智能电网电量异常数据的识别和修复研究
2023-11-01薛迎卫施炜炜
陈 婧,林 超,薛迎卫,施炜炜
(国网信通亿力科技有限责任公司,福建 福州 350003)
0 引言
智能电网是国家电网结构体系的重要组成部分,对国民经济建设具有推动作用[1]。传统电力行业的电量数据增长幅度较低,电量种类不多,且结构不复杂。随着智能电网信息化程度的不断提升,电力电量数据发生很大改变,不但结构、种类呈现多样性变化,而且电量数据规模增长迅猛,数据量突破亿万级[2-4]。对于当前电力行业的海量电量数据,传统数据处理方法已不能达到数据处理目标。另外,电力行业的供电量要与需求量相平衡。若破坏原本的均衡状态,会严重影响电力系统的安全、平稳运行。利用过去电量数据可实现未来用电量的预测,为电力生产分配及调度决策提供有力的数据支撑。这对于电力系统的高效运行具有重要意义。因此,电量数据必须准确、无异常。
通过数据挖掘技术对智能电网海量电量数据进行分析,对于异常电量数据的快速检测具有重要意义[5]。张春辉等针对电力系统电量数据受外在因素影响生成异常数据的问题,提出通过小波方法识别异常电力负荷。该方法虽能实现异常电量数据的检测,但对异常数据的自主修复能力较弱[6]。蒋华等针对海洋浮标异常数据,提出通过改进K均值聚类算法实现异常数据检测的方法。该方法可自适应确定聚类中心,通过数据与聚类中心的距离均值筛选异常数据。该方法的异常数据检测率虽高,但误检率也较高[7]。
为保证智能电网中海量电量数据质量、高效识别异常电量数据,本文基于数据挖掘的电量数据异常智能识别和修复,通过粒子群优化-可能性模糊C均值(particle swarm optimization-possibilistic fuzzy C-means,PSO-PFCM)聚类算法识别异常电量数据,并运用径向基函数(radial basis function,RBF)神经网络实现异常数据的修复,以提高异常电量数据的识别准确率。
1 电量数据异常识别与修复
1.1 PFCM算法聚类数目自适应确定
由于电力系统的电量数据信息规模巨大,利用可能性模糊C均值(possibilistic fuzzy C-means,PFCM)聚类算法对其进行聚类时,聚类数目难以预测。通过设定指标函数的方式,可有效解决PFCM算法的聚类问题。函数的描述为:
(1)
式中:c为数据类别;n为样本数;r为聚类参数;bi为第i个聚类中心;uij为模糊矩阵。
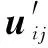
(2)
式中:tij为概率划分矩阵;k为归一化样本数。
(3)
(4)
由此说明,PFCM算法的指标函数在符合隶属度归一化限制条件的同时,可通过概率划分矩阵使聚类数目达到最优[9]。
1.2 粒子群算法
通过粒子群算法对粒子进行初始化。粒子选择遵循任意性原则,在不断迭代过程中寻求最佳答案。迭代过程产生两个最优解,分别为局部最优解和整体最优解,根据这两个最优解不断对粒子进行替换[10-11]。搜寻区域为d维。种群包含粒子数量为n。种群的第i个粒子在d维中的向量为Xi=(xi1,xi2,…,xid),i=1,2,…,n。飞行速度Vi=(vi1,vi2,…,vid),i=1,2,…,n。局部最优解为粒子搜寻到的最佳位置:
Pbest=(pi1,pi2,…,pid)
(5)
全局最优解为种群搜寻到的最佳位置:
gbest=(pg1,pg2,…,pgd)
(6)
vid=βvid+f1r1(pid-xid)+f2r2(pgd-xid)
(7)
式中:β为惯性权重;f1、f2为加速度因子,且f1≠f2;r1、r2为区间[0,1]内的任意数,且r1≠r2。
xid=pid+vid
(8)
通过式(7)、式(8),可对粒子的速度及位置进行替换。通过粒子群算法可进一步获得PFCM聚类算法的聚类中心。
1.3 基于PSO-PFCM的智能识别流程
异常电量数据的智能识别流程如图1所示。
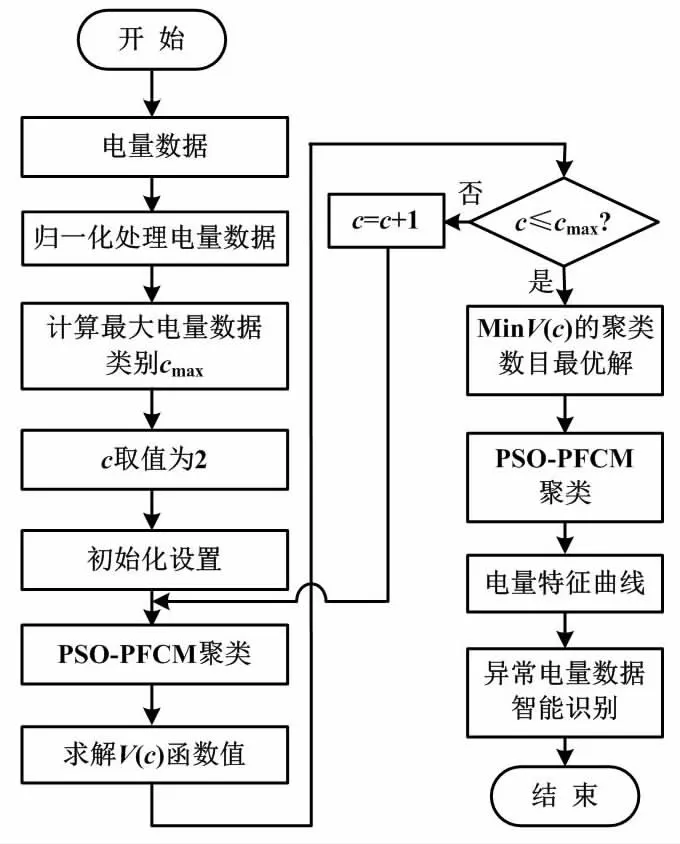
图1 异常电量数据的智能识别流程图Fig.1 Intelligent identification flowchart of abnormal power data
通过PSO-PFCM算法可实现电量数据的异常智能识别。电量数据异常智能检测流程如下。
①电量数据预处理。由于聚类结果会因电量增长受到一定影响,从而增加计算繁杂度,因此需归一化电量数据。
②电量特征曲线聚类。通过V(c)函数和粒子群优化(particle swarm optimization,PSO)算法确定聚类中心和聚类数量的最优解。PSO-PFCM聚类算法可实现电量曲线的聚类。
③电量数据异常智能识别。根据所获电量曲线对聚类结果进行研究,并结合全部类型电量曲线的特性对异常电量数据进行智能识别。
2 基于RBF神经网络的异常数据修复
2.1 输入、输出量选取
RBF神经网络是包含三层结构的前馈网络。三层结构分别为输入层、隐含层及输出层。本文方法以识别到的异常电量数据产生时刻为基点。该时刻前期的异常电量数据作为网络输入值,通过网络输出结果实现异常电量数据的修复。输出结果可用式(9)描述:
(9)
式中:x=[x1,x2,…,xm]T为神经网络的输入向量;m为输入层中的节点个数;y为网络输出向量;ωi为隐含层的第i个节点与输出层的权值向量;Ri(x)为网络隐含层的第i个RBF。
2.2 RBF及参数确定
RBF选取高斯函数,表达式为:
(10)

①采用K-means算法对训练样本进行聚类,以确定ci。聚类数量为隐含层节点数。
②根据ci确定σ,表达式为:
σ=bmin(ci-cg)
(11)
式中:b为叠加系数;cg为隐含层的聚类中心。
③ω采用最小均方(least mean square,LMS)算法计算,并通过对训练样本集分配的方式对其进行训练。分布式系统结构中增加计算节点数量。各节点构建RBF神经网络,将训练样本均分给各节点以实现并行处理。
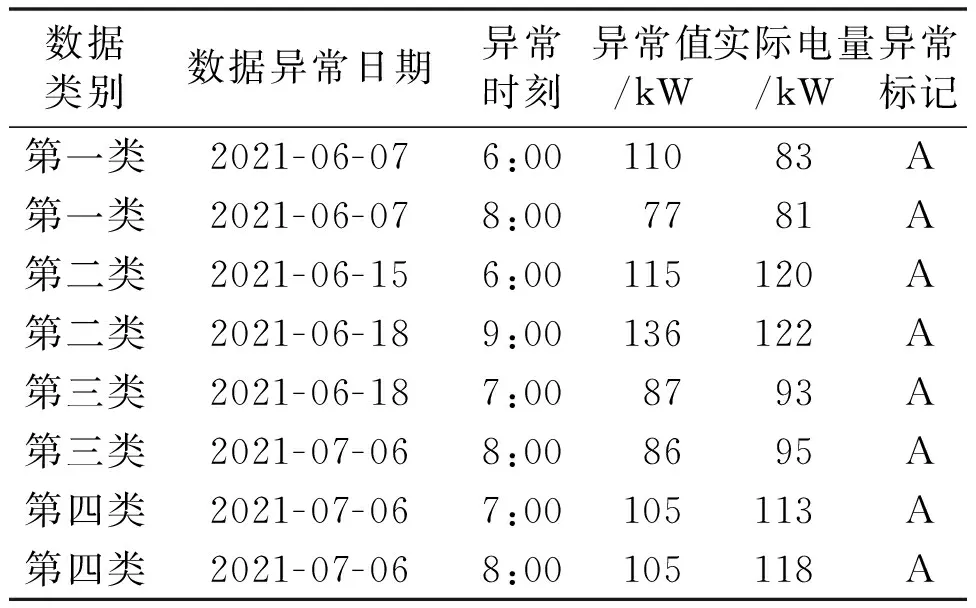
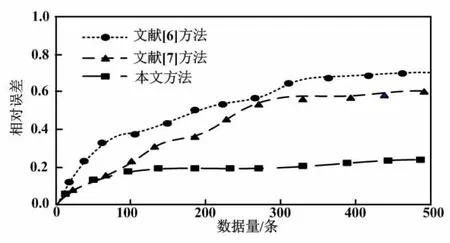
各节点实现任务处理后,获得权值向量ωi=[ωi1,ωi2,…,ωih]T,0 ω(m+1)=ωT(m)+ηX(m)e(m) (12) 式中:m为迭代系数,当m=0时,ω(0)为极小值;η为学习效率;X(m)为输入样本;e(m)为理想值与实测值的差值。 e(m)=d(m)-YT(m) (13) 式中:d(m)为理想输出;Y(m)为输出实测值向量。 在得到权值的基础上,本文训练各节点的RBF神经网络,以计算训练准确率。αi为各节点对于全部节点所占的比重,可通过准确率求得。RBF神经网络的权值向量可表达为: (14) 异常电量数据的修复流程如下。 ①对RBF神经网络异常数据修复模型进行构建。该模型可将识别到的大规模电量数据输入神经网络,并实现唯一结果的输出。基于某时刻的异常电量数据,以该时刻之前的电量数据作为历史数据,将其传输至神经网络。RBF输出结果为异常电量数据的修复值。 ②选取训练样本并对其归一化。预处理后的训练样本集分配到各训练节点,通过训练样本训练神经网络。 ③将历史电量数据输入训练好的RBF神经网络,得到对应的输出结果,并用输出结果替换异常电量数据。 ④异常电量数据修复后,通过相对误差检测修复是否准确。相对误差可描述为: (15) 式中:Zf为修复值;Z为原电量数据值。 异常电量数据修复流程如图2所示。 图2 异常电量数据修复流程图Fig.2 Abnormal power data repair flowchart 本文以某地区数据采集与监视控制(supervisory control and data acquisition,SCADA)系统为研究对象,采集当年6月、7月的电量数据并建立数据集。数据集中包含500条电量数据。试验随机选取其中300条电量数据作为训练样本,而剩余200条电量数据作为测试样本。为验证本文方法对于异常电量数据的智能识别能力和修复性能,试验在数据集中人为替换部分异常数据。 本文方法通过设计新指标函数对电量数据进行聚类,以确定最优聚类数;通过与原指标函数的对比,验证新指标函数对于确定聚类数量的有效性。最优聚类数确定结果如图3所示。 图3 最优聚类数确定结果Fig.3 Optimal number of clusters determines results 由图3可知,当采用原指标函数进行电量数据聚类时,指标函数值不存在最小值,无法判断出最优聚类数目。本文方法的指标函数在聚类数目为4时输出最小值为1。函数值越小,其聚类结果越接近真实数据规律。因此,本文确定最优聚类数为4。试验结果表明,通过本文方法可确定最佳聚类数目,且聚类效果较好。 在确定聚类数目的前提下,试验对数据集中的500条电量数据进行聚类,并以某个含有异常电量数据的聚类结果为对象,采用本文方法提取电量特征曲线,从而验证本文方法的聚类效果。电量特征曲线如图4所示。 图4 电量特征曲线Fig.4 Power quantity characteristic curves 由图4可知,在此类别电量曲线中,多数曲线的运行规律均与聚类中心的走势保持一致,仅有个别曲线偏离聚类中心。其中,异常电量曲线明显偏离聚类中心,且与聚类中心相距较远,完全违背了该曲线的原有数据规律。由此可判断,该曲线为异常数据曲线。因此,本文方法可智能识别出电量数据中的异常数据。 采用本文方法对数据集中数据进行智能识别,可判断各类别电量数据中是否存在异常数据。异常数据用A标记。各类电量异常数据识别结果如表1所示。 表1 异常数据识别结果Tab.1 Abnormal data identification results 由表1可知,本文方法可对数据集中的全部电量数据进行聚类,从而有效识别电量数据所属类别以及电量数据异常日期、异常时刻、异常电量值,并对异常数据进行标记。第一类电量数据6:00的电量值与实际值具有较大偏差,因此可进一步验证图4结果。 本文分别采用文献[6]方法、文献[7]方法及本文方法对电量数据进行异常识别,通过检测率及误检率指标验证3种方法的异常数据识别能力。异常电量数据识别效果分析结果如表2所示。 表2 异常电量数据识别效果分析结果Tab.2 Results of analyzing the effect of identifying abnormal power data 由表2可知,在同规模电量数据条件下:文献[7]方法的异常电量数据检测率最低;文献[6]方法检测率居中;本文方法的检测率最高,达到0.82以上。针对误检率指标,文献[6]方法最高、文献[7]方法居中。本文方法最低,低于0.06。试验结果表明,在3种方法中,本文方法的异常电量检测率最高、误检率最低,对电量数据的异常智能识别能力最强,效果最显著。 本文将训练样本输入RBF神经网络进行训练,运用训练后的RBF神经网络对异常电量数据进行修复,并与异常电量值、实际电量值进行对比,从而分析本文方法的异常数据修复性能。异常电量数据修复曲线如图5所示。 图5 异常电量数据修复曲线Fig.5 Abnormal power data fix curves 由图5可知,电量数据的异常时刻发生在6:00~9:00。在此期间内,电量数据异常值与实际电量值间存在较大偏差。经本文方法对其进行修复后,电量数据修复值接近于实际电量值。结果表明,本文方法可对异常电量数据进行修复,且准确度较高。 试验分别采用本文方法、文献[6]方法、文献[7]方法对异常电量数据进行修复,通过对比分析三种方法的修复相对误差,进一步验证本文方法的异常数据修复性能。修复性能对比曲线如图6所示。 图6 修复性能对比曲线Fig.6 Repair performance comparison curres 由图6可知,随着电量数据的不断增多,采用三种方法对异常电量数据进行修复,其相对误差呈现逐步升高的趋势。文献[6]方法的修复相对误差升高幅度最大,而文献[7]方法次之。本文方法的修复相对误差呈小幅度增长,仅增长了20%,且曲线增长更为平稳。试验结果表明,本文方法的异常电量数据修复相对误差更小、数据修复更准确、修复性能更显著。 针对智能电网电量数据增长迅猛导致的电量数据异常现象,为提高异常数据检测准确度,本文提出基于数据挖掘的电量异常数据的识别和修复方法。为验证本文方法的异常识别和修复性能,本文首先利用本文方法确定最佳聚类数目,并对电量数据的特征曲线进行提取;其次利用本文方法对数据集中的电量数据进行智能识别,判断是否存在异常电量数据,并与文献[6]和文献[7]方法进行比较,以验证本文方法的异常数据识别能力;最后对异常数据进行修复,以分析本文方法的修复性能。试验结果表明:本文方法可实现聚类数目及聚类中心的优化,通过电量特征曲线可智能识别异常电量数据;同时,本文方法对异常电量数据修复后,修复值与实际值的偏差很小。2.3 异常数据修复流程

3 试验结果分析




4 结论
