基于LSTM方法的新冠肺炎确诊人数预测模型
2023-10-27曹倩孙乾金永超
曹倩,孙乾,金永超
(华北理工大学 理学院,河北 唐山 063210)
引言
自2019年12月,新冠肺炎病毒席卷全球,给全球各国的经济、政治和人民身体健康造成了严重的损害。随着新型冠状病毒在全球的快速传播,2020年初新冠肺炎疫情在美国爆发。由于美国采取了消极的抗击疫情政策——自然免疫法[1],导致新冠肺炎累计确诊人数呈指数增长,对美国的经济发展和人民健康造成了极大的影响。美国作为新冠疫情的重灾区[2],截止2023年3月9日,新冠肺炎累计确诊人数达到了103 802 702人,位居全球第一。新型冠状病毒在全球的全面爆发,让世界再一次意识到公共卫生安全的重要性。
自新冠肺炎爆发以来,为了进一步了解新型冠状病毒的发展趋势,对其进行科学合理的防控,以减少新型冠状病毒带来的负面影响。国内外众多学者基于时间序列模型对新冠肺炎疫情和流行病发展趋势进行预测。在新冠肺炎疫情初期,盛华雄等人利用Logistic模型对新型冠状病毒疫情进行建模预测,在短期预测方面,模型的拟合效果较好,但是模型建立的一个前提假设是新型冠状病毒潜伏期内没有传染性[3],这与目前新型冠状病毒的特点不符。William W. Thompson等人建立了Serfling最小二乘周期回归模型对美国流感疫情死亡人数进行预测[4],证明了Serfling最小二乘周期回归模型应用于流行病预测的可行性。部分学者利用SIR[5]和SEIR[6]动力学模型对疫情发展趋势进行预测分析,取得了一定的成效,但由于模型包含感染率恒定等基本假设,导致SIR和SEIR动力学模型在预测新冠肺炎疫情发展趋势时存在一定的局限性。丘婕帆等人通过移动平均自回归模型(ARIMA)对中国广州新冠肺炎疫情进行建模预测[7],但是该方法非线性拟合能力较差[8],并且不能对新冠肺炎疫情进行长期预测。陈梦凡采用灰色预测模型(GM(1,1)模型)及其改进模型对意大利新冠肺炎疫情进行建模预测,新冠肺炎确诊病例的预测相对误差保持在5%以下[9],预测效果较好。由于机器学习在预测领域表现优异[10],一些学者采用机器学习的方法对新冠疫情发展趋势进行预测。孙许可建立了XGBoost预测模型[11],对中国新冠肺炎疫情进行预测,模型拟合效果较好。刘云翔等人利用支持向量机对中国新疆地区新冠肺炎疫情进行预测[12],模型泛化能力较强。随着深度学习的进一步发展,越来越多的学者采用深度学习的方法来处理时间序列数据,对时间序列数据进行建模分析与预测。为了克服动力学模型和移动平均自回归模型(ARIMA)模型在预测新冠肺炎疫情的局限性,部分学者利用深度学习对新冠肺炎疫情发展趋势进行预测。其中吴琦琦等人利用BP-神将网络进行预测[13],但是BP-神将网络存在梯度消失和梯度爆炸,难以捕捉时间序列数据中的长期依赖关系。张晴利用时间卷积网络TCN模型预测美国新冠肺炎疫情发展趋势[14],验证了该模型对新冠疫情进行长期预测的可行性,并且拟合效果较好。
为了更好地拟合非线性数据、避免传统神经网络的梯度消失与梯度爆炸问题,并且有效地捕捉新冠肺炎疫情时间序列数据中的长期依赖关系,进而对美国新冠肺炎疫情发展情况进行长期预测。本文基于LSTM时间序列预测模型,对美国新冠肺炎疫情发展趋势进行建模预测,进一步了解新冠肺炎疫情发展趋势,为政府采取科学合理的新冠肺炎疫情防控措施提供参考。
1 数据集与数据预处理
1.1 数据集
本次研究所采用的数据集为美国在2020年1月22日至2023年3月9日期间的COVID-19累计确诊病例,数据来源于霍普金斯大学新冠疫情统计网站。经验证,该数据集无缺失值和明显异常值,部分数据见表1。

表1 美国每日累计确诊病例
1.2 数据归一化
考虑到LSTM模型对输入数据的数值范围较为敏感,为了加快模型的训练速度,并且简化模型的复杂度,在此对数据进行归一化处理,归一化数据会被压缩到0~1之间[15]。除此之外,数据归一化还可以提高LSTM模型的精度和泛化能力。数据归一化公式见式(1)。
(1)
在公式1中,data*为归一化后的数值;data为原始数据的数值;min(data)、max(data)分别为原始数据的最小值和最大值。
在LSTM模型输出数据后,需对模型输出数据进行反归一化处理,反归一化公式见式(2)。
data***=data**(max(data)-min(data))+min(data)
(2)
在公式2中,data***为反归一化后的数值;data**为LSTM模型输出的数值;min(data)、max(data)分别为原始数据的最小值和最大值。
1.3 数据划分
在此次研究中,将经过归一化处理后得到的数据按照时间顺序划分为训练集和测试集。其中训练集为归一化处理后数据的前70%,测试集为归一化处理后数据的后30%。其中训练集用来训练LSTM模型,通过不断进行参数的更新和优化来提升模型的性能,测试集用来验证和评估模型的性能。
2 数据建模
2.1 LSTM模型简介
LSTM(Long Short Term Memory)模型是一种特殊的循环神经网络,最早由Hochreiter和Schmidhuber于1997年提出。其设计初衷是为了解决传统循环神经网络中普遍存在的长期依赖问题,实现对时序长期规律的学习[16]。在解决长期依赖问题的同时,它还很好的解决了传统循环神经网络的梯度消失和梯度爆炸等重大问题[17],被广泛应用于时间序列预测、自然语言处理、语音识别等领域。
LSTM模型通过设置记忆单元来解决长期依赖问题,每个记忆单元包含三个精心设计的“门”,分别为遗忘门、输入门和输出门。通过这三个精心设计的“门”来控制记忆单元保留或者丢弃信息。LSTM模型的记忆单元结构如图1所示[18-20]。
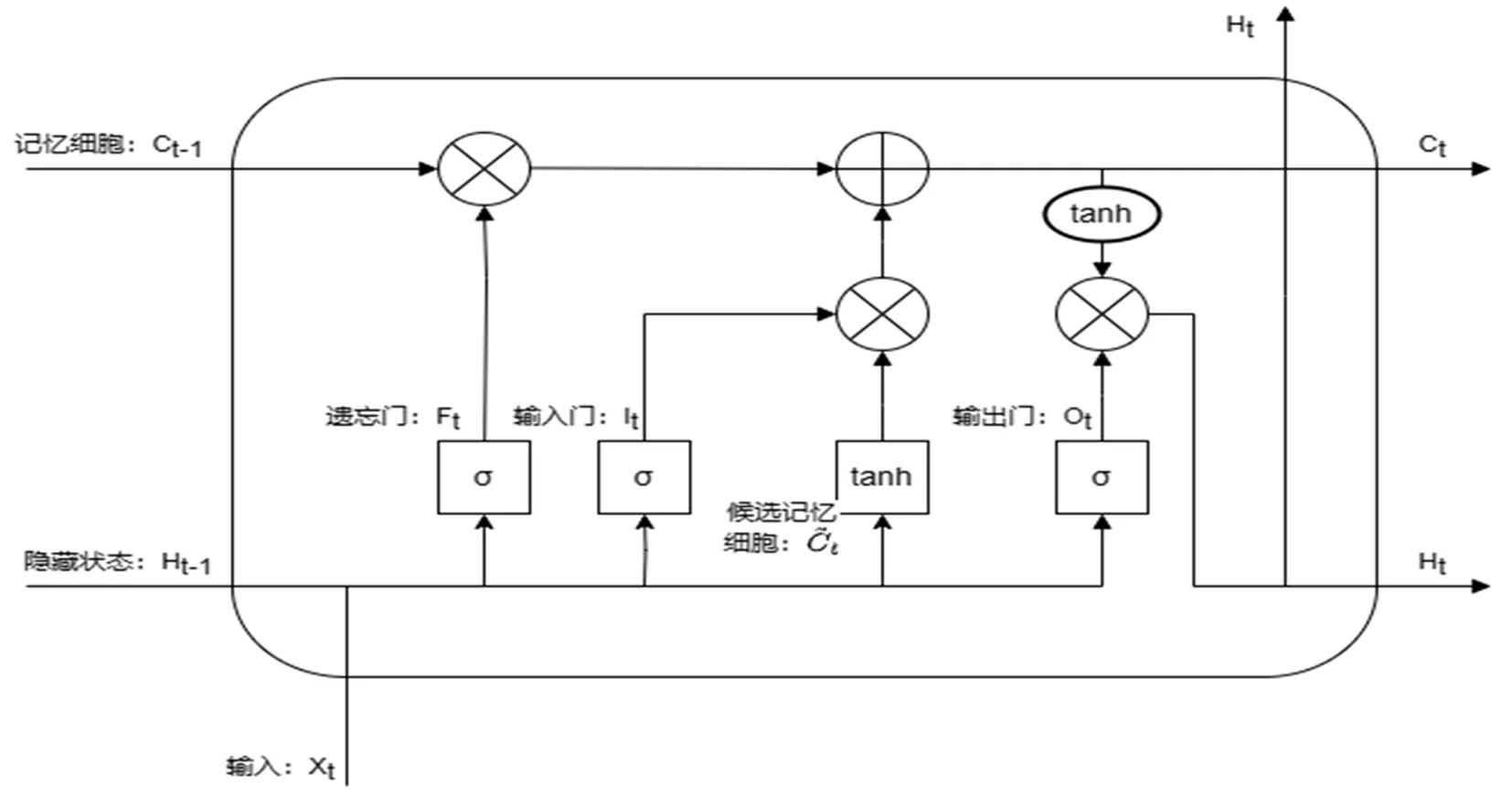
图1 LSTM记忆单元结构
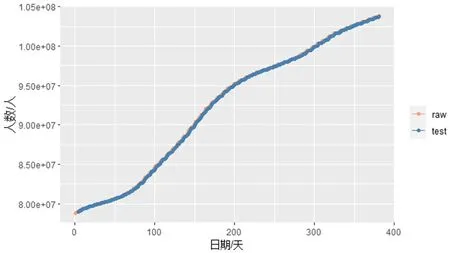
图2 LSTM模型预测值与真实值对比
遗忘门:遗忘门根据当前时刻的输入xt和上一时刻输出ht-1,通过激活函数sigmoid的作用,决定遗忘或者保留哪些信息。当ft→1,表示保留;当ft→0,表示遗忘。ft函数公式见公式(3)。
ft=sigmoid(Wf[ht-1,xt]+bf)
(3)
公式中Wf表示遗忘门的权重矩阵,bf表示遗忘门的偏置系数。
(2)输入门:输入门根据当前时刻的输入xt和上一时刻输出ht-1,通过激活函数sigmoid的作用,决定添加哪些信息。it函数公式见式(4)。
it=sigmoid(Wt[ht-1,xt]+bi)
(4)
在得到当前时刻的ft和it后,更新上一时刻节点的候选状态Ct-1→Ct,更新函数公式见式(5)。
Ct=ft·Ct-1+it·Ct
(5)
其中,
Ct=tanh(Wc[ht-1,xt]+bc)
(6)
(3)输出门:输出门根据当前时刻的输入xt、上一时刻输出ht-1和当前节点的候选状态Ct来决定当前时刻的输出,相关计算见公式(7)和公式(8)。
ot=sigmoid(Wo[ht-1,xt]+bo)
(7)
ht=ottanh(Ct)
(8)
2.2 LSTM模型的构建
本次研究通过R语言构建LSTM时间序列预测模型,考虑到本次研究仅包含美国每日累计确诊病例这一个变量,并且数据量较大,故采用One-to-One LSTM时间序列预测模型。在搭建LSTM时间序列预测模型中,使用的是Keras框架中的Sequential模型[21],通过添加Layers图层的方式构建了LSTM层和一个全连接层,模型根据LSTM层和全连接层自动创建相应的输入层和输出层。在LSTM层中,将时间步长设置为3,输入特征设置为1。在编译模型中,采用均方误差作为模型的损失函数,使用Adam优化器来优化模型参数。在训练模型中,将迭代次数设置为100,批量大小设置为10,学习率设置为0.001。
按照1.3介绍的数据划分形式,将数据划分为训练集和测试集。将训练集和测试集的数据转换为适合LSTM模型输入的数据结构后,运用训练集的数据对模型进行训练。模型训练完成后,将测试集数据输入到模型中,得到在测试集上预测累计确诊病例数和真实累计确诊病例数对比图如下。
通过上图可以看出,基于LSTM时间序列预测模型对美国每日累计确诊COVID-19病例拟合效果较为良好,在测试集上真实值和预测值曲线重合程度较高。在真实值急剧上升阶段,模型预测结果也较为准确,这说明LSTM时间序列预测模型很好的捕捉到了时间序列数据中的长期依赖关系,具备良好的非线性表征能力。
2.3 LSTM模型的评价
合理地选取模型评估的指标是非常重要的,不同的数据类型与预测模型的评价指标大多是不相同的。考虑到常见疫情的发展大多呈现指数趋势,故在本次研究中采用均方根对数误差(RMSLE)作为LSTM模型评价的指标。RMSLE对真实值和预测值进行取对数处理,在处理取值范围较大且呈现对数趋势的数据时,RMSLE惩罚欠预测大于过预测[14]。均方根对数误差的计算公式见公式(9)。
(9)
将模型在测试集上的预测结果经过反归一化处理后得到最终的预测值,将最终的预测值和测试集真实数据代入公式(9),得到在测试集上模型的均方根对数误差RMSLE=0.000 6。RMSLE接近于0,进一步定量的说明了LSTM时间序列预测模型的拟合效果较好,可以较为准确地对新冠肺炎发展情况进行预测。
2.4 模型对比与分析
为了验证LSTM模型预测美国新冠肺炎累计确诊病例的准确性,在本次研究中,除基本的LSTM模型(Basic_LSTM)外,还建立了包含有Dropout层的LSTM模型(Dropout_LSTM),对美国新冠肺炎疫情发展趋势进行预测。Dropout层可以在模型的训练过程中以一定的概率将一部分神经元的输出置为0,从而减少模型的复杂度,提高模型的泛化能力,防止模型过度拟合。在Dropout_LSTM模型建模中,将dropout层的丢弃率设置为0.5,其余参数设置同Basic_LSTM模型。二者在测试集上预测累计确诊病例数和真实累计确诊病例数对比图如图3。
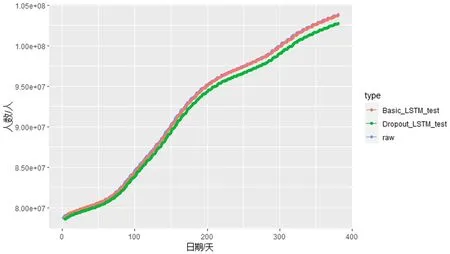
图3 不同模型预测结果对比
通过图3可以看出,Basic_LSTM模型在训练集上的预测效果明显优于Dropout_LSTM模型。进一步计算得Basic_LSTM模型的均方根对数误差RMSLE=0.000 6,小于Dropout_LSTM模型的均方根对数误差RMSLE=0.003 9。其主要原因在于本次研究所选取的数据噪声较小,使得Dropout_LSTM模型在训练过程中较为保守,没有充分利用数据集中的信息。
3 结论
新冠肺炎累积确诊病例数据存在非线性信息,使用传统时间序列预测方法对其进行预测时,预测精度较低,拟合效果较差。基于上述问题,本文采用LSTM时间序列预测模型,对美国新冠肺炎疫情进行建模预测。结果表明,LSTM模型可以有效的处理数据间的非线性问题并且很好的捕捉数据中的长期依赖关系,对美国新冠肺炎累计确诊病例数据的拟合效果较好。通过均方根对数误差对模型进行评估,计算得在测试集上均方根对数误差RMSLE=0.000 6,并且预测效果明显优于添加随机失活层的LSTM模型,说明建立的LSTM时间序列预测模型是切实可行的,可用于预测新冠肺炎疫情的发展趋势。
