基于双判别器的汉泰伪平行语料生成方法
2023-10-19陈奥博章浩然
陈奥博, 章浩然, 吴 霖
(1.昆明理工大学 信息工程与自动化学院, 云南 昆明 650500; 2.云南省人工智能重点实验室, 云南 昆明 650500)
0 引 言
随着神经机器翻译的飞速发展,在高资源语言对上,其性能已经优于统计机器翻译。但在低资源语言对上,神经机器翻译的性能仍然弱于统计机器翻译[1]。而汉泰语言对属于低资源语言对,如何通过数据增强方法改善汉泰神经机器翻译的性能是值得研究的问题。
比较常见的是利用回译模型获取伪平行语料,这种方式需要额外训练一个将目标语言翻译为源语言的翻译模型,该翻译模型可以由少量平行语料或单语语料训练得到。但在汉泰语言对中,由于缺乏平行语料,故而不能训练出高质量的回译模型,因此得到的伪平行语料也较差。
文献[2-3]中使用迭代回译的方式改进回译模型,对两个翻译方向相反的翻译模型进行回译,并将回译得到的伪平行语料与干净平行语料混合,共同输入到另一个翻译模型进行训练,以这样的方法来迭代提高两个回译模型的性能。其生成的伪平行语料质量有所提升。而文献[4-5]中提出将枢轴翻译与回译相结合,利用高资源平行语料来训练回译模型,以此改善回译模型的性能,从而提高伪平行语料的质量。文献[6-7]提出了利用生成式对抗网络(GAN)的方法来提高回译模型的性能。尽管生成式对抗网络在提高翻译模型性能上存在优势,但文献[6]提出的判别器只在句子级上进行判断,无法回传词级信息。Yang Zhen 等人使用蒙特卡罗搜索构造的中间句子来反馈词级信息[8],但其反馈的词级信息受句子质量影响较大,难以精准回传词级信息。
针对上述问题,本文在生成对抗网络的基础上,提出一种基于双判别器的汉泰伪平行句对生成方法。该方法主要从以下两个方面进行改进:
1) 在以回译模型作为生成器,以枢轴语言的筛选模型作为判别器的基础上,进一步构建汉语-泰语判别器,以此来提高判别器判断译文质量的准确性,提高生成器对汉泰数据集概率分布的拟合程度。
2) 提出基于词性的中间句子构造方法,并以原句子与中间句子的评估分数之差作为最终反馈分数,更为准确地将判别器的评估反馈到生成器中。
1 方 法
基于双判别器的汉泰伪平行句对生成方法包含三个部分,分别为基于Transformer[9]的翻译模型、双判别器的构建以及融入基于词性中间句子构造方法的对抗网络,其中,基于双判别器的生成式对抗网络框架图如图1 所示。

图1 基于双判别器的生成式对抗网络框架图(英语-汉语)
基于Transformer 的翻译模型在对抗训练中作为生成器,用于生成额外的伪平行语料;然后采用基于CNN的筛选模型作为判别器,用于评估生成器生成的伪平行语料。
1.1 双判别器构建
采用枢轴翻译与回译相结合的方式生成伪平行语料时,单个针对枢轴语言的判别器并不能帮助生成器拟合最终汉泰平行语料的分布,从而导致生成伪平行语料的过程中存在翻译误差,这会降低伪平行语料的质量。因此本文额外添加一个新判别器,帮助生成器拟合汉泰平行语料的分布。
1.2 基于词性的中间句子构造方法和对抗训练
由于传统的蒙特卡罗搜索方法在构建中间句子时,受上下文影响较大,因此本文提出基于词性的中间句子构造方法(在后文中称为词性替换),基于目标词的词性信息,分别利用词性相同和词性相异的词替换目标词来构造中间句子,公式如下:
式中:Rewardt代表目标句子中第t个词的对齐分数;N代表生成器(翻译模型)生成的目标句子;Sametk代表由词性相似的词构造的中间句子,Sametk=N1,N2,…,St,…,NT;Difftk代表由词性相异的词构造的中间句子,Difftk=N1,N2,…,Dt,…,NT;D(X,·)代表目标句子或中间句子的对齐分数;K是一个固定值;St和Dt分别代表与Nt词性相同的词和词性相异的词。
然后对两个判别器(筛选模型)的Rewardt进行加权求和,得到最终并且只取大于0 的部分。如果小于0,则在生成式对抗网络训练时容易造成训练不稳定,从而导致梯度消失,如式(2)所示:
式中:λ是一个固定值,经实验验证取0.5 时结果最好;是原有判别器的反馈;是本文额外构建判别器的反馈。最后该将加权到生成器的损失值中。
为了提高生成式对抗网络的稳定性,本文将生成式对抗网络的训练在原始数据和枢轴数据上交替进行。最后,将得到的对齐分数作为权重,加权到生成器的损失函数中,得到生成器最终的损失值。本文采用了与Li等人类似的Teacher forcing 方法[10]来进一步提高生成式对抗网络训练时的稳定性,在进行对抗训练前,先将生成器和判别器在原始数据集上训练至收敛,再进行对抗训练。
1.3 伪平行语料生成
生成伪平行语料时,分别利用英泰翻译模型(英泰生成器)和英汉翻译模型(英汉生成器)在两个翻译方向分别生成泰语-汉语以及汉语-泰语的伪平行语料。本文以生成汉泰伪平行语料为例,首先,将英语作为汉语和泰语的枢轴语言,在生成器部分将英泰平行语料中的英语作为输入,通过英汉翻译模型(英汉生成器)将其翻译为汉语;然后在判别器部分,通过英汉判别器和本文额外添加的汉泰判别器联合对生成器进行反馈,使生成器能够生成不易被判别器察觉的伪平行语料,从而使判别器能够更准确地判别出伪平行语料,以此进行对抗训练;最后,使用训练好的英汉翻译模型(英汉生成器)生成所需要的更高质量的英汉伪平行语料。生成汉泰伪平行语料的流程图如图2 所示。另一方面,生成泰汉伪平行语料时,需将英汉平行语料中的英语语料作为输入,通过英泰生成器将英语翻译为泰语,以此得到质量更高的泰汉伪平行语料。
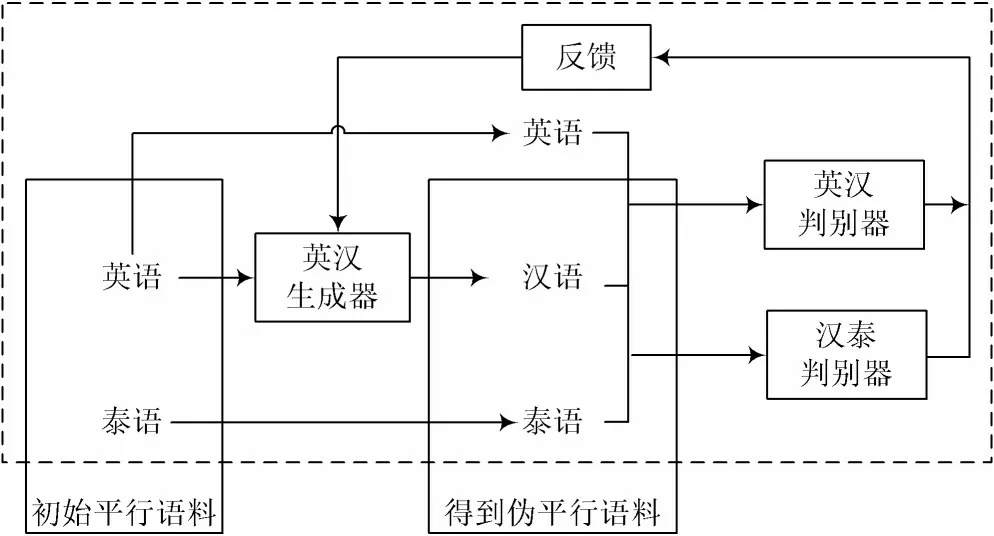
图2 汉泰伪平行语料生成流程
2 实验设置及方案
对本文采用的数据集、实验设置以及几种实验方案进行详细介绍。
2.1 数据集
本文的汉泰、英泰和英汉平行语料均来自于Opus[11]语料库,并且借鉴了OpusFilter 的方法[12]对汉泰、英泰和英汉平行语料进行初步过滤。从Opus 中抽取20 万句汉泰平行语料作为训练集,抽取2 000 句作为验证集,同时抽取2 000 句作为测试集;英泰和英汉平行语料则抽取出100 万句作为训练集,同样也分别抽取2 000 句作为验证集和测试集。并且从Opus 中分别抽取同领域1 000 万句的汉语单语语料和泰语单语语料,用于训练语言模型和对比。其中汉语采用jieba 进行分词,泰语采用pythainlp[13]进行分词。
2.2 实验设置
本文所有实验均在TensorFlow 2.2 框架上实现,并采用一张NVIDIA GPU(GTX Titan X)来训练模型。实验中所有的翻译模型均为Transformer,编码器和解码器均采用默认的6 层,注意力头数设置为8,词嵌入维度设置为512,隐藏层维度设置为512,参数优化器选择Adam 优化器,dropout 设置为0.1,学习率设置为5×10-5,对抗训练时学习率设置为1×10-5,批次大小设置为64,词汇表大小设置为50 000。在伪平行语料生成阶段,采用集束搜索算法进行生成,集束宽度设置为4。
本文采用BLEU[14]作为评价指标,为了保证实验结果的可靠性,每组实验结果的BLEU 值都是通过相同的汉泰测试集进行实验得到。在实验中,除了直接训练方法使用的语料为20 万真实汉泰平行语料外,其他方法均采用20 万真实汉泰平行语料和20 万伪汉泰平行语料进行混合训练。
2.3 实验方案
2.3.1 不同数据增强方法的性能对比
为了验证本文生成伪平行语料的有效性,分别与回译方法、文献[4]方法、文献[5]方法、生成器(GAN)方法进行对比。
首先由各方法生成伪平行语料等比混合原始语料作为训练集,然后使用该语料训练汉泰翻译模型,最后由BLEU 值作为评价标准。此外,在实验中需保证每种方法所使用的混合语料大小均相同,同时在泰汉翻译方向做相同实验。
2.3.2 不同判别器对生成伪平行语料的过滤能力比较
过滤能力的比较是在同一数据集上用不同方法进行过滤,然后获取同等规模的训练语料,最后将过滤后的语料用于训练翻译模型,将BLEU 值作为评估标准。本文分别采用LSTM 语言模型、GAN 训练前的判别器、GAN 训练后的判别器以及LSTM 和训练后的判别器双重过滤等作为过滤方法。
2.3.3 消融实验
本文共提出两个改进方案:首先是在原始枢轴语言判别器的基础上添加一个拟合,最终训练语料的额外判别器;其次是在进行中间句子构造时,采用本文提出的基于词性替换的方法代替蒙特卡罗搜索的方法,以更好地反馈词级信息。实验分别采用单个原始判别器、单个额外判别器以及双判别器三种方案,并利用蒙特卡罗搜索方法和本文提出的词性替换方法构造中间句子,进行不同的实验。
3 实验结果分析
本文从不同角度设计并分析了不同条件下得到的增强数据在训练翻译模型时的表现,且均在汉泰和泰汉两个翻译方向做了相同的实验。
3.1 不同数据增强方法的性能对比
表1 所示为不同的数据增强方法在相同数据量下训练相同翻译模型的性能对比。

表1 不同生成方法训练翻译模型的BLEU 值
表1 的实验结果表明:文献[5]方法与回译相比有所提高,这是因为文献[5]方法存在二次翻译误差,它会导致初始翻译模型性能上的优势被掩盖;而文献[4]方法与回译相比有所提高,这是由于文献[4]方法只存在一次翻译误差,同时初始翻译模型是由更大规模的英泰和英汉平行语料上训练得到的,性能更好;生成器(GAN)生成的伪平行语料的质量要高于文献[4]方法生成的伪平行语料的质量;本文提出的双判别器+词性替换方法由于缓解了蒙特卡罗搜索方法难以精准回传词级信息所产生的误差问题,而且额外判别器使生成语料更贴近原始训练语料,因此所生成的语料质量最好,BLEU 值在泰汉和汉泰方向分别提高了2.09 和2.04。
3.2 不同判别器对生成伪平行语料的过滤能力比较
过滤能力的比较是通过过滤后的同等规模语料上训练的翻译模型的BLEU 值来进行评估。从表2 的实验结果可以看出,经过LSTM 语言模型过滤后的伪平行语料质量要低于经过判别器过滤后的伪平行语料。

表2 不同判别器的过滤能力比较
将经过对抗训练的判别器和LSTM 语言模型进行结合,共同过滤噪声语料,并与没有经过对抗训练的判别器和LSTM 语言模型相结合的方法进行对比,结果如表3 所示。由表3 得出,过滤后的伪平行语料质量BLEU 分别提高了0.24 和0.07。这说明经过对抗训练的判别器在过滤伪平行语料的性能上有了进一步提升。此外,还将判别器作用在文献[4]方法生成的伪平行语料上进行了对比。从实验结果可以看出,生成的伪平行语料在经过过滤之后效果是有一定提升的,而文献[4]方法+判别器(GAN)比文献[4]方法+判别器的过滤效果提升明显,这是由于生成式对抗网络的训练依然可以提高判别器的性能,但是提升幅度不大。从整体来看,本文方法训练得到的判别器在对其他方法生成的伪平行语料进行过滤时也是有效果的。
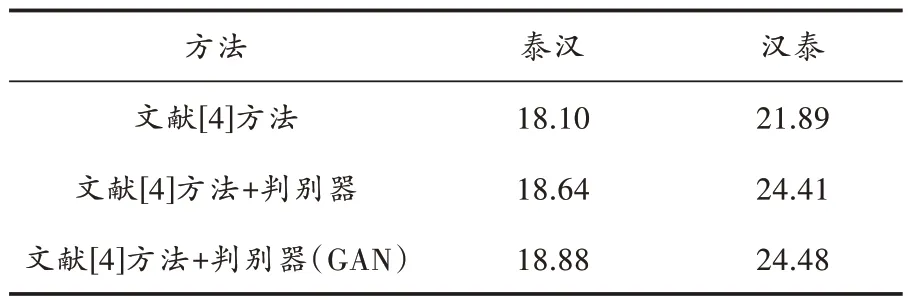
表3 判别器过滤效果验证
3.3 消融实验
针对文章所提出的改进方案进行消融实验,结果如表4 所示。
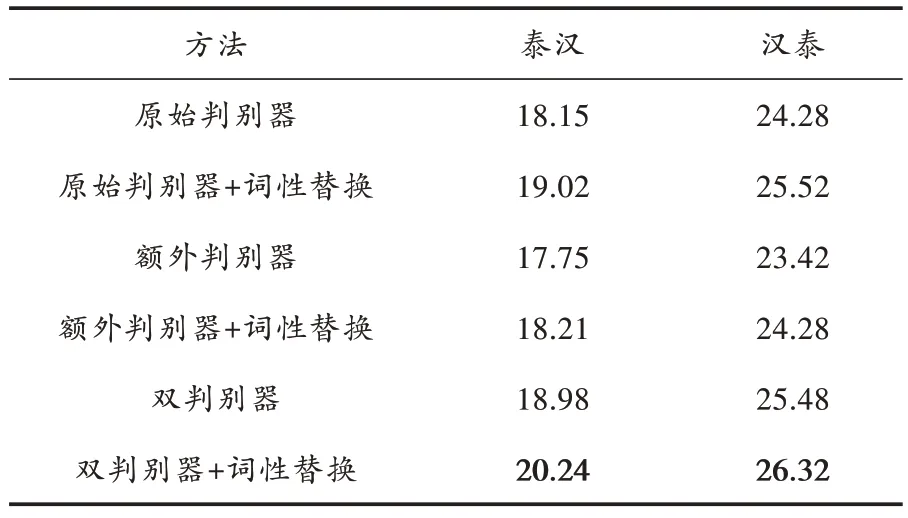
表4 消融实验结果
从表4 中结果可以看出,采用词性替换的方法替代蒙特卡罗搜索的方法性能有明显提升,这表明为模型提供更精准的词级信息有助于提升生成模型的性能。其中单使用额外判别器所表现的性能比单使用原有判别器略有下降,这表明单使用额外判别器使模型过度偏向目标训练集,会对最终生成模型的质量有所影响。最后,使用双判别器加词性替换的方法比单使用原始判别器加词性替换的方法效果也有所提升,表明本文提出的添加额外判别器的方法和词性替换的方法对提升生成模型的质量都有一定的效果。
4 结 语
本文在汉泰神经机器翻译任务上,针对汉泰平行语料规模不足和质量不佳的问题,提出双判别器的汉泰伪平行句对生成方法,并分别在汉泰翻译方向和泰汉翻译方向进行了实验验证。在原有的基于枢轴语言的生成式对抗网络的基础上,在汉泰翻译方向(泰汉翻译方向)进一步添加了汉泰判别器(泰汉判别器),帮助回译模型拟合汉泰(泰汉)数据集分布。在对抗训练中,原有的基于蒙特卡罗搜索的方法构造的中间句子在回传词级反馈信息时,词的质量过于依赖句子的质量,从而不能很好地反馈词级信息。为了缓解这个问题以及提高对抗训练的稳定性,本文提出了基于词性的中间句子构造方法替换蒙特卡洛搜索方法。实验结果表明,本文的方法在泰汉翻译方向上的BLEU 值为20.24,在汉泰翻译方向上的BLEU 值为26.32,相比文献[4]方法,BLEU 值在泰汉方向上提高了2.09,在汉泰方向上提高了2.04,证明了本文方法的有效性。
本文在对抗训练结合回译技术的基础上,实现了基于双判别器的汉泰伪平行句对生成方法,取得了不错的效果。在生成语料方面,伪平行语料的词汇和句法多样性可以帮助模型应对复杂的翻译情况,因此如何在提高模型性能的同时发挥生成式对抗网络的优势,提高伪平行语料在词汇和句法上的多样性,是本文未来的研究方向。在语料过滤方面,除了使用本文对抗训练中的判别器进行过滤,如何使用更好的评判方法评估伪平行语料的质量也是数据增强的一个研究方向。现有针对带有噪声的平行语料过滤方法大多都是根据一定的规则进行静态过滤,如何将过滤之后的结果动态地反馈给过滤模型也是提升低资源机器翻译模型性能有效的方法。
注:本文通讯作者为吴霖。
