基于Spark的大数据分析系统设计和实现
2023-10-31边宁
边 宁
(淄博市政务服务中心 山东 淄博 255000)
0 引言
随着科学技术的不断发展,网络中产生了海量的数据。面对海量数据流的影响,如何实现对网络当中存在的大数据实施高效地分析已经成为了当前学者的研究特点。而大数据的核心问题就是对大数据的分析处理。传统的大数据处理及分析方法,已经无法有效满足当前阶段对大数据的高效、实时存取和处理等方面的需求。丁鹏程[1]对用户行为数据分析包含数据采集、数据存储、利用等多个阶段实施分析,但是该方法存在用户行为数据丢失的漏洞。林星星[2]主要针对Spark在商品个性化推荐这种特殊场景中的应用展开研究,借助混合推荐算法,虽然解决了商品个性化推荐过程中存在的数据稀疏性及实时性等问题,但数据信息的处理效果相对较差,会导致系统的性能下降。上述方法均不能精准地实现大数据分析,因此,为解决上述问题,提出了一种基于Spark的大数据分析系统设计方案。该系统的框架选择适用性较强的Spark计算框架为主,能够支持多种类型语言的编程,此外还可以实现对大数据的交互式、批量处理、计算分析。基于Spark的大数据分析系统,以实现对大数据的实时分析。
1 Spark技术概述
Spark作为UC Berkeley AMPLab所开发的一款大数据计算框架,它和Hadoop两者之间既有相似部分,也有不同[3]。不过,Spark和Hadoop两者都具有分布式优点,能够实现对大数据的快速集群计算,并且Spark在Hadoop集群上运行,还可以实现对Hadoop当中的数据资源进行实时访问。Spark支持多种不同文件格式,对数据展开分析和处理,其数据结构主要以RDD(resilient distributed datasets,弹性分布式数据集)为主,且该数据集在完成创建之后无法修改。因此,在大数据分析处理中,Spark能够适用于机器学习与数据挖掘。此外,spark具有良好的工作负载性能,不仅可以实现交互式查询,还拥有内存分布式数据集性能,可以对迭代工作负载进行相应的优化。因此,在不同的应用场景当中,spark系统的各个组件具有不同的作用,具体见表1。

表1 Spark的应用场景
2 基于Spark的大数据分析系统设计及实现
2.1 系统设计原则
首先,从大数据分析系统的设计原则方面进行分析,考虑到后期数据量的增加及随着业务需求的提升,所使用到的组件也会增加,集群得到扩展,进行基于Spark的大数据分析系统框架设计。其次,结合该系统的功能需求,以及需要考虑的后期项目自身的扩展性,针对大数据分析系统的设计,应当严格遵循依赖倒置原则、开放封闭原则、接口隔离原则、单一职责原则、里式替换原则及迪米特法则等设计原则。其中,从依赖倒置原则来看,设计分析系统的上层模块并不会依赖底层的模块。从开放封闭原则来看,在进行大数据分析系统设计时,若没有严格遵循此原则时,就会使得项目的后期受需求变化的影响,可能会在原本的代码上进行修改,以及对部分代码进行重新编译、测试以及部署,从而会耗费很大,影响系统的扩展。
2.2 Spark集群搭建及环境配置
首先,Spark的运行需要Scala的支持,在进行Spark安装之前,需要先完成Scala环境的安装。然后,通过从官方网站上下载Spark源码,利用编译器进行编译。其次,利用Worker节点的主机名字,通过Spark文件配置写入到每一台的虚拟机设备中的Slaves文件当中,当写入作业完成之后,还需要对Spark安装目录当中的文件节点进行修改。并且,还需要集群上的所有节点文件和Slaves文件当中的内容相一致。在完成所有配置作业之后,可以选择利用Spark on YARN模式开启Spark集群。集群开启之后,可以通过浏览器进行浏览,并对集群的启动情况进行查询与测试。此外,由于Spark是由Scala编写而成,因此针对系统的Spark应用程序的开发语言选择应当为Scala。这样一来,在调试时,可以直接在开放环境当中调试,而不需要将作业上传到集群上进行调试。
2.3 大数据分析系统设计
2.3.1 系统总体框架设计
Spark计算引擎作为一种拥有通用性优点,能够实现对大规模海量数据的快速计算与处理。结合官方所给出的数据信息来看,Spark和HadoopMapReduce两者之间进行对比,Spark的计算引擎运算速度快于后者100倍。同时,Spark自身的运行模式拥有本地运行模式、独立集群运行等特征[4]。因此,采用Spark为框架构建大数据分析系统,其系统框架主要采用分层设计,分别为数据应用层、服务层、数据计算与存储层及基础层4个层次。基于Spark的大数据分析系统框架示意图,如图1所示。

图1 基于spark的大数据分析系统框架示意图
从数据基础层方面来看,该层次设计主要包含了系统的底层软件和硬件。其中底层软件主要包含了安装配置在服务器上的操作系统及Java基础环境等软件;而系统硬件部分主要包含了服务器和网络运营商。从服务层方面来看,该层的设计主要提供了工作调度功能、系统管理功能、服务接口功能以及工作管理功能等。其中,服务接口功能主要为服务层向Web提供restful接口,从而让系统前端能够获得管理与工作调度的能力。并且,该层直接会接入到Spark当中。从数据计算与存储层方面来看,引入了Spark,通过分布式存储系统所采集的数据信息,利用虚拟技术可以实现对数据信息的统一管理。同时,该层的设计主要包含了HDFS、YARN组件及分布式集群环境Hadoop等。其中,HDFS的应用为大数据分析系统,提供了较高的容错分布式文件系统。YARN的应用,为分布式资源管理器的分布式集群提供了统一的工作调度以及资源管理。此外,由于Spark在应用过程中采用了Spark on YARN模式实施了部署。因此,其计算工作同样交由YARN进行统一的调度与管理,且为了解决Map Reduce存在的高计算延迟问题,本文选择利用Spark作为数据计算工具来解决磁盘开销较大、高计算延迟等问题。最后,数据应用层的设计主要利用Web端借助服务层向用户提供各种接口的功能,以此实现对数据和信息的提取,并利用图表、文字等形式展现给客户。
2.3.2 系统主要功能模块设计
基于Spark的大数据分析系统主要包含了数据源、分析检测模块、报文预处理模块及Flume模块等主要功能构成。主要功能模块设计框架,如图2所示。其中,在大数据分析系统当中,Flume模块作为一种分布式日志聚合模块,其设计主要作用于对大数据的采集。Spark为计算模块,HDFS作为Hadoop分布式文件存储模块,其主要作用就是负责大数据的存储。而大数据分析系统当中的数据源,主要指网络当中或者服务过程中的大数据,如网络抓包报文、网络设备所提供的NETFlow数据和系统运行过程中所产生出来的日志文件等。通过利用分布式日志聚合模块,实现对系统运行过程中所产生的日志文件和相关数据进行实时采集及预处理后,将处理完成的大数据再上传到对应平台上。其中,一部分经过处理的大数据会通过平台直接保存到分布式文件存储系统当中。而另一部分大数据就会通过Spark对其进行有效处理与分析。因此,在设计大数据分析系统时,一般会采用分布式文件对大数据进行存储,接着利用架构将大数据均衡到集群的工作节点之上,这样Spark就能够实现对本地分块数据进行读取和计算,并且整个过程并不需要再计算整个大数据,由此降低了集群节点数据交互传输,使得系统对大数据的分析效率得到进一步提高[5]。
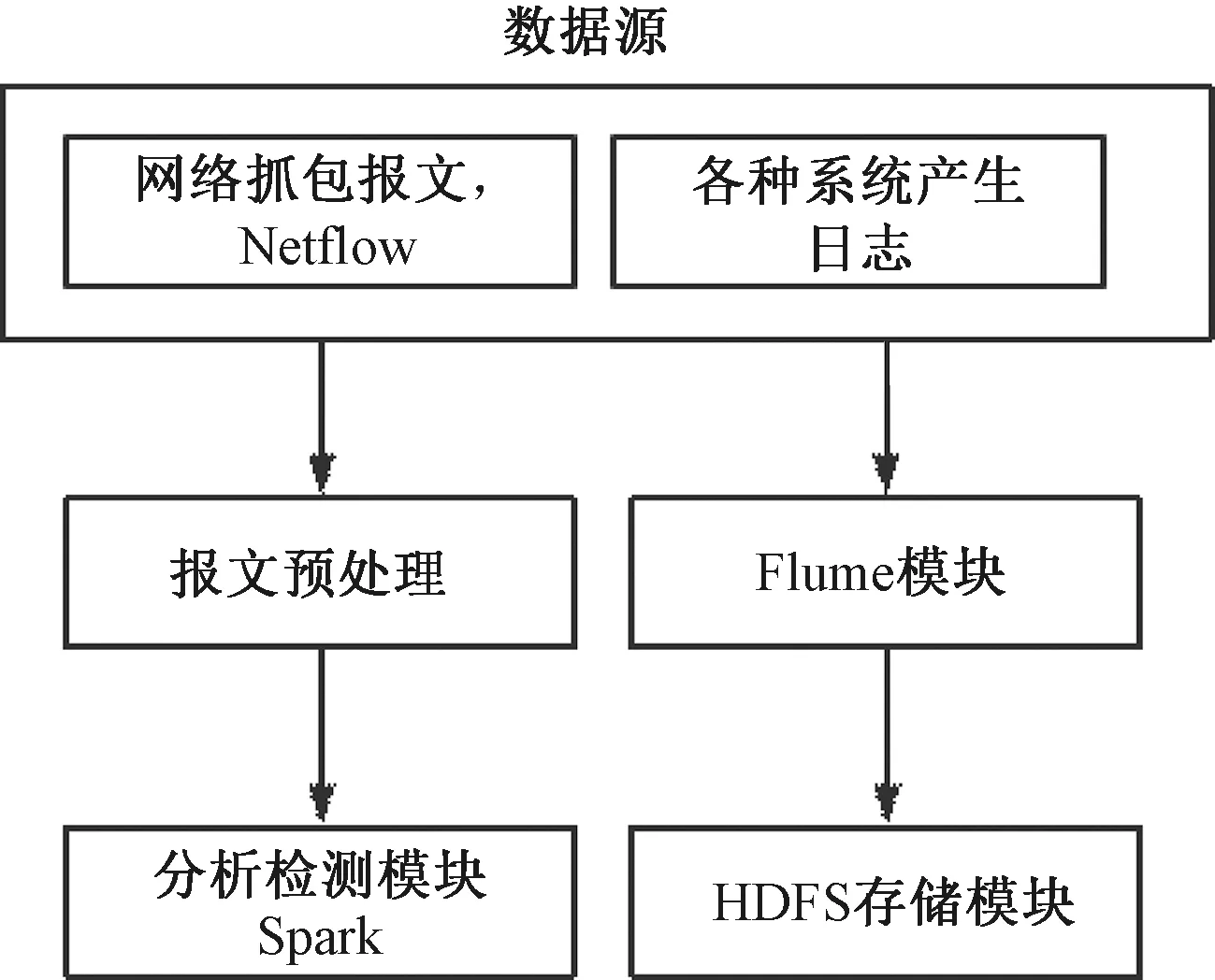
图2 主要功能模块设计框架
(1)分布式日志聚合模块
该模块的设计其功能主要是在接收到数据采集的相关命令之后,对所采集的大数据实施预处理和采集。分布式日志聚合模块的运行过程十分简单,并且对日志的收集也没有限制,其使用的范围相对广泛。同时,分布式日志聚合模块的设计,主要由Source组件、Channel组件及Sink组件这3个组件构成。其中,Source组件的设计实现了对系统原始日志的采集和分析。而Channel组件的设计主要负责为大数据分析系统提供临时的缓存通道。此外,还起到了对Source组件和Sink组件两者之间的连接服务,最后将所收集到的日志信息通过Sink组件上传到每一个模块之上,以此完成大数据交付。分布式日志聚合模块还拥有较强的可扩展性与低耦合度,可以支持多级流处理大数据[6]。
(2)分析检测功能
大数据分析系统当中,分析检测模块的设计具有在线获取可扩展性数据的作用。针对该模块的设计,主要分为HDFS和Kafka这2个部分组成。其中,从HDFS模块方面来看,其数据主要为能够扩展的大数据,通过HDFS当中的大数据可扩展性实现对KAFKA当中的数据进行分类处理,这样一来就能够得到具有扩展性的大数据。同时,分析检测模块的设计主要由离线训练模块SPARK及在线数据检测2个部分组成。首先,从离线训练模型方面分析,利用Spark对HDFS当中的大数据进行读取之后,通过对数据的清洗,提取出关于大数据的特征信息,再根据特征信息进行模型训练,当完成模型训练之后,再将其特征输入到分类模型当中。而在线分析检测,主要是对从KAFKA当中所获取的大数据进行重复和离线训练模型类似的训练,并采用Spark所输入的特征模型,实现对数据的检测分析。在2种模式的作用下,不仅可以促进大数据分析的效率得到提升,还能够保障大数据检测的实时性。
2.4 系统软件设计
大数据分析系统的软件设计,其中Spark模块主要选择采用ALS算法,实现对网络中大数据的有效排名获取,并利用Pagerank算法从中网络当中得到有关大数据的价值排名,最后在根据排名结果推荐的大数据,对专业大数据展开有效分析。
3 实验结果与分析
3.1 实验环境搭建
为了进一步验证基于Spark的大数据分析系统的可行性,需要通过相应的实验对其进行分析。首先,针对实验过程中所应用的计算机硬件配置,CPU为32位、内存为128 GB及硬盘为64 TB。其次,针对此次实验过程中所应用到的实验数据,本文选择以某企业网络系统正常工作状态下所产生的日志作为本次实验的主要数据源。接着,利用Flume将该企业系统的某个时间段内的查询日志全部写入到HDFS当中,得到了大小为128 GB的数据样本。此外,实验开始前,考虑到系统的有效性,本文选择对系统的性能进行分析,从中得到系统关于系统的运行效果。
3.2 性能对比分析
针对系统的性能分析,本文主要从系统分析数据的耗时和分析的精度2个方面进行综合考量。并对比本文系统、列存储系统等对数据分析的耗时情况,来判断本系统的可行性。随着数据样本数量增加,系统运行时间也会随着样本数量的上升而增加,通过对这2个系统进行对比分析来看,本文系统的运行时间相对较短。且在实验中后期,本文系统分析可扩展性大数据耗时约为150 ms,处于相对稳定的状态,而其存储的耗时在不断上升,当实验时间在380 ms 时收敛。因此,随着大数据样本量的增加,本文系统不仅耗时短,且系统的稳定性较好。同时,本文系统在对具备可拓展性大数据进行分析的过程当中,需要利用训练模型优化、更新数据集等步骤,才能够实现对此类大数据的有效分析,再通过多次的迭代之后,本文系统会随着迭代次数的增加,系统的运行时间却几乎没有变化。由于本文系统采用Spark建立训练模型,将中间数据缓存结果存储在自身内存中,经过多次迭代,运行时间变化较小,运行时间较为平稳。
4 结语
综上所述,通过对Spark技术和Hadoop技术进行分析,并兼顾2种技术构建了Spark on YARN集群环境,结合设计原则设计实现了基于Spark的大数据分析系统。从计算引擎选择方面,本文选择利用Spark计算引擎,以此提高了大数据计算速度,并利用Spark on YARN模式,充分发挥出了Spark自身的优势。且通过对该系统的测试,结果证明了本文大数据分析系统的可行性,以及可扩展性。
