基于DDPG的单目无人机避障算法*
2023-10-18刘小毛席永辉李思佳
魏 瑶,刘小毛,张 晗,席永辉,曹 爽,李思佳
(1. 西北工业大学 航天学院·西安·710000;2. 上海航天控制技术研究所·上海·201109;3. 中国航天科技集团有限公司红外探测技术研发中心·上海·201109;4. 西北工业大学 无人系统技术研究院·西安·710000)
0 引 言
人工智能的高速发展给无人机产业注入了蓬勃的生命力,无人机在各行各业中承担着越来越重要的角色,尤其是在复杂的室内环境中进行避障规划。由于小型无人机体积小、敏捷度高使得其能成功完成各种任务,例如搜索、救援环境测绘和未知区域探索等,因此一套行之有效的避障算法保证无人机能够安全执行各种任务显得尤为重要[1]。然而,避障算法的开发也面临着各种各样的挑战,其中之一便是小型无人机由于体积小、电池电量低而无法装载沉重的传感器,因此会降低避障算法的性能。
避障任务中常用的传感器有超声波传感器、雷达传感器、深度相机和单目相机。这些传感器各有优缺点,超声波传感器在测量近距离障碍物时性能相对较好,但其性能会随着与障碍物的增加而降低。雷达传感器测量精度高、具有宽广的探测范围与探测视野,能够提供来自周围环境的丰富信息,但其与其他传感器相比较,成本较高。此外,激光雷达传感器的质量使其很难在小型无人机上配备使用。深度相机可以提供无人机所处环境障碍物的几何以及距离信息,但其自身质量以及功耗可能会对无人机避障性能提出挑战。与激光雷达和深度相机相比较,单目相机所能提供的信息较少,但其具有体积小、质量小、能耗低、视野宽等优点,因此,在各种传感器中单目相机更适合于小型无人机的避障感知。
为了充分利用上述单目相机的优点,研究人员开发了各种避障算法,但直接使用来自单目相机的RGB信息仍旧具有挑战性。由于单目相机将来自环境的3D真实数据减少为2D图像像素,很难从图像中获得准确的距离信息。Alvarez H[2]等人使用RGB图像构建深度图像,并基于该深度图像生成无障碍路径,从而成功地实现了无人机的避障功能,但是这种方法至少需要1s的时间来计算航路点,这可能会导致无人机在躲避动态障碍物时失败。Cho S[3]等人利用光流来进行避障。基于光流的方法并不需要太高的计算负载,因此非常适合在不配备高性能计算板的小型无人机身上使用,然而当无人机处于无纹理或者障碍物巨大的环境中时,基于光流的方法很难在这种环境下提取特征[4]。另一种基于视觉的避障方法为同步定位与地图构建(Simultaneous Localization and Mapping,SLAM)方法。视觉SLAM使用3D地图信息估计无人机当前的位置和方向,Mur-Artal R[5]等人使用SLAM方法来计算航路点,从而在有障碍物的环境中对无人机进行导航。然而,视觉SLAM方法要重新构建无人机环境的地图信息,并配合路径规划算法计算出无人机的避障路径,因此对计算负载和内存的要求高[6]。此外,光流法和视觉SLAM方法都需要适当的参数设置才能在避障环境中发挥出好的性能,当避障环境出现变化时这些算法可能会失效。
作为机器学习的另一大分支,强化学习为无人机的自主避障提供了一种新的方法。强化学习根据智能体所处的环境状态产生动作以最大化奖励。在强化学习中,智能体通过反复试错从而学习得到特定的动作策略(例如:跟踪目标、抓住物体或避开障碍物),同时自动收集训练数据使得智能体最终可以在各种状态下选择最佳动作。Singla A[7]等人使用生成对抗网络 (Generative Adversarial Network,GAN)进行深度估计。在避障决策方面,它采用深度递归神经网络 (Deep Recurrent Q-networks,DRQNs),将顺序时间序列数据作为网络输入来解决深度 Q 网络 (DQN)中的部分可观测性问题。Xie L[8]等采用卷积神经网络(Convolutional Neural Networks,CNN)来估计深度图像,然后使用决斗双深度 Q 网络(Dueling Double Deep Q Network ,D3QN)通过估计得到的深度图像来选择最佳决策动作。以上两种方法通常表现出良好的性能,但由于它们的奖励功能,容易产生锯齿形运动或旋转运动。这些动作可能需要过多的控制努力,这会导致任务失败,尤其是对于电池容量较小的小型无人机而言。因此,需要设计一种新的奖励函数,以适应复杂环境,最大限度地减少电池损耗。目前,强化学习方法采用离散动作输出算法的研究居多,跳跃式的动作取值方法对无人机的避障效果会带来较大影响。
综上所述,文中需要考虑到该避障算法应基于单目相机并能应用于负载较小的小型无人机避障之中,且由于小型无人机的低电池容量,该算法应尽量减少不必要的运动。基于这些条件,本文提出一种深度强化学习算法,该算法仅通过单目相机为无人机在室内进行避障任务时给出决策信息。本文的主要贡献如下:
1)以无人机在复杂室内环境中避障为背景,结合CGAN网络实现了一种基于单目相机的无人机端到端避障算法;
2)针对传统强化学习给出离散动作空间决策信息,导致无人机避障效果差问题,提出一种基于深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)的强化学习方法,使无人机能够进行连续避障动作控制,从而优化避障轨迹;
3)分别在3D仿真环境和真实环境中进行测试验证。
1 算法原理
1.1 从RGB图像到深度图像的转化
文中使用条件生成对抗网络CGAN(Conditional GAN)来进行从RGB图像到深度图像转换。原始的GAN在生成图像时,不需要假设的数据分布,这种方法过于简单,会导致生成过程不可控。与此同时,CGAN是将无监督转换为有监督模型的改进网络,其在图像生成过程中加入了有标签信息,从而增加了生成过程中的约束性和针对性。文中使用的CGAN方法拥有两个独立的卷积网络,分别为生成器和判别器。生成器学习为训练数据集中的每个标签生成逼真的样本,而鉴别器则学习区分真的样本-标签对与假的样本-标签对。从某种意义来说生成器和鉴别器两个网络的目标是相互对立的。其损失函数反映了该目标。
LCGAN(θD,θG)=Ex,y~Pdata[logD(x,y)]+
Ex~pdata(x),z~pz(z)[log(1-
D(x,G(x,z)))]
(1)
其中,θD为判别器神经网络参数,θG为生成器神经网络参数,变量x为RGB图片;z为噪声图像;变量y为其所对应的真实深度图片;G(x,z)为生成器所生成的深度图片;D(x,y)为生成器所生成深度图片被判别为真实的概率。在本文中使用U-net为CGAN为模型生成器,U-net可以看做是一种编码-解码器模型,它在编码器和解码器之间将不同层的相应特征图连接在一起。鉴别器由编码器构成,通过训练鉴别器从而区分真假图片。其中CGAN的网络架构如图1所示,生成器以随机噪声图像z以及RGB图像为输入,生成服从实际图像数据分布的“假”深度图片G(z,y)。判别器的输入为x,y以及G(z,y),其输出为对生成器生成图片G(z,y)的真假判别标签。文中CGAN 网络生成器、判别器的具体网络架构与该网络结构[9]设计一致。
1.2 深度强化学习原理
深度学习侧重于“感知”,强化学习则与深度学习[10]不同,其侧重于“表达”。深度强化学习[11]将深度学习“感知”能力与强化学习的序列决策能力相结合,使得智能体在复杂状态空间下的决策问题得以解决。越来越多的研究人员已经将深度强化学习应用于无人机避障决策之中。深度强化学习一般由以下几部分构成:1)智能体Agent;2)交互环境E;3)状态转移方程P(表示智能体从一个状态转移到下一个状态的概率);4)奖励函数R,其具体结构如图2 所示,智能体感知所在环境状态,将状态信息作为深度神经网络输入,神经网络根据状态信息给出动作策略,智能体执行相应动作与环境发生交互,交互环境根据奖励函数以及状态转移规则给出智能体奖励r以及下一状态s′。
深度强化学习,将问题定义为一个马尔科夫决策过程(Markov Decision Process,MDP)。无人机在避障过程中,下一时刻无人机所处的状态仅仅依赖于当前场景以及其采用动作后的状态转移方程,而与之前所处的一系列历史状态无关。因此,可以将无人机的避障问题看做是一个马尔可夫决策过程,从而纳入到强化学习框架中进行求解。通常情况下,将当前状态st、当前动作at、奖励值r以及下一状态st+1作为一个元组(st,at,r,st+1)进行收集并构成集合(S,A,R,S′)。强化学习算法通过优化目标策略π:s→a,使得在st时刻累积获得奖励R最大,则R的表达式为
(2)
其中,γ∈(0,1)为衰减因子,表示当前时刻奖励对未来时刻的影响,t为当前时刻,T为整个马尔科夫决策过程。Q价值函数被定义为Qπ=E[Rt|st,at],其中,Rt为当前时刻奖励值。强化学习的训练目标为通过求得最优策略π*,从而使公式(2)中R的期望最大,即寻找出最优策略π*使得公式(3)成立。其中,s和a分别是此时智能体的状态和动作。
Qπ*(s,a)≥Qπ(s,a) ∀s,a∈S,A
(3)
1.3 深度确定性策略梯度算法
DDPG 算法[12]作为一种无模型的深度强化学习方法,无需对环境进行精确建模便可以实现连续动作策略输出。该算法采用行动者-评论家(Actor-Critic)的网络结构,Actor网络(记作μ(s|θμ))确定性地将状态st映射到动作,即基于当前环境状态给出无人机确定性动作,Critic网络(记作Q(s,a|θQ))根据当前状态动作逼近计算动作极值函数,其中θμ和θQ分别为网络参数。此外,为了减小对价值函数的过高估计对应设计了行动者目标网络μ(s|θμ′)和评论家目标网络Q(s|θQ′)。
1.3.1 Actor网络
Actor网络通过输入当前状态信息给出基于当前状态信息的确定动作策略,其中累积奖励与动作有关,因此可以通过梯度上升对Actor网络参数θμ进行更新,则Actor网络的更新方式如公式(4)所示
(4)

1.3.2 Critic网络
Critic网络通过其神经网络参数θQ,对基于当前状态的动作以Q值的形式给出评价,该Q值以链式法则的形式对公式(4)产生影响,因此准确的Q值对Actor网络的更新收敛有着至关重要的作用。Critic网络通过最小化损失函数来进行更新,并使得其评价值更加准确。Critic网络损失函数的计算方法如下所示
L(θQ)=Est~pβ,at~β,rt~E[(Q(st,at|θQ)-Q^)2]
Q^=rt+γQ′(st+1,μ′(st+1|θμ′)|θQ′)
(5)
1.3.3 目标网络
为避免自举算法过高估计价值函数,DDPG算法采用软目标更新策略,利用Actor目标网络 和Critic目标网络来计算目标价值。其中,Critic 目标网络通过网络参数θQ′来估计目标Q值,Actor目标网络使用网络参数θμ′来计算目标动作。其网络更新方式如公式(6)所示。其中,τ为滑动平均系数,其取值通常小于1。
θQ′←τθQ+(1-τ)θQ′
θμ′←τθμ+(1-τ)θμ′
(6)
1.3.4 随机噪声
DDPG中的智能体动作来源于Actor网络μ(s|θμ)根据目前智能体所处的状态信息而给出的确定性动作,当状态信息相同时,Actor网络只会输出相同的动作结果使得探索的样本减少。为使Actor网络进行更好的探索,将对策略μ添加随机噪声N,即μ′(st)=μ(st|θμ)+N使其输出的动作策略具有随机性,可以进行更多的探索。在实际训练中噪声N随训练迭代次数进行线性衰减至0,不再对Actor网络输出产生影响。
2 基于深度确定性策略梯度的无人机决策模型
2.1 系统模型
本文的目标是在室内三维环境下,利用单目相机以及环境信息(无人机速度)进行连续控制决策使得无人机能够避开障碍物并达到目标位置。系统的总体结构如图3所示,Actor网络与Target-Actor网络负责给出智能体动作决策;Critic网络与Target-Critic负责评估基于该状态动作的价值函数;经验回放池Memory负责存储探索数据;Airsim为无人机所交互运行的仿真环境,奖励函数为人为设计的函数,用来输出动作奖励值,鼓励网络朝着期望的方向训练。
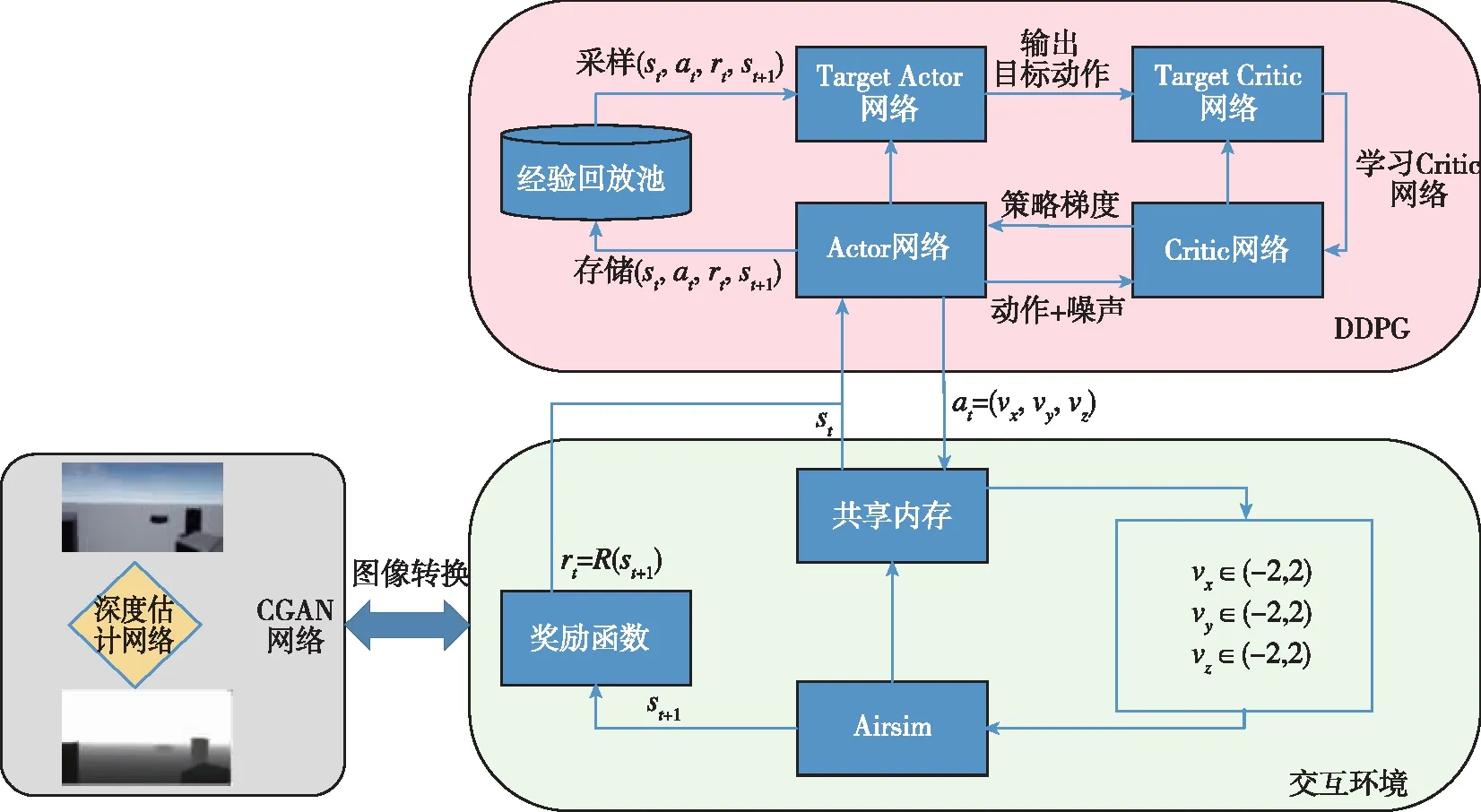
图3 系统模型Fig.3 System model
整个系统主要分为深度图片估计、环境探索以及网络训练两个部分,如图3所示,t时刻时,获得无人机所处环境状态的RBG图片,将RBG图片输入至已经训练好的CGAN网络之中生成深度图片并输出,通过将生成的图片进行处理得到此时的状态信息st。Actor网络根据此时的输出状态st给出无人机的动作策略at=μ(st|θμ),并对该动作添加噪声后得到at=μ(st|θμ)+N,将此时的动作at通过数据通信的形式发送至Airsim中的无人机上,无人机得到动作信息与环境产生交互,产生下一个状态值st+1以及动作奖励值rt=R(st+1)。此时,无人机完成环境探索将收集得到的数据(st,at,rt,st+1)存入经验回放池中以供后续网络进行训练。DDPG网络训练采用离线训练方法,首先在经验池中进行采样得到数据(st,at,rt,st+1),然后根据公式(4)更新Actor网络使其朝着使Q值上升的方向训练。Target-Actor网络根据采样数据st+1计算动作值at+1,将st+1,at+1传递给Target-Critic计算下一状态的Q值Q^=Q(st+1,at+1|θQ′),同时Critic网络计算当前状态Q值Q=Q(st,at|θQ)。通过最小化损失函数(式(5))更新Critic网络,并根据公式(6)更新目标网络。该结构能够在单步更新参数的同时控制连续变量,并借鉴了DQN算法的经验回放(Experience replay)机制,从经验回放池中随机采样,打乱状态之间的相关性,加快收敛速度,提高数据利用率。
2.2 状态空间和动作空间设计
状态空间:本文在仿真环境中进行训练,利用单目摄像机作为感知器得到640×480的RGB图像,该图像通过深度估计网络得到84×84的深度图像。在得到深度图片之后一般需要对图像进行预处理,从复杂信息中提取有效信息,以降低复杂度,提高算法效率。如图4所示,本文将此时84×84的深度图片转换成84×84的灰度图像dt,并叠加此时无人机的速度信息vt(该速度信息包括无人机x,y,z三个方向上的速度信息vx,vy,vz)作为此时的状态信息st如公式(7)所示。在本实验中,使用灰度图像不会影响学习性能,并且由于仅使用深度图片进行训练可以减少RGB图片中纹理色彩对训练结果的影响,增强算法的泛化能力并有效提高计算速度。
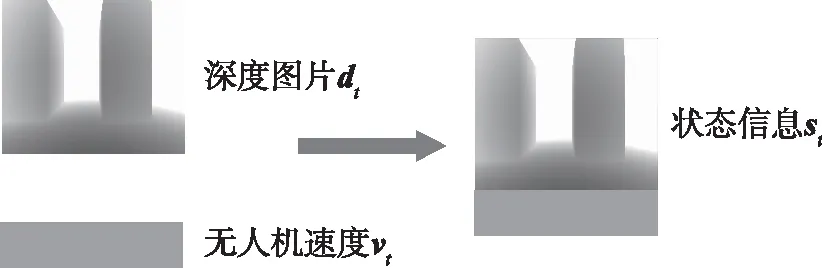
图4 状态信息预处理Fig.4 Preprocessing of state information
st=[dt,vt]vt=[vx,vy,vz]
(7)
动作空间:DDPG算法可以处理动作连续情况下的决策问题,此处选择无人机的状态:速度v(m/s)为主要动作,以避免利用位置信息需要全局定位的问题。在此基础上,为了减少神经网络计算量,降低网络训练难度,去除无人机偏航通道控制,将无人机看作为三自由度的质点运动,神经网络给出的动作策略为三个不同方向的速度大小。此时无人机的动作空间见表 1 。

表1 动作空间表Tab.1 Action space table
2.3 奖励函数设计
奖励函数的设计与训练目的有关,本文研究的目的是确保无人机能够在充满障碍物的室内环境中,躲避障碍物并到达目标位置。因此,奖励函数的设计既要保证无人机躲避开障碍物又要激励无人机朝着指定位置飞行而不能原地不动。在本文仿真中奖励函数的输入设为{p,speed,collision},其中p为位置信息,用来计算无人机此时与目标点之间的直线距离dist,speed为无人机当前三个方向上的速度范数,collision为碰撞标志位,是由仿真环境所给出的无人机碰撞信息。当collision为1时表示当前无人机产生碰撞,为0时表示无人机处于安全飞行状态。其算法交互过程如表 2 所示,当无人机碰撞标志位为1时说明无人机产生碰撞,则给予-20的惩罚并且结束该回合训练;当无人机并未产生碰撞时,检测速度大小是否小于speed_limit,在本文中speed_limit设置为0.1是为了防止神经网络为了避免碰撞惩罚而原地不动;当dist<0.3时说明无人机已经到达目标点附近则给予50奖励,否则奖励值为本次无人机与目标点之间距离与上一时刻距离之差,从而鼓励无人机在避免产生碰撞的同时到达指定目标位置。

表2 奖励函数计算过程Tab.2 Reward function calculation process
2.4 DDPG网络结构
文中DDPG算法采用Actor-Critic结构,Actor和Critic的具体结构如图5、图6所示,其具体参数设置如表4所示。Actor网络通过输入此时无人机的状态信息,从而给出无人机基于该状态的动作。与传统Actor网络仅输入深度信息进行决策相比,本文采用多模态网络来进行决策信息处理,从而提高网络对无人机的控制能力。根据协同表示方法,通过将速度信息与84×84的图像信息映射到不同的特征子空间进行处理。其中,使用9个卷积层来提取图像特征信息,使用全连接层来处理速度信息。经过卷积层后与同时经过全连接处理的动作信息进行合并,并通过三个全连接层输出动作信息。
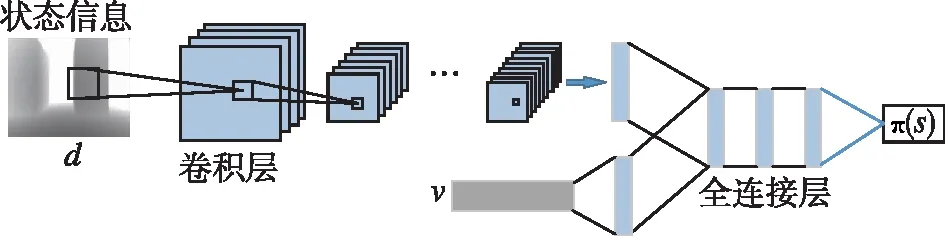
图5 Actor网络结构Fig.5 Actor network structure
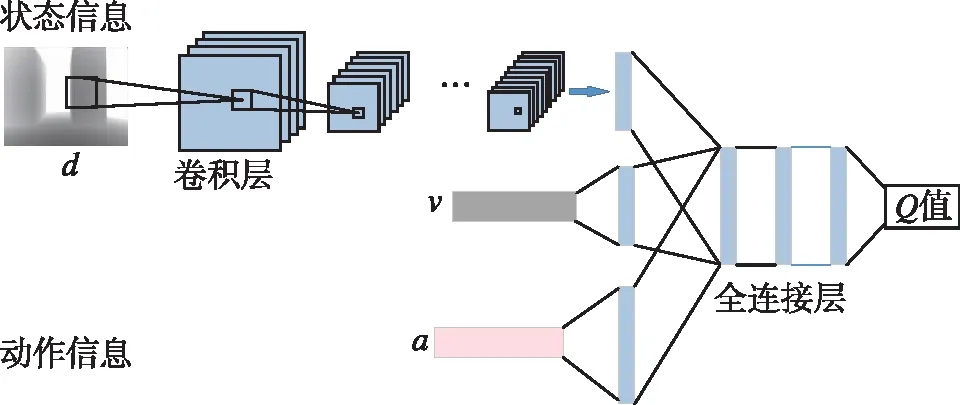
图6 Critic网络结构Fig.6 Critic network structure

表4 参数配置表Tab.4 Parameter configuration table
其次,在Critic网络中,状态信息的处理过程与Actor网络的一致,其相应的网络结构也相同,该过程被称为“观察预处理”。由于该动作输入为一维数据,因此将其输入一个具有128个单元的全连接层中进行处理,使得动作与处理后的状态信息拥有相同形状,该过程被称为“动作预处理”。接着将“观察预处理结果”与“动作预处理”结果,采用合并层结合在一起通过3个全连接层输出基于该状态的动作评估值。
3 仿真及实验研究
3.1 仿真场景
本文实验平台为Window 10 操作系统,CUDA 10.0,Tensorflow2.3.0,Python3.7,模拟环境为Airsim[13]。AirSim支持多种传感器的仿真与自定义,包括摄像机、气压计、惯性测量单元、GPS、磁力计、深度摄像机、激光雷达等。它提供基于C++和Python的多种API,例如飞控接口、通信接口、图像接口等,拓展性较高,便于进行半实物仿真。因此,本文选择其作为仿真系统的基础,开展无人机避障算法的研究。
在仿真实验中,无人机采用单目摄像机在其前向120°范围内采集来自环境的RGB图片,以及利用IMU测量自身线速度作为状态观测值。在进行算法训练测试过程中,为了能够快速评估算法的有效性以及各种性能,本文选用在如图7所示的无渲染的简单仿真环境中进行仿真。图8为无人机避障训练过程,无人机开始训练时初始奖励值为0,当无人机发生碰撞后会得到-20的惩罚,当无人机沿着正确的路线飞行靠近目标位置时会得到奖励,最终当无人机安全到达目标点时会得到+50的奖励。无人机训练的总分值为训练时每一步奖励之和,因此训练结束后,当总分值大于50时表明在当前训练回合中,无人机能够成功躲避所有障碍物并到达指定目标点,并且平均奖励值越高,表明无人机所选择的避障路线更好。为了验证本文所提出算法的有效性,本文分别将DQN、DDPG、优先经验回放DDPG[14-15](DDPG Prioritized Experience Replay,DDPG-PER)等算法在该仿真环境中进行训练测试。DDPG-PER为引入优先经验回放机制的算法,其目的在于提高数据利用率,加快训练速度。通过对比算法,可以验证所提出的新算法的有效性。

图7 仿真环境示意图Fig.7 Schematic diagram of the simulation environment
图8 无人机避障训练过程Fig.8 UAV obstacle avoidance training process
3.2 仿真结果分析
如图9~图14分别给出了无人机训练过程中的总得分、平均奖励、网络估计Q值、Actor 网络损失值(Actor Loss)、Critic网络损失值(Critic Loss)以及平均速度随训练时间的变化情况。本次训练共6000个回合,从图9中可以看出,本文所提出的DDPG算法在训练至500次时其累积得分便大于0,说明此时无人机已经拥有躲避障碍物的能力,当训练至1000次时期累积得分大于50,表明此时无人机已经能够成功躲避障碍物并到达指定目标位置附近。与DDPG相比较,DQN算法在整个训练过程中整体总得分一直在0左右徘徊,说明无人机只学习得到了简单的避障功能,但其可能只是在原地徘徊,或者在仿真环境 “漫游”而不能到达指定位置。图10为平均奖励变化曲线,平均奖励计算方式为总得分除以无人机在该回合中的步数,奖励值用来衡量在该训练中算法所给出每一步的动作决策是否有用。通过对比可以看出,DDPG算法的平均奖励值明显大于DQN算法的平均奖励值,在引入优先经验回放机制后,其算法的收敛性和稳定性也得到了提升。DQN算法由于反复取用最大值理论会导致Q值过高估计,从而影响正确决策动作的给出。DDPG算法由于解耦了动作决策和价值估计这两个网络,可以明显降低价值函数的过高估计。由于DQN算法网络结构与DDPG算法结构不相同,因此其损失值没有可比性,在此不予比较。图14为无人机速度变化曲线,该速度为无人机在x、y、z三个方向上的速度范数,从图中可以看出最终无人机的速度会收敛至2.75m/s附近。
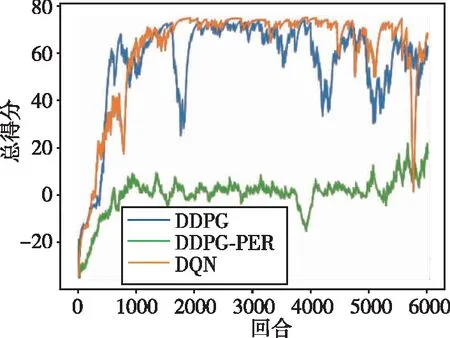
图9 总得分变化曲线Fig.9 Total score change curve
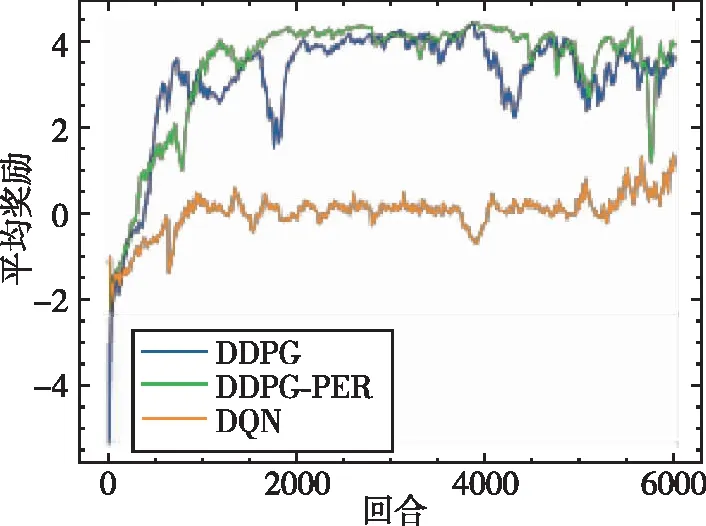
图10 平均奖励变化曲线Fig.10 Average reward curve
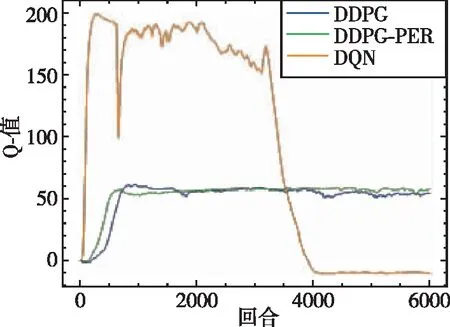
图11 Q值变化曲线Fig.11 Q value change curve
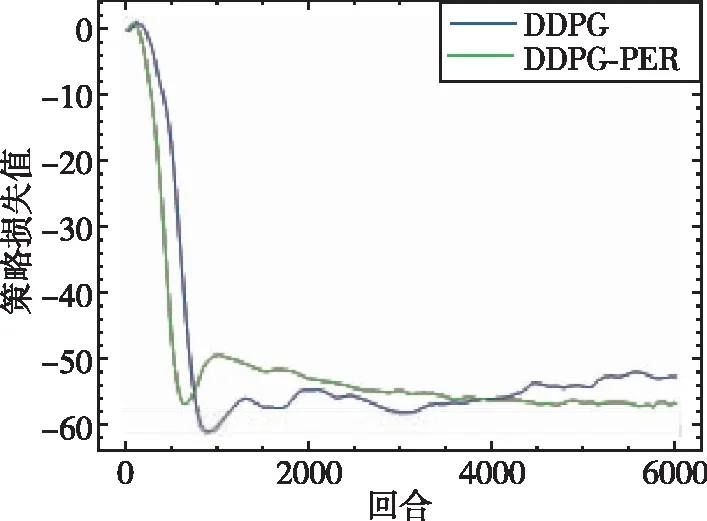
图12 Actor loss变化曲线Fig.12 Actor loss curve
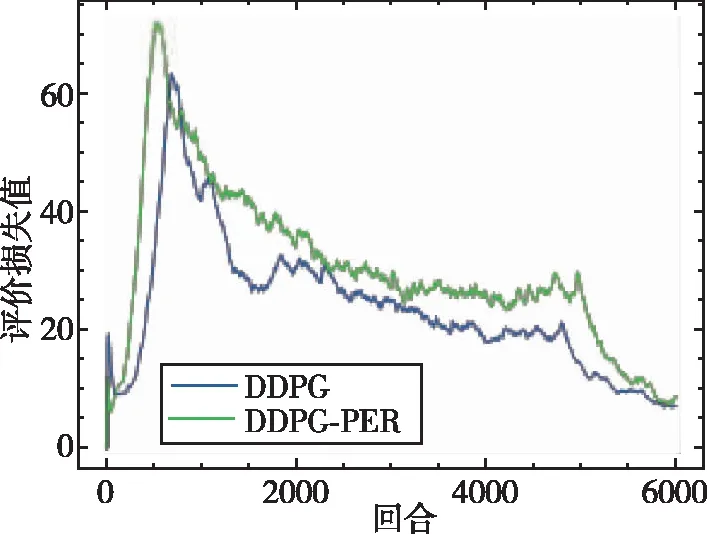
图13 Critic loss变化曲线Fig.13 Critic loss curve
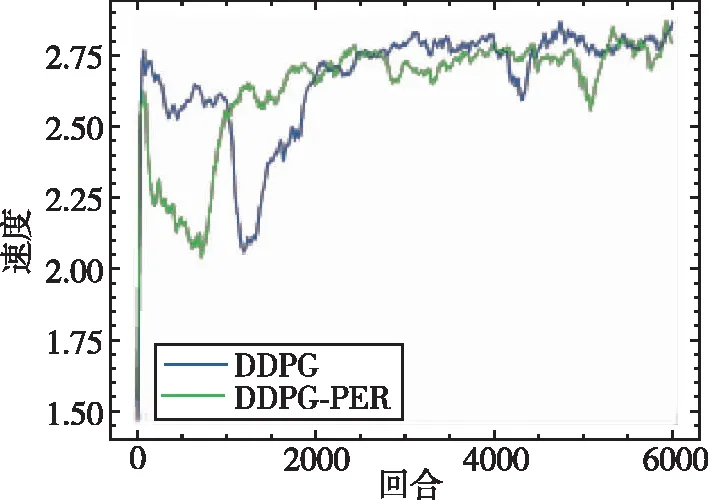
图14 速度变化曲线Fig.14 Speed curve
3.3 仿真结果测试
表 4所示为DQN和本文所提出DDPG算法模型所训练模型在测试环境中进行100次测试后结果。DQN算法由于只能进行离散动作控制,因此设定其动作空间分别为无人机在x,y,z三个方向上以2m/s的速度运动1s。其中DQN的平均累积得分和平均奖励值均远低于本文所提出模型。其累积得分小于0分说明,虽然在训练时DQN算法表现可以躲避障碍物,但测试时由于算法鲁棒性不强,很有可能因为一个小的扰动而导致无人机避障失败。DDPG算法模型在100次测试中的平均累积得分大于50说明,在测试过程中几乎每次测试,无人机都可以躲避障碍物并到达目标位置。图15为俯视下无人机避障路线对比图,由于DDPG算法采用连续速度控制,所以其避障轨迹相对于其他算法而言更加光滑,避障效果更好。
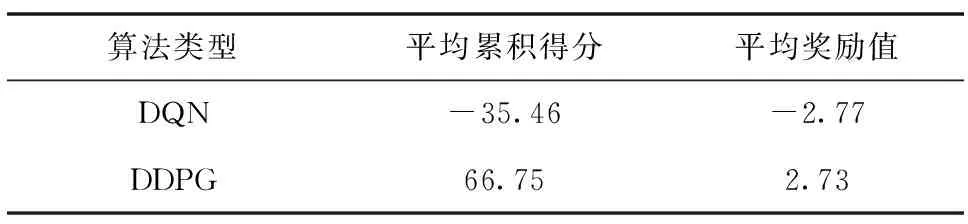
表4 对比试验结果Tab.4 Comparative test results
该测试环境分别在原有场景的基础上改变障碍物数量、颜色、大小以及分布情况,从而测试无人机是否真正学习到了躲避障碍物的能力。从图15中可以看出,在改变障碍物大小以及分布时候,无人机仍具有躲避障碍物的能力。当测试环境无人机起始位置、目标位置与之前训练环境中一致时,由于障碍物分布不同,无人机可能需更多的步数才能到达目标位置,但仍旧可以成功躲避障碍并到达指定位置点。这表明使用算法所训练得到模型在未知环境中仍旧具有避障能力。
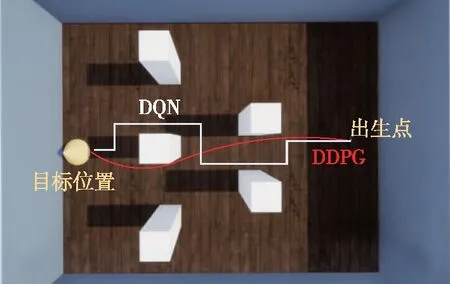
图15 无人机避障路线俯视图Fig.15 Overhead view of UAV obstacle avoidance route
3.4 真实场景测试
本文将之前在训练场景中得到的DDPG模型应用于真实环境下进行测试,决策系统框架如图16所示。本文所使用无人机为大疆Tello,该无人机配备有前置RGB摄像机以及IMU等可以读取自身速度信息以及高度信息。由于Tello 无人机可以直接通过无线Wi-Fi信号对x,y,z轴上的速度信息进行控制,因此本实验将深度信息估计模型与决策模型布置于本地计算机上,通过Wi-Fi通信读取无人机自身的传感数据,在本地计算机上进行计算,得到无人机相应的决策动作,再发送给无人机执行动作。
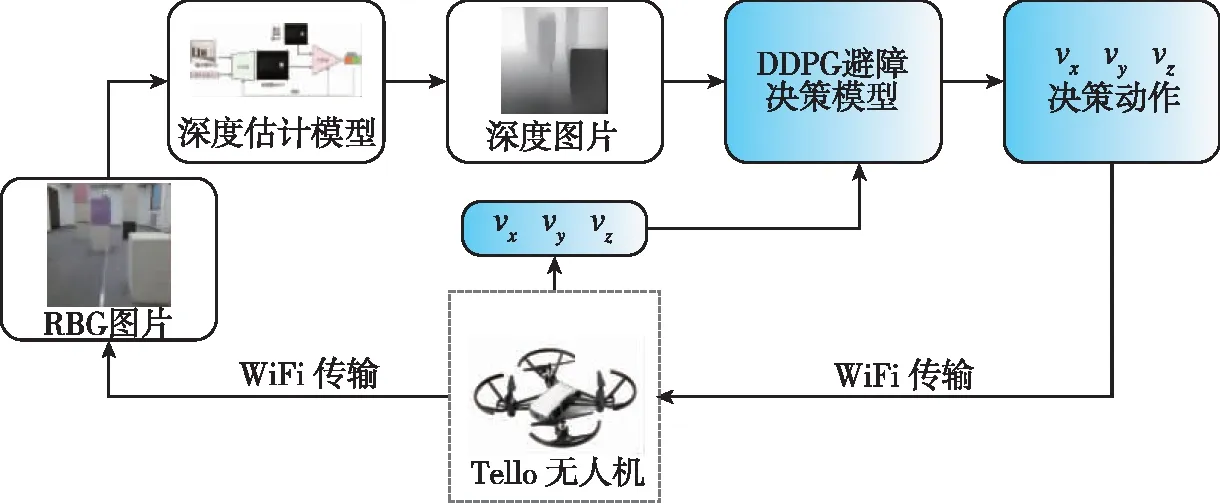
图16 真实场景下的单目无人机避障决策框架Fig.16 Obstacle avoidance decision framework for monocular UAV in real scenes
经过一系列实验,对本文所训练的避障决策模型在两个场景中进行了性能测试,图17所示为不同真实场景中决策模型所输出的无人机各个方向上的避障动作。其中,x方向为无人机左右方向,y为无人机前后方向,z为无人机上下方向。避障算法模型通过接收得到当前环境状态信息进行计算决策,给出无人机当前三个方向的速度大小,无人机飞控系统得到决策信息进行解算,并通过俯仰、滚动通道做出避障动作完成避障。图18所示为无人机在场景一和场景二中的避障路线。由此可以看出,在真实环境中,当无人机遇到障碍物时,也会做出相应的避障动作躲避障碍物,可见本文提出的避障算法在真实环境中仍旧有较好的避障能力。
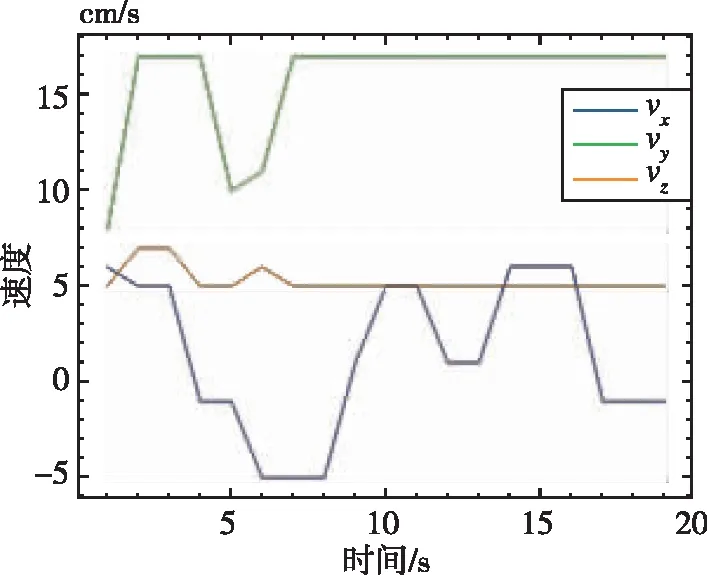
(a)真实场景一
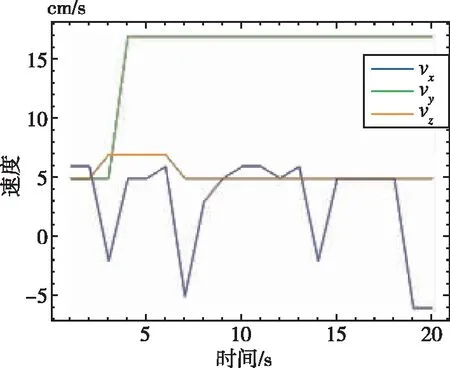
(b)真实场景二图17 无人机避障算法输出结果Fig.17 The output result of UAV obstacle avoidance algorithm

(a)真实场景一

(b)真实场景二图18 真实场景下无人机避障路线示意图Fig.18 Schematic diagram of UAV obstacle avoidance route in real scene
4 结 论
本文以无人机在未知三维室内环境中仅使用单目相机进行避障为研究背景,针对普通RGB图片无法提取深度信息进行避障以及无人机避障速度不连续问题展开研究。首先利用CGAN网络从单目RGB图像中预测深度图片,接着采用DDPG算法进行动作决策,以有效解决连续动作控制问题。在此基础上,对DDPG算法中的Actor和Critic网络进行改进,通过引入多模态网络将无人机当前速度信息与深度图片作为状态信息共同在网络中处理,从而提高算法控制的稳定性与有效性。通过在仿真环境中进行训练测试,表明本文所提出的算法模型能够较好处理单目避障问题,与DQN算法相比较,无人机避障轨迹也更连续,避障效果更好。最终,在实物上进行验证,证明了本文所提出的避障算法的实际有效性。
