复杂信息环境下多源数据情报价值发现研究*
2023-10-18鞠孜涵白如江冯梦莹张亚辉辛晓梦
鞠孜涵 白如江 冯梦莹 张亚辉 辛晓梦
(1.山东理工大学信息管理研究院 山东淄博 255049)
随着大数据、人工智能的迅猛发展,支撑科技情报决策的数据环境正发生着翻天覆地的变化。数据的来源、类型、规模、结构、质量等也由于信息技术的更新迭代发生重大变化,复杂信息环境下多源数据呈现相对“不稳定状态”[1]。地球上每天约产生5 亿条推文、400 万GB 的Facebook 数据[2]。诸如此类的多源异构数据为情报研究提供了丰富的数据资源,为情报工作转型带来了新契机,但也使得情报工作陷入了“信息泥潭”“数据焦虑”中。
复杂信息环境下,多源数据的内容涵盖了政策、报告、规划等,动态演变强,呈现出规模庞大、结构异构、语义复杂、数据不完备、粒度各异等特点[3]。在这些良莠不齐的多源数据网络中,究竟有多少是情报任务需要的信息,如何及时有效地发现多源数据的情报价值,迫切需要有一个完整的情报价值发现体系去支撑和指导实践。从而帮助情报人员从海量的数据中快速且准确地甄别出有情报价值的内容,使情报工作在这个数据、信息过剩的复杂环境中,更加精准化、智能化的发展,发挥多源数据对情报决策支持的重大效果。
1 情报价值发现研究综述
“价值”是指能满足人类某种需要的属性,而“情报价值”是指情报所具有的对人有用的属性[4],即情报的获取者接收该情报后,帮助其达到某一具体目标的有用性,是情报客观属性与用户需求的耦合。对于情报价值发现来说,多源数据的客观属性与用户的情报需求,二者缺一不可。在情报价值计算方面,由于情报在加工过程中投入的人力、物力等不能简单分割,而且情报的利用具有一定的特殊性,并不方便计量,因此对于情报价值的判断逐渐成为学界研究的焦点。
早期的情报价值发现研究以定性评价多源数据的外部特征指标为主。1991 年,Richmond 提出了最早的关于多源网络信息情报价值评价的“10C 原则”,包括了内容(content)、可信度(credibility)、连续性(continuity)等10 个定性指标[5]。1997 年,佐治亚大学的Oliver 等针对网络数据的质量问题,提出了经典的“OASIS 评价体系”,包括客观性(objective)、准确性(accurate)、数据来源(source)、信息量(information content)、范围(range)5 个指标[6]。在后续的研究中,各种不同的定性指标也被陆续提出,如数据的格式、时效性、原创性、全面性等[7]。
随着评价角度的不断完善,研究者开始更加注重指标体系构建的科学性与完备性。北约组织针对网络开源情报,提出了准确性、权威性、时效性、客观性和关联性5 个方面的评价体系。邹婧雅等结合上述方法,构建了国际智库开源情报的评价体系,从数据源和数据内容两个角度构建评价体系,包括了数据的真实性、完整性、时效性、预测性、实践性、反情报性、可理解性和可回溯性8 个要素[8]。情报价值的定性评价方法已经趋于成熟,能从多种视角对评价对象进行相对全面和细致的分析,但是其主观性强,分析结果的科学性和说服力有待提高,并且不能满足自动化评价的需求。
定量的情报价值评估方法通过数量统计分析等,能有效排除一些主观因素,使得评价结果更具可信度,是多源数据情报价值发现的重要发展方向。早在1996 年“链接(sitation)”[9]一词被首次提出,用来描述网站之间相互链接的行为,就为后续的定量评价提供了思想指导。基于网络链接分析的方法也在实践中取得了巨大成功,如Page 等提出的PageRank算法[10],作为主流的网页重要性排序方法,也被拓展到数据的情报价值评估研究中。后续,D-S 证据理论、AHP 层次分析法、Bayesian 网络和模糊评价等也被应用于数据的情报价值评估[11]。但是定量评价方法只能通过数量统计结果进行通用性的评价,无法对多源数据进行深层次的利用。
由于定性和定量评价方法都有各自的局限性,所以出现了将二者结合起来的综合性评价方法,评价的角度也从数据外部特征深入到文本内容维度,从而达到相对完整的评价结果。在具体实践中,中科院文献情报中心发布的《情报重要度的指标体系和计算方法》[12]报告中提出了情报类型、情报来源、情报主题、主题相关度和科技相关度5 个一级指标,并细化成31 个二级指标,率先将情报外部特征深入到文本内容维度,为相关研究提供了良好的借鉴。曾文等构建了科技前沿领域的开源数据质量评价体系[13]。
在近几年的研究中,以用户情报需求导向的评价指标构建研究逐步增加。如王晰巍等基于信息生态视角,发现不同用户的群体特征对于多源数据利用 价 值 的 评 判 具 有 较 大 影 响[14]。Vatani 和Shiri 聚焦数据内容的词特征,通过构建用户兴趣模型关联数据内容与用户偏好,实现了具有较高情报价值的数据过滤与筛选[15]。不难发现,情报用户的需求始终是情报工作的核心,对多源数据进行情报价值发现,最终目的也是为了服务用户(见图1)。
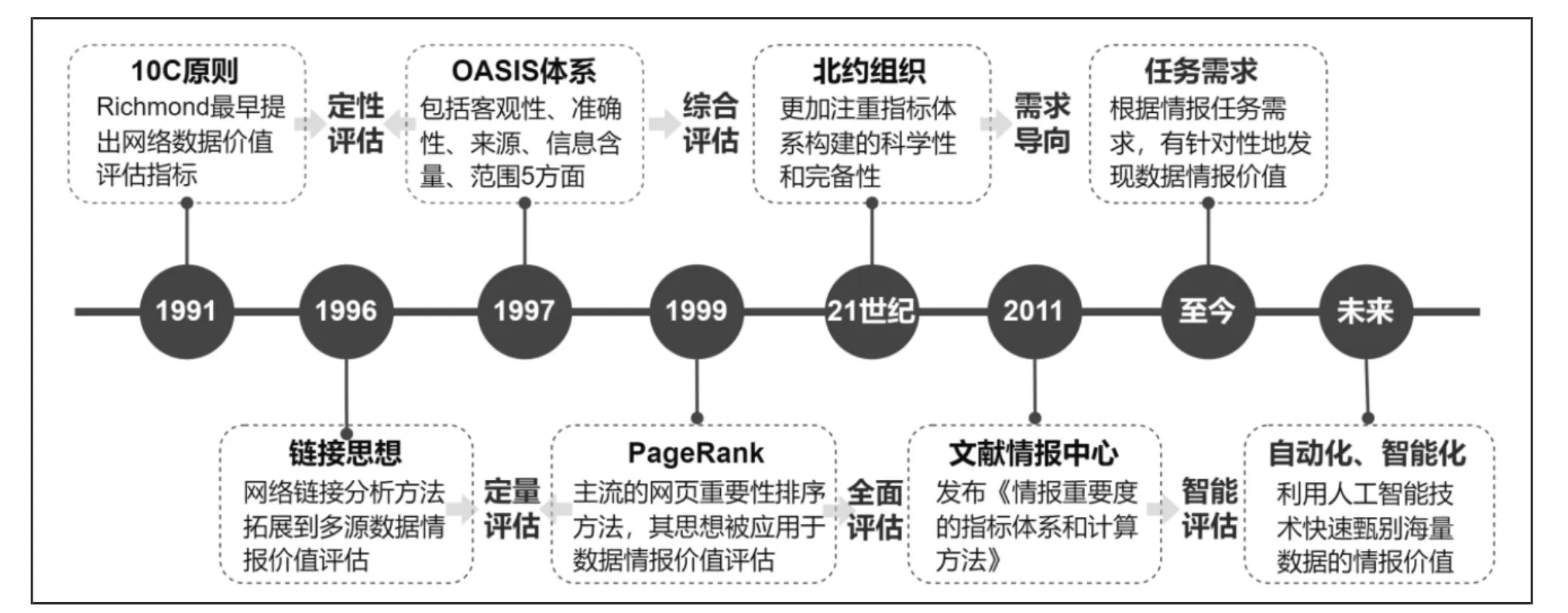
图1 多源数据情报价值发现重要研究节点
总体而言,国内外学者已经从定性评估、定量评估和综合评估3 个方面,展开了大量多源数据情报价值问题的研究。但仍存在以下问题:(1)定量化的情报价值计算方法,计算成本高、耗时长,复杂信息环境下迫切需要能支持更大数据规模、更快计算速度的情报价值发现方法;(2)价值评估维度单一,现有研究以考虑数据外部特征或内容特征等某一方面为主,分析结果片面,面对“不稳定”的信息环境需要全面评估而非单一维度;(3)复杂信息环境下数据焦虑、信息迷雾等困扰严重,现有方法对数据语义内容的挖掘程度不足,需要更加细粒度的价值发现方法;(4)用户需求不断提升,事实型、泛在化的情报服务难以满足需求,这也要求情报价值发现需要充分考虑情报需求,由表及里,提供精准情报价值发现。
综上,未来多源数据情报价值发现工作不但要关注数据的外部基础特征,而且要利用计算机技术对多源数据的内容特征进行深层次语义解析,并结合情报需求综合发现多源数据的情报价值已成为共识。因此,如何在复杂信息环境下,利用深度学习等技术,从数据的外部特征、内容特征和情报需求3 个方面快速甄别有情报价值的内容,实现精准化情报价值发现是目前面临的最突出问题。
2 复杂信息环境下多源数据情报价值发现的新要求
赵志耘指出,当前科技情报复杂信息环境的现实条件,使情报研究发生了前所未有的影响和变化[16]。“信息环境”是指科技情报工作在发展和演进过程中的信息条件[17],而“复杂信息环境”特指科技情报产品的生产环境,包括“外部”环境和“内部”环境两个方面[18]。“外部”环境是指外部环境日趋复杂,不确定显著增加,科技情报信息源呈复杂性;“内部”环境指情报产品生产所处的环境,也就是数据的来源、类型、规模等发生着翻天覆地的变化,数据内容更为复杂[16]。与此同时,人工智能技术以海量的数据支持、不断改进的核心算法和不断突破的计算速度,深刻变革科技情报感知、融合、分析与服务的模式[19]。BERT、ChatGPT 等新技术方法的突破,表明一代又一代的AI 技术突飞猛进,情报领域更不能浅尝辄止,复杂信息环境也为多源数据情报价值发现提出了新要求、新挑战。
2.1 数据海量异构:需要更快的感知响应能力
复杂信息环境下,单源数据往往呈现出碎片化、线索化的特征,无法提供完整的情报地图。只有通过多源数据间的相互支持、补充和校对,才能提供更加准确、全面和及时的信息支撑情报工作。此外,多源数据来自不同载体、不同渠道的数据体量大、更新快、种类多。面对海量的数据集合,需要更快的感知响应能力,提高情报工作的效率,数据的分析规模和处理效率大幅提高,海量数据的处理迎来“AI-first”突破。
复杂信息环境的不确定性,可能导致高价值情报数据稍纵即逝,需要利用先进的计算机技术快速感知、及时跟踪、全面掌握数据情况。不仅如此,复杂环境也为多源数据获取的深度和广度提供了极大帮助,情报数据分析不再受限于某一领域,要求情报价值发现工作运用数智技术,开展多维度研判。AI 技术的应用极大地节省了时间和人力成本,随着情报任务和问题呈现出实时化、复杂化、多维化等特点,过去依赖局部特征、传统工具、人工为主的多源数据情报价值挖掘方式必将跌落鸿沟。如何将海量异构的多源数据整合增益,提高情报价值发现的效率和准确率,成为新时代情报发展的关键。
2.2 数据价值稀疏:需要更细粒度的挖掘能力
复杂信息环境下,数据来源五花八门,科技博弈诱发的数据“迷雾”特征日益凸显,多源数据的情报价值稀疏,导致高质量情报极有可能被淹没在数据海洋中,迫切需要更细粒度、更智能化的情报挖掘能力来确保情报产品的质量。传统科技文献数据的组织方式往往以题目、摘要、关键词等外部信息组织为主,较少深入到文献内容层面。当前,情报分析方法由手工作坊转向大规模、细粒度智能分析,类ChatGPT 人工智能技术已具有自动综述、观点提炼等潜在能力,为情报分析提供了智能化工具的同时,提高了情报价值挖掘的准确性,更容易发现数据中隐藏的规律。如在下一代移动通信领域,如果只使用粗粒度数据分析,可能只能得到一些常规的技术发展趋势,如5G 商用化、6G 研发启动;但如果进行细粒度内容分析,就能挖掘出更多精尖技术、前沿技术,如太赫兹技术、大规模MIMO 技术等。
当然细粒度的数据挖掘也存在一些挑战,如需要更复杂的算法、更精确的数据采集和处理,但随着计算机技术的不断发展,使得从海量数据中精准挖掘细粒度知识对象的能力逐步提升,以研究问题、方法、步骤等深入到文献内容层面的内容组织成为可能,为细粒度的情报价值发现提供了可能。
2.3 情报需求提升:需要更精细化的研判能力
复杂信息环境,用户的需求也日渐宽泛,数据规模不断扩大,技术方法持续更新,情报任务日渐复杂,对多源数据情报价值的辨析需求相比于过去更为突出,情报需求更多时候由显在转为了潜在,由宏观转向了微观,并不断细化。宏观层面的情报需求,一般具有框架性、战略性、全局性的特点,通常是在制定战略定位时所需的需求。这类需求往往不需要经常去求证,可以根据情报用户大致判断,或放眼世界来判断可能会有什么样的情报需求。而微观情报需求大多是需要探明的需求,如一个具体研究问题折射出的情报需求,有关某一技术成熟度的情报需求等。
但不管数据环境和情报需求如何变化,情报工作“耳目、尖兵、参谋”的宗旨始终没有改变。及时、准确、全面地捕捉最新、最快的情报需求动态,更精细化的分析隐藏在数据背后的规律与趋势、内容与价值,提供精准情报支持,对于把握最新研究进展等情报工作具有重要意义。
2.4 信息环境复杂:需要更智能化的分析能力
“信息环境”日趋复杂,驱动了情报工作在数据获取手段、获取方式、处理技术等方面的深刻变革,仅仅依靠人力分析的做法已不能履行情报工作的使命。随着深度学习的出现,泛智能化是大势所趋,人工智能技术的应用对提高复杂信息环境下科技情报“线索发现”能力具有重要作用,为多源数据的自动化全面搜集、精准过滤和深度分析研判提供了新的机遇和可能。
复杂信息环境下科技情报工作的对象多元化、特征复杂化,数据领域也从传统的科技文献数据拓展至几乎所有的领域,信息环境转向开放,迫切需要弥补可用数据资源与紧迫情报需求之间的差距,更智能化发现多源数据的情报价值。如中科院自动化研究所的王飞跃团队提出基于ACP 的开源情报分析框架,构建了面向开源数据的科技监测与协作创新平台[20]。清华大学唐杰团队建立了新一代科技情报大数据挖掘与服务平台AMiner,以科研人员、科技文献和学术活动三类数据为基础,对异构科技情报网络进行深度挖掘,提供语义搜索、语义分析等服务,被称为科研搜索“神器”[21]。能够满足用户精准定位、实时分析的智能情报分析数据库越来越多,驱动情报工作者开始运用更智能化的方法从纷繁复杂的数据中发现情报价值。
2.5 对于提出复杂环境下的多源数据情报价值发现的思考
可以看出,相比于传统信息环境,复杂信息环境下给多源数据的情报价值发现带来的影响包括更强更快的处理力、更细粒度的挖掘力、更精细化的分析力和更智能化的发现力等。情报数据环境的变化也决定了情报研究必须重视对数据情报价值的挖掘,过去普遍认为只有人类才能实现的任务,正在一个个地由机器实现,“人类+AI”的组合既优于纯人类也优于纯计算机,将复杂信息环境与多源数据情报价值发现结合到一起进行研究,主要有以下思考:
(1)前瞻定位。复杂信息环境下,科技情报工作面临着需求、视角、模式等的变化,支撑情报研究的数据资源呈现出海量、多源、异构的特征。基于海量数据开展的情报研究越来越受到重视,做好多源数据的情报价值发现具有战略必要性。但是,传统的研究方法难以在大规模数据的基础上保证情报研究的质量,美国情报分析之父Sherman Kent 也曾指出:如果要进行情报工作,必须要对情报资料进行评判,才能得出相应的假设,如果情报资料是劣质的,那得到的情报图景也一定是不合格的[22]。所以在多源数据情报价值发现中考虑复杂的信息环境,把情报价值发现从传统认知范式里分解出来,更高效的开展情报工作是未来研究的重要方向。
(2)任务驱动。目前针对多源数据情报价值的分析方法通常根据数据的外部特征构建指标体系,从而发现情报价值。如来自官方媒体的数据要比来自个人社交媒体的数据更具有价值。但是,这种方法并没有对数据的语义内容进行深入探究,在对从多源数据中精确挖掘细粒度知识对象的要求不断提高的今天,显然是不够的。针对这个问题,充分考虑复杂信息环境下数据价值稀疏特征,着眼于数据内容层面,在外部特征的基础上增加文本语义内容维度,同时考虑情报任务需求,可以确保情报工作更加稳定、高效、准确地进行。
总体来看,面对复杂的信息环境以及海量、多源、异构的数据,如何高效地发现和挖掘符合需求的有效数据,实现数据价值的增值,成为情报研究面临的重要问题。本文就如何基于复杂信息环境进行多源数据情报价值发现进行可行性分析,希望在守正继承传统研究范式的基础上,拓展以深度学习等新技术支撑的多源数据情报价值自动发现,推动情报工作更加智能、高效地发展。
3 多源数据情报价值发现体系构建
多源数据情报价值发现的目的是为情报用户的决策提供支持,因此对于情报价值的判断通常是由情报用户使用后的效果来决定的,使用效果越好则情报价值越高。这种情报价值的判断方式虽有其客观性,但并不全面,因为在数据感知泛化的时代背景下,情报的准确性是相对的,情报的不确定性才是其客观属性。由此可见,对多源数据的情报价值判断,一方面要体现数据的基本性能,另一方面要考虑数据的内容语义特征,同时还要兼顾数据对于情报需求的参考作用。
综合上述三方面的考虑,本文提出多源数据情报价值发现研究思路,从良莠不齐的海量数据中,发现情报线索,针对情报需求,确定其情报价值。整体分为四个部分:首先,构建多源数据空间,获取多源异构的海量数据,初步筛选去除冗余;其次,选择定性与定量结合的方法对多源数据的外部基本特征(权威性、时效性、关注度等)进行情报价值的挖掘与计算;再次,充分利用BERT 模型Transformer 架构,对多源数据的内容特征进行深层次的语义解析;最后,根据情报任务的具体需求,结合情报线索的揭示,对多源数据进行指向性的价值发现,最终达到发现高价值数据的目的(见图2)。
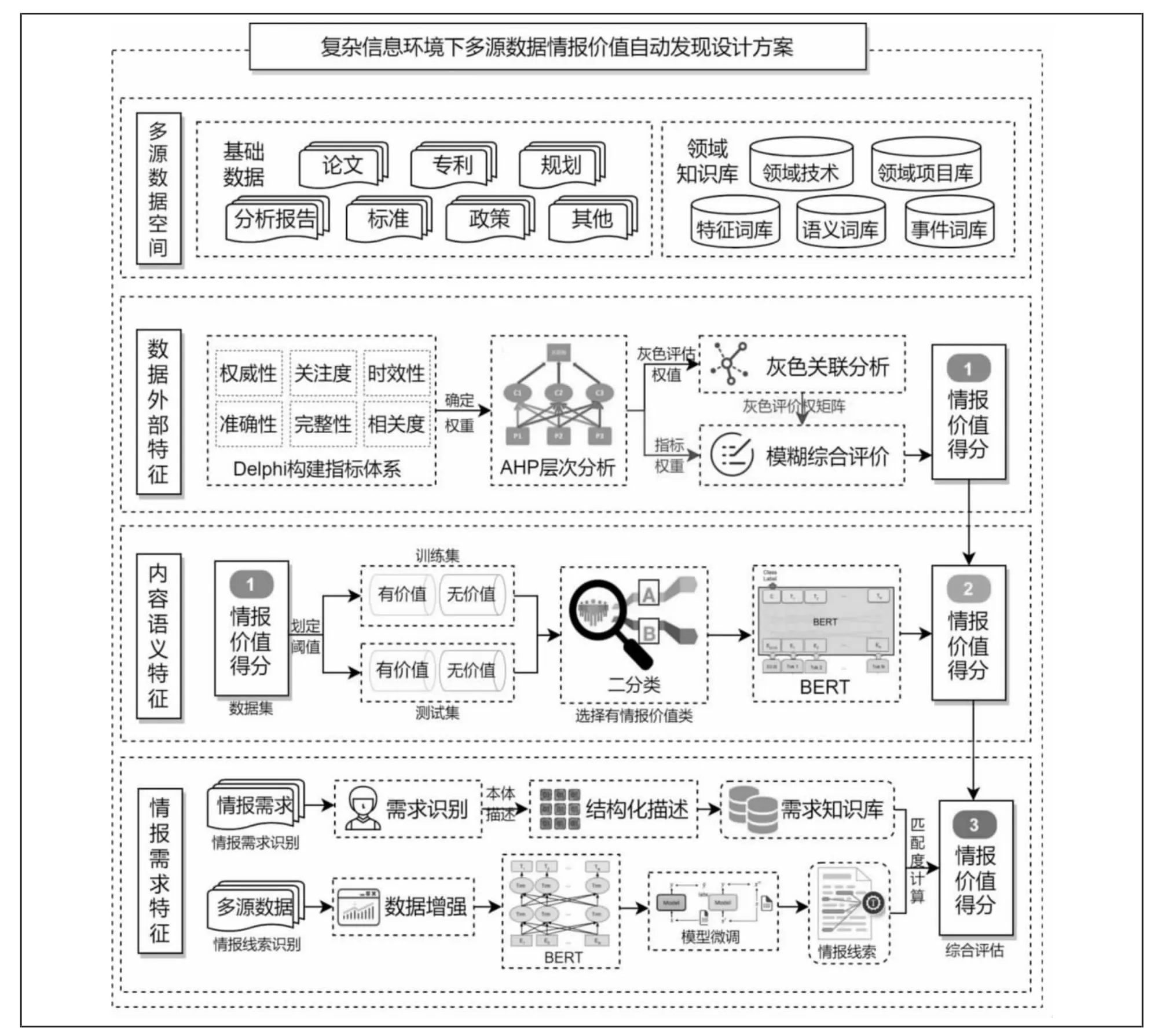
图2 复杂信息环境下多源数据情报价值发现设计方案
3.1 构建多源数据空间
大数据时代下,情报“耳目、尖兵、参谋”的作用越来越得到各方关注,科技情报的工作过程需要广泛并且可靠的数据作为支撑。在这个信息互联互通的背景下,数据的获取途径越来越多,获取方式更加多样,过去以单源数据为主的情报工作方式转向多源数据综合利用,但在杂乱无章的各类数据中构建高质量的多源数据空间仍是情报工作的重要准备环节。
从多源数据空间的组成来看,主要包括两方面的数据:一类是以篇章为基本单元的基础资源类数据,如论文、规划、专利、标准、分析报告等;另一类是领域知识库,涵盖相关领域项目、技术、特征等各类情报对象的基本情况。由于多源数据的情报价值判断有着非常细致的要求,如对通信领域重要的多源数据,对于其他领域的研究来说可能就没有那么重要,因此领域知识库的建立对于提高情报价值判断精确度会有所帮助。
在多源数据空间构建过程中,由于这些数据源异构性强、冗余度高,所以为了高效进行后续的情报价值发现,需要对搜集到的数据进行初步筛选,去除冗余信息,解决数据积累的过程中,数据重复、冲突和不一致的问题。同时,多源异构的数据会引起数据空间管理的混乱,如多源载体中针对同一对象有不同的表述方法,直接影响了数据的价值发现,甚至导致错误的情报决策。因此,需要构建结构化的多源数据表示方法,解决其异构性带来的问题,并基于情报任务对应的领域知识结构化、精细化的描述多源数据,继而计算相似度,将情报的重复和冲突程度量化,最终通过分析相似度来衡量数据价值。
快节奏时代的多源数据空间并不是一成不变的,每天都有海量的数据扑面而来,数据更新速度远超我们想象,所以多源数据空间一定是一个动态变化的,可以实时更新的同步数据集。此外,在数据获取和更新过程中,要重点关注几点:(1)多源数据质量的把握,着力解决好数据的获取途径和方式的问题;(2)获取基本数据类型的同时,兼顾领域数据,构建好知识组织体系(见图3)。
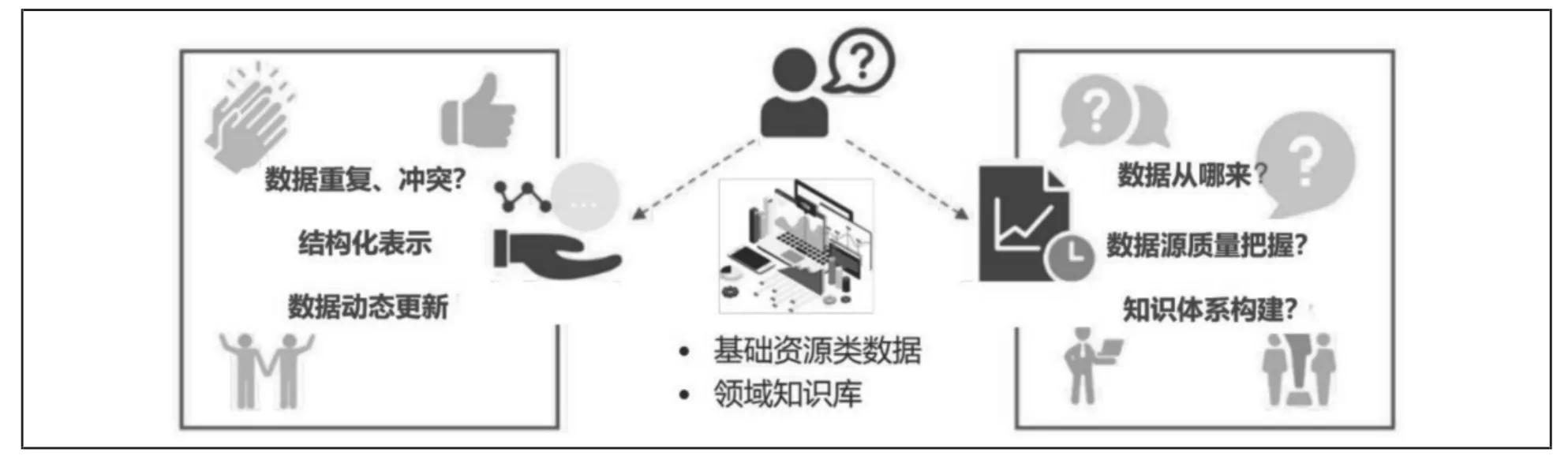
图3 多源数据空间构建重点关注的问题
3.2 基于数据外部特征的情报价值发现
多源数据的外部特征是指数据自身所具备的基本特征,主要是从数据的外在属性入手,并不涉及数据的具体内容,对数据的情报价值进行挖掘与计算。由于数据的基本特征直接影响了后续数据分析的可接受度和易挖掘性,所以一个或一类数据的基础特征评分越高,其研究价值也就越高。因此多源数据的外部特征是情报价值发现中必不可少的因素。
结合现有研究与科技情报工作的特点,本文选择多源数据的权威性、关注度、时效性、准确性、完整性和相关度6 个二级评价指标(见表1),提出DAGF算法充分考虑情报价值评估过程中的模糊、复杂、难以量化的因素,将定性与定量分析综合,得出量化的情报价值。如权威性是指数据来源对象或机构的权威性,多源数据来自科技管理机构、政府部门、国际组织、新闻网站等复杂渠道,来源机构的权威性越高,数据权威性越高,其数据价值也在一定程度上提高,如来自政府官网的数据要比自媒体平台的数据更权威;关注度是指数据所受关注的程度,关注度越高,数据传播越广泛,则更容易被发掘,数据价值也就越高。
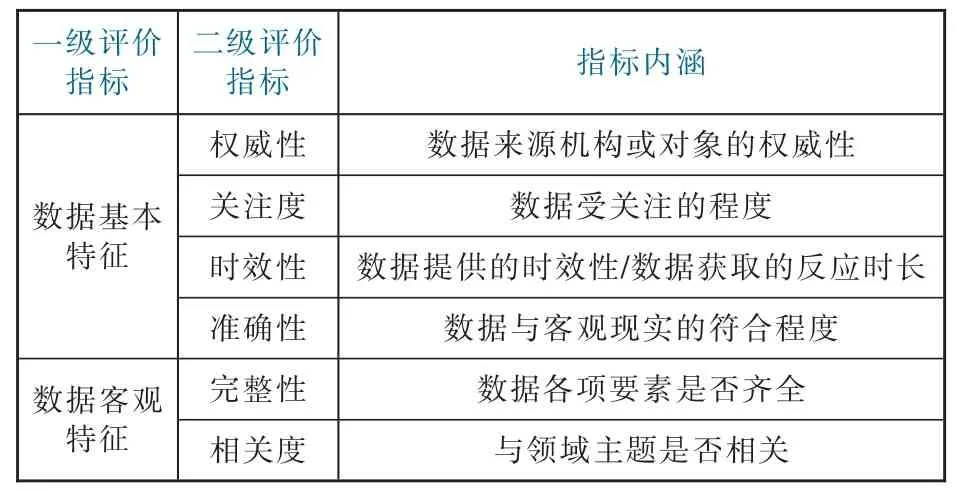
表1 数据情报价值评估指标
具体来说,DAGF 算法是由德尔菲法(Delphi method)、层次分析法(Analytic hierarchy process)、灰色关联分析(Grey correlation analysis)和模糊评价法(Fuzzy evaluation)集成的评价方法。首先,利用德尔菲法匿名函询、多轮反馈等优点,建立上述指标评价体系;其次,利用层次分析法系统性分析,构造判断矩阵并计算各指标的权重,并计算得到6 个二级指标在指标体系中的权重;第三,利用灰色关联分析操作简单、不需要经典分布规律,且计算量小的优势,依次确定评价量样本矩阵、评价等级集合、各等级的灰数和白化权函数、灰色统计数,最终确定灰色评估权值和权矩阵;最后,利用模糊综合评价矩阵,综合上述指标权重和灰色评价权矩阵,计算该数据的情报价值得分,依据得分对数据进行过滤,支持后续精细化的情报研究(见图4)。
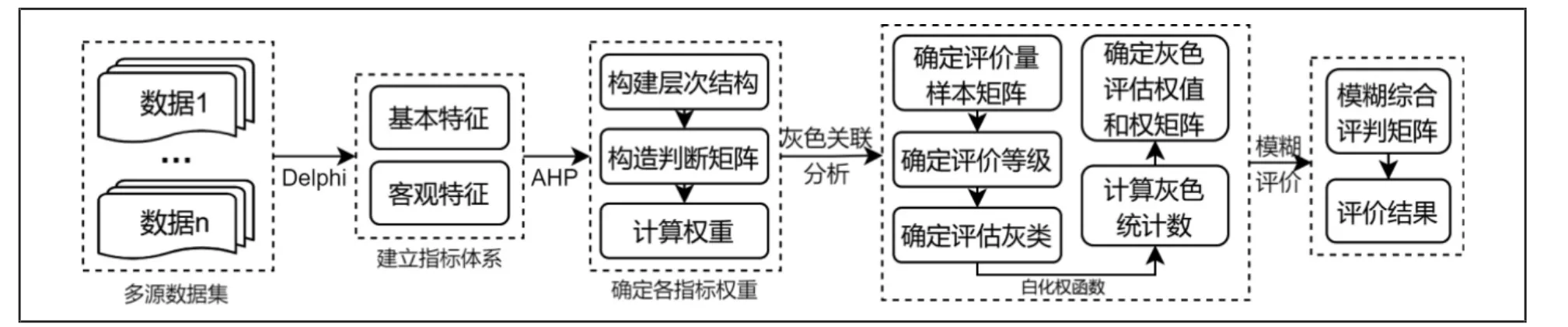
图4 基于数据外部特征的情报价值发现流程
将DAGF 算法引入多源数据情报价值发现研究,在一定程度上对多源数据进行了客观地评价,适用于情报数据要求低、情报需求简化的任务场景,但是由于情报价值判断是一个复杂的过程,在细粒度情报数据感知背景下,还应在实践中结合多源数据内容语义特征进行深度分析。
3.3 融合内容语义特征的情报价值发现
多源数据的内容特征主要是从数据内容的角度出发,对数据的情报价值进行计算与挖掘。对于数据来源,究其根源还是其内容是否完整,即数据的完备性,是否满足情报用户对内容领域的需求。如果需要研究的是“苹果”,而提供的资料却是很多关于“梨”的数据,即便基础特征再好,数据的情报价值也会大打折扣,所以基于内容语义特征的多源数据价值发现模块必不可少。
随着人工智能技术的发展,基于数据内容特征的语义挖掘方法逐渐成熟。本文基于BERT(Bidirectional Encoder Representations from Transformers)大规模无监督预训练模型以及其Transformer 架构,由于BERT 预训练模型不仅可以使下游模型性能大幅提升,且使Transformer 信息提取能力增强,是一种超强的特征抽取器,能对文本语义和句法特征有效建模,因此构建基于文本内容语义特征的情报价值发现模型,对多源数据的语义内容特征进行情报价值计算,并结合前文所述的数据外部特征情报价值评估结果,得出综合的情报价值计算结果。
由于标注语料集是不可或缺的一部分,但是人工标注情报价值费时费力,借鉴张敏等[23]提出的情报价值计算模型思路,利用多源数据情报价值外部特征得分自动构建训练集,采用二分类任务模型输出有无情报价值的结果,并通过预测有情报价值类别的置信度来得到该数据情报价值的评分,最后综合外部特征得分计算出最终的情报价值。
在模型构建过程中,充分发挥BERT 模型Transformer 架构的优势,并将情报的外部资源特征融入到模型中辅助决策。在基于数据内容语义特征的情报价值计算模型中,文本的向量化是重要环节之一,将文本映射到高维向量空间,获取字的表示。具体来说,先将文本分词、标记化,通过WordPiece 分词,将单词分解成词片段,并赋予不同的embedding 向量,位置嵌入表示词在文本的相对位置信息后进行分段嵌入,对输入的文本序列进行多层的encoding,得到多个带有语义信息的向量以及最终的文本向量表示。所得结果中的有情报价值类的预测得分即为基于内容语义特征的多源数据情报价值评分。最后结合前文数据外部特征的情报价值得分,得出综合的情报价值。
3.4 基于情报需求模型的情报价值发现
情报工作始终是由需求驱动的,正如情报学家包昌火所说“需求是情报的第一驱动力”,美国情报学家Herring 也认为情报工作的首要任务就是识别用户的情报需求[24]。因此,多源数据是否符合目标用户的情报需求直接决定了数据的价值,由于不同用户的情报需求差异性大,识别不同用户的情报需求和多源数据中的情报线索,成为了开展情报价值发现的重要环节。
部分学者尝试从数据驱动的角度获取情报需求,邹益民和张智雄提出了基于对象计算的情报价值判断方法[25],吕宏玉杨建林基于模板识别国家战略情报需求[26],Levashova 等通过情报需求建模,分析情报需求与数据价值[27]。借鉴现有研究中的情报需求关注模型,结合情报价值自动发现的任务,本文设计的多源数据情报价值发现模型主要包括三部分:一是情报需求识别,结构化描述情报需求和领域先验知识;二是情报线索识别,深层次揭示多源数据中蕴含的情报线索;三是情报需求与情报线索进行匹配度计算,判断多源数据情报价值(见图5)。
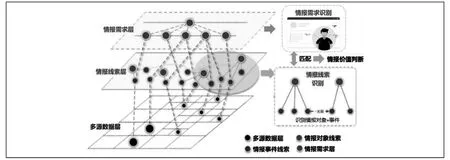
图5 基于情报需求模型的情报价值发现过程
3.4.1 情报需求识别
情报需求识别模型的主旨任务是将情报需求转为计算机可读、可计算的知识,也就是结构化、模型化的描述情报主体的任务需求。本文认为情报需求识别模型,还应该关注领域先验知识,考虑情报对象的特殊性,更加精细化的描述情报需求。
情报任务的差异性,导致了情报人员对各类多源数据的关注点大不相同,因此在结构化描述情报需求的过程中,必须考虑情报对象及行为的特殊性。如科研攻关团队更倾向于关注重大战略报告、技术白皮书、重要成果发布报告等,而对于企业团队则更加关注政策措施、投资预算等相关信息。不同的情报对象具有鲜明的特殊性,这也使得在情报需求识别中引入领域先验知识和精细化需求分析具有必要性。
首先,情报需求识别模型是用户情报需求、领域需求分析和领域知识描述的共同语言,是实现领域先验知识“启发”用户情报需求的关键;其次,对情报需求进行识别和分析,获取领域需求知识,常用的分析方法有专家知识分析法和大数据分析法;最后,通过本体描述情报需求,并构建情报需求知识库。值得注意的是,在情报需求的描述过程中,情报对象的行为强度影响了情报需求的识别准确率,如果情报对象中包含了“革命性地”“首次”“率先”等词修饰,则该数据更具备情报价值。
3.4.2 情报线索识别
多源数据中蕴含着与情报发生相关的地点、时间、任务、机构、人物、缘由等情报元素,然而这些元素结构分散、相关关系难以确定,造成了情报价值判断的困难。情报线索识别是对多源数据中蕴含的重要情报线索进行揭示,基于数据增强的BERT 预训练模型等,完成主体内容识别、情报元素抽取、对象行为抽取等处理过程,将多源数据中蕴含的情报发生时间、地点等不同语义角色信息、语篇结构特征等抽取出来,并映射成对象网络,将其转化为可计算的知识单元。
情报线索的主体是语篇中的情报对象,语篇对象及其行为直接影响了情报元素抽取的准确性和情报线索匹配的效率。通常情况下,多源数据篇章中的主体对象往往出现在开始部分,或贯穿整个篇章频繁出现。一方面,通过情报对象的分布规律可以辅助情报线索的识别;另一方面,情报对象的出现频次也可以作为定量指标来计算该对象行为情报元素的价值。
由情报线索也就是对象及其行为组成的语义结构图,能够更加清晰和直观地反映出多源数据所蕴含的情报信息,能够很好地联系并揭示散落在资源中的情报线索,为情报价值的判断提供坚实的语义模型支撑。更重要的是这种多源数据情报线索的揭示方式与前文所述的情报需求识别模型是一致的,都是在考虑情报对象及行为的基础上,进行线索的发现与揭示,为多源数据的价值发现奠定基础。
此外,当前数据与信息环境呈现复杂性,不同于传统科技数据呈现的相对稳定状态,复杂信息环境下的科技数据并不稳定,在获取更便捷、来源更丰富,带来新契机的同时,“科技信息迷雾”的困扰不容忽视[1]。由于“信息迷雾”的成因更为复杂,给情报线索的识别带来极大干扰,未来研究中能够准确感知、刻画和表达“情报线索”的方法和技术至关重要。
3.4.3 情报价值判断
在上述过程中,情报需求识别模型对基于领域先验知识的情报需求进行了结构化描述,情报线索识别对多源数据中散落的情报元素进行了揭示,两者分别立足于需求与数据视角,还需要对二者进行相似度计算,完成情报价值的判断。由于二者均考虑了情报用户及其行为,所以本质是是对用户行为模式的匹配,从相似度的视角将情报需求与情报线索的冲突和冲突量化,最终以相似度度量值来表示情报价值。具体来说,通过领域先验知识、行为强度修饰词等对情报线索进行数据增强,使得重要情报线索更加突出,再将情报用户需求与情报线索进行相似度计算,并将计算结果归一化和标准化。引用分级评价思想,将计算结果分段表示,如星级划分,使计算结果更容易理解和接受。
4 结语
复杂信息环境打破了传统情报价值评估的工作模式,将具有新时代特色的情报价值发现思路引入大众视野范围内,为科研人员及时发现高价值的情报信息带来了新机遇。本文提出了复杂信息环境下多源数据情报价值发现新思路,并分别设计了基于数据外部特征、融合内容语义特征和基于情报需求模型的情报价值发现过程。多源数据情报价值发现既要遵循一般情报源的规律,也要因具体领域的变化而适当调整,根据情报分析需求从不同的粒度进行多源数据情报价值挖掘是关键一步,关注情报用户及其行为是核心思想,基于深度学习模型实现情报价值自动化发现是大势所趋。在未来研究中,面对复杂数据环境,抢抓新一代信息技术发展机遇,加强多源数据情报价值发现在数据分析规模、挖掘粒度、情报需求匹配等方面的智能化建设,更准确地感知、刻画和表达多源数据情报价值的方法将引起广泛关注。
