双任务交互下的四段监督人群计数网络
2023-10-18王大正
王大正,张 涛
(江南大学 人工智能与计算机学院,江苏 无锡 214122)
1 引 言
当前世界经济飞速发展且人口呈爆炸式增长,为了更好地保障社会治安,准确估计各类复杂场景中的人数并预测其分布趋势变得尤为重要,特别是在监控治安、智慧交通等视觉相关领域.因此,人群计数和密度估计作为最基本的人群分析方法在近几年也得到了广泛研究.
传统的人群计数方法包含基于检测的方法[1]和基于回归的方法[2],分别通过检测后计数和直接特征回归来估计图中总人数,其在人群分布相对稀疏和均匀的场景下表现尚可,却严重囿于密集场景下的人群遮挡问题和由相机视角造成的多尺度问题.此外,这些方法均仅使用计数标签预测总人数,并不关注人群的具体分布状态,这为各个场景下的人群状态理解带来了局限性.Pham等人[3]将图片分块,然后通过随机森林方法学习每个块的特征和块中物体相对位置的映射,最后通过高斯核密度估计来生成密度图.至此,人群计数开始由简单的回归问题逐渐演化为密度估计问题[4].近几年卷积神经网络(Convolutional Neural Network,CNN)凭借其优秀的表征能力在计算机视觉任务中大放异彩,为人群的分布预测奠定了技术基础.Fu等人[5]首次使用CNN进行人群计数,有效地提高了计数精度;Zhang等人[6]设计了一个多列卷积神经网络,通过3列不同大小的卷积核来控制感受野大小以学习不同尺度形态下的人头特征,有效减少了因为透视或人头遮挡对计数和密度估计造成的影响;Li等人[7]则使用空洞卷积代替上下采样操作扩大网络感受野,在特征学习过程中保留了更多的细节信息,不仅显著提高了计数精度,还生成了更高质量的密度估计图.
然而上述介绍的都是基于单任务监督的方法,这些方法一般仅生成人群密度估计图,然后将其上所有像素相加得到人群总数,或者直接计数.此举会导致最终的预测结果中不仅包含由人头特征产生的正确预测,还包括背景区域上的误判,这将对最终的计数结果产生不利影响[8].此外,基于多任务学习的计数方法证明了在不同任务中共享向量表达能够让模型的泛化效果显著提升.Liu等人[9]针对人群密度问题将检测方法和回归方法结合到一起,并使用注意力模块调整网络参数在两种模式中自动切换,以此来提升人群密度估计精度.Sam等人[10]采用模型增长的方式在训练过程中自动划分不同的密度等级,并生成一组不同的模型在特定的数据上训练.由于其为基于分成聚类的模型,对于不同复杂度的数据集,也可以通过模型的调整和增长得到出色的结果.Shen等人[11]则充分利用对抗性损失来减弱密度图估计的模糊效果,并提出交叉尺度一致性追求损失来限制不同尺度人群带来的误差,既增强了密度图的清晰度,又提升了模型的计数性能.这些方法通过不同任务间的协作来分别提高网络的计数精度和密度估计能力,然而其均采用多列结构,虽然在一定程度上提升了模型性能,却付出了一定的空间代价,使得检测效率不高.本文则倾向于使用单列结构,通过合理利用特征学习中不同阶段语义的物理含义来自适应地寻找感兴趣区域,在几乎不增加参数的前提下提高网络的计数能力和密度估计能力.
本文提出双任务交互下的四段监督网络(Four-stage supervised crowd counting network,F2SNet),通过计数监督、早期分布优化、终期分布修正模块和背景抑制有效兼顾了计数准确性和密度估计图的分布一致性.Shanghai Tech[6]、UCF-CC-50[12]、UCF-QNRF[13]及JHU-CROWD++[14]4个常用人群数据集的实验结果也充分证明了所提方法的有效性.
2 F2SNet基本原理
2.1 F2SNet结构
双任务交互下的四段监督人群计数网络(F2SNet)的具体结构如图1所示,其由主干网络、计数监督、早期分布优化、终期分布修正模块以及背景抑制5个部分组成.其中,主干网络使用具有良好迁移能力和学习能力的VGG19前16层卷积层提取基础人头特征,并且为了在保留更多细节的前提下学习人头特征的不同尺度形态,使用膨胀率为2的空洞卷积代替原结构中的一组下采样上采样操作.计数监督用来直接预测图片总人数,并生成评估各个位置上特征对计数任务重要程度的人群响应图来锁定人群区域,其不考虑人群具体分布情况,仅从计数的角度来约束预测值与人数标签之间的误差,以提升网络的计数准确性.早期分布优化关注了浅层网络对人头特征的学习情况和早阶段分布预测的准确性,有效缓解了低级特征对后期计数的干扰.终期分布修正模块在网络进一步扩大感受野并使用高频语义信息对预测图加权后再一次监督人群的分布预测.背景抑制监督惩罚了最终密度估计图在背景区域上的误判,以获得更准确的密度分布估计和更干净的人群密度估计图.4个部分将协同工作,利用网络中不同阶段语义信息的特性来自适应地锁定感兴趣区域,分别从计数准确度、分布一致性和背景误判三方面来监督网络训练,彼此独立工作却又相互约束,计数监督所产生的人群响应图将放大感兴趣区域特征在密度估计任务中的贡献度,同时,对密度估计图分布的监督也将帮助人群响应图更好地锁定前景区域.
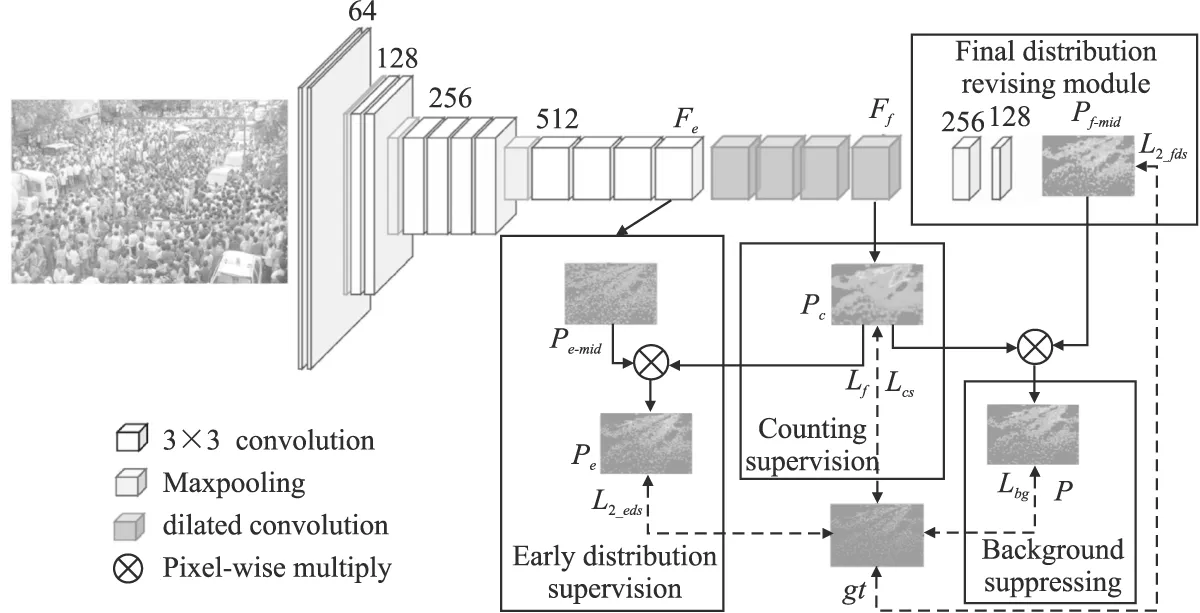
图1 F2SNet结构Fig.1 Overall structure of F2SNet
2.2 四段监督
2.2.1 计数监督
人群计数任务最直接的目标是准确预测图片中的总人数.计数层用特征回归的方法来寻找分辨力强的人群区域.将终期中间特征图Ff使用1×1卷积处理为单通道密度图作为用于计数的人群响应图Pc,如公式(1)所示:
Pc=conv1512(Ff)
(1)
其中conv1512(Ff)为通道数为512的1×1卷积.人群响应图Pc为人群图片经过层层学习后在最大感受野下所呈现的抽象的高级特征,其为特征提取器所筛选过的对最终计数任务非常重要的深层语义信息,反映了网络对原人群图片整体的理解情况.将人群区域响应图中所有像素值之和作为对原图中总人数的预测,具体计数损失函数Lcs定义为公式(2):
(2)
由于人群响应图为高级语义特征与人数标签之间映射,其像素值之间的差异谕示了不同位置特征对最终计数结果的贡献,也暗示了不同区域特征对计数任务的重要程度.人群响应图在原图上的对应如图2所示,可以看到在经过多层卷积核过滤后,人群响应图可以将人群区域从背景中甄别出来,但是会不可避免地产生一些来自背景噪声的错误预测,如图2(c)方框标识区域所示,这将会补偿网络对前景的预测不足,从而影响计数.因此,为了进一步强调人群区域,同时使对人数的预测更多来自于人头特征,提出前景突出损失函数来监督标注点位置的预测,其定义如公式(3)所示:
(3)
其中人群响应图与分布标签的乘积界定了网络前景像素点上的预测,监督前景预测将会提高网络对前景区域的关注度,从而增强该区域特征对计数的响应能力.在计数损失函数的基础上,前景关注损失将使得预测点凝聚在前景区域,从而有效减少背景噪声对计数的干扰.

图2 人群区域响应图在原图上的对应Fig.2 Correspondence of crowd response map on the original image
此外,人群响应图在人群越密集的区域对应预测值越大,在分布相对稀疏的地方的预测则较为发散,这意味着其强调了密集区域.人群响应图作为高级语义特征与计数标签的直接映射结果,体现了网络对原人群图片的理解,暗示了不同特征对预测结果的重要性,同时给出了前景和背景的概念.在后续对早期分布以及终期分布的监督中,将使用人群响应图对其进行加权调整,突出关键信息并着重关注密集场景下的预测,以得到更清晰准确的人群密度估计图.
2.2.2 早期分布优化
在基于CNN的人群计数方法中,模型性能主要取决于特征提取器对目标信息的表征能力,即其所提取的特征的质量.特别是在感兴趣目标不突出且缺乏细节的人群计数任务中,对人头特征的理解水平将直接影响计数精度和预测分布准确度.
为了提高网络对人头信息的理解能力,提出早期分布优化来监督浅层网络对人群分布的预测,使得其能在感受野受限情况下更早地聚焦前景,从而突出人头特征.如图1所示,首先使用1×1卷积将早期特征提取过程中产生的中间特征图Fe处理为单通道的早期中间密度图Pe_mid,Pe_mid为由浅层网络提取的低级特征所映射的、对人群密度分布预测的呈现,反映了早阶段下对人群概念的理解情况.其次,将Pe_mid与体现不同区域信息重要程度的人群响应图Pc进行逐像素相乘重新调整特征权重,生成早期密度估计图Pe,具体操作如公式(4)所示:
Pe=conv1512(Fe)⊗Pc
(4)
其中conv1512同样为通道数为512的1×1卷积,为像素级乘法.
使用早期分布优化损失函数Led来优化早期密度估计图Pe的分布,其由像素级欧氏距离定义,具体如公式(5)所示:
(5)
Pei为早期密度估计图上的每个像素值,gti为人群分布标签在对应位置上的真实人数,为了与预测图大小保持一致,所有参与计算的分布标签均为原标签3次下采样操作后所得.早期分布优化损失函数约束了浅层网络对人群的密度估计与实际分布之间的一致性,在关注浅层网络对关键特征的学习情况的同时,自适应地重新校准了人群响应图中对不同区域特征的响应,帮助网络更准确地锁定人群区域,并且促使由早期分布产生的梯度更多地来自于难例像素区域,以进一步减少背景误判.
对早期分布的监督能够帮助网络提升其在早期阶段对人头与背景信息的辨别力,从而将后续的参数和计算力用于进一步探寻关键特征区域以及细化修正人头点分布.同时,对浅层网络的优化同样能够提升计数网络的鲁棒性,减少人体躯干信息及复杂背景对计数的干扰,使得人群响应图中预测值更多来自于人头特征,从而减少背景区域误判对前景预测不足的补偿,进而提升网络的计数能力.
值得一提的是,相比于整个网络,早期分布优化模块只是一个很小的组成部分,只增添了极小的参数量,却明显提高了计数精度.同时,对浅层网络的监督也避免了训练过程中的梯度消失以及收敛过慢问题.
2.2.3 终期分布修正
在网络使用空洞卷积扩大感受野之后,终期分布修正模块将进一步整合高级语义信息来锁定人头位置.相比于早期阶段由低级特征产生的对人群密度的估计,终期的分布预测则来源于象征语义的高级特征,对图片中所包含的人群信息有了更深层的理解,其由终期中间特征图Ff学习而来,如公式(6)所示:
Pfmid=conv1128(conv3128(conv3256(Ff)))
(6)
其中conv1128为通道数为128的1×1卷积,conv3128和conv3256分别为通道数为128和256的3×3卷积.终期密度估计图Pf_mind展示了更深层次网络对人头特征的理解,对其进行分布一致性监督则帮助网络对图中的人群结构和分布状态有更全面和直接的把握.终期密度估计图Pf_mind还进一步强调了关键特征和人群在不同区域的密集程度,并且自主地分割了前背景区域,进一步减少了密度图中很多由背景误判产生的噪声.对终期分布的修正由公式(7)定义:
(7)
Pfmidi为终期密度估计图中的每个像素值,终期分布监督损失Lfd同样使用像素级的欧式距离来约束同分布标签之间的一致性,且其在早期分布监督的基础上进一步细化修正了人头预测的具体分布.相比于同样来自于高级特征却仅在图片和前景区域层面上由计数标签监督的人群响应图,终期密度估计图强调了单独的人的概念,其具体体现为即使是在存在严重遮挡现象、分布极其密集的区域,网络的预测范围也更加向标注点靠拢,减少了影响密度估计图中标注点四周大量的小峰值预测,且其没有忽略分散在稀疏场景下的个体,有效缓解了单张图片中由于不同区域密度跨度过大而导致的漏判现象.
同样,为了强调人群特征并抑制背景噪声,通过将终期分布密度估计图与人群响应图逐像素相乘的方式调整不同特征在最终分布中所占的比重,以得到能更好的呈现重要区域的密度估计图P,并将其作为最终反映人群分布情况的密度估计图进行后续工作,如公式(8)所示:
P=Pfmid⊗Pc
(8)
2.2.4 背景抑制
为了进一步抑制图片中复杂的背景信息对计数和密度估计的干扰,同时生成能更准确呈现人群分布的预测图,本文还对最终输出的密度估计图进行了背景误判抑制处理.
与前景专注损失函数设计思路一致,背景损失函数将在分割预测图中前背景区域的基础上锁定假阳性预测,通过惩罚非标注点区域的预测值总和来降低背景信息的响应,其具体定义如公式(9)所示:
(9)
其物理意义为密度估计图减去前景点预测后的预测值总和,其不仅包括被误判的背景预测,还包括未被标记区域人头特征对计数的响应.因此,背景损失不仅能够有效提高网络对前背景的甄别能力,还能使标注点周边区域的人头预测值集中于标注区域,使得在人群严重拥挤区域和被遮挡所影响的预测更加明朗化.
在以上四段监督中,计数层输出的人群响应图作为对原人群图片中所有特征重要性的评估将贯穿并作用于各个环节,且直接决定计数结果.其过滤了低级特征中的背景噪声,提升了早期分布监督对浅层网络的分布修正能力.此外,人群响应图还同样为终期密度估计图强调了人群区域,使得最终人群密度的呈现更加清晰明朗,尤其体现在在其所强调的密集区域.最终F2SNet的总体损失函数由公式(10)定义:
L=Lcs+Lf+Led+Lfd+Lbg
(10)
相比于堆叠卷积块来完成各个任务,F2SNet更侧重于充分利用不同阶段下不同任务所学特征本身的物理含义,其对网络计数能力以及密度估计能力的提升并没有以参数量作为代价,恰恰相反,整个F2SNet的结构相比于基础特征提取器仅增加了两个通道数为512、用于降维的1×1卷积.这体现了计数与密度估计双任务交互协作的重要性.
3 实验结果及分析
3.1 人群数据集
本文在UCF-CC-50、Shanghai Tech、UCF-QNRF以及JHU-CROWD++这4个人群数据集上进行了实验.UCF-CC-50是一个极其密集但样本量非常小的数据集,每张图片的人数从94~4543不等,平均为1280人,因此即使是最先进的模型在其上的计数结果也远非最佳.Shanghai Tech是当前最常用的人群数据集,其样本量和分辨率都相对较小.其它由1198张图片和330165个注释组成,并且根据不同的密度分布被分为Part A和Part B两部分.Shanghai Tech Part A为高密度场景图片.Part B中人群的分布则相对稀疏,因受相机视角的影响,人头的比例跨度很大.UCF-QNRF和JHU-CROWD++为近几年新公开的大规模数据集,其中所包含的数据更加丰富,同时涵盖了人群计数中更大范围的瓶颈问题.UCF-QNRF包括1535张具有挑战性的高分辨率图像和大约125万个标签,它涵盖了人群计数中更广泛的瓶颈问题,包含更多样化的场景以及视角、密度和光照变化,内容更加丰富.JHU-CROWD++则有更多的图像和更丰富的不利因素,如基于天气的退化和光照变化.有别于之前所有数据集,JHU_CROWD++给每个人头提供了一套丰富的标签,如头部位置、遮挡级别、近似边界框和其他图像级别等.这两者比之前的所有数据集均更全面、更有代表性,近年来也吸引了诸多研究者的关注.图3展示了每个数据集中颇具有代表性的测试集人群图像.

图3 来自5个人群计数数据集的代表性示例Fig.3 Representative examples from five crowd counting datasets
3.2 评价指标和实验设置
本文采用人群计数中最通用的计数评价指标平均绝对误差(Mean Absolute Error,MAE)和平均平方误差(Root Mean Square Error,RMSE)来评估不同方法间的性能,其定义如公式(11)和公式(12)所示:
(11)
(12)
本文实验均在显卡配置为NVIDIA GTX 3090下的pytorch深度学习框架下运行.使用由ImageNet[15]预训练的VGG19结构作为基础特征提取网络.对于不同数据集的训练周期均定为800代.训练期间使用权重衰减为1×10-4的Adam优化器优化模型参数.初始学习率为5×10-5,其将随着迭代自适应地进行调整.本文取验证集的最佳绝对误差结果模型用于最终测试.
为了更充分地利用已有数据进行实验,训练图像将被随机裁剪和水平翻转作为数据增强.与DM Count[16]中的设置一致,在投入网络训练之前,Shanghai Tech Part A和UCF-CC-50将被随机裁剪成256×256分辨率的子图,Shanghai Tech Part B和UCF-QNRF则被随机裁出512×512,而JHU-CROWD++的裁剪尺寸为384×384,大小不足的图像则按比例放大后再进行裁剪.
3.3 计数结果分析
将F2SNet在各个数据集上的运行结果与近两年来的优秀方法进行了比较,结果如表1和表2所示.与同样使用VGG19作为基础特征提取网络且使用点监督的Bayesian Loss和DM Count相比,F2SNet均在各个数据集上获得了更优的计数结果,这意味着在同等参数量下F2SNet要更高效,且更能适应不同场景,具有更好的泛化能力.与近几年的一些较好的方法比较,除了尺度跨度大且分布稀疏的Shanghai Tech Part B计数误差比AutoScale高一些,其余均获得更好的结果.这意味着所提的F2SNet在没有使用更复杂结构的前提下依然能拥有很好的计数能力,这也侧面体现了使用双任务交互模式监督训练对于准确计数的有效性.

表1 不同方法在Shanghai Tech和UCF-CC-50上的性能比较Table 1 Performance comparison of different methods on Shanghai Tech
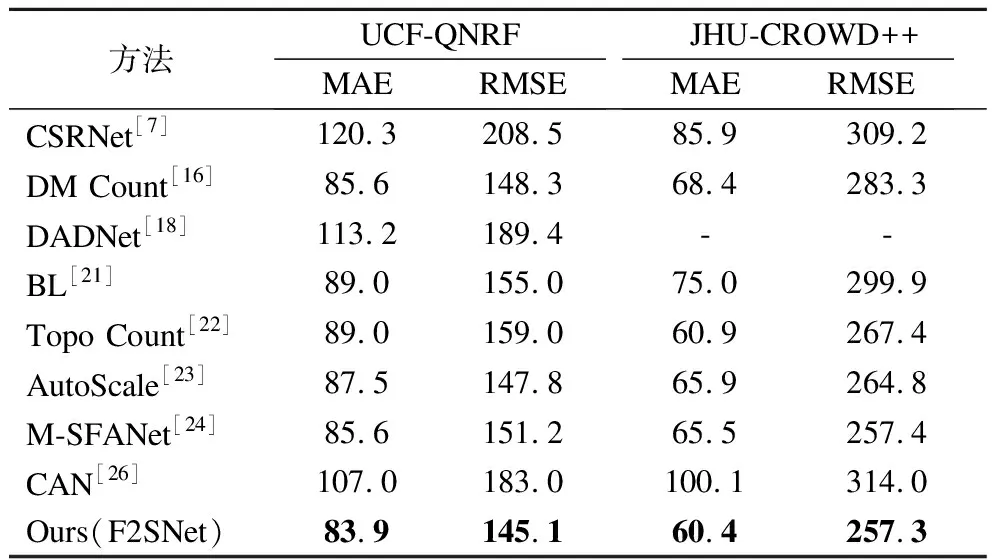
表2 不同方法在UCF-QNRF和JHU-CROWD++上的比较Table 2 Comparison of different methods on UCF-QNRF and JHU-CROWD++
3.4 密度图分析
为了验证F2SNet对于密度估计任务的有效性,在Shanghai Tech Part A上进行了密度估计图质量评估实验,其结果如表3所示.本文采用衡量图片间结构相似性的SSIM指标和反映像素点误差敏感度的PSNR指标来比较预测图与分布标签间的一致性,其值越高意味着预测图与标签越相似.由表3可见,F2SNet在两项图像质量评价指标上均获得了更好的性能,这意味着相比于其他方法,F2SNet所生成的密度估计图能够能好地拟合真实分布.
图4展示了F2SNet所生成的密度估计图的可视化结果,以显示对人群密度分布的推理.这些图像选自Shanghai Tech Part A中一些密集场景、人头尺度跨度较大的场景以及缺乏颜色信息且人群分布稀疏的场景.由于主干网络一致以及采用相同的点监督形式,将预测图与DM Count进行了比较.由图4可见,不管是在人群分布较为密集的区域还是相对稀疏的区域,F2SNet对于人头的预测均比DM Count要集中,且准确度更高.同时,由于更关注重要响应区域,因此即使是在人头特征不充分且存在严重遮挡现象的分布极度密集的区域,F2SNet也能获得更强调人头作为单目标的概念,使得预测分布更加清晰明朗.体现了F2SNet对于不同密度区域很好的适应能力.

表3 各方法在Shanghai Tech Part A上的密度估计图质量比较Table 3 Comparison of density map of different methods on Shanghai Tech Part A

图4 结果可视化Fig.4 Result visualization
3.5 复杂度分析
从表4中可以看出,与参数量较少的模型相比,F2SNet的计数准确性得到显著提高;与近几年精度较高的方法相比,

表4 不同方法空间复杂度分析Table 4 Analysis of the space overhead of different methods
在保持参数量较小的情况下,F2SNet明显取得了更好的效果.这体现了所提方法的有效性,并给出了一个很好的权衡,F2SNet有一个可比较的空间开销,同时大大改善了人群计数的准确性.
3.6 消融实验
为验证四段监督以及双任务交互训练对计数准确性和密度分布估计的有效性,在Shanghai Tech Part A上进行了一系列的消融实验.其对应实验结构设计如图5所示.首先将仅受计数标签监督所得的计数结果作为比较基准,随后依次单独验证早期分布优化模块图5(a)和终期分布细化模块图5(b)对计数及分布估计的重要性,再后验证双阶段分布监督的作用图5(c),再后验证背景抑制损失对密度估计图中不同区域预测的修缮能力图5(d),最后在计数层添加前景关注损失,来探索其对人群计数准确度及分布估计的作用图5(e).不同结构所对应的计数结果如表5所示.

图5 四段监督消融实验不同结构对应图Fig.5 Diagrams corresponding to the different structures of the four-stage supervision ablation
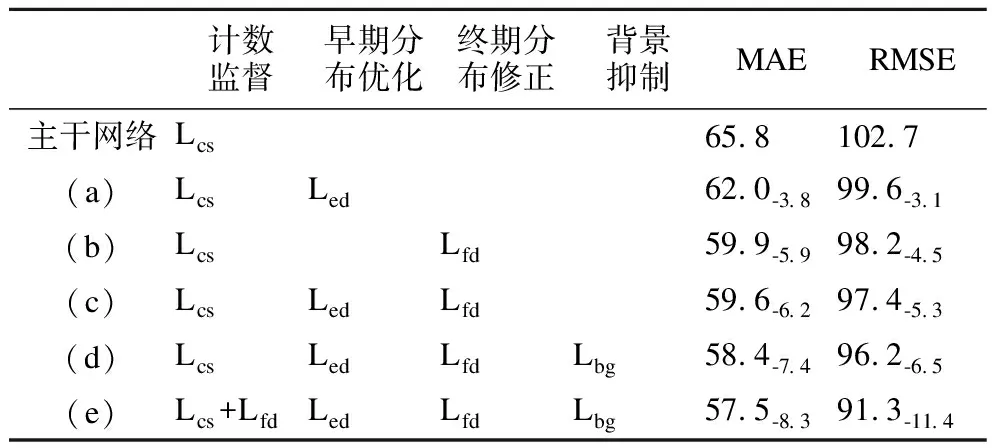
表5 四段监督消融实验Table 5 Ablation experiments of four-stage supervision
由表5可见,对每个阶段及任务的监督均能有效提升网络的计数能力,这意味着在监督不同阶段分布的同时也会调整计数层中人群响应图上的权值分布,重新评判不同特征对于计数任务的贡献度,每个结果的下标部分为相对于比较基准得到的精度提升.
为了体现其在特征提取过程中对人头特征的掌控能力以及展示其各自对前景背景的甄别能力,将各个实验各个阶段所得的密度估计图进行可视化,如图6所示,其中和分别为4段监督消融实验中不同结构下所产生的人群响应图和最终密度估计图的可视化结果,展示了训练过程中不同阶段下4段监督模块输出的密度图,分别为人群响应图、早期分布估计图、终期分布估计图以及最终输出的密度估计图.由图6可见,随着对不同阶段分布以及最终密度估计图背景关注度的提升,仅用于计数的人群响应图开始强调人头的概念,提升了标注点四周特征的响应程度,减少了大量来自上下文信息的低峰值预测,能够更好的为后续分布预测调整权重以及落点.由图6(Ⅱ)可见,在监督了不同阶段分布以及背景误判后,最终密度估计图对人群的分布情况呈现的要更加清晰明朗,尤其体现在人群密集分布区域,这体现了不同监督方式对于准确估计人群密度分布的能力.

图6 消融实验可视化Fig.6 Results of ablation study
4 结 论
本文提出了双任务交互下的四段监督人群计数网络(F2SNet),双任务交互是指计数和密度估计协同工作,在保证计数准确度的前提下,关注了人群的分布状态.四段监督分别为计数监督、早期分布优化、终期分布修正和背景抑制,其分别从计数准确度、分布一致性和背景误判三方面来监督网络训练,彼此独立工作却又相互约束.F2SNet充分利用了不同阶段下的特征语义信息,在几乎不增加参数量的情况下大幅提高了计数精度,并生成了更高质量的密度估计图,尤其改善了极度密集区域的预测情况.实验结果验证了所提方法的有效性,并取得了与当前先进方法相比更具竞争力的结果.此外,实验效果表明本文所提方法可以应对各种复杂场景,并且包含更小的参数量,因此可以考虑将来部署到街道人群聚集区域或商场的人群密度监控等场景中.下一步,则考虑通过调整网络对前背景预测的关注度来进一步缓解背景误判,同时将考虑每个人头的尺度大小并使用回归框对其进行定位.
