基于RDSRCNN的单幅图像去雨模型研究
2023-10-31傅继彬李春辉
傅继彬,李春辉
(河南财经政法大学 计算机与信息工程学院,河南 郑州 450046)
0 引言
雨是自然界中的一种常见气候,但是雨滴在图片上造成的雨痕不仅会劣化人对图像的视觉感受,而且由于大量计算机图像处理算法都假定输入图像清晰且可见度高,因此图片上的雨痕会对诸如目标检测、目标跟踪、图像分割等图像处理工作造成不良影响。综上,图像去雨模型研究具有重要现实意义。
对于带有雨痕的图像,即雨图像,使用最为广泛的模型[1-2]为:
其中,O为雨图像,B为所期望获得的无雨背景图像,R为在背景图像上层的雨痕。图像去雨的目标即为从O中分离B和R,以获得无雨背景图像。由于需要求解的未知项是已知项的2 倍,故求解本身并不容易。因此,实现彻底完善的图像去雨是计算机图像处理中一项具有挑战的工作。
从现有文献看,雨痕层R主要分为3 类,分别是线性形雨痕、离散雨滴[3]和聚积雨雾[4]。在方法分类上,之前提出的图像去雨方法大致可划分为视频图像去雨和单幅图像去雨2 类,其中视频去雨所需的连续帧图像与图像中物体相对稳定的要求在现实拍摄条件下并不容易满足。而单幅图像去雨不仅应用灵活,且可用于增强视频去雨的单帧图像处理性能。因此,自出现起单幅图像去雨就是视频去雨领域的重要研究方向。随着以视觉Transformer(Vision Transformer,ViT)[5]为代表以Transformer 为基础的图像处理方法的出现,以及摆动Transformer(Swin Transformer,ST)[6]的提出,以ST 为基础构建而成的图像处理方法Swin 图像恢复(Swin Image Restoration,SwinIR)[7]能以更优的效能提取图像内的特征,将其与单幅图像去雨方法结合可以有效提升其效能。
本文提供一种基于DSRCNN 的单幅图像去雨模型,利用增强型SwinIR 图像特征提取模块优化去雨方法效果,加深DSRCNN 网络结构,使用更为合理的损失函数,该方法创新点如下:①利用增强型SwinIR 图像特征提取模块(Enhanced SwinIR Image Feature Extraction Module,ESIFEM)取代深度去雨卷积神经网络(Deep Rain Streaks Removal Convolutional Neural Network,DSRCNN)[8]中的残差块,提取图像中的浅层与深层特征,建立Swin DSRCNN 的每级网络,通过更为高效的特征提取优化去雨方法效果,进而通过若干级网络的顺序结合构成残差Swin DSRCNN(Residual Swin DSRCNN,RDSRCNN)网络;②加深DSRCNN 网络结构并在除最后一级外的每级网络的输出上应用残差连接,串联本级网络与上一级网络的输出(或原图像),以此增强DSRCNN 的去雨能力以及保证输出图像的无雨背景强度,并降低提取特征所需的模型复杂度,以此构成单幅图像DSRCNN 去雨模块(Single Image DSRCNN Derain Model,SIDDM);③在损失函数上,l1范数[9]与MS-SSIM损失函数组成复合损失函数而非单一的l2范数损失函数,这种复合损失函数对图像亮度、颜色和对比度的保留能力优于l2范数损失函数,可增强网络本身的学习效率。
1 相关研究
图像去雨可分为视频去雨和单幅图像去雨两种,其中视频去雨问题最早在文献[10]中被提出。历经十几年发展,视频去雨领域既有传统的无网络方法[11-12],也有基于卷积神经网络(Convolutional Neural Network,CNN)的端到端深度学习去雨方法[12-13]。近期,Jayaraman 等[8]提出一种基于高效视频编码器(High-Efficiency Video Coder,HEVC)后处理优化算法DSRCNN,在此方法中,通过合理利用激活函数等方法避免了CNN 在去雨任务下的过拟合问题并加快了网络收敛速度。
单幅图像去雨工作由于其较高的复杂度,研究起步晚于视频去雨。在传统方法中,Kang 等[14]提出通过将去雨问题转换成形态分量分析(Morphological Component Analysis,MCA)问题实现单幅图像去雨痕。该方法利用基于MCA 的字典学习和稀疏编码将图像分为有雨和无雨两部分,进而完成去雨。Chen 等[15]提出并建立一种在二维图像上将矩阵变换为张量的低秩雨貌模型以捕获时空相关的雨痕,而后将这种模型泛化到高阶的图像结构(例如图像)上。
2017 年后,单幅图像去雨方法中引入了深度学习方法。DerainNet[16]通过学习无雨图像和雨图像之间的非线性映射关系进行去雨,深度细节网络(Deep Detail Network,DDN)[17]通过学习负残差细节实现去雨。Yang 等[18]提出联合雨水探测和清除(Joint Rain Detection and Removal,JORDER)的方法,首先利用膨胀网络学习主要特征,然后逐步去雨。随着循环挤压—激励上下文聚合网(Recurrent Squeeze-and-Excitation Context Aggregation Net,RESCAN)[19]、渐进循环网络(Progressive Recurrent Network,PReNet)[20]、密度感知的 多流密 集连接 网络(Densityaware Multi-stream Densely Connected Network,DIDMDN)[21]与空间关注网络(Spatial Attentive Network,SPANet)[22]等模型提出,深度神经网络已经成为去雨模型的主流算法。
Vaswani 等[23]首次提出Transformer 的概念,其在自然语言处理[24-25]上取得最先进的技术(State of the Art,SOTA)表现。在图像处理方面,Transformer 的自注意力机制没有CNN 卷积核处理不同的图像区域效果不佳这一问题,而是能捕获全局图像内容间的互动。由此其最初被应用于图像处理[26]和高级视觉问题处理[27-28]中。虽然全局自注意力机制能高效捕捉长距离上的像素互动,但其计算复杂度会随着图像分辨率的上升而呈平方级提高。举例而言,一幅大小为h×w,其图像的全局自注意力处理的计算复杂度Ω(MSA)为(C为常数):
因此,全局自注意力机制不适用于高分辨率图片。针对这一问题,文献[6-7,29]给出了大致2 种解决方案:文献[6-7]指出只对一个像素四周区域,即一个窗口的区域进行窗口自注意力处理;文献[29]指出将输入图像分解为多个互不重叠的块,而后分别对各块内进行自注意力处理。以上文献指向限制自注意力处理的扩展范围,以求在捕捉尽可能长距离像素之间关系的前提下实现高效图像处理。
2 RDSRCNN方法
本文端到端单幅图像去雨方法RDSRCNN 的去雨网络为N级网络,如图1 所示。整体网络的输入为由单幅雨图像与无雨真值图像所构成的图像对,将图像对中的雨图像输入特征提取模块进行特征提取并去雨,真值图像用于每一级网络。每级网络的输入∈Rc×h×w在经过归一化及特征提取后,取得第n个特征张量特征张量的大小cE×hE×wE根据方法中人为设置的投影维度(本文为90×16×16)确定。而后将特征输入DSRCNN去雨模块进行处理,处理结果为第n个中间结果图像,然后将中间结果图像与图像对中的真值图像输入混合损失函数LMix并进行反向传播。如此,整个网络中的一级处理结束,若网络级数低于设置数量(本文中为4),则下一级网络的输入为即对本级网络输入与上一级输出连接1×1 卷积,使用卷积是为了统一输入尺寸。对于没有上一级的第一级网络,为图像对中的单幅雨图像。输出结果则为网络的最终输出结果,即无雨图像Iderain∈Rc×h×w。

Fig.1 Structure of the network图1 网络结构
2.1 ESIFEM
由于文献[8]中DSRCNN 的原网络主要处理对象是视频图像,如上文所述,视频雨图像的帧间图像具有时空上的连续性,故视频去雨方法可以利用这种连续性以较低的计算代价捕捉雨痕的特征,或者利用背景相对雨痕静止以提取背景特征。对于单幅图像去雨,由于其数据集中的图像之间并不具有时空上的连续性,故若以DSRCNN 这类视频去雨网络直接处理单幅图像结果会十分不理想,最终通常无法完成去雨任务。为了避免这一问题在RDSRCNN 中出现,在特征提取方面,本文利用基于SwinIR 设计的Swin-IR 特征提取模块以提取雨图像中的特征。
增强型SwinIR 特征提取模块基于SwinIR 方法设计,其大体结构如图2(a)所示,包含浅层特征提取与图2(b)中的增强型深层特征提取模块(Enhanced Deep Feature Extraction Module,EDFEM)。浅层特征提取模块与文献[7]中方法相同,使用3×3 卷积层HSF(·) 从输入图像中提取出浅层特征F0∈RH×W×C,即:
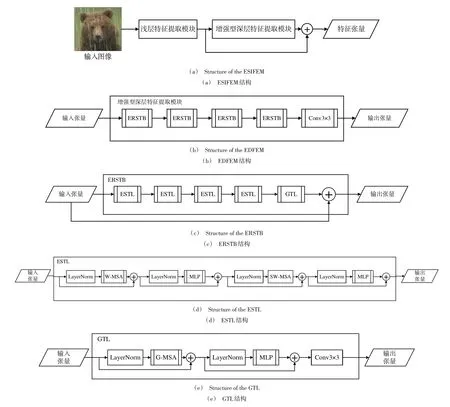
Fig.2 Structure of ESIFEM and its internal models图2 ESIFEM 及其各内部模组结构
H、W、Cin、C分别是输入图像的长、宽、通道数和特征张量的通道数。EDFEM 以增强型RSTB(Enhanced Residual Swin Transformer Block,ERSTB)层(图2(c))为基础构建,每个ERSTB 都由受到文献[6]的启发而构建的增强型STL(Enhanced Swin Transformer Layer,ESTL)(图2(d))和全局Transformer 层(Global Transformer Layer,GTL)构成(图2(e))。ESTL 内部包含2组自注意力处理,其中一组以窗口多头自注意力(Window Multi-head Self Attention,WMSA)处理特征张量以提取窗口内特征,另一组以Swin 窗口自注意力(Swin Window Multi-head Self Attention,SWMSA)处理第一组的输出以保证窗口自注意力处理不会忽略窗口周围的像素对窗口内图像的影响。在每个残差Swin Transformer 块(Residual Swin Transformer Block,RSTB)的末尾包含以整个输入张量而非张量窗口为处理对象的全局多头自注意力(Global Multi-head Self Attention,G-MSA)的GTL 而非ESTL 作为尾端处理模块以较低代价避免W-MSA 和SW-MSA 造成的全局像素关系信息缺失。
式(4)—式(8)表述的是EDFEM、ERSTB、GTL 和ESTL处理其输入特征张量的过程。因此得知,利用SwinIR 在特征提取阶段对于去雨任务的泛化能力,不仅保留了ESIFEM 对图像特征的高效提取能力,而且通过改进SwinIR 中的模块而设计的ESTL 与GTL 使ESIFEM 在维持ST 类图像特征提取方法的低复杂度前提下,还获得了利用窗口外像素辅助进行特征以及一定的全局像素间关系特征的提取能力。FESIFEM的上述特征,给予了RDSRCNN 处理单幅雨图像的数据基础。
2.2 SIDDM
为使视频去雨方法DSRCNN 能够有效处理单幅雨图像,SIDDM 对原始DSRCNN[8](以下称为原始去雨网络)做了3 项改进,即增强网络学习能力、输出迭代和残差连接处理。
在增强网络学习能力方面,以卷积—激活—池化的方式构建复合卷积层代替原始去雨网络中单纯的所有卷积层处理。其目的首先是增强初始化模块对于不同方向、密度和粗细雨痕的探测能力,其次是增加原始去雨网络中负责增强学习能力的批归一化层的深度,利用复合卷积层与池化层使其变为一个3 层并联深度网络模块,以多种卷积核大小(这里使用的是([hprev/2]+1,[wprev/2+1]))处理多尺度雨痕问题。
对于原始去雨网络而言,由于输入的帧间图像为多个区分度较低的相同背景雨图像,若对结果进行迭代处理可能会由于对某些特征的过度学习,加重原始去雨网络的过拟合倾向,故不对去雨结果进行迭代处理。由于RDSRCNN 的输入为除雨痕特征外互不相关的图片,对于输出的迭代不会引起与原始去雨网络一样的严重过拟合情况。相反,由于每个SIDDM 输出的都是相对其输入图像的雨痕弱化图像,通过残差连接对雨痕进行增强后输入下一个SIDDM 中进行处理即可在维持本SIDDM 的雨痕提取效果的前提下通过增强不易被捕捉雨痕的方法提升SIDDM 最终的雨痕捕捉比例与效果,也即通过逐级增强SIDDM 的去雨效果最终达成RDSRCNN 相对于原始去雨网络在单幅图像去雨上的性能优势。
最后,通过池化层统一输入特征张量,初始化模块处理张量以及改进归一化模块输出张量的大小,并将整合特征张量输入3 个串联线性层。由于无论是ESIFEM 或是SIDDM 都更倾向于提取图像中的高频特征,即雨痕,故线性层输出的是雨痕图像,用输入的雨图像与雨痕图像作差即可输出本SIDDM 的雨弱化图像(或最终去雨图像),SIDDM 的结构如图3所示。

Fig.3 Structure of SIDDM图3 SIDDM 结构
2.3 损失函数
RDSRCNN 方法采用Zhao 等[30]提出的混合损失函数LMix。结构相似性(Structural Similarity Index Measure,SSIM)提出自文献[31],SSIM 及以其为基础的损失函数是针对视觉感受的感知驱动函数。为了克服SSIM 作为损失函数对于高斯滤波器标准差的敏感,文献[32]提出SSIM的多尺度版本MS-SSIM(Multi-Scale SSIM,MS-SSIM),若将尺度设置为M级,某一像素位置的MS-SSIM 为:
式(9)中,μx、μy分别为2 张图片在该位置的均值,σx、σy分别为2 张图片在该位置的方差,σxy为联合方差,C1、C2为常数,α和βj统一设定为1。由式(9)可得,以MS-SSIM为基础的损失函数在以像素为中心的图像块P上的损失为:
不同于l2范数,l1范数作为损失函数时不会过度惩罚大误差而容忍小误差。l1范数的损失函数为:
式(11)中,p为图像块P上像素的索引。x(p) 与y(p)是2个输入图像块像素p的值。
根据文献[33]所述,a=0.84 时效果最佳。相较于l2范数损失函数,文献[33]中证明混合损失函数LMix在多种图像处理任务上的效能更优。
3 实验与结果分析
3.1 实验环境
为验证本文所提方法的效能,在Rain100H 数据集上利用DerainNet、DID-MDN 与RDSRCNN 分别进行训练与测试,给出实验结果并进行效能对比。参与对比的所有方法都统一在1 800 张图像的训练集上训练300 轮后,再根据训练模型进行单幅图像去雨以测试各方法效率。
实验在Google Colab 上进行。实验软件环境为:Python 3.6,Pytorch 1.12.1,CUDA 11.2;实验硬件环境为:内存52 GB,CPU 主频2.30 GHz,GPU Tesla P100 。
3.2 实验结果评估
对比实验评估分为两部分:①量化评估,通过峰值信噪比(Peak Signal to Noise Ratio,PSNR)与SSIM 两个数值,统计所有方法的去雨表现;②主观视觉评估,通过肉眼观察处理图像是否有明显的模糊、伪影、斑纹等缺陷。通过在数值上与视觉上对各方法进行分析以获得较为全面的评价。
3.2.1 量化评估
在量化评估方面,各对比方法的PSNR 和SSIM 值如表1所示。

Table 1 PSNRs and SSIMs of comparation methods表1 各对比方法的PSNR与SSIM值
表1 中的前3 行展示了Derain、DID-MDN 和Restormer[33]在Rain100H 上训练300 轮后结果的PSNR 及SSIM 值。可以看到,除Restormer 外的方法在规定训练轮数下的量化结果,即PSNR 与SSIM 均不如最后一行的RDSRCNN,Restormer 方法虽然在量化结果上具有完全优势,但是在训练期间其内存占用远超RDSRCNN(内存占用平均比例:Restormer70%,RDSRCNN 50%)且RDSRCNN 的结构较为简单,更为轻量级,更易于实现。
为了评估本方法中ERSTB 的网络块数量对于网络去雨性能的影响,在实验中通过分别削减EDFEM 中ERSTB数量为默认值的50%(每个EDFEM 中包含2 个ERSTB 模块)与削减整个网络中网络级数为默认值的50%(总级数为2)进行训练与去雨测试。测试结果见表1 中4-5 行,可以看到相对于不进行任何模块与级数削减的完整方法,对ERSTB 与总网络级数的削减都会导致网络性能下降,也从侧面证明ERSTB 与适当网络深度对本文网络整体性能的重要性。为评估混合损失函数LMix对于网络性能的影响,实验中在保留完整网络的网络结构的前提下,将LMix换为均方误差损失函数(MSE)进行训练与去雨测试。结果如表1 第6 行所示,可以看到在规定条件下,其性能仍不及使用LMix的完整网络,证明本文使用的混合损失函数相较于一般的损失函数MSE 具有更高的性能。
3.2.2 可视化评估
在可视化评估方面,由图4 可以看出Derain、DIDMDN 中的前景仍有未去除的雨痕(0-12 处),除RDSRCNN和Restormer 外没有一个对照方法完成了背景雨痕消除工作。RDSRCNN 的去雨结果显示,图像前景几乎无雨痕(0-1 处),背景雨痕去除率高于90%,但存在亮度过高的问题。Restormer 虽然去雨效果较为完美,但空间复杂度性能不如RDSRCNN。
由量化评估与可视化评估结果可以看出,RDSRCNN作为单张图像去雨方法对系统资源要求较低的同时保证了一定性能,在系统资源有限的场景中有其应用价值。
4 结语
RDSRCNN 方法在网络结构上结合了基于SwinIR 特征提取模块设计的ESIFEM 和基于DSRCNN 设计的SIDDM,利用ESIFEM 基于ST 的特征提取能力弥补了单幅图像相对于视频图像缺乏帧间图像关系的缺陷,利用增强网络学习能力、处理结果迭代和残差连接等方法保证了单幅图像在SIDDM 上的去雨效果。通过应用更为有效的混合损失函数LMix,提升了去雨网络量化评价。并且,通过实验证明了本文提出的增强型方法及其中模块的有效性与当前先进方法相比具有更强的经济性。近年来,随着社会智能化的演进,图像去雨的应用范围也将越来越广泛,将具有重大理论研究与应用价值,本文方法对于同类研究也颇具借鉴意义。
