面向司法领域的藏文事件数据集构建
2023-10-25赵小兵
高 璐,赵小兵
(1. 中央民族大学 中国少数民族语言文学学院,北京 100081;2. 邯郸学院 软件学院,河北 邯郸 056005;3. 中央民族大学 信息工程学院,北京 100081;4. 国家语言资源监测与研究少数民族语言中心,北京 100081)
0 引言
事件信息是司法案情的核心,司法事件抽取旨在识别司法案件中的多维事件要素,辅助司法工作者快速重构案件事实画像,厘清争议焦点,疏通司法痛点、堵点、难点问题,为类案推送、量刑辅助、偏离预警、判决结果预测等下游司法任务提供技术支持。图1为某司法文书陈述片段(1)西藏自治区类乌齐县人民法院刑事判决书,(2022)藏0323刑初1号,通过撬开、潜入、盗取、挥霍、鉴定、扣押等一连串事件及其要素,重塑盗窃场景,助力法官全过程研讨案情,掌握案件脉络,以便对犯罪嫌疑人的各种行为及其程度进行量化,并根据现有法律标准对其进行处罚,为司法工作赋能增效。
截至2022年12月17日,中国裁判文书网(2)中国裁判文书网,https://wenshu.court.gov.cn公开的文书总量已达1.37亿篇,访问总量近千亿人次,日均新增裁判文书10万多篇;双语审判工作进一步推进,蒙古语、藏语、维吾尔语、朝鲜语和哈萨克语等民族语言裁判文书体量呈上升趋势,满足了各族群众多层次、多样化的司法需求。以西藏为例,部分西藏基层80%左右的案件审理会用到藏语,涉及案件立案、审判、执行、文书制作等环节[1]。截至2022年12月,藏文裁判文书累计公开上网 11 685 篇,涉及刑事、民事、行政、赔偿、执行等多种案件类型,保障了藏族群众在诉前、诉中、诉后各个阶段的监督权、知情权、参与权,最大限度消除了当事人的诉讼不便及信息不对称,提高了人民群众的获得感和满意度。
借助海量公开的中文裁判文书,Yao Feng[2]等构建了一个大规模的中文法律事件检测数据集LEVEN(3)LEVEN, https://github.com/thunlp/LEVEN,包括8 116份法律文件、108个事件类型、150 977个人工注释的事件提及(4)事件提及是指描述一个事件的短语或句子。中国法律智能技术评测(CAIL2022)(5)CAIL2022, http://cail.cipsc.org.cn/新增事件检测赛道,以LEVEN数据集为基础,提供基于BERT的深度学习模型作为基线,极大促进了中文法律事件检测技术的提升。近年来,藏文裁判文书呈现数据量丰富、公开率高、案件种类多、实时性强等特点。然而,相较于中文,其蕴含的大量案由、案件事实、争议焦点、法律适用等有价值的数据资源有待充分挖掘,藏文司法事件抽取技术面临以下资源挑战。
数据欠缺目前缺乏公开的藏文司法事件数据集,无法提供足量的训练信号,建立统一的技术评测更是无从谈起,直接限制了深度学习等技术在藏文司法事件抽取方面的探索与优化。迫切需要构建高质量的藏文司法事件数据集,并以此为基准,推动藏文司法事件抽取技术的评测与发展。
事件模式不相容ACE2005制定了面向通用领域的事件Schema体系,其定义了8大类33小类的事件类型,DuEE构建的事件类型甚至高达65种。但上述成熟的事件Schema体系无法直接应用到藏文司法领域,原因有二: ①覆盖度低。通用领域预定义的事件知识无法覆盖真实的藏文司法文本,部分事件类型出现频次较低甚至从未出现过; ②刻画粒度粗糙。司法数据中的案件要素更加注重司法业务相关的属性,刻画的粒度更小、更细[3]。如“盗窃”事件涉及“盗窃者”“被盗人”“盗窃赃物”“盗窃地点”“盗窃时间”“盗窃金额”等事件要素,而非通用领域泛指的“人物”“地点”“时间”等命名实体信息。需要构建契合藏文司法文本的事件模式,满足藏文司法事件抽取的实际需要。
鉴于上述问题,本文面向藏文司法领域,以中国裁判文书网公布的藏文裁判文书为研究对象,通过深入挖掘案件描述信息,探索事件、人员、财物、外部信息等数据要素之间的关联关系,以半自动的方式构建了面向司法领域的藏文事件数据集TiEvent,以期探寻事件抽取技术在藏文司法智能领域应用的深度和广度。本文的贡献主要包括以下三点:
(1) 设计了“类别分组-主题建模”两阶段的契合藏文司法领域的事件模式。受ACE2005、DuEE等事件Schema构建理论启发,借助LDA主题建模技术,制定了藏文司法领域事件Schema体系,以更好地指导藏文司法事件数据标注工作。
(2) 采用模型驱动的事件触发词预标注与事件要素人工标注相结合的半自动化数据标注方式,构建了藏文司法事件数据集TiEvent。TiEvent共定义了3个大类、12个小类的事件类型,涉及1 863篇藏文刑事裁判文书、2 249个人工标注的事件提及。这可能是目前已知的首个藏文司法事件数据集。
(3) 对数据集进行了全面评估。搭建了BiLSTM、BiLSTM-CRF、CINO-CRF等事件抽取框架,并在该数据集上进行全要素、多维度质量评估。实验表明,在藏文司法文本上,TiEvent具有较高的事件覆盖度和事件要素完整度,能够满足藏文司法事件抽取工作的基本需要。
1 相关研究
1.1 事件数据集
随着事件抽取技术从特征工程到神经网络模型的转变,有关事件抽取的数据集也愈加丰富和多样化。就领域而言,ACE2005[4]、TAC-KBP[5-7]、MAVEN[8]、DuEE1.0[9]等数据集具有良好的事件类型覆盖度,为通用事件抽取技术统一评测提供了数据基准。然而,通用领域数据集包含的事件知识(事件类型、词汇形式、句子结构等)与特定领域具有实质性差异,因此很多研究者转而基于特定领域文本构建相应的数据集,如CASIE[10]、CySecED[11]面向网络安全领域,DuEE-Fin[12]面向金融领域,CEC(6)https://github.com/shijiebei2009/CEC-Corpus面向突发事件领域,LEVEN、CLEE[13]面向法律领域等。就语种而言,MAVEN、DuEE1.0、CASIE、LEVEN等均为单语数据集,也有研究人员构建多语数据集,对多语言事件模型进行了全面评估,如ACE2005、TAC-KBP均包含3种语言(7)ACE2005包括英语、中文、阿拉伯语3种语言;TAC-KBP包含英语、中文、西班牙语3种语言。,TempEval-2[14]包含6种语言(8)6种语言为中文、英语、法语、意大利语、韩语和西班牙语。,MINION[15]包含8种语言(9)8种语言为英语、西班牙语、葡萄牙语、波兰语、土耳其语、印地语、日语和韩语。等。
1.2 事件抽取技术评测
“以赛促研”是目前技术突破的主流渠道,事件抽取技术近几十年取得的进步与MUC[16]、ACE、TAC-KBP、TDT、TERQAS、BioNLP[17-19]等各个国际评测会议的推动密不可分。语言与智能技术竞赛连续三届(2019—2021)(10)http://lic2021.ccf.org.cn/涉及事件抽取任务,设置了丰富的数据集合和评测维度;CCKS(11)全国知识图谱与语义计算大会(China Conference on Know ledge Graph and Semantic Computing,CCKS)评测同样开辟了面向医疗、通信、金融等各个领域的事件抽取任务赛道,从准确性、鲁棒性和泛化性等多角度对中文事件抽取效果进行综合评价。司法领域方面,中国法律智能技术评测(Challenge of AI in Law, CAIL)在最高人民法院和中国中文信息学会的指导下已顺利举办五届,提供大量标签化的法律文本作为数据集,先后吸引了来自海内外高校和企业组织的近 5 000支队伍参赛,成为中国法律智能技术评测的重要平台。CAIL 2022年首次将事件检测纳入赛道,除此之外,还开辟了司法考试、文书校对、类案检索、涉法舆情摘要、论辩理解、信息抽取、可解释类案匹配等7个赛道,任务设置更贴合现实世界中的法律环境痛点。
2 事件Schema制定
本文结合藏文司法数据的实际特点,设计了“类别分组-主题建模”两阶段的事件层级体系;同时参照ACE框架,针对某类事件,对该事件类型下对应的事件论元进行人工约束,最终完成事件及其要素的完整定义。
2.1 事件类型确定
类别分组对1 863篇藏文刑事裁判文书(12)数据来源参见3.1。进行类别分组,经统计,文书类别主要围绕危害公共安全罪、侵犯财产罪、侵犯公民人身权利罪、扰乱公共秩序罪等刑事案件展开,其中涉及盗窃罪的文书620篇,占总文书的30%左右(13)盗窃罪属于侵犯财产罪之一。。为了确保事件类型在真实文书中有更多的事件提及,剔除比例较少的扰乱公共秩序等类别,最终确定的事件类别为危害公共安全、侵犯财产、侵犯公民人身权利,并对1 863篇文书分门别类。
主题建模首先对原始文本完成分词、停用词处理等数据清洗操作,其中分词器的选择,本文在李亚超开源的TIP-LAS[20]基础上,充分利用第二届少数民族语言分词技术评测提供的2万句藏文分词语料[21]进行训练,得到了较好的藏文分词效果。然后利用开源第三方Python工具包Gensim(14)https://pypi.org/project/gensim/提供的LDA模型处理接口,对三个类别文书内容分别进行主题建模,得到各个类别的主题表示和所属主题概率。根据主题建模结果,对主题词进行过滤、归一与抽象。最终确定的事件类型为盗窃、藏匿、诈骗、抓捕、鉴定、倒卖、购买、死亡、醉酒驾驶、故意伤害、交通肇事、抢劫等12个事件类型。
“类别分组-主题建模”两阶段的事件类型层级体系构建流程如图2所示。
2.2 事件论元确定
对于每个事件类型,遵循ACE2005框架体系,由法学院专业人士人工确定对应的事件论元及论元限定类型。在确保事件要素在真实文本覆盖度的同时,维护事件Schema体系的专业性。以“盗窃”事件为例,各事件要素限定类型如表1所示。

表1 “盗窃”事件要素及其限定类型
最终的事件类型及其论元如表2所示。
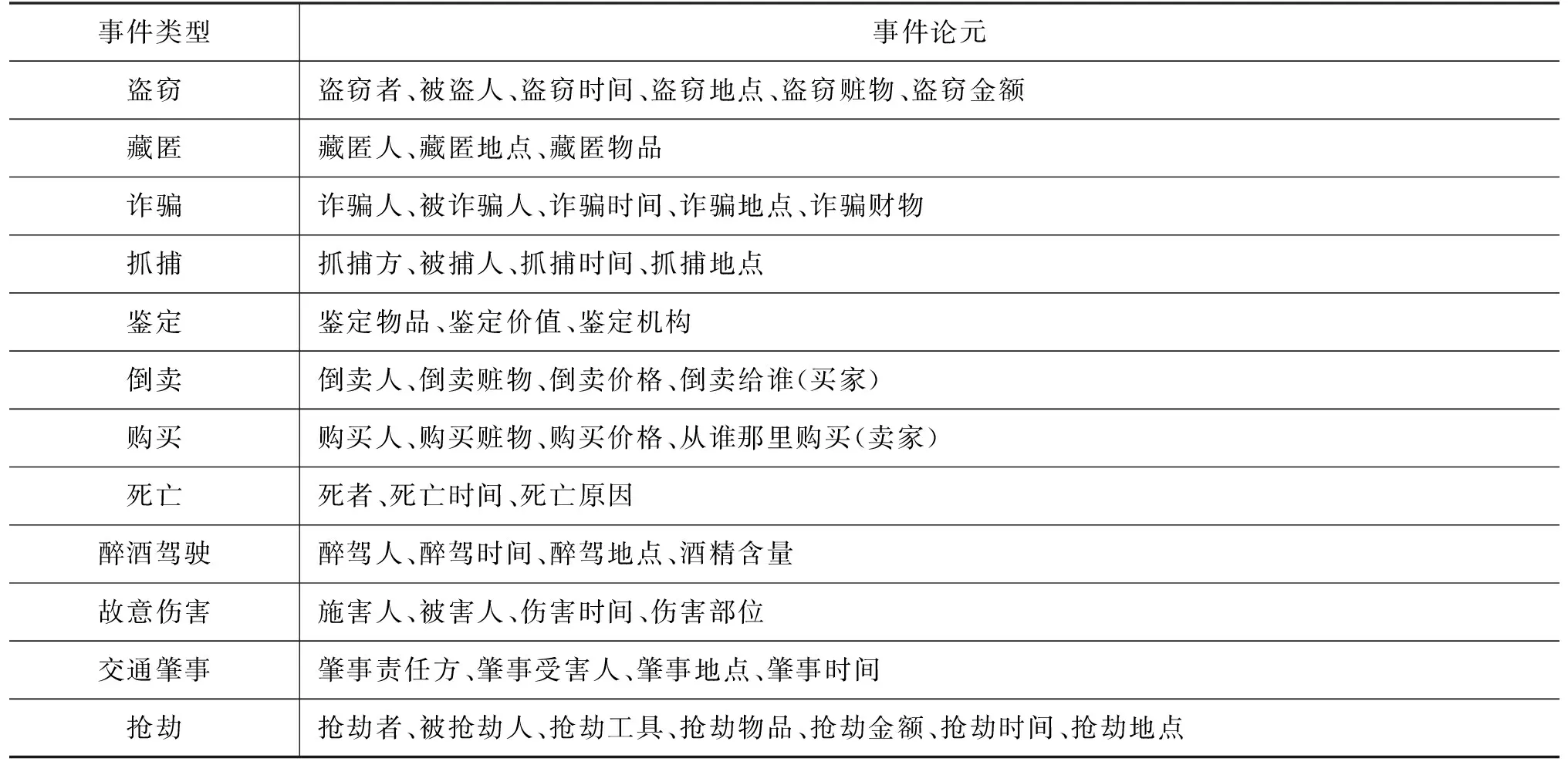
表2 事件类型及论元
3 构建方法
数据集TiEvent构建包含事件Schema制定、数据处理、事件核心词预标注、事件要素人工标注四个阶段,构建流程见图3。其中事件Schema制定在第2节已详细阐述,下面重点阐述其余部分。

图3 TiEvent构建流程
3.1 数据来源
本文以中国裁判文书网公开的藏文裁判文书为原始文档来源。藏文文书栏目共包含刑事、民事、行政、赔偿、执行等多种案件类型,但没有分门别类,所有文书糅杂在一起。本文穷尽式爬取藏文全量文书11 685篇(截止2022年12月),由于数据量较大,考虑网站响应负载与反爬机制,数据采集策略为:
(1) 将11 685篇全量文书对应的ID、Title、Court、Link、Time等信息爬取并存储在本地;
(2) 编写Shell脚本批量下载Link对应的PDF文书,并按照对应ID进行命名;
(3) 根据文书Title筛选出刑事类文书1 863篇。
整个数据采集流程如图4所示。
3.2 数据清洗
由于下载的藏文文书均为PDF文件,不能直接使用,需要进行一定的预处理:
(1)OCR识别利用西藏大学的开源系统(15)http://bmfx.utibet.edu.cn/socr.fds进行OCR识别,由于该系统仅支持对图片的处理,故首先将所有的PDF文件批量转为JPEG,再进行OCR识别。
(2)人工降噪OCR系统对藏文字符识别准确率较高,但对于阿拉伯数字、部分特殊字符的识别稍有偏差,因此本文对系统识别噪声较大的文字、数字、特殊符号等进行人工降噪,并将校准后的正确内容转储为TXT文本文件,方便后续标注及处理。
(3)关键内容摘录根据任务需求,本文将司法文本中的案例描述、被告及证人陈述内容摘录出来,作为我们数据集标注的初始语料文本。
3.3 标注平台及理念
本文采用开源标注平台DoTAT(16)https://github.com/FXLP/MarkTool进行多人协同标注[22]。标注过程遵循MATTER理念[23](图5),依照“生成数据集、模型训练与测试、问题数据分析、更新策略、重新生成数据集”的轮次不断迭代。在迭代的早期,尽量使得基线在数据集上正常收敛;在迭代的中期,重点关注基线在开发集上的表现,留意数据泄露问题;在迭代的后期,更多关注问题数据。通过验证可用性,尽早实现数据集迭代闭环。
3.4 事件核心词预标注
数据标注采用半自动化方式进行,分为事件核心词预标注和事件要素人工标注两个环节。事件核心词预标注即事件触发词的定位,采用基于预训练模型CINO-CRF驱动的方式自动进行事件触发词检测(图6),其中CINO层获得输入上下文的语义特征,CRF层习得状态序列的关系,解码并计算最优的序列标注,最终完成事件核心词预标注。这种自动的事件核心词标注方法一方面能够提升标注效率,另一方面将包含相应事件的事件句筛选出来,为每个事件类型生成对应的待标注集,降低无效句子干扰。然而,模型预标注的准确率并不高,对于模型预标注结果,需要人工介入进行二次审查。
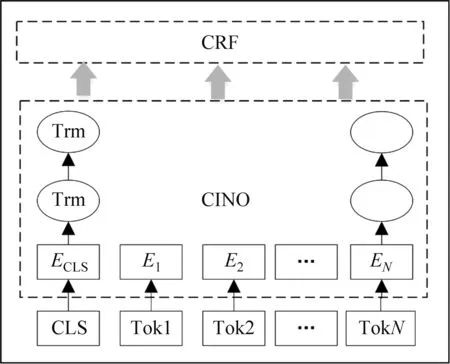
图6 基于CINO-CRF的事件核心词预标注
3.5 事件要素人工标注
事件要素标注即确定事件论元,并为每个提取的论元分配特定的论元角色,采用人工方式进行,标注流程如图7所示。

图7 事件要素人工标注流程
培训我们从法学院邀请母语人士,包括两名标注人员和1名审核人员,进行标注指南解读以及DoTAT标注平台操作培训。
标注每个文本分别指派给两名注释者独立标注,标注者需人工审查上一环节模型自动标注的事件触发词及其对应的事件类型。由于事件类型一旦确定,所有待标注的论元角色会被自动确认,因此,要求标注者提取事件论元,并以类似的方式为每个提取的论元分配特定的论元角色。根据标注指南定义,对于预定义的事件类型,其触发词是必须的,但事件论元可缺省。另外,一个事件论元可以在同一文本中扮演不同的角色,多个事件论元也可以分配给同一个论元角色。整个标注过程一旦存疑,随时翻阅标注平台里嵌入的标注指南,防止标注漂移。
审核根据标注指南,每个文本被独立注释两次,两次的标注会产生结果完全一致、部分一致、完全不一致三种可能性,审核人员需要对两次标注结果进行一致性检验、手动合并和调整,得到黄金标注数据。
迭代数据集构建并非一蹴而就,需要进行多次迭代。依据各阶段迭代目标,对数据集的测试结果进行错误分析,回溯模式设计阶段,不断地更新标注策略,校正和丰富数据集。
以“醉酒驾驶”事件为例,标注样例如图8所示。
4 数据集分析
4.1 数据集大小
TiEvent共定义了3个大类、12个小类的事件类型,涉及1 863篇藏文刑事文档、63个事件要素(此处包含事件触发词,后面同理),和2 249个人工标注的事件提及,平均每个文本包含事件提及1.2个,是目前已知的首个藏文司法事件数据集。
4.2 数据集分布
本文进一步分析了事件类型和论元角色的数据分布,结果分别如图9、图10所示。部分事件类型由于文书篇数较少,在Schema规划初期就已排除在外,因此,本数据集涉及的事件类型分布较为均衡,即使数量最少的“购买”事件,也包含42个事件提及。然而,事件论元分布情况较为复杂: ①各事件类型包含不定数目的事件论元, 如“鉴定”事件包含3个事件论元,而“抢劫”类事件则包含多达7个事件论元,经分析,每个事件类型平均包含5个事件论元。②部分论元事件提及偏少,长尾现象严重,如在“抢劫”事件中,每个文本都会涉及“抢劫者”“抢劫物品”等事件要素,但“抢劫工具”“抢劫金额”却不一定存在,事件本身的特性决定了论元的稀疏性。
总体而言,TiEvent面向藏文真实司法文本,涵盖12种事件类型和63个事件要素,标注较为全面,一定程度上可以满足藏文司法事件抽取任务的需求。
5 实验
5.1 实验设置
本文按照8∶1∶1将数据集随机划分为训练集、验证集和测试集,采用宏平均的精确率、召回率和F1得分作为实验的评估指标。
5.2 基线
本文选择了几种成熟通用的基线模型,从多个维度对数据集进行全面评估,包括: ①BiLSTM: 利用双向LSTM作为特征提取器; ②BiLSTM-CRF: 引入CRF,在双向LSTM建模的输出端,添加可依赖的约束; ③mBERT: 利用mBERT进行上下文语义表征及参数微调; ④mBERT-CRF: 在mBERT的输出端,添加CRF进行语义约束; ⑤CINO: 利用CINO进行特征提取及参数微调[24]; ⑥CINO-CRF: 在CINO输出端,添加CRF进行语义约束。
5.3 实验结果
由表3、表4可知,从横向抽取阶段来看,事件触发词检测效果(F1最高75.36%)明显优于论元识别(F1最高70.98%)。产生这种结果的原因可能是: 事件触发词是必须的,每一个事件提及至少伴随着一个事件的产生(即触发词的出现),触发词分布均衡且覆盖度大;而事件论元的分布差异明显,部分论元数量少,如论元“伤害部位”仅涉及16个事件提及,无法提供足量稳定的训练特征,影响了论元识别整体效果,这也从侧面论证了数据集数据分布(4.2节)情况。因此,对于部分稀疏论元,需要进行数据增广,改善事件论元分布现状,优化论元识别效果。

表3 触发词检测 (单位: %)
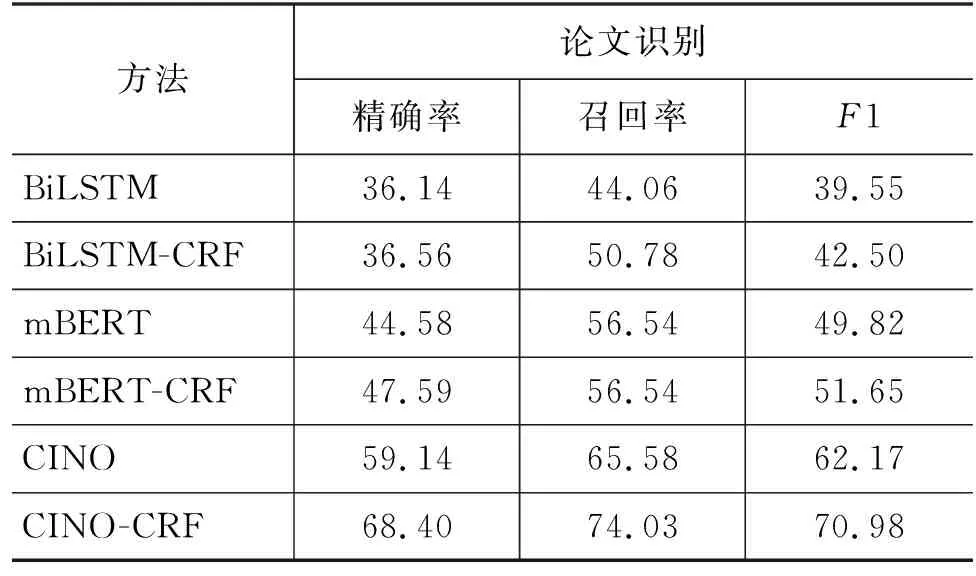
表4 论元识别 (单位: %)
从纵向模型结构来看,无论在事件触发词检测阶段还是论元识别阶段,CRF结构对抽取效果都有一定提升。此外,通过BiLSTM-CRF、mBERT-CRF、CINO-CRF三个模型对比可知,由于数据集规模有限,提供的训练特征不足,BiLSTM没能获取有效的训练信号,F1_AVG(17)F1_AVG为Trigger Detection和Argument Recognition的F1平均值。仅40.25%;mBERT虽为多语言预训练模型,但其训练语料不包含藏语,提供的多语言语义信息虽有价值,但优势并不明显;CINO 是HFL发布的首个面向少数民族语言的多语言预训练模型,提供了藏语、蒙古语、维吾尔语、哈萨克语、朝鲜语、壮语、粤语等少数民族语言与汉语方言的理解能力,弥补了低资源语言数据规模带来的语义限制,提升了藏文事件抽取技术的效果,其F1_AVG高达73.17%。不可否认的是,目前藏文司法事件数据集的质量和规模与高资源语言相比仍有很大差距,需要进一步迭代完善。
5.4 错误分析
我们对表现最佳的CINO-CRF模型的测试结果进行了错误分析与总结,方便后期数据优化迭代。通过分析发现,错误主要集中在论元角色重叠和论元跨句两种类型,具体分析如下:


表5 错误分析

6 结论
本文面向藏文司法领域,对1 863篇藏文刑事裁判文书进行爬取、整理、降噪、分析、标注,制定了契合藏文司法实际的事件Schema体系,构建了首个开源的藏文司法事件数据集TiEvent。该数据集标注了12种事件类型和63个事件要素,涵盖1 863个藏文真实司法文本的2 249个事件提及。与此同时,本文评估了几种成熟基线模型在TiEvent上的测试结果并进行了误差分析。实验结果表明,该数据集标注较为全面,能够为藏文司法事件抽取技术的统一评测提供基准,为藏文司法领域的下游任务提供基础。相对于中英文等高资源语言,其规模和质量需进一步优化迭代。
