基于实体间关系的数据空间实体解析技术
2023-10-20祁祥威
祁祥威
(西南交通大学制造业产业链协同与信息化支撑技术四川省重点实验室,成都 611756)
0 引言
实体解析(entity resolution,ER)是一种用于识别数据集中多个数据记录是否为同一现实世界实体的技术。随着时代的发展,实体解析成为了大数据应用中数据清洗和数据集成的关键技术之一[1],并且在信息检索、人工智能、机器学习、数据库等各个领域中都受到了相当的重视。
目前实体解析技术在各个领域都有不同的适用于其领域的方法,但还是以统计学中的概率决策为主,即,计算记录之间属性值的相似度,根据相似值与预设的属性级阈值或记录级阈值,判断两条记录是否匹配[2]。
而数据空间是以图数据库为基础的数据管理系统,集成了大量异质数据,没有统一的语义[3],无法将不同的记录的属性值进行一一对应,从而无法进行基于统计学的实体解析。但数据空间中存有实体之间的关系,从实体之间的关系入手可以有效地进行数据空间的实体解析任务。
1 相关技术
1.1 数据空间
数据空间是为了应对海量异构的数据,由Franklin 提出的一个概念:一个数据空间由一系列相关的异构资源对象集和资源对象间的关联关系集组成,包含某个组织或个体相关的一切信息,这些信息可以以任意形式,在任意地方存储;在将数据加入到数据空间之前,无需像关系数据库事先为其定义严格的关系模式,直接将数据源加入数据空间,并以pay-as-you-go模式实现数据的管理[4]。数据空间主要具有数据优先、模式滞后的特点[5],即优先集成数据,随着数据的不断加入再进行数据模式的演化。
1.2 实体关系模型
实体关系模型是一种描述现实世界中实体之间关系的模型,通常被应用于数据库设计和数据建模领域。实体通常指从现实生活抽象出的一种有区分性的概念,可以指向具体的物体,如房子、车,也可以是一种逻辑上的概念,如交易、订单。而关系则描述了实体之间的连接方式,一般有三种:“一对一”“一对多”和“多对多”。
2 算法实现
利用实体间关系进行实体解析的思想比较简单。首先,找到两侧的实体至少有一个具有唯一性的关系,即,实体之间“一对一”或“一对多”的关系,称为“决策关系”。将决策关系两端的只能有一个出度或入度的结点(这里表示的是数据记录)称为决策结点。例如,“顾客”“酒店房间”之间的“预订”关系,就可以称为决策关系,而“酒店房间”则称为决策结点。因为在这个关系中,“顾客”可以预订多个“酒店房间”,但是“酒店房间”不能被多个“顾客”预订(见图1)。
其次,在数据空间中,查询所有与决策结点具有决策关系的结点,在这些结点之间增加一个“匹配”关系(见图2)。

图2 基于实体关系进行匹配
最后,将结点进行分组合并。具体过程如下:
(1)为每一个结点分配一个整数ID 作为标识;
(2)将这个ID 传送到与之具有“匹配”关系的相邻的结点;
(3)使用从相邻结点接收到的最小值ID 作为结点的新ID;
(4)重复步骤(2)、(3)直到没有可以更新的ID;
(5)将具有相同ID的结点分为一组;
(6)对于每组内的结点,保留其中一个并使其继承其它结点的属性,删除其它的结点。
3 实验结果与分析
目前对于异质数据的实体解析任务,尚未有公认的数据集,因此,根据研究对象的特点,构建了包含顾客和房间两种对象的小规模数据集作为实验数据,见表1。
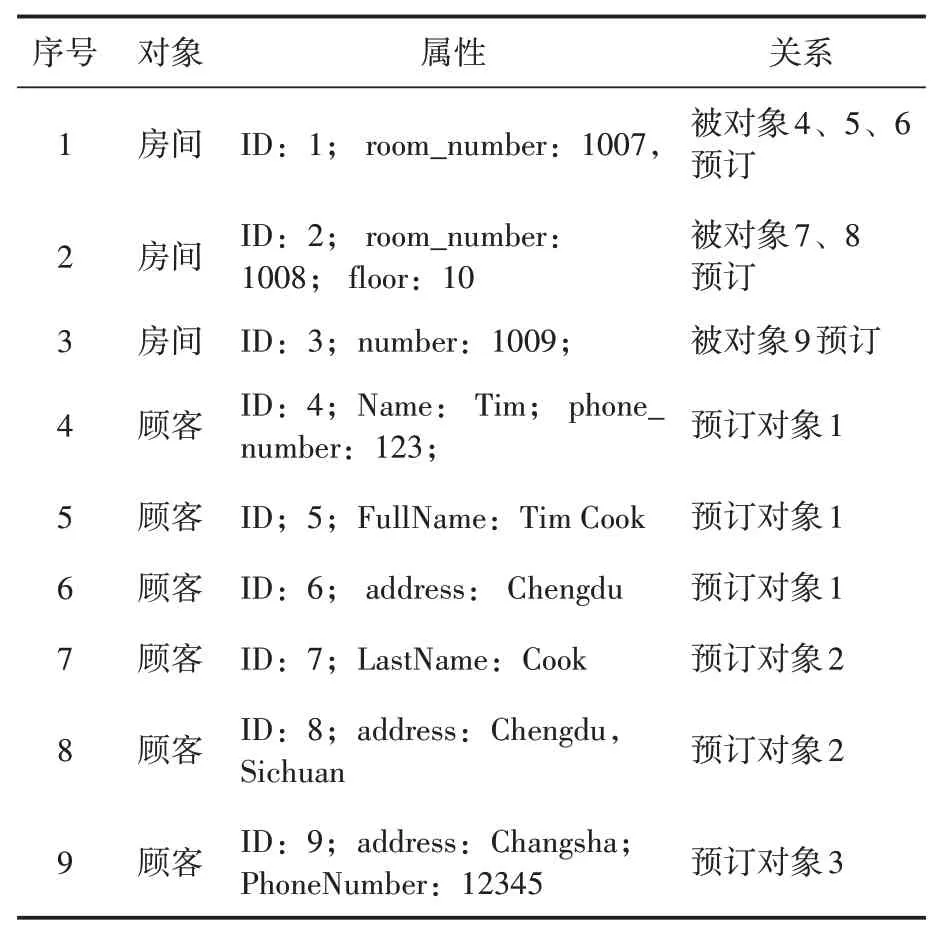
表1 包含顾客和房间两种对象的小规模实验数据集
如表1所示,顾客拥有的不同属性用于表达数据空间中集成的异质数据,即,没有统一的语义。将上述数据进行前文所描述的算法,则可以得到决策实体类型为房间,决策结点为结点1、结点2和结点3。
本文以Neo4J为基础进行算法的验证。数据的初始状态如图3所示。
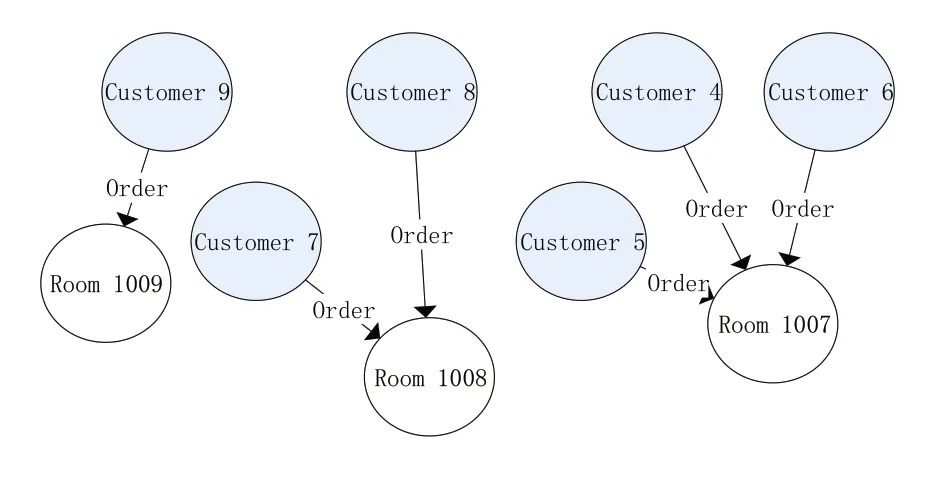
图3 Neo4j中数据初始状态
通过上文所述算法过程,如图4 所示,Costomer 4、Costomer 5 和Costomer 6 之间增加了“Matches”关系,而Costomer 7 和Costomer 8之间增加了“Matches”关系。最后通过连通分量算法进行冗余结点的删除,得到如图5所示的结果。可以看出,该算法简洁有效。
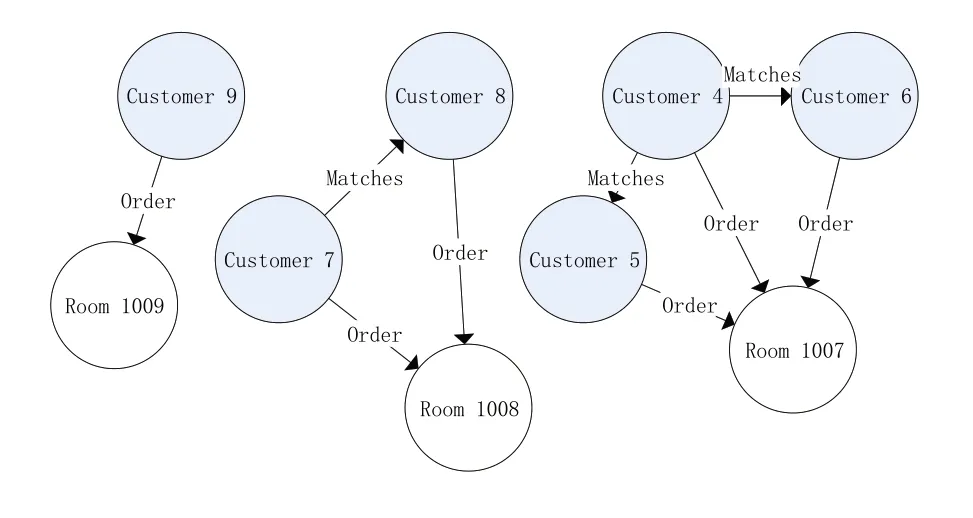
图4 Neo4j中进行匹配后的数据

图5 进行属性继承和删除冗余结点后的数据
4 结语
实体解析是一个领域性较强的问题,不同的领域有着适合该领域的方法。对于结构性较强的数据,可以采用基于属性值相似度计算的办法。但是在数据空间中,大量的数据是异质,没有统一的语义,无法运用类似的实体解析方法。本文针对这个问题,从数据空间中的数据关系入手,提出了基于实体关系的实体解析方法,并通过构建小规模数据集验证了算法的有效性。但是对于缺少决策关系的数据,本算法则有一定的局限性,有待后续研究。
