基于元辅助任务学习的中药饮片识别方法
2023-10-21张一鹏罗启甜吴梦麟
张一鹏,罗启甜,吴梦麟
(南京工业大学 计算机科学与技术学院,江苏 南京 211816)
0 引 言
中药饮片是中药材按中医药理论,经过加工炮制后,可直接用于中医临床的中药。中药饮片种类繁多,且由于炮制方式和产地不同造成的外形差异较大,都给中药饮片鉴别带来了不小的挑战。传统的人工鉴别方法通过观察形、色、气、味等,依靠经验知识进行鉴别[1],这样的方法需要有较强的专业知识,鉴别结果受主观性影响较大,且检测效率较低。
随着计算机技术的发展,基于计算机视觉的中药自动识别技术的优势愈发明显。相较于传统的人工鉴定手段,自动识别技术能够更好地提取中药饮片图像的特征,加强鉴别的客观性;且自动识别技术的效率更高,可以实现高效的大批次检测。
在中药饮片鉴别的自动识别领域,早期的图像处理方法通过从中药饮片的形状、纹理、颜色中提取出人工设计的底层图像特征,然后结合浅层机器学习分类器对中药饮片进行分类。如陶欧[2]提出采用灰度共生矩阵研究中药材的纹理特征;胡继礼[3]利用颜色矩、灰度共生矩阵以及Hu不变矩提取中药的视觉特征,最后利用SVM分类器进行分类。这类方法有一定效果但提取的浅层不具有高层语义的特征信息,很容易受检测环境影响,实际应用时可靠性较差[4]。
近年来伴随着深度学习的兴起,图像自动识别技术有了巨大突破,同时也推动了中医药识别技术的发展[5]。李玲[6]基于电子鼻的三七及其伪品,采用了堆叠栈式自编码网络和深度信念网络两种网络结构,探究了深度学习方法在电子鼻数据上的适用性;Tan等人[7]利用深度卷积神经网络提出了一种高效、准确的蔷薇科山楂属植物鉴别方法。深度学习卷积神经网络依靠强大的特征提取优势已经应用于中药鉴别领域。但这些方法对图像的细节特征关注度不强,且模型的泛化性不强,与实际应用仍有差距。
为解决普通模型泛化性不强、不利于实际应用的问题,该文提出了一种基于元辅助任务学习的方法,该方法在传统的单任务分类模型上加入了辅助任务,通过共享不同任务之间的参数达到提升模型泛化性的目的;此外该方法还利用元学习的思想,在辅助任务学习的基础上新增了一个标签生成网络,从而达到自动生成辅助任务标签的目的;最后该方法使用Swin-Transformer作为模型的骨干网络,目的是利用Transformer的全局感知能力更好地捕获图片的空间信息,进一步提升模型的精确度与泛化性。
主要贡献有:(1)将辅助任务学习的方法引入中药饮片识别当中,达到了提升药材分类精度的目的;(2)将元学习思想引入中药饮片识别当中,达到了可以自生成辅助任务标签的目的,从而减少了人工定义辅助任务时需要做的大量标注工作;(3)将Transformer结构引入中药饮片识别当中,利用Transformer的全局感知能力更好地捕获图片的空间信息,达到了进一步提升了药材分类精度的目的。
1 相关工作
1.1 多任务学习与辅助任务学习
多任务学习的目的是通过同时训练若干个相关的任务进而实现不同任务之间的共享特征表示,提升各个任务的表现。一般来说有多个目标函数的损失同时进行学习的都属于多任务学习的范畴。由于从相关任务中提取到的先验知识是相互依赖的,所以由这些先验知识共同编码构成的共享特征表示可以提升每个独立任务的表现。Yi等人[8]提出了一种联合训练人脸确认损失和人脸分类损失的多任务人脸识别网络;Zhang等人[9]提出了将SoftmaxLoss和TripletLoss结合在一种网络中进行多任务训练的方法,并将此方法用于细粒度车辆分类中,取得了不错的效果。相较于普通的单任务学习,多任务学习框架在提升模型的泛化性、防止训练过程陷入局部最优、提升模型学习速率、防止过拟合等方面都有比较好的效果。
中药饮片由于产地与锻造方式的不同,普通单任务模型会有泛化性不足、跨批次精度下降的问题,而多任务学习框架为解决该问题提供了可行的思路。
与多任务学习为提升各个任务的表现不同,辅助任务学习将若干个相关任务分成了主任务与辅助任务两大类,其中辅助任务的作用是为主任务提供更多的先验知识进而提升主任务的表现。Shubham等人[10]为了提升会话语音识别的性能,将中低级的音素识别作为辅助任务;He等人[11]为了解决图片中是否包含文字区域的问题,其在传统CNN基础上加入了对图片进行字符分类和用BinaryMask表示字符位置两个辅助任务。
该文利用辅助任务学习的方法,将中药饮片分类作为主任务,中药饮片的形状和颜色分类作为两个辅助任务,通过硬参数共享[12]的方式对三个任务进行联合训练。经过实验证明,在同一骨干网络下,加入了辅助任务学习的模型要明显优于普通的单任务模型。
在后续的工作中,该文利用元学习框架设计了标签生成网络,实现了自动为模型选择最适宜标签的功能,在提升模型泛化性的同时还能够减少人工标注的工作量。
1.2 元学习
元学习又称作学会学习,与传统深度学习中对提取特征进行学习不同的是,元学习的目的是对算法本身进行归纳学习。在早期,元学习的探索主要集中在如何对神经网络模型进行自动学习更新[13-15];而近几年的方法主要聚焦于基于LSTM[16]或者合成梯度[17-18]的深度神经网络模型。此外,元学习也可以被用来寻找最优的超参数,并可以在小样本学习中学习出一个更好的初始化参数。
该文提出的标签生成网络就是基于元学习方法,元学习阶段的目的在于生成有用的辅助任务标签,而这些辅助任务标签会被用于多任务学习阶段。
1.3 Transformer
Transformer最早应用于自然语言处理领域并且取得了巨大成功,研究者尝试将Transformer引入计算机视觉任务中。Dosovitskiy等[19]提出了一个基于Transformer的图像处理模型,将图像划分为多个图像块并编码形成序列向量,解决了Transformer应用在图像领域的输入问题,并在图像分类领域的基准数据集上取得了优于卷积神经网络的效果。Liu等[20]提出的Swin-Transformer利用空间维度的移位窗口来对全局和边界的特征进行建模,增强了模型对局部和全局特征的提取能力。该文将Transformer结构引入中药饮片识别的问题当中,将Swin-Transformer作为模型的主干网络进行特征提取,利用Swin-Transformer特有的全局感知能力更好地捕获图片的空间信息。
通过引入Swin-Transformer结构可以进一步提升模型的泛化能力,进而提升药材的分类精度。
2 基于元辅助任务学习的中药饮片识别
2.1 模型框架
该文提出的用于中药饮片分类的基于元辅助任务学习的模型结构如图1所示。该模型主要由多任务学习阶段和元学习标签生成阶段两部分构成,两阶段的网络均采用了Swin-Transformer作为骨干网络。
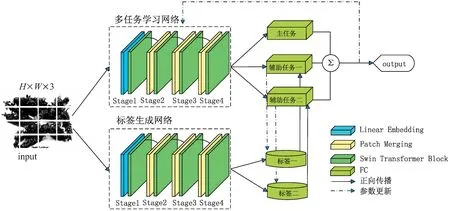
图1 基于元辅助任务学习中药识别方法的模型结构
多任务学习阶段与元学习标签生成阶段同时训练构成一个epoch,每个epoch有两个步骤:第一步是多任务学习阶段使用药品的主任务标签(即真实标签)与来自标签生成阶段的辅助任务标签进行训练;第二步是根据第一步得出结果更新元学习标签生成阶段的参数。
2.2 多任务学习阶段
在多任务学习阶段,作为主任务的中药饮片分类任务与其他辅助任务所使用的预测损失函数都是focal loss[21]。中药饮片由于其产地和珍稀程度导致样本的分本不均衡,呈现出长尾分布的状态,而focal loss损失函数比较适用于数据样本不均衡的场景,相较于其他损失函数更适用于中药饮片的数据集。focal loss损失函数定义如下:
(1)

将定义好的focal loss应用到作为主任务的中药饮片分类任务与所有的辅助任务上,定义多任务学习阶段为函数fθ1(x),其中θ1为中药饮片分类多任务学习阶段需要进行学习更新的参数,x代表输入,多任务学习阶段的损失函数定义如下:
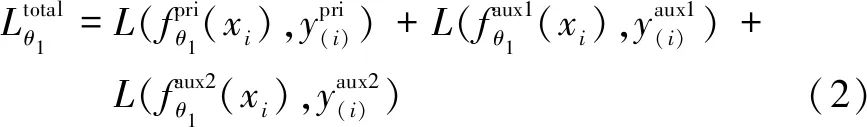
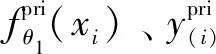
2.3 元学习标签生成阶段
在元学习中药饮片识别辅助标签生成阶段,标签生成网络的参数θ2由多任务学习阶段的结果进行更新;θ2更新之后又可以为多任务网络选择最适合的中药饮片识别辅助标签,进而使得多任务学习网络有更好的表现。在这个过程中,利用多任务学习阶段的结果进行标签生成网络参数的更新,可以被认为是元学习的一种形式。
将元学习标签生成阶段的损失函数定义如下:
(3)
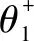
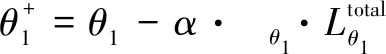
(4)
式中,α代表多任务学习阶段的学习率。

此外,在参数θ2更新过程中加入了熵损失函数H(yaux1+yaux2)作为一个正则项[24]。加入该正则项可以避免标签生成网络每次都产生相同标签的现象,进而使得标签生成网络能够生成更复杂且有用的中药饮片识别辅助标签。最终将式(3)和熵损失函数应用到元学习标签生成阶段,参数θ2的更新过程如下:
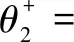
(5)
3 实验与分析
实验部分使用Python语言完成了训练数据的预处理、PyTorch框架的使用和实验结果数据的整理,同时使用PyTorch框架完成了训练数据的加载、模型的结构实现和模型的训练,具体的硬件环境配置如下:CPU使用Intel(R)Xeon(R)E5-2630 v3,GPU使用NVIDIA GeForce GTX 1080 Ti,内存大小为32 GB,操作系统为Windows 10。
3.1 数据集介绍
目前中药饮片识别领域还没有公开的大型数据集可用,并且网上可搜寻的图片往往背景复杂,带来的噪声对结果影响较大。本实验所使用的数据集是由专业的高清设备拍摄,如图2所示,拍摄的背景进行了统一,进而保证了噪声影响的最小化。实验所用药材采样于中药饮片交易中心,保证了药材的质量与种类,并且为了测试模型的泛化性,共计采样了两批次、数十种药材进行实验。将采样后的图片进行了归类,每张图都人工配以标签(种类、颜色、形状),该过程的目的是为了将人工定义辅助标签与自动生成标签进行实验比较。最终用于本次实验的数据集共有两个批次、三十六种药材、六千五百余张图片。

图2 部分数据集的展示
3.2 实验设置及评价标准
实验将第一批次的数据集,按照8∶2的比例划分成训练集与验证集,将第二批次的数据集均用作测试集,最终的精度测试结果均来自测试集上,这样的划分可以保证最大程度上对模型的泛化性进行评估。为保证数据的统一,所有的图像统一到224×224大小的尺寸,然后采用随机水平翻转并进行归一化处理。实验中采用自适应矩估计(Adaptive moment estimation,Adam)优化算法,训练迭代总次数为100,初始学习率设置为0.000 1,每迭代25个epoch将学习率下降为原来的1/2。
为了定量评估文中方法且适应中药饮片数据集存在样本分布不均衡的情况,实验采用了针对每一类别的精确率(Pre)、召回率(Recall)、F-score作为具体药材的评价指标,计算公式分别为:
(6)
(7)
(8)
其中,TP代表真阳性,指一类药材正确分类的样本数;FP代表假阳性,指错将其他类药材错分为一类药材的样本数;FN代表假阴性,指错将一类药材分成其他类的样本数。
最终的实验结果取同一批次中各类药材的精确率与召回率的平均值作为评价标准,即:
(9)
(10)
(11)
3.3 实验结果与分析
3.3.1 卷积神经网络的对比
为了同Swin-Transformer进行对比,实验首先对几种卷积神经网络进行了测试,使用单任务学习网络,实验结果如表1所示。
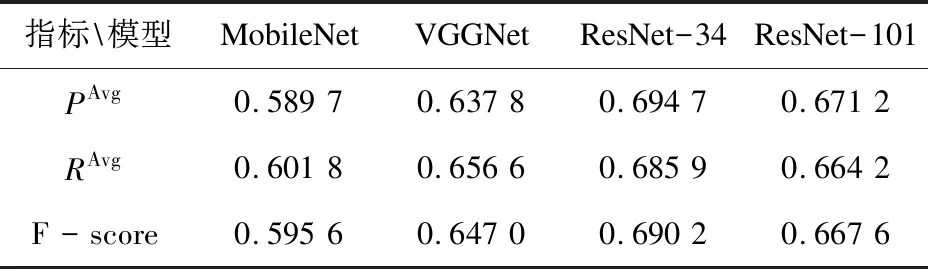
表1 卷积神经网络的对比
可以看出,在卷积神经网络的对比中,ResNet-34网络在精确率与召回率方面的表现都更好一些,因此选取了ResNet34作为与Swin-Transformer进行对比的卷积神经网络。
3.3.2 卷积神经网络与Swin-Transformer的对比
实验部分主要是将Swin-Transformer(SwinT)与ResNet-34进行对比,使用人工标注属性数据集,实验结果如表2所示,其中M-SwinT、M-ResNet34代表对应的网络应用于多任务学习框架上,PAvg、RAvg、F-score的计算方式与公式(6)~公式(8)相同。

表2 卷积神经网络与Swin-Transformer的对比
从表2可以看出,Swin-Transformer在单任务与多任务框架下相较于ResNet-34,其实验的指标都更好,也就意味着以Swin-Transformer为骨干网络的模型有更好的表现。
同时在这一小节的实验中,可以看出在同一骨干网络下单任务与多任务框架的表现差异,从表中可以看出,多任务框架的模型相较于单任务模型有着更好的表现。
3.3.3 消融实验
本实验部分为消融实验,目的是在主干网络的基础之上进行逐步扩展,同时进行实验证明每一步的扩展是否能在先前基础上使得模型性能有所提升,最终确定最优模型框架。实验结果如表3所示。

表3 消融实验
(1)该部分实验采用Swin-Transformer(SwinT)作为骨干网络,得出的PAvg、RAvg、F-score结果作为该部分基准。
(2)在数据处理方面增加了数据增强处理步骤(Data Augmentation),该部分利用翻转、旋转、平移、亮度增强的方法对原始数据进行扩充增强,实验结果表明数据增强能够提升模型的性能。
(3)在先前基础上加入了多任务学习框架(Multi Task),与3.3.2中已经应用了多任务学习框架的M-SwinT结果相比,该部分的数据已做了数据增强,实验结果表明多任务学习能够提升模型的性能。
(4)加入了元学习标签生成网络(Meta-Generation),该部分的实验数据不再需要人工额外标注属性,实验结果表明元学习标签生成网络在节省人工标注成本的同时能够提升模型的性能。
从消融实验的结果可以看出,每一部分的融入都使得实验结果有所提升,最终得到的包含SwinT+Data Augmentation+Multi Task+Meta Generation的模型框架达到了实验的最佳性能。
4 结束语
为解决普通深度学习模型泛化性不强、不利于实际应用的问题,提出了一种基于元辅助任务学习的方法。该方法在传统的单任务分类模型上加入了多任务学习网络、元学习标签生成网络,同时使用了相较于卷积神经网络有更好表现的Swin-Transformer作为模型的骨干网络。实验结果表明,该方法能够有效地提升深度学习模型在中药饮片识别中的精确度与泛化性,有利于将深度学习模型应用到实际的中药饮片识别当中,同时也为中药自动识别提供了更宽阔的思路。
