基于层次分析法的图书协同过滤推荐算法研究
2023-10-31林丽
林 丽
(集美大学 图书馆,福建 厦门 361021)
0 引言
高校图书馆拥有丰富的图书文献资源,而读者获取文献资源主要通过图书馆的OPAC 系统检索、再浏览、筛选感兴趣的图书。这种服务模式下,读者需要有明确需求及相应的检索技能,且检索结果较多,难以快速、精准获取所需要的文献资源。此外,高校图书馆流行的Top-N 热门图书推荐一般是基于全馆的热门图书统计,无法满足读者的个性化需求。
图书馆个性化推荐是指根据读者历史借阅行为、个人信息等主动向读者推荐相关文献资源,实现“千人千面”的推荐服务。协同过滤算法[1]是图书推荐系统中广泛采用的推荐算法,该算法基于一个“物以类聚,人以群分”的假设,研究图书或用户之间的相似性,然后借助用户对图书的评分数据做Top-N 相似图书推荐。但是,由于高校图书馆缺乏图书评分数据且借阅数据稀疏,导致协同过滤算法推荐性能差。针对此问题,本文以某高校图书馆近5 年借阅数据及读者信息为实验数据集,通过层次分析法[2](Analytic Hierarchy Process,AHP)构建图书热度评价模型解决图书评分问题。协同过滤算法则是基于图书的中图分类号[3]相似实现图书热度Top-N 和新书热度Top-N 推荐,不仅可提升推荐类别的准确率,也可改进协同过滤算法冷启动问题,提高推荐结果新颖度。
1 相关研究
1.1 图书评价
图书评价是图书推荐算法的一个重要指标,通过图书评价结果,推荐系统可以向读者推荐高质量图书。如何评价图书一直是图情领域的研究热点。邱悦等[4]提出基于图书利用、图书关注和图书评论3 个维度的评价体系,引入情感倾向分析进行评论处理,应用CRITIC 方法为指标赋权,并对心理学图书评价体系可靠性进行实证分析。姜春林等[5]基于学术图书被引次数、评论数、下载量、读者数、在线提及5 个指标数据,分析学术图书的Bookmetirx 指标数据特征和动态变化规律。王萝娜等[6]基于图书声誉、图书引用、图书评价和图书利用4 个层次的指标体系,利用CRITIC 法确定指标权重,加权TOPSIS 法计算图书影响力综合排名。这些研究一般集中于线上图书或学术图书,而高校图书馆图书缺少图书的书评及引文数据,故当前图书评价指标方法应用程度较低。本研究选择图书借阅次数作为图书评价主要依据,基于AHP 分析法构建图书热度评价模型,并将图书的热度值作为推荐算法Top-N 的评分指标。
1.2 图书协同过滤推荐算法
图书协同过滤推荐算法一般是依据读者借阅列表相似或图书内容相似向读者推荐评分Top-N 图书。相关研究包括:林晓霞等[7]利用借阅记录数据构建评分矩阵,融合信任度改进用户相似度计算方法,根据邻居用户计算图书推荐度,实现图书推荐,提高推荐精度。梁思怡等[8]提出基于时间上下文优化的协同过滤推荐算法,构建了阅读兴趣评分模型、时间衰减模型和内容兴趣捕捉模型,从时间轴提取用户兴趣变化,提高推荐准确度。王刚等[9]基于用户的图书借阅行为序列提取用户之间的最长公共子序列和所有公共兴趣子序列作为用户相似度计算方式,再通过借阅时长、借阅形式及用户类型构建读者图书评分矩阵,提出改进协同过滤的图书推荐算法。刘佳奇等[10]提出以用户图书借阅信息相似度、用户上网日志聚类相似度及用户学院信息相似度加权和作为用户相似度计算方法,通过热门图书打压过滤方法解决冷启动问题,提升推荐覆盖率。张金柱等[11]引入异构网络表示学习方法,融合图书多维特征包括书名、购买者、作者、类别、关键词等形成图书语义向量,基于向量相似度做图书推荐,实验证明推荐准确率、推荐类别多样性、推荐内容多样性指标都有所提升。董杨帆[12]通过图书借阅记录和图书关键词属性建立流通矩阵和关键词矩阵,建立概率关键词模型,生成Top-N 图书推荐列表,提升推荐性能。
上述图书协同过滤推荐算法从读者或图书特征分析入手,采用不同的相似度计算方法做Top-N 推荐算法研究,实现个性化推荐目标。但也存在如下问题:①相似度计算方法基于借阅列表或书名的语义相似,保证了推荐准确率,但是由于高校用户借阅数据稀疏,有些用户长时间没有借阅行为,导致推荐结果新颖度和多样性差;②协同过滤算法自带冷启动问题,如果用户没有借阅记录或图书为新书,则推荐算法失效;③由于用户兴趣变化,无法及时推荐新物品。
综上所述,本研究对图书相似度计算方法进行改进,利用中图分类号能够准确表示图书学科主题的特点,图书的相似通过中图分类号值是否相似表示,保证推荐图书所属学科主题的准确率。本文还基于读者借阅记录,推荐图书热度Top-N 新书推荐列表,解决协同过滤算法冷启动问题。
2 基于层次分析法的图书热度评价模型
2.1 图书热度评价指标
实际应用中,高校图书馆虽然提供图书评分功能,但是读者对图书的评分数据很少。因此,图书的热度值可通过图书的借阅信息进行构建。陈宇奇等[13]提出基于客户关系管理RFM 模型改进的图书热度评价模型BRFM,评价指标包括图书首次借阅间隔时长(Beginning)、最近借阅间隔时长(Recency)、借阅频率(Frequency)和借阅总时长(Monetary)。本文分析馆藏借阅数据后发现:①对于长期没有被借阅的图书,即Recency 指标为0,Beginning 指标大小都不能说明图书热度。而Recency 指标不为0,首次借阅图书时长和图书检索结果关系大,不能说明图书本身热度,故加入Beginning 指标会干扰图书热度值计算结果;②馆藏借阅数据中,90%图书的借阅时长指标都是90 天。因为图书馆给予读者的最长借阅时长是90 天,大部分读者都是一次借多本图书,等收到图书馆催还短信后才还,专业图书体现更为明显,导致Monetary 这个指标数据差异不大,不适合作为图书热度指标。
基于上述问题,本文提出AHP-BP 图书热度计算模型,保留了Frequency 和Recency 指标,加入书龄指标。3 个指标计算方法如下:
(1)图书书龄A(Age)。在馆藏图书中,不同年份出版的图书中,新书显然更受读者欢迎。在借阅热度计算模型中加入书龄指标,也有助于提升新书热度值。书龄表示图书的老旧程度,可通过图书的出版时间计算获取,书龄越大,图书老旧程度越高,则图书热度越低。
(2)观测时间内的图书借阅次数F(Frequency)。图书借阅次数,是图书热度的核心指标,借阅次数越多,表示图书越受欢迎,图书热度越高。考虑到部分旧书虽然借阅次数多,但近几年借阅次数较少或为0,说明这部分图书借阅热度趋势降低,热度值也减少,故不能用图书总的借阅次数作为指标,改成选择近期的图书借阅次数。本文选择观测时间为2017-2022 年即近5 年的图书借阅次数作为热度指标。
(3)最近图书借阅间隔R(Recency)。最近图书借阅间隔表示读者最后一次借阅行为发生的年份距离分析时间点(本文选择2022 年)的间隔,最近借阅时间间隔越短,说明图书近期还有关注度,相应的热度值也越高。
2.2 图书热度指标权重分析
图书热度的3 个指标对图书热度的影响程度,可以通过设置不同指标权重表示。权重计算方法采用AHP 层次分析法。AHP 是对定性问题进行定量分析的一种简便、灵活而又实用的多准则决策方法。该方法的主要思想是将复杂问题分解成若干层次和若干因素,对两两指标之间的重要程序进行比较判断,建立判断矩阵,再计算判断矩阵最大特征值及对应特征向量,可得出不同方案的重要性程序的权重。
2.2.1 图书热度指标权重计算
图书热度指标权重计算过程如下:
(1)构造判断矩阵。判断矩阵是对所有指标因素两两比较,采用相对尺度,尽可能减少不同因素相互比较的困难,提高准确性,值采用1-9标度。

Table 1 Judgment matrix scale definition表1 判断矩阵标度定义
通过对馆藏借阅数据预处理后获得图书热度3 个指标数值,经过对比不同指标之间对图书热度决策的影响程度,最终构建判断矩阵如图1 所示。其中,借阅次数因素比书龄因素极端重要,比最近借阅间隔因素明显重要,最近借阅间隔因素比书龄稍微重要。
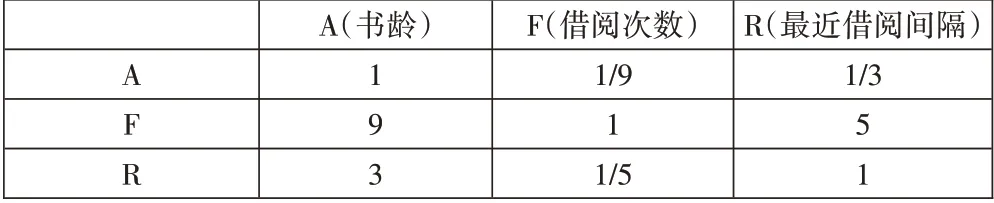
Fig.1 Book popularity judgment matrix图1 图书热度判断矩阵
(2)指标权重计算。每个因素的权重计算步骤为:①先将矩阵的每列进行归一化为[0,1]的数值;②将标准化后的各元素按行求平均值。算出权重为:A 指标权重为0.071,F为0.748,R 为0.18。
(3)判断矩阵一致性检验。判断矩阵是否符合逻辑,需要计算一致性指标CI,CI越接近0,则矩阵越一致,符合逻辑。CI越大,判断矩阵不一致性越严重,越不符合逻辑。CI计算方法如式(1)所示。
其中,λmax为判断矩阵最大特征值,n为判断矩阵的阶数,本文有3 个指标因素,故n为3。λmax的计算方法如式(2)所示,其中A为判断矩阵,W为权重矩阵。
为了衡量CI的大小,引入随机一致性指标RI。RI是随机模拟1 000 次取得,数值如表2 所示。本模型的判断矩阵阶数为3,则RI值为0.58。
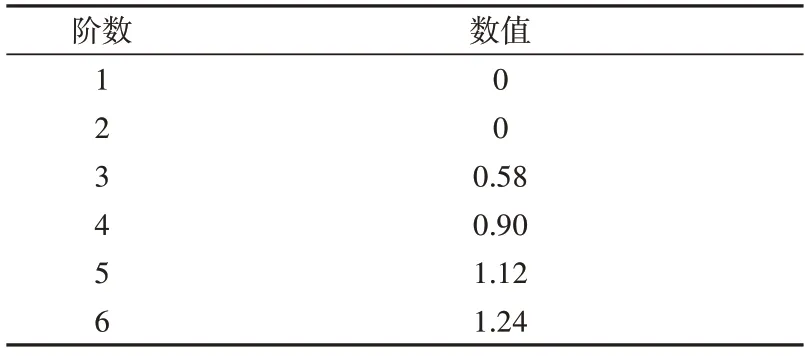
Table 2 The value of the random consistency indicator RI表2 随机一致性指标RI的数值
一致性比例CR计算如式(3)所示。其中CI为式(1)计算所得。当CR<0.1 时,则判断矩阵的不一致程度在容许范围之内,一致性检验通过。表2 的判断矩阵通过式(3)计算的不一致性比例CR值为0.028,小于0.1,故表2 所示的判断矩阵通过一致性检验。
2.2.2 图书热度值计算模型
综上所述,基于AHP 模型构建图书热度值AHP-BP(Book Popularity)为书龄A、借阅次数F、最近时间间隔R等 3 个指标的加权值。其中:A=2022-出版时间;F=近5 年借阅总次数;R=2022-最后一次借阅年份。
A 和R 指标越大,则AHP-BP 值越低,故A、R 和AHPBP 都是负相关。F 越大,则AHP-BP 值越大,故F 和AHPBP 是正相关。此外,由于3 个指标数据分布不一致,数据差异大,故需要先对数据进行归一化处理。如式(4)所示,使3 个指标的数据都分布在[0,1]内。其中,X 为原始数据,Xmin和Xmax为元数据的最小值和最大值。经过式(4)作归一化计算后,A、F、R 转为A1、F1、R1,代入式(5)加权计算后得到图书热度值AHP-BP 如下:
3 基于 中图分类号相似的图书推荐算法设计
3.1 计算方法
中文图书包含的中图分类号(中国图书馆分类法号码)属性,指采用《中国图书馆分类法》对科技文献进行主题分析,并依照文献内容的学科属性和特征,分门别类地组织文献,所获取的分类代号。若两本图书的中文图分类号一样,则表示图书属于同一学科类别,可判断为学科主题相似。如《明朝那些事儿》和《世间再无张居正》两本图书的中图分类号均为“K248.09”,虽然书名不相似,但是中图分类号表示的学科主题“历史、地理,中国史,明”是一样,即主题相似。主题相似结果用于推荐算法,虽然推荐精准率降低,但推荐主题的准确率得以提升。主题相似条件下,推荐内容可以更多样,用户可以有更多选择。
故图书相似的计算方法为:2 本书的中图分类号一致,则相似度值为1,否则为0。如式(6)所示。
基于中图分类号相似的图书推荐方法为:先基于AHP-BP 模型计算馆藏图书热度值,再读取读者的借阅列表,推荐与借阅图书的学科主题相似的Top-N 热度图书。基于中图分类号相似的图书个性化推荐算法模型如图2所示。为了解决冷启动问题,本文将推荐结果分为3 类:热门图书推荐单、热门新书推荐单、专业图书推荐单。
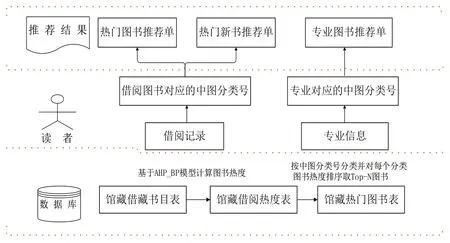
Fig.2 Personalized recommendation model for popular books图2 热门图书个性化推荐模型
(1)热门图书推荐单。热门图书推荐单的做法是先对馆藏借阅数据按照中图分类号分类,每个分类按照图书借阅热度排序,生成馆藏Top-N 热门图书表;再提取读者近期的10条借阅记录所对应的中图分类号,在馆藏Top-N 热门图书表中查找对应记录,按照分类号依次提取一定数量的图书生成热门图书推荐单。这种方法不仅实现学科主题相似的图书推荐,也保证了推荐的图书质量。
(2)热门新书推荐单。协同过滤算法存在新物品冷启动问题,既新书由于借阅数据少,导致借阅热度低,无法进入Top-N 图书推荐列表中。而新书一般是图书馆重点推荐的图书,故本文将馆藏的新书单独作为一个分类推荐,即热门新书推荐单。推荐做法为:首先对馆藏新书(出版年为当前年份的图书)基于中图分类号分类,每个分类按照新书借阅热度做排序,生成馆藏Top-N 热门新书表;再读取读者借阅记录,进行中图分类号相似热门新书的推荐和借阅。
(3)专业图书推荐单。高校师生是图书馆主要读者对象,而师生的主要任务是教授课程和学习课程。如何精准向师生推荐专业图书是高校图书馆学科服务的主要任务。通过提取读者专业信息,获取学科专业对应的中图分类号,再从馆藏热门图书表中查找对应学科分类的Top-N 图书做为专业图书推荐单。通过读者专业信息推荐学科图书,也可以解决协同过滤算法的用户冷启动问题,即新用户如新生,没有借阅记录,则可以向用户主动推荐其所学的专业图书,有助于用户及时获取热门专业图书信息。
3.2 算法设计步骤
推荐算法设计步骤为:
输入:读者借阅数据:ReaderList={B1,B2,B3,B4,...Bm}
输出:热门图书推荐单HotBookRecommendList、热门新书推荐单NewBookRecommendList、专业图书推荐单Professional-BookRecommendList
(1)基于APH_BP 模型计算馆藏图书的借阅热度值。对每一条借阅数据,统计书目的借阅次数、最后一次借阅年份,基于式(5)计算图书的借阅热度值,存入图书借阅热度表。
(2)对步骤(1)生成的图书借阅热度表按照中图分类号进行分组排序,提取前N 条的图书id 生成图书热度Top-N 图书和新书列表。以中图分类号为关键字,构建Top-N热门图书字典TopBookDict 及Top-N 热门新书(新书为当年发行时间的图书)字典TopNewBookDict。通过字典,可快速获取每个中图分类号所对应的热门图书列表。
TopBookDict[中文图分类号]=[BookID1,BookID2,...BookID10]
TopNewBookDict[中文图分类号]=[BookID1,BookID2,...BookID10]
(3)读取读者的借阅数据列表ReaderList,若借阅记录为空,则读取读者专业信息,生成专业信息对应的中图分类号。若借阅记录不空,则读取最近的10 条借阅记录,查找每条借阅记录所对应的中图分类号。
(4)基于Top-N 图书字典生成图书推荐单Hot-BookRecommendList、Top-N 新书字典生成热门新书推荐单NewBookRecommendList、Top-N 图书字典生成专业图书推荐单ProfessionalBookRecommendList。
推荐流程如图3所示。
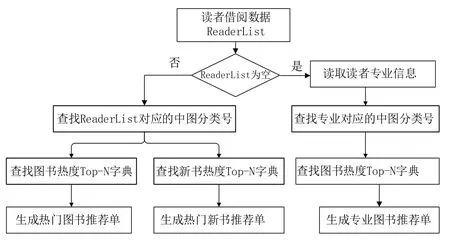
Fig.3 Recommendation flow图3 推荐流程
4 实验与结果分析
4.1 数据集
本实验数据源为某图书馆2018—2022 年的图书借阅记录,借阅记录共425 615 条,借阅图书种数203 613 种,用于图书热度评价AHP-BP 模型构建。推荐算法选择读者2个月借阅记录作为实验数据,前一个月的数据作为历史借阅数据即训练数据集,后一个月数据作为算法性能指标的验证数据即测试数据集。
4.2 借阅模型评价结果
通过AHP 层次分析法构建的AHP-BP 模型可以判断观测周期内图书的热门程度,从而为图书检索、Top-N 图书推荐提供数据支持。为了检测模型有效性,将AHP-BP模型计算的中图分类号为“TP3”的Top10 热门图书和借阅次数最多的Top10热门图书进行对比。
如表3 所示,AHP-BP 模型计算的借阅热度前10 图书和借阅次数前10 图书重合率达到70%。借阅次数是反映图书是否热门的重要指标,但是单靠借阅次数,并不能很好地反映图书的热门程度。AHP-BP 模型计算的图书热度在借阅次数差距不大的情况下,还考虑了书龄、最近借阅间隔时间两个指标。故同等借阅次数下,对于书龄越小或最后一次借阅时间越近的图书,表明越受读者欢迎,图书热度越高。因此,表3中《Python实战编程》《Arduino程序设计与实践》《深度学习框架PyTorch 入门与实践》等书在借阅次数差距不大的情况下,综合了书龄、最后一次借阅间隔指标,图书热度更高。由此可知,AHP-BP 模型不仅能够量化评价图书的热门程度,而且评价结果更有效、合理。

Table 3 Top 10 book ranking comparison表3 Top10图书排名对比
4.3 推荐算法评价指标
(1)查准率。查准率表示正确推荐给用户的项目占推荐总数的比例。协同过滤算法生成的Top-N 推荐物品中,若出现在用户的测试数据集中,则生成一个正确推荐。准确率越高,表示推荐性能越好。查准率如式(7)所示,N表示用户总数,Ru表示用户u的图书推荐列表,Bu表示用户u真实借阅的图书集合。
(2)多样性。多样性一般被定义为相似性的反面[14]。图书推荐系统中,读者希望推荐的图书是主题相似,但主题内的图书差异大,以避免同质化推荐,且更好地了解不同内容的图书。因此,推荐图书列表中的图书越不相似,多样性的推荐能力越强,读者的选择越丰富。
图书多样性的度量可以通过计算推荐图书列表的内部相似性表示[15]。相似度计算方法不一致,导致数据不平衡,故本文采用标准偏差值度量推荐列表的内部相似性。式(8)中的σ 为相似度标准差,xi为某本图书和其推荐图书的相似度,μ为推荐列表中所有图书相似度的均值,N为推荐图书列表数量。标准差可以很好地衡量数据与均值的偏离程度,标准差越大,说明样本之间的差异越大,多样性推荐能力也越强。
(3)新颖度。现有推荐算法评价指标都基于用户的历史借阅行为相似推荐,造成推荐结果的冗余和同质化问题,使用户难以接触到新鲜、多样的内容,导致用户对推荐结果不满意。新颖度评价方式中,基于冷启动的新颖性分析方法[16]是计算推荐列表中冷启动项目数量num 占推荐列表项目总数R 的比例,能有效评价推荐商品的新颖度。本实验选择新书作为冷启动项目,新颖度即推荐新书数量占推荐列表项目总数的比例,如式(9)所示。
4.4 结果分析
为了对本文算法(CLCS-CF)(Chinese Library Classification Similarity-Collaborative Filtering)的性能指标进行评估,对比分析其他协同过滤算法,具体包括:①Item-CF:基于项目的协同过滤算法,利用评分矩阵计算物品相似度预测评分,本实验没有评分数据,改成与读者借阅图书的书名相似且图书热度前10 的项目推荐;②PW-IBCF[17]:改进相似度计算方法,设置流行度阈值,对大于阈值的流行项目设计惩罚权重,降低对相似度的贡献,提高推荐多样性和新颖度,该算法没有对项目聚类;③IACSO-CF[18]:从项目属性特征相似性分析出发,利用K-Means 聚类算法对项目进行聚类,再进行图书所属类相似度前10的项目推荐。
上述3 个算法中,图书相似度是基于Doc2Vec(Document to Vector)[19]模型计算书名相似度。Doc2Vec 算法是将文本转成向量的深度学习算法,继承了word2vec 模型的优点,考虑上下文单词顺序关系,能从语义上表示语句相似度。图书的书名作为语句,馆藏所有图书书名作为语料库,将其装入Doc2Vec 模型训练。通过训练后的Doc2Vec模型能够方便获取与图书书名相似的Top-N 图书。
4.4.1 查准率比较
查准率比较结果如图4 所示,随着推荐列表长度增加,各算法查准率都有所上升。但是,本文提出的CLCSCF 算法的查准率低于PW-IBCF、IACSO-CF,主要原因在于CLCS-CF 是基于中图分类号即学科主题相似推荐,故推荐图书与实验数据是学科主题相似,但是书名相似度没有其他3 个算法准确。IACSO-CF 中引入K-Means 聚类算法并优化相似度计算方法,图书相似度准确率更高。
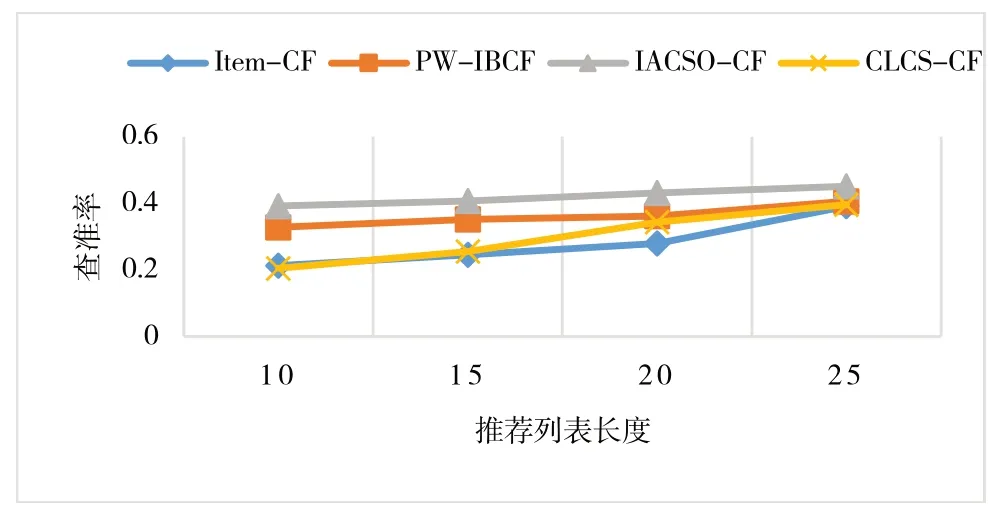
Fig.4 Comparison of the accuracy of different algorithms图4 不同算法查准率比较
4.4.2 多样性比较
多样性比较结果如图5 所示,CLCS-CF 是基于图书主题相似,故推荐列表中图书的相似度差距大,多样性指标明显高于其他算法。推荐列表长度为20,相比PW-BCF 模型,多样性提升19%;相比IACSO-CF 模型,提升47%。由此可见,CLCS-CF 算法虽然查准率低于其他算法,但是在推荐主题相似前提下,更侧重于提高推荐多样性指标。
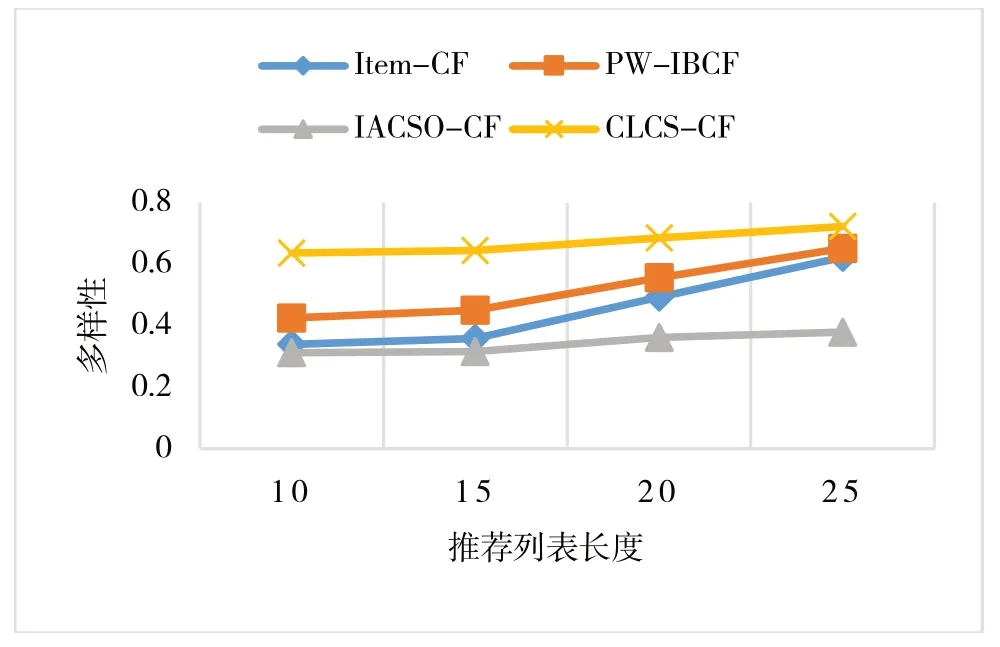
Fig.5 Comparison of the diversity of different algorithms图5 不同算法多样性比较
4.4.3 新颖度比较
新颖度比较结果如图6 所示,随着推荐列表长度增加,各算法新颖度都有所上升。CLCS-CF 算法的新颖度稳定0.67 左右,相比PW-IBCF 算法,新颖度平均提升47%;相比IACSO-Cf 算法,新颖度平均提升65%。由此可见,CLCS-CF 算法引入新书推荐列表,可在一定程度上解决新物品冷启动问题,提升推荐新颖度,扩大用户选择范围。
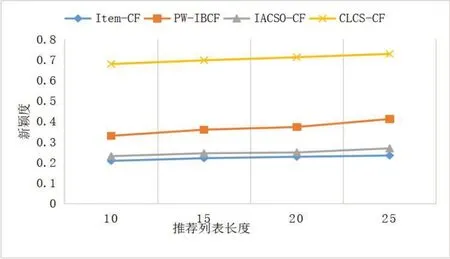
Fig.6 Comparison of the novelty of different algorithms图6 不同算法新颖度比较
5 结语
高校图书馆由于评分数据缺乏,基于用户需求的主动推荐应用较少。当前的图书协同过滤推荐算法一般是基于用户借阅列表相似或评分相似的推荐,存在推荐结果和历史记录同质化严重、推荐多样性及新颖度差等问题,而协同过滤算法自带的冷启动问题也导致新书、新用户无法有效推荐。
针对评分数据缺乏问题,本文加入图书书龄、借阅次数及最近借阅时间指标,并应用层次分析法分析各指标权重后构建AHP-BP 模型评价图书热度,有效评价图书的热门程度,为推荐算法提供评分指标。针对协同过滤算法推荐同质化及冷启动问题,本文将图书的推荐结果分成馆藏热门图书列表和馆藏热门新书列表。本文利用中图分类号可精准表示图书学科主题特点,改进图书相似度度量方式,以图书的中图分类号是否相似表示图书间的相似度,再基于中图分类号相似推荐图书热度Top-N 图书和Top-N 新书。实验结果表明,基于中图分类号相似的协同过滤推荐算法,能提升推荐类别准确率和推荐内容多样性。同时,热门新书推荐列表可解决协同过滤算法的冷启动问题,有助于新书推广。
当然,为了进一步提高图书推荐准确率,图书相似度还可以加入语义度量指标,但如何实现推荐结果准确率和多样性平衡,还需作进一步研究。
