基于调度云平台通用分布式架构实践
2023-10-31邹文仲邓力源张高峰王凌梓章金峰
邹文仲,邓力源,张高峰,王凌梓,章金峰
(1. 南京南瑞继保电气有限公司,南京 211102;2. 中国南方电网电力调度控制中心,广州 510663)
0 引言
近年来,电力系统智能化、数字化不断发展,云计算、大数据、物联网等技术给电力行业注入了新的活力,智能电网建设得到了深入推进。伴随着气象、低压配网、分布式新能源等数据接入电网,如何对大规模数据资产进行合理的分析与应用,进一步提高电网数据综合分析能力和提升电网运行效率,已成为一个重大的研究课题。而云计算平台因其高效计算能力、动态资源扩展等特点受到了广泛关注[1-4]。
南方电网“调度云”平台于2019 年正式上线,其采用阿里云飞天操作系统构建,提供对象存储(object storage service,OSS)、关系型数据库(relational database service,RDS)和各类容器编排工具等基础组件。截至目前,已有调度、科研机构超200 套业务系统在云上运行。受限于对“调度云”平台理念理解不深,云平台部署运行的系统中存在单个容器存在多个进程、微服务拆分不合理、未能实现数据持久化等共性问题,这些问题给云平台整体安全、高效运行带来了挑战。同时,云上数据集成类系统中的任务处理、文件存储、数据库存储等核心功能多是集中式部署,此类部署模式资源利用率低、可靠性差、大规模数据处理时易出现瓶颈问题,这使得对调度云中系统标准化部署、大规模数据分布式处理及存取的研究分析成为亟待开展的重要工作。
目前,已有文献对云平台系统部署、大规模数据集成处理作了一些研究,文献[5]利用Hadoop 和数据共享技术设计了一种电力大数据的数据集成平台;文献[6-9]介绍了基于云平台构建的电网状态监测数据中心及数据治理和数据质量提升方案策略;文献[10]基于区块链技术提出一种电能量数据分布式采集模式,可以在提高计量设备数据采集效率的前提下保证采集过程数据的安全性;文献[11]提出基于区块链的分布式电能量数据可信存储机制,解决了电能量数据中心化存储安全性和存储效率低下的问题。可以看出,现阶段基于云平台数据集成的研究主要在数据如何高效计算方面,对于基于云平台的系统部署、分布式数据处理、文件存储、数据存储等鲜有介绍。
为此,本文依据现阶段电网调度云实际建设情况构建了一套系统典型架构。首先利用该典型部署架构解决了微服务拆分不合理、数据持久化存储等共性问题;进而利用分布式任务处理中心、分布式文件存储、分布式数据库存储、分布式业务部署等关键技术解决了数据集成系统中大规模数据处理易出现瓶颈的问题。该架构已应用于南方电网调控中心试点项目中,工程应用结果表明,本文所述架构具有数据吞吐量大、资源利用率高、数据处理效率高、存取速度快等特点,具有一定的创新性和行业借鉴性。
1 系统典型架构
1.1 通用数据处理流程
调度云平台作为大数据背景下面向电网生产、运营环节的大数据解决方案,为区域现货、负荷预测、电网气象等系统提供了可靠的技术支撑。调度云系统通用需求服务包括电网海量数据采集、云端多类型数据存储、云端数据分析和业务应用等,其数据处理流程如图1所示。

图1 调度云数据处理流程图Fig.1 Scheduling cloud data processing flowchart
数据流可分为数据采集、数据存储、数据分析和业务应用管理等环节。其中数据采集将数量众多的独立定时任务耦合成任务处理中心,并采用分布式部署实现任务功能的合理调配,提升数据处理的及时性、可靠性;数据存储主要包括结构化数据的数据库存储及非结构化文件存储,其数据来源于数据采集环节或数据分析环节;数据分析通过数据分析工具对海量数据源进行深层次智能分析,并将分析结果转发至数据存储环节进行存储;业务应用环节包括前端与后端模块,实现前后端分离式部署,并对上述步骤的分析结果进行综合展示及人机交互。
1.2 软件架构
依据调度云电力气象系统实际运行环境,分别利用云平台基础级IaaS(infrastructure as a service,如RDS数据库)、平台级PaaS(platform as a service,如各类容器)、软件级SaaS(software as a service,如云平台数据传输工具)实现了一套典型业务部署架构。该架构主要解决了单个容器中存在多个进程、微服务拆分不合理、未能实现数据持久化和云平台组件使用场景错误等共性问题。该典型架构对数据采集、数据存储、数据分析及业务应用等环节采用了全栈分布式架构。其中数据采集采用分布式任务处理中心实现;数据存储包括分布式文件存储及分布式数据库存储;数据分析及业务应用分布式在业务应用模块中实现。各应用模块架构如图2所示。
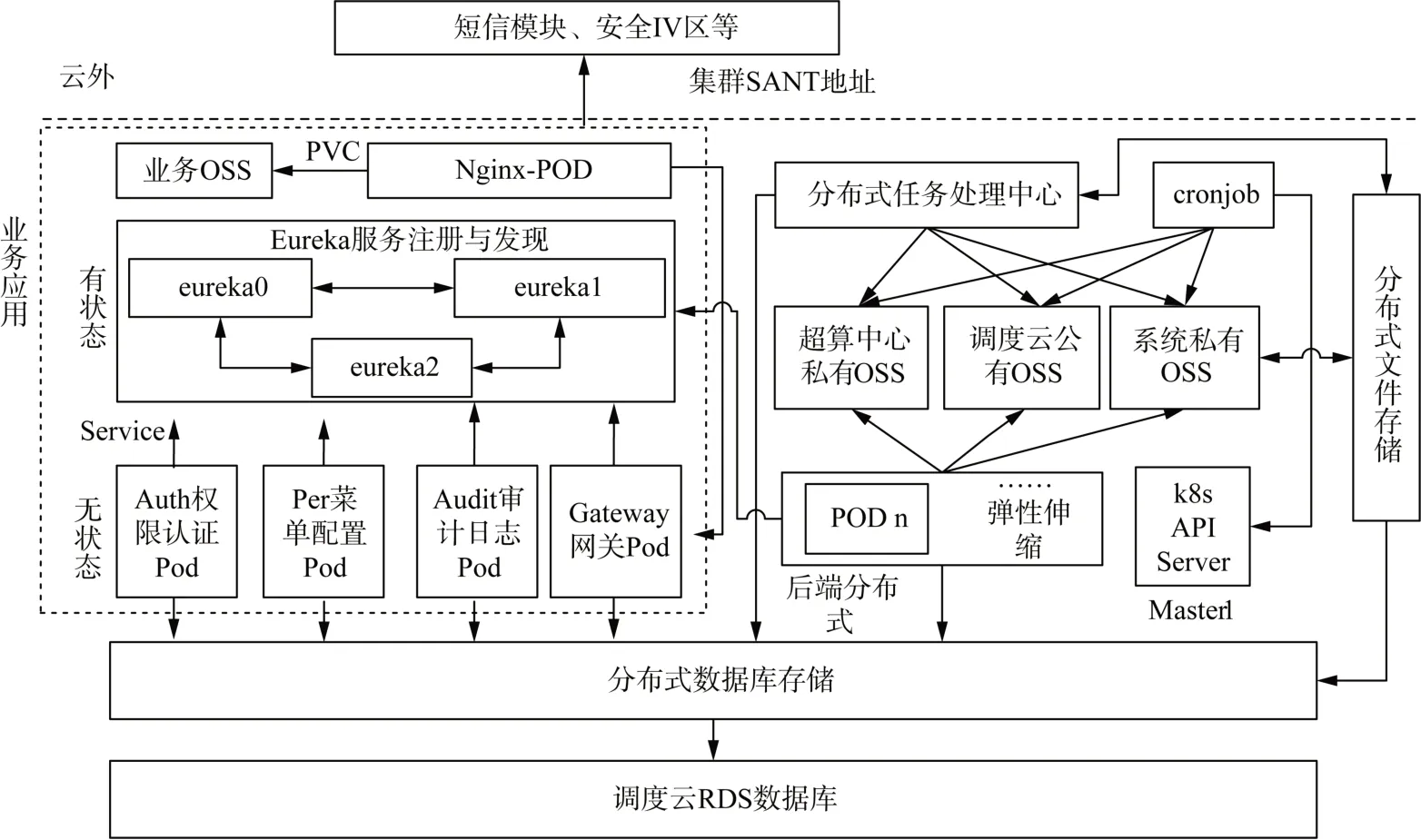
图2 系统典型架构Fig.2 Typical system architecture
系统整体运转流程是数据处理中心高效、及时处理各类气象数据,数值类数据存入RDS 数据库,文件类数据存入OSS,系统所有应用部署在容器中,并利用存储卷声明(persistent volume claim,PVC)的方式实现容器与OSS的交互[12-14]。
在数据采集环节,各数据提供商按照规定格式将数据推送至南方电网数据中心互联网大区,由内外网摆渡平台将数据转存至安全Ⅲ区中转节点,再由中转节点将数据推送至Ⅲ区调度云。任务处理中心将实况、预报、台风、山火、数值模式等气象数据解析处理后转存至分布式数据库及OSS中。任务处理中心采用基于微服务的分布式技术架构,可及时依据任务数实现任务处理中心执行器个数的弹性伸缩。
作为任务处理中心的补充,云平台Cronjob 组件在数据采集环节也发挥了重要作用。Cronjob 适用于大规模并行处理任务或需用独立镜像处理数据的场景,如台风模式预报数据,其在1h 内输出单个大小为1G、总数量为168个的预报文件,通过配置Cronjob 并行任务数、时间序列等参数,可以在30min内将所有数据处理完毕。
在数据存储环节,主要包括数据库存储及文件存储。数据库主要存储结构化数据,如实况、预报等;文件存储主要利用OSS实现非结构化文件的存储,如数值模式预报中各类图片、中央台各种文档产品等。数据库存储及文件存储皆采用分布式技术架构,数据库的分布式主要体现在基于数据库代理技术实现分库分表,如实况信息按月进行了分表存储,但应用访问时无需跨表查询,由代理服务实现了此功能;文件存储的分布式主要利用元数据理念与OSS实现海量多重异构数文件的快速存取,如数值模式预报每小时近1万张png图片。
在数据分析环节,通过数据挖掘及大数据分析技术,对采集到的数据进行校验清洗、指标计算等。该部分功能集成在业务后端应用中,通过微服务的方式实现分布式部署,并可依据计算量实现弹性伸缩。
在业务应用环节,采用“微服务+微应用”的互联网技术实现平台业务应用。微服务主要包括后端模块,微应用主要包括权限、菜单、审计、网关等前端组件。微服务通过访问分布式数据库及各类OSS 提供业务应用接口,微应用基于微服务接口利用多种展示组件构建人机交互的前端应用。业务应用环节整体采用分布式架构,并利用基于消息队列的单向网络传输技术将业务应用集成在4A 系统中,实现业务全网应用推广。
此外,系统在VPC(virtual private cloud)环境下构建一个私网流量的出入口,通过自定义SNAT(source network address translation )和 DNAT(destination network address translation)规则灵活使用网络资源,实现与云外系统的交互。
2 关键技术
为解决云上系统处理大规模数据时资源利用率低、可靠性差、易出现瓶颈等问题,本文分别对任务处理、文件存储、数据库存储、业务部署等核心功能研究探索分布式架构关键技术。
2.1 分布式任务处理中心
数据集成类系统核心功能之一是处理错综复杂的数据。如何及时、高效地把各类数据处理完毕是提升系统用户体验的关键。基于服务器自身或开源架构的定时任务处理模式具有版本管理困难、资源易抢占、处理滞后等缺陷[15-18],因此本文设计了一种分布式、模块化的任务处理中心。
分布式任务处理中心构建于通用数据服务层,可方便完成对异构数据的增删改查,快速地对本地及远程系统数据文件进行操作而无需关心软件底层实现,为系统提供数据的快速整合能力,架构如图3所示。
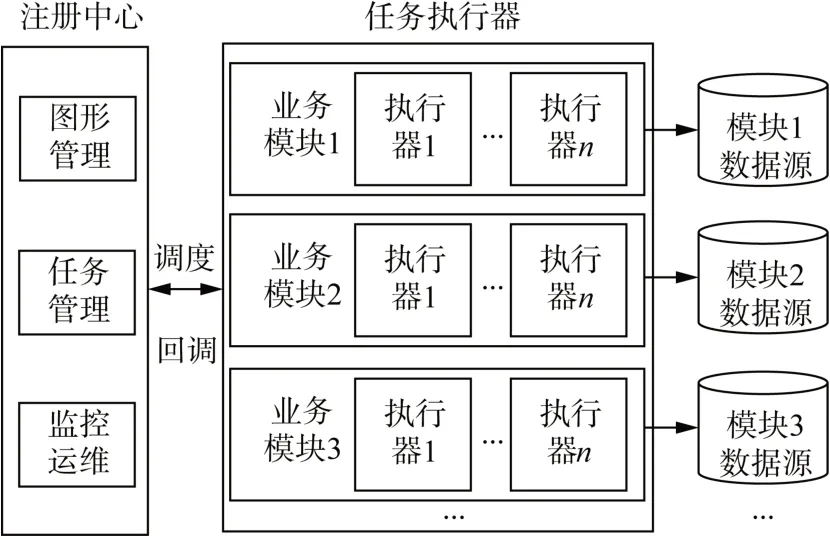
图3 分布式任务处理中心架构Fig.3 Distributed task processing center architecture
分布式任务处理中心分为注册中心和任务执行器两大模块,注册中心提供可视化图形管理工具,负责调度任务的分发、运维、监控。调度任务的分发可自定义调度策略,如轮询、随机、指定执行器等,且可以根据实际使用需求开发新策略。本文依据实际使用需求,开发了基于异常任务回收机制的综合负载调度算法,以解决执行器镜像更新时执行中任务失败导致数据缺失以及容器利用率低问题。首先定义执行器容器的综合负载:
式中:Q为容器的综合负载;C为CPU 利用率;M为内存利用率;D为磁盘利用率;N为网络流量。k1、k2、k3、k4为其对应的权重,满足k1+k2+k3+k4= 1,且ki>0。合理配置权重可使系统运行在最佳工况,如若待执行任务计算量比较大,对CPU使用率较高,则把k1调高,优先调度到CPU空余多的容器中。其次,执行器镜像更新时会导致正在执行调度任务异常终止,导致数据处理不完整,影响部分系统功能。为避免此类情况出现,在调度流程中加入了异常任务回收机制,对异常终止的任务重新分配资源调度,整体流程如图4所示。

图4 基于异常任务回收机制的综合负载调度流程Fig.4 Integrated load scheduling process based on exception task recovery mechanism
执行器模块专注于任务的执行操作,具有良好的可用性、可扩展性。可针对不同的业务或数据源,划分不同的数据集成模块,各个模块间相互独立,不具备耦合性,单个模块故障不影响其它业务模块的正常运行,开发、维护更加的高效。单个模块内部可配置多个执行器,多执行器分布式部署减轻了单个执行器压力,也避免了单执行器出现故障后整个业务模块不可用的情形,提高了整体架构的可用性。
综上,分布式任务处理架构相较于传统模式优势如下。
1) 通用性:支持多种类数据集成及信息转换。
2) 易维护性:所有任务都集成在统一项目中,版本管理方便,且提供可视化的图形维护界面,操作更简单直观。
3) 及时性:注册中心提供任务的监控告警功能,根据任务日志和回调结果可以清晰地观察到任务的执行情况,对执行出现故障的任务,可以通过配置告警,及时通知运维人员处理。
4) 易扩展性:对执行器配置弹性伸缩,根据执行器所在容器的CPU、内存使用情况及时调整执行器个数,避免任务的等待。
2.2 分布式文件存储
数据集成类项目接入数据庞杂,以电力气象系统为例,需接入超算中心模式预报、气象局监测站点、保护大数据、覆冰监测、山火监测和台风等系统数据,数据类型主要包括Json 数据、Xml 文件和图片等结构与非结构化数据。结构化数据读取处理后存入云数据库,非结构化数据,特别是模式预报数据,每小时有近万张png 图片以及近千个grib 气象专用文件,常规图片存储方式已不能满足要求,故探索研究了基于元数据存储管理文件索引、OSS存储数据实体的分布式架构[19-21]。
元数据即描述数据的数据,分为元数据采集、元数据存储、元数据管理和接口管理等功能。OSS云存储服务具有安全、高可靠性特点,其提供与调度云无关的Restful API(application programming interface)接口,方便文件的存储与调用。元数据与OSS 共同实现文件的分布式存储架构图如图5所示。

图5 分布式文件存储架构图Fig.5 Distributed file storage architecture diagram
元数据采集分为手动和自动两种方式,两种方式皆通过OSS 接口读取文件信息完成元数据的更新。元数据的存储根据实际情况分为公共元数据和实体元数据两部分。公共元数据是指所有数据都具有的元数据,实体元数据是指根据具体业务数据类型细分出来的元数据。以电力气象系统业务数据为例,公共元数据主要有:来源、OSS 存储位置、业务描述、数据更新时间和数据是否解析入库等。实体元数据以模式预报数据为例,主要有:模式名称、起报时间、预测时间和气象要素类型等。采用元数据管理的文件存储系统将分散、存储结构差异大的业务数据进行描述、定位、检索、评估和分析,以描述和分类的形式实现对所有类型数据的格式化,为数据自动处理创造了可能,提升了数据处理及访问的效率。
OSS 可利用丰富的API、SDK(software development kit )包和便捷工具进行二次开发。也可以通过控制台、图形化工具、命令行工具对OSS进行操作。根据数据场景使用的不同,提供标准、低频访问、归档和冷归档4 种存储类型,其中标准存储类型提供高持久、高可用、高性能的对象存储服务,可作为移动应用、大型网站存储方式。同时,OSS 还支持生命周期管理,对符合条件的特定数据进行删除,优化存储空间。
2.3 分布式数据库存储
对于不具备大数据处理技术的云环境,如何存取海量数据是影响系统性能的关键。传统云环境数据库如Mysql 对存储容量、读取速率都有一定的瓶颈,不适用大容量数据的存储。以电网气象系统为例,每小时有近1G 的增量数据,以实况气象信息单表为例,每天数据增量达80 万条,月数据增量2 000多万条,传统存储模式下,系统运行3个月以上数据读取速率就开始下降了。
为解决以上问题,传统做法是数据进行分库、分表存储。分库是指将一个大数据库分为多个小的数据库,分表是指用水平切分、垂直切分等方法将一个数据库表拆分成多个数据库表,此种方法应用和数据耦合度高,当数据量增加需要对数据库、表进行扩展时,都需要对应用程序进行改造,风险高、可维护性差[22]。
为此本文设计了一种基于数据代理的分布式存储方案。它由监控管理、数据库连接、结果集处理、路由解析和通信协议等模块组成。当数据量增加,数据库、表需要扩展时,无需修改应用程序,只需修改中间件配置即可。该代理服务工作原理是拦截应用发过来的SQL,并对SQL 语句作特定分析,如分片分析、路由分析、读写分离分析、缓存分析等,然后将此SQL传送至真实数据库,并对返回结果做适当处理后返给应用。架构如图6所示。

图6 数据代理服务架构图Fig.6 Data broker service architecture diagram
数据代理服务工作流程如下。
1) 配置分库、分表信息,启动代理服务时除读取分库分表信息外,还会生成所有真实数据库的datasource缓存池。
2) 客户端连接数据代理服务,并发送需要执行的SQL语句。
3) 数据库代理接收到SQL 语句,利用SQL 解析及优化组件完成真实库表、分片的信息,并把分析的结果连同SQL语句一并送入执行组件。
4) 执行组件按照分析的结果连接对应数据库执行SQL语句,等待结果返回。
5)执行组件将返回结果发给结果处理模块进行排序、合并等操作后返给客户端。
基于数据代理的分布式存储方案支持多种数据库类型,易扩展,支持读写分离及故障切换。从开发者角度来看,将分表虚拟成一张表,简化了数据查询复杂度,提高了开发效率。
2.4 业务系统分布式部署
传统web 项目前后端放在同一工程项目中,如Spring MVC(model view controller)架构。此种开发模式项目资源耦合程度高、服务器压力大,一旦宿主服务器故障,系统所有模块皆不可用,用户体验差;此外还存在开发效率低、页面加载慢等问题,故此种开发模式已逐渐被前后端分离的开发模式替代。本文以前后端分离的开发模式来介绍业务系统分布式部署[23-25],架构如图7所示。

图7 业务系统分布式部署架构Fig.7 Distributed deployment architecture of business system
业务系统分布式部署分为总体分布式以及前后端模块分布式两部分。总体分布式是指系统中所有功能模块如前端、后端、权限、网关、菜单等都是单独服务、分布式部署,通过网络服务(service,SVC)实现模块间相互通信并根据实际需求配置模块的副本数。前后端模块分布式是指模块内程序与服务的分离,前端分布式是指除前端副本数可根据用户访问数伸缩外,项目程序文件以PVC方式关联前端容器,实现了前端程序文件的热部署;后端分布式是指引入负载预测技术,通过水平伸缩控制器(horizontal pod autoscaler,HPA)实现后端服务的弹性伸缩。
业务系统分布式部署具有如下优势。
1) 项目整体分布式实现了项目高可用性,不因单个服务器故障导致系统宕机。
2) 前端模块分布式可依据实时访问量扩展副本,如按照两万访问量/单个前端副本的规则进行伸缩;同时,Nginx 容器项目目录通过PVC 方式映射至OSS目录,系统更新时不必重新制作镜像及重启容器,增强了用户系统体验及系统可维护性。
3) 后端分布式则采用了弹性伸缩策略。构建了基于Kubernetes 原生自定义指标接口并与HPA 交互完成伸缩,且引入多种预测技术,让系统提前感知访问量的变化,做到伸缩先于访问量,减少系统卡顿。
3 工程应用
上述分布式架构已在南方电网试点项目中部署运行,基于阿里专有云技术,所用Kubernetes 集群为1.7 版本,集群开通了4 个OSS 的访问权限,数据库采用RDS数据库,系统所有模块皆采用上述分布式部署架构。
3.1 分布式文件存储性能分析
系统所需分布式存储的文件主要是模式预报生成的各类图片文件,每日数据增长约40 G 左右。为验证分布式存储性能优势,本文基于调度云OSS测试了分布式存储和集中式存储的性能指标。其中分布式存储采用2.3 节所述方式,即采用元数据管理模式将文件索引存入RDS库,文件体存放在OSS中;集中式存储方式是指对文件不做任何处理采用堆积的方式存入OSS相应文件夹。两种模式OSS存储文件内容完全一致,存储容量为5T,对特定日期的降雨图片执行查询、存储操作,通过多次重复执行程序获取消耗时间的平均值来代表该项操作的时间。统计结果表明,分布式存储方式下,单个图片文件查询展示及存储时间分别是95 ms及110 ms,而集中式存储方式下时间分别是988 ms 及472 ms,查询展示时间缩减了约90%,存储时间缩减了约76%,大幅提升了系统数据存储效率及用户体验。
3.2 分布式任务处理中心性能分析
分布式任务处理中心采用单个注册中心、多任务执行器的配置模式。执行器的个数可根据任务负载情况弹性伸缩,判据为执行器CPU或者内存使用率达到容器分配值的80%,任务调度的算法为本文提出的新调度算法,在容器内部通过系统命令测试了不同任务数下平均负载及网络响应时间,如图8所示,并在云管中心监控新调度算法与普通轮询算法在不同任务数下执行器的个数,如表1所示。

表1 执行器个数对比Tab. 1 Number comparison of actuators

图8 多执行器下系统性能图Fig.8 System performance diagram under multiple actuators
结合表1、图8 可以看出,新调度算法充分发挥每个执行器POD 的性能,在完成相同任务数的前提下,需要的POD 数量更少,更节约资源,在任务数为800、1 300等高负载情况下,分别可节约40%、33%的资源使用量。此外,得益于执行器的分布式及弹性伸缩,随着任务数的增长,平均负载及网络响应时间皆保持相对稳定水平,避免了因任务数激增导致的进程卡顿情况出现。
3.3 分布式数据库存储性能分析
数据库存储采用上述分布式方案,配置3 个数据库:实况数据库、预报数据库、其他数据库。气象实况类数据按月进行分表,预报类数据、台风数据按年进行分表,其他类型数据根据实际情形进行分表。为验证分布式数据库存储的优势,设计了对比实验来分析性能优化程度,以数据库中实况站点跨月查询统计极值需求为例,实验组为基于数据代理的分布式存储方案,即本文介绍的方案,对比组为数据集中式存储方案,即数据单表存储。执行相同SQL 语句,通过多次重复执行SQL 获取消耗时间的平均值来代表不同读写次数下消耗时间,对比结果如图9所示。

图9 数据库读写性能对比图Fig.9 Database read/write performance comparison chart
可以看出,基于数据代理的分库分表技术SQL执行时间在不同读写次数工矿下都比单表存储短,读写次数越多,性能提升越明显,1 000 读写次数情形下,实验组及对比组耗时分别是316 ms、483 ms,耗时减少约35%。
3.4 业务系统分布式部署性能分析
业务系统采用图5 所示的分布式部署架构,利用公式(2)计算得出近一年系统可用率高达99.8%,相较于传统集中式部署方式可用率提升近3%。
3.5 应用效果
得益于系统全环节分布式及新任务调度算法的扩展性,目前试点项目南方电网气象系统在仅有11台ECS 节点(16 核CPU、32 G 内存)的调度云环境中全面接入了8 000 多个气象站点、4 套数值模式、南网区域雷达云图、卫星遥感等气象数据[26],系统运行一年半以来,RDS 数据库存储容量接近1T,OSS使用容量约5T,在云桌面用浏览器查看系统各接口响应时间,统计结果表明数据库及OSS响应时间均维持在80~420 ms 之间,实现了全网气象数据的统一采集、存储及应用。2022年台风灾害天气期间,系统访问量激增,高峰时刻约5 000 并发访问量,而此时在云桌面浏览器中多次刷新台风页面系统最长响应时间仍保持在2s内,得益于分布式架构优势,系统保持平稳、高效运行。
4 结论
本文针对调度云环境下分布式架构技术进行分析和研究,取得主要成果如下。
1) 首次将元数据管理技术与调度云组件相结合,提升了调度云环境中大规模非结构化文件的存取速度,平均查询时间减少了约90%。
2) 首次将数据代理技术与调度云RDS 相结合,提升了高频数据的存取性能,读写次数越多,性能提升越明显。
3) 提出了基于异常任务回收机制的综合负载调度算法,解决了分布式任务处理中心因外部操作导致的数据缺失、容器利用率低的问题。
4) 建立了调度云环境中全栈分布式架构,涵盖数据处理流程全环节,有效提升了数据集成类项目数据处理能力及系统高并发响应能力,具有一定的行业借鉴性。
下一步需在以下两方面深入研究。
1) 扩展平台在电网实时监控类系统中的应用,研究基于调度云实时库、时序库分布式架构技术。
2) 研究分布式内存技术在调度云环境中的应用,提出分布式内存与分布式存储优化调度算法,进一步提升系统存储性能及用户体验。
