基于用户记忆的对话推荐模型
2023-10-25潘杰忠陈佳钦
袁 健,潘杰忠,孙 煜,陈佳钦
(上海理工大学 光电信息与计算机工程学院,上海 200093)
0 引言
随着一大批电子商务平台如淘宝、京东的出现,在线购物越来越普遍,满足了人们日常购物的需要。随着在线商城的商品和用户数量与日俱增,平台中的人工客服难以同时回应所有用户的需求,为了缓解人工的压力,同时帮助用户在大量商品中更快速地找到心仪的商品,催生了面向任务的对话系统,利用智能系统与用户进行对话来帮助用户更快地找到心仪的商品[1],这也极大地促进了对基于对话的推荐系统的研究[1-2]。
传统的推荐系统通常为静态推荐模型,主要根据用户过去的信息(如点击记录、对物品的评分)进行离线训练,进而预测用户对某个项目的偏好。早期的方法,如协同过滤[3],应用矩阵分解技术根据用户购买过的商品计算近邻关系进行推荐,然而缺少新用户数据会出现冷启动问题[4]。最近的基于神经网络的推荐方法,假设用户具有静态偏好,进而根据用户的历史数据来推断用户兴趣,但是由于内部或外部因素,用户的兴趣会随着时间的推移而不断变化[5],因而难以获取用户当前兴趣,同时用户的历史数据通常并不连续,即数据存在一定的稀疏性,进而影响推荐质量[6]。并且,不同用户购买相同的商品虽然很常见,但他们的动机可能不同[7],而静态推荐模型很难发掘用户消费行为背后的不同原因。与传统推荐方法相比,对话推荐方法将用户置于推荐循环中来解决这些问题[1],对话推荐系统是一种动态推荐模型,通过反复提问和收集反馈,可以很容易地引出用户当前的偏好,并理解用户消费行为背后的原因,从而为用户生成更准确的推荐。因此,对基于对话的推荐系统的研究有着较高的应用价值[8]。
目前的对话推荐系统大多通过询问用户当前心仪商品的相关属性来更新用户偏好,但忽略了用户的历史偏好,例如,用户的历史记录(对话、评论)中会反映出用户对某一商品或商品属性的偏好,这些偏好可能与用户当前想要购买的商品相关,但现有的对话推荐系统未有效利用用户的历史记录中所隐藏的偏好信息,通常会以随机顺序询问用户当前心仪商品的属性,这种方式可能需要较多对话回合数才能达到一定的准确性,进而导致对话过长而影响整个系统的效率。此外,在电子商务平台中,用户通常有多种行为(如点击、购买),这不同程度地反映出用户的潜在兴趣,如何有效利用这些行为数据来提高对话推荐系统的性能也是一个有待解决的问题。
针对以上问题,本文首先提出了用户记忆的概念来表示用户可能遗忘的交互、对话记录,用户记忆包括用户的行为记忆和关系记忆,其中行为记忆是用户对商品产生的交互行为(点击、加入购物车和购买)记录,关系记忆是将离线和在线状态下获取到的用户评论、对话记录融入知识图来得到基于用户-商品的关系图。在此基础上,本文提出了基于用户记忆的对话推荐模型(User Memory for Conversational Recommendation,UMCR),利用关系记忆来捕获用户、商品和属性之间的关系信息,保证系统能够始终询问与用户偏好最相关的问题,从而使对话尽可能简短地尽快捕获用户当前偏好,并结合对话之外的行为记忆信息,在缓解用户历史记录稀疏性的同时,充分挖掘用户的潜在兴趣,以提高其对用户需求和搜索结果的信心,进而快速准确地向用户进行推荐。
1 相关工作
在电子商务平台中,用户对商品的行为通常是序列化的,而不是独立的,并且用户的兴趣是动态变化的,通过序列机制可以很好地捕捉这种变化,进而挖掘用户的潜在兴趣;而对话、评论数据中通常包括用户、商品、属性等多种实体,这些实体是离散的,通过图结构可以很好地在这些实体之间建立连接,从而捕获它们的关联关系,并且图结构可以跟踪用户到推荐项目的连接路径,并将路径呈现给用户,使推荐系统具有可解释性和透明性,因此本文利用基于序列和图的方法分别对用户行为记忆和关系记忆进行处理来进行对话推荐。本节首先介绍基于序列和图的推荐算法研究现状,然后介绍对话推荐的研究现状。
1.1 序列推荐
序列推荐的目的是根据用户的历史行为序列进行推荐。行为序列一般包含丰富的用户偏好信息,充分地挖掘序列信息可以更好地理解用户意图。早期的基于序列的推荐方法如马尔可夫链,利用序列数据计算物品之间的转移概率来预测用户的下一个可能点击的项目。最近基于深度学习的技术得到越来越多的关注,Tan等人[9]应用RNN建模用户和物品的交互序列进行推荐,通过并行方法加快模型的训练。You等人[10]利用卷积神经网络来解决RNN带来的梯度消失问题,同时细化序列短期特征。但是深度学习模型难以捕获序列中物品之间的长期依赖,导致推荐效果较差[11]。
注意力机制在序列数据建模方面展示出良好的性能,如机器翻译[11],因此也被应用于序列推荐来提高推荐性能和可解释性[12-13]。例如,Li等人[12]在GRU中加入自注意力以捕获用户行为序列中的潜在兴趣。上述方法只是将注意力机制作为原始模型的一个附加组件。相比之下,完全建立在多头自注意力机制上的Transformer[11]在序列建模方面取得了最好的性能,Liu等人[14]提出基于Transformer的模型TiSAS,将时间戳信息合并到自注意力中来对用户历史行为序列建模,并通过实验证明了Transformer对序列推荐的有效性。但目前基于序列的方法存在以下局限性: 只是对单一行为序列进行学习,忽略了序列的上下文信息,并且在模型的多头自注意力中使用相同的嵌入,这可能会浪费时间学习重叠的信息。
1.2 基于图的推荐
基于图的推荐主要有两种形式,第一种是将推荐建模为一个图上的路径推理问题,用于构建可解释的推荐系统[15]。另一种是通过基于图的表示学习来提高推荐性能,利用图的结构信息进行协同过滤,并将图的嵌入表示作为上下文信息[16]。近年来,图神经网络(GNN)非常流行,其目的是学习离散图结构上的隐藏表示[17],可以学习到传统推荐算法中无法学习到的用户与物品相互之间的关联关系,能够很好地适用于基于图的推荐模型,Wang等人[18]提出NGCF模型,将GNN应用于图的推荐,建模用户与项目之间的关联并依此做出推荐。
最近有人提出基于图的对话推荐,Moon等人[19]构建一个语料库,将对话中的实体与知识图谱中的路径连接起来,进而预测下一个可能出现的实体来进行推荐。Chen等人[20]提出基于知识图的对话推荐系统,通过GNN学习到的知识表示来有效集成推荐系统和对话系统。但目前的工作均利用的是外部知识图,未考虑将用户端信息即用户历史记录中用户与物品之间的关系作为图的一部分,将用户历史记录整合进知识图可以更快地找到合适的项目。
1.3 对话推荐
对话推荐系统可定义为通过实时多回合互动,来获取用户偏好并根据其当前需求采取行动的推荐系统[8]。对话推荐的雏形可追溯到早期设计的交互式对话搜索系统,通过与用户对话加快信息检索。随着自然语言处理技术的不断发展,对话推荐得到越来越多的关注,现有的研究大多遵循系统询问用户响应范式[2],当收集到足够多的用户偏好时向用户做出推荐。例如,Raymond等人[21]通过对话来获取新用户的偏好,然后与传统推荐系统中类似用户进行匹配来解决冷启动问题。Zou等人[22]提出基于问题的对话推荐方法,通过自动生成和算法选择的问题来询问用户对物品属性的偏好。这些方法对偏好的学习只是短期的,接近于面向任务的对话系统。Zhang等人[2]利用用户评论模拟在线对话来更新现有用户的偏好,并通过重排序方法进行推荐。Ali等人[23]将强化学习应用于对话推荐系统来提高问题与用户的相关度,然后通过提问或推荐候选物品进行迭代,直到达到用户标准。Ma等人[24]在知识图上进行树结构推理以探索背景知识,并利用实体之间的联系进行对话推荐。但是上述方法都未考虑用户的历史与潜在兴趣,导致需要较多对话回合数才能准确获取用户当前偏好,进而影响系统整体效率。
本文利用用户记忆信息来解决上述目前对话推荐系统存在的问题,主要贡献如下:
(1) 提出了基于用户记忆的对话推荐模型UMCR,通过融入用户的多行为序列和用户-物品的关系信息来动态管理用户的过去偏好和当前需求,以实现以最少的对话次数完成精准推荐;
(2) 针对目前序列建模方法的局限性,设计了一种基于改进的Transformer的兴趣提取单元,该单元在多头自注意力中使用多类型上下文嵌入来捕获序列中的多种特征,能更好地学习用户行为记忆序列中的潜在兴趣;
(3) 针对目前图的构建方式的局限性,将用户历史评论、对话记录融入外部知识来构建用户、商品和属性之间的关系图,基于学习到的图的表示来调整对话策略,以生成下一个与用户偏好最相关的问题,并随着对话的进行不断更新图以供长期使用。最后,通过实验表明,本文提出的模型在保证准确性的基础上能以更少的对话次数成功推荐。
2 基于用户记忆的对话推荐模型
本文提出基于用户记忆的对话推荐模型UMCR,包括用户记忆模块、推荐模块和对话模块三部分,用户记忆模块包括行为记忆与关系记忆,分别通过序列方法和图方法进行处理来应用于推荐和对话,UMCR的框架设计如图1所示。首先应用关系图卷积网络学习关系记忆中关系图的节点嵌入,基于学习到的嵌入表示,将其加入对话模块中来生成最符合当前对话上下文的语句以尽快捕获用户当前偏好,同时根据用户的反馈不断更新关系图;其次,利用改进的Transformer[9]建模多行为序列来生成用户的潜在兴趣向量,与关系图的节点嵌入融合获得用户兴趣表示,最后与候选商品嵌入进行匹配来产生推荐。

图1 UMCR模型框架图
2.1 用户记忆模块
通过用户记忆模块,在对话时利用关系记忆捕获用户当前需求与历史偏好之间的关联,从而生成与用户偏好最相关的问题,以减少无效的询问;在推荐时利用行为记忆获取用户的潜在兴趣,并与关系记忆融合,在缓解数据稀疏性的同时做出更准确的推荐。
2.1.1 行为记忆
在电子商务平台中,用户通常具有多样化的行为,例如,点击、加入购物车和购买。将用户多行为序列引入对话推荐系统中,不仅缓解了数据稀疏性,而且在对话推荐时通过结合从行为序列中提取到的用户潜在兴趣,能显著提高对用户需求和搜索结果的信心。
对于行为序列的处理,基于多头自注意力机制的Transformer模型可捕获序列中行为之间的依赖关系,并可实现并行训练,因此可被用于建模用户多行为序列来提取用户的潜在兴趣。但用户的不同行为通常有着不同的时间尺度(如用户一天中会有许多点击行为,但一周只有少数购买行为),即不同行为序列中行为之间的依赖程度不同,进而会不同程度地反映出用户的潜在兴趣,而目前的模型大多忽略了包含这些重要信息的时间尺度,或者考虑到了时间尺度却在每个注意力上使用相同的嵌入,这可能难以有效利用时间特征,导致学习到的信息有限。为此,本文设计了一种兴趣提取单元(Trans),通过在Transformer中引入多类型上下文(时间、位置)嵌入来关注序列的多种特征,不仅学习到行为的位置顺序信息,也考虑到了行为之间依赖程度不同的特点,并且在多头自注意力的每个注意力上使用不同的嵌入,在提升计算效率的同时使每个注意力专注于特定的特征来学习更准确的序列表示,进而更准确地提取用户的潜在兴趣。
(1) 输入和嵌入方法
首先定义行为记忆的输入为用户的多行为序列,由一个可变长度的商品序列表示。对于用户u∈U,商品i∈I,输入表示为B=[i1,i2,…,iL],其中L是序列的长度,序列中的每个元素代表用户u对商品i做出了此种类型的行为,本文考虑了三种类型的用户行为序列: 点击序列Bc,购物车序列Ba和购买序列Bo。同时对于序列中的每一个商品,都有其对应的时间戳值和位置索引作为上下文信息,分别以序列T=[t1,t2,…,tL]和P=[p1,p2,…,pL]表示。
然后利用嵌入方法将序列转换为提供给兴趣提取单元的隐藏特征。对于每一个商品i,使用其名称id和标签id来表示,然后使用可学习的嵌入表将稀疏的名称id和标签id转换为低维稠密向量表示,再将这些向量串联成单个嵌入向量el,最后获得序列嵌入EB=[e1;e2;…;eL]∈Rd×L,el∈Rd表示维度为d的嵌入向量。对于时间戳序列T,序列中的元素代表用户对商品产生交互行为的具体时间戳值,使用一个可学习的矩阵XT∈R|l|×h将每一个时间戳转换为一个嵌入向量来获得时间嵌入ET,其中h是隐藏特征大小,l是数据集中的时间跨度,考虑到矩阵大小和整体有效性,选择“一天”作为时间长度。为了更好地表达位置信息,类似于以往的工作[11],采用两种方式建模位置序列P: 第一种是绝对位置嵌入,使用一个可学习的嵌入矩阵XP∈R|l|×h映射每一个位置索引,进而获得绝对位置嵌入EP;第二种是使用正余弦函数将序列的位置信息转换为嵌入向量来表示相对位置嵌入ER。对于用户id,将其表示为独热编码向量作为用户特征嵌入。
(2) 兴趣提取单元
利用兴趣提取单元(Trans)来提取行为序列中的用户潜在兴趣,其结构如图2所示。
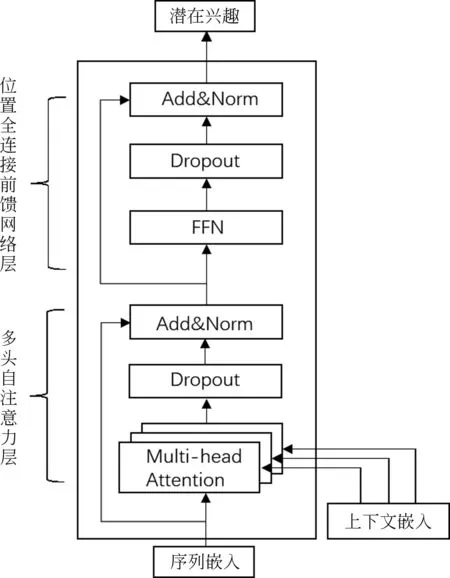
图2 兴趣提取单元
多头自注意力层兴趣提取单元的输入为行为序列嵌入和三种上下文嵌入(一种时间嵌入和两种位置嵌入),嵌入特征首先通过多头自注意力层。传统的自注意力模块使用注意函数将查询和一组键值对映射到输出,输出的是值的加权和且查询、键值都是向量,分配给每个值的权重由一个查询和相应键的函数计算,通过自注意力可以考虑到序列的整体相关性,具体计算公式采用的是缩放点积注意,如式(1)所示。
(1)
其中,Q,K和V分别代表查询、键和值,查询和键的维度相同都为dk,值的维度为dv,通过Softmax函数获得值的权重。
由于单个自注意力只能捕捉一种序列中的关系,因此在实践中通常使用多个并行的自注意力模块捕捉序列中的多种关系,即使用多个注意力矩阵和多个权重对输入值进行加权平均成为多头自注意力,最后对加权平均的结果进行拼接,这样可以更好地捕获序列中的相互关系。该过程可用式(2)、式(3)所示。

其中,bK,bQ,bV∈Rdk,然后通过计算QKT可分别捕捉位置信息和包含key的内容信息。
但是序列中包含着丰富的上下文信息,仅仅利用位置信息难以捕捉行为之间不同的依赖关系,并且在多头自注意力中的每个注意力头都使用相同的位置嵌入,这可能会浪费训练时间,学习到的信息也是有限的。因此本文设置了三个注意力头,在每个注意力头上使用不同的上下文嵌入,如图2所示,分别是时间嵌入、绝对位置嵌入和相对位置嵌入,时间嵌入可以将注意力范围限制在同一(周或类似)天内,从而更好地捕捉不同时间尺度下行为之间的依赖关系;绝对位置嵌入可以提取序列中不同位置的信息,从而在学习当前行为表示时不仅用到之前的行为信息,还考虑到后面位置的行为信息;相对位置嵌入捕捉序列中的周期性行为信息,通过这样设置将反馈给注意力模块的上下文信息多样化,从而关注序列的多种特征以更好地学习用户潜在兴趣。
对于每个注意力头中序列嵌入和上下文嵌入的合并方式,传统的直接合并的方法(图3左图)仅适用于多头自注意力只有单个位置嵌入的情况,难以适用于本文提出的多类型上下文嵌入机制,因此为了充分利用多种形式的上下文嵌入,在每个注意力头上分别合并序列嵌入和上下文嵌入的查询、键映射,从而使每个注意力头专注于各自的上下文嵌入来学习更准确地序列表示,如图3右图所示。

图3 多头注意力设置
位置全连接前馈网络层在经过多头自注意力层后,应用一个位置全连接前馈神经网络来提高模型的表达能力,使用更平滑的GELU激活函数,如式(7)所示。
FFN(x)=GELU(xW1+b1)W2+b2
(7)
其中,W1∈Rd×h,W2∈Rh×d,b1∈Rh,b2∈Rd为可学习的参数,但是随着网络的层数增加,训练会变得困难,因此如图2所示,在多头自注意力层和位置全链接前馈网络层这两个子层的周围都使用残差连接和层归一化步骤,具体表示如式(8)~式(10)所示。
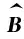
2.1.2 关系记忆
本文通过提取用户历史(对话、评论)记录中包含的所有实体(如商品、属性)来构建关系记忆,其基本思想是: 用户的历史记录通常反映用户对商品和属性的偏好,通过提取历史记录中的实体并以不同的关系建立连接,由此构建一个关系记忆网络来具体记录用户、商品和属性之间的关系信息,进而在对话时通过关系记忆能够找到与用户当前偏好最相关的商品或属性进行询问,以提高系统效率和用户满意度。
由于历史记录中的实体大多是离散的,传统的将历史记录直接编码的方法难以捕获实体之间的关系,在对话中存在实体候选空间过大的问题,通常需要较多回合才能找到与用户偏好最相关的商品和属性,而图结构可以很好地建立起离散实体之间的关联,从而能够发现用户对商品和属性的偏好,因此本文以图的方式处理用户历史记录,并融入外部知识来得到基于用户-商品的关系图作为关系记忆。
为了构建和更新关系图,需要将非结构化的话语转化为结构化知识,因此在预训练阶段,本文根据Chen等人[20]的方法从亚马逊语料库[25]提取实体关键词,主要包括用户历史记录语句中的关键字词和相关的商品属性信息(名称、类别、特征、品牌名、价格等领域词汇),然后将获得的实体关键词作为起始节点,在外部知识图KG[26]上提取它们一跳范围内的三元组来构建关系图。在此基础上定义关系图中的三元组表示为
例如,对于表1用户当前需求,利用图4关系图进行的对话如下: 根据用户的对话,得知当前用户需求为饼干,希望系统给出推荐,系统收到请求后通过关系图获取用户对饼干的偏好可能与“卡夫公司”的产品相关,从而缩小了询问的范围,避免饼干的种类过多难以选择要询问的类型。然后系统询问用户对“趣多多”类型的饼干是否感兴趣,用户做出肯定答复但想尝试其他类型的饼干,然后系统进一步根据用户在评论中表达出对“健康”食品的偏好,询问用户是否偏好比较健康的饼干,然后得知用户依然喜爱,再结合用户潜在兴趣推荐具有这些属性的“无糖奥利奥”,最后获得用户肯定答复后表示推荐成功,再更新关系图,如图4所示。
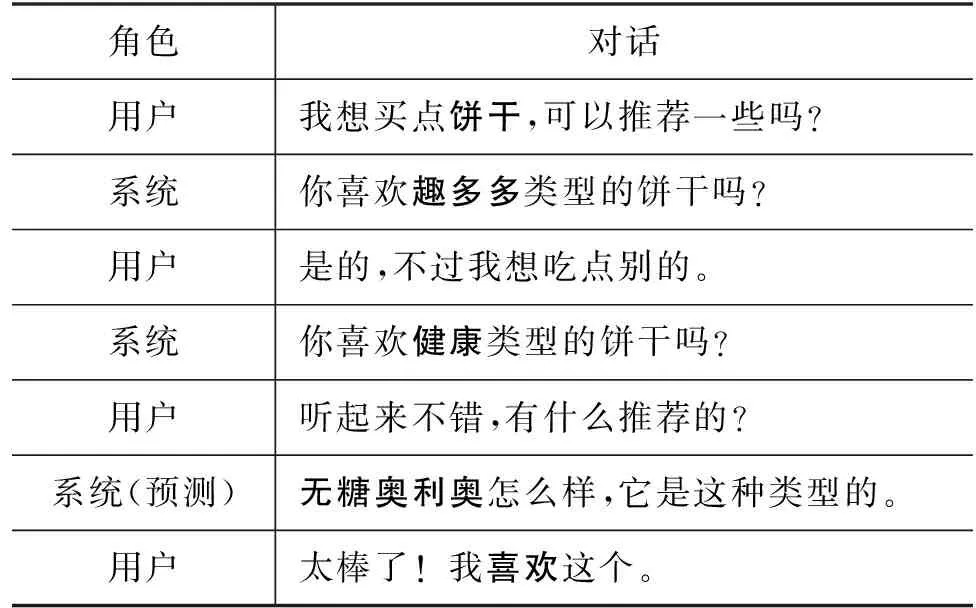
表1 对话示例

图4 关系图示例
为了在对话中利用关系记忆,首先需要学习关系图中的实体表示和结构信息,然后加入对话模块。考虑到本文提出的关系图中的边表示为不同的关系,为了更好地学习图中用户、商品及属性之间的相关性信息,应用关系图卷积网络(R-GCN)将关系图中的实体和关系信息编码为隐藏表示,R-GCN是一个带有类型化关系的图卷积网络,其中每个关系都与它们自己的权重相关联[17]。每个实体由多层R-GCN进行编码,节点在第l+1层的隐藏表示可通过式(1)计算。
(11)

2.2 推荐模块

其中,σ为激活函数,W,b分别为可学习的参数矩阵和偏置向量,z表示门控信号,通过门控机制来控制信息的融合速度,有选择地加入新的信息和遗忘不需要的信息,并使模型能够选择与用户当前需求相关的信息来提高推荐的准确性。
然后根据学习到的用户兴趣表示,遵循一般的方法,计算从商品集合中向用户u推荐商品i的概率,如式(14)所示。
(14)
其中,ei表示商品嵌入,根据式(14)可以得到所有商品的预测分数进行排序,然后将预测分数最高的商品推荐给用户。在训练阶段,为了学习模型的参数,定义以下交叉熵损失,如式(15)所示。
(15)
其中,t是对话的轮数索引,l是商品的索引,通过循环整个集合来计算交叉熵损失,由于损失函数相对于模型的参数是可微的,因此本文在基于梯度的数值优化算法上使用反向传播来训练模型。
2.3 对话模块
Transformer[11]在人机问答、自然语言生成等任务中性能显著,能顺利进行对话生成,因此本文将其作为基础对话模块。Transformer包括编码器与解码器,编码器将输入的用户语句序列中的每个单词进行编码,得到序列的高阶表示;然后将其输入解码器解码,得到输出的语句词向量序列;最后在词向量序列上应用Softmax分类函数来得到单词表上的概率分布。
为了生成与用户偏好和当前推荐任务最相关的对话,本文将关系图的增强表示加入对话模块。具体来说,将学习到的关系图的实体隐藏表示矩阵XR加入解码器中来增强相关实体的表示,方法为在经过多头自注意力层后,加入一个基于关系图的自注意力层(RA)来融合关系图的信息,可以表示为:

通过上述方式将关系图中的信息融入解码器,使得对话模块能够依据此信息动态地调整对话策略,然后生成与用户偏好最相关的回复。不同于一般的对话模型(如开放域对话),对话推荐系统生成的回复语句中的词汇应包含推荐的商品、相关属性和描述性关键字等相关实体,并且应最大限度地提高对话下一个语句与用户偏好的相关性,因此采用复制机制[26]从关系图中复制与对话相关的词汇来增强语句中这些词汇的生成,计算方式为: 在给定已知词汇序列w1,w2,…,wn-1时,生成wn作为下一个词汇的概率如式(20)所示。
(20)
其中,p1表示解码器输出的词汇概率分布,p2表示在关系图R的节点上使用复制机制实现的复制概率,然后进一步设置下列交叉熵损失来训练对话模块,如式(21)所示。
(21)
其中,N表示对话的回合数,通过计算对话中每个语句sn的损失来获得对话模块的交叉熵损失。
3 实验
3.1 数据集
本文在COOKIE数据集[26]上评估模型的效果,COOKIE是一个基于Amazon Review数据集构建的对话推荐数据集,用于电子商务平台中基于知识图的对话推荐,该数据集包含四个领域,分别是手机&配件、食品、玩具&游戏以及汽车。本文需要利用用户评论记录来构建关系记忆,由于Amazon Review包含用户评论信息,并且COOKIE建立在Amazon Review的基础之上,因此根据COOKIE中的用户id在Amazon Review中找到对应的用户,然后将其评论记录加入COOKIE。对于每一个用户,都有其点击、购买行为记录,但缺少购物车行为记录。考虑到JD Recsys数据集是一个包含多种电商平台数据的大型工业数据集,具有多行为记录,于是将其用于推荐系统的训练,与COOKIE中的数据存在交叉,因此将COOKIE和JD Recsys中的用户名称与id进行匹配,从而提取到当前用户的购物车行为记录,部分用户可能无法找到对应的购物车行为记录,本文将该部分用户作为后续消融实验的数据。将数据整合后,删除缺少用户或商品属性信息的行为数据、对同一商品的重复操作和只有一个回合的对话,以确保数据集的质量。对数据集进行预处理后,得到的具体统计数据如表2所示。

表2 数据集统计
其中实体包括用户、商品及属性数量,关系表示唯一关系类型的数量,行为表示存在点击、加入购物车和购买三种行为的商品总数,三元组表示三元组数量,语句表示对话和评论语句总数。
3.2 对比方法
为了验证UMCR模型的有效性,选取序列推荐模型(传统序列推荐和结合时间尺度的序列推荐)、对话推荐模型(传统对话推荐和结合知识图的对话推荐)和对话模型进行比较,在比较整体性能的同时验证模型各模块的有效性和生成的对话质量。具体为: ①GRU4Rec[9]: 一种传统序列推荐模型; ②TiSAS[14]: 一种将注意力机制与时间尺度相结合的先进的序列推荐模型; ③PMMN[2]: 一种传统对话推荐模型; ④CR-Walker[24]: 一种利用知识图的先进的对话推荐模型; ⑤Transformer[9]: 一种传统对话模型。
3.3 评价指标
为了评估UMCR的性能,采用不同的评价指标来分别评估模型的推荐性能和对话生成质量。对于推荐性能,采用平均回合数(AT)来评估模型推荐成功所需的平均回合数,采用平均倒数排名(MRR)来评估对话n轮后推荐的准确度,分别定义如式(22)、式(23)所示。
MRR表示向用户推荐正确的商品之前用户必须浏览的预期数量,根据前10个商品计算。其中Q表示目标商品的数量,ranki表示第一个正确推荐商品的位置。
对于对话生成质量的评估,采用自动评估和人工评估两种方式。自动评估标准包括Distinctn-gram(n=2,3,4)和Item Ratio。Distinct用来衡量句子层面的多样性。由于在对话推荐中生成与商品相关的信息性回复十分重要,因此通过Item Ratio来计算生成的对话中项目的比率。自动评估指标定义如式(24)、式(25)所示。
其中,Count(uniquen-gram)表示回复中不重复的n-gram数量,Count(item)表示回复中与商品相关的实体数量,Count(word)表示回复中词语的总数量。在人工评估方面,本文邀请10名具有语言学知识的注释人员从Fluency(流利度)、Coherence(连贯性)、Informativeness(信息量)和effectiveness(有效性)四个方面对生成的对话进行评分,分数范围为1到3,将10名人员的平均分数作为最终结果。其中Fluency和Coherence侧重于对话生成质量评估,Informativeness评估模型是否引入了丰富的知识,effectiveness评估模型是否让用户成功找到心仪的商品。
3.4 实验设置
3.4.1 用户模拟器
由于对话推荐模型的交互性,它需要通过与用户对话来进行训练和评估。因此采用文献[1]中的用户模拟器,让其充当真实用户的代理,自动生成用户当前需求和对商品的自然语言反馈,该过程类似于购物客服和用户之间的购物对话场景。
3.4.2 实现细节
对于数据集中的每个领域,随机选取80%、10%和10%的数据分别作为训练、验证和测试集,采用用户模拟器与对话推荐模型交互并使用验证集在线训练模型。对于超参数的设置,用户记忆处理模块的嵌入维度和隐藏维度设置为64,R-GCN的层数为2,正则化常数设置为1。在训练中使用默认参数的Adam优化器,批量大小设置为32,学习率设置为0.001,其他超参数的设置本文一般遵循作者的建议并适当地在验证集上优化。本文从头开始训练所有模型,直到精度只有微小变化或不再提高,同时为了排除单次实验的随机性,重复训练各个模型10次,然后取平均值作为实验结果。
3.5 实验结果及分析
3.5.1 推荐性能评估
首先将回合数设置为3来对各个模型的准确性指标进行测试,均取最好的结果进行比较。不同的回合数设置下模型的性能会不同,这将在后续各节中进行分析。如表3所示,基于注意力的序列模型TiSAS的准确性明显优于基于RNN的序列模型GRU4Rec,表明注意力机制对序列建模的有效性;同时基于对话的模型的准确性高于基于非对话模型,表明通过与用户对话可以更准确地获取用户的偏好。UMCR在准确性指标上有最好的表现,比非对话模型提高了15.7%,比先进的对比模型提高了3.54%,可以推断出通过利用用户与物品之间的关系信息,并结合从用户多类型行为序列中学习到的用户潜在兴趣,可以有效提高对话推荐的准确性。

表3 推荐性能评估
其次,对各个模型的平均回合数(AT)指标进行测试,AT越小表示系统效率越高。在表3中,基于序列的推荐方法仅依赖用户历史数据,难以获取用户当前偏好,通常需要较多回合来做出令用户满意的推荐。基于对话的推荐模型通过向用户询问,可以在一定程度上加快对用户当前偏好的获取,CR-Walker相比于PMMN引入了外部知识图,从而尽量询问与当前对话中出现的项目相关的问题来减少与用户的对话回合数,但用户不太可能对外部知识图中的所有实体感兴趣,因而导致候选空间过大,因此可能需要额外的询问回合。UMCR相比于CR-Walker考虑到用户与商品及其属性之间的关系信息,在对话时可以快速定位到与用户偏好最相关的实体上,从而大幅减少图中的候选空间,因此能够以更少的对话次数完成推荐。
3.5.2 对话生成质量评估
表4和表5分别展示了不同模型对话生成质量的自动评估和人工评估结果。在自动评估结果中, PMMN相比于Transformer生成的对话中项目比率更高,因为PMMN利用预训练GRU模型对语句进行编码,并根据编码来最大限度地提高对话中相关项目的出现概率。而Transformer生成的对话具有更高的多样性,一个可能的原因是Transformer采用自注意力机制来捕捉语句中单词之间的依赖关系,此GRU更适合建模单词和项目之间的关系。其次,在基线模型中,CR-Walker生成的对话最为多样,并且项目比率最高,即生成的对话中包含更多与用户偏好相关的项目,表明利用知识图能够很好地指导信息性语言生成,从而提高项目和相关实体的出现概率。UMCR在所有评估指标上表现最好,相比于对话生成质量最好的基线模型,在Distinct和Item Ratio指标上分别平均提高了5.1%和8.3%。UMCR采用Transformer作为对话基础模块,将用户项目的关系信息注入解码器并利用复制机制,在保证对话多样性的同时增强了生成文本的信息性。
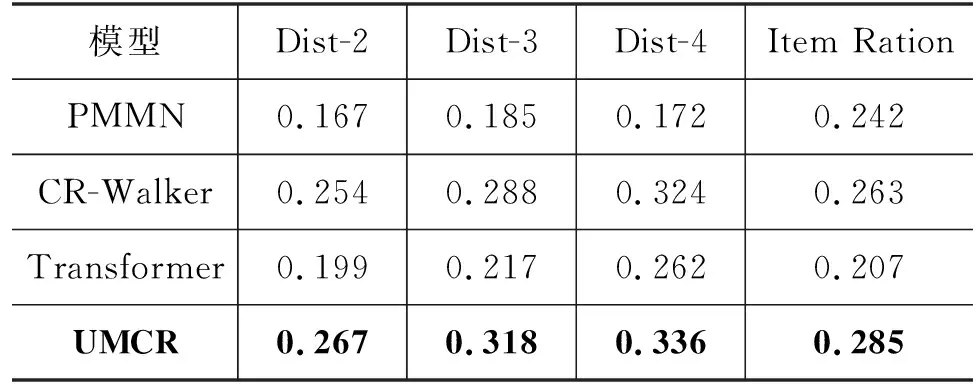
表4 对话生成质量自动评估

表5 对话生成质量人工评估
在人工评估结果中,Transformer作为对话模型具有较高的对话生成质量,但可能会产生诸如“不知道”“请再说一次”之类的安全回复,因此对话在信息量和有效性方面有所欠缺。为了提高对话的信息量与有效性,模型应有效利用用户历史记录并了解用户偏好。PMMN没有在用户偏好和对话之间建立连接,仅根据上下文进行对话生成,在信息量和有效性方面显著低于CR-Walker和UMCR。UMCR在人工评估中表现最好,其在引入外部知识图的基础上通过用户历史记录构建用户和商品之间的关系,能够更好地捕捉用户偏好,并将这些信息加入对话解码器来生成流畅连贯且信息丰富的响应,从而更有效地满足用户需求。
3.5.3 对话回合数对模型准确性的影响力分析
本文进行实验研究对话推荐模型在不同对话回合数(从0到10)下的准确性指标变化,在各个领域数据集上的实验结果如图5所示,可以看出随着对话的进行,各个模型的准确性会不断提高,并且在对话后期各模型的性能会越来越接近,这是因为模型能够从用户反馈中获取更多描述用户需求的信息,从而更准确地学习用户的偏好,并获得更高的概率来找到符合用户需求的商品。UMCR在所有数据集和对话的每一回合都表现更好,并且在对话的中间阶段,UMCR比其他模型表现更突出,即能够在较短回合达到更高的准确性。因为UMCR在对话时利用关系记忆信息更快地定位到与用户偏好相关的实体上,从而有效地减少较大的实体候选空间,因此能够以更少的对话回合做出准确的推荐。

图5 对话回合数对性能的影响
当对话回合数T=0时表示直接对初始请求进行推荐,不考虑用户的对话反馈,对话推荐模型可看作是一个搜索应答系统,UMCR能够有效利用从历史交互和对话、评论数据中获取到的用户兴趣表示进行推荐,因此在缺少用户反馈时也能保证一定的准确性。以上结果表明,相比于其他的对话推荐模型,UMCR在用户、商品和对话建模方面具有显著的优势。
3.6 消融实验
为了验证UMCR中各模块及相关技术的有效性,本文进行了广泛的消融研究。
3.6.1 用户记忆模块及相关技术有效性分析
在本节中研究用户记忆模块及记忆模块中相关技术的有效性。
(1) 用户记忆模块有效性分析
首先研究行为记忆是否能够很好地学习用户行为序列的潜在兴趣,去除UMCR的关系记忆与对话模块得到模型BMR进行推荐(可看作是序列推荐模型),然后与基线序列推荐模型对比准确性,结果如表6所示。

表6 行为记忆有效性分析
可以看出BMR取得了最好的结果,表明利用注意力机制建模用户行为序列并融合上下文信息能够很好地学习用户潜在兴趣。特别是,尽管基于注意力机制的TiSAS同样使用了上下文信息,但相比于传统的序列模型它的性能并没有显著提高,可以推断出在多头注意力中使用相同的上下文嵌入会使学习到的信息有限,阻碍了性能的提高。相比之下,BMR在每个注意力头上使用不同的上下文嵌入来学习序列的多种特征,表明这种不同上下文嵌入和注意力机制的联合设计能够更有效地对序列进行建模。
其次,研究关系记忆对于对话推荐的有效性,去除UMCR的行为记忆部分得到模型RMCR与基线对话推荐模型对比平均回合数,结果如表7所示。可以看出在成功推荐时,CR-Walker比PMMN所需的对话回合更少,表明外部知识图信息有助于增强数据表示,提高对话推荐的性能,而RMCR能够以最少的对话回合数完成推荐,相比于CR-Walker仅利用外部信息,RMCR将用户评论、对话记录中的历史偏好加入知识图来探索用户、商品及属性之间的关系信息,进一步增强了相关数据表示,从而更快地帮助用户找到合适的商品。

表7 关系记忆有效性分析
最后,研究记忆模块对模型整体的有效性,将模型BMR和RMCR与原模型UMCR对比,结果如图6所示。可以看出,UMCR在缺少关系记忆时,模型无法获取用户当前偏好,导致准确性平均下降了5.75%,并且推荐成功所需的回合数也平均增加了3.43;缺少行为记忆时,模型无法获得用户的潜在兴趣,需要额外的询问来提高对搜索结果的信心,进而导致对话回合数增加。综上,模型在缺少关系记忆时对性能的影响较大,缺少行为记忆主要影响模型的对话效率,因此两种记忆信息都有助于提高推荐的性能,使UMCR能够以最少的对话次数准确推荐。
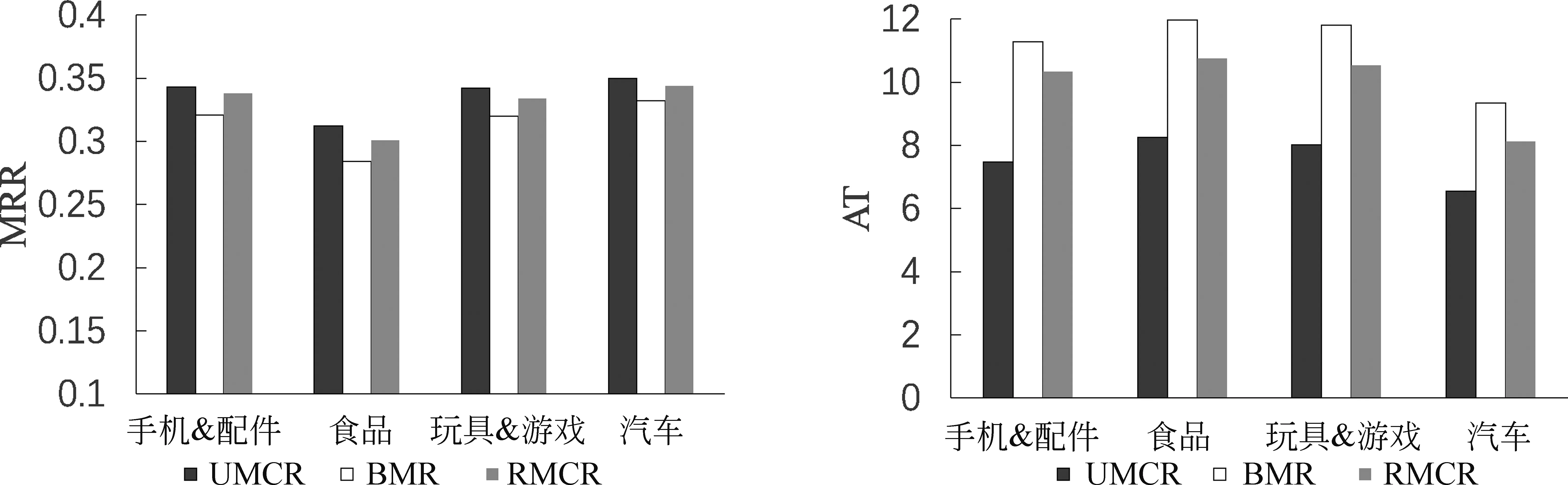
图6 记忆模块有效性分析
(2) 用户多行为序列有效性分析
为了研究建模用户多行为序列对模型性能的影响,设置了三种行为序列组合,分别是只有点击行为序列,以及点击购物车行为序列、点击和购物车和购买行为序列,然后对比不同行为序列组合下模型的准确性,结果如表8所示。可以发现同时建模点击序列和购物车序列比单独建模点击序列会获得更好的性能。然而,当进一步增加购买序列时,模型的准确性在不同领域会产生不同的变化: 在食品、玩具&游戏领域会提高准确性,但在手机&配件和汽车领域存在一定程度的下降。根据经验分析: 手机和汽车领域中的商品回购期较长,用户在购买后不会在短时间内再次购买该商品;对于回购期较短的商品(如食品、玩具),用户在购买后可能会在短时间内再次点击购买。因此在商品回购期较长的领域加入购买序列可能会干扰点击和购物车序列中的信息,从而造成准确性下降,故模型仅适合在商品回购期较短的领域加入购买序列。

表8 多行为序列有效性分析
(3) 多类型上下文嵌入有效性分析
为了研究模型在多头注意力中使用多类型上下文嵌入(时间嵌入、绝对位置嵌入、相对位置嵌入)是否有效,设置了所有可能的上下文嵌入组合,如表9所示,然后对比在不同嵌入组合下模型的准确性。结果显示,使用多类型嵌入明显比使用单一类型嵌入表示具有更好的性能,但是在不同领域的数据集中每个嵌入的重要性不同。时间嵌入和绝对位置嵌入能够捕捉序列中短时间内大量行为之间的依赖关系(如用户在同一天会多次购买食品),因此在用户产生交互更频繁的食品领域发挥更好的作用。相对位置嵌入主要捕捉序列中的周期性行为信息(如用户会周期性地更换汽车配件),从而在汽车领域做出更准确的预测。
3.6.2 推荐模块相关技术有效性分析
为了研究推荐模块中利用门控机制对两种记忆表示进行融合的有效性,设置UMCR的变体UMCR_Gate,表示移除门控融合机制直接拼接两种记忆表示进行推荐,然后与原模型对比准确性。实验结果如图7所示,可以看出原模型相比于移除了门控机制的模型,准确性平均提高了3.7%,表明门控机制可以有效地提升推荐的准确性,这是因为通过门控机制可以有效地将用户潜在兴趣与当前偏好动态结合,使模型能选择与用户当前需求最相关的信息,从而提升推荐的准确性。
3.6.3 对话模块及相关技术有效性分析
为了研究对话模块以及在对话模块中加入基于关系图的注意力层和复制机制的有效性,设置UMCR的变体UMCR_CM、UMCR_RA和UMCR_Copy进行对比实验,分别表示移除对话模块、基于关系图的注意力层RA和复制机制。首先与原模型对比平均回合数,实验结果如图8左图所示。当移除对话模块后,模型可看作是静态推荐系统,无法通过对话获取用户实时偏好,仅仅通过用户历史记录进行推荐,成功推荐所需要的回合数大大增加,表明对话推荐相比于静态推荐的优越性。另一方面,当移除RA和复制机制后同样会增加推荐成功时所需的回合数,平均增加了3.1个回合,这是因为基于关系图的注意力层能够通过多头注意力机制将关系记忆信息有效地融入解码器,复制机制能够增强相关实体的生成,两者都有利于生成与用户偏好更相关的对话,从而有效提高对话的效率。
其次,与原模型对比对话生成质量,实验结果如图8右图所示。可以看出对话模块中的基于关系图的注意力层RA和复制机制都有助于提高对话生成质量,并且RA更为重要,移除后会显著降低对话质量。基于关系图的注意力层通过多头自注意力可以有效地将融合后的关系图信息注入解码器,进而提高对话文本的多样性与信息量。
4 结论
本文提出了基于用户记忆的对话推荐模型UMCR,通过关系记忆学习用户、商品和属性之间的关系信息,根据学习到的信息来更好地生成对话,并结合从用户行为记忆中挖掘到的用户潜在兴趣做出更准确的推荐。通过构建大量实验,UMCR相较于对比模型具有更好的性能,能够以更少的对话次数准确推荐。
未来的工作中,我们将考虑融入更丰富的语义信息和对商品属性的不同看法来生成更多样化的对话,并适当地处理意外的用户响应。
