基于大数据技术的网络舆情感知系统的分析与实现
2023-10-19赵淑君江凤月
赵淑君, 刘 伟, 江凤月
(南阳理工学院 河南 南阳 473000)
0 引言
近年来,我国社会进入社交媒体爆炸式发展的阶段,信息的传播速度奇快,网络舆情信息不仅是一个个热门话题,更是对政府的感知能力和社会治理能力提出了全新的挑战[1]。所谓的网络舆情是以网络为载体,在一定的社会空间内,通过网络对社会事件的发生、发展和变化,产生的态度、信念和价值观,即广大网民对热点事件的情感、态度、意见、观点的表达、传播与互动,以及造成的后续影响力的集合[2]。因此,互联网成为有关部门了解网民的思想动态和舆情信息的重要途径。近年来,网络舆情事件频发,从表现上看,相关职能部门对网络舆情信息的感知度不够灵敏,常常错过网络舆情事件处理的最佳时间,或者对网络舆情信息的发展形势判断不够准确,出现误判等情况。基于该现状,一款能够自动获取网络舆情信息并对舆情信息进行分析的软是相关职能部门迫切需要的。相关职能部门可以通过该系统在海量数据中抓取网民对某事件的评论和情感倾向,来了解并把握群众的情绪,从而对舆情事件做出更加高效、正确的决策。
1 大数据技术和网络舆情
当下正处于“数据大爆炸”的时代,全球数据规模飞速增长,目前全球存储系统迎来新一轮变革机遇,正在从“Big Data”(大数据)发展到“Fast Data”(快数据)。至2022年12月,我国网民规模达10.67亿,比去年同期增长3549万,互联网普及率达75.6%。网民规模在不断扩张,数据越来越大,数据的结构、类型更加丰富和多元。从近年来的一些网络舆情热点现象来看,网络舆情在社交新媒体的“加持”下更是具有多元、多样、快速、情绪化的特性[3]。
1.1 大数据概述
对于大数据的概念麦肯锡全球研究所给出的定义是一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型[4]。“大数据”有4V层面,分别是Volume(规模性)、Velocity(多样性)、Variety(高速性)、Veracity(价值性)[5]。Volume是体积,“大数据”的数据量体积庞大,2021年全球实时数据量规模为16 ZB,2025年实时数据量将达到51 ZB;Variety是速度,大数据正在向快数据演变,即数据产生的速度快,同时要求“大数据”的处理频度要高、处理速度要快;Variety是类型,“大数据”的数据类型繁多,包括日志、UGC(包括图片、音视频)、LBS信息等;Variety是价值密度,“大数据”价值密度低,比如某个用户的LBS信息需要长时间积累才能有价值。
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,是一个开源的大数据分析软件,集合了大数据不同阶段技术的生态系统。用户可以在不了解分布式底层细节的情况下,开发分布式程序。网络舆情数据采集和数据处理分析过程中,充分利用集群的威力进行高速运算和存储,选用Hadoop集群可以从单一的服务器扩展到成千上万的机器,将集群部署在多台机器,每个机器提供本地计算和存储,可以在本地进行网络舆情信息爬取,并且在本地进行计算和存储。Hadoop的核心组件有Yarn、HDFS和MapReduce,其中,Yarn是分布式资源管理系统,实现集群资源管理和调试;HDFS是分布式文件系统,主要用来解决大数据分布式存储问题;MapReduce是分布式计算框架,实现大数据分布式计算功能。
1.2 网络舆情处理技术
在Web3.0大环境中,网络信息的传播呈多样化,网络舆论场从微博、聊天室的单一渠道发展到小红书、抖音、哔哩哔哩、微信等多种形式,网络舆论场的数量和聚集地剧增,特别是对舆论事件的评述也由传统的设置议题和阐述言论演变为弹幕、投票等多种新的形式,给网络舆情的监测、分析和治理工作带来了更大的难度[6]。利用数据科学与大数据技术来研究网络舆情,能够快速获取有效信息,并对信息进行分类和推送,为相关组织机构的舆情监测、舆情分析、舆情危机公关决策等提供一定依据。借助于成熟的大数据技术,通过全文搜索、来源搜索、热搜监测等多重功能实现对全网文本、图片、视频舆情实时发现,利用文本分析技术进行情感分析、高频词分词、文本分类、事件分类等,对网络事件进行关联分析、趋势分析和倾向性分析[7]。本文主要对大数据技术结合网络舆情进行分析研究,从而构成新型的网络舆情分析模型。
本文中网络舆情处理的核心技术主要有5个步骤:
(1)舆情监测:利用爬虫技术对网络上的舆情信息进行实时监测,通过全文搜索、来源搜索、热搜监测等多重功能实现对全网文本、图片、视频舆情实时发现。
(2)舆情预处理:利用大数据技术对舆情信息进行数据去重和数据清洗。将不同类型的数据存储在不同的数据模型中,如数据去重,可以把URL都存储在Redis中完成URL的去重;内容去重,用Elasticsearch将文章标题一样的内容进行检索过滤。数据清洗可以通过自动提取字段和采用自动分类技术对软文、广告文、敏感文章分类,并且对抓取信源屏蔽。
(3)舆情存储:利用HDFS技术将数据存储多份,用储存空间换取查询时间。
(4)舆情分析:利用文本分析技术进行情感分析、高频词分词、事件分析、评论分析等。
(5)舆情报告:利用可视化技术对舆情信息生成分析报告,为舆情管理提供科学依据。
网络舆情感知系统主要有数据采集模块、数据分析处理模块(数据仓库)和数据可视化展示3大功能模块。系统的数据处理流向如图1所示。

图1 数据流向图
2 数据采集系统
从爬虫角度看,基于大数据技术网络舆情感知系统的数据处理的关键在于能够及时捕抓到舆情信息。系统数据的获取通过使用分布式框架,建立分布式舆情数据采集机制,可以快速抓取各种类型的数据。
(1)网络舆情数据获取。系统运用Redis数据库做分布式,一个Master节点和多个Slave节点,Master端管理Redis数据库URL队列和任务的分发,Slave节点根据分配的任务,爬取网页信息并解析提取网页数据,再将解析的数据存储在MongoDb数据库中。分布式爬虫控制节点执行流程如图2所示。

图2 分布式爬虫控制节点执行流程图
(2)网络舆情数据存储。系统选用Hadoop框架HDFS文件系统以及NoSQL数据平台,将提取到的数据存储到MongoDB数据库中,便于后续流程对数据进行分析使用。
(3)网络舆情数据的分布式计算。Hadoop框架的MapReduce可以实现分布式计算,将待处理的舆情信息自动划分成多个数据块存储在不同数据节点上;将每个数据块的数据处理作业划分成多个Map任务加以执行,再经过Reduce任务处理后将结果进行输出,MapReduce计算保证了系统执行的可靠性和可扩展性。
3 数据分析处理
为从海量原始数据中获取到有效数据,需要对爬取到的原始数据做进一步的提取和数据清洗,得到标准的数据格式,然后再对数据进行文本分析。
(1)数据提取
系统采用Redis数据库,可以充分发挥它的优势,首先对URL进行去重,另外,在HTML的原始代码中,有很多成对的标签,需要找到要爬取的标签,再开始提取有效信息。
(2)数据清洗
通常爬取到的数据都是非标准的数据格式,需要对数据进行预处理[8]。从非标准的数据格式中提取每个新闻的标题、正文、作者、发布日期以及对应的正文页面URL等,将有效数据保存到CSV文件。
(3)文本分析
将数据存储到CSV文件之后,对文本内容进行分析。先使用jieba分词器对中文文本分词,分词后的数据仍是杂乱无章,需要再次进行数据清洗工作,通过去除停用词将文中多余的一些副词、量词去掉,只保留主体内容,然后做词频统计,将高频词统计出来生成词云。为了便于计算将文章词语转化成数字,然后把文档生成TF-IDF矩阵,计算文章相似度,再通过K-means聚类,最后得到几个类的主题词。
4 系统架构设计
本文的系统架构设计分3个层次,分别是舆情数据采集层、舆情数据加工层和舆情数据分析与挖掘层,系统架构设计如图3所示。

图3 系统架构图
(1)舆情数据采集层
舆情数据采集的质量与大数据的分析结果有着至关重要的关系,舆情监测的准确性和全面性直接关系到后期舆情数据的分析和舆情事件的处理,是保证网络舆情感知系统是否能够准确进行舆情处理的重要因素[9]。网络舆情数据的采集,数据源主要有新闻媒体(新闻网站、电子报、APP)、网络自媒体(搜狐、今日头条、博客、微信公众号、微博)、论坛(贴吧、论坛、问答、知乎)、短视频(抖音、快手等众多平台)等。本文采用分布式网络爬虫技术从上述网站、论坛等平台来获取数据,通过利用关键词、主题词,如“高考”“就业”“民生”“南阳”等进行网络爬虫,从而抓取相关的网络舆情数据。
(2)舆情数据加工层
利用爬虫技术采集来的舆情数据通常多而杂,会有大量的不完整的、不一致的和含有噪声的数据。舆情数据加工主要是对这类数据进行过滤、去重和清洗。本文采用Redis数据库可以自动进行URL去重;采用Elasticsearch内部的查询将文章标题一样的内容检索过滤掉;通过自动提取字段来提取关键数据,自动分类技术对软文、广告文、敏感文章分类,并且对抓取信源屏蔽实现数据的清洗工作,具体运用的技术有缺失数据的人工填充、噪声数据平滑技术等。然后,将清洗和加工后的数据存储在非关系数据库中,为便于后期数据分析和挖掘在数据仓库中加以存储。
(3)舆情数据分析与挖掘层
数据分析与挖掘是对数据仓库中的数据进行分析,利用数据挖掘技术,获取相关网络舆情数据信息,给舆情的危机预警和应急事件处理提供决策支持[10]。例如,通过中文分词提取关键词并对关键词进行分析,来获取有价值的舆情信息;根据关联规则挖掘,获得相应网络舆情发展态势;利用聚类分析技术,对文章相似度聚类,挖掘相似的网络舆情信息,利用深度学习框架进行情感分类,获取积极舆情、中性舆情和消极舆情。为相关职能机构提供有价值的舆情信息。
5 系统实现
5.1 系统集群规划
系统实验阶段配置3个数据节点,结合Hadoop使用情况和系统所占用资源比例与其他组件所需内存配置与用户需求。最终选取测试服务器规划如表1所示。
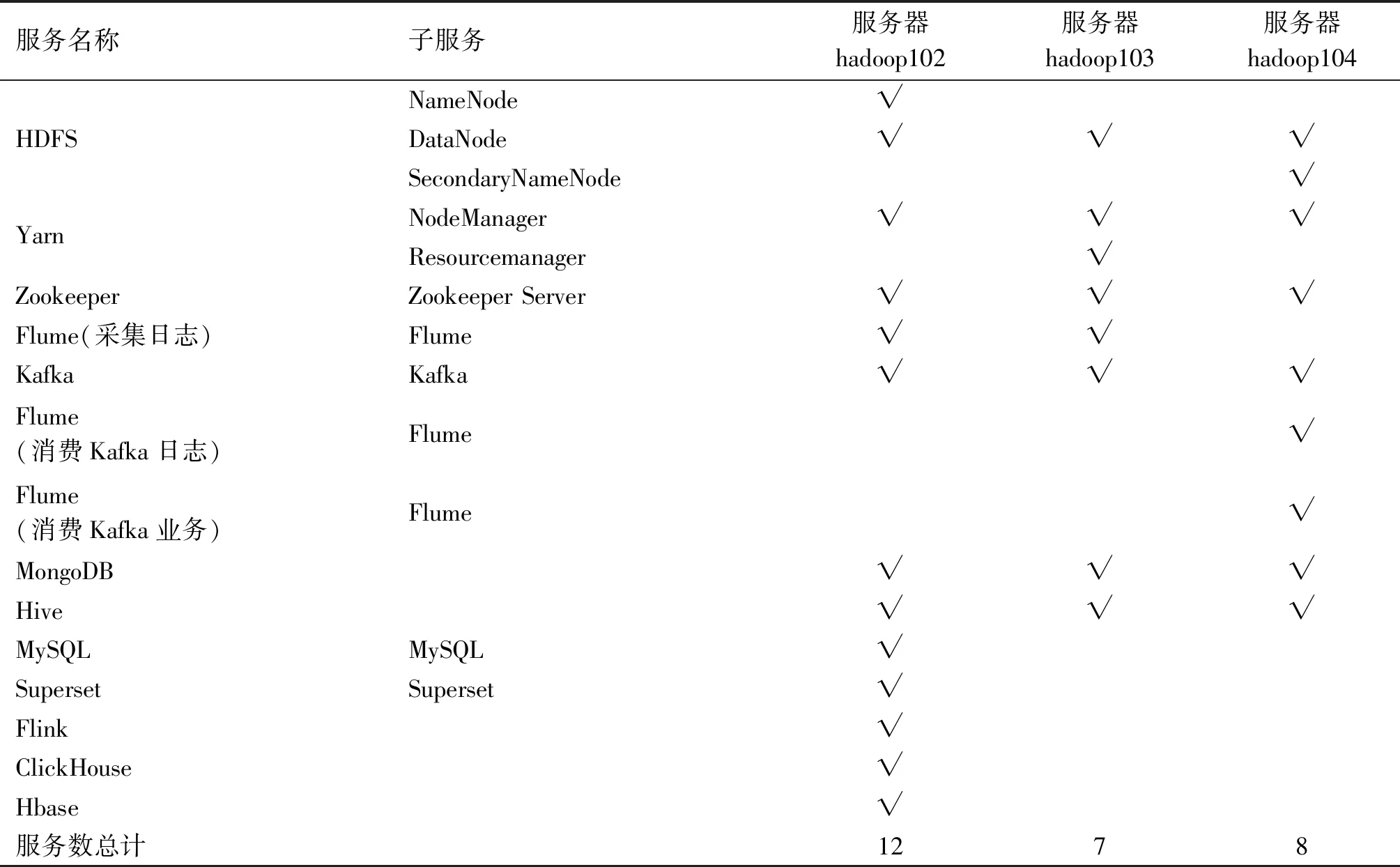
表1 测试服务器规划
5.2 数据可视化展示
基于大数据技术的网络感知系统可以根据用户的关注点不同,灵活设置关键字,从不同的媒介平台爬取用户所关心的新闻信息,并对爬取的数据进行分析展示。文中的实验数据,以南阳市“社会民生”版块为例,设置“南阳市”“高考”“民生”等关键字,用分布式爬虫技术,抓取2023年6月份部分数据并进行存储。获取到新闻基础内容,舆情的数据结构不同,数据格式不同,来源分散。下文分别从不同的角度展示爬取到的舆情内容。
(1)舆情数据监测
利用分布式爬虫技术实时监测“南阳市”“高考”“民生”等关键词的网络舆论,将监测到的数据罗列显示,自动将舆论进行聚类以及情感分类。舆情数据监测如图4所示。
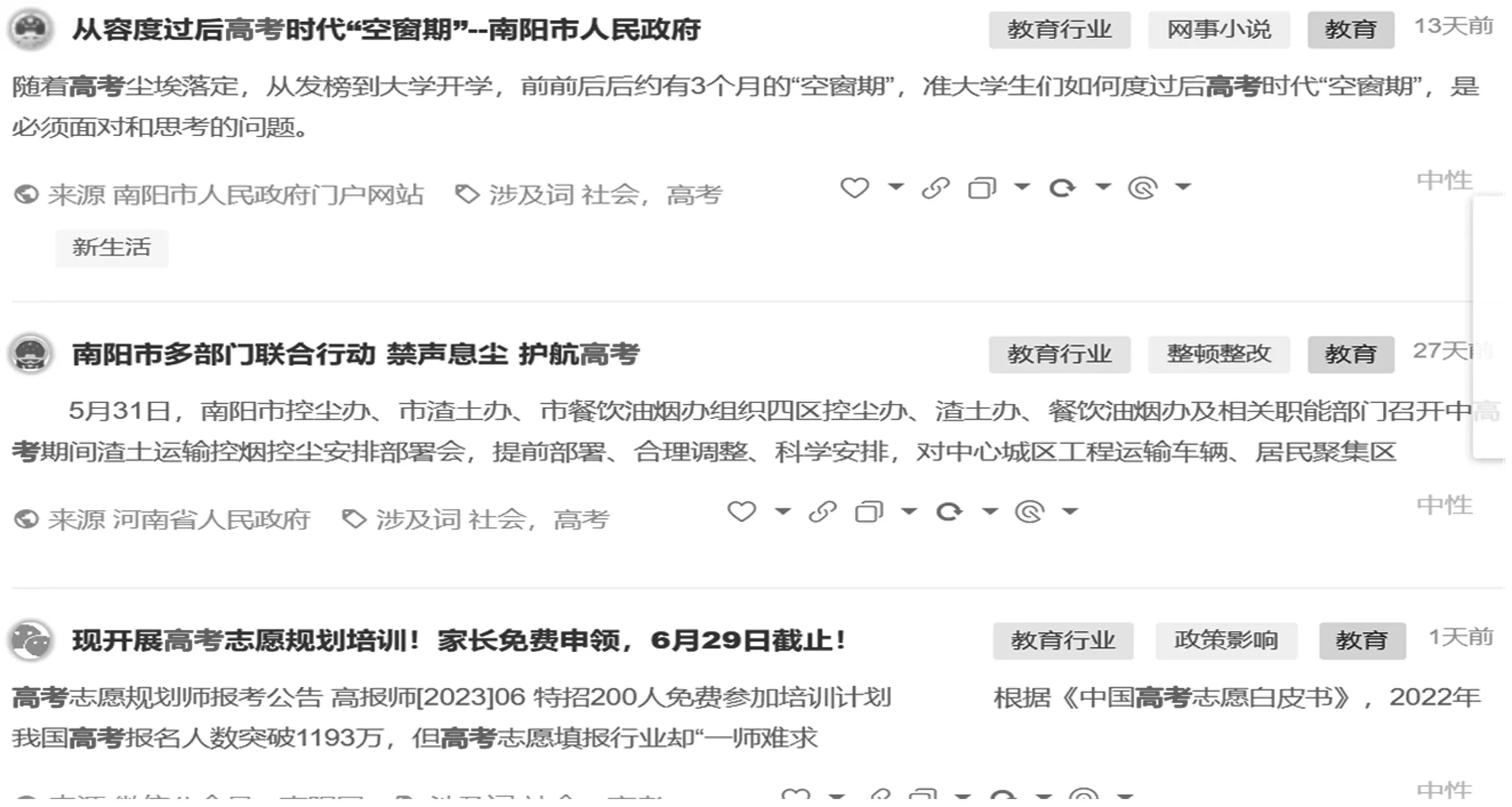
图4 舆情数据监测图
(2)舆情热词云分析
词云是将词语按照一定顺序和规律进行排列,按照词语出来的频度或者字母的顺序进行排列,再以文字的大小来显示热点词语。图5是南阳市6月份“社会民生”板块的关键词。从图5中可见,毕业季南阳市网民的关注点是大学生、就业、人工智能;高考过后,人们的关注点是志愿填报、招生计划等内容。

图5 舆情热词云图
(3)舆论情感占比分析
本文采用百度情感分析Senta模型自动识别和提取文本中的倾向、立场、评价、观点等主观信息。自动判断该文本的情感极性类别并给出相应的置信度进行情感分类,获取积极舆情、中性舆情和消极舆情。从图6舆情情感占比分析图中积极情感占10.43%,中性情感占82.7%,消极情感占6.87%。

图6 舆论情感占比分析图
6 结语
经研究测试,利用大数据技术实现网络舆情分析系统,能够帮助相关职能部门更好地掌握人们对于热点事件的关注强度,对网络舆情有效引导起到重要作用,有利于社会的稳定[11]。该系统在数据获取上,抓取数据途径受到一定的限制,对视频、音频、图片等载体的数据获取量不够,数据采集技术和关键词设置不够全面,数据分析模型也需要进一步研究完善,这些内容也是下一步继续研究的方向。总之,通过大数据技术,实现对不同数据的有效抓取,实现网络舆情的感知分析,为网络环境的健康发展打下良好基础。
