TenrepNN:集成学习的新范式在企业自律性评价中的实践
2023-10-21赵敬涛赵泽方岳兆娟李俊
赵敬涛,赵泽方,岳兆娟,李俊*
TenrepNN:集成学习的新范式在企业自律性评价中的实践
赵敬涛1,2,赵泽方1,2,岳兆娟1,李俊1,2*
(1.中国科学院 计算机网络信息中心,北京 100083; 2.中国科学院大学 计算机科学与技术学院,北京 100049)( ∗ 通信作者电子邮箱lijun@cnic.cn)
为了应对互联网环境中企业自律性低、违规事件频发、政府监管困难的现状,提出一种针对企业自律性评价的双层集成残差预测神经网络(TenrepNN)模型,并融合Stacking和Bagging集成学习的思想提出一种集成学习的新范式Adjusting。TenrepNN模型具有两层结构:第1层使用3种基学习器初步预测企业评分;第2层采用残差修正的思想,提出残差预测神经网络以预测每个基学习器的输出偏差。最后,将偏差与基学习器评分相加得到最终输出。在企业自律性评价数据集上,相较于传统的神经网络,TenrepNN模型的均方根误差(RMSE)降低了2.7%,企业自律性等级分类准确率达到了94.51%。实验结果表明,TenrepNN模型集成不同的基学习器降低预测方差,并使用残差预测神经网络显式地降低偏差,从而能够准确评价企业自律性以实现差异化的动态监管。
企业自律性评价;集成学习范式;残差预测神经网络;显式偏差修正;互联网企业监管
0 引言
当今人们的生活与互联网的关系越来越密切,截至2022年6月,我国网民规模为10.51亿[1]。部分企业通过申请网络文化经营许可证在网络上经营或宣传。这类公司数量众多、经营自律性低、违规现象频发且调查取证难,这对政府在网络文化市场中监管企业提出了新的挑战[2]。
为了及时发现风险事件,加强对高风险企业的管理,督促企业自律,构建政府监管与市场主体自律相结合的动态监管服务机制,开拓集成学习、深度学习等先进的机器学习方法在该领域的实践,本文设计了双层集成残差预测神经网络(Two-layer ensemble residual prediction Neural Network, TenrepNN)模型,根据企业经营特征评估企业的自律性,使监管部门聚焦于自律性差的企业,促使企业提高自律性和公信力。
集成学习模型融合多个弱学习器,在预测性能和模型鲁棒性方面都优于单个机器学习模型,适用于企业自律性评价这种特征数目多、数据集规模小且需要精准预测的任务;但是在集成学习框架中,基学习器很大程度地影响模型集成效果。基学习器需要同时满足准确性和多样性,才能在集成时取得较好的表现[3]。由于集成模型一般较复杂,对存储空间的需求大且预测速度较慢,基学习器的选择需要大量经验积累。随着自动机器学习技术的发展,在一些数据集上使用自动机器学习的效果已经超越了人工调参的机器学习模型[4]。但是自动机器学习框架使用的基础模型种类多,难以根据实际需要精细改动其中的子模型,延迟可以使用自动学习技术帮助人们选择基学习器,减少使用先验知识。
本文的主要工作如下:
1)建立了一种新的集成学习的范式Adjusting。第1层融合Stacking和Bagging的思想,用数据集或它们上采样的某个子集在自动机器学习框架中训练,根据结果选择最合适的模型,对选择的模型使用不同的子数据集训练获得不同的基学习器;第2层拟合基学习器输出与真实结果的残差,整合基学习器的预测值和残差值。
2)设计了残差预测神经网络。使用神经网络预测第1层各基学习器的残差,模型的输出由基学习器的预测结果和神经网络预测的残差相加。通过对第1层的残差预测,减小机器学习模型的预测偏差。
3)提出了用于企业自律性评价的TenrepNN模型。本文将集成学习应用于企业自律性评价,根据企业的经营信息端到端地计算企业的自律性分数,批量评估企业自律性,辅助监管者定位风险企业,实现对不同企业的差异化监管。
本文模型的基本架构如图1所示。

图1 TenrepNN模型框架
1 相关工作
1.1 企业自律性评价
企业自律性评价是为了帮助政府判断企业是否遵循网络文化市场监管规范的新任务。依靠人工监管众多企业的方式难以应对互联网中庞大的数据量,因此应用机器学习评判企业的遵规守纪情况。如果模型能对企业的自律性打分,管理人员就能将更多精力放在自律性分数低且具有潜在风险的企业。当这些自律性差的企业出现违规行为时,监管人员可以第一时间发现并处理事件,及时采集证据为执法部门提供依据。
国内外关于企业自律性的研究较少,且各国国情不同,难以找到一套通用的评价体系。对企业评价模型的研究方向集中在经济领域,以传统的概率分配和数学建模的方法为主,侧重点在于评价指标的构建和特征选择。近年有一些企业贷款信用评价方面的研究,可以加以改进应用于自律性评价。
张珏[5]通过决策树筛选特征,使用逻辑回归模型分析中小企业的信用风险;邓大松等[6]根据企业经营特征,使用逻辑回归模型分析是否向该企业提供贷款;陶爱元等[7]先使用主成分分析方法从企业财报中提取企业特征,再运用数据包络分析算法给出介于0~1的信用指标;卢悦冉等[8]为了对企业进行风险评估,建立基于逻辑回归的评分卡模型,辅助银行的信贷决策;秦晓琳[9]使用极端梯度提升树(Extreme Gradient Boosting, XGBoost)模型结合企业的定性指标和定量指标计算企业的信用评分,根据评分决定是否通过企业的贷款申请。以上研究的重点大多聚焦在特征设计上,使用的模型较为简单,未能深入探索模型结构。
1.2 集成学习
集成学习就是训练多个模型,再对模型的输出结果归纳总结。单个基学习器对于某个样本的误差可能较大,但是各个基学习器具有一定差异,在不同数据上的表现不同,集成能够避免选择最差的学习器,集成后的效果一般有所提高。常用的两种集成学习范式是Stacking和Bagging[10-11],两种集成策略的实现过程如图2所示。

图2 Stacking和Bagging集成学习对比
1.2.1Stacking模型堆叠
Stacking是模型集成的一种方法,一般由两层或多层机器学习模型堆叠构成[12-13]。在第1层,模型设置多个不同类别的基学习器,每个基学习器都使用部分数据集训练,将这些基学习器的输出作为新特征添加至数据集,作为高层模型的输入[14]。高层模型通常使用线性回归等简单学习器,学习更好地组合基模型的输出。
通过基学习器的多层堆叠降低模型的方差和偏差,但是这种方式的训练步骤复杂,对上层模型的参数敏感,且依赖经验选择基学习器和高层模型,因此需要通过实验调整Stacking堆叠的参数。随着堆叠层数和基学习器数的增多,所需的存储空间随之增加,模型的预测速度也越慢。
对于Stacking,虽然采取了两层甚至多层的堆叠方案,但是每一层只是相当于在原有的数据中加入了一维新的特征[15],难以衡量新加入的特征对最终的预测的作用,它关注的重心仍然在数据层面,即用学习器输出扩充数据特征。
1.2.2Bagging模型组合
Bagging是另一种集成学习的范式,它通过训练多个独立的基学习器,然后简单结合(平均或投票)每个基学习器的结果,以获得一个强学习器[16]。Bagging中的基学习器通常使用同质弱学习器,这些弱学习器相互独立训练并行学习,然后对所有基学习器的输出作一个简单的平均(回归问题)或者投票(分类问题),Bagging的关注点是获得一个方差比基学习器更小的集成模型。在训练阶段,Bagging随机从原始数据集采样一定比例的子数据集,使用采样的子数据集训练某个学习器,由于每次采样的数据各不相同,各个基学习器通过使用不同的训练数据产生差异,提升基学习器集成效果。
Bagging集成学习[17]自身也有相当大的局限。它通常只使用一种基学习器,基学习器的选择较大地影响了模型效果,并且各个基学习器的输出只作简单的投票或平均,效果不同的学习器对最终结果产生的影响相同。
2 数据及其处理
2.1 数据集介绍
由于目前没有关于企业自律性的公开数据集,为了训练模型,从网上公开数据搜索拥有网络文化经营许可证的公司相关信息,构建企业自律性评分数据集。
分别从企业基本属性、不良信用记录和企业表彰信息等方面的数据衡量一个公司的自律性情况。通过对齐、去噪和去重等操作处理数据,最终得到3 868家企业的经营特征,按照3∶1随机划分训练集和测试集,训练集共2 902条数据,测试集共966条数据。数据集中各个企业的自律性分数从1到100不等。数据集各个维度的信息见表1。
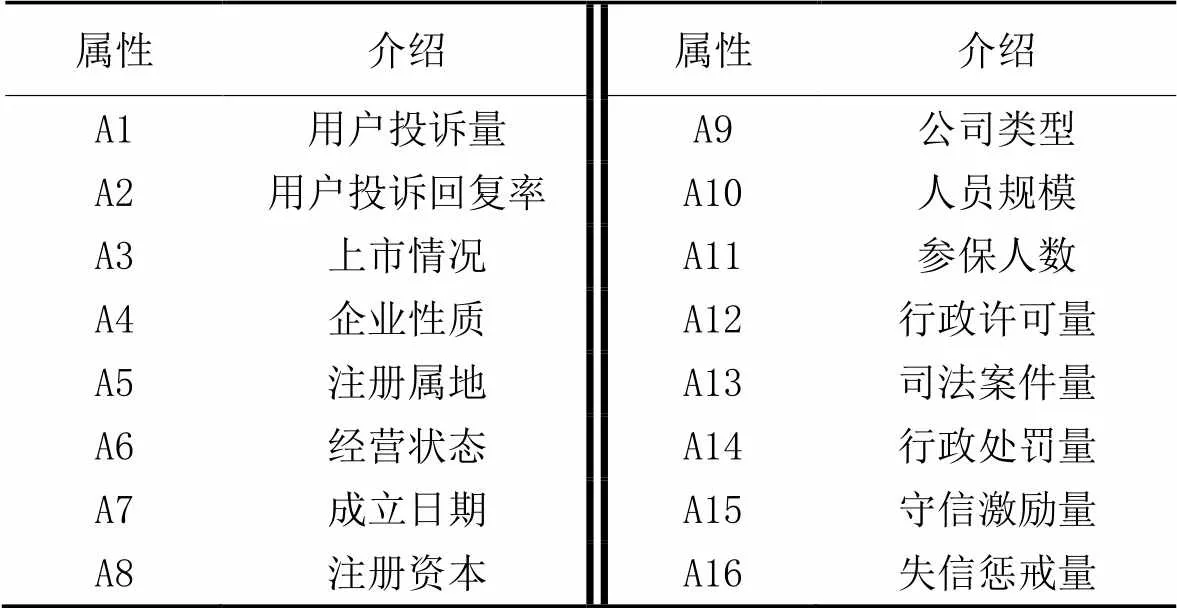
表1 企业自律性评价数据集信息
2.2 特征工程
数据的原始特征存在离散类特征和连续类特征,对这两种特征采用不同的处理方法。
2.2.1连续类型特征处理
对于连续类特征,首先将公司成立日期转化为公司成立距今的天数以方便计算,其次将它与用户投诉量、用户投诉回复率、参保人数、注册资本、行政许可量、行政处罚量、守信激励量和失信惩戒量等连续特征进行对数变换,减轻长尾分布的数值特征对机器模型效果的损害。
对于人员规模特征,该维度既包含数值也包含区间量,并且存在数据之间的大小关系,因此设计了一套按照区间分箱的规则,将公司人员按规模分为小公司、较小公司、中等公司、较大公司和大公司这5类,分别使用数字1~5表示。
2.2.2离散类型特征处理
离散特征包括上市情况、企业性质、注册属地、经营状态和公司类型。对于上市情况,由于原始数据类别划分过细,无法充分训练模型,所以将公司分为未上市公司、传统上市公司和新三板上市公司这3类。对于注册属地,按照2022年最新的城市梯次划分,将公司的注册属地划分为一线城市、新一线城市和其他城市。对于经营状态,按照公司是否正在经营划分为两类:第一类包含注销、吊销和迁出这3种情况;第二类包含存续和在业这两种状态。由于特征的离散取值较少,为了减少离散数值本身的大小带来的干扰,对5个离散特征进行独热编码,处理后,拼接离散特征和连续特征作为第1层基学习器的输入。
3 双层集成企业自律性评价方法
3.1 Adjusting集成学习
本文提出了一种新的集成学习范式Adjusting,为了解决Stacking训练过程复杂的问题,改进Stacking框架,并融合了Bagging集成学习中数据采样的思想。相较于Bagging,Stacking集成学习中的基学习器是异质的(Bagging中是同质基学习器),更容易从数据中学习不同方面的特征,使模型拥有更好的泛化性能,适用于训练数据较少的情况;此外,Stacking在第2层可以使用多种机器学习模型集成第1层的基学习器,以此获得更高的预测准确性。Adjusting继承了Stacking的优势,同时将关注点从数据样本转移到基学习器,使用自动机器学习技术选择基学习器,认为基学习器本身是不准确的,通过高层的学习器拟合它们的残差。相较于Bagging,Adjusting无论是基学习器的选择范围,还是输出融合的方式都具有更好的灵活性和可操作性[18]。相较于Stacking,Adjusting不必与原始数据特征相结合,只利用基学习器的输出作为训练样本,减轻了高层学习器的学习压力,强化了基学习器的重要性。
如图3所示,Adjusting集成学习的第1层使用自动机器学习框架选择最适合当前数据的种基学习器模型,将原数据集折交叉或直接采样成不同的份子数据集,使种机器学习模型在每份子数据集都训练一次,得到个训练好的基学习器;在第2层,利用残差学习的思想,计算基学习器输出值与真实值的差距,将基学习器的预测值和第2层计算的残差融合,得到模型最终输出。
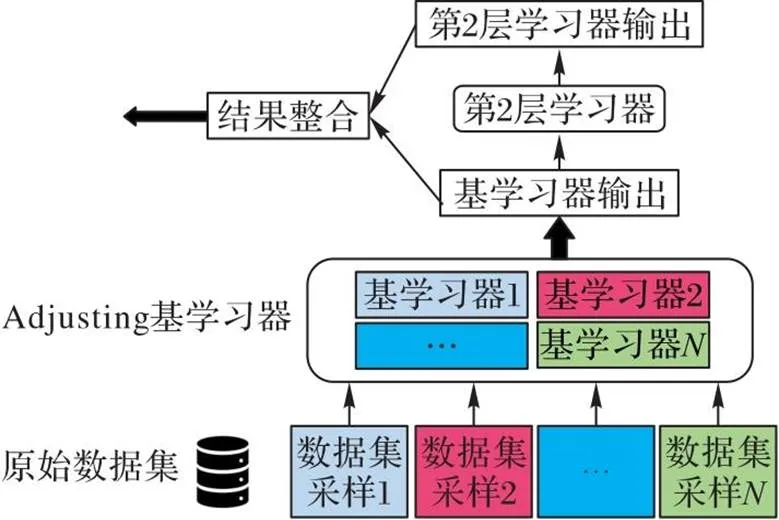
图3 Adjusting集成学习范式
3.2 残差预测神经网络
针对Adjusting集成学习框架第2层的残差拟合问题,设计了用于预测第1层中每个基学习器的与真实标签的残差的神经网络,网络结构如图4所示。
该网络使用单隐藏层,并且输出维度等于输入维度。以第1层基学习器的预测分数作为输入,网络预测在输入某样本时各个基学习器的输出值与真实标签的差值。
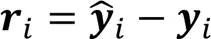
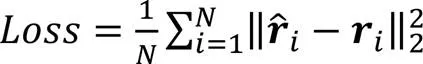
模型的最终输出为各个学习器第1层的评分预测值与第2层的残差预测值相加,求平均得到:

使用残差预测神经网络,使某个基学习器对某个样本的残差不仅依赖自身,也依赖其他基学习器的输出值。
3.3 自动机器学习选择基学习器
为了探索自动机器学习框架在基学习器选择上的应用,使用自动机器框架AutoGluon[19]选出最适合当前数据集或当前数据集随机采样的子数据集的基学习器模型。
将数据集输入AutoGluon,框架使用多个不同的机器学习方法对它回归拟合,回归误差较小的8个模型如表2所示。

表2 AutoGluon框架中不同模型的表现
基于集成学习的准确性和差异性原理,同时考虑在模型效果与模型复杂度两个方面的均衡,本文的自律性评价模型使用在测试集和验证集上得分最高的3种模型,分别为:类别梯度提升树(Categorical features gradient Boosting, CatBoost)[20]、轻量梯度提升机(Light Gradient Boosting Machine, LightGBM)[21]和XGBoost[22]作为第1层的基学习器。
3.4 双层集成企业自律性评价模型
本文根据提出的Adjusting集成学习框架,将上述3种基学习器与残差预测神经网络结合,设计了TenrepNN模型。
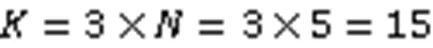
在第2层,模型通过残差预测神经网络,以基学习器在训练集产生的预测得分作为输入,以训练集样本的标签与各个基学习器预测得分之间的差值作为网络的预期输出,个基学习器共有个差值。通过预测每个基学习器的残差,显式地减小模型的预测偏差。
最后,将第1层基学习器产生的预测值与第2层神经网络拟合的每个基学习器的残差相加取平均值,获得该样本对应的自律性评分。
虽然在训练时需要先训练好第1层的基学习器,再计算残差训练第2层的神经网络,但是在测试和正式使用时,输入一条样本,可以端到端地计算该样本的预测分值,在面对批量的企业数据时,能够快速获得各个企业的自律性分数。
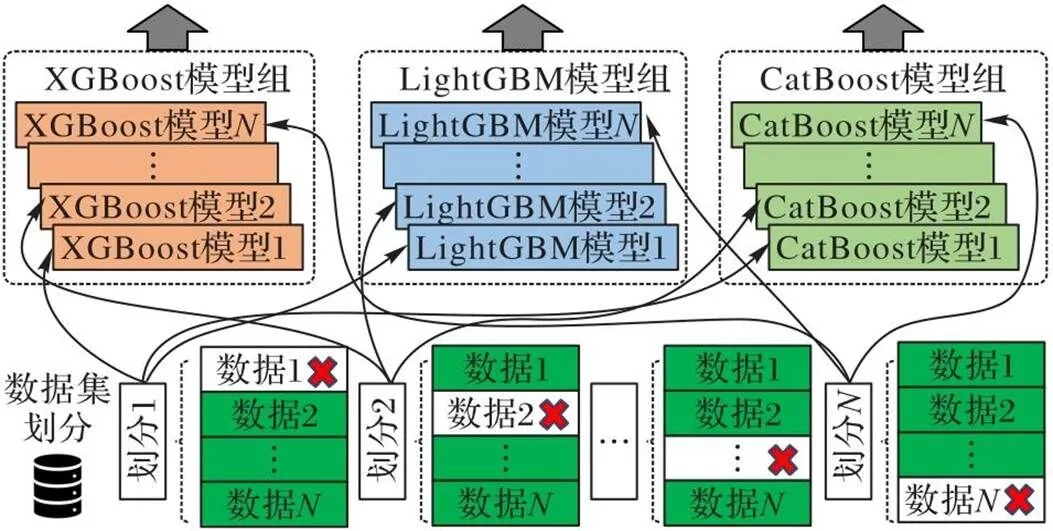
图5 三种基学习器的训练示意图
4 实验与结果分析
4.1 算法评价指标
4.1.1回归任务评价指标
企业自律性评价任务本质是一个对企业自律性评分进行拟合的回归任务,可以通过常用的回归学习评估指标评价模型。本文使用均方根误差(Root Mean Square Error, RMSE)评价模型效果。
RMSE是预测值与真实值的误差平方根的均值,是均方根误差(Mean Square Error, MSE)的算术平方根,真实值与模型预测值的差距越大,均方根误差就越大,理想状况下RMSE为0。
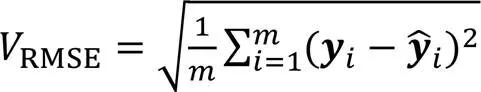
4.1.2企业自律性等级分类指标
除了评价模型的回归拟合能力,为了提高模型输出的可解释性,根据企业自律性评分分类企业,将所有企业划分为5个等级,各个等级与企业自律性分数的关系见表3。
根据模型拟合分数与样本真实分数是否处于同一等级判断模型是否产生了正确的输出,并基于分类正确的数量计算准确率(Accuracy),准确率为正确分类的样本个数占总样本个数的比例:
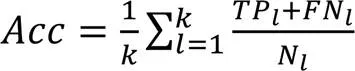

表3 企业自律性等级划分情况
4.2 模型超参数搜索与设置
4.2.1基学习器超参数网格搜索
对于XGBoost等树模型,超参数较多且模型表现受部分超参数影响较大。为了防止第1层使用的3种树模型因为超参数设置不当导致性能下降,对模型效果影响较大的超参数进行网格搜索,既节省参数搜索的时间又能使模型性能获得最大程度的提高[23]。
根据不同超参数的取值要求,设置两级参数搜索范围。首先使用较大的步长在大范围内确定最优参数所在的大致位置,再设置小的步长在大致位置附近精细搜索。经过搜索,各个基回归器的超参数设置见表4。
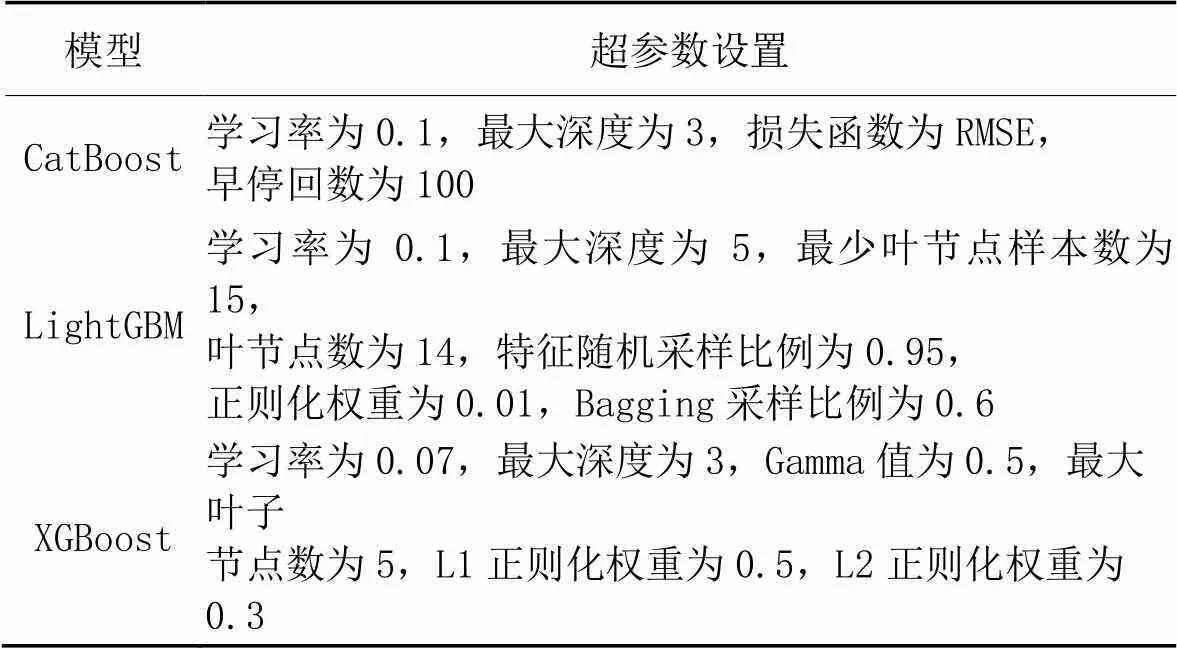
表4 基模型超参数设置
4.2.2残差预测神经网络超参数设置
对于第2层的残差预测神经网络,网络输入为上层所有基学习器的预测分数。第1层共使用3种机器学习模型,每种模型训练5个,共计15个基回归器。网络输出是这15个学习器预测分值与真实分数的残差,使用反向传播算法训练。网络超参数设置如表5所示。

表5 残差神经网络超参数设置
4.3 实验结果分析
4.3.1基学习器结果分析
为了验证3.2节使用自动机器学习框架选择基层学习器的准确性,使用逻辑回归、岭回归、随机森林、神经网络、CatBoost、LightGBM和XGBoost这7种机器学习模型拟合企业自律性评分数据集,统计这些模型在测试集上的RMSE和企业自律性等级分类准确率,结果如表6所示。
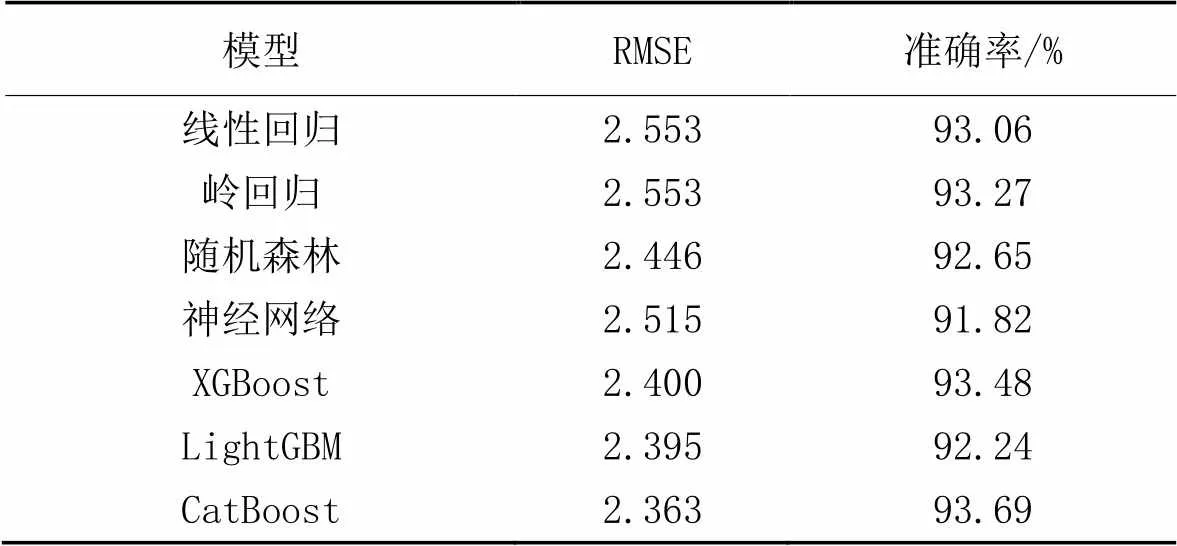
表6 单个模型在企业自律性评价数据集上的表现
树模型由于容易产生随机性,受训练数据样本分布的影响较大且自身准确度较高,适合用作集成学习的基学习器[24]。实验结果显示,在数据集上表现较好的前3个学习器是CatBoost、XGBoost和LightGBM,与自动机器学习框架给出的结果相同。只有当基学习器的效果较好且互相存在一定差异时,对多个基学习器集成才能获得效果上的提升。
4.3.2双层集成模型结果分析
为了与提出的残差预测神经网络进行对比,在第1层输出上分别使用线性回归、CatBoost、XGBoost、LightGBM和传统神经网络[25]这5种机器学习模型整合基学习器的输出。传统神经网络的隐藏层单元数为10,但输出层维度为1,直接输出样本的自律性分数。实验结果见表7。

表7 不同第2层模型下的实验结果
数据显示,相较于线性回归和树模型,神经网络模型用于集成学习第2层时拟合效果更好。与表现次好的传统神经网络相比,使用残差预测神经网络的TenrepNN模型在均方根误差上也降低了2.7%。特别地,当神经网络模型直接应用于原始特征时,效果比XGBoost等树模型差;而在基学习器的输出之上使用神经网络,效果优于树模型。XGBoost等模型用于第2层时,预测误差相较于单层没有明显减少,甚至有所增加。无论是XGBoost等树模型还是传统神经网络,本文提出的残差预测神经网络在所有指标上的表现都更好。
拟合基学习器的残差相较于直接拟合自律性分数,网络的输出维度从1增大到基学习器的个数。当某个学习器表现较差时,可以充分利用其他学习器输出的预测信息,通过神经网络计算的残差修正该学习器。采用残差预测神经网络作为第2层,即使不同的样本在某个基学习器上的预测得分相同,也会因为其他大多数学习器的得分不同使得该网络输出的残差有所区别,使模型最终能给出更准确的预测结果。
此外,基于残差的神经网络还增强了整个模型的可解释性,当模型接收一条数据后,可以查看残差预测神经网络的输出,确定各个基学习器的预测差值,并调整或再训练表现较差的基学习器。
4.3.3与自动机器学习结果的比较
自动机器学习框架AutoGluon在第1层共使用了13个不同的基学习器,在第2层使用了线性回归整合第1层的输出。
TenrepNN模型只使用了3种表现较好的基学习器,防止拟合效果差的模型影响最终输出。从表8可以看出,TenrepNN模型在两个指标上的表现均超过了自动机器学习框架AutoGluon。

表8 所提模型与自动机器学习框架AutoGluon的比较
4.3.4残差预测神经网络的消融实验
通过消融实验验证残差预测神经网络输出结果的有效性。去掉第2层的残差预测神经网络,使用第1层所有基学习器的平均得分作为最终预测,实验结果如表9所示。

表9 残差预测神经网络的消融实验结果
实验结果表明,相较于直接输出基学习器输出的平均值,使用残差神经网络能够通过建模第1层的输出与真实值的残差,降低预测评分的均方根误差并提高自律性等级分类的准确率,说明提出的残差预测网络能够对基学习器的预测值进行有效的纠偏。
4.3.5与其他集成学习方法的比较
为了验证集成学习范式Adjusting的有效性,将提出的TenrepNN模型与其他集成学习方法在企业自律性评价数据集上进行对比。
模型首先与Stacking和Bagging集成学习对比,为保证其他集成学习方法的实验效果,在Stacking基模型的设置上,仍然使用CatBoost、XGBoost和LightGBM这3种单独表现最好的树模型作为第1层的基学习器,第2层使用线性回归做模型融合;在Bagging模型的设置上,由于Bagging集成要求只使用一种基学习器,故使用表现最好的CatBoost作为Bagging基学习器,输出时将所有基学习器的预测分数取平均。
除了Stacking和Bagging外,还选取了AdaBoost[26]和梯度提升决策树(Gradient Boosted Decision Tree, GBDT)[27]两种有代表性的集成学习模型对企业自律性评价数据集进行拟合。AdaBoost是一种基于迭代的集成学习方法,它将关注点放在拟合误差大的样本上,提高困难样本的训练次数并在最终集成时根据各个基学习器的误差大小加权组合。GBDT也是一种应用广泛的集成学习方法,它的思想是在每一次迭代中使用损失函数的负梯度值作为当前模型误差值的近似,并利用这个近似值训练更高层模型。
AdaBoost和GBDT是Boosting集成学习的两种典型代表。Boosting集成学习又叫提升集成学习,与Bagging和Stacking的思想不同,Boosting在训练过程中通过调整样本权重或损失函数的方式串行组织各个基学习器,把多个基学习器叠加以减小模型总的预测偏差[18]。由于在Boosting中各个基学习器逐个串行训练,没有考虑降低模型方差的影响,训练时间成本也较高。更重要的,面对企业自律性评价这种数据集规模较小的任务,Boosting容易受误差值干扰导致预测不准确。
在实验中,AdaBoost集成学习的基学习器也设置为单独使用效果最好的CatBoost;而GBDT由于算法自身的限制,基学习器只能使用决策树。5种集成学习模型的对比结果如表10所示。
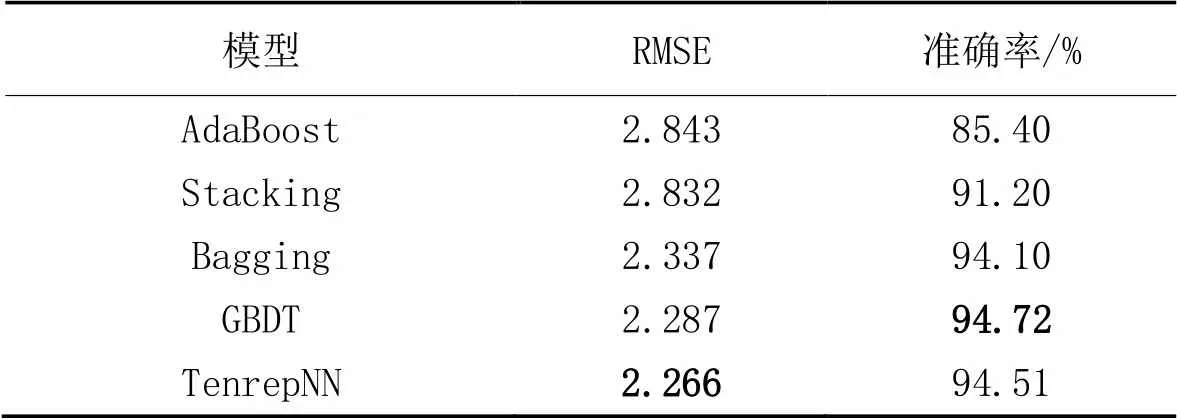
表10 本文模型与其他集成学习方法的比较
由表10可知,本文设计的TenrepNN模型在企业自律性评价数据集上取得了优秀的实验结果。在RMSE指标上,本文模型优于其他4种传统的集成学习方法,并且本文模型的分类准确率与表现最好的GBDT模型非常接近。
5 结语
为了评估企业的自律性,本文提出了双层集成残差预测神经网络(TenrepNN)模型,集成了3种基学习器降低模型的方差,设计残差预测神经网络显式地减小模型的偏差。具体地,模型在第1层通过自动机器学习选择基类模型,使用采样出的不同数据子集训练;在第2层,设计残差预测神经网络,拟合第1层基学习器的输出与真实标签之间的残差,最后将基学习器的输出与对应的残差相加再求均值。实验结果证明,本文提出的残差预测神经网络在企业自律性评价数据集上的表现超过了传统神经网络和XGBoost等树模型。另外,与Stacking相比,本文提出的Adjusting集成学习范式更简洁直接,与Bagging相比,更灵活准确,然而它的有效性还需要在更多数据集上验证。由于企业自律性评价是一个典型的回归任务,残差学习的思想容易应用;而对于分类问题,可以考虑使用两个概率分布之间的距离代替残差。在分类任务中的实际效果,仍有待进一步的研究。
[1] 中国互联网络信息中心. 第50次中国互联网络发展状况统计报告[R/OL]. (2022-08-31) [2022-04-22].https://www.cnnic.net.cn/NMediaFile/2022/0926/MAIN1664183425619U2MS433V3V.pdf.(China Internet Network Information Center. The 50th statistical reports on China’s internet development[R/OL]. (2022-08-31) [2022-04-22].https://www.cnnic.net.cn/NMediaFile/2022/0926/MAIN1664183425619U2MS433V3V.pdf.)
[2] 卢加元,张晓东. 我国网络文化市场分级监管问题研究[J]. 江苏商论, 2021(7):23-26.(LU J Y, ZHANG X D. Research on classified supervision of China’s internet culture market[J]. Jiangsu Commercial Forum, 2021(7): 23-26.)
[3] 张春霞,张讲社. 选择性集成学习算法综述[J]. 计算机学报, 2011, 34(8):1399-1410.(ZHANG C X, ZHANG J S. A survey of selective ensemble learning algorithms[J]. Chinese Journal of Computers, 2011, 34(8):1399-1410.)
[4] GIJSBERS P, LeDELL R, THOMAS J, et al. An open source AutoML benchmark[EB/OL]. (2019-07-01) [2022-04-22].https://arxiv.org/pdf/1907.00909.pdf.
[5] 张钰. 中小企业财务预警与信用评分研究[J]. 经济研究导刊, 2021(30):63-65.(ZHANG Y. Research on financial early-warning and credit scoring of small and medium-sized enterprises[J]. Economic Research Guide, 2021(30):63-65.)
[6] 邓大松,赵玉龙. 我国商业银行小微企业申请评分卡构建及验证研究[J]. 投资研究, 2017, 36(5):149-159.(DENG D S, ZHAO Y L. Research on the application card on small enterprise in the commercial bank[J]. Review of Investment Studies, 2017, 36(5):149-159.)
[7] 陶爱元,吴俊. 基于DEA方法的我国上市中小企业信用评分研究[J]. 征信, 2014, 32(6):52-56.(TAO A Y, WU J. Study on credit rating for China’s listed SMEs based on DEA method[J]. Credit Reference, 2014, 32(6):52-56.)
[8] 卢悦冉,芮英健,袁芳,等. 基于评分卡模型下中小微企业的信贷决策[J]. 中国市场, 2021(27):53-54.(LU Y R, RUI Y J, YUAN F, et al. Credit decision of SMEs based on score card model[J]. China Market, 2021(27):53-54.)
[9] 秦晓琳. 中小企业借贷信用分析系统的设计与实现[D]. 北京:北京交通大学, 2019:49-56.(QIN X L. Design and implementation of credit analysis system for SME lending[D]. Beijing: Beijing Jiaotong University, 2019:49-56.)
[10] 姜正申,刘宏志,付彬,等. 集成学习的泛化误差和AUC分解理论及其在权重优化中的应用[J]. 计算机学报, 2019, 42(1):1-15.(JIANG Z S, LIU H Z, FU B, et al. Decomposition theories of generalization error and AUC in ensemble learning with application in weight optimization[J]. Chinese Journal of Computers, 2019, 42(1):1-15.)
[11] ZHOU Z H. Ensemble Methods: Foundations and Algorithms[M]. Boca Raton, FL: CRC Press, 2012:47-50.
[12] WOLPERT D H. Stacked generalization[J]. Neural Networks, 1992, 5(2): 241-259.
[13] 李珩,朱靖波,姚天顺. 基于Stacking算法的组合分类器及其应用于中文组块分析[J]. 计算机研究与发展, 2005, 42(5):844-848.(LI H, ZHU J B, YAO T S. Combined multiple classifiers based on a Stacking algorithm and their application to Chinese text chunking[J]. Journal of Computer Research and Development, 2005, 42(5):844-848.)
[14] RASCHKA S. MLxtend: providing machine learning and data science utilities and extensions to Python’s scientific computing stack[J]. The Journal of Open Source Software, 2018, 3(24): No.638.
[15] DŽEROSKI S, ŽENKO B. Is combining classifiers with Stacking better than selecting the best one?[J]. Machine Learning, 2004, 54(3): 255-273.
[16] BREIMAN L. Bagging predictors[J]. Machine Learning, 1996, 24(2):123-140.
[17] AGARWAL S, CHOWDARY C R. A-Stacking and A-Bagging: adaptive versions of ensemble learning algorithms for spoof fingerprint detection[J]. Expert Systems with Applications, 2020, 146: No.113160.
[18] SAGI O, ROKACH L. Ensemble learning: a survey[J]. WIREs Data Mining and Knowledge Discovery. 2018, 8(4): No.e1249.
[19] ERICKSON N, MUELLER J, SHIRKOV A, et al. AutoGluon-Tabular: robust and accurate AutoML for structured data[EB/OL]. (2020-03-13) [2022-05-14].https://arxiv.org/pdf/2003.06505.pdf.
[20] DOROGUSH A V, ERSHOV V, GULIN A. CatBoost: gradient boosting with categorical features support[EB/OL]. (2018-08-24) [2022-03-11].https://arxiv.org/pdf/1810.11363.pdf.
[21] KE G, MENG Q, FINLEY T. LightGBM: a highly efficient gradient boosting decision tree[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 3149-3157.
[22] CHEN T, GUESTRIN C. XGBoost: a scalable tree boosting system[C]// Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2016:785-794.
[23] KOMER B, BERGSTRA J, ELIASMITH C. Hyperopt-Sklearn: automatic hyperparameter configuration for scikit-learn[C/OL]// Proceedings of the 13th Python in Science Conference [2022-04-22].https://conference.scipy.org/proceedings/scipy2014/pdfs/komer.pdf#:~:text=With%20this%20paper%20we%20introduce%20Hyperopt-Sklearn%3A%20a%20project,Scikit-Learn%20components%2C%20including%20preprocessing%20and%20classifi-%20cation%20modules.
[24] ZHANG L, SUGANTHAN P N. Benchmarking ensemble classifiers with novel co-trained kernel ridge regression and random vector functional link ensembles [Research Frontier][J]. IEEE Computational Intelligence Magazine, 2017, 12(4):61-72.
[25] LIU W, WANG Z, LIU X, et al. A survey of deep neural network architectures and their applications[J]. Neurocomputing, 2017, 234: 11-26.
[26] DRUCKER H. Improving regressors using boosting techniques[C]// Proceedings of the 14th International Conference on Machine Learning. San Francisco: Morgan Kaufmann Publishers Inc., 1997: 107-115.
[27] FRIEDMAN J H. Greedy function approximation: a gradient boosting machine[J]. The Annals of Statistics, 2001, 29(5): 1189-1232.
TenrepNN:practice of new ensemble learning paradigm in enterprise self-discipline evaluation
ZHAO Jingtao1,2, ZHAO Zefang1,2, YUE Zhaojuan1, LI Jun1,2*
(1,,100083,;2,,100049,)
In order to cope with the current situations of low self-discipline, frequent violation events and difficult government supervision of enterprises in the internet environment, a Two-layer ensemble residual prediction Neural Network (TenrepNN) model was proposed to evaluate the self-discipline of enterprises. And by integrating the ideas of Stacking and Bagging ensemble learning, a new paradigm of integrated learning was designed, namely Adjusting. TenrepNN model has a two-layer structure. In the first layer, three base learners were used to predict the enterprise score preliminarily. In the second layer, the idea of residual correction was adopted, and a residual prediction neural network was proposed to predict the output deviation of each base learner. Finally, the final output was obtained by adding the deviations and the base learner scores together. On the enterprise self-discipline evaluation dataset, compared with the traditional neural network, the proposed model has the Root Mean Square Error (RMSE) reduced by 2.7%, and the classification accuracy in the self-discipline level reached 94.51%. Experimental results show that by integrating different base learners to reduce the variance and using residual prediction neural network to decrease the deviation explicitly, TenrepNN model can accurately evaluate enterprise self-discipline to achieve differentiated dynamic supervision.
enterprise self-discipline evaluation; ensemble learning paradigm; residual prediction neural network; explicit deviation correction; internet enterprise supervision
This work is partially supported by National Key Research and Development Program of China (2019YFB1405801).
ZHAO Jingtao, born in 1998, M. S. candidate. His research interests include recommendation system, machine learning.
ZHAO Zefang, born in 1996, Ph. D. candidate. His research interests include natural language processing, sentiment analysis.
YUE Zhaojuan,born in 1984, Ph. D., senior engineer. Her research interests include computing propagation, data mining.
LI Jun,born in 1968, Ph. D., research fellow. His research interests include computer network, artificial intelligence.
1001-9081(2023)10-3107-07
10.11772/j.issn.1001-9081.2022091454
2022⁃09⁃30;
2022⁃12⁃15;
国家重点研发计划项目(2019YFB1405801)。
赵敬涛(1998—),男,山东聊城人,硕士研究生,主要研究方向:推荐系统、机器学习; 赵泽方(1996—),男,山西临汾人,博士研究生,主要研究方向:自然语言处理、情感分析; 岳兆娟(1984—),女,河南驻马店人,高级工程师,博士,主要研究方向:计算传播、数据挖掘; 李俊(1968—),男,安徽桐城人,研究员,博士,主要研究方向:计算机网络、人工智能。
TP391.4
A
2023⁃01⁃05。
