卷包设备故障检修业务知识图谱的构建
2023-10-26韦伟,张玉,胡亮
韦 伟,张 玉,胡 亮
(安徽工业大学管理科学与工程学院,安徽马鞍山 210012)
0 引言
卷包设备具有高精密、高自动化、资产价值高等特点,是卷烟生产企业的核心生产设备。设备故障检修时,检修人员通常需要查询设备故障维修手册、故障案例库等检修业务资料。然而这些设备故障数据资料大部分存储在各信息系统、系统日志、纸质文件及设备维修专家的头脑中,存在查询不便、查询准确率不高、检修工作效率较低、数据知识价值不能得到有效利用等问题。知识图谱作为对知识进行有效管理的一个重要工具,它可以将多源异构的故障数据相互联系,以图的形式存储,大大方便卷包设备故障数据资料的检索复用,同时也使故障数据知识价值得到充分利用。
1 知识图谱相关介绍
知识图谱最早由谷歌公司提出,旨在提升搜索引擎性能,使搜索结果以精准的方式反馈给用户,然而知识图谱目前还没有统一的官方定义,刘峤等人[1]将知识图谱定义为:以符号形式对现实世界中概念与关系进行结构化展示的语义知识库。知识图谱在数据结构上表现为,“节点和边”联系在一起的有向图结构,通过把所有不同类的实体和关系以
依据应用领域与应用场景的不同,知识图谱可以分为通用知识图谱和领域知识图谱。知识图谱搭建方式分为自顶向下、从下向上、上下相结合3 种,而领域知识图谱常用自顶向下的构建方式,首先定义故障知识图谱本体,其次基于本体相关概念关系的定义对故障数据资料进行知识抽取,获取故障数据实例,最后将基于本体概念获取的数据实例经知识消歧、知识分类、知识融合、知识存储导入图数据库。
在知识图谱构建过程中,知识抽取获取数据实例的质量对后续故障知识图谱的应用尤为重要,为知识图谱构建过程中的研究重点。
2 卷包设备故障知识图谱的构建
2.1 故障数据预处理
收集与整理卷包机组设备在检修业务中涉及的相关数据资料,如设备维修技术手册、设备故障检修报告、设备故障检修分析数据、安装或拆除的部件信息等数据资料作为故障知识图谱的数据源。这些数据资料大多为以自然语言记录设备故障相关知识,以PDF、Word 形式存储的非结构化数据,故该类数据的知识抽取较为负复杂,需要对数据资料进行预处理,首先需要读取故障数据资料内容,其次通过正则表达式、自定义规则将数据整理转化为规则完整的数据,最后将处理后的数据存储为txt 格式。
2.2 故障知识图谱本体构建
基于检修业务相关故障知识范围以及检修业务中需要重用的知识信息,定义检修业务中知识本体相关概念与关系。首先,定义需要重用的故障知识本体概念。基于本体构建不交类和避免类循环的原则,定义概念如设备(EQUIPMENT)、设备机型(EQUIPTYPE)、故障(FAULT)、检修物料(EQUIPBOM)、故障现象(EQUIPFAULTPHEN)、故障原因(EQUIPDAULTCAUSE)、故障措施(EQUIPFAULTMEASURE)、处理效果(EQUIPFAULTEFFECT)、人员(PERSON)等共9 类。
其次,定义本体概念间的关系,如属于、就职于、组成、包含、并发、引发、影响部位、影响物料、原因、措施、现象、产生、预防建议、修复效果、最终结果等共15 种。
2.3 训练卷包设备故障知识抽取模型
故障数据知识抽取需要借助自然语言处理(NLP)相关方法,BERT+BILSTM+CRF 联合模型为当前NLP 知识抽取中使用较多、知识抽取准确率较高的模型[2]。模型训练的数据集来源于故障数据预处理后的.txt 数据资料,从中选取1000 项故障频次较高、对检修业务影响较大的数据,并对.txt 数据资料中的每行字数进行限定,避免模型训练过程中因过拟合而影响训练结果。对处理后的模型数据集借助“标注精灵”,按照B-I-O 方法标注本体中定义的9 类概念、19 种概念标签(表1)。
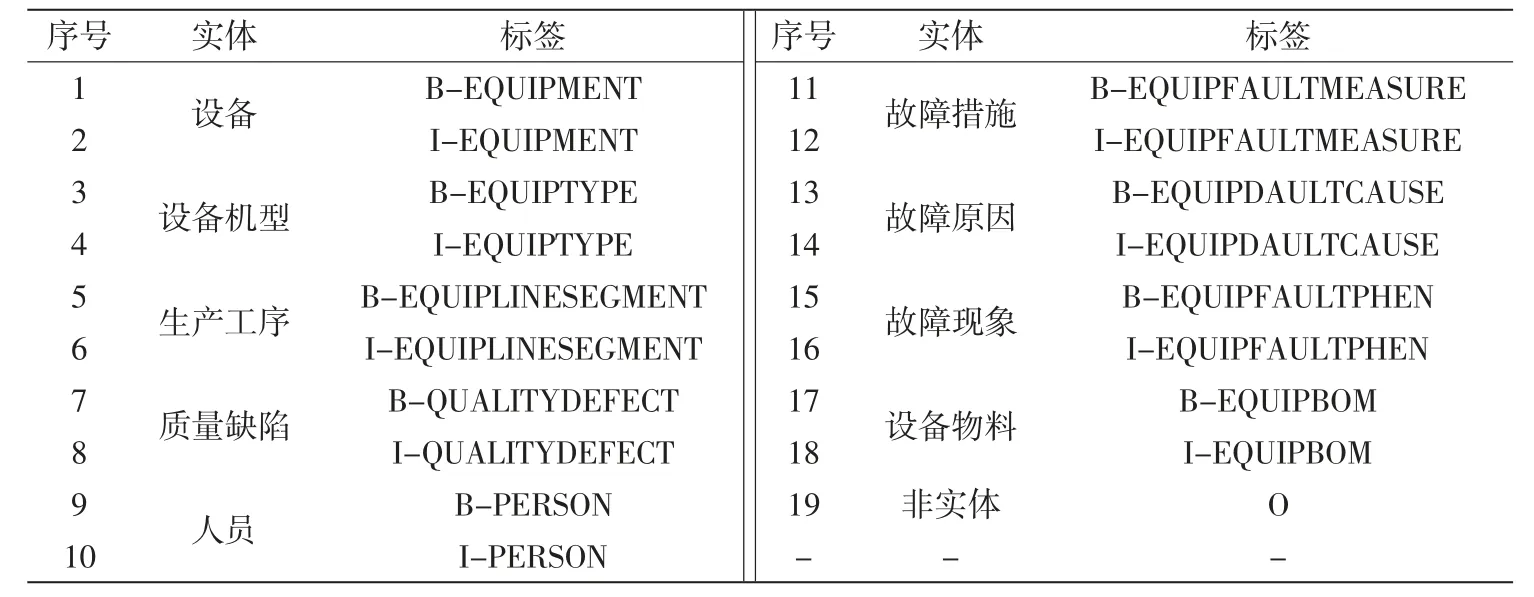
表1 数据标注的标签
将标注的数据集按7:3 分为训练集和测试集,模型训练环境Python 为3.6,Tensorflow 为1.5.0。模型参数设置如表2 所示。BERT-BILSTM-CRF 模型训练效果的判别借助混淆矩阵(Confusion Matrix)分别计算出模型的Accuracy(准确率)、P(精确率)、R(召回率)和F1 值。模型训练(train)数据集和测试(test)数据集的最优训练结果如表3 所示。

表2 知识抽取模型参数设置

表3 知识抽取模型训练结果
模型经训练后,训练集准确率达98.75,F1 值为91.32,测试集的准确率达98.59,F1 值为90.75。对该模型的识别效果通过自然语句进一步验证,可以准确识别出语句中相关知识标签(图1)。

图1 知识抽取模型效果验证
2.4 卷包设备故障知识抽取与融合
(1)故障知识抽取。借助BERT-BILSTM-CRF 模型结合定义的知识抽取规则,从文本数据资料中抽取故障知识。
(2)故障知识消歧。因不同数据源获取的故障知识,可能会存在知识表达方式不同但表示同一类知识,故需要对此类数据进行知识消岐、删除重复信息以避免故障知识重复。
(3)故障知识分类。将经过消歧的故障知识,按照标签自动划分数据类别。
(4)故障知识融合。主要解决数据冲突问题,如一个短语对应多个实体的情况。
2.5 故障知识存储
本文故障知识存储选择Neo4j图数据库[3],因该数据库以图的形式存储和管理知识,在检索数据库中知识时,只遍历与检索知识相关的节点,不受总数据集大小影响,知识检索效率较高,且数据库中主要以节点和边将知识联系组织在一起便于对获取的知识直观展示。将获取的卷包机组设备故障知识存储为csv 格式,再以系统中的load 批量导入方式将故障知识导入Neo4j 图数据库,再借助match 查询语句获取知识图谱相关故障知识。
以查询故障知识图谱中的“烟支破损”为例,match 查询后获取到故障知识图谱中有关烟支破损相关知识将以节点和边的形式直观展示(图2)。
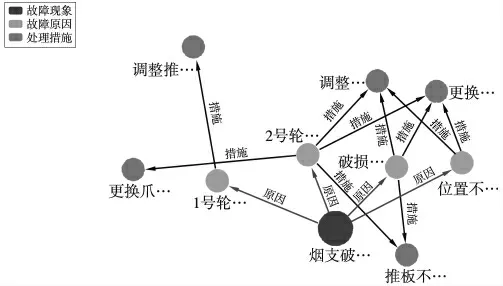
图2 故障知识图谱检索结果示例
3 结论
通过构建卷包设备故障知识图谱,一方面可以使卷烟企业存储多年的多源异构的设备故障数据资料发挥信息价值,另一方面还可以辅助设备故障检修人员的检修工作,提高检修工作效率。此外,还可以通过Neo4j 的cypher 相关语句对故障知识进行增、删、改、查等,使故障知识图谱持续更新与完善。
