一种基于变分推断的可评判推荐算法
2023-10-21姜宜鑫韩国敬
吴 杰,姜宜鑫*,韩国敬,马 驰
(1.辽宁科技大学 计算机与软件工程学院,辽宁 鞍山 114051;2.鞍山市气象局,辽宁 鞍山 114004;3.惠州学院 计算机科学与工程学院,广东 惠州 516007)
0 引 言
随着互联网的不断发展,信息量的不断暴涨,每位用户找寻自己想要的需求信息更是难上加难。为了解决信息过载问题,帮助用户快速准确地找到自己想要的东西,推荐系统应运而生,并且被认为是缓解信息过载问题的最有效办法之一[1]。
传统上推荐系统分为:基于内容的推荐系统、协同过滤推荐系统和混合推荐系统[2-4]。目前,主流推荐任务的实现依赖用户的历史交互行为(例如点击记录,购买记录)。然而推荐系统很难从这些隐式反馈中挖掘用户的真正偏好,使推荐结果受到很大程度的限制,并且给不出推荐某个商品的理由。对于这些问题,可评判(Critiquing)推荐系统[5-8]不仅可以对推荐的商品进行解释,也可以通过用户对解释项的评判挖掘用户的偏好,从而提高推荐质量。相比传统推荐系统,通过用户的评判,推荐系统能及时获取用户的显示反馈,更能准确反映用户的真实偏好。
整个推荐过程分为两步,首先通过用户与项目的历史交互行为,推荐系统生成解释项及推荐项。关键字作为商品的解释项,用来解释推荐的项目,如图1(a)所示。其次,对于生成的项目,如果没有满足用户需求,则可以对解释项进行评判。用户对“棕色”这个关键字进行评判,代表用户并不偏好“棕色”属性,而是对“水果味”“焦糖”这两个属性比较感兴趣,推荐系统则可以通过偏好反馈来重新推荐,如图1(b)所示。
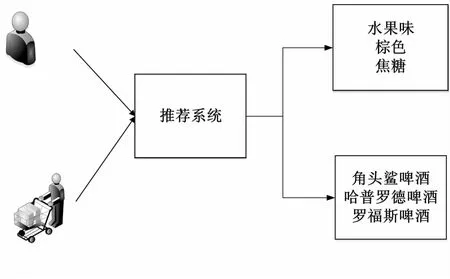
(a)
该文的贡献如下:
(1)使用变分推断进行了模型定义和推导,提出了基于变分推断的可评判推荐算法(CRS-VI)。
(2)利用解释关键字的先验分布对解释向量聚类。相对于文献[6-7]中使用自编码器获取解释向量,并且在损失函数中去除了回归预测项,减少了对推荐准确性的影响。
(3)使用贝叶斯神经网络实现模型。消融实验表明贝叶斯神经网络模型在推荐性能上有更好表现。
(4)基于BeerAdvocate[9]数据集的实验表明,在各项指标上都有所提升,表明了该方法的有效性,并且实验代码已经在Github开源(代码:https://github.com/wujieaa/VariationalInferenceCRS)。
1 相关工作
1.1 可评判推荐系统
可评判推荐不仅可以使推荐项目具有可解释性,也可以根据用户对项目的偏好反馈获取显式信息,从而挖掘用户偏好,再对推荐项目调整,以此提高推荐质量。Wu Ga等[6]提出一种端到端的学习框架,通过拓展神经协同过滤实现对项目解释及评判,并且在隐含变量中嵌入基于关键字的反馈,从而提高推荐质量,最后以打分的形式体现推荐结果。
Luo Kai等[5]提出利用变分自编码器,生成推荐项以及解释项,通过联合概率来建模用户偏好及关键字,不仅提高了推荐质量,而且提升了整体性能。
Sanner等[8]提出基于线性嵌入推荐算法,将关键字属性与用户首选项嵌入对齐,并且利用嵌入的线性结构和推荐预测制定基于线性程序(LP)的优化问题,以确定用户反馈的最佳权重。
Antognini等[7]提出一种基于多模态建模假设的可评判推荐算法,在一个弱监督学习下训练模型,以模拟完全和部分观察到的变量。有效地提高推荐以及评判的质量,并且在评判的速度上,也取得了不错的效果。
1.2 变分推断
变分推断[11]是一种近似推断的方法。通过更新变分参数,使观察到的数据最大化,并且引入了一个近似分布,用KL散度[12]使近似分布逐渐接近真实的后验分布。
变分自编码器是变分推断的广泛应用之一。变分自编码器是一种深度生成模型,是由Kingma等[13]提出基于变分推断的生成式网络结构,利用两个神经网络建立两个概率密度分布实现推断网络和生成网络。
变分自编码器在推荐系统领域中的应用也很广泛,并且也是解决推荐问题的方法之一[14]。
Krishnan等[15]把变分自编码器应用在基于隐式反馈的协同过滤推荐任务中,通过非线性的概率模型解决线性因子模型的局限性问题,并且引入了一个具有多项式似然函数的生成模型。通过实验表明,多项式相似性非常适合于隐式反馈数据的建模。
Li等[16]提出以协同过滤为框架,把项目内容和评分信息联合建模,通过无监督的方式,学习商品内容的潜在表示,并可以从评分数据以及项目内容中学到用户及项目间的隐式关系。
2 问题定义
可评判推荐系统的任务是通过用户编码生成关键字的解释项和推荐项,并对解释项关键字属性进行评判来修改用户的兴趣偏好,并再次向用户推荐匹配的商品的过程。形式化地说,该过程可以表述如下两个步骤:
z,c=f(u)
(1)
其中,u代表用户编号,z代表解释项,c代表推荐的项目编号。
(2)
3 基于变分推断的可评判推荐算法
基于变分推断的思想,该文通过贝叶斯神经网络来实现模型,不仅可以生成解释项也可以生成推荐项。并且以用户交互的角度对解释项进行偏好反馈,准确挖掘用户的兴趣偏好,从而提高推荐质量。本节主要包括3部分:(1)模型推导;(2)模型优化;(3)模型实现。
3.1 模型推导
由于解释项可以看作用户与商品的交互的属性信息,因此公式(1)可以写为z=f(u),c=g(z)。推荐项目c的概率可写为:
(3)
其中,u为用户向量编码,c为推荐项。该公式通过变分推断的思想进行简化,如公式(4)所示。
(4)
公式(4)不能直接进行优化,所以转而优化变分下界(ELBO)[13],如公式(5)所示:
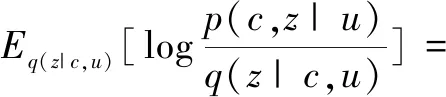
Ez~q(z|u,c)[logp(c|z,u)]-
KL(q(z|u,c)‖p(z|u))
(5)
其中,u为用户的向量编码,z为隐变量,c为推荐项,q(z|u,c)是用来接近真实分布的后验分布,可以假设为均值μ和方差σ的正态分布,μ和σ的值用神经网络拟合。计算公式如公式(6)(7)所示:
(6)
(7)
其中,sigmoid(x)=1/(1+exp(-x)),ψ是解释项向量,φuc是用户和项目的特征向量。在公式(5)中,推荐项的分布p(c|z)也是通过神经网络来实现,如公式(8)所示:
(8)
其中,ψz为解释项目的概率向量,φc为推荐项目的嵌入向量。模型的先验分布p(z|u)假设为标准正态分布,均值为μ'方差为1,这个先验分布可以直接通过用户与商品的交互信息来进行计算。如公式(9)所示:
(9)
其中,N为用户与解释项目相关的推荐项目总数,Nu为包含解释项目的用户推荐项目数量。公式(5)中,KL散度[12]是用来衡量两个分布的差异,该文对后验概率分布进行两种假设来计算KL散度。第一种:假设后验概率分布为伯努利分布,解释项信息看似为离散的分布,来更准确地预测解释项,如公式(10)所示;第二种:假设后验概率分布为标准正态分布,如公式(11)所示:
DKL(p(z|u)‖q(z|c,u)=
(10)
DKL(p(z|u)‖q(z|c,u))=

(11)
在公式(5)中,期望Ez~q(z|u,c)需要通过采样来完成,但是由于采样不可以进行反向传播,无法通过神经网络来实现采样,所以该文提出了两种方法对期望进行近似,以达到近似采样的效果。
(1)直接使用q(z|c,u)神经网络生成的概率作为期望值,不进行采样。
(2)通过Gumbel-Softmax技巧[19]实现采样,如公式(12)(13)所示:
gi=-log(-log(ui))
(12)
(13)
其中,u为服从均匀分布的独立样本,g为Gumbel分布,T为温度参数,控制Softmax函数平滑程度。再通过Softmax函数生成Z。所以,训练时逐渐降低T,以逐步逼近真实的离散分布。
3.2 模型优化
为了防止过拟合发生,公式(5)引入正则化[17],所以总体损失函数,如公式(14)所示:
L=Ez~q(z|u,c)[logp(c|u)]-
(14)
其中,λ为正则化参数,控制正则化强度,θ为神经网络参数。
由于公式(8)计算量较大,采用负采样进行优化,如公式(15)所示:
(15)
其中,σ(x)=1/(1+exp(-x)),pn(v)为噪声分布,K为负样本数。
3.3 模型实现
模型采用贝叶斯神经网络与神经协同过滤相结合,使用公式(14)作为损失函数,以用户和项目编码向量作为输入,通过Embedding层生成用户和项目嵌入编码,连接全连接层和Sigmoid函数生成解释项概率,选取概率值最高的前k个关键字作为解释项,其中k为超参。再通过神经网络学习均值及方差,使每个权重服从不同的高斯分布,最后生成推荐项。通过训练来优化均值和方差,在得到解释项的同时也可以得到推荐项,如图2所示。

图2 CRS-VI模型
用户再对不感兴趣的解释项进行评判,采用修改解释项中关键字的概率值(概率置0),以此实现用户的偏好反馈。系统则会重新推荐出符合用户偏好的商品。
4 实 验
4.1 数据集
使用数据集BeerAdvocat[9]对模型进行训练及评测。该数据集是啤酒商品的数据集,包含用户对啤酒商品的评论信息。数据集中包含6 370个用户4 668个项目,以及263 278条评论。其中80%进行训练,20%进行测试。
关键字使用和CE-VNCF[6]相同的处理方式:从数据集评论中提取高频名词和形容词,为了防止选取的关键字具有随机性,采用点线互信息(PMI)对关键字进行修剪。一共在数据集中摘取了75个关键字作为项目的解释。
4.2 实验参数设置
通过以下几个方面介绍参数设置(见表1):(1)学习率;(2)正则化权重;(3)嵌入层的维度;(4)负采样个数。
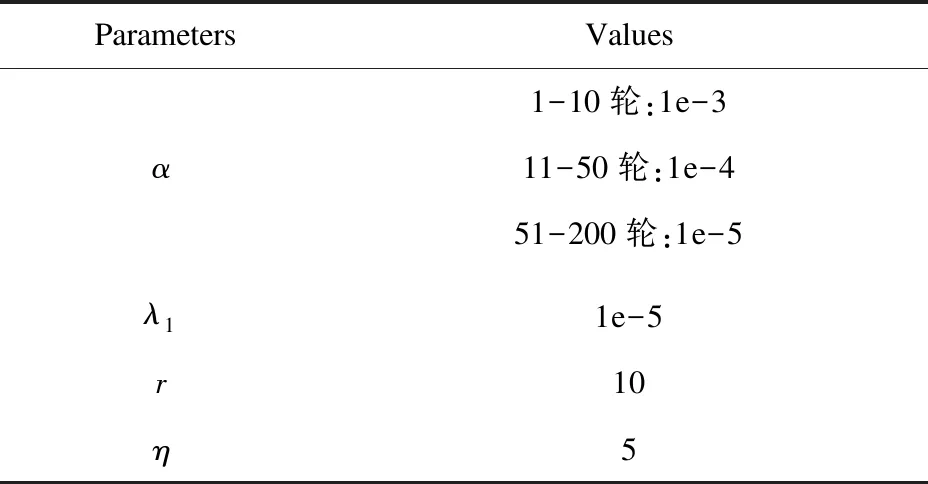
表1 实验参数
其中,α表示学习率,λ1表示正则化权重,r表示嵌入层的维度,η表示负采样个数。
实验环境的设置:显卡:nvida rtx 2060 6G;内存:32G;操作系统:Windows 10;pytorch版本:pytorch 1.7.1。
4.3 评价指标
通过5个指标衡量推荐项的质量。分别为:R-precision、NDCG、Recall、MAP、Precision。
R-precision表示排序后真实推荐项出现在前R个的概率,越大说明推荐项与真实用户喜好的商品越相关,R-precision越大越好。
NDCG(Normalize Discounted Cumulative Gain)是一种对搜索引擎排序进行度量的有效性方法,用来衡量推荐系统返回的列表是否优秀。一个推荐系统返回一些商品并生成一个列表,想要算出这个列表有多优秀,每一项都有一个相关的评分值,通常这些评分值是一个非负数,这就是gain(增益)。此外对于这些没有用户反馈的项通常设置起增益为0。
Recall称为召回率或查全率,就是预测的信息有多少是用户真正喜欢的商品,如公式(16)所示:
(16)
其中,TP为被模型预测为正的正样本,FN为被模型预测为负的正样本。在推荐系统中,MAP是十分重要的衡量指标。将所有类别检测的平均正确率(AP)进行综合加权平均而算出。Precision被称为精准率或精度,指我们预测的真实商品中有多少是用户真正感兴趣的商品,如公式(17)所示:
(17)
其中,TP为被模型预测为正的正样本,FP为被模型预测为正的负样本。
对于评判任务,加入了F-MAP[5]评价指标,以此衡量评判前与评判后推荐的项目是否有效,如公式(18)所示:
(18)
其中,N表示推荐的项目数量,Sk表示观察到的项目,MAP@表示平均精度。修改关键字前推荐的项目平均精度与修改关键字后推荐的项目平均精度相比是正值则代表评判是有效的。希望通过修改关键字使关键字对应的项目,在重新推荐后的排名下降,代表评判是有效的。
4.4 实验结果对比
该文关注于可评判推荐领域,故选用如下两个模型作为基线模型进行比较,通过实验证明提出的模型在推荐任务上的有效性。
(1)CE-VNCF[6]:一种端到端的模型,拓展了神经协同过滤[10]模型,增加了解释和评判的神经网络。
(2)CE-VAE[5]:改进了CE-VNCF的评判策略,输入层也进行了优化。
CRS-VI-GS:对损失函数中的期望,使用Gumbel-Softmax的方法[18]进行采样,并把后验分布看作伯努利分布计算KL散度。
CRS-VI-ND:使用重参数技巧对标准正态分布进行的采样。
CRS-VI:模型直接运用概率对期望值进行计算。
通过实验表明,这三种模型收敛速度很快,训练达到50轮左右就可以收敛,如图3所示。

图3 模型收敛效果
通过实验表明,这三种模型在可评判推荐任务的准确率、召回率、排序准确度及归一化折损累计增益上均有着较突出的表现,这是由于模型利用解释关键字的先验分布对解释向量聚类。相对于CE-VAE[5]中使用自编码器获取解释向量,并且在损失函数中去除了回归预测项,优化了损失函数,减少了对推荐准确性的影响,这使得推荐项的评价指标均有提升。评判和解释任务实验结果如表3和图4所示。解释项任务在召回率方面具有很高的水平,评判解释项任务上的表现也具有相似的水平,部分指标提升并不明显,这种情况是由于模型使用KL散度,让关键字的概率分布接近先验分布,属于聚类操作,表现结果弱于有监督的学习。所以,在评判解释项的任务上并没有得到很好的结果。
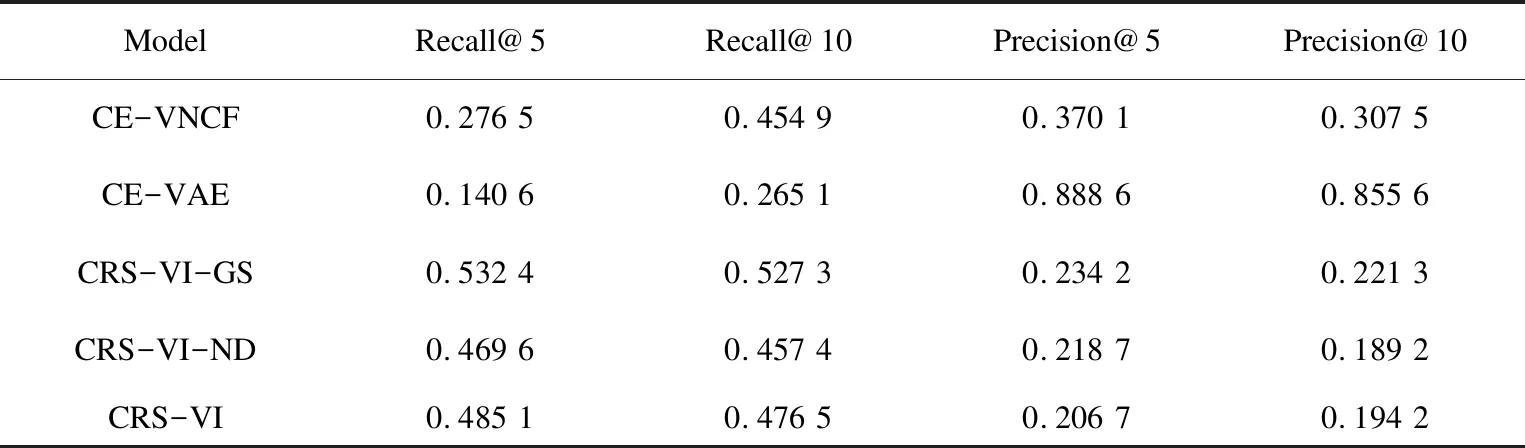
表3 BeerAdvocat数据集评判及解释任务评测

图4 BeerAdvocat数据集评判及解释任务评测
4.5 消融实验
模型采用贝叶斯神经网络,其核心是通过采样来实现损失函数中的期望值。通过不使用Gumbel-Softmax[18]采样技巧来实现模型,实验结果如表4和图5所示。

表4 BeerAdvocat数据集评判及解释任务评测

图5 BeerAdvocat数据集评判及解释任务评测
通过表4和图5可知,采用贝叶斯神经网络可以有效地提高评判及解释项性能。
5 结束语
该文提出了一种基于变分推断的可评判推荐算法,通过评判解释项挖掘用户的真实偏好,从而推荐出用户喜好的商品。与文献[5-6]相比,提出的模型在推荐任务的准确率、召回率、排序准确度及归一化折损累计增益方面有着较突出的表现,并且在评判解释项任务中也有相似水平。该模型在优化损失函数的同时,也有效避免了局部最小值等问题。这些研究成果提高了可评判推荐系统的推荐质量,从而增加了深度评判模型在大规模交互推荐应用中的实用性。该框架可以应用于各种领域,例如扩展到其他协同过滤领域,如组推荐和项目生成。
接下来的工作中,可以进一步挖掘用户偏好,采用多轮评判的方式,获取更多的显示反馈,以此提高推荐质量。
