机器学习中混合特征选择对模式预报广西春夏气温的订正研究
2023-10-28李德伦肖志祥谢宁新
李德伦, 肖志祥, 谢宁新, 龚 荣
(1.广西民族大学电子信息学院,广西 南宁 530000;2.广西壮族自治区气象科学研究所,广西 南宁 530022;3.广西民族大学人工智能学院,广西 南宁 530000)
0 引言
近年来数值计算方法和高性能计算技术的迅速发展,数值模式已成为现代天气预报的基础,但其受地形、模式初始场、参数的不确定性等诸多因素的影响存在着一定的误差[1]。 气温是最重要的预报要素之一,对它的精确度和精细化预报也有更高的要求。 因此,开展数值模式订正技术研究,提升温度的预报精度不仅能提高社会经济效益,还为日常生产活动带来便利。
当前对数值模式气温的订正主要有传统统计和机器学习两种方法。 传统统计方法主要包括滑动周期法[2]、双线性插值法[3]、一元或多元线性回归法[4-5]、递减平均法[6]和卡尔曼滤波法[7]等。 这些统计方法经过长足的发展,对数值模式气温预报准确率的提升有巨大的推动作用。 但随着海量数值模式数据的出现以及对气温预报精细化要求的不断提高,大气系统高度非线性特征使得传统的线性气温订正模型难以进一步提升预报效果。
机器学习方法对非线性问题和大数据的处理具有独特的优势,已被广泛应用于数值模式的订正。 有研究表明,RF、XGBoost、LightGBM 等机器学习算法能有效降低数值模式气温预报的误差[8-11]。 特征选择是机器学习领域一个重要的预处理步骤。 在不弱化算法能力的基础上,从原始特征中选择出最有效的特征,可简化学习任务,大大缩减算法的运行时间,提升模型效率并增强可解释性[12-13]。 常用的特征选择方法主要有3种:过滤法,具有简单高效的优点,但其存在跟后续学习算法不关联的弊端,导致无法针对性的选出相应模型合适的特征集合,如Spearman 相关系数法[14-15];包裹法,其选出的特征集合性能较好,但通用性较差且计算复杂度高、开销大,如递归特征消除法[16-17];嵌入法,性能较好,但一定程度上依赖于参数调整,结果稳定性相对较差,计算复杂度介于过滤式和包裹式之间,如XGBoost 特征选择法[18-19]。
单一的特征选择方法在特征选择过程中可能会过滤掉一些潜在信息,导致结果稳定性差,而通过组合不同的特征选择方法,发挥各自优势,通常可以提高性能[20]。 Spearman 相关系数和XGBoost 特征重要性是机器学习中最常用的两种特征选择方法,但优缺点同样明显。 本文融合两种方法的优势,提出了SpearmanXgb 混合特征选择方法,并结合预测性能和泛化能力较好的RF、XGBoost、LightGBM 3 种常用机器学习算法[21-22]对广西地区ECMWF 近地面2 m气温模式格点预报进行误差订正,为提升模型订正效果、实现气温的精准预报提供一种新的尝试。
1 数据和方法
1.1 数据
使用的数据来源于欧洲中期天气预报中心(european centre for medium-range weather forecasts,ECMWF)网站(https:/ /www. ecmwf. int/en/research/projects/tigge)公开的TIGGE 数值模式数据。 数据包含逐日00:00 时的分析场(0 时刻场)和预报时效为24 ~240 h 的预报场。 数据时间范围为2015-2020 年的春季和夏季(3-8月),空间范围为20 °N~27 °N,104 °E~113 °E,水平分辨率为0.5°×0.5°,共285 个格点。 ECMWF 模式输出数据总共24 个气象要素,除近地面2 m气温外其余的23个要素作为模型特征(表1)。

表1 ECMWF 数值预报的23 个气象要素
ECMWF 模式的分析场由其观测的气象数据通过模型预测和数据同化得来,广泛应用于相关研究[23-24]。 本文将近地面2 m气温的00:00 时的分析场作为机器学习模型的标签,将标签所处时刻模式预报的23 个要素作为机器学习模型的特征,以此对ECMWF 模式的近地面2 m气温进行订正。
1.2 方法
1.2.1 特征选择
(1)Spearman 相关系数
Spearman 相关系数也被称为等级相关系数,反映特征之间的关联程度,并且它不依赖于样本的分布。公式[24]如下:
式中,di=x′i-y′i,x′i表示观测值xi的等级,y′i表示观测值yi的等级,n为样本数量。
Spearman 相关系数绝对值在0.8 ~1.0 表明相关性极强,在0.6 ~0.8表明有较强相关性,在0.4 ~0.6表明相关性中等,在0.2 ~0.4表明相关性较弱,在0~0.2表明相关性极弱或不相关[25]。
(2)XGBoost 特征重要性
XGBoost 是Chen 等[26]在2016 年提出的基于梯度下降决策树改进的机器学习模型,使用的特征重要性计算方法是信息增益,公式如下:
Spearman 相关系数法能够在模型建立前快速过滤掉一些相关性差的特征,方法简单快速,但缺点是可能会选入冗余特征或剔除有用特征,得到的不是最优特征子集,造成模型预测性能不佳。 而XGBoost 特征重要性法其特征选择过程与模型训练是同步完成的,通常所选的特征子集能得到比Spearman 特征选择更好的模型回归效果,但计算复杂度高、耗时长且容易过拟合。 因此,本文提出混合特征选择(SpearmanXgb)方法,充分发挥二者的优势,即先通过Spearman 相关系数法快速剔除一些特征,降低数据规模,从而加速XGBoost 特征重要性的计算过程,得到最优特征子集,提升模型预测性能。
1.2.2 3 种机器学习方法
(1)RF
随机森林是Leo Breiman[27]在2001 年提出的基于决策树的集成学习算法。 其构建过程如下:
(i)从输入样本中以随机且有放回的方式抽取与输入同等数量的样本,构建k棵决策树。
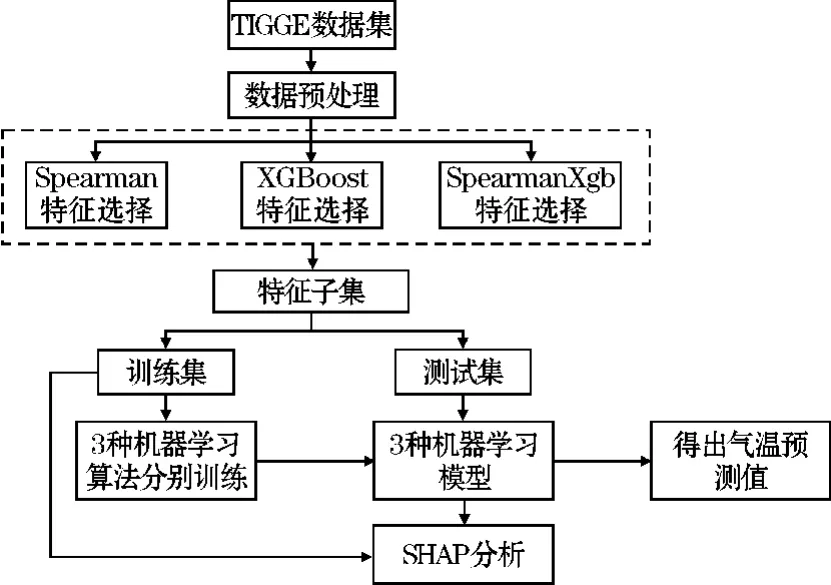
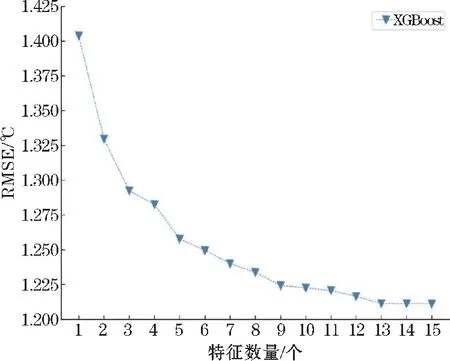
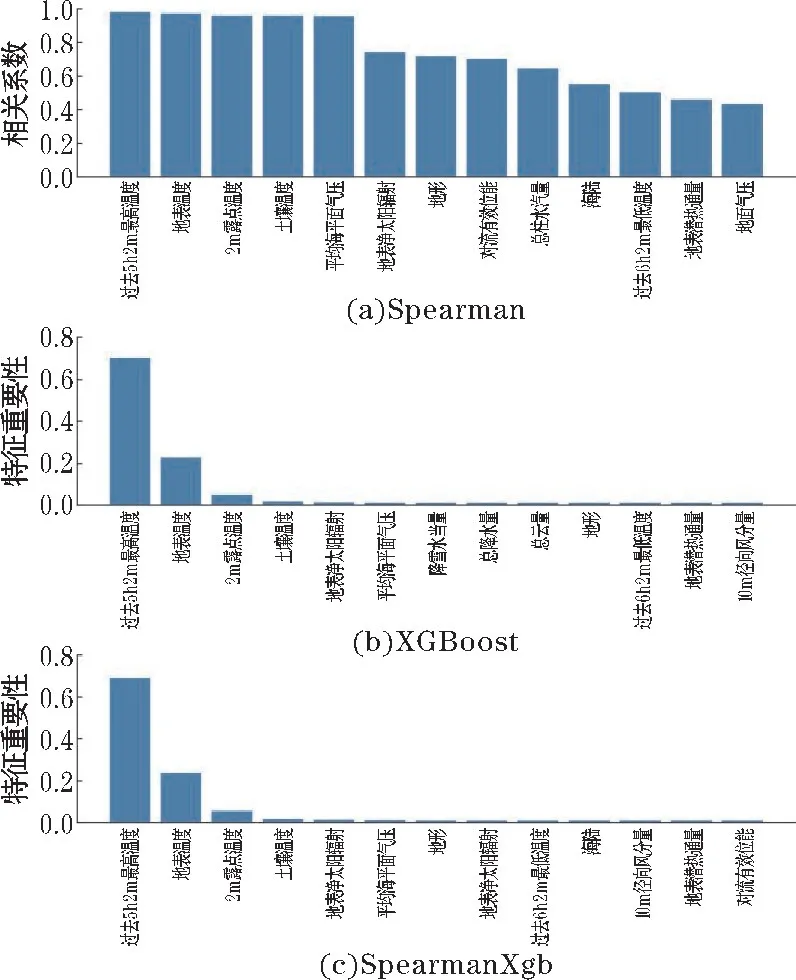
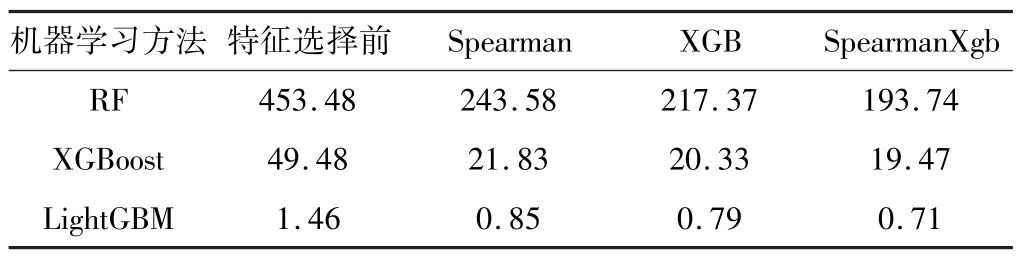
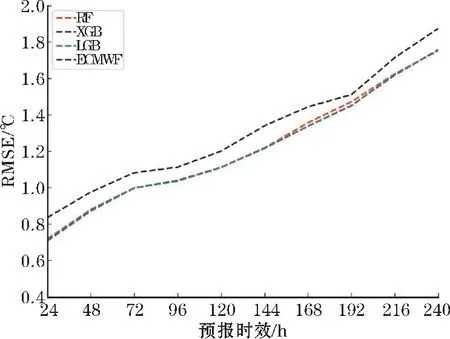
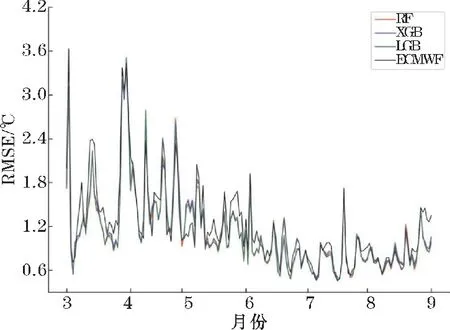
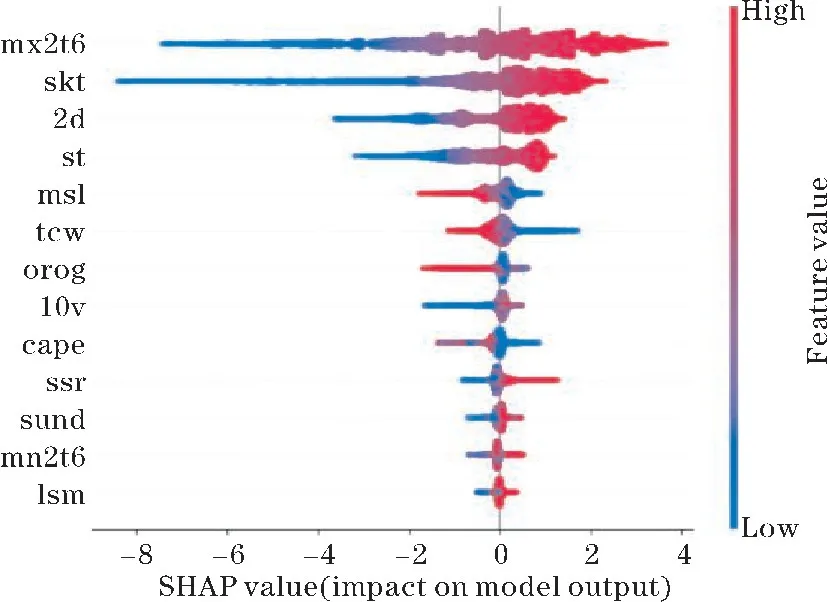
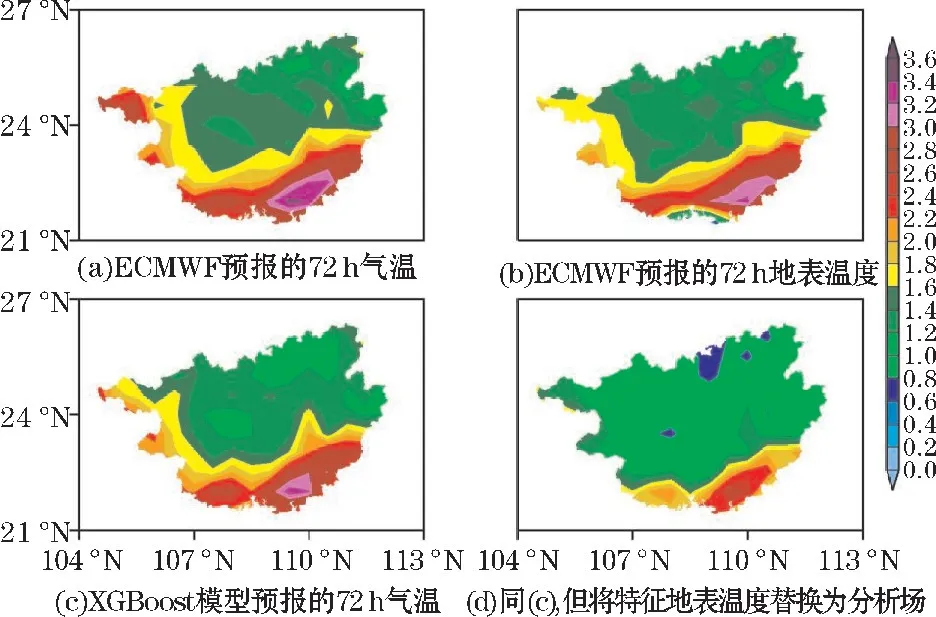
(ii)在对决策树的每个节点进行分裂时,从全部N个特征中随机抽取n个特征(n (iii)将生成的k棵决策树组合成森林,其平均值作为模型的最终输出结果。 (2)XGBoost XGBoost 是基于CART 树的一种集成学习算法。假定有k棵CART 树,则XGBoost 算法的预测值为k棵CART 树的预测值总和,公式如下: 式中,fk(xi)表示第k棵CART 树的输出结果,^yi表示XGBoost 算法对第i个样本的预测结果。 (3)LightGBM LightGBM 是一个基于决策树的GBDT 算法框架,它在GBDT 算法的基础上主要进行了直方图算法和按叶子生长策略等优化[28]。 直方图算法是指把连续的浮点特征值转化成k个离散值,并构造一个以k为宽度的直方图,然后根据直方图的离散值来作为特征最优分裂点的选取方式,能达到减少内存开销的效果;按叶子生长策略是指决策树是带有深度限制的按叶子生长,区别于大部分GBDT 算法的按层生长策略。 在分裂次数相等的情况下,按叶子生长策略能够得到更好的精度。 采用RF、XGBoost 和LightGBM 3 种机器学习算法分别对近地面2 m气温进行预报。 基于机器学习的气温预报模型流程图如图1 所示。 图1 机器学习气温预测流程图 (1)数据预处理:对数据集中损坏的数据进行剔除。 按模式数据起报时间将数据分为训练集(2015-2019 年的3-8 月)和测试集(2020 年的3-8 月)。 (2)特征选择:计算23 个特征与标签之间的Spearman 相关系数,剔除相关性弱(0 ~0.2)的N个特征,将剩余特征输入XGBoost 算法;然后计算剩余特征的特征重要性权重,按从大到小排序,得到1,2,…,23-N的特征排序,并依次输入XGBoost 算法。 当XGBoost 模型的均方根误差(RMSE)下降幅度很小且开始趋于收敛时,此时的特征子集则为最优特征子集。 (3)将最优特征子集分别输入RF、XGBoost 和LightGBM 进行训练,得到3 种预报模型。 (4)将测试集输入训练好的模型,得到订正后的气温预测值,评估模型的预报性能。 (5)使用SHAP 值并结合订正后的气温预测值对机器学习模型进行分析。 经过Spearman 相关系数特征选择后,预报时效24 h和48 h分别有6 个特征,72 ~240 h分别有7 个特征因相关系数小于0.2 被首先剔除。 然后通过XGBoost 特征重要性由高到低排序来确定特定数量的特征组合下的10 个预报时效的平均RMSE 随特征数量的变化(图2)。 当特征数量为13 时,XGBoost 模型的平均RMSE 下降幅度很小,并开始趋于平稳,表明此时的特征子集使得模型的效率和精度达到了平衡点。 因此,该特征子集即为模型最优特征子集。 图2 XGBoost 特征选择 由于不同预报时效选择的特征不同,本文以预报时效24 h为例(图3)。 经过3 种特征选择方法选择后的13 个特征各有差异,但也有相似之处。 3 种方法筛选后最重要的前4 个特征均为过去6 h 2 m最高温度、地表温度、2 m露点温度和土壤温度,表明2 m气温与过去6 h 2 m最高温度、地表温度、2 m露点温度和土壤温度之间关联性最强。 图3 3 种方法的特征选择结果 RF、XGBoost 和LightGBM 在特征选择后平均训练时间均有较大幅度的缩短。 其中,经过混合特征选择后平均训练时间缩短的幅度最大,RF、XGBoost 和LightGBM 的训练时间分别缩短了57.3%,60.7% 和51.4%(表2)。 SpearmanXgb 方法使XGBoost 模型的RMSE 略微下降,RF 和LightGBM 的RMSE 略微上升(不到1%),其余两种特征选择方法都使3 种机器学习模型的平均RMSE 略微增大(图4)。 结果充分表明特征选择能够筛选出对气温有关的主要特征。 另一方面,SpearmanXgb 特征选择方法的平均RMSE 相对Spearman 和XGB 分别下降了0.94%和0.64%。 从训练时间和均方根误差上,SpearmanXgb 混合特征选择方法都要优于单一的特征选择方法。 因此,本文主要对SpearmanXgb 特征选择方法的结果进行分析。 图4 3 种特征选择方法10 个预报时效平均RMSE 对比 表2 3 种特征选择方法平均训练时间对比单位:s 分别采用RF、XGBoost 和LightGBM 3 种机器学习算法,对预报的广西近地面2 m气温进行订正。 为分析机器学习算法随着预报时效的增加对模式气温订正的整体趋势和变化,对3 种机器学习模型和模式的预报结果进行评估(图5)。 图5 3 种机器学习模型及ECMWF 的RMSE 随预报时效的变化 从图5 可以看出,3 种模型的RMSE 均小于ECMWF,表明3 种机器学习模型的预报效果均优于ECMWF。 随着预报时效的增大,3 种订正方法和ECMWF的均方根误差都呈现上升趋势且上升幅度相似。 10个预报时效的平均预报效果最好的是XGBoost,其平均RMSE 为1.2112 ℃,其次是LightGBM,RF 和ECMWF,平均 RMSE 分别为1.2125 ℃、 1.2169 ℃和1.3090 ℃。 3 个模型的平均RMSE 相比ECMWF 分别降低了7.04%、7.47%和7.37%。 3 种机器学习算法的订正效果较接近,但又有差异。 在预报前期(24~96 h),XGBoost 的表现最好,其次是LightGBM 和RF;在预报中后期(120 ~240 h),LightGBM 的预报效果最优,然后是XGBoost 和RF。 3 个模型和ECMWF 对气温的预报具有显著的季节差异(图6),夏季(6-8 月)的预报效果比春季(3-5月)好。 在夏季,RF、XGBoost、LightGBM 和ECMWF 10个预报时效的平均 RMSE 分别为0.8402 ℃,0.8358 ℃,0.8410 ℃和0.9271 ℃,其中XGBoost 订正效果最好。 在春季,RF、XGBoost、LightGBM 和ECMWF 的平均均方根误差分别为1.6091 ℃、1.6024 ℃、1.6008 ℃和1.7096 ℃,LightGBM 订正效果最好。 图6 3 种机器学习模型和ECMWF 的RMSE 时间序列 以预报时效48 h、144 h、216 h为例。从气温预报效果的空间分布上看(图7),3 种订正方法和ECMWF的RMSE 在空间上呈现出相似的分布,但在模式误差较大的地方,机器学习方法的订正效果更明显。 预报时效48 h和144 h,广西地区的东南部的RMSE 相对较高,其余格点RMSE 较低;预报时效216 h,广西地区东北部的RMSE 最高,西部和东南部的RMSE 较低。 总体而言,广西地区中部地形以盆地、平原为主,RMSE较低,订正效果好;东南部和东北部地形以山地、丘陵为主,更容易受到台风、前汛期降水等复杂天气过程的影响,气温变化幅度较大,订正效果要差一点。 图7 预报时效48 h、144 h、168 h 的ECMWF、RF、XGB 和LGB 的RMSE 空间分布 Lundberg 等[29]在2017 年提出基于SHAP(shapley additive exPlanations)值的可解释模型,以提高机器学习模型的可解释性。 其基本思想是把单个特征在所有特征序列的边际贡献的均值作为该特征的SHAP 值,通过它来解释特征做出相应预测的内在逻辑,已被广泛应用于企业投资策略[30]、新能源汽车电荷预测[31]、医学临床治疗[32]等领域。 因此,本文采用SHAP 值对机器学习模型中影响气温的特征进行分析。 根据气温预报的空间分布结果,预报前期广西东南地区误差较大,预报后期东北地区误差较大,这是机器学习模型和ECMWF 模式预报的共同特点。 因此,本文对预报时效72 h的其中一个模型(XGBoost)的结果进行分析(图8)。 图8 XGBoost 模型预报的72 h 气温各特征SHAP 值 图8 表示模型每个特征所有样本的情况,一个点代表一个样本。 纵坐标为经过重要性排序的特征子集,即过去6 h 2 m最高温度(mx2t6)重要性程度最高;横坐标为SHAP 值,颜色越红表示该特征数值越大则模型预测的气温越高,蓝色含义相反。 在这个模型中,mx2t6 的SHAP 值范围很广,说明mx2t6 的大小变化对模型的预报结果有很大的影响:即较大的mx2t6 取值会增大气温的预测值,较小的取值则会减小气温的预测值。 而海陆分布(lsm)除了对该时效模型的贡献较小外,其SHAP 值分布范围极小,说明该模型的预报结果对海陆分布的取值不敏感。 由于重要性最高的mx2t6 没有00:00 时的分析场数据,所以选择重要性排第二的地表温度(skt)进行分析。 将XGBoost 模型中地表温度的预报场数据替换为分析场数据,并对比替换前后结果(图9)。 图9 ECMWF 和XGBoost 模型RMSE 的空间分布 从图9 可以看出,ECMWF 预报的气温、地表温度和XGBoost 模型预报的气温空间误差分布非常相似,误差中心都集中在广西南部边缘地区。 说明地表温度的误差对模型的预报效果有很大影响,如果改善模式中地表温度的预报效果,是否可以提升对气温的预报效果。 在实验中把地表温度的预报场数据替换为分析场数据,而模型中的其他特征保持不变,重新放入XGBoost 模型,替换前后结果如图9(c ~d),替换前模型预测的 RMSE 为1.4940 ℃, 替换后 RMSE 降为1.1382 ℃。 可以看出替换后模型预报的温度误差明显下降,尤其是误差较大的东南部地区。 这说明ECMWF 模式预报的空间误差很大程度上是由于地表温度预报的空间误差所造成的。 考虑到地表温度与2 m气温具有很大的相关性,因此选择与2 m气温相关性弱但特征重要性相对较高的平均海平面气压(msl)进一步检验。 结果表明,替换前模型预测的RMSE 为1.4940 ℃,替换后RMSE 降为1.4864 ℃,同样能改善模型的预报效果,但相比特征重要性较高的地表温度改善效果弱一点。 通过SHAP 值分析找出影响模式预报效果的要素并对其进行检验,从而为改善模式气温预报效果提供一些思路。 (1)SpearmanXgb 混合特征选择方法在训练时间和均方根误差两方面,均优于单一的特征选择方法,对大型数据集能够发挥更大作用。 (2)从10 个预报时效(24 ~240 h)的平均RMSE看,RF、XGBoost 和LightGBM 的平均RMSE 相比ECMWF 分别降低了7.04%、7.47%、7.37%。 3 种机器学习算法的订正效果差别较小,但均优于ECMWF。 在预报前期(24 ~96 h),XGBoost 的预报效果最好,其次是LightGBM 和RF;在预报中后期(120 ~ 240 h),LightGBM 的预报效果较好,其次是XGBoost 和RF。 (3)模型的预报效果受模式本身的预报误差影响很大。 ECMWF 的预报场在春季的误差较大,夏季的误差较小,机器学习算法受此影响,春季的预报效果相比夏季要差一些。 由于广西地处云贵高原往两广丘陵的过渡地带,桂东南部和桂东北地形以山地、丘陵为主,地形较为复杂,且是台风、华南前汛期等复杂天气过程影响的前沿阵地,气温变化幅度较大,模式的预报效果较差,因此模型的订正效果也较差。 (4)利用SHAP 值揭示了各个特征取值对预测结果的正负效应,很好地解释了机器学习模型做出相应预测的内在逻辑。 通过对入选特征进行检验为改善模式对气温的预报提供一些思路。2 预测模型构建

3 结果与分析
3.1 各预报时效订正
3.2 2 m 气温的季节差异
3.3 2 m 气温的空间差异

3.4 SHAP 模型分析
4 结论
