基于改进YOLOv5模型的高速道路裂缝检测研究
2023-10-31闫卫坡王志斌任祖跃来程轩胡锦程张子雄
闫卫坡,王志斌,任祖跃,来程轩,胡锦程,张子雄
(1.北京市首都公路发展集团有限公司公路资产管理分公司,北京 101116;2.中央民族大学 信息工程学院,北京 100086)
0 引言
随着我国高速公路骨干网的高速建设与完善,高速公路荷载在迅速激增,道路病害问题随之浮现眼前,道路裂缝病害尤为严重[1]。目前,在理想情况下的道路裂缝识别算法研究已取得一定的成果,但在实际道路中背景间存在灰度值重叠等因素干扰[2],为识别道路裂缝带来了巨大挑战[3]。
传统裂缝检测基于数字图像处理方法,提取、分类图像中裂缝的颜色、形状、边缘等特征。Oliveira 等[4]利用裂缝与背景的灰度值差异进行检测,在实际道路情况下效果不佳。王兴等[5]使用小波变换识别复杂道路裂缝,但在高速行驶时数据采集存在大量噪声,无法较好地检测不连续的裂缝。
随着深度学习技术不断发展,基于神经网络的检测方法逐渐被应用到工业领域[6]。游江川等[7]提出一种改进RCNN 的沥青路面裂缝检测方法,精度达到91.25%,但检测速度较慢,无法适用于快速形式场景中。徐康等[8]提出一种改进Faster-RCNN 的沥青路面裂缝检测方法,精度达到85.64%,但需要大量参数和浮点运算,不适合资源受限的移动部署平台。顾书豪等[9]提出一种增强语义信息与多通道特征融合的裂缝自动检测算法,通过添加扩张卷积模块及注意力机制,提升模型对特征细节的提取能力。
2014 年后,基于深度学习的目标检测网络井喷式爆发,例 如R-CNN[10]、Fast-RCNN[11]、Faster-RCNN[12]、Mask-RCNN[13]、AlexNet[14]等二阶段网络。现有深度学习方法在理想情况下,在道路裂缝检测中取得了不错的效果,但应用到高速行驶的实际应用场景中仍存在以下问题:①网络需消耗大量资源;②实时性不佳;③多尺度精度低。针对以上问题,本文选择计算量少、速度快的onestage 检测算法——YOLOv5 进行实验,其内存大小仅为14.10 M,在自带的4 个版本中最轻量级。YOLOv5 在检测目标时,只需将图片送入网络一次就能完成分类及定位任务。
综上,YOLOv5 的特点非常适合低成本且对实时性有要求的工业场景。为了进一步提升网络检测能力,在YOLOv5 网络模型中添加CBAM 注意力机制,从通道、空间两个维度定位目标提升模型检测能力。此外,引入BiFPN 结构解决多尺度精度低的问题,BiFPN 相较于FPN-PAN 结构可在不同尺度的特征融合过程中,自适应区分不同输入的重要程度,以此缓解多尺度融合精度低的问题,提升网络的表达能力。
1 YOLOv5模型
本文研究基于YOLOv5s 模型进行改进,YOLOv5 从小到大依次分为YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x 共4 个模型,网络结构主要由输入端、Backbone、neck、head 组成,网络结构如图1所示。

Fig.1 YOLOv5 model structure图1 YOLOv5模型结构
由图1 可见,输入端对输入图像进行Mosaic 数据增强、自适应锚框、自适应图像增强等预处理。由于Mosaic可随机选取4 张图片通过拼接、缩放、翻转等操作丰富数据集,同时在新的图像中保留原本4 张图片的真实框,该操作可一次计算4 张图片的数据,进而节省GPU 的显存,因此本文使用Mosaic 方法扩容数据集。Backbone 为CSPDarknet53 主干网络、输入图像经过主干网络提取到丰富的特征。Neck 核心则为特征金字塔网络(Feature Pyramid Networks,FPN)[15]和路径聚合网络(Path Aggregation Networks,PAN)结构,该结构通过Concat 操作将自下而上和自上而下的Feature map 横向连接,进而融合深层和浅层不同尺度的特征,融合后的特征具有高级语义信息,有助于检测小目标,提升网络表达能力。Head 为YOLOv5 的检测结构,网络最终输出80×80、40×40、20×20 尺寸的特征图分别检测小、中、大目标。通过交叉熵函数计算分类、置信度损失,CIoU 函数计算定位损失,并基于非极大值抑制(Non-Maximum Suppression,NMS)提升网络预测精度。
2 改进YOLOv5
2.1 改进方法
为了提升模型对高速道路的裂缝病害的检测能力,本文提出一种基于改进的YOLOv5 道路病害目标检测模型,网络结构如表1 所示。首先在主干网络中添加注意力模块(Convolutional Block Attention Module,CBAM)[16]加强特征提取;然后,在Neck 中将FPN-PAN 结构替换为双向特征 金字 塔(Bi-Directional Feature Pyramid Network,BIFPN),为不同输入添加权重,让网络区分输入特征的重要程度进而加强多尺度融合;最后,在BiFPN 结构中加入CBAM 模块,以在多尺度融合后进一步关注关键特征,加强对主要特征的提取,进而实现在裂缝病害密度较高的道路中精准定位裂缝。
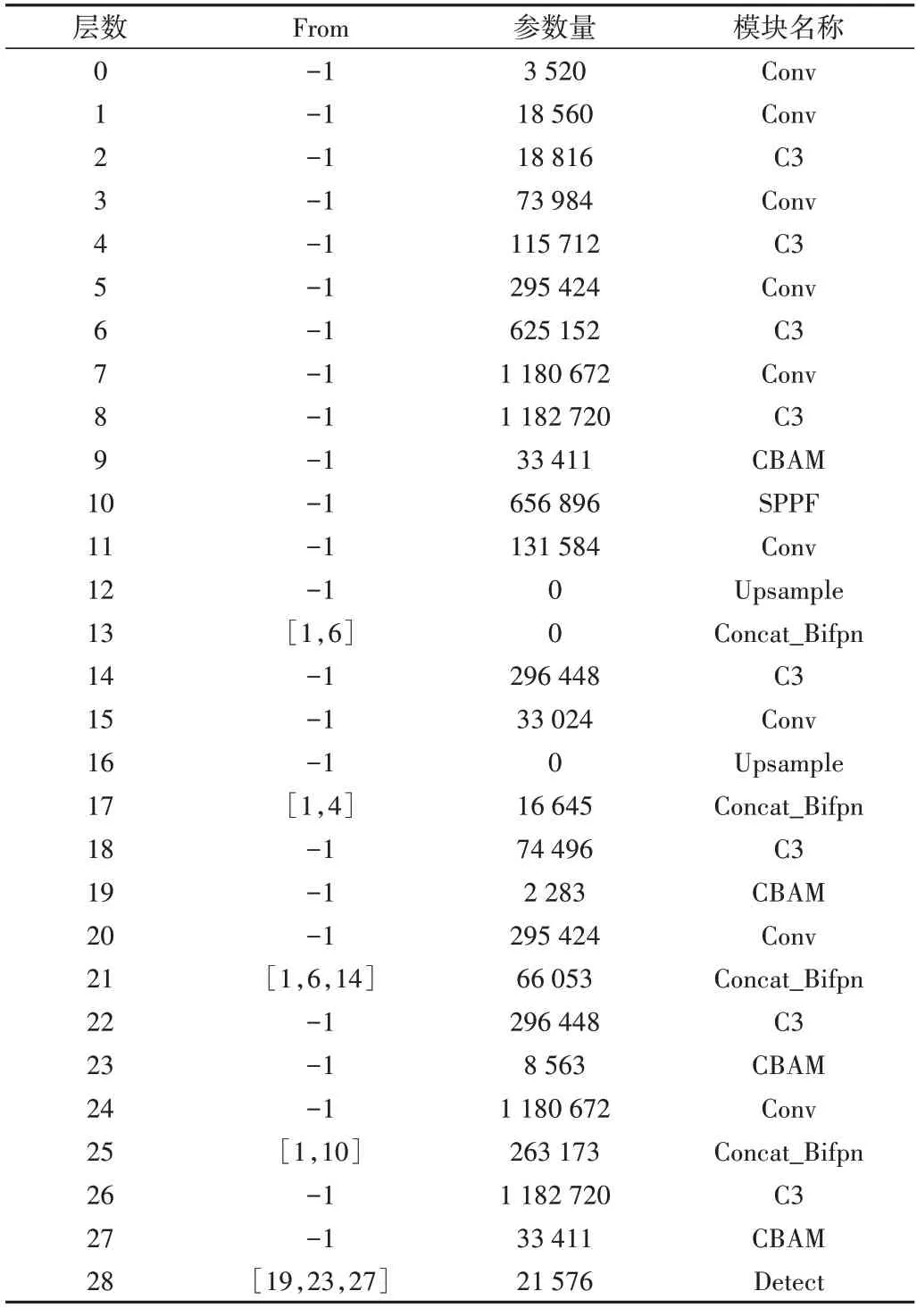
Table 1 Network structure of improved YOLOv5表1 改进后YOLOv5网络结构
2.2 骨干网络改进
在骨干网络中,本文首先更替Focus 和SPP,将位于第一层的Focus 改为6×6 的Conv 模块,两者作用等价,但对现有一些GPU 设备,卷积层相较于Focus 更高效。然后,将SPP 模块替换为空间金字塔模块(Spatial Pyramid Pooling,SPPF),将输入串行通过多个5×5 卷积大小的Maxpool 层,虽然相较于SPP 而言计算结果一致,但速度更快。SPPF 结构如图2所示。
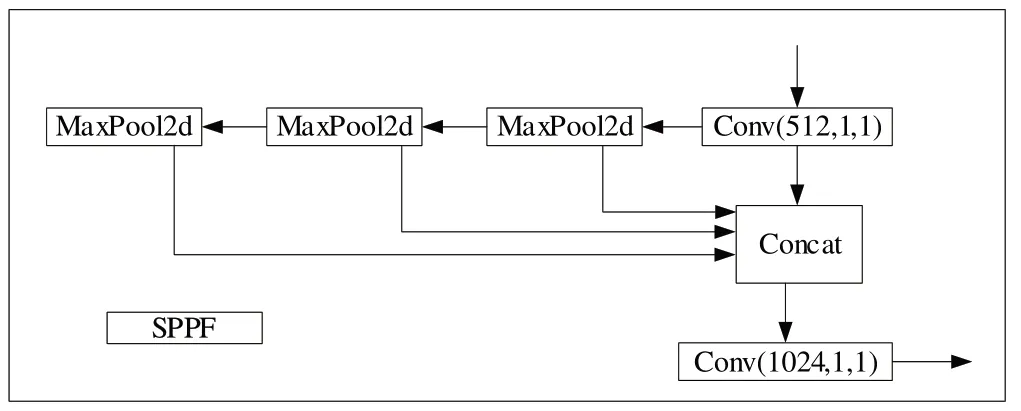
Fig.2 Structure of SPPF图2 SPPF结构
为了解决裂缝在图像中占比较小、与道路材质的灰度值重叠、修补裂缝形态相似等问题,本文引入CBAM 特征注意力模块。该模块是一个轻量级的卷积注意力模块,适合移动部署,内部包含通道和空间注意力模块,能从空间、通道两个维度定位、识别目标并细化提取的特征,避免了由卷积导致冗余信息淹没目标的问题。此外,为避免过早加入注意力机制,导致网络关注重点发生偏差,将该模块加在骨干网络的最后一层。CBAM 如图3所示。
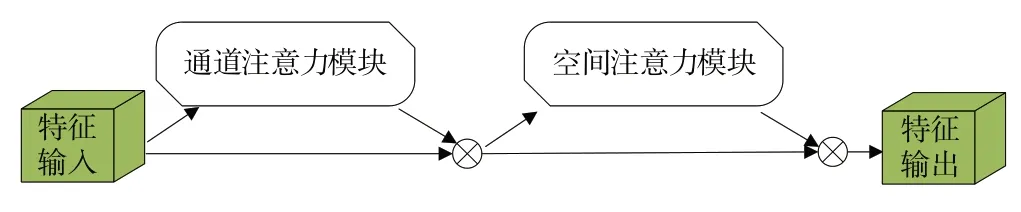
Fig.3 Structure of CBAM图3 CBAM注意力模块结构
由图3 可见,CBAM 整体运算由通道、空间注意力结构组成。首先,feature map 进入通道注意力模块,经过Max-Pool 和AvgPool,此时特征图大小将由C×H×W 转为C×1×1;然后,将变化后的特征图送入共享全连接层(Share MLP),将两个输出先后相加、Sigmoid 激活,得到通道权重;接下来,再将通道权重与输入相乘,得到经通道注意力模块调整后的特征图F 并将其输入空间注意力机制,经过Max-Pool 和AvgPool 后F 的大小将由C×H×W 转为1×H×W;再之,对输出的两个特征图进行concat 操作,此时特征图大小将由1×H×W 转为2×H×W,同时利用7×7 卷积降维1 通道的特征图。最后,通过Sigmoid 函数激活得到空间权重,并将空间权重与输入特征图F 相乘得到调整后的最终feature map。
2.3 特征融合网络改进
由于在网络卷积过程中,随着层数增加特征信息会在不同程度上逐层丢失,并且深层与浅层特征在跨尺度融合时具有不同的分辨率,将直接影响输出结果,因此本文将原有FPN-PAN 结构替换为BiFPN 加权特征双向金字塔,采用不同尺度间连接融合的方法丰富语义信息,避免因网络层数加深导致的特征信息丢失问题。同时,BiFPN 结构在不同尺度特征融合过程中引入自适应权重,可让网络自行区分输入特征的重要程度,根据权重抑制或增强输入特征,以平衡不同尺度间的特征信息。
综上,相较于FPN-PAN 结构直接对不同输入进行Concat 操作,BiFPN 结构具有更好的特征融合效果,能提升网络表达能力,具体加权公式如式(1)。
式中:wi代表可学习的权重,随着模型不断训练,该参数值会随着优化器更新,向着使损失函数最小值的方向变更,在初始化时设定值为1;fmi代表网络结构中的输入特征图;ϵ=0.000 1;ReLU 函数将权重细数规范到0~1。
网络中某一层的融合方式如图4 所示。由式(1)可知,特征融合过程与输出如式(2)、式(3)所示。
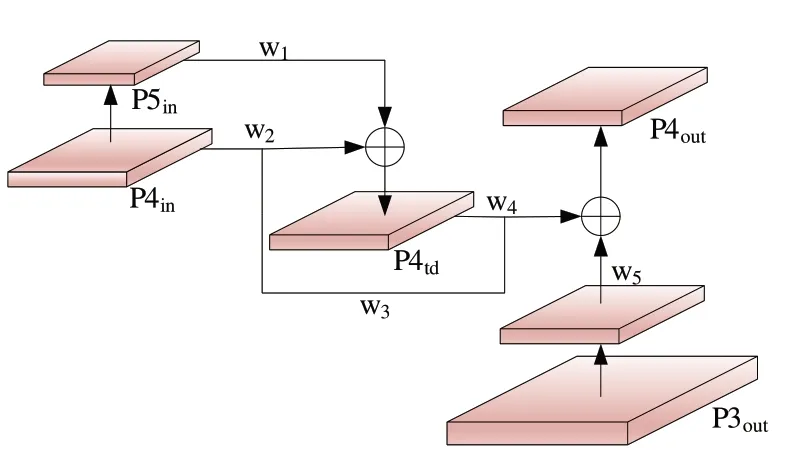
Fig.4 Cross-layer convergence architecture图4 跨层融合结构
此外,本文还改进了BiFPN 结构,在跨尺度特征融合完成卷积后,在Backbone 的尾部与Head 添加CBAM 注意力模块,以突出关注的特征,提升网络表达能力。融合CBAM 模块的BiFPN 结构如图5所示。

Fig.5 BiFPN incorporating CBAM modules图5 融合CBAM模块的BiFPN结构
3 实验结果与分析
3.1 实验环境与参数设置
本文试验操作系统为Linux,基于GPU、Pytorch 和CUDA 框架完成,具体参数如图表2所示。

Table 2 Test platform parameters表2 实验平台参数
3.2 实验数据集
为了让研究模型对真实道路病害情况进行训练,学习到最符合真实情况下的道路病害特征,提升算法泛化能力。本文数据集来源于北京高速交通(首发集团),使用固定在高速巡航车上的摄像头拍摄的实际高速道路,研究对象包括裂缝、修补裂缝、伸缩带3 类。其中,裂缝最为常见且数量庞大;修补裂缝虽然并非为高速道路病害,但数量众多且容易与裂缝病相互混淆;伸缩带并非为道路病害,但由于特征较为明显,同时也是实际工作中需要检修的重点,因此将其纳入研究对象。
研究共采集图片2 164 张,标注了4 916 个目标,按照8∶2 的比例划分训练集、验证集。其中,训练集共有1 715 张图片,标注裂缝2 047 个、修补裂缝1 804 个、伸缩带62 个;验证集中共有449 张图片,标注了裂缝563 个、修补裂缝421个、伸缩带19个。数据集样例如图6所示。

Fig.6 Sample images图6 样例图片
3.3 评价指标
本文采用精确度(Precision,P)、召回率(Recall,R)、平均精确度(Average Precision,AP)和平均精确度均值(Mean average Precision,mAP)作为模型评测指标,具体混淆矩阵如表3 所示。其中,召回率直接反映识别为正确的目标中实际为正样本(TP)占所有正样本的比值(TP+FN),如式(4)所示;精确度直接反映识别为正确的目标中实际为正样本(TP)占所有识别为正确目标的比值(TP+FP),如式(5)所示;平均精确度如式(6)所示;mAP是对所有类别的平均精度(AP)求均值后获得,如式(7)所示。
Table 3 Confusion matrix表3 混淆矩阵
式中:AP代表平均精确度;APj代表第j类目标检测的平均精度;c代表标记的类别;mAP代表平均精确度均值。
式中:AP@0.5j代表交并比阈值为0.5 的情况下第j类目标的平均精确度;c代表标记的类别;mAP@0.5代表交并比阈值为0.5时平均精确度均值。
3.4 实验结果
实验中输入图像尺度为640×640,Batch-size 为16,训练200 轮,初始学习率为0.01,优化函数采用随机梯度下降算法(Stochastic Gradient Descent,SGD),改进后的P-R 曲线如图7 所示。由此可见,裂缝、修补裂缝、伸缩带的mAP@0.5 分别达到了45.8%、62.9%、93.8%,所有类别的mAP@0.5 达到67.5%。改进YOLOv5 模型、Precision、Recall和mAP@0.5的结果如表4所示。
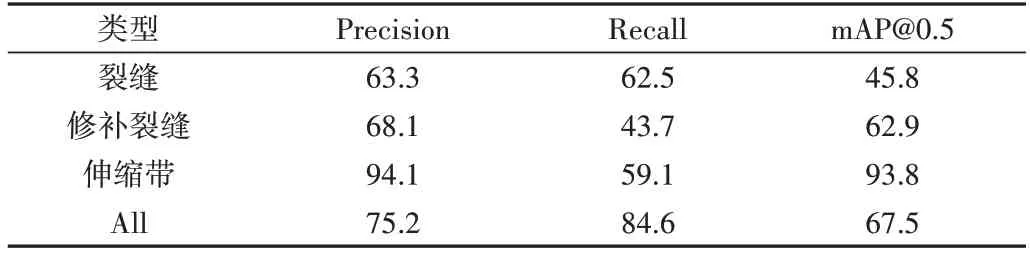
Table 4 Precision,Recall and mAP@0.5 results of improved YOLOv5 model表4 改进YOLOv5模型Precision、Recall和mAP@0.5结果(%)
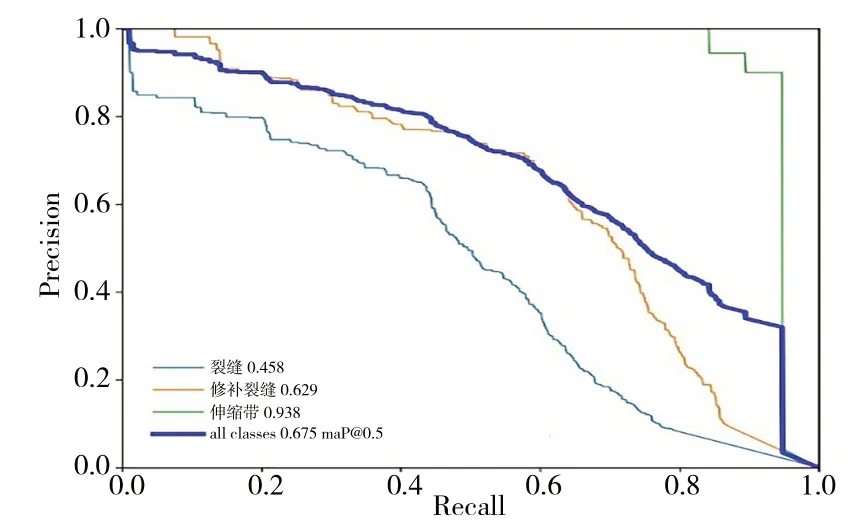
Fig.7 P-R curve of YOLOv5图7 YOLOv5的P-R曲线
改进YOLOv5 模型和原YOLOv5 模型训练200 轮后的3类loss如图8所示。

Fig.8 Training loss comparison function图8 训练损失对比函数
图8(a)为基于CIoU 函数计算的边框回归损失(box_loss),由此可见改进模型的边框回归损失优于原模型。在训练前50 轮,原YOLOv5 模型表现更好,但随着网络不断学习,改进模型对网络的优化更快。其中,分类概率损失(cls_loss)和置信度损失(obj_loss)均基于交叉熵函数。由图8(b)可见,改进模型置信度损失始终小于原YOLOv5 模型,但由于模型使用SGD 随机梯度下降算法,会导致整个训练过程中存在轻微震荡的情况。由图8(c)可见,改进模型分类概率损失基本始终优于原模型,且在20 轮后逐渐趋于平稳,证明网络对数据集已具备较为准确的分类能力。
3.5 定量评价
为验证改进模型的性能,本文针对当前主流的单阶段目标检测模型进行比较分析,每个模型训练环境相同,实验结果如表5所示。
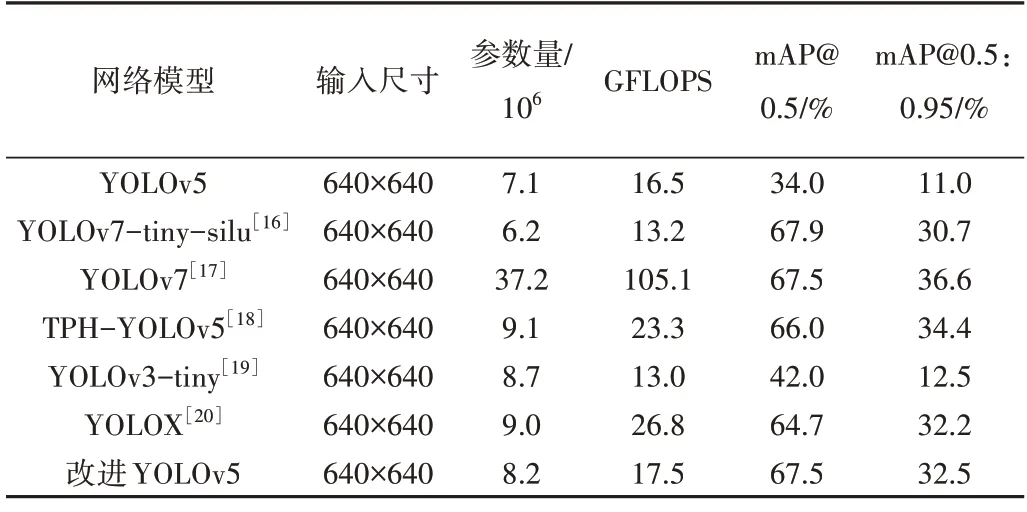
Table 5 Experimentation comparison表5 实验比较
由表5 可见,改进YOLOv5 在mAP@0.5 指标中相较于YOLOv7-tiny-silu 模型降低0.4%,但mAP@0.5:0.95 提升1.8%。YOLOv7 虽然在以上两个指标取得了优秀的表现,但计算量、参数量非常大。改进YOLOv5 算法在与其他复杂度相似的模型中,两项平均精度均值指标的表现十分优秀。在7 组实验中,改进YOLOv5 在mAP@0.5 中排名第2,在mAP@0.5:0.95 中排名第3,在YOLOv5 中加入注意力机制、改进融合网络结构后,虽然在参数量、计算量分别增加15.4%、6%,但平均精度均值提升明显。
总体而言,改进YOLOv5模型在保持轻量级的同时,还具备较高的检测能力,在低成本的工业检测任务中相较于大多数模型能发挥更好的作用。
为了更直观地展示原模型和改进模型的区别,随机选取部分检测结果,如图9所示。

Fig.9 Detection results图9 检测结果
由图9 中Image1 可见,改进网络能提取更丰富的特征,可识别先前未能识别的裂缝,漏检率得到了改善。由图9 中Image2 可见,改进模型识别先前置信度低的目标的性能也具有明显提升。由图9 中Image3 可见,改进模型对先前误检的目标进行了改正,识别精确度得到了显著提升。通过上述多种检测数据可知,改进模型相较于原模型提升较大,能精确检测、识别高速道路上的病害目标。
3.6 消融实验
为继续探究改进算法的检测能力,本文在相同环境下共设计了4组消融实验,实验结果如表4所示。
由表6 可见,在引入CBAM 注意力模块后模型的mAP@0.5、mAP@0.5:0.95 提升十分明显,在几乎不增加网络参数的前提下,既能降低计算量,还能有效提升网络的定位及边框预测能力。检测效果证明了引入CBAM 模块后,网络特征提取能力得到增加,既保留了需要关注的特征,又有效避免了由卷积冗余导致的信息丢失问题。
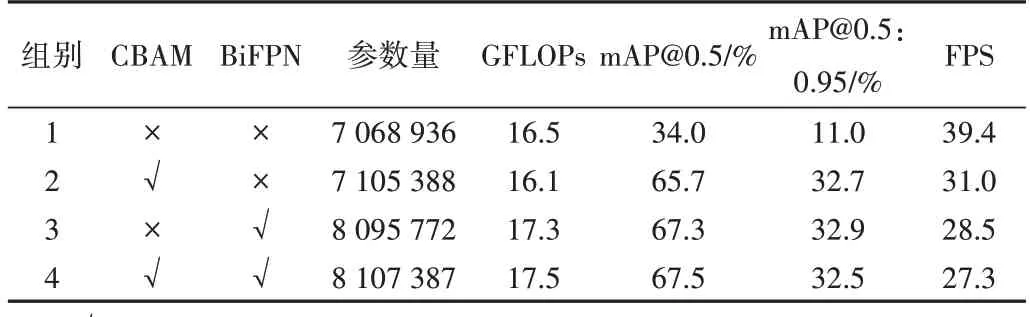
Table 6 Comparison of target mAP by each category表6 各类别目标mAP比较
在更换特征融合结构后,模型的表现相较于仅添加CBAM 模块更优秀,mAP@0.5 提升1.6%,mAP@0.5:0.95 提升0.2%。虽然更换BiFPN 结构后,参数量、计算量均存在小幅度增加,但自适应权重相较于FPN-PAN 结构的等价融合效果更佳,既在一定程度上区分了融合时的输入,又平衡了输入的重要程度,还提升了网络表达能力。
综上,改进YOLOv5 模型相较于原YOLOv5s,mAP@0.5、mAP@0.5:0.95 分别提升33.5%、21.5%,参数量增加14.7%,GFLOPs 增加6%,模型特征提取、目标边界的回归能力得到显著增强。
3.7 实验分析
相较于检测建筑裂缝[21],裂缝检测环境更复杂、难度更大,阳光折射造成的反光及高速移动造成的模糊时将增加检测难度,同时修补裂缝与裂缝灾害形态相似,易造成系统误检测。
基于YOLOv5 模型[22]检测公路灾害的精度约为45%,mAP@0.5 约为40%。在同等复杂背景、干扰因素更多的情况下,本文改进YOLOv5 模型精度为75.2%,mAP@0.5 为67.5%。同时,引入Ghost 模块[23]和ECA 的YOLOv4 公路路面裂缝检测方法[24]的参数量达到11.18 M,图片检测速度为0.083 张/s,而本文模型参数量为8.2 M,图片检测速度为0.037 张/s。
然而,本文研究存在许多不足之处。例如,本文仅对3类道路灾害进行分类识别,在复杂的公路环境中还存在其他类别的病害[25]。下一步,应扩大数据集、病害研究的广度与深度,提升模型的鲁棒性与检测性能,使其能够适应更加复杂多变的高速道路环境。此外,可更换拍摄设备获取更优质的数据集,以提升模型对道路病害的检测效果。
4 结语
本文为解决当前高速道路裂缝的错检、漏检、精度低等问题,提出一种基于YOLOv5 改进的道路裂缝识别模型。首先在改进YOLOv5模型的骨干网络中添加注意力机制,以此获取更多细节特征,并替换骨干网络中的Focus、SPP 等模块来提升模型识别速度。具体为,在特征融合层采用BiFPN 加权双向特征金字塔网络进行多尺度特征融合,并在检测头处进行修改,还添加了CBAM 注意力机制来强化网络表达能力。
在真实道路的测试效果表明,改进算法的平均精度值能达到75.2%,FPS 可达到27.3,基本满足高速检测的精确度与检测速度需求。然而,本文仅对3 类道路灾害进行分类识别,仍需进一步完善数据库。此外,希望开发出具有完整界面和软硬件平台的道路灾害分类系统,以便于道路巡检工作人员检修与保养道路。
