面向拟态存储系统的高效同步方法研究
2023-10-18李婉桃张帆陈鑫朱进黄潇
李婉桃 张帆 陈鑫 朱进 黄潇

摘 要:针对现有拟态存储架构中数据同步方法时延增速过快,导致系统安全调度时的性能下降问题,提出了一种预同步模型,让备用执行体在异构池中利用检查点进行数据预同步工作,从而减少执行体上线时间。进一步地,根据预同步模型的同步特点和切换调度情况,提出一种执行周期最大有效率的检查点放置(execution cycle maximum efficiency checkpointing,CMEC)方法。通过最大化每个执行周期的有效工作率求得最佳的检查点间隔,较好地平衡了检查点开销和回滚开销。实验证明,与现有的全量同步策略相比,该方法缩短了执行体上线过程中的同步时间开销,提高了同步效率,保障了系统在业务量不断增加场景下的服务稳定性和连续性。
关键词:拟态存储系统;预同步模型;检查点;服务稳定性和连续性
中图分类号:TP309.3 文献标志码:A
文章编号:1001-3695(2023)09-036-2792-06
doi:10.19734/j.issn.1001-3695.2023.02.0055
Research on efficient synchronization method for mimic storage system
Li Wantao1,2,Zhang Fan3,Chen Xin2,Zhu Jin2,Huang Xiao2
(1.School of Cyber Science & Engineering,Southeast University,Nanjing 210000,China;2.Endogenous Security Research Center,Purple Mountain Laboratory,Nanjing 210000,China;3.National Digital Switching System Engineering & Technological R&D Center,Zhengzhou 450000,China)
Abstract:Aiming at solving the problem that rapid increase of time delay in data synchronization within existing mimic storage architecture,which leads to the performance degradation during system security scheduling,this paper proposed a pre-synchronization model that enabled standby executors to utilize checkpoints in heterogeneous pools for data pre- synchronization,thereby reducing the time required for the executor to go online.Furthermore,according to the synchronization characteristics of the pre-synchronization model and the switching scheduling situation,this paper designed CMEC method.This method could determine the optimal checkpoint interval by maximizing the effective work rate of each execution cycle,balancing checkpoint overhead and rollback overhead.The experiments show that,compared with the existing full-volume synchronization strategy,this method shortens the synchronization time required for the executor to go online,improves the synchronization efficiency and ensures the stability and continuity of the system under increasingly heavy business loads.
Key words:mimic storage system;pre-synchronization model;checkpoint;service stability and continuity
0 引言
隨着云计算和大数据技术的高速发展与应用,计算、存储数据等资源愈发呈现共享化、集中化趋势,在促进服务能力更灵活高效的同时,也加剧了系统的功能安全与信息安全问题。特别是近年来众多隐私数据泄露与违法交易事件被频繁曝出,使得人们对于重要业务和数据迁移上云抱有极大迟疑,数据安全已经成为了制约新一代信息技术发展的核心问题。
在整个数据安全的研究中,数据存储系统的安全性与可靠性是一个重要方向。拟态存储系统,正是从应对数据存储系统中的漏洞和后门问题出发,基于内生安全拟态防御理论与方法对分布式存储架构进行重新设计和实现,期望为大数据和云计算场景提供更为安全可靠的数据存储服务支撑。
其核心设计思想是划定系统中核心元数据服务作为拟态防护边界,引入动态(dynamicity)、异构(heterogeneity)、冗余(redundancy)和裁决反馈的机制[1,2],改善原有分布式存储系统架构静态、相似、单一的基因缺陷,使拟态化分布式存储系统从结构上具备对漏洞和后门内生的抵御能力[3],以此保证分布式存储系统的数据安全。目前,拟态存储系统的安全性在理论和原型测试上均得到较好印证,但在异构执行体构建、拟态裁决调度的合理性、性能开销、鲁棒性等方面仍存在诸多需要研究的问题。
在拟态存储系统中,拟态调度是提供系统动态性的重要机制。当某个执行体受到攻击输出异常时,系统会调度其下线清洗恢复,同时从异构池中选取“纯净”的执行体上线继续执行元数据服务功能,以此往复保证系统功能和数据的安全鲁棒。这个环节中至关重要的一点,就是要保证新上线执行体的运行状态和数据能够与已在线执行体同步至相同状态,否则便无法保证系统一致性的基础前提。进一步地,随着拟态存储系统规模与业务量的增大,所需同步的系统元数据体量和时间开销均会增加,导致系统服务连续性急剧下降。因此,为支撑系统快速且正确地调度切换,就需要研究和设计高效的同步方法,从而保证拟态存储系统的可用性、稳定性。
针对上述问题,本文期望引入检查点机制,从而利用数据的预同步来达成数据高效同步的目标。尽管检查点机制在镜像管理、系统还原恢复等研究中均有涉及,但在拟态存储系统中,该应用仍然面临着一定的难点:a)如何针对拟态存储的多执行体场景,设计简单合理的预同步模型与交互流程;b)如何根据拟态存储的调度与数据同步特点,设置合理的检查点间隔。对此,本文将着重研究和解决上述难点问题,并通过实验测试来评估所提方法的正确性和有效性。
1 相关工作
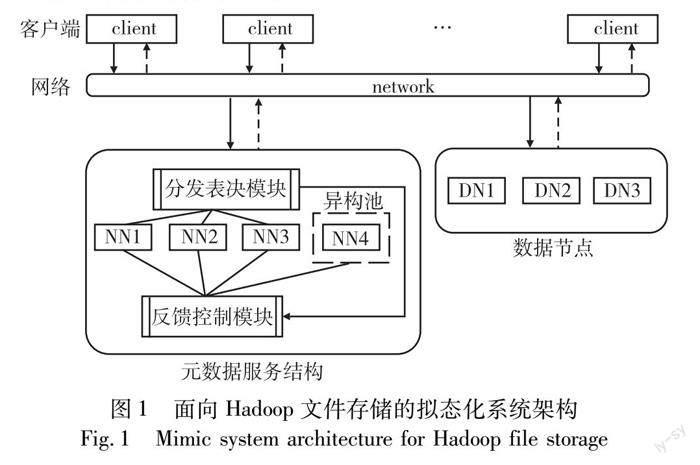
文献[4]给出了网络空间拟态防御的动态异构冗余基本模型,在此基础上文献[5]面向Hadoop文件存储系统设计了一种拟态化架构,如图1所示。
系统的元数据服务节点基于DHR模型重新进行了设计实现。在保留原有功能接口和对外交互方式不变的基础上,分发表决模块将输入的交互信息分发给多路在线的异构执行体,并且收集其返回的响应结果进行裁决输出。当裁决过程发现了不一致信息,就会将异常信息上报给反馈控制模块进行动态调度处理。经过对执行体的下线、清洗、同步、上线等一系列操作,在线执行体集合能够对当前攻击迭代收敛至相对安全的状态,以此保证整个系统的安全性和稳定性。
文献[5]提出了一种拟态存储架构并验证了其有效性,拟态防御技术也在Web、防火墙、SDN、数据库等[6~9]领域得到了广泛应用,但它们都未给出数据同步的具体方法。目前拟态应用中涉及到同步问题的研究主要有如下两种思路。一种思路是将各个执行体维护的主要数据存放在后端数据库中,凡是新上线的执行体都和其他在线执行体一样,与数据库交互从而保证数据状态一致。例如文献[10]提出利用异地的备份服务器资源池对数据库服务器执行体进行备份同步;文献[11]通过配置分布式数据库在每个控制器节点上实现多节点间的数据同步;文献[12]利用核心数据库分析来自不同执行体的数据并利用强一致性将数据整合成一个检查点,解决拟态网络操作系统在运行过程中的数据同步问题。但是,这种思路受限于原有应用场景的数据存储模型,针对拟态存储系统执行体处理逻辑和数据强绑定的情况则难以真正实施。另外一种思路是选择相对可靠的执行体作为同步数据源進行数据和状态同步。例如文献[13]提出基于执行体的历史信息和异构性的置信目标选择可靠执行体,从中获取元数据信息达到状态同步。这些方法通常在确定同步源后,将同步所需的数据文件和配置文件全量拷贝至待上线执行体,加载完毕后转入正常工作。那么整个过程中,待同步数据量大小就变得十分关键。对于一个拟态存储系统来说,数据量会随着环境扩容和业务积累而不断提升。当数据量较小时,同步过程耗时较短,系统的服务连续性尚可保持;随着数据量不断增加,同步耗时将会逐渐增大,系统的可用性也会大打折扣。受系统还原恢复和虚拟机镜像管理等应用技术机制的启发,本文期望借助检查点机制,并设置合理的检查点间隔来解决数据量持续增加下的数据同步效率问题。由于该思路尚未应用于拟态系统的研究,所以本文针对其他领域已有的检查点设置方法进行了梳理归纳。
检查点间隔设置方法主要分为两类。一类是检查点间隔随时间动态的变化,以减少频繁检查点带来的系统开销。文献[14]提出了一种迭代检查点算法来计算具有中等失败风险的作业的有效间隔,以最小化检查点的预期成本。Akber等人[15]建议在故障率较低的系统中连续增加检查点间隔来减少检查点的数量,从而减少检查点的开销。然而,上述为减少检查点开销而动态增大检查点间隔的方法更适用于一般运行稳定的系统,对于常需进行突发调度切换的拟态系统来说并不适合。另一类设置则根据具体应用场景,计算出一段时间内的最佳检查点间隔。文献[16]针对长期运行的软件,从能耗和执行时间的角度确定检查点的最佳数量,进一步导出最佳检查点间隔,以最小化总平均能耗或总平均执行时间。文献[17]针对运行在易故障平台上的软件应用程序,建立了一个数学模型,通过最小化应用程序的平均执行时间来估计最佳检查点间隔。文献[18]针对分布式流处理系统,计算在不同工作负载下的最优检查点间隔。这些研究聚焦于系统容错性能与检查点开销间的平衡,而针对拟态架构,检查点设置更需要关注如何根据调度切换和同步特性实现检查点开销和同步开销的折中考虑。
综上所述,现有的动态变化和特定应用场景下的检查点间隔都无法直接引入到拟态架构中应用,需要进一步根据拟态存储元数据执行体进行模型设计,进而依据同步的模型和特点确定合适的检查点间隔方法。
2 拟态预同步模型
在拟态存储系统中,为确保新上线执行体的运行状态和数据与已在线执行体一致,需进行元数据的同步。传统方法是新上线的执行体依据相应算法选择一路在线执行体,逐一获取元数据进行全量同步,但是这种方法效率较低。本章旨在原有拟态架构的基础上引入检查点机制,建立预同步模型以解决在拟态切换调度时执行体元数据同步的效率问题。架构设计如图2所示。
2.1 模型设计
与初始的拟态架构一致,模型中有客户端、分发表决器、反馈控制模块、NameNode(元数据执行体)及DataNode(数据节点)。在保证原有架构基本不变的前提下,为充分利用架构中各节点的功能和特性,针对待上线节点同步数据的需求,将其设计为合并节点的角色。该节点具有双重身份:一是作为检查点机制中的合并节点,主要用于提前进行元数据的同步;其次,从拟态系统的角度来看,它亦为异构池中可供调度切换上线的备用执行体。同步中最关键的问题即为数据的正确性和可靠性,数据源的安全性直接关系到合并节点所同步数据的可信度,因而让反馈控制模块在承担执行体切换工作的同时,负责在线执行体集合中可信同步源的选取工作。
预同步模型在工作时,客户端的请求经分发表决模块分发至三个在线执行体,若请求为创建、修改、删除等写操作则记录至元数据执行体的操作日志文件中。反馈控制模块选择一路可信执行体作为同步源,即图2中的主节点。异构池中的合并节点定期从主节点中获取元数据镜像文件和操作日志,将它们合并为新的镜像文件后传回主节点。这种周期性地获取镜像文件和日志文件来合并的操作称之为检查点。
当预同步模型进行执行体调度切换时,需要将合并节点上线。由于该节点的磁盘中已保存了一份与主节点相同的镜像文件,只需将镜像文件加载至内存中,再使用从反馈控制模块处获得的主节点操作日志来恢复已在线执行体的最新状态。这种方法极大地缩短了拟态切换中元数据同步和状态恢复所需的时间,从而实现了备用执行体的快速上线。
完成执行体的上线工作后,需选取合适的节点作为新的同步源。预同步模型可支持主节点的动态切换,任何在线执行体均可成为新的主节点。如图3所示,反馈控制模块根据相应算法选择在线执行体集合(图为nn2,nn3和nn4)中的一路作为新的主节点或同步源,合并节点即为异构池中的新备用执行体。在提升同步效率的同时,保证了系统的灵活性和可靠性。
2.2 流程设计
为了实现流畅的执行体切换,帮助预同步模型更好地融合进原有拟态架构中,针对多执行体场景,设计了以下的交互流程。
图4主要描述了预同步模型中,从系统发出切换调度命令开始到切换工作完成的整个过程。当拟态存储系统需要下线执行体时,需从异构池中选取一个新的执行体上线,并使之与其他在线执行体达到一致的状态,以保证拟态架构的正常运转。在此过程中,步骤a)反馈控制模块向待下线执行体发送下线指令,并向异构池中待上线的执行体发送上线指令,以准备进行节点切换。在发送切换命令后,步骤b)中反馈控制模块依据相应的算法选择一路执行体作为新的同步源。
在选择同步源之后,通过步骤c)在选定的新主节点上执行切换脚本。该脚本将修改即将成为主备执行体和普通执行体的配置文件,为后续切换做好配置准备工作。为确保所有在线执行体的元数据状态保持一致,步骤d)中反馈控制模块将向在线执行体发送进入安全模式的命令,给予待上线的执行体获取余下操作日志的时机。随后,步骤e)f)发送剩余操作日志,确保待上线执行体已完全同步操作日志。
待上线执行体完成对原主节点日志的同步后,将其元数据目录更改为在线工作目录,完成其余准备工作后启动上线。同时,下线的执行体需将元数据目录更改为合并节点的工作目录,并重新启动为新主节点对应的合并节点。
该流程实际将预同步模型纳入拟态架构中,能够高效自动化地完成任意节点的切换,同时满足随机选取主节点的要求,提升了预同步模型下系统的安全性和稳定性。
2.3 检查点设置
在确定了预同步模型后,另一个关键问题则是检查点该如何设置。检查点间隔即合并节点获取镜像文件和操作日志进行合并的时间间隔。若间隔过短,频繁地检查点操作会增加系统开销,而间隔过长则会增加回滚恢复的开销。为在拟态预同步模型中权衡加载日志的开销和检查点开销,根据系统的切换和同步特点建立执行周期模型,采用了一种执行周期最大有效率的检查点放置(execution cycle maximum efficiency checkpointing,CMEC)方法来确定适当的检查点序列,使得每个执行周期中真正有效的执行时间占比率达到最大,从而动态地确定各个周期的最佳检查点间隔。
系统在正常运行、检查点操作以及启动前日志的回滚恢复三个阶段交替执行。日志的回滚恢复常发生于拟态系统的调度切换中,为方便统计和计算相关开销数据,将两个连续切换事件之间的时间段称为执行周期。如图5所示,在时间t内,执行周期从时间t0的切换事件Sm开始,经过重放日志恢复过程R,正常运行和检查点操作,到下一个切换事件Sm+1结束。在执行周期中,设每个检查点操作均产生时间开销C,检查点序列{C1,C2,C3,…,Cn-1}已经成功地放置在时间{t1,t2,t3,…,tn-1}(n=1,2,3,…)。执行周期t被内部检查点序列划分为多个间隔{I1,I2,…,In}[19]。
为寻找最佳的检查点间隔,进行如下假设:
a)拟态存储系统执行体切换时间遵循泊松分布,故障发生率为λ,故障即为拟态存储系统中的切换事件;
b)采用顺序的检查点时,检查点延迟对最佳的等距检查点间隔的影响可以忽略不计,因此在该模型中不考虑检查点延迟;
c)在一次执行周期间,执行体始终处于运行状态,无法改变其检查点间隔。因此,假设在一次执行周期中检查点开销恒定,力求得到一次执行周期中最佳的等距检查点间隔。
将执行周期中用于處理用户请求的真正有效工作时间段称之为工作段,检查点开销C和恢复R称之为附加段。在图5中,tn-1后的X段也为附加段,因为在Sm+1处发生了切换,切换后系统需回滚至In-1段的检查点。设工作段在一个执行周期内的持续时间总和为W,附加段的持续时间总和为A,则该执行周期的总持续时间为W+A。据更新奖赏过程定理[20],该执行周期的有效工作率为
H=Σ(W)Σ(A+W)=E(W)E(A+W)(1)
设系统在长为t的时间间隔内发生切换的次数N(t)服从参数为λt的泊松分布λt(N(t)~λt),λ为切换发生率。两次连续切换间的时间间隔T的概率分布函数为F(t)=1-e-λt,平均切换时间为1/λ,等于A+W的期望值,故H=Σ(W)/Σ(A+W)=λE(W)。下面将以图6为框架计算一个执行周期的有效率,设每个间隔Ii中真正工作时间为T,则检查点间隔为T+C,从t0~tn-1的有效工作时间为tn-1-t0-R-(n-1)C。
设P(Ii)是切换事件Si在Ii段发生的概率,故
E(W)=P(I1)×0+∑∞i=2P(Ii)×(ti-1-t0-(i-1)C-R)(2)
P(Ii)=F(ti)-F(ti-1)(3)
由式(2)和(3)得有效利用率H(T)为
H(T)=λE(W)=λ∑∞i=2P(Ii)×(ti-1-t0-(i-1)C-R)=
λ∑∞i=1P(Ii+1)×(ti-t0-iC-R)=
λ∑∞i=1[(1-e-λ(i+1)(T+C))-(1-e-λi(T+C))](iT-R)=
λ∑∞i=1(e-λi(T+C)-e-λ(i+1)(T+C))(iT-R)=
λ(1-e-λ(T+C))∑∞i=1(e-λi(T+C))(iT-R)=
λ(1-e-λ(T+C))(T∑∞i=1ie-λi(T+C)-R∑∞i=1e-λi(T+C))=
λ(1-e-λ(T+C))[Te-λ(T+C)(1-e-λ(T+C))2-Re-λ(T+C)1-e-λ(T+C)]=
λ[Te-λ(T+C)1-e-λ(T+C)-Re-λ(T+C)]
由此可知,只需对有效利用率H(T)求极值,找到H(T)T=0时的Topt,Topt+C即为最佳的检查点间隔。与Te-λ(T+C)1-e-λ(T+C)相比,Re-λ(T+C)的值微乎其微,因此H(T)≈ λTe-λ(T+C)1-e-λ(T+C)。在实验中,假设平均切换时间为2 h,则λ=1.389 9×10-4,实验时检查点开销C平均为2 s。代入λ和C的值绘制Η(T)≈ λTe-λ(T+C)1-e-λ(T+C)的函数图像,得到H(T)取最大值时的Topt值。
图7为当C=2 s且λ=1.389×10-4时的部分函数图像,其横坐标为T,纵坐标为有效利用率H。
由图7可知,当0
3 实验与测试
本实验依托于现有HDFS,在四台Vmware虚拟机环境中搭建了Haoop3.7.1集群,其中包含主机名为master、slave1、slave2、slave3,对应实验中的nn1、nn2、nn3、nn4四个节点。通过修改对应的配置文件和编写切换脚本,简要模拟了拟态存储系统的同步和切换过程。针对预同步模型的效率提升、同步的准确性和性能损失方面,设计了三个部分实验:首先比较引入预同步机制前后的同步数据量大小和同步时间差异;其次对新上线执行体的元数据与其余执行体进行了一致性对比;最后测量了引入预同步机制前后的读写吞吐速率。
3.1 时间开销
为评估预同步机制在元数据同步方面的效率,将执行体上线前所需同步的数据量大小和同步时间作为关键的评价指标。实验将预同步机制下的同步上线开销与现有同步方案进行了比较。现有的拟态存储系统采用全量同步策略,即执行体上线前,将同步源的所有元数据文件逐一发送至待上线节点。
在全量同步和预同步两种策略下,同步时间通常包括元数据文件传输和重放日志以恢复状态的时间。在此实验中,仅计算元数据文件的传输时间,不考虑重放日志的时间,且预同步机制能够定期合并日志,其需重放的日志数量也显然少于全量同步。因此,实验使用TestDFSIO工具分别测试在HDFS中写入30、50、100、200、400个10 M文件时所需传输的元数据文件(镜像文件和操作日志)的大小。在原有的拟态架构中,当节点新上线时,其内部数据为空,需完全同步镜像和日志文件。相比之下,引入预同步机制后,因备用执行体在异构池时已由检查点提前同步了主节点的镜像文件,只需再同步日志文件即可。由图8可知,随着系统处理的数据量和业务量不断增加,执行体镜像文件所存储的数据规模也逐渐扩大。由此导致全量同步的数据量逐渐增加,而预同步却能保持相对稳定。
当网络带宽为2 Mbps时,绘出其传输所需时间曲线,如图9所示。在2 Mbps的网络带宽下,当写入文件数为30时,预同步的开销减小并不明显,同步时间仅缩短了2 ms;而当写入文件数增加到400时,预同步比全量同步方案的时间开销减小了18 ms。随着网络带宽的增加,数据同步的开销相应减少,预同步和全量同步方案间的差距亦随之变小。当网络带宽增加到20 Mbps,写入文件数为400时,两种方案的同步时间差缩短为1.8 ms。这表明拟态预同步机制在网络质量较差且处理文件数较多的情况下表现出更加明显的优势,而在网络质量好或处理文件较少也始终优于原拟态的全量同步方案。无论系统的规模和业务量如何增长,擬态预同步机制始终能够保持稳定和较高的同步效率,保证系统流畅的调度切换以支撑服务的连续性。
3.2 元数据一致性
实验前各执行体的元数据为空,无任何文件,故可通过对比新上线执行体与已在线执行体的文件一致性,以检验预同步的正确性。为此,选取图3的切换情况进行验证,在实际的拟态调度环境中,切换工作不会在所有日志均由检查点操作合并后再进行,故本实验分两种情况来验证预同步的准确性:a)验证合并节点nn4上线前已完全同步主节点的操作日志并生成镜像文件的情况;b)验证nn4上线前并未完全同步主节点所有操作日志的情况。
首先验证情况a),将a.txt文件上传至拟态HDFS的根目录下,待nn4经检查点合并完操作日志生成新的镜像文件后,进行调度切换工作。模拟反馈控制模块对nn1和nn4进行下线和上线指令后,在其选定的主节点nn3上启用切换脚本sync.sh。图10为切换过程中的配置同步信息,切换完成后验证新上线的nn4节点,发现其状态已由备用执行体转为Active执行体,在根目录文件中显示已将a.txt文件同步过来。
随后验证情况b),上传a.txt文件至拟态HDFS的根目录下,待上传a.txt文件的操作日志被同步完成后上传b.txt文件,不等合并节点nn4从主节点nn3获取上传b.txt的日志,反馈控制模块发出切换命令,如图11所示。
此时nn3的镜像文件fsimage13中包含了a.txt的元数据信息并经检查点同步给了备用执行体nn4,而文件b.txt上传后还未进行检查点操作就发生了切换动作,因此该文件的上传日志并未写入检查点fsimage13中,而位于edits_inprogress14文件中。nn3的元数据目录如图12所示。
在进行切换工作后观察新上线的nn4中是否存在b.txt文件。发现在nn4上线后,可以访问a.txt和b.txt,观察其元数据目录发现它已成功同步了未在检查点fsimage13文件的上传b.txt文件的操作日志。nn4的根目录文件和nn4的元数据目录如图13、14所示。之所以能将检查点后的操作记录同步至待上线执行体,是因为nn4节点在切换脚本中同步了编辑日志文件edits_inprogress14,所以可以恢复上传b.txt文件至拟态HDFS的元数据信息,从而保证了在未完全同步日志下执行体切换前后元数据的一致性。实验表明,在两种同步日志的情况下,预同步模型均能保证拟态调度切换工作的可靠性。
3.3 性能损失
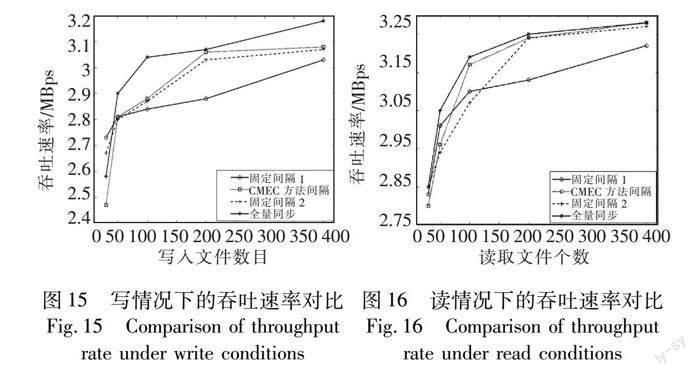
由于拟态预同步模型的检查点机制有一定的性能损耗,为评估拟态预同步模型的性能,并分析前文所述CMEC方法所得间隔的优劣,使用基准测试程序TestDFSIO对比了拟态存储系统在不同同步策略和同步间隔下读写操作的吞吐速率。具体比较了拟态系统现有的全量同步策略、预同步策略下的CMEC方法间隔170 s、小于CMEC间隔的固定间隔1(120 s)以及大于CMEC间隔的固定间隔2(220 s)这四种设置的性能差异。使用TestDFSIO工具分别测试上述四种方案在HDFS中读写30、50、100、200、400个10 M文件时的吞吐速率。
根据图15和16的读写吞吐速率对比可知,随着读写数据量的增加,各方案的吞吐速率均呈现出先快后慢的增长趋势,全量同步策略在读写操作下的性能始终优于预同步策略。在预同步策略中,CMEC间隔在元数据读写操作下的性能表现最佳,仅次于全量同步方案。尽管在写操作时与全量同步相比吞吐速率略有下降,特别在写入文件数为100时,下降约5%。而在读操作时,随读取数据量的增加,CMEC间隔的性能表现逐渐与全量同步相当。固定间隔为120 s的方案表现最差,因其小于CMEC间隔,频繁的合并操作引入了更多的系统开销,当写入文件数为200时,CMEC间隔相对其提升了约6%的吞吐速率。固定间隔为220 s的方案表现略差于CMEC间隔,即便其检查点数量更少。由于间隔过长,每个检查点操作所需合并的日志数据开销也随之增加,这导致该间隔下系统的读写性能略低于最佳间隔。
在拟态架构中引入预同步机制虽对性能有一定影响,但若按本文所提的CMEC方法设置预同步模型中的检查点间隔,可以将损失降至最低。这表明预同步机制引入的性能损失是可承受的,且随处理数据量的增加,损失率逐渐降低,这与本文预同步模型的初衷和适用场景不谋而合。
3.4 应用与局限性分析
由于分布式存储大多基于云计算和大数据的环境搭建,其数据体量本身较为庞大,同时需不断地扩容以应对增长的业务需求。在实际应用中如何保证调度切换时系统始终能高效地同步数据,而不因数据量的增加降低同步效率至关重要。本文方法可适用于拟态存储系统,解决随着集群规模不断增扩大而导致的业务量和数据量快速增长的问题。另外,本文方法还可在其他类似的拟态架构中使用。同时,本文方法亦能作为数据同步的一种参考方案,如云计算平台、大规模数据中心等场景。希望研究结果能为拟态场景下的高效数据同步方法提供有益的参考和借鉴。
然而,本文方法在預同步机制的数据一致性验证上仍存在着一定的局限性,其中网络中的数据延迟和数据质量问题可能会导致数据的不完整和同步的失败。为了提高预同步模型的同步准确率,需要结合实际拟态环境的数据一致性验证进一步地研究和改进。
4 结束语
为了应对拟态系统在数据量和业务量持续增加的情况下,调度切换时元数据同步效率低下的问题,本文提出了一种新颖的解决思路。通过在原有拟态架构中引入检查点机制来建立预同步模型,利用合并节点实现对元数据文件的预先同步进而提升同步效率。在新上线的执行体加载已同步的镜像文件后,只需花费少量时间重放日志即可投入运行,保证了系统的稳定性和服务的连续性。此外,根据模型的同步特性和调度切换情况,在建立执行周期模型的基础上提出了CMEC方法,通过最大化每个周期中的有效工作率推导出最优检查点间隔,较好地平衡了检查点开销和回滚开销。实验结果表明,本文方法可提高拟态系统中的元数据同步效率,同时利用CMEC方法最小化对预同步机制对系统性能的影响,具有良好的可靠性和实用性。后续将进一步优化CMEC方法间隔的设置,记录每个执行周期的检查点开销,以实现动态调整检查点间隔。
参考文献:
[1]Yu Haiyang,Li Hui,Yang Xin,et al.On distributed object storage architecture based on mimic defense[J].China Communications,2021,18(8):109-120.
[2]Lin Zhili,Li Kedan,Hou Hanxu,et al.MDFS:a mimic defense theory based architecture for distributed file system[C]//Proc of IEEE International Conference on Big Data.Piscataway,NJ:IEEE Press,2017:2670-2675.
[3]Song Ke,Wei Shuai,Zhang Wenjian,et al.An equivalent scheduling strategy for cyberspace mimicry defense based on security priority[C]//Proc of International Conference on Advanced Mechatronic Systems.Piscataway,NJ:IEEE Press,2018:52-57.
[4]鄔江兴.网络空间拟态防御研究[J].信息安全学报,2016,1(4):1-10.(Wu Jiangxing.Research on mimic defense in cyberspace[J].Journal of Information Security,2016,1(4):1-10.)
[5]郭威,谢光伟,张帆,等.一种分布式存储系统拟态化架构设计与实现[J].计算机工程,2020,46(6):12-19.(Guo Wei,Xie Guangwei,Zhang Fan,et al.Design and implementation of a mimic architecture for distributed storage system[J].Computer Engineering,2020,46(6):12-19.)
[6]刘昕林,黄建华,罗伟峰,等.动态异构冗余架构下Web实践及安全性分析[J].计算机应用,2021,41(S1):125-130.(Liu Xinlin,Huang Jianhua,Luo Weifeng,et al.Web practice and security analysis under dynamic heterogeneous redundant architecture[J].Journal of Computer Applications,2021,41(S1):125-130.)
[7]刘文贺,贾洪勇,潘云飞.基于执行体防御能力的拟态防火墙执行体调度算法[J].计算机科学,2022,49(S2):690-695.(Liu Wenhe,Jia Hongyong,Pan Yunfei.Mimic firewall executor scheduling algorithm based on executor defense ability[J].Computer Science,2022,49(S2):690-695.)
[8]顾泽宇,张兴明,林森杰.基于拟态防御理论的SDN控制层安全机制研究[J].计算机应用研究,2018,35(7):2148-2152.(Gu Zeyu,Zhang Xingming,Lin Senjie.Research on security mechanism for SDN control layer based on mimic defense theory[J].Application Research of Computers,2018,35(7):2148-2152.)
[9]万仕贤,赵瑜,吴承荣.拟态数据库的网络攻击抵御能力评估和实证[J].计算机应用与软件,2022,39(1):319-327.(Wan Shi-xian,Zhao Yu,Wu Chengrong.Evaluation and demonstration of network attack resistance of mimetic database[J].Computer Applications and Software,2022,39(1):319-327.)
[10]樊永文,朱维军,班绍桓,等.动态异构冗余数据保护安全架构[J].小型微型计算机系统,2019,40(9):1956-1961.(Fan Yongwen,Zhu Weijun,Ban Shaohuan,et al.Dynamic heterogeneous and redundancy data protection architecture[J].Journal of Chinese Computer Systems,2019,40(9):1956-1961.)
[11]李军飞,兰巨龙,胡宇翔,等.SDN多控制器一致性的量化研究[J].通信学报,2016,37(6):86-93.(Li Junfei,Lan Julong,Hu Yuxiang,et al.Quantitative approach of multi-controllers consensus in SDN[J].Journal on Communications,2016,37(6):86-93.)
[12]Qi Chao,Wu Jiangxing,Hu Hongchao,et al.Dynamic-scheduling mechanism of controllers based on security policy in software-defined network[J].Electronics Letters,2016,52(23):1918-1920.
[13]杨珂,张帆,郭威.一种基于执行体的历史信息和异构性的置信目标快速构建算法[J].信息工程大学学报,2021,22(6):694-698.(Yang Ke,Zhang Fan,Guo Wei.Fast construction algorithm for confidence targets based on historic information and heterogeneity of executive bodies[J].Journal of Information Engineering University,2021,22(6):694-698.)
[14]Frank A,Baumgartner M,Salkhordeh R,et al.Improving checkpoin-ting intervals by considering individual job failure probabilities[C]//Proc of IEEE International Parallel and Distributed Processing Symposium.Piscataway,NJ:IEEE Press,2021:299-309.
[15]Akber S M A,Chen Hanhua,Wang Yonghui,et al.Minimizing overheads of checkpoints in distributed stream processing systems[C]//Proc of the 7th International Conference on Cloud Networking.Pisca-taway,NJ:IEEE Press,2018:1-4.
[16]Gelenbe E,Siavvas M.Minimizing energy and computation in long-running software[J].Applied Sciences,2021,11(3):1169.
[17]Siavvas M,Gelenbe E.Optimum interval for application-level checkpoints[C]//Proc of the 6th IEEE International Conference on Cyber Security and Cloud Computing.Piscataway,NJ:IEEE Press,2019:145-150.
[18]Zhang Zhan,Li Wenhao,Qing Xiao,et al.Research on optimal checkpointing-interval for flink stream processing applications[J].Mobile Network and Applications,2021,26(5):1950-1959.
[19]Zhai Yongning,Li Weiwei.The optimal checkpoint interval for the long-running application[J].International Journal of Advanced Pervasive and Ubiquitous Computing,2017,9(2):45-54.
[20]Yao Kai,Zhou Jian.Renewal reward process with uncertain interar-rival times and random rewards[J].IEEE Trans on Fuzzy Systems,2018,26(3):1757-1762.
收稿日期:2023-02-22;修回日期:2023-04-11 基金項目:国家重点研发计划专项资助项目(2022YFB3104300)
作者简介:李婉桃(1999-),女,湖南郴州人,硕士,主要研究方向为拟态安全;张帆(1981-),男(通信作者),河南郑州人,副研究员,博士,主要研究方向为主动防御、人工智能等(zhangfan@pmlabs.com.cn);陈鑫(1989-),男,江苏泗阳人,硕士,主要研究方向为主动防御、拟态分布式文件存储系统;朱进(1989-),男,江苏泰州人,硕士,主要研究方向为主动防御、拟态分布式文件存储系统;黄潇(1991-),男,江苏徐州人,硕士,主要研究方向为主动防御、拟态分布式文件存储系统.
