基于深度强化学习的无人战车多回合火力分配
2023-10-20刘诗瑶郝宇欣李强强
刘诗瑶,王 明,张 耀,李 飞,郝宇欣,李强强
(北方自动控制技术研究所,太原 030006)
0 引言
新时代的战争形态正在由机械化、信息化向智能化、无人化加速变革,无人系统作战将成为一种颠覆性的新型作战样式主导未来战场。无人系统作战将不再是纯粹的武器与武器、平台与平台之间的较量,更是一种以分队为最小作战单元的体系与体系之间的对抗。地面无人战车作为未来陆军的主要无人作战装备,其分队作战将会占有非常重要的地位。火力分配,又称为武器-目标分配(weapon-target assignment,WTA),是地面无人战车分队作战的关键环节[1],主要是根据作战任务、战场态势和武器性能等因素,将一定类型和数量的火力单元以某种准则进行分配,攻击一定数量敌方目标的过程[2]。对于传统的有人装甲装备作战,可以通过直瞄方式进行协同火力打击;而对于无人战车分队作战,迫切需要通过人工智能技术实现自动火力分配。如何在高动态环境、强博弈对抗条件下实现地面无人战车分队火力分配具有很大挑战性。
目前,对火力分配问题的研究主要包括静态火力分配(static weapon-target assignment,SWTA)和动态火力分配(dynamic weapon-target assignment,DWTA)两方面。其中,静态火力分配是单阶段分配,一次分配对应一次攻击,与时间无关;而动态火力分配是多阶段分配,每个阶段对应一次攻击,前一阶段的分配结果仅作用于该阶段的攻击,下一阶段的分配结果需根据前一阶段的攻击结果进行调整。无人战车分队火力分配作战是典型的动态火力分配。动态火力分配问题最早由HOSEIN 等提出[3],近年来对该问题的研究呈持续上升趋势[4],主要包括火力分配模型和火力分配算法两部分。在火力分配模型方面,有学者利用多阶段的静态火力分配建立了动态火力分配模型[5]。文献[6]用协同决策思想,对合成分队火力优化分配方法进行了研究,考虑了分队内的火力协同优化。在火力分配算法方面,由于火力分配问题属于多参数、多约束NP-complete 问题[7],求解时间随问题规模增加成指数级增长[8],因此,许多学者采用启发式算法求解火力分配问题,比如遗传算法[9]、粒子群算法[10]、蚁群遗传算法[11]、模拟退火遗传算法[12]等。近年来,有学者试图利用强化学习方法解决火力分配问题,文献[13]分别利用强化学习的蒙特卡洛方法和离轨时序差分方法(Q-learning 算法)对防空领域防御作战的火力分配问题进行求解,取得了较为理想的结果。文献[14]利用贝叶斯网络进行威胁评估得到强化学习模型中的必要参数,并利用Q-learning 算法对火力分配问题进行求解,显示出强化学习方法的优势。
以上文献基本都是研究有人装备的火力分配,而且是单回合火力分配问题,即根据人为划分的作战阶段,每次输出一个火力分配结果,只能保证当前回合局部最优。由于无人战车分队作战过程是敌我双方对抗博弈的动态过程,一般会持续多个回合,每一回合的火力分配局部最优解并不一定是整个作战过程的火力分配全局最优解。因此,针对无人战车分队作战的多回合火力分配问题,提出一种基于深度强化学习的火力分配方法。分析无人战车分队作战问题,建立基于马尔科夫决策的火力分配模型;采用深度强化学习算法进行火力分配模型求解,计算出整个作战过程中多回合火力分配结果,进行仿真验证,并进行比较。
1 基于马尔科夫决策的火力分配建模
无人战车分队作战过程实际上是敌我双方不断进行火力分配并实施打击的动态过程。在完成一回合火力分配并相互对抗之后,战场态势发生变化,需要再根据变化后的战场态势进行下一回合火力分配,如此循环。无人战车分队整个作战过程的火力分配如图1 所示,其中,SWTA 表示每一回合的火力分配,即静态火力分配。无人战车分队的多回合火力分配问题本质上属于马尔科夫决策问题,本文采用马尔科夫决策模型对无人战车分队火力分配进行建模。
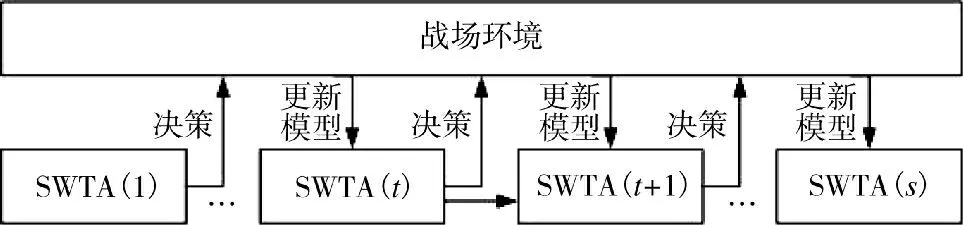
图1 作战过程中的火力分配模型示意图Fig.1 Schematic diagram of weapon-target assignment model during the combat process
1.1 马尔科夫决策过程
马尔科夫决策过程(Markov decision processes,MDP)是一种通过交互式学习来实现目标的理论框架。将进行学习及实施决策的机器称为智能体(agent),智能体之外的所有与其相互作用的事物都被称为环境(environment)。这些事物之间持续进行交互,智能体选择动作,环境对这些动作作出相应的响应,并向智能体呈现出新的状态。环境也会产生一个收益,通常是特定的数值,这就是智能体在动作选择过程中想要最大化的目标,如下页图2 所示。
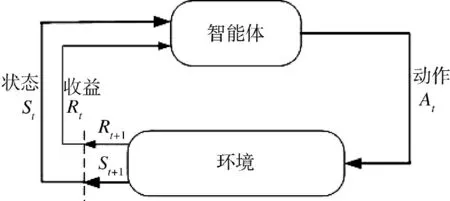
图2 马尔科夫决策过程中的“智能体-环境”交互Fig.2 “Agent-Environment”interaction in MDP
MDP 和智能体共同给出了一个序列或轨迹:
通过某一动作使状态发生改变被称为“策略”:
式中,S 和a 分别表示当前的状态和动作,表示下一状态;P 表示“策略”,表示一条具体策略,即当前状态为s,通过动作a,状态转化为s';E 表示期望。在强化学习中,一般用式(3)表示策略:
1.2 无人战车分队火力分配建模
无人战车分队火力分配的建模,可以将作战过程分为若干个回合,在每个回合根据战场态势进行一次火力分配,从而解决整个作战过程的动态火力分配问题。将每个阶段的战场态势称为“状态”s,将每一回合的火力分配(即我方无人战车i 攻击敌方目标j)称为“动作”a,将作战中的火力分配近似看作一个MDP,即下一状态仅与当前状态有关,而与之前的状态无关。对应马尔科夫决策过程,设置状态集
其中,Mi表示我方无人战车i 的状态,Nj表示敌方目标j 的状态,有
2 基于深度强化学习的火力分配算法
无人战车分队的多回合火力分配问题属于马尔科夫决策问题,而马尔科夫决策问题一般可以采用深度强化学习进行求解。本文采用DQN 的双网络结构,即网络Q 和目标网络。两个神经网络结构相同,均由3 层全连接层组成,神经网络结构如图3所示。

图3 神经网络结构Fig.3 Neural network structure
考虑采用深度强化学习中的深度Q 网络(deep Q-network,DQN)算法解决火力分配问题。利用DQN 算法求解最优结果,在于通过计算确定使Q 值最大,其中,Q 值的计算方法为式(5):
式中,Q 的值由当前的状态-动作对Q(st,a)以及预测的下一个状态-动作对Q(st+1,a)确定,并不断迭代更新,Q 值最大的状态-动作对应当前的最优策略。Rt+1表示下一状态对应的奖励值,γ 表示折扣因子。DQN 算法用于预测最优行动策略,即根据当前状态s 预测接下来的动作a,并转移到状态s'。R 表示奖励值,跟状态有关,每一个状态对应一个奖励值。DQN 算法的伪代码如表1 所示。本文需要利用DQN对m 个我方无人战车进行控制,然而m 个无人战车作为一个整体对敌方目标产生作用,因此,不同无人战车之间不是独立的,战场态势S 是所有无人战车共享的,不同无人战车的动作a 产生的q 值会受到其他无人战车的影响。

表1 DQN 算法伪代码Table 1 Pseudocode of DQN algorithm
基于上述情况,建立以下基于DQN 的算法结构:
式中,θi表示当前状态网络Q 的参数,y 由目标网络求出,有
根据DQN 伪代码中的算法,网络Q:eval_net 和目标网络:target_net 的输入分别是当前状态s 和下一状态s',单个我方无人战车单元的网络结构如图4 所示。
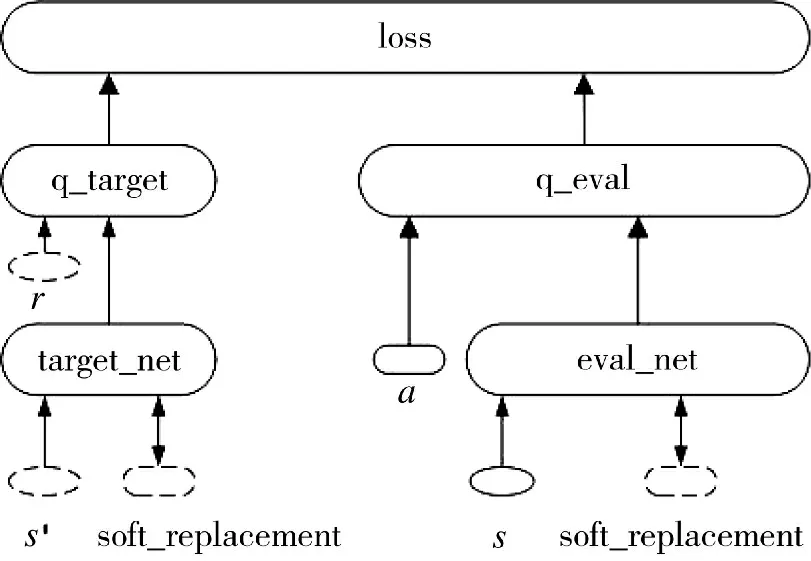
图4 单个无人战车单元的DQN 结构图Fig.4 DQN structure diagram of a single unmanned combat vehicle unit
2)对每个无人战车的指令是从n 个敌方目标中选择一个进行攻击,因此,Q 和的输出是n 个动作对应的q 值:q_eval 和q_target。
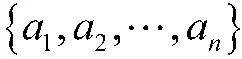
图5 单个无人战车单元的神经网络训练图Fig.5 Neural network training diagram of a single unmanned combat vehicle unit
3)每C 步分别用m 个无人战车Q 的网络通过soft_replacement 环节替换对应的目标网络。
结合DQN 算法伪代码,设计求解无人战车分队火力分配问题的流程,如图6 所示。根据战场态势信息确定我方无人战车数目和敌方目标数目,建立状态集S 和动作集A;利用评估方法确定我方无人战车分队对敌方目标群的毁伤概率矩阵Q 和敌方目标群对我方无人战车分队的威胁度矩阵T,同时设定相关约束条件,建立无人战车分队多回合火力分配模型;根据基于DQN 设计的火力分配算法对模型进行训练和解算。

图6 基于DQN 的火力分配算法流程Fig.6 Flow of weapon-target assignment algorithm based on DQN
3 仿真验证
为验证所提方法的有效性,假设在某次作战任务中,我方9 个无人战车需要攻击7 个敌方目标,根据战场态势建立威胁评估模型,并利用贝叶斯网络等评估方法进行威胁评估,确定毁伤概率矩阵和敌方威胁度矩阵,利用毁伤概率、威胁度以及敌我初始状态等战场态势信息,根据图6 的算法流程图进行训练。为了在训练过程中模拟战场状态的变化,并实时更新战场状态,利用python 中的tkinter模块设计了火力分配的GUI,如图7 所示。
图7 中,方块表示我方无人战车,圆表示敌方目标。初始状态为我方无人战车和敌方目标都未被损毁,分别为红色和黄色。经过多回合的火力对抗,我方和敌方分别有部分火力单位被损毁,此时相应单位变为黑色。当有一方全部变为黑色,即全部被损毁,则此轮模拟结束,完成一次训练。
训练过程中,实时输出当前回合的我方火力分配结果,如表2 所示。

表2 训练过程中的多回合火力分配结果Table2 Multi-round weapon-target assignment results during training processes
表2 中,分配结果分别表示我方9 个无人战车打击的敌方目标的编号,编号为0 说明该无人战车已被损毁,不能再选择打击目标;在第1 轮训练中,随着回合数的增加,打击目标逐渐减少,表示相应的敌方目标被损毁;在第2 轮训练中,最终我方无人战车存活数为负,表示战斗结束时我方无人战车全灭,而敌方目标仍有两个未被损毁,作战失败,得到负的奖励值。
经过120 000 次训练后,9 个无人战车的损失函数如图8 所示,可以看出每个损失函数都逐渐收敛。当训练达到120 000 次时,9 个无人战车的损失函数全部收敛,图8 为无人战车“5”号车的损失函数训练情况。

图8 “5”号车训练过程中的损失函数Fig.8 Loss function during the training process of No.5 unmanned combat vehicle
仿真结果显示,通过训练,9 个无人战车单元的Q 网络都逐渐收敛于对应的目标网络,表明利用深度强化学习算法同时控制多个动作单位(agent)从而实现无人战车分队级别的火力分配具有可行性。
同传统的火力分配方法相比,本文所提出的基于深度强化学习的火力分配方法有以下优势:
1)多回合全局最优。传统方法只能针对当前战场态势作出当前单回合的最优或局部最优的火力分配决策,难以保证整个作战过程的最终结果。而本文提出的火力分配方法面向整个作战过程的多个回合,以取得作战的最终胜利为准则,实现无人战车分队的多回合火力分配,得到多回合分配的全局最优结果,更符合实际作战需求。
2)环境适应性更强。传统方法在作战过程中需要对火力分配模型进行多次人为修改,同时,只能对当前回合的战场态势信息进行分析,难以对战场态势变化作出预测,无法正确识别敌方用于迷惑对手的行为,进而造成严重后果。而本文提出的火力分配方法,可以根据战场态势变化对模型作出自动调整,能够对战场上可能出现的态势变化提出合理的应对方法,进而在一定程度上避免单回合火力分配的不利影响,更好地适应高动态强对抗的战场环境。
4 结论
本文针对传统单回合火力分配方法难以求得整个作战过程火力分配最优解的问题,提出了基于深度强化学习的无人战车分队多回合火力分配方法。通过对无人战车分队作战问题进行描述,基于马尔科夫决策过程对整个作战过程的火力分配问题进行建模,基于DQN 设计了相应的火力分配算法,对该模型进行求解,进行仿真验证。仿真结果表明,利用深度强化学习算法同时控制多个动作单位(agent)从而实现无人战车分队级别的火力分配,并通过与传统火力分配方法进行对比,展现了新方法多回合全局最优、环境适应性更强的优势。今后可通过采用更先进的深度强化学习算法,以及设计更复杂的训练架构和实现技巧,进一步提高多回合火力分配的解的质量。
