基于语义分割网络的克氏原鳌虾图像识别与分割
2023-10-30龚珺函陈义明朱幸辉王冬武
龚珺函,皮 瑜,陈 黎,陈义明,朱幸辉,王冬武
(1.湖南农业大学信息与智能科学技术学院,湖南 长沙 410128;2.湖南元想科技有限公司,湖南 长沙 410000;3.湖南省水产科学研究所,湖南 长沙 410153)
克氏原螯虾,俗称小龙虾,其肉质鲜美,营养丰富,是我国重要的养殖经济虾类[1]。克氏原螯虾产业的发展对提高养殖户收入、促进养殖技术升级、农民脱贫致富等均具有重要的现实意义。由于受养殖技术、养殖理念和养殖规模等因素的影响,目前克氏原螯虾产业存在种质资源混乱、种苗供应能力不足、种苗质量不一等问题[2],严重影响该产业的可持续健康发展,也不利于养殖户增产增收。为了更好地服务克氏原螯虾产业发展,学者们将图像技术引入克氏原螯虾的生产和监测过程中。例如:Sistler 等[3]用彩色图像处理方法通过克氏原螯虾脱壳前颜色的变化来预测脱壳时间;Tan 等[4]远程操控水下潜水器获取视频序列,通过目标检测与跟踪进行水下克氏原螯虾数量的统计;田灿等[5]采用地标点法和传统形态测量法对我国5 个不同产地克氏原螯虾群体间形态特征进行分析,结果显示2 种方法均可将各群体进行了有效地区分,但基于图像识别的地标点法更高效,有利于克氏原螯虾生产和选育过程中群体的鉴别及外形特征的快速获取。
随着深度学习方法在计算机视觉领域的成功应用,学者们将其优异的性能逐步应用到水产分析领域以实现智能化生产,而对鳌虾进行图像语义分割处理和智能分析为克氏原螯虾优质种质筛选提供了新途径。图像语义分割在遵循人类视觉特点的基础上,可以提供简单且可靠的图像特征信息[6-8]。在图像分割领域中,将边界与其他区域区分开是关键,目前的主流方法有面向对象的图像分割算法和基于深度学习的语义分割算法2 大类[9-10]。面向对象的图像分割算法是基于边界区域与其他区域的颜色差异进行分割,多应用在田间道路和地块边界检测等方面。基于深度学习的图像语义分割算法则是通过深度卷积神经网络提取特征,对特征图进行上采样,输出每个像素的类别来进行分割,多应用于无人驾驶、自动抠图和遥感图像分割等方面。近年来,基于全卷积神经网络框架的U-Net 语义分割模型在生物医学图像分割上取得了较好的效果,在多个相关数据集上也具有实际的应用价值。U-Net 模型由Ronneberger 等[11]提出,只需较少的训练数据就可以得到较为精确的端到端的图像分割结果,当前广泛地应用于各种图像分割任务之中。通常,典型的卷积神经网络输出的是一个单一的类标签,但在图像分割中,需要输出像素的定位,为每个像素分配类标签。U-Net 模型使用简洁的全卷积网络,使用上采样替代池化操作,提高了输出特征的分辨率;运用基于弹性变形的方法连续地对数据进行增强,实现像素的精准定位,并减少了对于训练数据的需求。
该研究在小样本训练数据下,基于传统深度学习语义分割方法,以U-Net 语义分割模型为基础,训练克氏原螯虾样本数据,来获取克氏原螯虾精准分割图。
1 材料与方法
1.1 图像采集与数据集构建
数据采集地点位于湖南省长沙市开福区的水产科学研究所,采集日期为2022 年7—8 月。通过克氏原螯虾活体检测平台操控拍摄硬件设备进行活体克氏原螯虾图片拍摄,硬件机箱内安装6 个海康威视摄像头,同一时间段拍摄6 个方位的克氏原螯虾图,摄像头采集的图像分辨率为2 560 像素×1 920像素,每只克氏原螯虾采集速度大约为60 s。从采集数据中随机选取约1 600 幅图像进行克氏原螯虾数据集制作,其中训练集图片与验证集图片比例为8 ∶2,采用Labelme 工具进行数据标注处理。根据研究目标,该研究只对克氏原螯虾躯干像素进行标注,然后读取标签文件中克氏原螯虾躯干边缘的坐标信息,得到每幅图像对应的掩码区域灰度图。由于克氏原螯虾拍摄过程中,光照的反射以及克氏原螯虾(活体)本身活动对底部的划痕等均将影响拍摄图片的清晰度,后期(8 月)对设备进行了调整,在底部添加灯光罩,加装灯光线路,中和光照,并且为了防止训练过程中数据过拟合,训练数据集中包含2 种环境下共同采集的数据,扩大样本的数量。图1 为数据集中2 种不同光照环境下的图像标注图与灰度图生成效果。
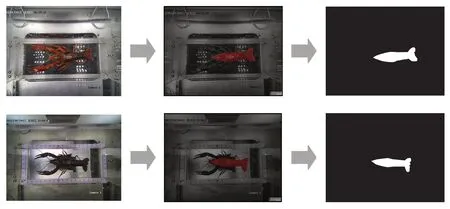
图1 设备整改前后采集的图像数据比对
1.2 基于U-Net 的克 氏原螯虾分割网络
U-Net 是较早使用全卷积神经网络的语义分割网络,该网络呈完全对称分布,其中较浅的高分辨率特征图解决像素的定位问题,较深的低分辨率特征图解决像素的分类问题。网络通过跳跃连接的方式将特征图进行维度拼接,能够保留更多的位置和特征信息,更适合处理像素级语义分割任务。U-Net能从更少的训练图像中进行学习,当它在少于40张图的生物医学数据集上训练时,IOU 值仍能达到92%,并且网络权重参数总量较少,对较小的数据集具有良好的适应性。
1.2.1 传统的U-Net 分割网络 传统的U-Net 分割
网络整体采用U 型编码-解码结构。编码部分由4 个下采样模块组成,每个模块包含2 次卷积操作(kernel_size=3×3,stride=1,padding=0)和一次最大池化操作(kernel_size=2×2,stride=2),通过编码阶段来降低图像尺寸,提取一些浅显的特征,其中卷积采用valid(padding=0)的填充方式来保证结果都是基于没有缺失上下文特征得到的,因此每次经过卷积后,图像的大小会减小。解码部分由4 个上采样模块组成,每个上采样模块包含2 次卷积操作(kernel_size=3×3,stride=1,padding=0)和一个上采样操作(反卷积过程)。编码-解码中间通过concat拼接的方式,将编码阶段获得的feature map(特征图)同解码阶段获得的feature map 结合在一起,结合深层次和浅层次的特征,细化图像,再根据得到的feature map 进行预测分割。由于编码-解码阶段的feature map 大小是不同的,因此拼接时需要对编码阶段的feature map 进行切割。最后,通过1×1 的卷积做分类,分割出前景与背景。传统U-Net 网络整体框架[12]如图2 所示。
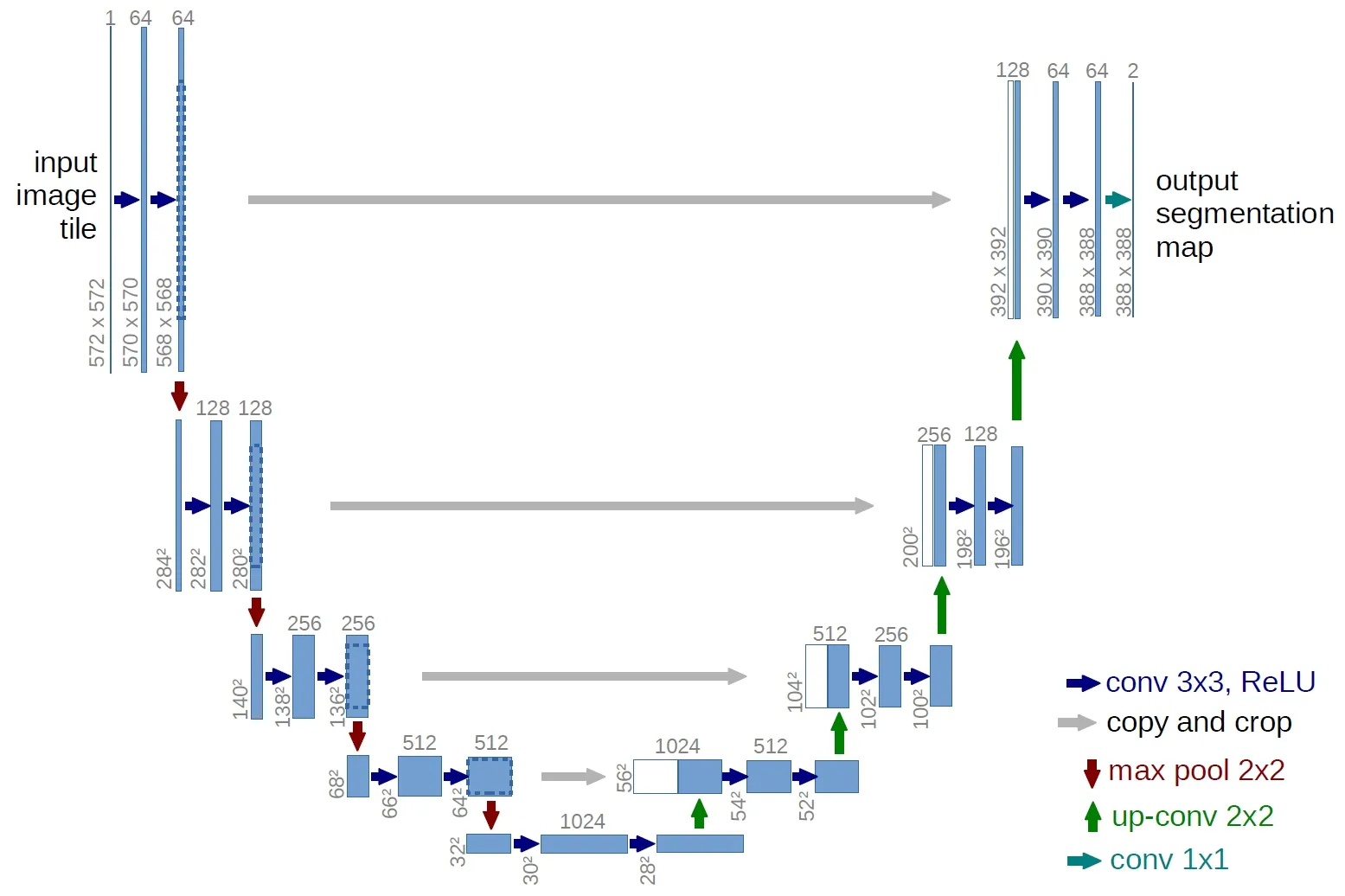
图2 传统U-Net 网络结构
1.2.2 改进的U-Net 分割网络 基于传统的U-Net网络模型,在其基础上做出改进,采用padding 为1 的方式进行上下采样中卷积操作以及利用双线性插值方法代替上采样中的反卷积操作,如图3 所示。传统的U-Net 网络模型通常采用padding=0 的卷积核进行卷积操作,由输入大小为572 像素×572 像素的图片,得到输出大小为388 像素×388 像素的图片(如图2 所示)。但由于试验中缺少的像素点是通过边缘镜像方式得到,因此部分像素点是猜想的,必然会引起误差。而在该文中采用padding=1的卷积层,根据特征矩阵大小计算公式W=(W-3 +2)/1 +1 可知,所输出特征矩阵和输入特征矩阵大小是相同的,且不用边缘镜像的方式就能得到缺少的像素点,最终输入2 560 像素×1 920 像素的图片,得到2 560 像素×1 920 像素的图片(图3)。
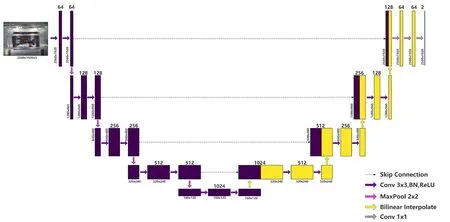
图3 改进的U-Net 网络结构
在早期的语义分割任务中,网络模型涉及到上采样操作,最常见的方法是通过填充0 或者最近邻插值的方式来完成上采样,这种方法虽然简单直接,却无法实现图像的还原,且整个过程不可学习。随后在2015 年,Noh 等[12]提出了可学习的深度反卷积网络,不再通过填充0 或者最近邻插值方法来完成上采样,使得整个过程变成可学习,在图像语义分割网络中实现了对上采样过程的训练。但随着语义分割任务的多样性以及复杂性,在传统的U-Net网络模型上采样过程中,使用反卷积方法进行反卷积的结果与编码部分中对应步骤的feature map(特征图)concat 拼接(即将深层特征与浅层特征进行融合,使得信息变得更丰富)时,由于编码部分中的feature map 尺寸偏大,需要将其修剪过后才能进行拼接(这里是将2 个特征图的尺寸调整一致后按通道数进行拼接),导致上采样过程变得复杂且繁琐,此时,将双线性插值算法引入上采样就是一个不错的选择。
双线性插值算法是一种比较好的图像缩放算法,它充分的利用了源图中虚拟点四周的4 个真实存在的像素值来共同决定目标图中的一个像素值。如果采用双线性插值进行上采样的话(经过双线性插值自身不会改变通道数),上采样后面跟着的2 个卷积的通道数(该研究中为RGB 图,所以通道数为3)是不一样的,比如通过第1 个卷积后通道数会减半,通过第2 个卷积后,通道数又会减半。这样,经过双线性插值后得到的通道数和要进行concat 拼接的特征层的通道数就会保持一致。如图4 所示,图4a为传统的U-Net 所采用的反卷积方法,图4b 为该文采用的双线性插值方法(x1 指的是需要上采样的特征层,x2 指的是要concat 拼接的特征层)。

图4 反卷积与双线性插值上采样
1.2.3 改进后U-Net 图像分割可视化 对改进后的U-Net 模型进行训练,训练完成后,将测试集图像输入便可得到每个像素的回归概率,分割结果如图5 所示,从左至右依次为原图、预测前景(class 1)可视化图、预测背景(class 2)可视化图。

图5 图像分割可视化结果
2 结果与分析
2.1 克氏原螯虾图像分割重要评价指标
克氏原螯虾分割主要通过 4 个考核指标进行评价:Dice、精确度(Precision)、训练参数(Parameter)和训练时长(Training Time)。
2.1.1 Dice 与Dice loss Dice 系 数(Dice coefficient)是一种集合相似度度量函数,通常用于计算2 个样本的相似度,取值的范围为[0,1],常用于分割问题,分割效果最好时为1,最差时为0。
Dice 系数计算公式如下:
式中:|X∩Y|是X和Y之间的交集,|X|和|Y|分别表示X和Y的元素个数,其中,分子的系数为2,是因为分母存在重复计算X和Y之间共同元素的原因。对于语义分割问题而言,X为GT 分割图像(Ground Truth),Y为Pred 预测分割图像,因此也可以理解为(2×预测正确的结果)/(真实结果+预测结果),具体如图6 所示。
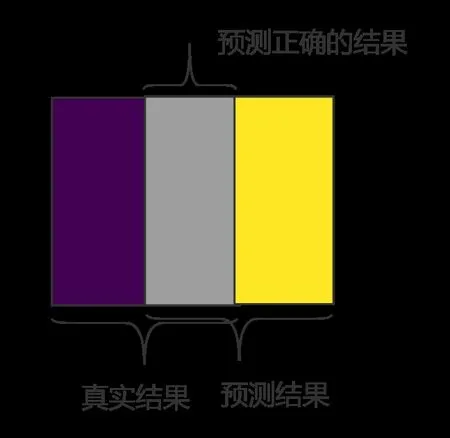
图6 Dice 系数示意图
Dice Loss 是在Dice 系数的基础上进行计算的,用1 去减Dice 系数,即Dice Loss = 1-Dice,因此从结果而言,Dice 系数越大,Dice Loss 越小,表明样本集合越相似;相反Dice 系数越小,Dice Loss 越大,表明样本集合越不相似[13-15]。
在计算Dice Loss 前,首先需要得到预测前景概率矩阵(X)和前景GT 标签矩阵(Y),使用onehot 方法编码对模型输出预测结果图进行处理,分别生成前景和背景的标签,此时预测图的维度由(N,H,W)变为(N,H,W,C),然后再使用permute 方法来调整维度,最终维度变为(N,C,H,W),其中N 代表分类类别数(该研究中图片分割只包含前景与背景,是2 分类问题,因此N 为2),C 代表channel 通道数(例如黑白图像的通道树C 为1,RGB 彩色图像的通道数C 为3,该研究为RGB 图,C 为3),H 代表图片的高度,W 代表图片的宽度。该研究中,Dice loss 采用softmax 方法与one-hot 方法相结合计算得出。
2.1.2 精确度(Precision) 对于一个二分类任务,混淆矩阵confusion matrix 由TP、FP、FN、TN 组成。TP 判定为正样本的正样本像素数量,FN 判定为负样本的正样本像素数量,FP 判定为正样本的负样本像素数量,TN 判定为负样本的负样本像素数量;如表1 所示。

表1 混淆矩阵
而精确度在混淆矩阵基础上表示模型预测为正例的所有样本中,预测正确(真实标签为正)样本的占比,精确度的计算见公式(2)。
2.2 不同模型的对比分析
在正式模型训练前,该研究采用不同模型结构进行预试验,对比分析其结果。首先从克原氏螯虾数据集中选取280 张图片(设备调整后的图片),按照9 ∶1 的比例分为训练集与验证集,利用CPU 设备,分别在改进的U-Net,UNet++,UNet+++以及AttU_Net 这4 种不同模型上进行训练,然后设置5个模型训练次数为10 个epoch,取其中Dice 值最高的epoch 来进行比较分析,训练结果如表2 所示。

表2 不同模型的测试性能指标
由表2 可知,改进后的U-Net 有80.5%的Dice值,预测精确度达到了99.9%,高于其他3 个模型的精确度。虽然AttU_Net 模型的Dice 值比改进的U-Net 模型高1.3 个百分点,但是其所需的训练参数和训练时间均远远超出改进的U-Net 模型,因此利用改进的U-Net 模型来实现克氏原螯虾分割是4 种模型中的最优选择。
为更好地体现改进的U-Net 模型的分割效果,提取改进的U-Net 模型与AttU_Net 模型训练中Dice值最高的epoch 来进行克氏原螯虾分割测试,结果如图7 所示,显而易见,改进的U-Net 模型分割结果较AttU_Net 模型更佳,进一步验证了改进的U-Net模型效果最佳。

图7 改进的U-Net 模型与AttU_Net 模型的分割测试结果
2.3 模型训练
根据预试验结果,进一步证明改进的U-Net 模型效果最佳,因此选择改进的U-Net 模型进行正式训练。训练的硬件配置为AMD Ryzen 7 5800H CPU,Tesla K80 GPU。训练前,随机选取1 276 幅图像作为训练集,318 幅图像作为验证集,其余作为训练集。为了加快训练和预测速度,对原图进行预处理时,图像的缩放比例为0.5,图像分辨率统一转换为2 560 像素×1 920 像素。该试验采取RMSprop 自适应学习率优化器来加速神经网络训练速度,设置epoch总轮次为5,初始学习率为1e-5,weight_decay 为1e-8,momentum 为0.9,batch_size 为1。总共训练时长约为15 h,图8 为模型训练到第5 个epoch 后得到的可视化validation Dice 曲线图,其中最终的validation Dice 为0.944 5,validation loss(即:1-validation Dice)为0.055 5,train loss 为0.029 8。
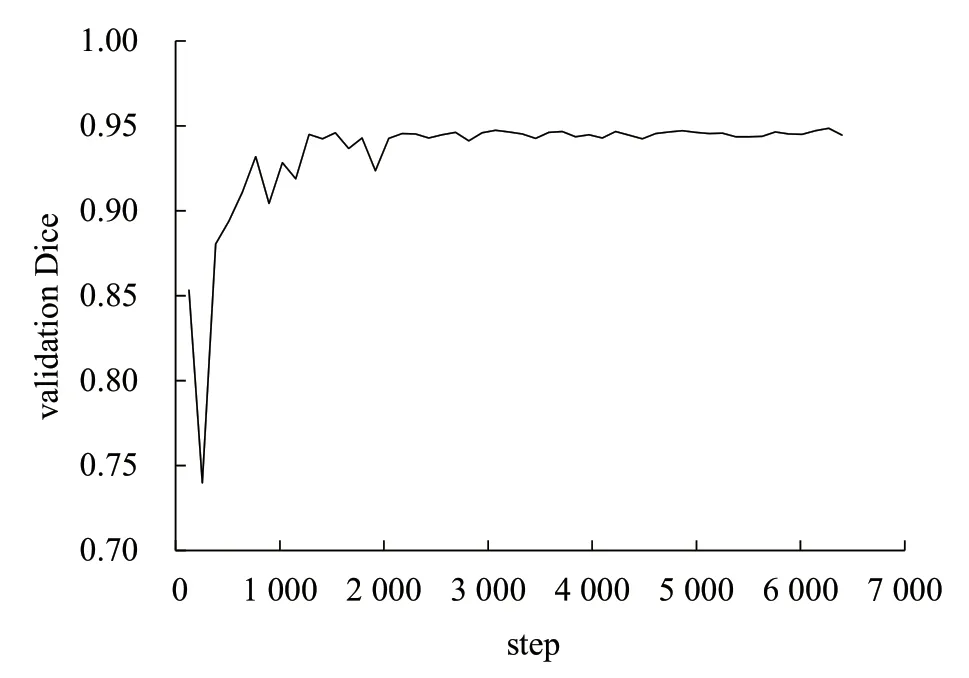
图8 改进的U-Net 模型训练的validation Dice 曲线变化
模型训练完后,为了更好的得到克氏原螯虾的直观分割图,对原图和预测的分割图进行合成,最后得合成抠图,如图9 所示。这表明该研究提出的方法能够有效识别与分割克氏原螯虾,可为水产养殖智能化提供视觉支持。

图9 模型分割图与抠图效果
3 结 论
以克氏原螯虾为研究对象,采用图像语义分割方法,根据采集设备内部场景的实际情况,对鳌虾图像进行了语义分割及分析,基于深度学习语义分割网络模型,在传统的U-Net 基础上进行改进,来训练克氏原螯虾数据集,最终训练完成后得到了较好的结果。试验最终验证集的Dice 系数validation Dice 为0.944 5,validation loss 为0.055 5,train loss为0.029 8,在小样本数据下获得较好的分割效果,为实现克氏原螯虾机器化优质选种打下了的基础,也为水产养殖智能化提供了视觉支持。
