改进BERT词向量的BiLSTM-Attention文本分类模型*
2023-10-25杨兴锐赵寿为张如学陶叶辉杨兴俊
杨兴锐,赵寿为,张如学,陶叶辉,杨兴俊
(1.上海工程技术大学 数理与统计学院,上海 201620;2.重庆大学 机械与运载工程学院,重庆 400044;3.上海工程技术大学 管理学院,上海 201620)
0 引 言
由于文本分类在情感分析以及舆情分析等方面有着广泛的应用。近年来,关于文本分类任务的研究引起国内外许多学者的关注,提出了许多的模型,例如:循环神经网络(recurrent neural network,RNN)、长短期记忆(long shortterm memory,LSTM)网络、双向长短期记忆[1](bidirectional LSTM,BiLSTM)网络、卷积神经网络(convolutional neural network,CNN)、BERT[2]模型以及注意力(attention)模型等。传统的文本分类主要有词袋模型或者TF-IDF(term frequency-inverse document frequency)算法、词典匹配算法以及基于统计学的特征提取方法[3,4]。但这些方法提取特征往往需要消耗大量的时间。因此,许多学者致力于深度学习方法的文本分类研究[5,6]。
1 相关工作
RNN在文本分类任务中已经取得了不错的效果,然而当所研究的文本较长时,RNN与LSTM 并不能很好地学习到距离较远的词语之间的“联系”,即缺乏“记忆信息”的能力。BiLSTM通过双向学习语义信息,可以捕获句子的上下文联系。谢思雅等人[7]基于BiLSTM 提出了BiLSTM-Attention模型用于微博情感分析任务。李启行等人[8]结合CNN与BiLSTM提出了双通道DAC-RNN文本分类模型,利用注意力机制与BiLSTM模型分别捕获文本中的关键特征和上下文联系。
随着注意力机制模型的提出,鲍海龙等人[9]以及Tian H等人[10]同时将注意力机制运用到语义分割任务上均取得了良好的效果;张周彬等人[11]建立了相互循环作用的注意力模型用于情感分析任务中;程艳等人[12]基于注意力机制提出了多通道CNN 和双向门控循环单元(bidirectional gated recurrent unit,BiGRU)的文本情感分析模型,提取丰富的文本特征。
本文在改进的BERT词向量、BiLSTM 和Attention 机制的基础上,提出了一种基于改进BERT 词向量的BiLSTMAttention中文文本分类模型。
2 改进BERT词向量的BiLSTM-Attention模型的构建
2.1 模型的结构
本文首先将残差网络引入到BERT模型内部的注意力模型部分中,构建残差注意力模块。然后,将BERT词向量输入到BiLSTM-Attention 模型中,用注意力机制改善Bi-LSTM网络不能长距离记忆信息的不足,然后将BERT 预训练模型中的“[CLS]”对应的输出结果与BiLSTM 模型的输出结果进行向量拼接,最后进行全连接以及SoftMax运算得到文本分类结果。实验表明,本文模型在公开的THUNews数据集上准确率和F1值均优于其他深度学习模型的结果。模型结构如图1所示。

图1 BiLSTM-Attention文本分类模型
2.2 文本表示
由于深度学习模型的输入数据并不支持文本类型。本文首先将句子进行分词,并建立词典映射得到每个词语的序列号。本文的初始输入是每个词语的序号,模型自动查找对应词语的词向量作为BERT模型的输入。模型训练前的词向量是随机生成的,随着模型的训练,词向量不断地得到更新。假设输入的句子长度为N,则文本表示向量为
2.3 BERT预训练模型
BERT预训练模型[5]在较大的数据集上进行训练,最后将训练好的模型运用到下游任务中。BERT 预训练模型有两种基本的训练方法,其中一种方法是将输入变量信息以一个概率值进行掩盖(MASK),训练模型来预测所被掩盖的输入变量,这种方法称MLM(masked language model);第二种训练方法是构建具有上下文关系的句子,在上文句子的句首加入特殊字符“[CLS]”,同样在下文句子的句首也加入特殊字符“[SEP]”;同时准备不具有上下文关系的两条句子。训练模型判断句子是否具备上下文关系。这种方法称为预测序列句子。
BERT模型基本的结构如图2所示。

图2 BERT预训练模型
该模型结构中,每个Trm 结构由注意力层、全连接网络、归一化以及残差单元构成,BERT 模型使用的是双向Transformer编码器[13]。将输入的文本以单个“词”为单位进行分词,将分词结果进行词典映射为序列,从而可以对应查找到相应的词向量,接着输入给微调后的BERT 预训练模型输出文本类别,这样得到的输出向量结果极大地刻画了原始文本的信息。
2.4 BiLSTM
BiLSTM模型较合适更加细粒度的文本分类问题。设S =[x1,x2,…,xn]为模型输入的文本表示,BiLSTM 模型的计算方法如下
该计算过程中,sigmoid(·)为激活函数;ft,at,wt,Ct,outt,Ht分别为遗忘门、输入门、细胞状态、输出门在时刻t的状态和隐含层。
2.5 自注意力机制
自注意力机制的核心是给每个输入的词语进行权重赋值并不断学习更新,将重要词语赋予较大的权重,表示该词语在句子中的作用较大。因此,本文Attention 层主要使用自注意力机制,其基本结构如图3所示。

图3 自注意力机制模型
首先,对于输入文本信息分别乘以相应的权重得到q1,k1以及v1,多个权重值拼接后即可得到Q、K以及V 矩阵,将得到的Q与K 做矩阵运算;接着,将得到的信息值归一化处理;最后,将结果乘以相应的权重矩阵V得到信息输出内容。将上述计算过程用矩阵的方式表示为
2.6 残差网络模型
残差网络模型结构如图4所示[14]。

图4 残差网络模型
x为输入,H(x)为特征的输出,F(x)为残差,其表达式为
特征信息x可以直接与后边层相互连接,这样使得后边的层可以学习到残差值。残差结构通过恒等映射来增大模型的深度,其基本的运算为
式中 xL为第L层深度单元特征信息的表示,当残差值等于0时,残差网络相当于进行恒等映射,使得模型的精度不会受影响。事实上,由于数据的复杂性与多样性,残差值并不会为0,即相当于模型在不断地堆叠层,而学习到更多的特征信息。
2.7 SoftMax层
经过自注意力机制输出的特征向量带有词语权重信息、词语上下文信息以及词语多样化信息。将特征向量作为全连接层的输入,该层中使用ReLU 激活函数进行非线性运算。在进行全连接运算后,将得到的输出值作为Soft-Max层的输入,用于预测文本的分类结果概率。其基本运算为下式
2.8 模型算法分析
模型的计算流程是:对于输入的文本表示首先进行BERT词向量计算,BERT内部的残差注意力计算为
其中
即BERT模型内部多个Trm结构的注意力模块相互残差相连,使得模型学习到的词向量更具多样性;然后将BERT词向量输入到BiLSTM模型中用于学习词语的上下问关系,接着将BERT模型对应“[CLS]”的输出内容与BiLSTM 模型信息的输出内容进行向量拼接,这有利于特征信息的深度融合。设“[CLS]”对应的输出向量为C,BiLSTM 模型的输出向量为h =[h0,h1,…,Ht-1,ht],则向量拼接运算过程为
最后将特征信息进行自注意力、全连接运算以及Soft-Max运算得到分类的结果。
3 模型实验结果与分析
3.1 实验数据
本文选择清华大学THUNews 网站的部分新闻文本数据,共计20万条,另外在互联网上搜集到10 万条最新的文本数据加入一起训练,随机划分26 万条训练集,测试集与验证集各划分2万条。新闻文本分为10 个类别,各个类别的含义如表1所示。
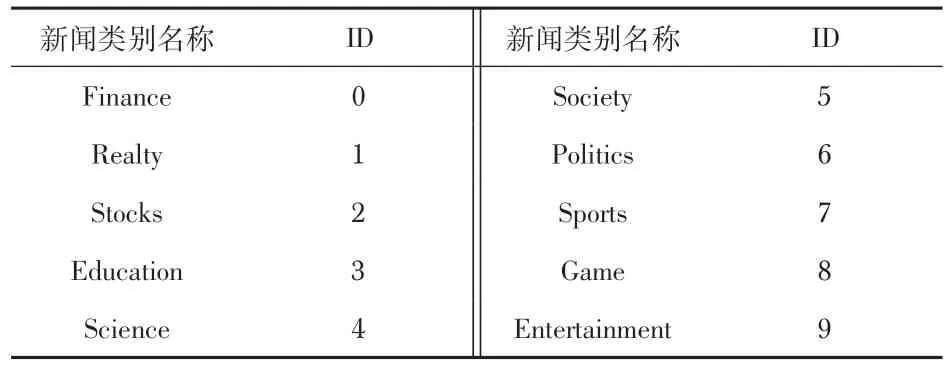
表1 新闻类别名称及其ID
3.2 实验环境与模型参数
环境配置如表2所示。

表2 实验环境配置信息
深度学习模型参数设置如表3所示。
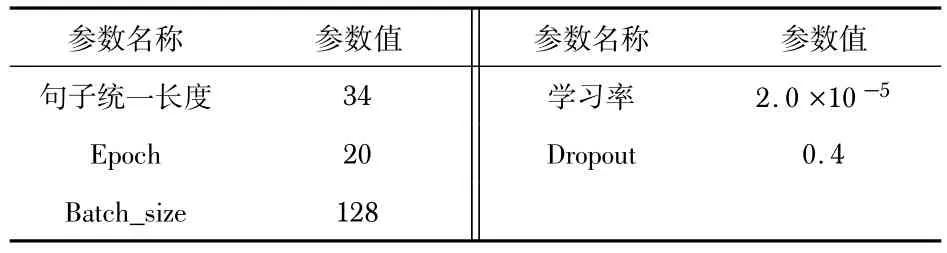
表3 模型参数设置
3.3 实验结果与分析
3.3.1 与BERT词向量模型的对比
首先,将文本数据进行序列标注,序列的长度固定为34,序列长度不足34的用0补充;句子序列长度大于34 的进行裁剪使其长度为34,最后将序列输入到BERT 预训练模型中训练。模型在训练集上训练,训练的结果用验证集来评估,将验证集上结果最好的模型用于测试集上测试并得到最终的结果。将此结果用准确率以及F1值进行评估,其中的F1值的计算公式为
由公式可以看出,F1值是精确率(precision)和召回率(recall)的调和均值,其中的TP、FP 以及FN 由混淆矩阵(confusion matrix)给出,如表4所示。

表4 混淆矩阵
精确率P和召回率R由下式给出
训练过程中为了防止过拟合加入了Dropout[15]方法,其值设置为0.4,表示以0.4 的概率去除某些神经元,达到防止过拟合的作用。该过程本质上在模拟集成学习,其训练的结果如表5所示。

表5 模型的训练结果对比 %
对比BERT +全连接模型以及BERT +BiLSTM模型,本文模型在测试集上的准确率和F1值分别为90.30 %与90.03%;BERT +全连接模型在测试集上的准确率和F1值分别为87.21%与87.68%;BERT +BiLSTM在测试集上的准确率和F1值分别为87.36%与87.10%。本文模型可以学习到注意力残差值,通过残差运算可以学习到句子的多样化信息,同时本文模型通过BERT 模型中“[CLS]”的输出信息与BiLSTM模型的输出信息拼接,融合了更加丰富的特征信息,使得模型可以充分利用特征进行学习,保证模型不过拟合的前提下训练精度得到提高。因此,无论准确率还是F1值,本文模型均优于其他模型,其中,本文模型较BERT +BiLSTM 准确率和F1值在测试集上分别提高了3.37%和3.36%,较BERT +全连接模型准确率和F1值分别提高了3.5%和2.7%,证明了本文模型的有效性。本文所采用的新闻文本句子长度较小,训练集、测试集以及验证集上的句子平均长度是34,BERT +BiLSTM以及BERT +全连接模型在短文本分类任务上很容易克服长期依赖问题。因此,BERT +全连接与BERT +BiLSTM模型的训练精度大致相同。
3.3.2 与其他词向量模型的对比
本文还对比了基于Word2Vec[16]词向量以及FastText词向量的深度学习模型。本文主要利用Word2Vec 工具包进行词向量的训练,该工具使用Skip-gram 和CBOW(continuous bag-of-words)两种模型进行词向量的训练。Skip-gram模型通过上下文信息来预测中心目标词的方式来捕获词语的语义信息。FastText 词向量采用FastText 工具直接得到训练的结果。其训练的结果如表6所示。

表6 模型的训练结果 %
4 结 论
本文引入残差注意力BERT 词向量构建BiLSTMAttention模型。实验结果表明:对比主流的深度学习模型,本文模型在文本的分类任务中取得了比较好的分类结果。
