基于自编码器的大规模样本标签校正方法
2023-10-28孙郑依冯涛王晶
孙郑依 冯涛 王晶
北京工商大学 北京 100048
0 引言
压缩机是空调系统的核心组件,压缩机壳体的振动与其运行状态密切相关,故可通过压缩机壳体的振动信号来判别压缩机的运作状况。
基于深度学习技术构建的异常检测模型具有强大的自主学习能力以及良好的特征提取能力,在学习高维数据、时间数据等复杂数据的表达、表示方面显示出了巨大的能力,突破了不同学习任务的界限,可以有效地进行异常检测任务[1-5]。徐丰甜等[6]针对往复压缩机气阀故障根据温度数据有不同的表现特点,提出一种基于主成分分析(PCA)法建立基于径向基函数的故障异常监测模型,实现往复式压缩机故障异常自动检测。王远涛等[7]提出一种基于自编码器模型的制冷压缩机异常振动检测方法,探讨了自编码器迭代次数、隐藏层数以及训练样本数量对判定准确率的影响,结果表明,自编码器模型可以应用于制冷压缩机异常振动检测任务并且样本数量对准确率影响显著。刘恒等[8]针对压缩机故障样本稀缺的特点,提出一种基于变分自编码器模型提取正常样本共性特征进而实现故障检测的方法。
基于分类的深度学习模型可以保证压缩机正异常判断的准确性,但标签准确的高质量数据是确保分类模型判别精度的基础。随着压缩机生产技术的提升,故障压缩机在生产中出现的几率越来越低,正常样本和故障样本的比例极不均衡;大规模生产加大了人工现场实时标注的难度,很容易出现样本标签标注错误的情况。产品生产过程中,各种加工都是根据设计参数进行,所以生产出来的正常机都具有趋同的特性,而故障机基本都是偏离正常参数的结果,在特征空间中表现出较大的离散度,这些问题对分类模型训练和评估带来了极大困难。本文针对这一难题,研究了大规模样本标签的校正方法,采用基于深度学习的自动编码器神经网络模型,使用渐进调整方式训练自动编码器,基于重构误差序列和重构损失值分布曲线提炼样本,纠正错误标签,为后续分类模型提供标签准确的样本。
1 自编码器重构样本误差序列
自动编码器是一种无监督学习模型,它由编码器(Encoder)和解码器(Decoder)两部分构成,如图1所示。编码器将输入数据映射到低维表示,压缩为一个特征向量,其中包含了输入数据的重要特征;解码器将得到的低维表示重新映射回原始数据的维度,它的目标是尽可能准确地重构原始数据。

图1 自编码器网络结构示意图
对于第k个输入数据:
其编码过程为:
解码过程为:
式中:Hk为神经网络的隐含特征;为神经网络的重构向量;W0、W1为权重;b0、b1为偏置量;σ0、σ1为ReLU激活函数。
自动编码器训练过程旨在最小化重构误差即原始输入数据与解码器输出数据之间的差异。训练过程可以通过最小化重构误差的损失函数来实现。常见的损失函数包括均方差损失(Mean Squared Error,MSE)和二进制交叉熵损失(Binary Cross Entropy Loss),本文采取均方差损失。
损失函数为:
本文研究采用Adam优化器,其结合了动量法和自适应学习率的特性,能够在不同参数和不同数据的情况下更好地适应和调整学习率,实现对模型参数的高效优化。其更新公式如下:
压缩机样本标签主要依靠人工标注的方式,当面对大规模样本时,人工标注难免会出现偏差,导致标签与真实情况不符合,直接影响模型分类性能。但人工标注出现偏差属于小概率事件,大部分样本标签与实际情况是相符的,通过人工标注得到的数据仍对模型训练具有指导性意义。因此,本文利用自动编码器模型,基于人工标注的方式制作初始数据集,逐步校正样本标签,得到纯净的正常压缩机数据集和故障压缩机数据集,为分类模型奠定数据基础。
训练时单纯用正常压缩机样本训练自动编码器,测试时将全部样本输入自动编码器,将每个样本的重构误差从小到大排序得到重构误差序列。由于生产线在同一生产模式下,因此故障压缩机与正常压缩机必然存在一定差异,则其均方差损失较正常压缩机要大一些,对此,将重构误差序列头部对应的样本真实标签修改为正常机,尾部修改故障机,进行数据集的迭代更新。具体实施流程如图2。

图2 流程图
(1)采集样本制作初始数据集,搭建模型架构,确定损失函数、优化器、学习率等参数;
(2)挑选初始数据集中标签为正常压缩机的部分样本作为初始训练集,训练自动编码器;
(3)初始数据集全部样本依次输入训练好的自动编码器并统计每个样本损失值,从小到大依次排列得到重构误差序列;
(4)根据重构误差序列,结合当前标签画出正常样本与故障样本重构损失值的分布曲线;
(5)修改重构误差序列头部样本的标签为正常压缩机,尾部为故障压缩机,生成更新数据集,头部样本作为更新训练集;
(6)根据更新训练集,继续训练上一步得到的自编码器;
(7)根据更新数据集,重复第三步,直至正常数据与异常数据的分布曲线区分开来;
(8)基于更新数据集和重构损失值分布曲线,划分出“干净”的正常样本数据集和故障样本数据集。
2 数据集和模型搭建
2.1 数据采集与数据集制作
数据集来源于大量生产线上空调压缩机实测振动数据,如图3所示,压缩机被放置在托盘上,并随生产线移动。当托盘到达检测工位时,通过下气缸将托盘顶起,使其离开生产线,以减小传送链自身的振动对测量结果的影响。同时,上气缸下压,确保加速度计与压缩机壳体紧密贴合。为了确保加速度计与压缩机壳体的可靠接触,在上气缸和加速度计之间采用弹性阻尼环进行连接。在生产线上使用加速度计来采集压缩机壳体的振动信号,通过NI9234采集卡进行数字信号采集并做傅里叶变换作为自编码器的数据集。

图3 数据采集示意图
图4~5分别为正常压缩机频谱和故障压缩机频谱,为归纳统计压缩机频谱数据的分布特性,对其做最大最小值归一化处理。自编码器的编码器和解码器由神经元和激活函数构成,归一化处理能够加速神经网络学习速率,加快模型收敛速度。
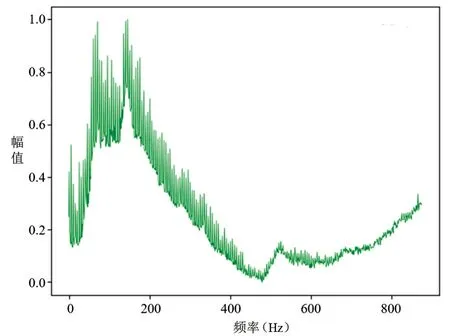
图4 正常压缩机频谱

图5 故障压缩机频谱
图中横轴为频率,单位Hz;纵轴为幅值强度,单位dB。本研究中,选取压缩机数据的频率成分对应的幅值强度作为模型的输入。在生产线上采集的压缩机振动数据共有14784条数据,将其作为初始数据集,标签均由人工方式在采集过程中同步给出。其中,初始正常压缩机样本数为14598,初始故障压缩机样本数为186,随机挑选初始正常压缩机样本中的5000条数据作为初始训练集。根据得到的重构误差序列修改样本标签,得到更新数据集和更新训练集,如表1所示。

表1 数据集说明
本研究的核心目标是让参与训练自编码器的正常机数据越纯越好,使得自动编码器的编码器部分学得样本的特征向量能更准确、充分地表达正常压缩机数据特征,解码器重构时能够对正常压缩机数据进行一个很好的还原;当给自编码器输入故障机数据时,由于两类数据存在一定差异,使得故障压缩机样本的损失值会稍大一些,这样可选取分布靠前的样本标注为正常压缩机;分布靠后的样本标注为故障压缩机,最终得到两类样本的“干净”数据集,为分类模型提供准确的训练样本。
2.2 自动编码器模型搭建
本研究基于PyTorch深度学习框架搭建自编码器网络模型,模型架构如图6所示。

图6 编码器网络结构图
该模型架构属于堆叠式自动编码器的形式,编码器和解码器由多个线形层和激活函数组成,输入层为了匹配输入的频谱数据共设置876个神经元,编码器将876维的频谱数据逐渐压缩至20维作为输入数据特征向量的表示。激活函数选用了ReLU激活函数和Sigmoid激活函数,前者具备良好的非线性建模能力,后者可以将输出限制在0~1之间来匹配输入数据。本研究采用均方差损失函数(MSELoss)作为重构误差的度量,并使用Adam优化器来更新模型参数。
3 结果与讨论
研究对象为某厂商生产的汽车空调压缩机,数据均由生产线上实测而得。基于图2,本研究共进行80000次迭代训练、修改标签47次,经过修改后,数据集中正常压缩机样本数变为14519,故障压缩机样本数为265。为了评估模型的性能,本研究跟踪了损失函数随训练迭代次数的变化,截取部分损失函数曲线如图7所示。

图7 损失函数曲线
损失函数值在训练开始时较高,但随着训练的进行,损失曲线呈梯度下降趋势,说明自动编码器正在学习输入数据的特征。如图7 a)、b),在训练前期,损失下降的较快,训练振动的幅度较大,在相同的迭代次数情况下,损失函数值下降范围大概在0.0013左右;但随着训练的进行,下降趋势逐步减小,如图7 c)、d),相同的迭代次数损失函数值下降范围很小,此时加大了重构误差序列头部所占比例,增加训练样本并增大batchsize参数,使模型加快收敛速度、梯度下降方向准确度增加、训练振动幅度减小。本文得到的自动编码器模型对数据的重构结果如图8,重构损失值分布曲线如图9所示。
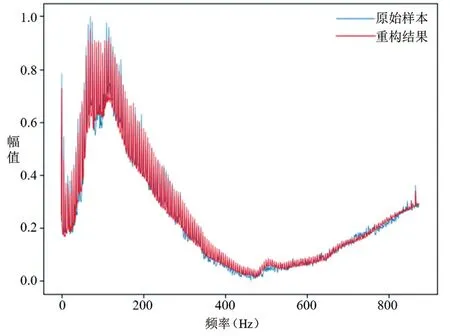
图8 重构结果

图9 重构损失值分布曲线
如图9所示,将全部样本损失值从小到大排序并等间隔划分区间,正常压缩机样本分布曲线能够区别于故障压缩机样本分布曲线,即正常压缩机整体损失值偏小,故障压缩机整体损失值偏大一些。针对这一分布特性,可选定某一区间界限,挑选出样本标签与真实情况准确无误的样本划为分类模型的数据集。在本研究中,图中第50个区间内的某一损失值0.00054,设为正常压缩机样本标签的分界线;第125个区间内的某一损失值0.0014,设为故障压缩机样本标签的分界线。在现有样本中,若样本输入自编码器模型得到的损失值小于0.00054可认为其真实标签为正常压缩机;大于0.0014则认为其真实标签为故障压缩机。
训练好的自动编码器模型也可作为人工实时标注现场的辅助工具,若人工标注为正常压缩机,且其损失值小于0.00054;或人工标注为故障压缩机,其损失值大于0.0014,则可直接划分到分类模型数据集当中。
在原始数据集中,共包含14598个正常压缩机和186个故障压缩机,经过本研究校正后,正常压缩机个数变为14519,故障压缩机个数变为265。如表2所示,在正常压缩机当中,标签未被修改即人工标注正确的个数为14400,被修改即人工标注错误的个数为198;故障压缩机中,“标签未被修改”即人工标注正确的个数为67,“标签被修改”即人工标注错误的个数为119,所修改的样本标签经过人工复听认可。

表2 标签校正结果
选择表2中“标签未被修改”列中的样本作为后续分类模型的训练测试样本,因为这类样本的标签得到了人工和自编码器模型的双重认定,确保了样本标签的准确性。
4 结论
本文提出一种针对大规模样本标签的校正方法,通过样本渐进调整,完成了自动编码器模型的训练,实现了样本标签的校正。在样本渐进调整的训练过程中,自编码器损失值梯度逐步下降,最终收敛,表明自编码器可用于样本渐进调整。本研究可对工业现场采集的大规模样本进行标签校正,可为后续分类模型的训练、验证和测试提供了标签更为准确的数据样本。
