面向数据集制作的图像重复性检测方法
2023-10-20崔溜洋张文哲
李 玲,崔溜洋,张文哲
(大连理工大学城市学院,大连 116600)
0 引言
图像处理算法的研究离不开数据集的支撑,而算法的效果和性能与训练数据的规模和质量密切相关,因此数据集的制作工作也尤为重要。图像数据来源的多样性在提升数据的规模和丰富性的同时也增加了数据筛选的难度。以往的人工处理流程繁琐复杂、效率低下,尤其是在大规模数据集的制作中,为保证准确度只能投入大量的作业时间。虽然也有部分工作会借助算法进行,但功能分散,自动化程度低,还有很大的提升空间。
基于以上背景,本文提出一种面向数据集制作的图像相似性检测方法,先对原始数据进行个性化的预处理,初步筛除不合格数据,然后使用感知哈希算法[1-2]结合k-means[3-4]聚类,对图像特征进行散列化,计算数据签名间的距离,过滤掉相似度高的重复图像,图像筛选的严格程度具有可调节性。经过本方法处理后的数据经由简单复检后,即可用于后续使用,大大提高数据的筛选效率和准确率。
1 相关工作
相似度检测是图像处理中的基础应用[5-7],目前主流的方法是哈希算法。图像哈希算法的中心思想都是将图像进行散列化,作用在于生成图像的指纹信息,可通过比较两图像指纹信息的间距来判断图像的相似性,在图像处理领域有着广泛应用。例如,Randhir等[8]使用pHash算法计算平台上传内容的相似度,解决多媒体的版权侵权问题。Biswas等[9]对感知哈希算法进行改进,更好地提取人脸图像的特征,应用于人脸分类任务。Verlekar等[10]通过计算用户腿部区域上的感知散列并将其与针对训练序列获得的pHash 值进行比较来识别行走方向。Liu 等[11]提出深度哈希方法用于遥感图像的分类和检索。虽然感知哈希的处理时间最长,但由于其对于图像细微变化的低敏感性,尤其是在角度旋转情况下表现出的强鲁棒性而备受青睐。
在数据集的制作中,也有团队会使用相关算法对数据进行筛选。例如,邓庆昌等[12]在做目标检测数据集的过程中,采用直方图法进行图片去重。花明珠等[13]使用感知哈希算法对通过爬虫技术在网络中搜集大量珊瑚图片形成的初始数据集中的图像进行去重处理。但是这些方法功能单一,只完成了数据筛选的小部分工作,而且对于大规模数据的筛选速度和精度无法保证。
因此本文基于敏感哈希算法,提出针对数据集制作的综合筛选方法,同时为了弥补时间缺陷,借鉴k-means 思想,先经过聚类后再计算指纹序列间的距离,以降低执行大规模数据过滤工作的时间复杂度。
2 算法实现
本文提出的图像重复性检测方法旨在实现图像数据集制作过程中图像筛选部分的自动化处理,代替人工筛选,降低图像过滤的时间成本,提高过滤质量。算法流程如图1所示。
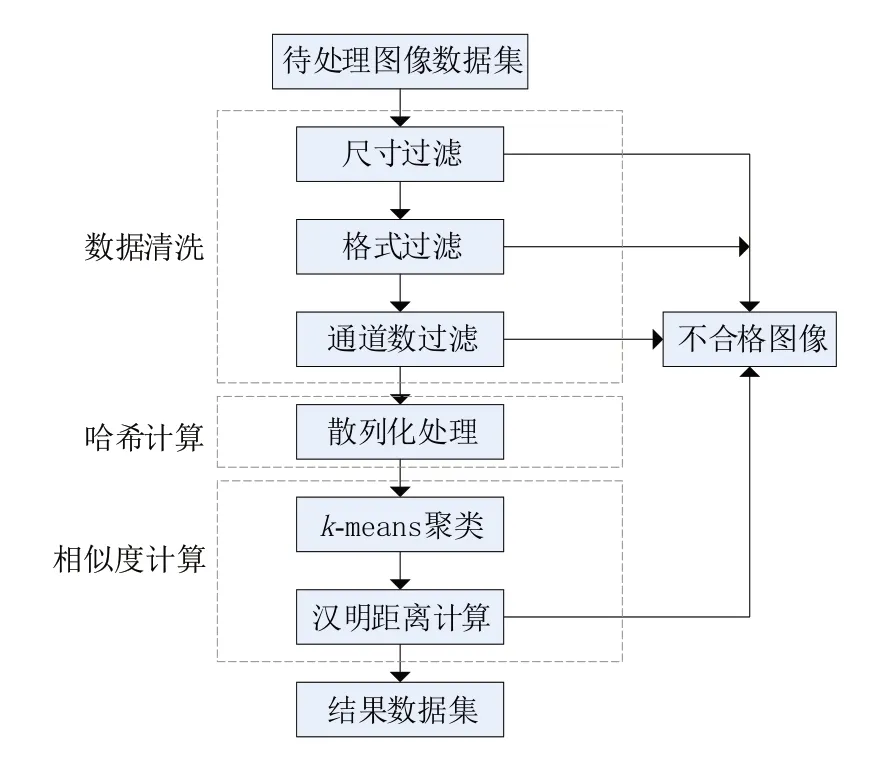
图1 算法流程
算法整体分为三大部分:数据清洗、哈希计算和距离计算。首先将通过爬虫等方式采集到的原始数据集作为算法的输入,根据个性化要求进行数据清洗,初步筛除不符合要求的数据;其次使用pHash算法[14-15]对每张图像进行签名计算,得到代表图像的散列化数据;最后对所有图像的哈希值进行k-means聚类,在同一簇中两两计算汉明距离,过滤超过阈值的相似图像。
2.1 数据清洗
数据清洗主要包括三部分内容:尺寸检查、通道数检查和图像格式检查。图像数据的尺寸限制参数和格式限制参数可在配置文件中进行个性化设定,根据配置内容将范围外的图像数据“淘汰”。通道数检查主要为了删除灰度图像,因为在很多图像处理算法中,是无法对灰度图像进行处理的。本算法删除的数据不会直接删除,而是会被收集至单独的文件夹中,目的是保留原始数据,以供人工复检比对或其他处理使用。
2.2 感知哈希算法
感知哈希的核心思想是无损DCT(离散余弦变换)。DCT 变换最早由Ahmed 等[16]于1974 年提出,其基本原理是对图像进行压缩,将空域信号转到频域,获取更有效的表达。因计算开销低,处理效率高,适应性强等优点在图像处理中具有重要应用。二维DCT变换的公式为
其中:x、y为空间采样值;u、v为频率采样值;f(x,y)为原始二维信号。
感知哈希的处理流程如图2所示。先将图像统一缩放至32 × 32 px,再转换为单通道灰度图,目的是为了进一步减小计算量,简化DCT变换。经DCT 变换后的图像信息主要集中在左上角,取8 × 8 的矩阵即可呈现图片的低频信息。计算矩阵中所有元素的均值,再依次将矩阵中的元素与均值进行比对,根据比对结果赋1或0,从而生成64 bit的指纹信息,即哈希值。

图2 感知哈希算法示意图
2.3 距离计算
当数据规模很庞大时,对指纹信息两两比较并计算距离是十分耗时的过程。为解决该问题,本文引入了聚类思想。聚类是一种无监督学习方法,无需准备数据集,将一个庞杂数据集中具有相似特征的数据自动归类到一起,称为一个簇,簇内的对象越相似,聚类的效果越好[17]。
使用k-means 算法将所有图像数据的哈希值先聚成k簇,此时相似的图像在很大概率下会被聚在同一簇中,然后在同一簇中两两计算距离,大大减少计算量。k-means聚类具有随机性,可能收敛到局部最小值,手动设定的k值也会影响最终的聚类效果。在配置文件中提供了设定k值的接口,可根据数据的实际情况进行设定,从而提高方法的泛化性能。另外,对于最佳k值,在3.2节中进行了对比实验。
距离计算选用汉明距离[18],对图像的哈希值进行异或运算,统计结果为1 的个数。其公式为
其中:xn、yn表示两个N位的字符串,⊕符号表示进行XOR运算。
3 实验结果
3.1 实验数据集
为了有效地对算法进行定量评价和对比实验,本文构建了一个具有已知不合格图像和相似图像数量的实验数据集。通过网络爬虫的方式,采集了约20000张图像作为原始数据。人工挑选了5000 张合格图像作为基础样本(命名为DATA-BASE)。通过对DATA-BASE 中的图像进行加噪、尺寸变更、图像旋转、灰度转化、格式变换等处理进行数据集的扩展,具体的处理数量和参数见表1。

表1 实验数据处理
从DATA-BASE 中随机选取数量列对应数量的图像,按照对应的处理方法和参数进行处理,最终得到共13000 万张图像的扩展数据集(命名为DATA-L)。再从DATA-L 中随机选取2000 张图像构成DATA-S,均作为对比实验的数据支撑。以一张图像为例,进行处理后的效果说明,如图3所示。

图3 扩展数据集处理示例
3.2 k-means聚类
在本节中将进行两组对比实验,第一组是验证选取的最佳k值,第二组是验证对于不同数据规模,进行聚类后再计算图像间的距离和直接计算距离的时间优化结果。
选取合适的聚类中心,不仅能减少聚类的时间,还能提高聚类的准确度。一般的聚类中心数在3~10之间,对于数据筛选来说,聚类的目的是使类似的图像被聚到同一簇中,过多的聚类中心更易使数据分散,达不到良好的聚类效果。因此,在本组实验中选取的聚类中心数的范围为2~8。使用DATA-L 数据集进行实验,聚类结果的分析方法使用经典的“手肘法”,即通过计算不同簇数下的聚类误差平方和(SSE)来确定最佳k值。实验结果如图4 所示,可以看出k=4时是拐点位置,因此最佳k值取4。

图4 最佳k值实验结果
选用k-means 的目的是为了减少图像签名比对的计算时间,尤其是在数据规模庞大的情况下。为了验证该方法的有效性,进行了时间对比实验。分别计算在两种数据规模下,不使用k-means 直接进行汉明距离计算、进行聚类后再进行距离计算所需要的时间,聚类中心数均设置为4,本实验的结果见表2。
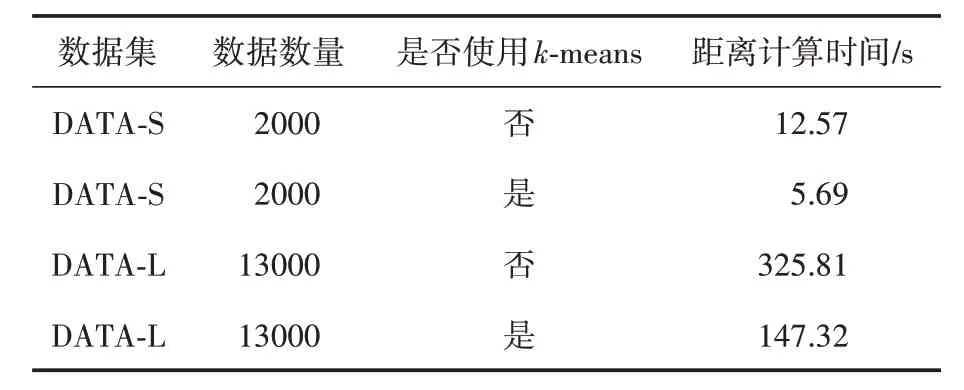
表2 时间对比实验结果
从表2可以看出,在所有数据规模下,进行聚类的时间均比不进行聚类的时间短,且数据规模越大,效果越明显,这充分表明了融合聚类能够减少哈希签名比对的时间。
3.3 算法评价
本节实验,我们将通过人工方式筛选的结果和通过本文方法的筛选结果进行比较。为了使实验数据更具说服力,人工过滤流程与算法过滤流程保持一致,图像清洗部分需要人工调用多个程序进行,过滤标准与配置文件中设置的条件一致。图像相似度检测的方法,通过人工进行肉眼比对,根据人的主观判断进行相似数据的筛除。
评价从时间和准确率两方面进行,准确率采用以下两个评价指标进行计算:
其中:ri代表被正确保留的数据数量,rall表示应该被保留的数据总数,ei表示被正确筛除的数据数量,eall表示应该被筛除的数据总量。该部分的实验结果见表3。
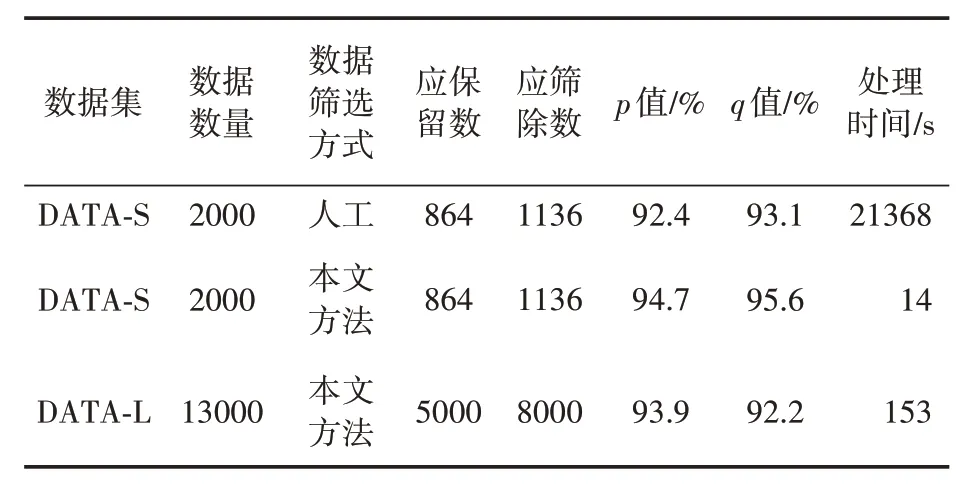
表3 算法评价实验结果
根据以上实验结果,人工筛选2000 张图像的时间就已经达到了约6小时,随着数据规模的增大,对于人工筛选的挑战性更高,人工筛选的效率更低,准确率也会随之降低。而使用本文提出的方法,仅需不到3 分钟即可完成13000张图像的过滤工作,且过滤效果较好,能够满足数据集制作的筛选需求。
4 结语
本文针对数据集制作的特定场景,提出了图像重复性检测方法,实现数据筛选的“一站式”服务,解决了数据筛选效率低下、准确率不佳等问题,具有实际应用价值。通过实验验证了算法在处理时间和筛选精度上的表现,与传统人工处理流程的时间和性能进行比较,证明了算法的有效性和优越性。
图像处理技术将继续发展,数据集的制作也会趋向自动化。数据集的制作还包括标注、分类等部分,在后续的工作中,我们也将探讨和研究其余部分的自动化处理方法,考虑采用深度学习方法,尽可能降低数据集制作的人工成本,这也对图像处理技术的发展有着至关重要的影响。
