基于词向量的基站退服告警预测方法及应用
2023-10-25王亚楠陈毅敏李佳袁
王亚楠,陈毅敏,李佳袁*
(1.中国移动通信集团设计院有限公司,北京 100080;2.北京市第一中西医结合医院,北京 100026)
0 引言
以5 G为代表的新一代信息通信技术,正成为引领新一轮科技革命和产业变革的核心引擎。一方面,5 G网络自身的发展虽融入了开放化、智能化等特性,但越来越复杂的网络同样急需运维模式的革新;另一方面,网络智能化的程度也随着业务层面的不断创新而日益加深[1-3]。
随着无线通信技术的快速迭代和网络规模的不断扩大,用户对网络质量的要求越来越高,传统被动响应式的基站告警处理方式已越来越不能满足运营商对网络告警,尤其是影响网络质量的重要告警的管理需求。
为了减少基站退服事件的发生,降低基站退服时长,本文提出了一种基于词向量的退服告警预测方法,通过对高隐患基站的精准定位,为基站巡检和隐患的提前排障做出有力指导,从根本上实现了基站退服的主动预防,提升了网络运维的效率和质量。
1 基于词向量的基站退服告警预测模型构建
1.1 基站退服告警处理机制分析
现阶段的维护方式,导致基站或小区不可避免地在运维实施期间停止服务,极大地影响了客户的感知和体验,并有大量投诉随之产生。
退服处理中最主要的分析依据就是基站的告警数据。告警数据能够及时反映当前基站的运行状态,而重要退服类告警的发生常常伴随着次要告警、性能指标波动等,现有的分析方法仅依靠经验粗粒度估计大面积退服发生的风险,预测的准确性不高,也难以为巡检隐患排查、运维资源针对性调度等提供科学依据。
如何利用海量的历史运维数据挖掘退服规律,准确预测退服基站,提前进行故障隐患排查,已成为减少退服事件发生率、降低运维成本、实现运维思路从被动处理向主动预防转变的关键。
1.2 基站退服告警语料库生成与Word2Vec模型构建
针对上述问题,本文提出了一种基于词向量的退服告警预测方法。该方法首先利用Word2Vec模型,对基站级别的故障、性能、动环告警等数据进行全面分析,重点探究基站历史发生的退服告警及退服告警发生前后基站告警数据的变化情况,尽可能地挖掘次要告警和退服告警数据之间的内在关联。
Word2Vec是一种结构特殊的神经网络,其出发点是考虑了上下文相似的两个词,它们的词向量也应该是相似的,一举解决了传统的One-Hot编码无法代表语义且维度过高的问题。Word2Vec有两大常用模型:以上下文词汇预测当前词汇的CBOW(Continuous Bag-of-Word)模型以及以当前词汇预测其上下文词汇的Skip-gram模型。模型结构如图1所示,以上下文窗口为3举例说明。

图1 Word2Vec常用模型原理
本文所提出的方法以退服告警序列作为预测模型的特征输入,并结合了两种方法生成退服告警序列:
(1)对每个基站的所有告警序列按时间排序,以每固定1~n天无任何告警发生的时间为间隔划分所有告警序列,生成序列语料库,再将所有基站的语料库合并。(2)对每个基站的所有告警序列按时间排序,以每一个退服告警的样本为中心,取前面n1天的所有告警和后n2天的所有告警,按顺序排列,作为一个告警组。将所有的告警组合并,形成告警类型编码语料库。
对生成的告警序列语料库使用Word2Vec模型,训练不同告警的上下文信息编码模型。其参数如表1所示。

表1 Word2Vec模型参数
1.3 特征样本生成
特征样本生成主要有以下3个步骤:
1.3.1 特征数据生成
在完成Word2Vec模型的训练后,输入每个告警标题,将其与模型训练得到的权重矩阵W相乘得到的对应告警的词向量。在生成的词向量空间中,两个向量夹角间的余弦值可以衡量两个个体之间差异的大小:
(1)
余弦值接近1,夹角趋于0,表明两个向量越相似,余弦值接近于0,夹角趋于90°,表明两个向量越不相似。因此,通过计算非退服告警向量与退服告警向量之间的余弦距离,可以得出其他次要告警i与退服告警j之间的相似度δij,其中负值统一置成0。最后,将告警i与J类退服类告警之间的相似度相加,得到告警i的编码:
(2)
1.3.2 标签标注
根据需要预测的天数M(如3天),以该天数M为滚动窗口,遍历统计告警数据,计算每个窗口期间基站是否发生了退服告警。如果发生退服告警则标注为1,如果没有发生退服告警则标注为0。
1.3.3 样本生成
将上述过程产生的特征数据和标签数据按基站与日期相关联,生成训练样本,训练数据使用了试点地市1—10月共10个月的历史告警数据,并以同样的方式生成预测样本,只含输入特征数据,不含标签数据。基站退服告警预测样本生成流程如图2所示。
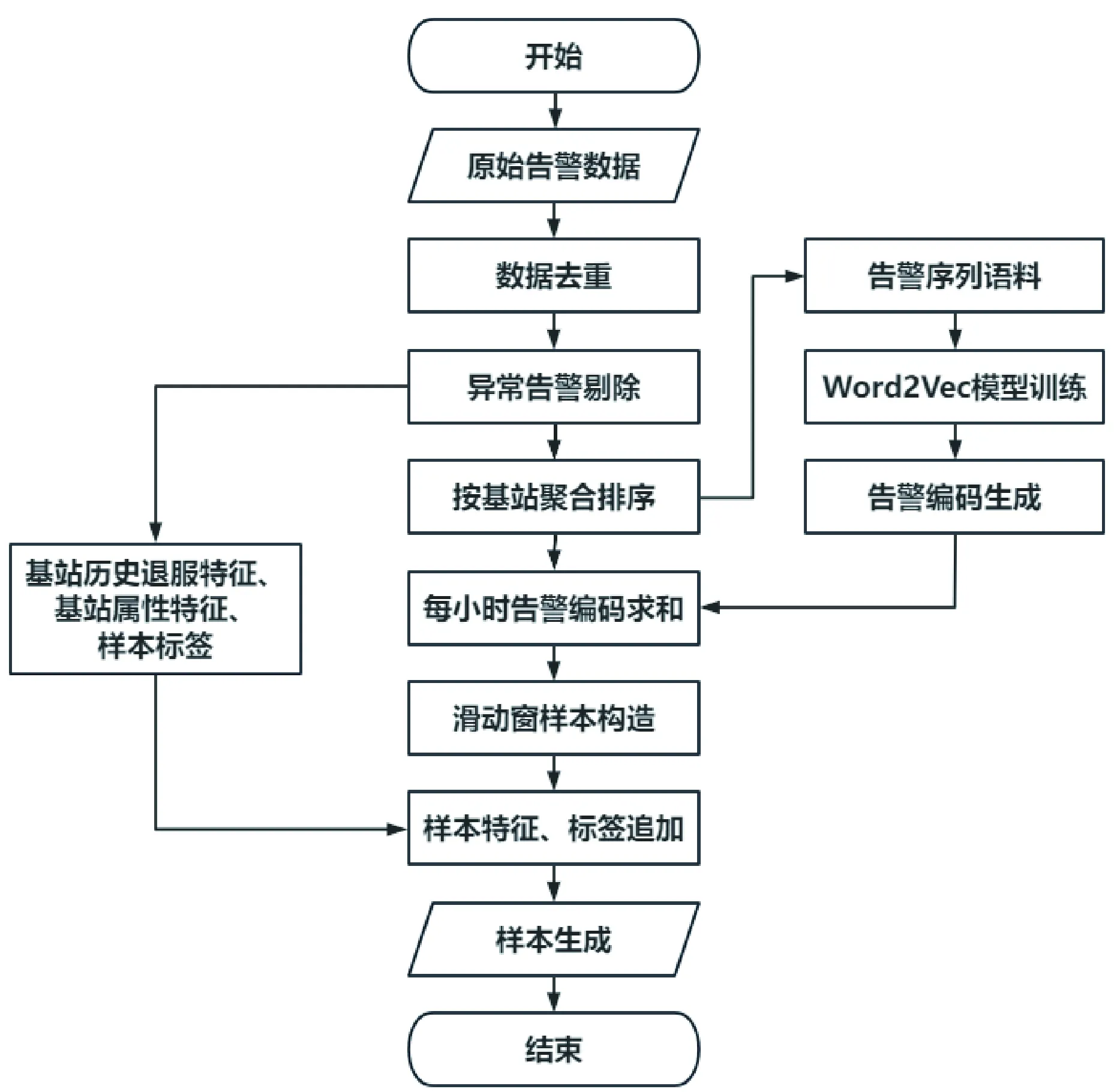
图2 基站退服告警预测样本生成流程
1.4 预测分类模型构建
本文使用基于XGBoost算法和LightGBM算法的二分类模型进行退服告警预测,二者都是基于梯度下降树(Gradient Boosting Decision Tree,GBDT)的提升方法。使用XGBoost和LightGBM的二分类模型进行退服告警预测,具体算法流程如图3所示。

图3 基于XGBoost和LightGBM模型的基站退服告警预测流程
首先对样本按照其所在周数进行分组,采用Group-Kfold进行交叉验证,将原始样本分割成K个子样本集,每一个单独的子样本集被保留作为验证模型的数据,其他K-1个样本集用来训练XGBoost和LightGBM模型,且保证同一周的样本不会同时出现在训练集和测试集上。然后重复K次,使得每个子样本集均被验证一次,同时生成K个模型。Group-Kfold通过避免同一周的样本出现在训练集和测试集上,提高了模型的泛化能力。
此外,为了解决数据集正负样本比例严重失衡的问题,采用Focalloss代替传统的交叉熵损失函数。二分类的交叉熵损失函数如下:
(1-yi)log(1-pi)]
(3)
Focalloss通过引入参数α和γ对负样本和易分样本进行惩罚,其函数形式如下:
(4)
其中,γ>0用于减少易分类样本的损失,使得模型更关注于困难的、错分的样本。例如γ= 2,对于正类样本而言,预测结果为0.95,肯定是简单样本,所以(1-0.95)γ就会很小,这时损失函数值就变得更小。而预测概率为0.3的样本其损失相对很大。此外,加入平衡因子α,加大正样本的权重,平衡正负样本本身的比例不均。
完成K个子模型的训练后,根据其在验证集上的精确率,计算各个模型的权重。预测时,通过输入对当前基站过去一段时间的历史告警数据、工参数据,根据已训练得到的告警编码、历史退服特征、基站属性特征,按时间窗进行滑动形成输入样本,输入XGBoost和LightGBM的各个子模型,即可获取未来一段时间内退服告警发生的概率。最后,根据计算出的模型权值,融合子模型上的预测结果,得出最终的退服告警概率预测值,对未来一段时间内(通常为1~3天)发生退服告警的概率进行准确预测,为隐患提前排查和日常精准巡检提供依据,提升基站排查效率,指导运维人员的巡检工作。
2 基站退服告警预测应用效果
2.1 模型验证
以陕西移动部分基站为例,进行基于词向量的基站退服告警预测算法应用。并通过f1分数(f1-score)、准确率(Accuracy)、精确率(Precision)、召回率(Recall)及混淆矩阵(Confusion)5个指标对已经训练好的退服告警预测模型,使用独立的数据集做验证,输出验证结果如表2所示。模型输出的预测结果如表3所示。

表2 退服告警预测模型输出结果验证

表3 退服告警预测模型输出结果
其中,date为预测周期的第一天,pred_probability为预测的退服告警发生概率,pred_label为是否发生退服告警(1为发生退服,0为未发生退服)。其中,pred_label 通过指定的分类阈值(如表3中取0.5),由pred_probability计算得到。
2.2 试点地市应用效果
将训练好的基于词向量的基站退服告警预测模型应用于陕西省某地市试点基站进行退服预测,得到的试点地市模型输出结果验证如表4所示。

表4 试点地市退服告警预测模型输出结果验证
可见,在试点地市应用基站退服告警预测模型后,预测结果精确率达到96%,召回率约为12%~13%。本方法已经在陕西省移动公司进行了试点应用,通过对高隐患基站的精准定位,为基站巡检和隐患的提前排障做出有力指导,10个地市在试点期内平均退服基站预测准确率大于88%。
3 结语
基于词向量的基站退服告警预测方法,在试点省份预测基站未来一段时间内发生重要退服告警的概率,准确率大于88%,可明显提升基站智能运维的主动性。同时,及时发现设备或服务的相关告警信息,可以对退服故障进行早排查、早修复,从而可以有效地减少因退服故障而带来的经济损失。本算法通过系统性引入AI技术,对大量运维数据进行分析,构建面向无线基站的重要故障预测工具,为网络数智化转型提供新的支持手段。
