基于Q-learning算法的配电网储能装置控制策略研究
2023-10-19王晓康俞智浩芦翔
王晓康,俞智浩,芦翔
(1.国网宁夏电力有限公司吴忠供电公司,宁夏 吴忠 751100;2.国网宁夏电力有限公司电力科学研究院,宁夏 银川 750011)
0 引 言
随着可再生能源技术的发展,分布式发电技术不仅应用于变电,而且,在接入更方便的配电网中应用更为广泛。但在大量分布式电源接入配电网后,其固有的出力波动和高度间歇性会直接影响配电网的电压运行水平和功率平衡性,进而导致电压越限和配变过载等问题[1]。解决上述问题的关键在于控制配电网有功功率的平衡性,因此在配电网末端接入储能装置的辅助运行方式成为一种可行的技术方案[2]。
储能技术的应用对于改善配电网系统的电压特性,实现负荷侧灵活削峰填谷有着重要的价值。除此之外,合理的储能控制可以有效提高能源的利用效率[3]。在储能装置的辅助下,配电网对于功率波动的耐受性更强,配电网区域内的电压波动减小,有利于接纳更多的新能源接入,从经济性和稳定性上对区域电网都有着重要的价值[4]。
储能装置的控制目标通常为减小系统内节点电压波动,根据负荷需求合理控制出力水平。储能控制技术通常基于一定的模型,以提升系统某项指标为目的,通过对系统控制策略进行优化和创新来实现预期控制效果[5]。目前国内外常用算法有线性规划、混合整数规划、动态规划、模糊逻辑等,其中动态规划算法作为目前应用较为成熟的一种算法形式,在迭代计算后可以实现对状态空间内的控制效果优化,得到局部最优解。但随着状态数的增加动态规划算法容易出现“维度灾”问题,即迭代计算量出现指数型上升,从而导致在线计算时间大大增加,同时也会增加计算成本。为了解决这个问题,强化学习算法被提出,并用来求解动态的决策任务。强化学习是一种从历史经验中学习最佳策略的算法,主要思想就是智能体通过不断和环境互动来学习系统的动态特性,具体到每一个迭代过程就是智能体根据当前的状态做出一个动作,然后得到一个奖励值和下一时刻的状态。强化学习智能体和环境互动的次数越多,经验越丰富,所做的策略越准确。强化学习的Q-learning算法作为一种应用领域较为广泛的算法类型,通过调整迭代条件可以避免过多状态量的出现,从而解决维度灾难的问题[6]。
Q-learning在使用历史数据进行训练时具有优势且易于理解,对计算资源需求较少,算法训练过程更为稳定,更能适应配电网的实际情况;因此本文将Q-learning算法应用于以储能电池为模型的配电网储能装置电能出力控制中,研究该算法在储能电池荷电状态管理策略下可行状态空间的优化特性,并将该算法的优化结果与经典动态规划方法优化结果进行对比,验证了在储能电池出力控制的应用背景下Q-learning算法能够与动态规划算法达成一致最优解的结论。
1 蓄电池的储能特性
以蓄电池为代表的电化学储能是一种目前应用较为广泛的储能技术。不仅拥有较高的能量密度和功率密度,同时低廉的成本也是其在能源应用领域的优势所在。在配电网储能系统的应用背景下,选取蓄电池储能装置,研究蓄电池储能装置正常工作时剩余电量、固定时段内的充、放电量以及自放电等参数的相互关系。储能充电过程可以表示如下:

(1)
对应的储能放电过程可表示为
(2)
式中:SOC(t)为蓄电池储能装置在t时间段的荷电状态,Pb是蓄电池储能装置在t时间段的充放电功率,σ为储能介质的自放电率,LC为蓄电池储能装置的充电损耗,LDC为蓄电池储能装置的放电损耗,Δt为计算周期时长,Ecap为蓄电池储能装置的额定容量。
蓄电池储能装置在其正常工作内的充放电功率受到硬件限制的充放电特性和自身荷电状态状态的影响,其荷电状态需要满足以下条件:
SOC min≤SOC(t)≤SOC max
(3)
式中:SOC min和SOC max分别为蓄电池储能装置荷电状态的最小值和最大值,即约束了荷电状态的正常范围。
2 储能装置优化调度模型
2.1 强化学习建模
强化学习方法的原理是将优化问题建模为一个马尔科夫决策过程来进行求解[7],本文把配电网储能装置的策略优化问题描述为一个马尔科夫决策过程。在马尔科夫决策过程中,定义环境状态st为t时间段蓄电池储能装置的可行离散电量,动作at为t时间段内蓄电池储能装置的平均放电量,由当前时间段和对应下一时间段可行离散电量、时间段内平均充电量所确定;同时定义t时刻的奖励函数rt(st,at)为
(4)
其中
(5)
Et=APf,tΔt
(6)
式中:C为常数,Et为t时段内蓄电池储能装置对外发出的电能,Nt为t时段内蓄电池储能装置的平均出力,Nb为t时段内蓄电池储能装置的保证出力,Eb则作为惩罚项代表蓄电池储能装置在保证处理下产生的电能;A为出力系数,Pf,t为t时段内蓄电池储能装置的平均发电功率,Δt为t时段的时间长度值。
采用值迭代的算法求解储能装置调度的最优方案,定义Q(st,at)为动作值函数,简称Q值,即:
…+r(st-1,at-1)+r(st,at)]
(7)
转化为递推形式:
(8)
将蓄电池储能装置优化调度模型以时段奖励函数rt(st,at)为基础,以确保电能出力为目标,在扣除惩罚值后将各时段内的发电量进行累加,即可得到总发电量E*,并以该数值为基础构建目标函数,表达式如下:
(9)
也可将E*表示为
(10)
2.2 建立强化学习约束空间
2.2.1 强化学习状态转移约束
蓄电池储能装置的供能关系约束条件即为强化学习状态转移约束条件。功能平衡方程的计算公式如下:
(11)
式中:Qt、Qt+1分别为t时间段初、末时间段下的储能状态。Pin,t、Pout,t分别为t时间段内蓄电池储能装置的输入和输出平均功率。
储能装置输出功率约束:
Pmin,t≤Pout,t≤Pmax,t
(12)
式中:Pmin,t和Pmax,t分别为t时段内储能装置输出功率的最小值和最大值。
配电网需求侧功率约束:
Pdis,min≤Pdis,t≤Pdis,max
(13)
式中:Pdis,min和Pdis,max分别为t时段内配电网需求侧功率的最小值和最大值。
荷电状态约束同式(3)。
2.2.2 确定强化学习可行状态空间


图1 蓄电池储能装置可行荷电状态边界求解。
当确定荷电状态边界后,可以将强化学习过程的要素定义为t时间段的状态集合、动作集合以及式(4)中的奖励函数。状态集合为t时刻的可行荷电状态;动作集合为蓄电池储能装置的输出功率,数值可由功能平衡关系确定;奖励函数集合由t时刻当前蓄电池储能装置荷电状态及其对应的动作集合共同确定[9]。
2.3 配电网储能装置优化调度模型
Q-learning是一种基于离轨策略的强化学习算法,它根据时序差分控制的原理并以Q值为评价标准,通过不断的迭代来求解最优动作,Q-learning算法的目的是在一个迭代回合中使累计期望回报达到最大。Q-learning算法的迭代过程就是从历史经验轨迹(也即马尔科夫决策链)中学习最优动作的过程,在单次的模拟流程中,Q-learning通过即时更新Q值为下一次模拟形成新的方案,其算法流程如下:
1)随机初始化Q(s,a),∀s∈S,a∈A(s)。
3)t时刻下,智能体应根据环境状态st执行动作,本文采用了ε-greedy策略作为智能体的动作策略。
(14)
εt=εb
(15)
式中:εt为t时刻ε的值;ε为小数,其含义为智能体在t时刻有ε的概率随机选取动作;b为接近1的小数,一般取0.9;π(st)为t时刻根据状态st采取的策略;εm为小数,一般取0.1。

图2 算法流程。
当算法迭代次数达到一定数量时即可终止,最优策略的生成不再由ε-greedy策略决定,而是依据各时刻相应状态下的最优Q值选取动作形成最优策略。
3 实例分析
3.1 配电网储能装置实例
以某配电网储能装置为例,其储能容量为60 kW·h,最大输出功率为30 kW,出力系数A=1。以台区日内负荷变化作为调度时段,将储能装置典型高负荷日的输出功率作为模型的输入。
3.2 试验结果分析
为了证明Q-learning算法在配电网储能装置优化调度问题上的有效性,设置了Q-learning算法与动态规划算法的对比实验:首先,使用动态规划算法求出储能设备日内各时刻的最优荷电状态;其次,将离线训练好的Q-learning算法在线部署,使其在线生成储能设备日内各时刻的最优荷电状态;最后,对比两种方法的性能。动态规划的优化结果见图3。
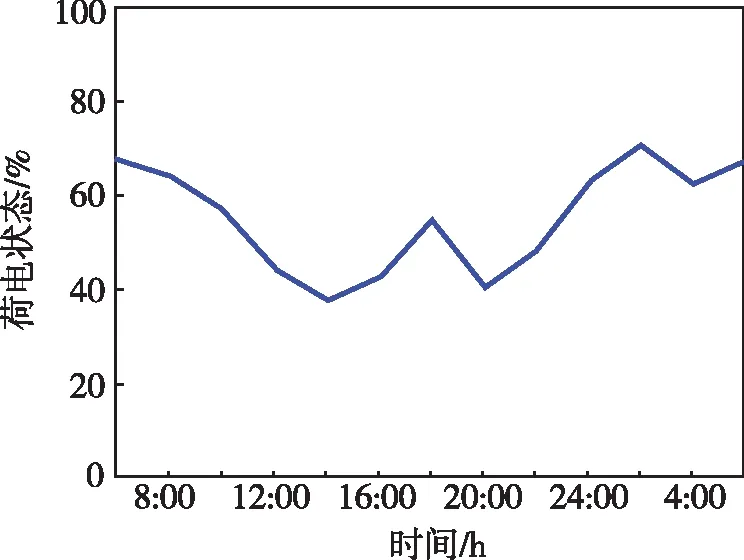
图3 基于动态规划算法的日内最优荷电状态。
本论文定义Q-learning算法的学习率为α,同时对该参数进行敏感性分析,分别设置3组实验,每组实验α值分别设置为0.01、0.05、0.1,然后观察各组实验Q-learning的迭代过程。对于其他超参数,设置ε初始值为0.99,常数值b为0.99,εm值为0.1。强化学习智能体和环境互动的次数越多,经验越丰富,所做的策略越准确。在训练时让智能体和环境交互1百万次,其中包括1 000个回合,每回合包括1 000个迭代步,每回合记录依赖Q值生成的解对应的总奖励值,最终优化结果见图4。
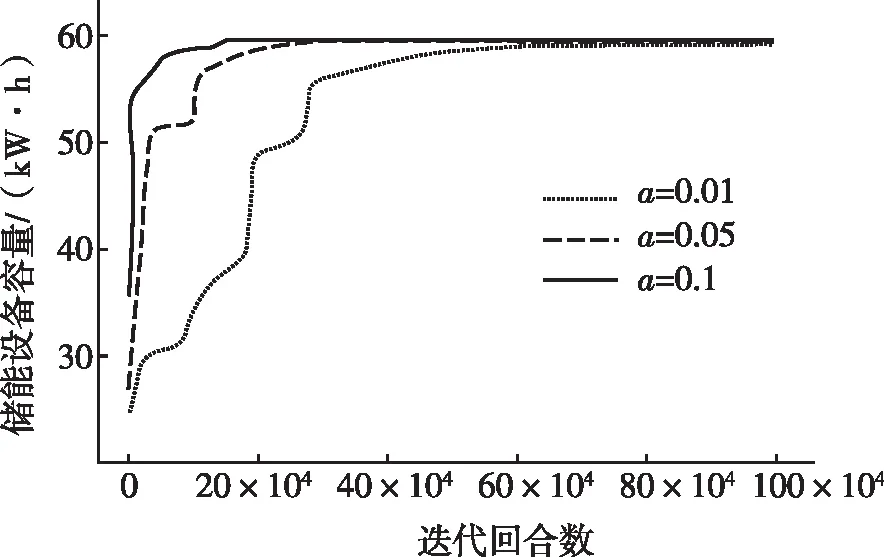
图4 Q-learning迭代过程曲线。
从图4中可以看出:由于Q-learning算法刚开始进行随机探索,所做的动作是随机的,因此获得较低的奖励,随着探索的减小,Q-learning算法逐渐学习到正确的策略,奖励值不断增大,随着迭代的进行,Q-learning算法不再探索随机动作,而是采用学习到的最优动作,因此奖励函数逐渐收敛,Q-learning智能体也进入稳定的最优状态。参数α越大,Q-learning收敛的越快。
表1为Q-learning算法不同α值的对比结果,图5为动态规划与Q-learning不同α值变化的对比。由表1及图5可知,随着α值的不断增大迭代收敛的速度会不断变快,其训练所需的时间也会大大减小,因此我们在训练时需要将α值调整为0.1。在Q-learning算法训练的前期,由于动作是随机探索的,因此Q值存在较大的优化空间,其奖励值和优化效果也会呈现较大的变化趋势。随着迭代的进行,Q-learning算法的动作逐步稳定并趋于最优,这时Q值对动作的评估和每回合的累计奖励也达到稳定,迭代收敛。迭代后期当Q-learning算法所做的决策逼近最优解时,优化趋于平稳状态,Q-learning算法能够与动态规划算法达成一致最优解。
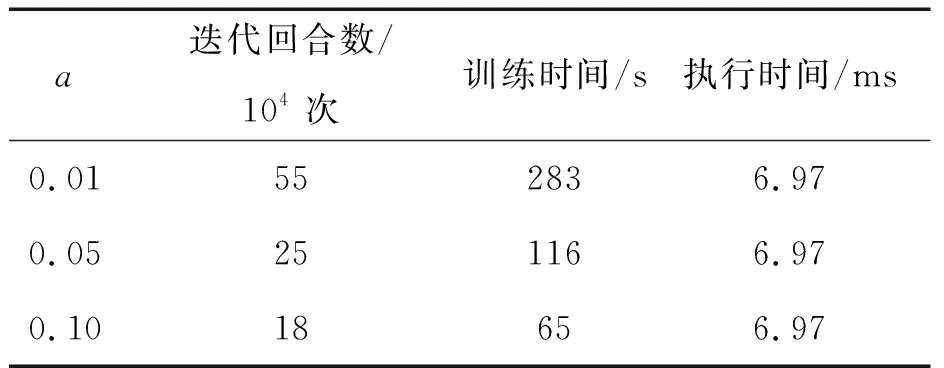
表1 Q-learning算法不同a值对比结果
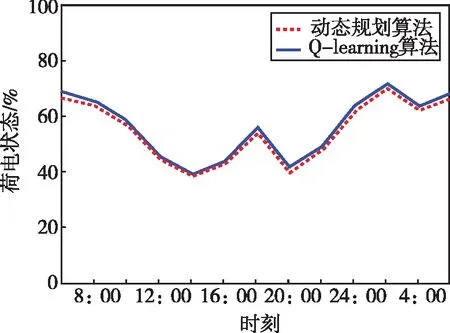
(a)α=0.01。

(b)α=0.05和α=0.1图5 动态规划与Q-learning不同α值荷电状态变化对比。
如2.3节中的算法流程所示,在每个迭代步开始时智能体根据当前的状态从Q表中选取Q值最大的动作,迭代步结束时根据式(8)来更新Q表。训练迭代1百万次的目的就是得到一个完美的Q表,这个过程是离线进行的,所消耗的时间是可以接受的。训练完成后,将训练好的智能体(具备完美的Q表)部署下去进行在线执行,在线执行时智能体输入当前的状态,根据Q表可以实时得到一个最佳的策略,因此相比其他算法,Q-learning算法在执行过程中得到策略的过程非常快,是毫秒级别[10]。
上述结果显示,在整个可行的策略搜索空间中,当训练回合数达到一定的数量时,Q-learning算法所构建的配电网储能装置可以执行最优的动作,实现调度任务的最优化。
4 结 论
将强化学习的Q-learning算法应用于配电网储能装置的控制策略中,以蓄电池储能装置为例建立了优化调度模型,并通过调节强化学习超参数实现迭代优化。证明了当迭代次数达到一定数量时,Q-learning算法可达到理论上的最优解。该方法在大大减少优化时间的同时,获取了同动态规划一致的最优调度方案。该算法能够有效引导蓄电池储能装置学习到满足预设目标且趋于最优的充放电策略,根据用户在不同时段用电需求及用电特征,储能装置在用电低谷期时充电,在日间根据用户负荷的实时需求放电,就地增大供电能力,缓解配电网季节性配电变压器重过载问题,具有较高的应用价值,但Q-learning算法仍然存在一定的局限性,例如在处理大规模问题时会出现计算效率低下和内存需求过大的问题,以及在用于多智能体的环境时,会面临其他智能体策略变化导致非平稳问题。针对配电网的环境中的不确定性可以考虑将其他算法与Q-learning相结合,来提高Q-learning算法的适应能力。
