基于词汇迁移的跨语言形态复用
2023-10-25刘伍颖
刘伍颖,王 琳
(1. 鲁东大学 山东省语言资源开发与应用重点实验室,山东 烟台 264025;2. 广东外语外贸大学 外国语言学及应用语言学研究中心,广东 广州 510420;3. 上海外国语大学 贤达经济人文学院,上海 200083)
0 引言
随着语言科学和计算技术的发展,特别是近年来深度学习在自然语言处理中的成功应用,超大规模语言资源越来越成为算法成功的关键因素。对于低资源语言,如何快速有效地构建超大规模结构化良好的语言资源对其高效处理应用至关重要[1]。
早期研究发现,来自不同类型的同种语言文本之间存在较强的形态相似性[2]。利用迁移学习进行形态复用,我们可以实现跨类别的有效文本分类。即用A型文本训练出一个文本分类模型,然后成功应用于B型文本的分类任务。但是两种不同语言之间的形态相似性究竟有多大?它能不能足以支持低资源语言处理应用中的形态复用呢?
带着这些思考,我们首先回顾了以往的研究。已有研究发现,不仅英式英语和美式英语之间,而且英语、德语、法语和其他西方语言之间在词汇层面上都有高度交叠。研究还发现,汉语和日本语、韩国语或越南语之间有超过60%的共用词汇[3]。这些借词的形态相似性主要是源于这些语言之间的同源性和文化交流性。同源语言是指在人类语言进化的长河中,它们在语言谱系树上具有共同祖先节点的那些语言。同源语言之间的形态相似性已成为形态复用的希望之桥。接下来,我们选择一对同源语言(马来语和印尼语)作为我们的检测对象。
1 词汇交叠检测
来自同语族的语言的形态同源性和相似性最为明显。马来语和印尼语同属南岛语系的马来-波利尼西亚语族。广义上讲,印尼语也是一种马来语。以现代印尼语为母语的人数约为4 500万,全世界以其为第二语言的人数有1.6亿。而现代马来语的母语使用者超过8 000万,主要分布在文莱、印度尼西亚、马来西亚、新加坡和其他地方。全球范围马来语使用者超过了3亿。尽管这两种语言的使用者不少,但它们到汉语的平行句库等资源仍然稀缺。相对于英语等富资源语言,马来语和印尼语仍然属于低资源语言。因此,在接下来的定量分析中,我们检测马来语和印尼语之间的词汇交叠。
如式(1)所示,本文定义从A语言到B语言的形态迁移率(MTR)为A语言和B语言Token集合中共现Token数除以B语言Token集合中Token数的百分比。其中,函数#(·)表示集合中的Token数,函数TokenSet(·)表示语言的某种Token集合。
MTR(A→B)=

(1)
上述定义表明形态迁移在两种语言之间具有方向性。MTR(A→B)的数值属于[0%,100%],反映的是从A语言到B语言形态迁移的有效程度。有两种特例: ①当#(TokenSet(A))数值等于#(TokenSet(B))数值,形态迁移的有效程度在两种语言之间将是双向等价的(MTR(A→B)=MTR(B→A))。②当#(TokenSet(A)∩TokenSet(B))数值等于0,在两种语言的这类Token之间不会进行任何有效的形态迁移。
我们统计的语料来源于Wikipedia马来语和印尼语20191101版,包括bz2 package 格式的202.9 MB马来语篇章和523.4 MB印尼语篇章。由于计算MTR时可以采用任意粒度的Token,所以我们关注广泛使用的去重后的词级N元Token。而且对于每个Token我们分别统计了大小写相关的Token数和大小写无关的Token数。经过交叠Token数统计,最后得到具体的MTR结果如表1所示。其中正常字体数值表示大小写相关结果,粗体数值表示大小写无关结果。

表1 马来语和印尼语的形态迁移率
根据表1数值,我们发现所有马来语文本仅由590 105个不同的大小写相关单词组成,而所有印尼语文本由1 081 745个不同的大小写相关单词组成,并且两种语言的共现大小写相关单词数多达315 312。1元大小写无关Token的MTR(M→I)值为29.67%,而相同Token的MTR(I→M)值为53.66%,这说明1元大小写无关Token的形态迁移从印尼语到马来语比反方向更有效。从1元到5元Token的MTR值可知,尽管马来语对印尼语的提升不及印尼语对马来语的提升大,但相关提升对于相对低资源语言而言还是意义非凡。而在最近的深度学习算法中,为了降低语言空间维度,往往采用子词特征代替词汇特征,这有利于形态迁移率的进一步提升。
上述MTR数值为形态复用提供了坚实的基础,接下来我们通过语言资源建设和语义转述应用这两个特定的任务来进一步阐明形态转移学习的有效性。
2 多词表示提取
多词表示(MultiWord Expression, MWE)通常是指由两个以上词汇连接构成,其意义不能通过部分构成词汇获得的一种介于词汇和句子之间的形态粒度。多词表示适合高效的形态复用和语义处理,已被广泛成功用于机器翻译等自然语言处理应用[4]。因此每种语言的多词表示语料库已成为一种关键的基础语言资源。
为了高效构建多词表示语料库,人们进行了长期的探索。除了人工标注之外,采用自然语言处理算法自动提取也经历了基于规则的方法、有监督学习方法[5]、半监督学习方法[6]等,并取得了一系列成果。早期的采用统计上下文特征的提取算法在英语多词表示提取上取得了较高的准确率[7]。后来有研究采用形态、句法、词汇等特征实现德语的多词表示提取[8],而另一些研究者借助WordNet和Google Translate等第三方资源和工具实现阿拉伯语多词表示提取[9]。但这些早期方法的有效性取决于人工标注规模和复杂特征选择[10]的质量,而这些先决条件往往费时费力且代价高昂。随着语言大数据的爆炸增长,富资源语言的多词表示自动提取变得越来越容易。尽管当前的无监督学习方法[11]和深度学习方法[12]对人工标注语料的依赖程度不断降低,但它们仍需要大规模无标注的原始语料。因此,对于既缺乏标注语料又缺乏大规模无标注语料的低资源语言而言,已有的方法难以高效解决多词表示提取问题,这也促使我们尝试基于词汇迁移的形态复用方法。
小学数学教材中专业术语极多,不容易理解的知识点,大幅度的文字描述都让教材显得晦涩难懂,所以,教师除了拥有传达知识,引导学生理解掌握知识的作用外,还要注意调整语言,以保证能将数学教材中难以理解的知识点转换成直白简单的口语,通过简化专业术语的方式加深学生对知识点的掌握,同时在教学过程中,老师所讲解的知识点最好结合生活实例,让学生能从生活中发现并解决问题,从而达到提升思维能力的目的。
本文设计的用于多词表示提取的形态复用框架如图1所示。该框架主要包含源语言(短虚线)和目标语言(实线)两条路径。沿着短虚线路径,多词表示提取器(MWE Extractor)接收F语言文本并输出F语言的多词表示集(MWEF)。沿着实线路径,N元Token索引器(N-gram Token Indexer)接收T语言文本,并输出大小写无关的词级1元到5元的Token索引。最关键的迁移学习器(Transfer Learner)接收MWEF,搜索1元索引并输出T语言多词表示大集(MWEB),同时搜索2、3、4、5元索引并输出T语言多词表示小集(MWES)。我们还使用相同的多词表示提取器直接从T语言文本中提取T语言多词表示集(MWET)。最后,评估器(Evaluator)采用MWET分别萃取MWEB和MWES,据此输出从F语言迁移得到的T语言多词表示集MWEb和MWEs,也就是采用相同的多词表示提取算法从当前T语言文本中提取不到的多词表示。
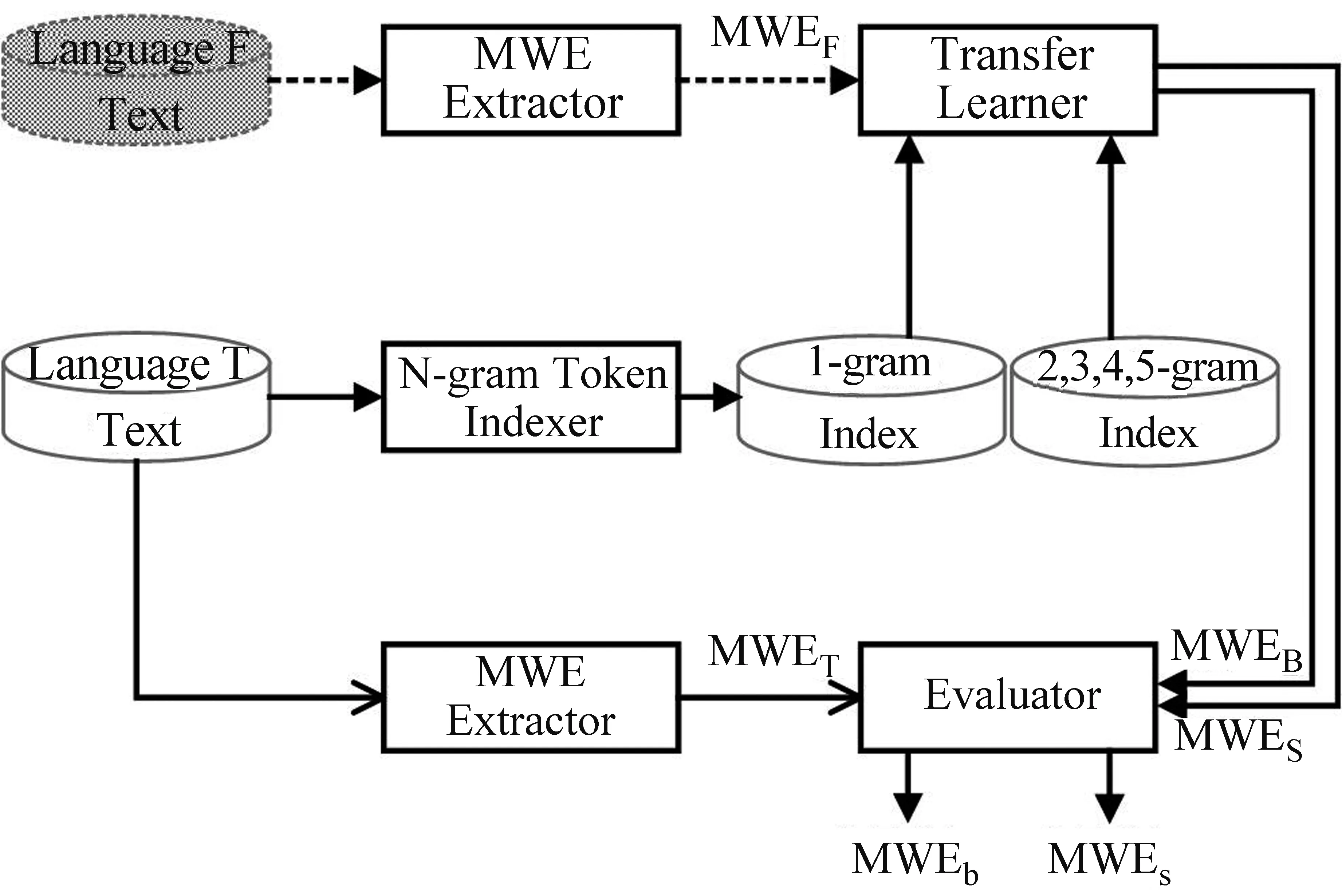
图1 多词表示提取的形态复用框架
该框架是一种适用于任何语言用作F语言或T语言、任何具体多词表示提取算法实现多词表示提取器(MWE Extractor)的元框架。本文4.1节实验采用了我们以前提出的空格二值分类思想实现多词表示提取器。对于框架中的迁移学习器(Transfer Learner),我们在实验时充分考虑算法的高效可计算性,设计实现了两款迁移策略: ①大策略对于MWEF集合中的每条多词表示,先以空格切分得到词汇集合,再逐一搜索1元索引。如果每个词汇都命中索引,那么判断该条多词表示是T语言多词表示; ②小策略对于MWEF集合中的每条多词表示搜索2、3、4、5元索引。如果命中索引,那么判断该条多词表示是T语言多词表示。大策略是一种模糊策略,能够提取T语言语料中并未连续出现的潜在多词表示,在一定程度上克服了新多词表示发现的困难;小策略是一种精准策略,能够提取T语言语料中出现但频率偏小的潜在多词表示,在一定程度上克服了语料受限时多词表示发现的困难。
3 神经机器翻译
机器翻译(Machine Translation, MT)是采用目标自然语言转述源自然语言语义的算法计算过程。在经历规则机器翻译的青铜时代和统计机器翻译[13]的白银时代之后,基于深度学习[14]的神经机器翻译(Neural MT, NMT)开启了新的黄金时代[15]。迄今产生了一系列优秀模型[16],如谷歌的端到端(End-to-End)模型[17]、蒙特利尔大学的编码器-解码器(Encoder-Decoder)模型[18]、深度Transformer模型[19]等。
在超大规模双语平行语料的支持下,深度学习神经机器翻译取得了比较理想的效果,基本上能够满足日常的翻译需求[20]。但对于缺少超大规模双语平行语料的低资源语言机器翻译问题,目前尚无成熟算法。而在全世界现存的7 000多种语言中,绝大部分的非通用语言都在不同程度上存在超大规模双语平行语料稀缺的困难。当前理性主义追本溯源,力求通过解析语言本质来实现更高水平的机器翻译,但尚未取得明显进展。而经验主义采用数据制导,认为结果有效即王道,并依仗深度神经网络取得了实用性进步。后一种思路促使我们尝试基于词汇迁移的形态复用方法应对低资源语言语义转述任务。
我们设计的用于神经机器翻译的形态复用框架如图2所示。该框架包含了三种语言: 源语言F、目标语言T以及相应的平行语言C。其中,源语言、目标语言以及平行语言都可以是任意的人类语言。由于我们着重研究外语到汉语的机器翻译,因此,本文中的平行语言是汉语。首先,1元Token索引器接收TC平行句库中的T语言句子,生成大小写无关的词级1元Token索引。接着,迁移学习器接收FC平行句库中的F语言句子,并通过搜索1元索引对该FC句对进行可迁移和不可迁移的二值分类。最后,NMT训练器综合TC平行句库中的TC句对和从FC平行句库中迁移来的TC句对,训练出一个T语言到C语言的神经机器翻译模型。
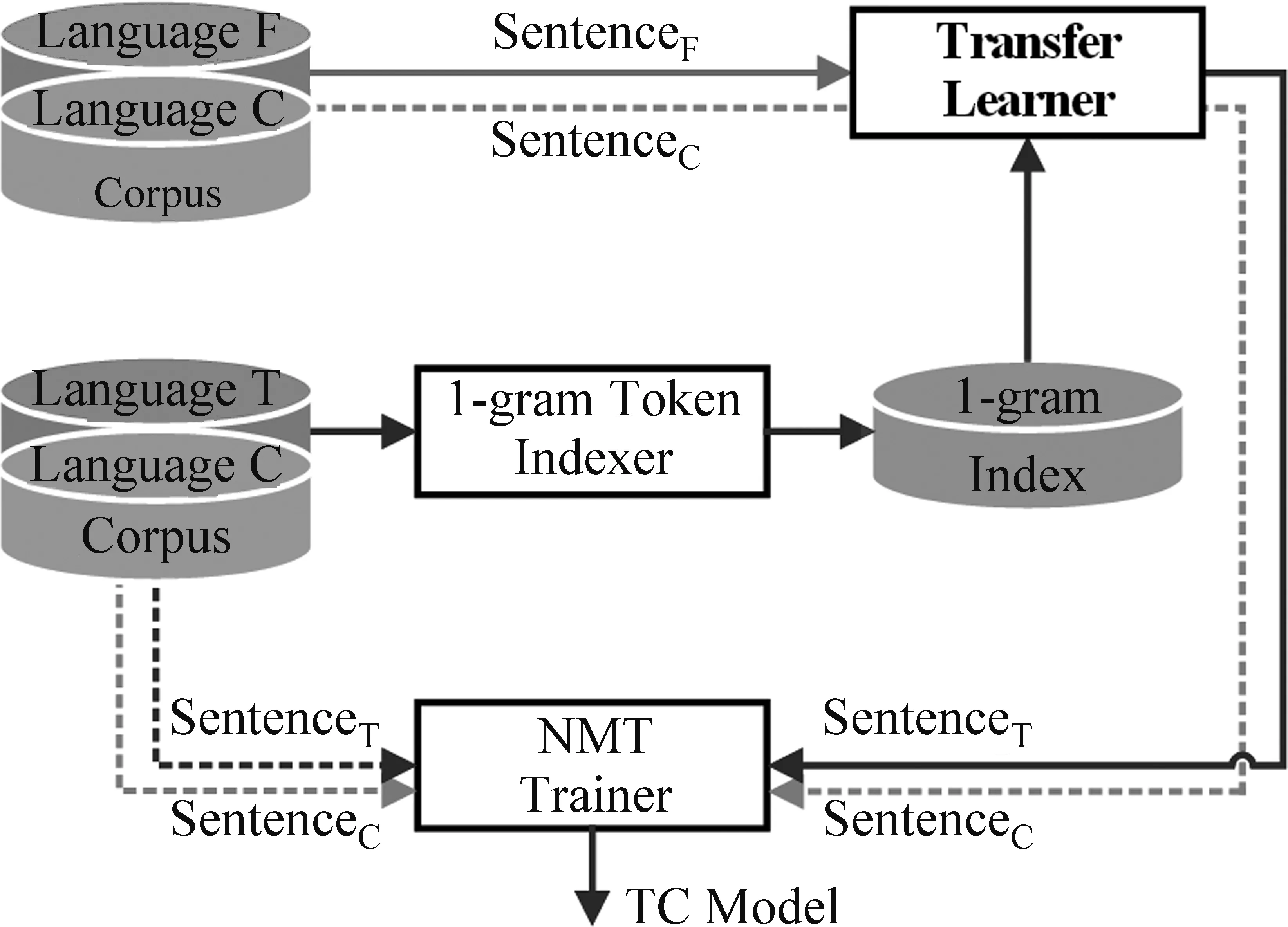
图2 神经机器翻译的形态复用框架
该框架是一种与具体神经机器翻译算法无关的元框架,也可以看成是神经机器翻译算法的语料增强预处理过程。在实现迁移学习器的二值分类时,具体迁移策略是对于FC平行句库中的F语言句子,先以空格切分得到词汇序列,再逐一搜索1元索引,如果每个词汇都命中索引,那么判断该句子对应的FC句对是可迁移句对,反之是不可迁移句对。该策略最大限度地保证了可迁移句对的有用性。
4 实验
为了验证本文新提出的形态复用方法对低资源语言的有效性,根据语言资源建设和语义转述应用任务,选择马来语和印尼语作为实验对象语言进行双向迁移实验。即: 我们从马来语(印尼语)语料库提取印尼语(马来语)多词表示;从马来语(印尼语)资源增强的印尼语(马来语)-汉语平行句库训练出印尼语(马来语)-汉语神经机器翻译模型。具体的实验实现、实现结果与讨论如下文所述。
4.1 多词表示提取结果与讨论
我们首先实现了图1框架,其中的多词表示提取器采用广泛使用的空格二值分类有监督学习算法[21]。学习时,需要统计空格已标注文本语料的1元Token频率和2元Token频率。应用时,只需计算两个Token邻接共现的概率除以每个Token出现的概率,就能较好实现不定长多词表示的提取。接着,把Wikipedia 20191101版的202.9 MB马来语篇章和523.4 MB印尼语篇章分别用作马来语文本语料和印尼语文本语料。最后,把人工编订的114 032条马来语多词表示和253 176条印尼语多词表示用作标准答案,对下列实验结果进行讨论。
具体的多词表示提取结果如表2所示。我们从202.9 MB马来语语料提取得到76 078条多词表示,从523.4 MB印尼语语料提取得到143 521条多词表示。采用形态复用方法,可以从马来语语料迁移得到45 201条印尼语多词表示大集和34 487条印尼语多词表示小集,反向可以从印尼语语料迁移得到51 137条马来语多词表示大集和30 257条马来语多词表示小集。经过评估器萃取,我们可以从马来语语料迁移获得仅从印尼语语料提取不到的印尼语多词表示(大集21 534条,小集10 823条),反之也可以从印尼语语料迁移获得仅从马来语语料提取不到的马来语多词表示(大集37 784条,小集16 908条)。根据标准答案,从马来语语料迁移获得的印尼语多词表示MWEb和MWEs的准确率分别为0.35和0.59,从印尼语语料迁移获得的马来语多词表示MWEb和MWEs的准确率分别为0.29和0.45。 在实验过程中,采用同样的空格二值分类有监督学习算法实现的多词表示提取器(MWE Extractor)从T语言文本直接提取MWET就是一个可对比的Baseline方法。而迁移学习的实验结果表明采用形态复用能够提取到Baseline方法提取不到的多词表示。

表2 多词表示提取结果
根据上述语言资源建设实验,我们可以得出下列结论: ①形态复用方法能够有效提取目标语言语料中并未连续出现或出现但频率偏低的潜在多词表示。②上述形态复用的实验准确率都低于0.60是因为标准答案与实验语料是相互独立的,而且空格二值分类有监督学习算法0.90左右的准确率也导致错误累积。因此我们形态复用的实际准确率应该更高。③N元Token索引器采用索引数据结构、迁移学习器采用一趟扫描的流处理,因此时空复杂度在实际应用中也是可接受的。当然,如果还想获得更精准的语言资源,则需要进一步人工审定。④经过随机采样人工标注,我们发现采用形态复用识别出的多词表示中人名、地名、机构名占据75%以上,对相对低资源语言的语言资源建设具有实用价值。
4.2 神经机器翻译结果与讨论
我们实现了图2框架,其中分别采用了两种经典的GNMT模型[22]和Transformer模型[23]来实现NMT训练器。实验采用汉语作为框架中的C语言。因此我们迁移马来语(印尼语)-汉语句对资源,增强训练出印尼语(马来语)-汉语神经机器翻译模型。为了显示形态复用的增强效果,我们针对两种神经机器翻译模型(GNMT模型和Transformer模型)、两个迁移方向(马来语到印尼语和印尼语到马来语)运行了8次模型训练实验。
表3中的实验语料主要包括马来语-汉语平行句库(3 856 449句对)、印尼语-汉语平行句库(10 297 458句对)以及采用我们的形态复用方法得到的马来语到印尼语可迁移1 934 968句对、印尼语到马来语可迁移6 354 026句对。实验运行之前先将TC平行句库分成训练、验证、测试3个集合,其中验证集和测试集各包含100 000句对,是通过不放回随机采样技术抽取而成。

表3 神经机器翻译结果
表3显示了8个神经机器翻译模型训练的实验结果,其中4个无形态复用(迁移句对数等于0)的实验结果用作可对比的Baseline结果。从中可以发现采用形态复用方法挑选的迁移句对资源的确能够提高GNMT模型和Transformer模型的性能。例如,在印尼语-汉语神经机器翻译实验中,马来语资源增强的印尼语-汉语训练集包含12 032 426(=1 934 968+10 297 458-100 000-100 000)句对。相应GNMT模型的BLEU4得分从无形态复用的38.62提高至41.35,Transformer模型的BLEU4得分更能从无形态复用的39.88显著提高至42.75。与此类似,在马来语-汉语神经机器翻译实验中,迁移印尼语资源6 354 026句对后,GNMT模型的BLEU4得分从对应无形态复用的26.16提高至30.21,Transformer模型的BLEU4得分能从对应无形态复用的27.33提高至31.57。我们已经成功将上述BLEU4得分最高的印尼语-汉语神经机器翻译模型(BLEU4=42.75)和马来语-汉语神经机器翻译模型(BLEU4=31.57)部署成互联网应用系统。
根据上述语义转述应用实验,我们可以得出下列结论: ①形态复用对GNMT模型和Transformer模型的增强训练都是有效的,这是由于同语族的同源性和相似性带来很强的形态可迁移性。②形态复用框架中1元Token索引器采用的索引数据结构以及迁移学习器采用的一趟扫描流处理的时空复杂度是实际应用可接受的,这使得同语族低资源语言具有很强的迁移可计算性。③增加迁移句对资源后,训练集总规模相近,但印尼语-汉语神经机器翻译性能优于马来语-汉语神经机器翻译性能,这是因为最终的马来语-汉语训练集掺杂了60%以上的印尼语-汉语句对,导致训练出的模型产生了过拟合。④Transformer模型性能普遍优于完全相同条件下的GNMT模型性能,BLEU4得分均高出1点多,这是由于两个模型原生的性能差异。
5 结论
本文围绕形态复用这个科学问题,采用形态迁移率指标定量评估了同语族语言之间的迁移效果,通过马来语和印尼语之间的多词表示提取和神经机器翻译实验阐明了形态复用对低资源语言的语言资源建设和语义转述应用是有效的。而形态复用框架所采用的索引数据结构和一趟扫描流处理也都是时空高效和实际可用的。
未来将进一步定量研究不同语族语言之间的形态复用效果,探究适合任意语言之间的分级形态复用框架和算法。多源扩建低资源语言的双语多词表示资源,改善神经机器翻译中的专有名词译不准窘态,增强神经机器翻译的精准性。此外,我们还将上述研究成果用于其他低资源语言的语言资源建设和语义转述应用。
