并行计算框架Spark的自动检查点策略
2017-04-12英昌甜钱育蓉
英昌甜 于 炯, 卞 琛 鲁 亮 钱育蓉
(1新疆大学信息科学与工程学院, 乌鲁木齐 830046)(2新疆大学软件学院, 乌鲁木齐 830008)
并行计算框架Spark的自动检查点策略
英昌甜1于 炯1,2卞 琛1鲁 亮1钱育蓉2
(1新疆大学信息科学与工程学院, 乌鲁木齐 830046)(2新疆大学软件学院, 乌鲁木齐 830008)
针对现有的Spark检查点机制需要编程人员根据经验选择检查点,具有一定的风险和随机性,可能导致恢复开销较大的问题,通过对RDD属性的分析,提出了自动检查点策略,包括权重生成 (WG)算法和检查点自动选择(CAS)算法.首先,WG算法分析作业的DAG结构,获取RDD的血统长度和操作复杂度等属性,计算RDD权重;然后,CAS算法选择权重大的RDD作为检查点进行异步备份,来实现数据的快速恢复.结果表明:在使用CAS算法时,不同数据集执行时间和检查点容量大小都有所增加,其中Wiki-Talk由于其计算量较大,增幅明显;使用CAS算法设置检查点后,在单点失效恢复的情况下,数据集的恢复时间较短.因此,自动检查点策略在略微增加执行时间开销的基础上,能够有效地降低作业的恢复开销.
自动检查点;RDD权重; Spark; 恢复时间
近年来,随着数据量的爆炸式增长,对大数据[1-2]的处理和分析已经成为企业界和学术界的迫切需求,利用内存的低延迟特性来提升系统性能成为了研究的热点.Spark[3-4]以其低延时的出色表现,利用Scala强有力的函数式编程、Actor通信模式、闭包、容器、泛型,借助统一资源分配调度框架Mesos,融合了MapReduce和Dryad,正在成为最具影响的基于内存的并行计算框架之一.
现有的多种计算框架的容错和检查点[5-7]策略各有不同,例如Storm和Apache S4[8]都由Zookeeper为其提供容错,但Storm不设置检查点,Apache S4提供设置异步检查点的机制.而基于内存的分布式文件系统RAMCloud[9]和Tachyon[10]则分别利用集群并发能力和高速带宽的Infiniband,以及使用Edge算法对有向无环图(directed acyclic graph, DAG)叶子节点所对应的文件进行信息备份,来实现容错的目的.
与已有研究不同的是,Spark通过数据集血统(lineage)和检查点(checkpoint)机制实现容错,由编程人员负责选择检查点并进行设置.由于编程人员往往根据经验选择检查点,如果检查点选择不当,不仅降低应用程序的恢复效率,还可能增加程序异常的风险.为此,本文通过分析Spark作业执行机制,定义了作业和弹性分布式数据集(resilient distribution datasets,RDD)的执行时间和恢复时间,并在此基础上,根据RDD的不同属性,提出自动检查点策略(包括权重生成算法和自动检查点算法),从而应对突发性的宕机风险,提高作业恢复效率.
1 模型与相关定义
1.1 作业执行模型
定义1 集群节点.设Spark并行计算集群由集合N={n1,n2,…,nm}组成,其中nm表示第m个节点.节点nm上的资源可由三元组〈fm,gm,hm〉表示,分别表示内存大小、磁盘读写速率和网络速率.
定义2 节点状态.设S表示集群所有的节点状态,U={u1,u2,…,um},ui∈{a,ua}表示节点nm当前所处的状态,其中a, ua分别表示可用和不可用,系统故障、电源中断、硬件故障等原因都有可能造成节点处于ua状态.
定义3 资源分配.记J={1,2,…,n}为Spark框架一个时间段内同时运行的作业,对于作业i,记Ai={Ai1,Ai2,…,Ail}为在群集中的资源分配量.由于Spark保证所有作业的并发执行,当且仅当每个工作节点的资源都不会溢出,即
(1)
定义4 作业执行时间.Spark根据宽依赖作为分界,将作业划分为多个阶段(stage)执行.若作业划分为u个阶段,每个阶段的计算时间定义为Tst,i,则作业的执行时间Tjob为
(2)
若第i个阶段包含v个RDD,记TR,ij为其第j个RDD的计算时间,那么该阶段的执行时间应为该阶段所有RDD计算时间的总和,即
(3)
因此,作业执行时间Tjob则为
(4)
定义5 RDD执行时间.记TP,ijk表示第i个阶段中第j个RDD的第k个分区的计算时间,则该RDD计算时间为所有分区计算时间的最大值,即
TR,ij=max(TP,ij1,TP,ij2,…,TP,ijk)
(5)
分区的执行时间TP,ijk为读取父分区数据的时间dPa,ijk与父分区处理时间cPa,ijk之和,即
TP,ijk=dPa,ijk+cPa,ijk
(6)
若所有父分区都存储在同一节点内存中,则数据读取代价可以忽略,即
dPa,ijk=0
若父分区存储在节点nm的内存中,则数据读取的代价与其数据容量Sijk大小成正比,网络带宽速率成反比,即
(7)
若父分区存储在节点nm磁盘中,则为
(8)
1.2 作业恢复模型
定义6 作业恢复时间.在作业执行过程中,若单个或多个节点产生故障,即节点处于ua状态,则作业恢复时间为恢复节点上所丢失RDD需要的时间.若故障次数为0,则没有作业恢复开销.若故障次数为k,则为k次故障时,恢复RDD所用时间eR,ij.设找到空闲节点,并分配恢复工作所需的调度开销定义为α,则作业的恢复开销ejob为
(9)
定义7 RDD恢复时间.设检查点集合为O={o1,o2,…,op},其中op为作业的第k个RDD,也是设置的最新检查点.当前执行到第i个阶段第j个RDD时,节点故障宕机导致RDD丢失,此时所需的恢复时间为
eR,ij=α+TR,i(k+1)+TR,i(k+2)+…+TR,ij=
(10)
若未设置检查点时,则重新计算所有RDD,即
(11)
而丢失分区的恢复需要通过父分区进行恢复,最终需要检查点进行恢复.因此,恢复第j个分区的时间为
eP,ijk=α+dPa,ijk+cPa,ijk
(12)
由此可知,检查点的选择和恢复检查点所用的时间都是影响作业恢复效率的重要因素.在宕机时, 作业用于恢复的开销越小,对作业执行效率的影响就越小.因此,自动检查点策略则在系统资源满足作业需求的情况下,以最小化作业恢复开销为目的.
定义8 RDD权重.通过分析,与恢复开销相关的主要因素有血统长度LR,ij、操作类型OR,ij、计算时间TR,ij和容量大小SR,ij.因此,将RDD的权重表示如下:
(13)
式(13)表明,血统长度对权重起决定性作用,血统越长,表示恢复时的计算路径越长,作为检查点备份的必要性就越大.而RDD类型、计算时间和RDD容量对权重起辅助作用,因为这3个因素对恢复开销的影响有限.
2 自动检查点策略
自动检查点策略根据作业的血统图,分析RDD属性,利用权重生成算法计算RDD的权重.在作业执行时,后台执行检查点设置算法,根据当前的执行状态,选择权重最大的RDD作为检查点备份到磁盘.在节点失效时,Spark系统的恢复机制利用已设置的检查点进行快速恢复.
2.1 权重生成算法
权重生成(weight generated, WG)算法在执行作业前,遍历作业的DAG图,生成RDD结构树,获得每个RDD的操作和属性,并根据式(13)计算权重,具体过程如算法1所示.
算法1 权重生成算法
输入:结构树RDDtree; RDD计算时间T;
fori=0 to RDDtree.Length-1 do
RDD[i].L←GetDepth(RDDtree[i])
//获得血统长度
if (RDDtree[i].operation==WideDependency)
then
RDD[i].O←RDDtree[i].partition(num)
Widedependencylist.add(treeRDDs[i]);
else if (RDDtree[i].operation==NarrowDep endency)
RDD[i].O←1
//生成操作复杂度
end if
Weightlist.add(RDD[i]);
Weightlist [i]←calcWeight(RDD[i]);
//计算权重
end for
2.2 检查点自动选择算法
检查点自动选择算法(checkpoint automatic selection, CAS)的步骤为:① 作业开始执行时,设置检查点列表为空;② 添加生成的第1个RDD作为检查点,并添加到检查点列表;③ 获取当前最新生成的RDD列表;④ 通过Spark 用户接口(user interface, UI)获取已生成RDD的开始时间和结束时间,则结束时间与开始时间之差为RDD的计算代价;⑤ 获取已生成RDD所属多个分区的容量大小,求和计算得到RDD容量大小;⑥ 通过调用算法1,计算 RDD的权重;⑦ 比较已生成列表中的RDD,并将权重最大的RDD自动设置为检查点,添加到检查点序列;⑧ 等待检查点写入HDFS成功后,对结构树RDDtree剪枝, 切断已设置检查点前的血统;⑨ 若作业结束, 则跳出循环,否则跳转到步骤③.
算法2 检查点自动选择算法
输入:结构树RDDtree;
checkpointList←null;
maxWeight←0;
visit(RDDTree);
RDDtree.length←getlength(RDDtree);
fori=0 to RDDtree.length-1
newRDD [i]←generatenewRDD;
while(newRDD[1]!=null&&checkpointList==null)
checkpoint(newRDD[0]);
checkpointList←addToList(newRDD[0]);
end while
//设置生成的第1个RDD为检查点
if(newRDD!=null)
newRDD.length←getLength(newRDD)
end if
forj=0 to newRDD.length-1 do
newRDD[j].T←newRDD[j].finishTime-newRDD[j].startTime;
fork=0 to RDD[j].partition.num-1
RDD[j].S←sum(partition[j][k].size);
end for
//获取RDD的计算时间和容量大小
call algorithm1;//计算RDD的权重
if(RDD[j].wt>maxwt)
then maxwt←RDD[j].wt;
maxwtRDD←RDD[j];
//选择权重最大的RDD
end if
end for
checkpoint(maxwtRDD);
writeToHDFS(maxwtRDD);
checkpointList←addToList(maxwtRDD);
cutlineage(RDDTree, maxwtRDD);
end for
3 实验验证与分析
3.1 实验环境设置
实验环境用1台服务器和8个工作节点建立计算群集,服务器作为Spark和Hadoop的主节点,工作节点配置如表1所示.
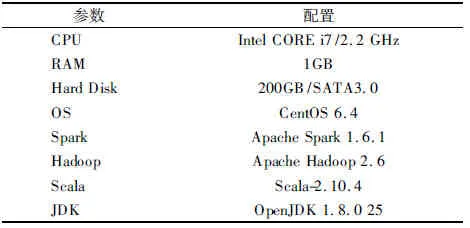
表1 工作节点配置参数
3.2 实验分析
实验采用PageRank算法进行系统性能测试,使用nmon监控任务执行时间和检查点大小.实验数据选用斯坦福网络分析平台(stanford network analysis platform, SNAP)提供的有向图数据集.不同数据集在PageRank任务下检查点自动选择算法的执行效率、检查点大小和检查点存储处理平均时间如图1~3所示.
如图1所示,4个不同的数据集(Web-Standard,Amazon0312,Wiki-Talk,Web-Google)在使用CAS时对PageRank作业都有额外影响,导致作业的执行时间比原Spark略微增加.由于使用CAS时,需要获取RDD属性信息和作业执行状态信息,基于权重值选择检查点备份会产生额外开销.另外, 在相同迭代次数不同数据集之间对比,Wiki-Talk的执行时间最长,而Web-Standard的执行时间最短.数据集的节点数和连线数越大,则需要计算的数据量越大,执行时间越长.由图2可知,在相同数据集时,由于迭代次数的增加,设置作为检查点的RDD数量增加,检查点的总容量也随之增

图1 检查点自动选择算法的执行时间
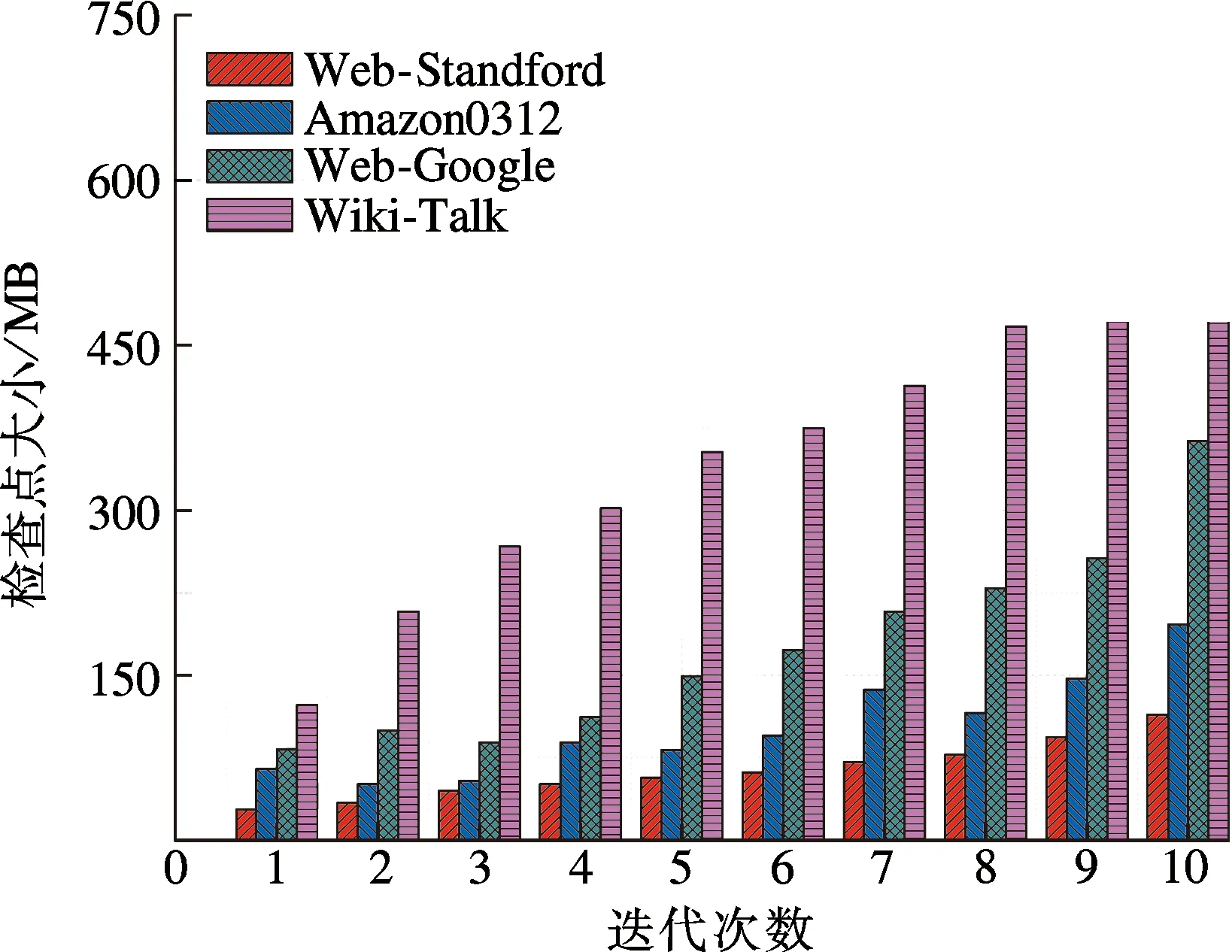
图2 检查点自动选择算法的检查点大小

图3 检查点自动选择算法的检查点平均时间开销
加.同时,Wiki-Talk相同迭代次数下,检查点大小明显高于其他3个数据集,Wiki-Talk的计算数据量较大,因此作为检查点的RDD容量也较大.
由图3可看出,不同数据集之间,当数据集计算量较大,检查点个数增加时,对应检查点存储设置的平均时间开销也随之增加,并且随着迭代次数的增加, 对检查点平均时间开销的影响也减少.
如图4所示,4个数据集在节点单次失效的情况下,PageRank算法在设置与未设置检查点时执行时间和恢复情况对比.随着迭代次数的增加,设置检查点的执行效率明显优于未设置检查点的情况,因为未设置检查点时仅通过RDD血统从头计算来实现恢复,在宕机时迭代次数越大,则恢复所需的时间就越长.
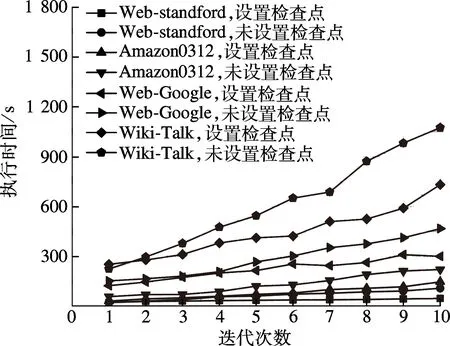
图4 设置检查点与未设置检查点的恢复效率对比
结合图1~4可知,当Spark采用检查点自动选择算法执行PageRank时,其执行时间要略高于传统Spark任务.然而,在出现单点故障需要恢复时, 4个数据集使用自动设置检查点算法时,恢复效率较高,比未设置检查点算法所用的恢复时间短.
4 结语
为了避免Spark框架下人工设置检查点可能出现的不确定性和风险,定义了Spark框架下RDD和作业的计算代价、恢复代价,通过分析RDD属性,确定了与恢复开销相关的RDD权重.在此基础上设计了权重生成算法和检查点自动选择算法,使系统在作业执行时自动识别有价值的RDD作为检查点,进行持久化存储,并在系统宕机时利用检查点执行恢复.最后通过不同数据集的实验,验证了自动检查点策略的有效性.下一步的研究方向是分析在多点多次故障时,不同的检查点恢复策略对于作业恢复效率的影响.
References)
[1]孟小峰, 慈祥. 大数据管理:概念、技术与挑战[J]. 计算机研究与发展, 2013, 50(1):146-169.DOI:10.7544/issn1000-1239.2013.20121130. Meng Xiaofeng,Ci Xiang. Big data management: Concepts,techniques and challenges [J].JournalofComputerResearchandDevelopment, 2013, 50(1): 146-169.DOI:10.7544/issn1000-1239.2013.20121130. (in Chinese)
[2]王元卓, 靳小龙, 程学旗. 网络大数据:现状与展望[J]. 计算机学报, 2013, 36(6):1125-1138.DOI: 10.3724/SP.J.1016.2013.01125. Wang Yuanzhuo, Jin Xiaolong, Cheng Xueqi. Network big data: Present and future [J].ChineseJournalofComputers, 2013, 36(6):1125-1138.DOI: 10.3724/SP.J.1016.2013.01125. (in Chinese)
[3]Zaharia M, Chowdhury M, Franklin M J, et al. Spark: Cluster computing with working sets[C]//UsenixConferenceonHotTopicsinCloudComputing.Berkeley, CA, USA: USenix Association, 2010:1765-1773.
[4]Zaharia M, Chowdhury M, Das T, et al. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing[C]//UsenixConferenceonNetworkedSystemsDesignandImplementation.Berkeley,CA, USA:USenix Association, 2012:141-146.
[5]易会战, 王锋, 左克, 等. 基于内存缓存的异步检查点容错技术[J]. 计算机研究与发展, 2014, 51(6):1229-1239. DOI: 10.7544/issn1000-1239.2014.20121125. Yi Huizhan, Wang Feng, Zuo Ke, et al. Asynchronous checkpoint/restart based on memory buffer[J].JournalofComputerResearchandDevelopment, 2014, 51(6): 1229-1239. DOI: 10.7544/issn1000-1239.2014.20121125. (in Chinese)
[6]慈轶为,张展,左德承,等. 可扩展的多周期检查点设置[J]. 软件学报, 2010, 21(2): 218-230. DOI: 10.3724/SP.J.1001.2010.03787. Ci Yiwei, Zhang Zhan, Zuo Decheng, et al. Scalable time-based multi-cycle checkpointing[J].JournalofSoftware, 2010, 21(2): 218-230. DOI: 10.3724/SP.J.1001.2010.03787. (in Chinese)
[7]吴俊.基于双优先级队列的异构分布式控制系统容错调度算法[J].东南大学学报(自然科学版),2008,38(3):407-412. DOI:10.3321/j.issn:1001-0505.2008.03.009. Wu Jun.Fault-tolerant scheduling algorithm for heterogeneous distributed control systems based on dual priorities queues[J].JournalofSoutheastUniversity(NaturalScienceEdition),2008,38(3):407-412. DOI:10.3321/j.issn:1001-0505.2008.03.009. (in Chinese)
[8]Neumeyer L, Robbins B, Nair A, et al. S4: Distributed stream computing platform[C]//IEEEInternationalConferenceonDataMiningWorkshops. Piscataway, New Jersey, USA: IEEE, 2010: 170-177. DOI: 10.1109/ICDMW.2010.172.
[9]Ongaro D, Rumble S M, Stutsman R, et al. Fast crash recovery in RAMCloud[C]//ACMSymposiumonOperatingSystemsPrinciples. New York, US:ACM, 2011:29-41. DOI: 10.1145/2043556.2043560.
[10]Li H Y,Ghodsi A, Zaharia M, et al.Tachyon: Reliable, memory speed storage for cluster computing frameworks [C]//IEEEConferenceonSYSTEM-ON-CHIP. Piscataway, New Jersey, USA: IEEE, 2014: 1-15. DOI: 10.1145/2670979.2670985.
Automatic checkpoint strategy for parallel computing frame with Spark
Ying Changtian1Yu Jiong1,2Bian Chen1Lu Liang1Qian Yurong2
(1School of Information Science and Engineering, Xinjiang University, Urumqi 830046, China)(2School of Software, Xinjiang University, Urumqi 830008,China)
The existing Spark checkpoint mechanism required the programmer to choose the checkpoint according to the experience, thus it had a certain risk and randomness, resulting in large recovery overhead. To address this problem, the resilient distribution datasets (RDD) characteristics were analyzed, and the weight generated (WG)algorithm and checkpoint automatic selection (CAS) algorithm were put forward.First, in the WG algorithm, the directed acyclic graph (DAG) of the job was analyzed, and the lineage length and the operation complexity of RDD were obtained to compute the RDD weight. Secondly, in the CAS algorithm, the RDD with the maximum weight was selected for setting checkpoints asynchronously to fast recovery. The experimental results show that comparing with the original Spark, the execution time and the checkpoint size of different datasets are increased by the CAS algorithm, while the increasing extent of Wiki-Talk is more obvious. For the single node failure recovery, the datasets have smaller recovery overhead after setting checkpoint by using the CAS algorithm. Therefore, the strategy can efficiently decrease the recovery overhead of jobs with sacrificing the slight extra overhead.
automatic checkpoint; resilient distribution dataset (RDD) weight;Spark; recovery time
10.3969/j.issn.1001-0505.2017.02.006
2016-11-12. 作者简介: 英昌甜(1989—), 女, 博士生;于炯(联系人), 男, 博士, 教授, 博士生导师, yujiong@xju.edu.cn.
国家自然科学基金资助项目(61462079,61262088,61562086,61363083,61562078)、新疆维吾尔自治区高校科研计划资助项目(XJEDU2016S106).
英昌甜,于炯,卞琛,等.并行计算框架Spark的自动检查点策略[J].东南大学学报(自然科学版),2017,47(2):231-235.
10.3969/j.issn.1001-0505.2017.02.006.
TP311
A
1001-0505(2017)02-0231-05
