fMRI 揭示日中双语者的语义和读音加工脑机制
2023-10-21李修军刘小迪杨菁菁
李修军,刘小迪,杨菁菁
(长春理工大学 计算机科学技术学院,长春 130022)
双语者是指掌握两种语言的人,在语言处理的过程中,双语者通常先对词汇进行处理,然后再对整体句子进行判断。整个过程涉及正字法(文字符号的使用规则)的使用,以及对读音(声音)和语义(意思)的加工处理[1]。每种语言都具有其独特的正字法,研究发现正字法距离(两种语言之间的正字法相似性)会影响大脑神经表征的激活模式[2-3]。具有不同正字法距离的双语受试者在进行相同的语义判断时,可能导致不同的大脑激活表征[4]。而且在实验过程中即使对于同一种第二外语(L2),两组双语者不同的母语(L1)正字法,也会使其表现出不同的激活模式[5]。双语者在进行不同的语言加工处理时,呈现出的激活表征会有所不同,特别是在读音和语义两种加工任务上[6-9]。对于双语者语言产生过程中的语义或读音的共同神经表征,之前的一些神经影像学研究表明,读音加工相关的大脑区域主要涉及梭状回(Fusiform Gyrus,FFG)、颞顶叶和额下回等,语义加工相关的大脑区域主要分布在FFG、颞中回(Superior Temporal Gyrus,STG)、颞上回(Middle Temporal Gyrus,MTG)等[10-11]。汉语和日语尽管在日常书写中存在相似的正字法(字形相似),但在读音和语义上却不尽相同,这就可能导致大脑的不同区域被激活。
功能磁共振成像(functional Magnetic Resonance Imaging,fMRI)技术因其具有高空间分辨率和无创性等优点被广泛应用于认知科学领域的研究当中,为研究者能够更直接地分析大脑语言区域提供了有力途径[12-13]。通过对fMRI 数据的统计分析能够得到大脑表征的相关信息,进而解码大脑的语言机制。多体素模式分析(Multi-Voxel Pattern Analysis,MVPA)作为一种大脑解码分析方法,可以精确地定位在每个体素上,在单变量分析的基础上,能够更准确地分析出不同任务条件下的大脑活动模式[14-15]。然而,目前使用MVPA 方法的研究大多将句子任务作为实验刺激[16],并且很少有人使用MVPA 研究读音的相关大脑区域。对于使用MVPA 在词汇任务条件下分析以及对读音加工的相关研究都还需要更多的理论支撑,所以需要研究者在这两个方面进行更深层次的探讨。
双语者大脑加工机制的实验研究通常是将句子或词汇作为实验刺激,想要更好地从源头分析双语者的大脑表征,词汇任务更为合适。决策任务比简单的公开命名任务涉及更多的认知[17]。所以为了更好地探索大脑认知区域,本研究对15 名以日语为L1,汉语为L2 的日中双语受试者进行视觉词汇的语义和读音判断任务。使用基于一般线性模型(General Linear Model,GLM)的单变量分析简要划分大脑不同任务的不同激活区域,然后再采用MVPA 方法进行更深层次的分析,以解码在两种任务条件(语义和读音)下,日语和汉语在实验过程中产生的不同大脑神经激活模式。这种对于具有特殊正字法的双语者大脑加工机制的研究,不仅能够为日中双语者的大脑加工机制带来新的证据,还为双语教学、失语症患者的治疗以及新型人工智能的研发带来新的帮助与启示。
1 材料与方法
1.1 数据收集
(1)受试者
本实验在沈阳医科大学附属盛京医院进行,招募了15 名(7 名女性,8 名男性)沈阳中国医科大学的日本籍留学生,他们的平均年龄是22.9岁。所有受试者均以日语为L1,汉语为L2,且均为身体健康的右利手。受试者的具体情况如表1 所示,其中L2 熟练程度反映了第二语言熟练程度测试的正确率。他们在详细了解知情同意书的情况下签字。该研究经中国医科大学盛京医院伦理委员会批准。

表1 受试者个体特征
(2)数据扫描
(3)实验刺激
每个受试者都需要进行日语和汉语的视觉词汇语义判断任务、读音判断任务和字号判断任务。实验刺激包括日文汉字和中文汉字各96个词,具体以日语为例,将日语的96 个词打乱,每两个词组成一个视觉图片刺激。每个任务(语义判断、读音判断和字号判断)都由这96 个词组成且各生成一个刺激集(S、P和O),每个刺激集包含48 张图片(24 张正向判断,24 张反向判断)。
不同的词汇刺激代表着不同的实验任务,以汉语任务为例,如图1 所示。对于语义词汇判断任务,图片包括两个相同含义的词(包庇和偏袒),以及两个相反意义的词(精华和糟粕);对于读音词汇判断任务,例如,成功和进攻为读音押韵词汇,立刻和油腻为非读音押韵词汇;对于字号判断任务,判断无意义词汇的字符大小是否相同。
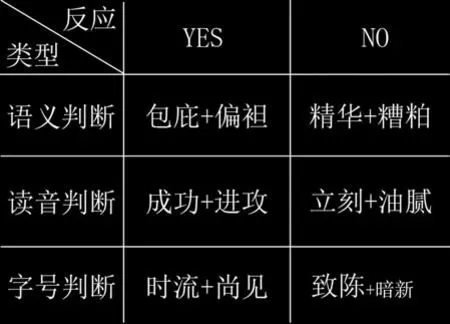
图1 实验刺激
(4)实验过程
受试者进行任务态(词汇决策任务)的fMRI扫描。他们需要分别进行汉语和日语词汇任务,每种语言的任务分为三个会话,每个会话都包含刺激集S、P和O的16 张图片刺激,共48 次实验。实验任务是伪随机的,以保证每个会话中的实验任务的个数是相同且平衡的。
在实验过程中,首先会提示受试者下一个是什么判断任务,显示4 s。每个实验包括两部分,均以黑底白字的方式呈现,第一部分是呈现2.5 s的词汇刺激,两个词汇通过白色十字加号固视点并排连接;第二部分是显示1.5 s 的固视点,要求受试者在这个时间内尽快按下按钮进行词汇决策(图2)。连续进行8 次实验后,会有24 s 的休息时间,期间显示固视点。每个会话有6 个块大约需要6 min,每个受试者需要进行约40 min的实验。

图2 词汇决策实验过程
1.2 数据分析
(1)fMRI 数据预处理
佛经翻译、《圣经》翻译、西学翻译合作模式译者构成的历时变迁为当前中国文化经典英译合作模式译者构成建构提供了诸多启示。
在进行预处理之前需要对采集到的Dicom 图像进行格式转换,使用MRIconvert 软件将其转换成NIFTI 格式。图像的预处理使用Matlab 软件下的SPM12 工具箱(www.fil.ion.ucl.ac.uk)。首先,对转换完成的图像进行时间切片校正和头部运动校正。然后使用工具箱中提供的由蒙特利尔神经研究所研制的标准模板(MNI)对图像进行空间标准化。最后,采用8 mm×8 mm×8 mm 的全宽各向同性高斯核进行空间平滑。在执行MVPA 时使用未平滑的数据,以防止单个体素的激活不明显。
(2)单变量分析
为了探讨日中双语者在进行词汇语义判断任务、词汇读音判断任务和字号判断任务时有关语义和读音的神经表征区域,采用基于GLM的单变量分析方法对其进行分析。三种不同的任务模式被建模为三个独立的回归模型,并与每个受试者的标准血流动力学响应函数进行卷积。以往的经验将视觉刺激通过字符特定表征转换为整体的语义或读音表征,所以这里的字号判断是一种基线。语义和读音任务与基线进行比较,使用随机效应模型对受试者进行组分析,并采用单样本T检验进行分析。阈值设定为P<0.05(Uncorrected)和P<0.001(Uncorrected)。
(3)多体素模式分析
使用PRoNTo 工具箱(www.mlnl.cs.ucl.ac.uk)进行多体素模式分析,研究两种语言分别在语义和读音上的大脑激活差异。首先,使用未平滑的fMRI 数据,以单个块为独立事件定义GLM的设计矩阵以计算大脑活动的激活情况。然后,基于前人的研究和单变量分析得到的结果绘制感兴趣区域(Region Of Interest,ROI),使用WFUpickatlas 工具箱构建掩码,并在固定区域的体素中分析大脑的激活模式。再使用线性支持向量机(Linear Support Vector Machine,LSVM)分类器对语义和读音任务条件下的两种语言(日语和汉语)进行分类,并使用留一法(Leave one block out)训练模型。最后,通过置换检验来检验模型的有效性和可靠性。
2 实验结果
2.1 行为学结果
fMRI 扫描所有受试者在执行词汇决策任务时的大脑,行为学分析结果如图3 所示。


图3 两种语言的行为学分析结果
图3中CS 为汉语语义任务;JS 为日语语义任务;CP 为汉语读音任务;JP 为日语读音任务;**P<0.01;***P<0.001。图3(a)、图3(b)分别表示语义和读音任务的平均反应时间,图3(c)、图3(d)分别表示语义和读音任务的平均正确率。在平均反应时间上,日语和汉语在语义和读音的任务条件下均无显著差异;而在平均正确率上,日语和汉语在语义和读音任务条件下均存在显著差异。
2.2 单变量分析结果
日语和汉语在语义和读音判断任务中激活的大脑区域如图4 所示,其中图4(a)、图4(b)显示汉语和日语在语义任务下的激活脑区(P<0.05,Uncorrected),选取大于5 的所有体素;图4(c)、图4(d)显示汉语和日语在读音任务下的激活脑区(P<0.001,Uncorrected),选取大于5 的所有体素。CS 为汉语语义任务;CP 为汉语读音任务;CO 为汉语字号任务;JS 为日语语义任务;JP 为日语读音任务;JO 为日语字号任务;R 为右脑。

图4 两种语言在语义和读音判断任务下的大脑激活图
汉语词汇语义判断任务的大脑激活涉及大量的左半球区域。包括舌回、FFG、STG、MTG、角回(Angular Gyrus,AG)、缘上回(Supramarginal Gyrus,SMG)以及部分额叶区域。右脑也有少量的激活区域。汉语词汇读音判断任务激活的脑区包括枕叶的视觉皮层、顶叶的SMG 和中央前回,颞叶的MTG、STG 和部分区域,还有额叶的额下回三角部(Pars Triangularis,PT)和额下回岛盖部(Pars Opercularis,PO),以及扣带皮层、辅助运动区等。
日语在语义和读音任务下的激活脑区相对较少。语义任务的主要激活区域包括双侧颞叶部分区域、STG、扣带回皮层和中央后回。读音任务主要激活脑岛、PO、PT、顶下缘角回、辅助运动区及视觉相关区域等。
图5(a)代表汉语与日语在语义任务条件下的差异脑区(P<0.001,Uncorrected),图5(b)代表汉语与日语在读音任务条件下的差异脑区(P<0.001,Uncorrected),选取大于5 的所有体素。对于语义任务,两种语言的差异脑区包括额叶部分区域、中央前回和辅助运动区、顶叶的楔前叶、SMG、AG 和中央后回、颞叶的海马区和MTG、枕叶部分区域、扣带皮层;对于读音任务,两者存在激活差异的区域在中央旁小叶、中央前回、枕叶的枕上回和舌回、额叶的额中回和额上回、楔前叶、顶上回、扣带回皮层、MTG。

图5 两种语言在语义和读音判断任务下的差异脑区
2.3 多体素模式分析结果
结合前人对语义和读音任务的讨论以及单变量分析的结果,最终选取了14 个大脑经典语言加工区域的ROI,包括双侧AG、SMG、FFG、PO、PT、STG 和MTG,探讨14 个脑区在两种不同任务(语义和读音)条件下日语和汉语的分类准确率。通过使用单样本T 检验将每个ROI 的平均分类准确率与偶然准确率(50%)进行对比,以此判定是否成功分类。如图6 所示,其分别表示语义和读音判断任务的分类准确率。AG 为角回;SMG 为缘上回;FFG 为梭状回;PO 为额下回岛盖部;PT 为额下回三角部;STG 为颞上回;MTG为颞中回;L 为左脑;R 为右脑;*P<0.05;**P<0.01;***P<0.001。

图6 14 个ROI 在两种任务下日语和汉语的分类准确率
在词汇语义任务中,双侧AG、MTG,左侧FFG、PT,右侧SMG、PO 和STG 具有较高的分类准确率,这说明两种语言在右半球的激活差异更明显。对于词汇读音任务,在双侧AG、SMG、FFG、PO、PT、MTG 和左侧STG 具有显著的分类准确率,这表明两种语言在大部分经典语言区域,特别是左侧SMG,具有较大的激活表征差异;而在右侧STG 可能存在两种语言的相似激活模式。
3 讨论
本研究采用单变量分析和MVPA 两种方法探究双语者在词汇语义加工和读音加工过程中的双语脑机制。
单变量分析结果发现,日中双语者在执行两种词汇决策任务时,表现出同一个激活特点,即汉语加工过程中产生的大脑神经激活表征区域相比日语加工更为广泛,而这些区域主要集中在大脑的认知控制区域,这一发现与Liu 等人[11]的研究一致。对于汉语读音和语义任务以及日语读音任务,其脑区激活情况与Price[18]的研究结果一致。而日语语义任务的激活区域较少且涉及到多个右脑区域,这可能与受试者对日文汉字[19]的语义进行识别有关。
受试者在观察呈现出的视觉词汇时,首先通过舌回、距状裂周围皮层等视觉皮层进行初步的加工,接着会在FFG 对词汇进行识别。如果是语义加工可能会在左侧AG、左侧MTG 等区域进行语言信息的整合;如果是读音加工,则可能在SMG、STG 等区域进行词汇的记忆提取和听觉转换。接下来如果将词汇复述,不断地默读词汇,则可能激活PO、PT 等区域。
在本研究中,使用MVPA 方法对14 个脑区在两种加工任务下汉语和日语的大脑活动模式进行分类,发现双侧AG、右侧PO、右侧STG 和右侧MTG 在词汇语义加工中具有显著的分类准确率。这些区域在词汇语义任务下表现出两种语言不同的大脑神经激活模式。
AG 具有分析视觉信息并将分析后的信息传输到中枢神经系统的能力。单变量分析结果显示,在汉语语义任务中,左侧AG 激活明显。两种语言在左侧AG 的激活差异或许与双语者对L1 更熟悉有关[20]。双侧AG 均参与一般视觉的语义加工[21],而在右侧AG 体现出的两种语言的激活差异可能与两种语言表达能力的强弱有关。
PO 在复述或阅读信息时非常重要。右侧PO的分类准确率较高,这可能与受试者进行不同的词汇语义决策有关,涉及个体的大脑变化[22]。右侧STG 在记忆关联中起着重要作用,其在语义判断过程中产生的激活差异可能与双语者两种语言的不同记忆连接[23]有关。右侧MTG 是命名语言中心,与语言网络密切相关,但这两种语言之间的具体差异是难以区分的。
在词汇读音加工过程中,除右侧STG 外,其余13 个区域均表现出显著的分类准确率。特别是在左侧SMG 区域,分类精度很高。SMG 是经典的听觉中枢,两种语言之间发音的差异可能是分类准确率较高的原因之一。在右侧STG,有研究者发现其是处理汉字声调的特异性区域[24],但在这里没有发现两种语言激活差异的可能原因是日中双语者对中文汉字的声调存在一定的基础。
尽管本研究得到了日中双语者在语义和读音任务条件下两种语言的大脑神经激活表征差异,并探讨了产生这种差异的原因,但仍然存在一些不足之处。首先,在受试者的数量方面。本文选取了15 名受试者参与了本次实验,受试者的数量较少可能会导致实验结果受到个体差异的影响较大;其次,实验中使用以单个块为独立事件定义GLM 的设计矩阵,这可能导致单个刺激间的体素值过于接近,进而造成分类误差。所以在未来的研究当中,需要对实验进行改进,选取更多的受试者参与实验,并以单个刺激为独立事件定义GLM 设计矩阵,完成两种语言大脑活动模式的分类。
4 结论
综上所述,本研究利用单变量分析和MVPA方法探索日中双语者的大脑机制,发现两种语言在共同语言处理区域的激活存在明显差异以及共同点。结果表明,无论是在词汇语义还是读音加工任务条件下,相比于L1、L2 的激活表征更广泛,涉及大脑的认知控制区域。日语和汉语的词汇语义加工在双侧AG、右侧PO、MTG 和STG 的激活上存在较大差异,且右脑的激活差异更为明显。在词汇读音加工中,两种语言在13个ROI 中的分类准确率均相对较高,其中左侧SMG 的差异更明显,而在右侧STG 可能存在两种语言共同的神经表征区域。这些结果为进一步理解双语者的大脑机制提供了证据,并为双语教学、失语症患者的治疗以及新型人工智能技术的发展带来了新的启示。
