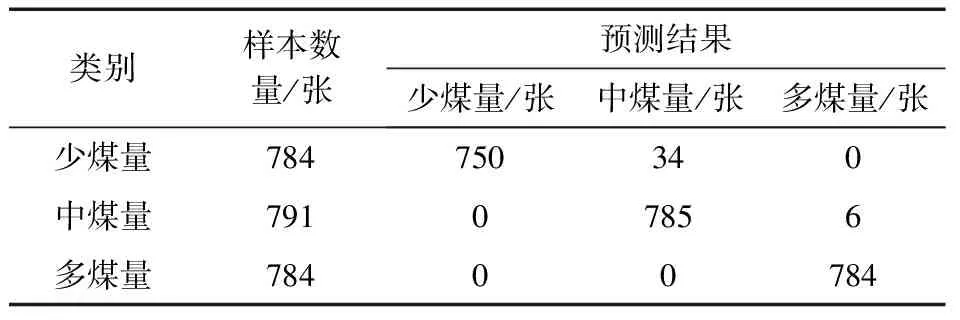
表3 模型验证
根据表3所示,计算出每个类别的精确率、召回率和F1 score。具体计算结果如下。
对于类别少煤量,样本数量为784张。其中,750张样本被正确地预测为少煤量,34张样本被错误地预测为中煤量。因此,该类别的精确率为0.956,召回率为1,F1 score为0.977。
对于类别中煤量,样本数量为791张。其中,785张样本被正确地预测为中煤量,6张样本被错误地预测为多煤量,没有样本被预测为类别0。因此,该类别的精确率为0.992,召回率为1.000,F1 score为0.996。
对于类别多煤量,样本数量为784张。其中,全部样本被正确地预测为多煤量。因此,该类别的精确率为1.000,召回率为1.000,F1 score为1.000。
综上所述,该模型的F1 score可以通过对每个类别的F1 score进行加权平均得到该模型的F1 score为0.991。
3.8.3 模型性能对比
为了验证 DID-CNN 网络的性能,将其与传统的分类网络VGG16做对比。将数据集导入VGG16网络进行模型性能对比,结果见表4。
由表4可知DID-CNN网络比 VGG16网络收敛速度更快且准确率更高,有更好的拟合性能。因为在DID-CNN 网络中加入了BN层,使其能够更充分地利用图像特征,同时避免了反向传播,加速了网络收敛,而且CMBA模块提升了网络学习有用特征的效率,因此网络能够快速达到较高的准确率,更适用于煤量深度图像的检测。
4 结 论
1)提出一种基于深度图像的带式输送机煤量检测方法,使用双边滤波对图像进行预处理,去除噪声的同时增强图像的边缘特征,使用图像增强技术弥补煤量图像数量相对较少的问题。
2)根据CSPnet的思想构建DID-CNN煤量检测网络。使用网络提取煤量深度图像的特征并进行分类。在网络中加入L2正则化和Dropout泛化模型,最终得到的煤量检测模型检测效果较好。
3)在实际的煤矿井下胶带机控制中多采用分级调控,而试验所得到的煤量检测结果能够用于胶带机的分级调控。
4)DID-CNN煤量检测效果虽好,但是由于空载和满载数据的单一性样本不足,因此并未将其作为检测结果。下一步的研究重点是在此基础上将空载和满载也作为检测结果,使检测模型能够更好地为带式输送机调速提供依据。
