基于预训练语言模型的繁体古文自动句读研究
2023-10-25唐雪梅陈雨航
唐雪梅, 苏 祺, 王 军,4, 陈雨航, 杨 浩
(1. 北京大学 信息管理系,北京 100871; 2. 北京大学数字人文研究中心,北京 100871;3. 北京大学 外国语学院,北京 100871; 4. 北京大学 人工智能研究院, 北京100871)
0 引言
中华文明历史悠久,古典文籍浩如烟海。古籍具有极高的文献价值和学术价值,古籍整理是连接现代和历史的桥梁,有利于民族文化的传承和研究。而古人在著书时一般不使用标点,现存的许多古籍也没有断句和标点,这给读者阅读学习和学者研究古籍造成了障碍。所谓 “凡训蒙,须讲究,详训诂,明句读”,即是说句读是古人求学问道的基础。传统的古籍句读工作主要依靠人工,但人工句读对标注者的古汉语素养要求较高,一般人难以胜任。且中国古代典籍数量众多,人工句读效率低,短时间内无法完成批量典籍的句读工作。计算机自动句读可以有效地解决以上两个问题。古文自动句读是指根据古代汉语句子特点,结合现代汉语的标点符号用法,让计算机自动切割、断开连续的文本字符序列为句,然后加标点的过程[1]。
古文自动句读经历30多年的发展,从基于规则的方法逐渐发展到基于深度学习的方法。由于目前没有公开的大规模的繁体古文语料库,且整理过的古籍散落在不同的语料库或者出版社数据库,难以收集到大量整理过的繁体古籍文本,所以目前古文自动断句的研究基本都是针对简体汉字文本,如王博立[2]、胡韧奋[3]、俞敬松[4]等人的研究。而现存很多未被整理的古籍都是繁体汉字,若将繁体转为简体再做句读,繁简转化的错误可能会延续到句读的结果中。同时现在常用在古籍任务中的预训练语言模型[5-6]都有固定的词表,词表中包含的繁体字较少,在词表之外的繁体字会被替换成特殊字符,造成语义的缺失,会影响任务效果。因此构建一个专门用于繁体古文的句读模型是有必要的。断句之后的古籍文本方便阅读研究,标点之后的文本有助于整理出版,现有研究较多集中在自动断句[3,7],俞敬松等[4]虽然同时关注自动断句和自动标点,但用于自动标点的训练语料规模较小,且标点效果并不理想;释贤超等[8]在不同朝代的不同类型语料上进行自动标点研究,但其模型泛化能力有限。另一方面未经整理的古籍文本篇幅较长,整篇文章连成整体居多,篇章级句读是应用环境下必须解决的问题。现有的研究较少涉及篇章级断句,胡轫奋等[3]的断句模型以段落为单位,俞敬松等[4]提出以串行滑动窗口方式处理长文本句读,但是该方法的句读效率较低。
本文的主要工作有以下三项:
(1) 本文整理了约10亿字的繁体古文语料,基于整理的语料增量训练BERT[5]模型得到繁体古文预训练语言模型;
(2) 基于繁体古文预训练语言模型,利用高质量带标点繁体古文语料微调预训练语言模型,实现繁体古文的自动句读和自动标点;
(3) 基于前人的工作,本文改进数据串行滑动窗口方式进行篇章级句读,在一定程上提高了运行效率;同时本文提出了一种数据并行的滑动窗口方案,不仅保证了自动句读的准确率,而且大幅度提高了篇章级句读的运行速率。
1 相关研究
古文自动句读的研究大致经历了三个发展阶段,分别是基于规则的阶段、基于统计方法的阶段以及基于深度学习的阶段。
黄建年等[9]总结农业古籍的断句标点规则,包括句法特征、词法特征、引文特征等,利用规则在农业古籍上进行测试,断句的准确率为48%。基于规则的方法简单、易于理解,但是需要专家建立规则库,不仅费时费力,且规则的覆盖面有限,只能用于处理小规模文本。
陈天莹等[10]采用基于上下文的N-gram模型对古文做句子切分,在《论语》上达到了81%的召回率、52%的准确率。后续逐渐有学者将序列标注算法应用到自动断句任务中,黄瀚萱[11]比较了基于字的条件随机场模型(Conditional Random Field,CRF)和隐马尔可夫(Hidden Markou Model,HMM)模型在《孟子》《论语》上的断句效果,发现CRF模型优于HMM。张开旭等[12]在CRF的基础上引入互信息和t-测试差,在《论语》和《史记》上训练断句任务,分别取得了0.762和 0.682的F1值。张合等[13]基于六字位标记集,采用层叠CRF对《老子》《水经注》《战国策》《左传》《赤壁赋》《出师表》等进行断句和标点,低层CRF模型用于识别句子边界,高层CRF模型用于自动标点。基于统计的方法主要依靠人工特征模板,但是古籍文体风格多样,年代跨度大,很难构建一个适用于所有古籍的断句模板,从而导致统计模型的泛化能力较弱。
随着深度学习在自然语言处理领域的应用,陆续有学者将深度学习方法用于自动句读任务。循环神经网络具有时序性结构,相比于卷积神经网络能够更好地处理长文本,常用于序列标注任务。王博立[2]在2.37亿字规模的训练集上训练双向GRU (Gate Recurrent Unit)模型,该模型在古文上的断句F1值达75%。释贤超等[8]在南北朝、隋、唐、宋、辽和明六个朝代的佛、道和儒典籍上比较了长短时记忆网络(Long Short-Term Memory, LSTM)和卷积神经网络(Convolutional Neural Network, CNN)的标点效果,实验表明,LSTM的标点效果好于CNN,在唐代的语料上标点可以达到94.3%的准确率。古文分词需要建立在断句的基础之上,分步进行容易造成错误多级扩散,程宁等[7]设计了断句、分词及词性一体化标注方法,利用Bi-LSTM模型同时训练断句、分词和词性标注三项任务,发现一体化标注方法在三个任务上的F1值均有提升。
2018年谷歌提出了预训练语言模型BERT,通过精调在11项自然语言处理任务上的效果超过了之前的模型,自此古文句读模型也逐渐转向使用预训练语言模型阶段。俞敬松等[4]利用3亿7 000万殆知阁古文语料对BERT语言模型做断句和标点训练,分别在单一类别文本和复合文本上测试断句,达到了89.97%和91.67%的F1值。在单一文本上测试,标点F1值达到了70.4%。胡韧奋等[3]基于33亿字古汉语语料训练了古文BERT模型,并比较了BERT+FCL、BERT+CRF、BERT+CNN等序列标注方法在古文断句任务上的表现,发现BERT+CNN模型在诗、词及古文三种文体上自动断句效果最好,分别达到了99%、95%、92%的F1值。
以上研究已经在自动断句任务上取得了较好的结果,但自动标点的效果还有待提升,并且对篇章级长文本的自动句读关注较少。受前人研究启发,本文试图将BERT模型用于繁体古文自动句读,但由于谷歌发布的中文BERT模型是基于简体现代汉语语料训练得到的,并不一定能够很好地表示古文语义,本文利用大规模繁体古文语料对BERT中文模型进行增量训练,使其得到更好的繁体古文语义表示,然后再进行自动断句和自动标点训练。在实际的生产环境下,很多需整理的古籍的篇幅都较长,本文改进了数据串行滑动窗口方式并提出数据并行滑动窗口方式,能够同时解决篇章级自动句读准确率低和效率低的问题。
2 模型构建
预训练语言模型BERT的使用包括增量训练和微调两个阶段,以下分别介绍BERT模型增量训练过程和自动句读标点实验设置。
2.1 增量训练BERT模型
BERT由多层Transformer构成,具有强大的语义表示能力。与传统的静态词向量不同,BERT能根据上下文生成动态的词向量,即同一个词在不同语境中会有不同的向量表示。BERT的训练过程是无监督的,能够自动从大量无标注语料中学习到字词和句子的语义表示。
本文从不同渠道收集大量繁体古文语料,包括诗歌、小说、骈文、论文等各类文体,内容包含经史子集、佛经等,文献分布年代广泛,包含从先秦至清朝的文献。经人工清洗整理,最后得到了约10亿字的带标点繁体古文语料。统计整理的语料得到的繁体字表有7万字左右(包括各类异体字、古今字),BERT中文模型(以下称BERTbase)有固定词表,其中仅包含7 321个汉字,覆盖率不到十分之一,如果直接使用BERTbase,会使得很多繁体字在任务过程中被替换成UNK,造成语义不完整,从而影响自动句读任务的效果。因此本文在进行增量训练之前,对整理得到的字表中的古今字、异体字去重,并在整理得到的字表中选择部分高频字替换掉原来词表中的部分简体字。基于新的词表和训练语料对12层BERTbase进行增量训练。根据BERTbase模型预训练步骤将增量训练分为三个阶段,每个阶段训练参数如表1所示。
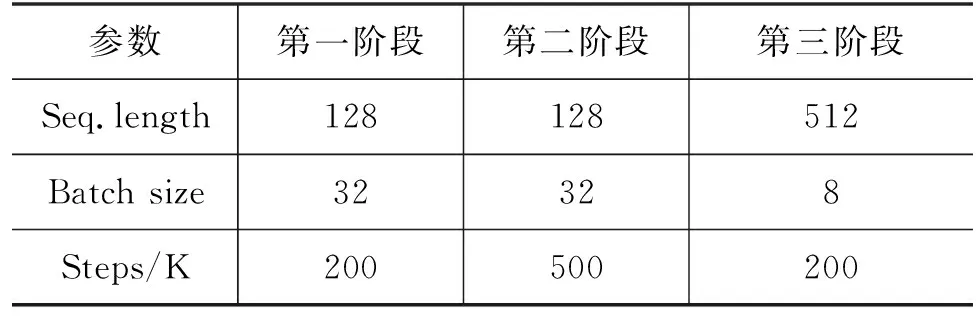
表1 BERT增量训练三个阶段参数设置
因为更换了词表,原来的Embedding层对应于原来的词表,因此在第一阶段,只更新Embedding层参数,使之和新的词表对应。第二阶段用于学习古汉语知识,因此训练步骤为500K,比第一阶段和第三阶段训练步骤更多,使其有更多时间学习古汉语表示,在第二阶段时更新模型的所有参数。在前两个阶段中,将Sequence Length设为128,在第三阶段将其设为512,因为第三阶段用于学习长距离语义关系,据BERT研发者回应,长距离的语义关系比较容易学习到,因此只需进行较少步骤的学习。经过三个阶段的学习,最后得到增量繁体古文BERT模型,以下称BERTguwen。实验设备为两块32 GB的TESLAV100 显卡,训练时间为7天左右。
2.2 自动句读模型
预训练模型可以通过微调迭代调整为适合当前任务的模型,本文将自动句读和标点当作是预训练模型下游的序列标注任务。
2001年Lafferty等人提出的条件随机场模型(CRF)是一种无向图模型,在词性标注、命名实体识别等序列标注任务中表现优异。虽然现在深度学习模型也可以很好地解决序列标注问题,但是增加CRF作为解码层似乎效果更好。如Huang等[14]在做命名实体识别任务时考虑到标签前后的依赖性,在Bi-LSTM后接CRF层作为解码层,发现增加CRF层会比单独使用深度学习模型效果更好。因此,本文也将CRF作为模型的最后一层,通过其学习标签之间的关系,找到全局最优的标签序列。
CNN是一种前馈神经网络,可以在大量数据中识别序列的局部特征,并将它们生成为固定大小的向量表示,捕捉对当前任务最有效的特征。我们在BERTguwen后接CNN层和全连接层,在BERTguwen的基础上对句子的上下文做进一步编码,捕捉局部特征。BERTguwen+CRF/CNN模型如图1所示。
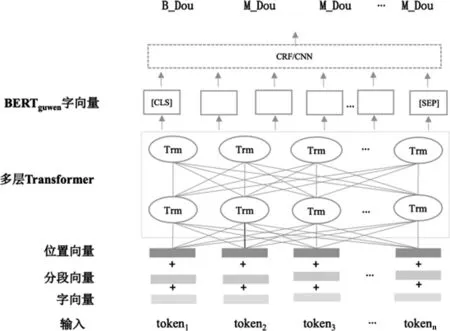
图1 BERTguwen+CRF/CNN模型图
3 实验
3.1 数据集
本文以学衡网(1)http://core.xueheng.net/200本核心典籍和github(2)https://github.com/jackeyGao/chinese-poetry公开的全中华古诗词数据库中的30多万首诗作为实验语料,两部分皆经过人工整理,都是繁体汉字,且标点质量比较高。语料具体统计信息如表2所示,虽然最大句长超过万字,但统计发现97%的句长都在200字以内。我们将数据集按照句子数8∶1∶1切分为训练集、测试集和验证集。为了让模型能处理较长文本,我们随机将同一段落中的3~10个句子合并作为一条训练数据。本文选用二元标签BM进行断句数据标注,在二元标签基础上设计断句和标点联合标注标签。“B”表示对应的字符在句首,“M”表示对应字符在句中或句尾。“Dou”“J”“Dun”“F”“M”“W”“G”分别表示该句以逗号、句号、顿号、分号、冒号、问号、感叹号结尾。

表2 数据集统计信息
3.2 实验设置
BiLSTM-CRF模型是经典的序列标注模型[14],本文将该模型作为基准模型,将BiLSTM的隐藏元数量设为256,词向量维度设为300。俞敬松等人[4]和胡韧奋等人[3]的古文句读和标点研究非常具有代表性,因此本文也将他们的模型作为基准模型。本文比较BERTguwen+CRF、BERTbase+CRF、BERTguwen+CNN、BERTbase+CNN模型在句读和标点任务上的表现,Sequence Length设为300,Batch Size设为32。实验在两块32 GB的Tesla V100 GPU上进行,每个模型训练到收敛为止。
3.3 断句实验结果
为检验不同模型在断句任务上的性能,本文使用精确率(Precision)、召回率(Recall)和F1(F1-score)作为评价指标。
断句实验结果如表3所示,可以看出诗歌断句结果整体好于古文断句结果,可能是因为古诗具有特定的体制和韵律,如五言绝句、七言律诗等,模型更加容易学得其断句规律,古诗断句最好的F1值已经超过99%。而古文的形式更加灵活,句式更加丰富,最好的断句F1值为95.03%,比古诗低了4.5个百分点。
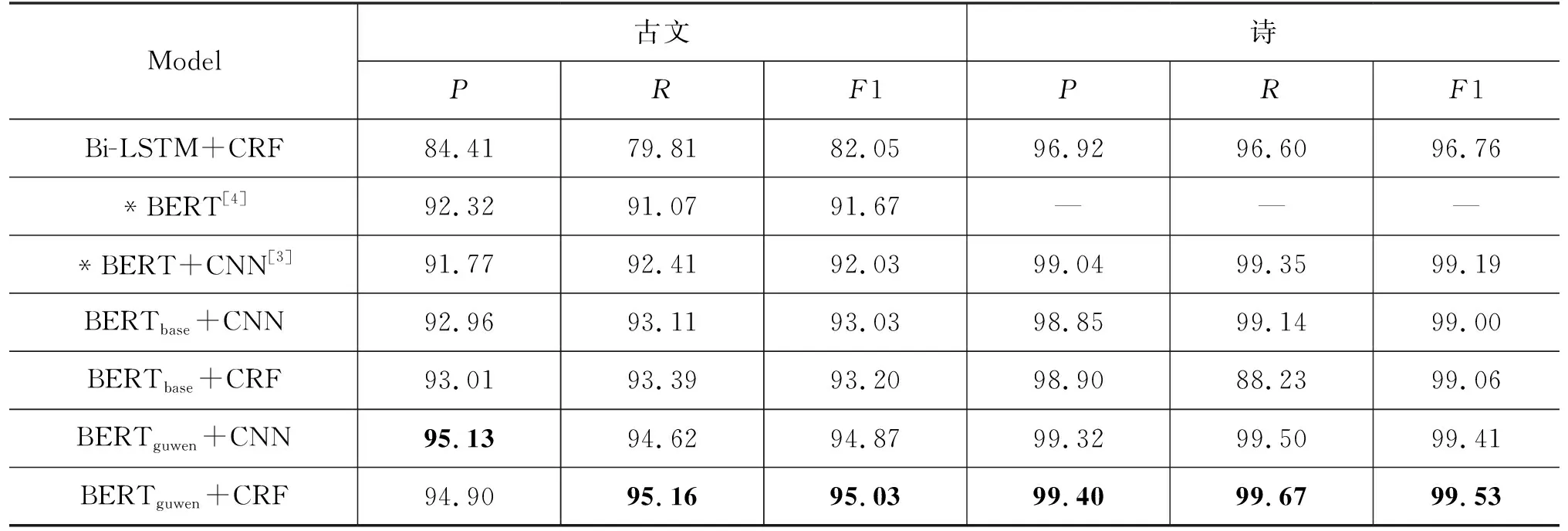
表3 不同模型在古文和诗歌上的断句实验结果 (单位:%)
对比不同模型的性能,可以看到BERTguwen+CRF模型相比其他模型在断句任务上有最高的召回率和F1值,分别为95.16%、95.03%,BERTguwen+CNN模型有最高的准确率95.13%。相比于基线模型Bi-LSTM+CRF,融入了预训练语言模型之后断句效果均有一定程度的提升。融合增量训练的古文预训练模型的BERTguwen+CRF模型比基线模型Bi-LSTM+CRF的F1值提高了12.98个百分点。
对比BERTbase+CRF和BERTguwen+CRF的实验结果。可以看出,使用了BERTguwen的模型断句效果比使用BERTbase的模型好,F1值提高了1.83个百分点,这说明对BERT模型做繁体古文增量训练,可以使模型学习到更多古文知识,能更好地处理断句任务。如以下案例所示, “用兵”其主语本是“朝廷”,在此处承前省略主语,“其主”与“秉常”属于同位语,共同作为“囚廢”的宾语,BERTguwen+CRF经过了古文增量训练,能够更好地识别此类主语省略的句式,断句结果正确。而BERTbase+CRF模型错误地将“秉常”当作“用兵”的主语,“西方”作为“既下”的主语,导致断句错误。“城砦”为双音节文言词,在古文中属于比较常用的词,但在现代汉语中几乎不再使用,BERTbase+CRF不能准确地识别这一词语,可能是因为在其现代汉语训练语料中“城砦”出现频次较低,BERTguwen+CRF将“城砦”作为一个整体且断句正确,这说明增量训练之后的BERTguwen+CRF对文言词更加敏感。
例1
原文: 朝廷以夏人囚廢其主秉常。用兵西方。既下米脂等城砦數十。
BERTguwen+CRF: 朝廷以夏人囚廢其主秉常。用兵西方。既下米脂等城砦數十。
BERTbase+CRF: 朝廷以夏人囚廢其主。秉常用兵。西方既下。米脂等城。砦數十。
通过分析断句结果,我们发现断句经常出现“可断可不断”的情况,如以下两个案例所示,原文为“借兵於楚伐魏”,模型断句结果为“借兵於楚。伐魏”,在“伐魏”之前断句应该也不为错误。案例2的模型断句也是类似的情况,模型断句偏向于将长句断为小句,但这种断句结果似乎不能算作错误。在实验时,将唯一断句标注集作为标准答案,并不能全面地评估模型的性能,以后可以尝试在测试集中给出多种正确标注答案。
案例1:
原文: 取我剛平。六年。借兵於楚伐魏。
BERTguwen+CRF: 取我剛平。六年。借兵於楚。伐魏。
案例2:
原文: 故曰。禮人而不荅則反其敬。愛人而不親則反其仁。治人而不治則反其知。
BERTguwen+CRF: 故曰。禮人而不荅。則反其敬。愛人而不親。則反其仁。治人而不治。則反其知。
3.4 标点实验结果
本文在评价标点模型时使用微平均精确率(Pmicro)、召回率(Rmicro)和F1micro。
标点实验结果如表4所示,由于诗歌的标点规则比较简单,所有模型的标点F1值都在95%以上。BERTguwen+CNN模型在古文和诗歌上标点表现最好,F1值为80.18%和98.91%。在古文标点中,BERTguwen+CRF比BERTbase+CRF的标点F1值高1.54个百分点,BERTguwen+CNN比BERTbase+CNN的标点F1值高2.21个百分点,说明增量训练之后的模型在一定程度上能够帮助提升标点效果。

表4 不同模型在古文和诗歌上的标点实验结果 (单位: %)
和断句任务的结果相比,标点的精确率、召回率、F1值与断句均有较大差距,因为断句规则相对比较统一,而标点的规则比较复杂,不同的标点表达不同的感情和意义。本文实验的语料虽然是经过人工整理的,但是依然存在标注规则不一致的情况,如逗号和句号、分号和逗号的使用常常因人而异,模型也难以分辨。
3.5 增量古文模型语义表示能力
上面的实验结果已经证明BERTguwen模型相比BERTbase模型在断句和标点任务上表现更好。本文设计实验进一步讨论BERTguwen的表现优于BERTbase的原因。
古代汉语和现代汉语各有特点,现代汉语以双音节词为主,古代汉语以单音节词为主,且多义词比例很高。BERT与传统的词向量模型不同,BERT能够对不同语境下同一个词有不同的语义表示,具有区分同一个词的不同义项的能力,如“君之病在肠胃”中的“病”与“人皆嗤吾固陋,吾不以为病”中的“病”分别对应不同的向量。
本文选取一组古汉语多义词来讨论BERTguwen和BERTbase文言词的语义表示能力。本文选取古汉语多义词基于以下三个原则: ①单音节多义词,因为BERT中文模型只能对句子和单字词做语义表示; ②词语义项多,文言词除本义外通常还有引申义和假借义; ③词语在古汉语中使用率高,属于常用词。
基于以上三点,我们参考文学网(3)https://wyw.hwxnet.com/article/24.html发布的150个古文多义实词以及《古汉语常用字字典》第四版,选取“安”“謝”“信”“兵”“愛”“病”“假”七个单音节词作为实验对象,以上七个多义词义项都在3个以上,并且在我们的语料库中出现频次较高。
首先从整理的语料中分别找到3 000条含有以上七个单音节词的句子,利用BERTguwen对每条例句中的词作向量化表示,然后用k-means对以上七个词语的所有词向量做聚类,最后使用t-nse对聚类结果进行可视化。根据《古汉语常用字字典》中的义项,七个单字词的义项共36个,将k-means的聚类数设为36,模型自动将所有词向量聚为36个小类。聚类效果如图2所示,图中每个点代表一个词向量,从图2上可以比较明显地看出聚类之后出现了七个模块,每一模块对应一个文言单字词,每个模块内部又包含不同灰度的点,不同颜色表示词内部有不同的义项。以上聚类结果说明BERTguwen能够将不同文言词的语义区分开,并且能表示出一个多义词的不同义项。
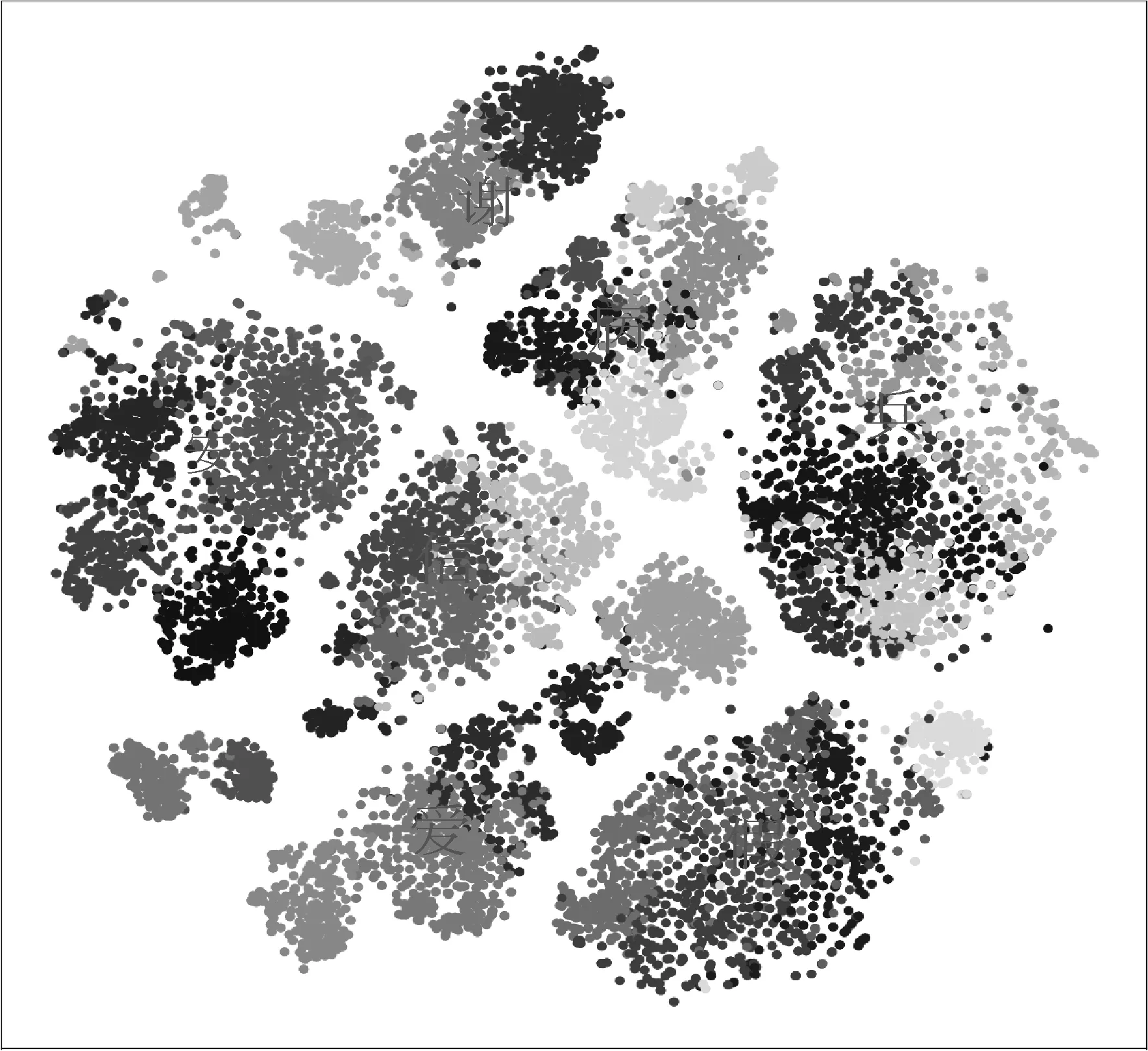
图2 k-means对七个古汉语单字词向量的聚类效果图
为了进一步讨论BERTguwen模型对同一个文言词的不同义项的区分能力,我们对比BERTguwen和BERTbase两个模型对七个多义词的不同义项的语义表示能力,即是否能将不同义项分开。以“安”和“謝”为例,首先根据文言词“安”的四个常用义项人工挑出2 000条例句,根据文言词“謝”的三个常用义项挑出1 500条例句,部分例句如表5所示。

表5 文言词“安”“谢”常用义项例句(部分)
分别使用BERTguwen和BERTbase两个模型生成“安”和“謝”在所有例句中的词向量,最后进行聚类。我们使用轮廓系数评估聚类效果,聚类效果越好,轮廓系数越高,计算如式(1)所示。
(1)
其中,a(i)表示样本点i的簇内不相似度,j表示与样本i在同一个类中的其他样本,distance(i,j)表示i和j之间的距离。
(2)
其中,b(i) 表示i和其他每个类别的所有样本之间的距离和的最小值,计算方式和a(i)类似。所有样本的S(i)均值即为聚类结果的轮廓系数。
如图3所示,图3(a)为BERTguwen生成的“謝”的词向量的聚类效果,聚类系数为3,轮廓系数S为0.1173;图3(b)为BERTbase生成“謝”的词向量的聚类效果,聚类系数为3,轮廓系数S为0.096 4;对比图3(a)和3(b)发现BERTguwen生成的“謝”的向量能够被清晰地聚为3类,且图3(a)的轮廓系数大于图3(b)的轮廓系数。对比七个多义词的七组聚类效果图及其轮廓系数发现,除了“信”以外,BERTguwen生成的词向量的聚类效果明显好于BERTbase生成的词向量。
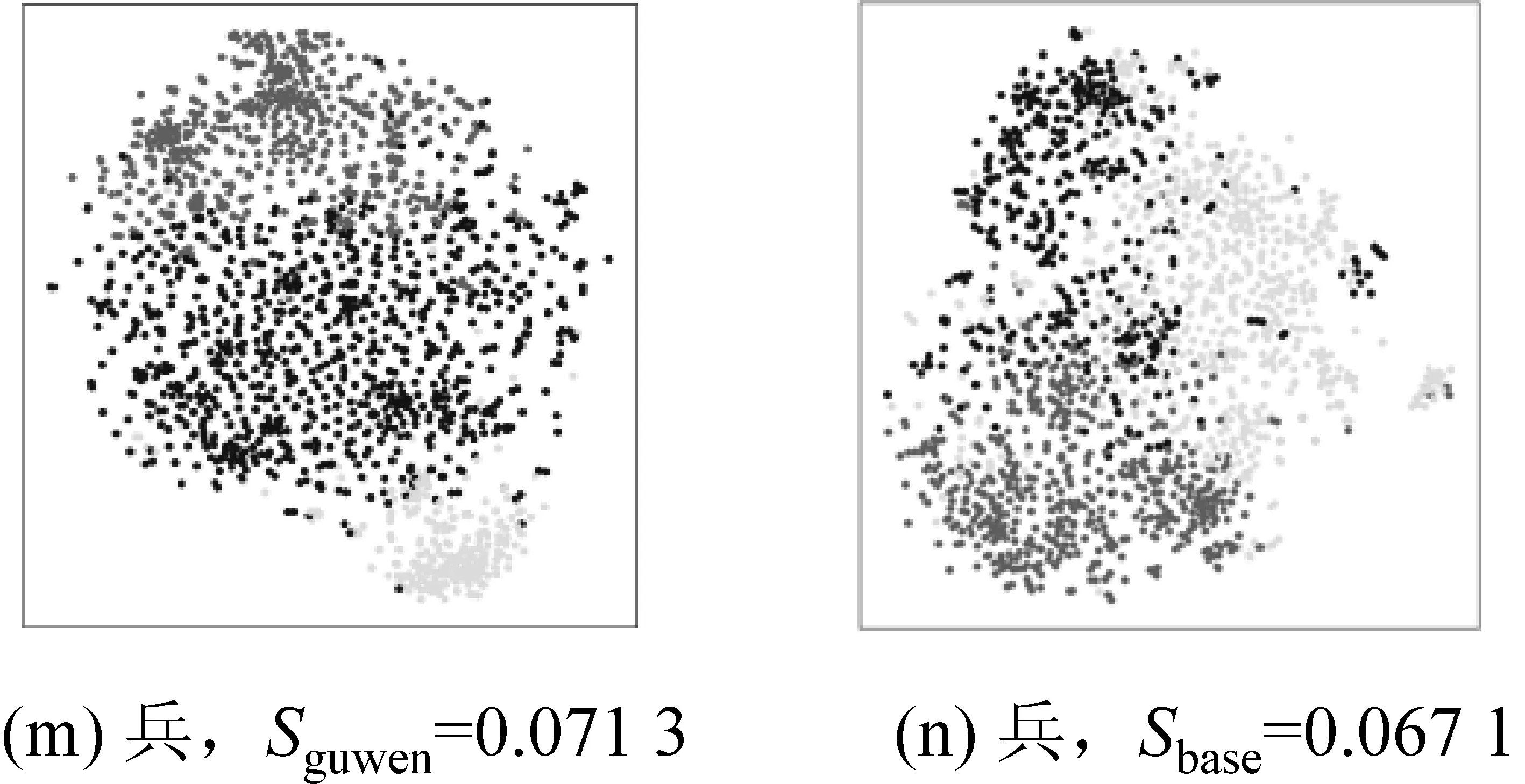
图3 (续)
观察“信”的聚类效果图我们可以看出,BERTguwen的聚类效果似乎好于BERTbase,但轮廓系数前者却小于后者。原因可能是“信”的义项较多,并且这些义项之间有比较紧密的引申关系,词性主要是动词和名词。如“不欺,讲信用”(言而有信)“信任”(愿陛下亲之信之)“相信“(忌不自信)“信用”(小信未孚,神弗福也)。而如“安”“謝”这类多义词,不同义项距离较远,且词性多样。
4 篇章级断句
近年来,不断有学者提出长文本处理模型,BlockBERT[15]切断BERT中不重要的注意力头,将BERT可处理的Token数从512个扩展到1 024个。Big bird模型[16]使用稀疏注意力机制,将计算复杂度降到线性,可以处理比全局注意力Transformer长8倍的序列。但是这类模型能处理的长度依然有限,长文本句读是生产环境下需要解决的问题,但目前涉及这一问题的研究较少。俞敬松等[4]使用滑动窗口的方式处理篇章级句读(以下称串行滑动窗口1),如图4中示例所示,每次输入不超过64字的片段,因其训练数据最长为21字,所以只取输出结果的前一个或两个断句结果,剩余的部分归并到第二次切分的64字。这种滑动窗口方式虽然在一定程度上保证了断句的准确性,但是每次处理的序列只有64字,且每次只取前两句的断句结果,后面的处理结果因准确性不高都被放弃。这种方式每次需等待前一片段输出结果之后才能进行第二片段的处理,处理效率很低。
本文提出了两种新的滑动窗口方式,在保证准确率的同时也能极大提高运行速率,以下称串行滑动窗口2和并行滑动窗口。串行滑动窗口2是通过对串行滑动窗口1改进得到,如图5示例,首先输入文档的前125个字,然后等待模型返回前125个字的断句结果,因为倒数第一句可能因为语义不完整而出现错误断句,所以将倒数第一句的断句结果加入到下一次切分的125字中过,依次处理完所有文本。这种方法使得每次能处理更长的序列,并且每次只放弃输出结果的最后一句,运行速度相比串行滑动窗口1有一定提高。但是因为数据处理的方式仍然是串行的,每次需要等待前面的返回结果,句读效率不足以满足使用需求。

图5 串行滑动窗口2示例第一次取得结果为“……據其要害。擊之可破也。岱不從。遂與戰。”
为了进一步提高篇章级句读速率,本文提出了并行滑动窗口方法。如图6案例所示,将长文本数据按照滑动窗口的方式切分,第一个片段与第二个片段重复n个字,第二个片段与第三个片段重复n个字,依次将长文本切成m个片段,将m个片段同时送入模型,同时返回m个结果。在处理返回结果时也按照滑动窗口的方式处理,对于片段1,首先删除倒数第一句的输出结果得到新的片段1,然后在片段2的输出结果中删除和新的片段1重复的部分,同样删除片段2的倒数第一句的输出结果,得到新的片段2,最后将新的片段1和新的片段2拼接,依次将所有的片段拼接得到最后的输出序列。将一整篇文本切分为多条数据并行处理,大幅度提高了句读速度,并且能保证句读的准确率。在实验中我们将片段长度设置为125,重复字数n设为20。
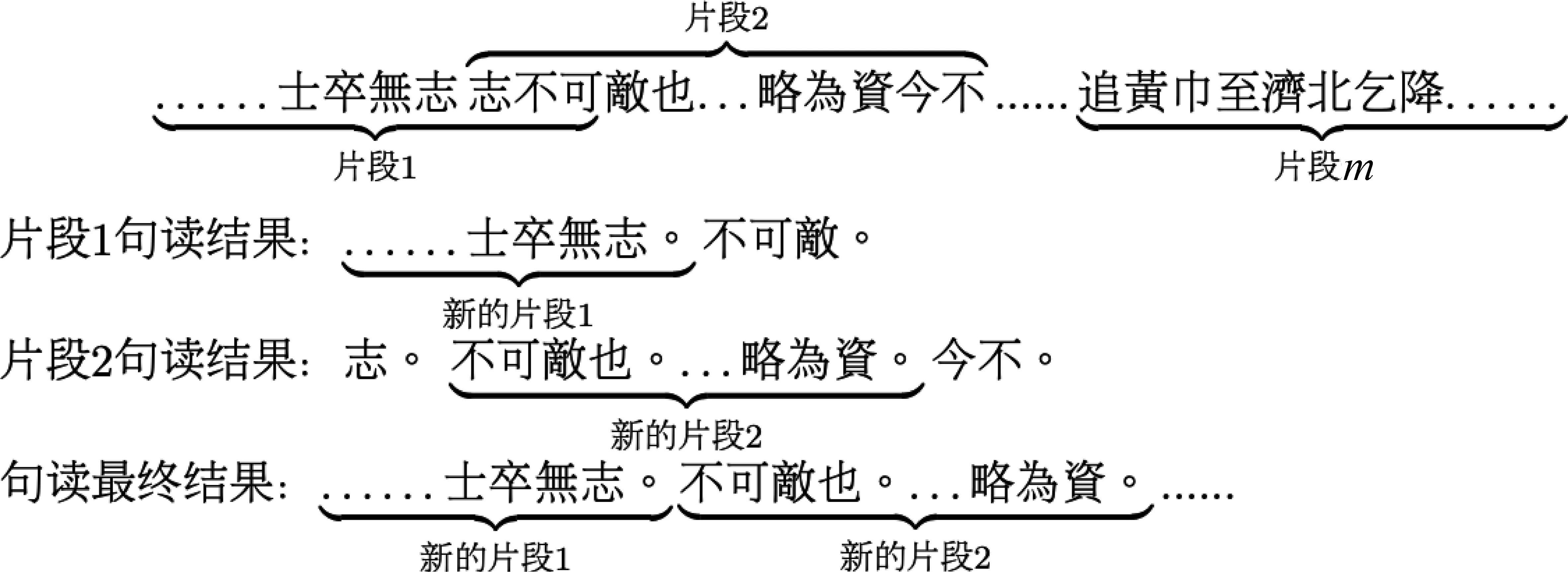
图6 并行滑动窗口示例切分为m个片段,然后在返回的断句结果中,将每个片段重复的部分去掉。
我们将直接截断的方式作为基线标准,将长文本每64字截断组成一批数据喂进模型。使用以上四种方式句读一段4 168字的长文本,实验结果如表6所示。

表6 四种篇章级句读方法实验结果
从表6中可以比较明显地看出,滑动窗口方法的F1值都高于直接截断的方法,这是因为滑动窗口只取语义比较完整的文本片段作为输出结果,而直接截断的方式容易造成文本片段结尾强制断句的错误,但是直接截断的方式具有最高的处理效率。对比两种串行滑动窗口方式,本文改进的串行滑动窗口2句读速度相比于串行滑动窗口1提高了11倍,且有最高的F1值。比较并行滑动窗口和两种串行滑动窗口,并行滑动窗口方式用时5.79 s,和直接截断方式用时基本无差,同时也保证了断句具有较高的F1值。
基于本文提出的句读模型和并行滑动窗口方式,我们开发了“吾与点”古籍自动句读平台(4)http://wyd.pkudh.xyz/。该平台可以辅助古籍研究者和爱好者自动句读古籍文本。
5 总结
古文断句和标点是古籍整理过程中重要的一步,本文利用预训练语言模型实现了繁体古籍的自动断句和标点。首先利用10亿字繁体古文语料对中文BERT模型做增量训练,然后以此预训练模型为基础实现了繁体古文的自动断句和标点。古文和诗歌的自动断句F1值分别为95.03%和99.53%,标点F1值分别为80.18%和98.91%。并且通过实验发现增量训练后的BERT模型能够提升自动断句和自动标点的效果。本文通过对文言多义词的多个义项聚类发现,增量训练的语言模型的古文语义表示能力优于原始BERT模型,并且具备一定的区分多义词不同义项的能力。在篇章级句读方面,本文改进了数据串行方案并提出数据并行的滑动窗口方式,既能保证句读的准确率,也能保持极高的处理效率。
