逐层Transformer在类别不均衡数据的应用
2023-10-17杨晶东李熠伟江彪姜泉韩曼宋梦歌
杨晶东 李熠伟 江彪 姜泉 韩曼 宋梦歌

摘 要:為解决临床医学量表数据类别不均衡容易对模型产生影响,以及在处理量表数据任务时深度学习框架性能难以媲美传统机器学习方法问题,提出了一种基于级联欠采样的Transformer网络模型(layer by layer Transformer, LLT)。LLT通过级联欠采样方法对多数类数据逐层删减,实现数据类别平衡,降低数据类别不均衡对分类器的影响,并利用注意力机制对输入数据的特征进行相关性评估实现特征选择,细化特征提取能力,改善模型性能。采用类风湿关节炎(RA)数据作为测试样本,实验证明,在不改变样本分布的情况下,提出的级联欠采样方法对少数类别的识别率增加了6.1%,与常用的NEARMISS和ADASYN相比,分别高出1.4%和10.4%;LLT在RA量表数据的准确率和F1-score指标上达到了72.6%和71.5%,AUC值为0.89,mAP值为0.79,性能超过目前RF、XGBoost和GBDT等主流量表数据分类模型。最后对模型过程进行可视化,分析了影响RA的特征,对RA临床诊断具有较好的指导意义。
关键词:量表数据分类; 类别不均衡; 级联欠采样; Transformer
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2023)10-025-3047-06
doi:10.19734/j.issn.1001-3695.2023.01.0056
Application of layer by layer Transformer in class-imbalanced data
Yang Jingdong1, Li Yiwei1, Jiang Biao1, Jiang Quan2, Han Man2, Song Mengge2
(1.School of Optical-Electrical & Computer Engineering, University of Shanghai for Science & Technology, Shanghai 200093, China; 2.Guanganmen Hospital, China Academy of Chinese Medical Science, Beijing 100053, China)
Abstract:In order to solve the problem that class-imbalance data of clinical medical tables tend to have an impact on the model and that the performance of deep learning framework is difficult to match that of traditional machine learning methods when processing scale data tasks, this paper proposed a layer by layer Transformer (LLT) network model based on cascaded under-sampling. LLT deleted the most types of data layer by layer by cascade under-sampling method to achieve the balance of data categories and reduced the impact of class-imbalance data on the classifier. Moreover, LLT used attention mechanism to carry out correlation evaluation on the features of the input data to achieve feature selection, refined the feature extraction abi-lity and improved the model performance. This paper used RA (rheumatoid arthritis) data as test samples. Experimental results show that, on the premise of not changing the sample distribution, the recognition rate of a few categories is increased by 6.1% by the proposed cascade under-sampling method, which is 1.4% and 10.4% higher than that of the commonly used NEARMISS and ADASYN respectively. The accuracy of the RA tabular data and the F1-score index of LLT reach 72.6% and 71.5%, the AUC value is 0.89, the mAP value is 0.79, and the performance exceeds the current mainstream tabular data classification models such as RF, XGBoost and GBDT. This paper also visualized the model process and analyzed the characteristics affecting RA. It has a good guiding significance for the clinical diagnosis of RA.
Key words:tabular data classification; class-imbalance; cascaded under-sampling; Transformer
0 引言
临床问诊是指临床医生采用对话方式,向就医患者及其陪同人员了解疾病的发生、发展及现状过程,是医生了解患者病情的重要方式。随着各种医学信息数据库的不断建立,问诊数据逐渐积累形成了大量的临床量表数据,这些临床量表数据多具有类别不均衡(class-imbalance)的特点。类别不均衡是指在一个数据集中某些类别样本数量多于其他类别[1~3]。这种类型的数据会对分类器预测结果有较大影响,使预测偏向多数类,表现为多数类的先验概率增加、准确率降低,少数类样本漏检率增加,部分少数类样本被预测为多数类,分类结果偏向多数类别,严重影响了分类精度和泛化性能[4~6]。
近年来,研究人员提出各种方法来减少样本不均衡对分类结果的影响。常用的样本均衡化方法包括随机过采样(ROS)和随机欠采样(RUS)。为了获得平衡的数据,ROS随机复制一些正样本,而RUS随机丢弃一些负样本。在更高级的方法中,如合成少数过采样技术(SMOTE)系列[7,8],通过线性插值生成新的正样本。类似地,可以通过丢弃信息较少的样本改进RUS。例如Lin等人[9]使用K-means算法将负样本分成k个聚类,负类由聚类中心表示;Hoyos-Osorio等人[10]引入了信息论学习,以更少的样本保持负类的相关结构;Koziarski[11]采用相互類势(MCP)的方法改进过采样和过采样过程。此外还有一种将集成学习技术和数据级方法结合的混合策略,如SMOTEBoost[12]、Balanced Cascade[13]和AdaC1-AdaC3[14]。这些方法通过将权重集成到集成学习算法中,迭代地增强正样本的影响,虽然一定程度上缓解了数据集类别不均衡带来的问题,但通过生成或者删减数据的方式改变了原有的数据分布,降低了分类性能的可信度。
决策树(DT)通常用于量表类数据分类,主要优点是可以有效地选取具有最多统计信息增益的全局特征,从而提高标准分类性能。随机森林(random forest)[15]则根据随机选择特征生成若干森林树,统计若干森林树的分类结果投票,生成一个强分类器。XGBoost[16]和LightGBM[17]是近几年流行的DT方法,并且在大部分数据分类比赛中占据主导地位。
深度学习(deep learning, DL)模型凭借良好的全局关联特征提取能力,已经在CV/NLP等非结构化数据上得到了充分研究,涌现了大批突破性的研究成果[18~20]。但在量表数据中并未表现出优越的分类性能,主要是因为量表数据具有特征多源性和稀疏性,缺乏先验知识和可解释性,使DL无法有效兼容[21]。集成决策树对于量表类数据虽然具有较好的分类精度和泛化性能,但是无法提取量表数据中有效的全局关联性的深层特征,如能改进DL模型结构,将多源数据和量表数据一起编码,可以有效减轻DT中烦琐的特征工程需求[22]。近年来人工智能技术越来越多地应用于医学临床辅助决策,Khanam等人[23]通过医院提供的患者数据,训练和设计准确的ML/DL分类器,实现糖尿病早期检测的自动分类;Islam等人[24]使用ML分类模型,包括朴素贝叶斯(NB)[25]、逻辑回归(LR)[26]和随机森林,使用10倍交叉验证和80∶20训练测试分割方法对ESDRPD量表数据集进行训练。随着深度学习研究的不断深入,许多研究人员尝试使用神经网络实现量表类数据分类。Humbird等人[27]开始采用DNN模拟DT;Cortes等人[28]提出一种装箱函数,通过枚举所有可能的决策方法,采用DNN来模拟DT;Tanno等人[29]提出一种DNN架构,通过从原始块自适应生长,从边缘路由函数和叶节点进行表征学习。但这些通过穷举的方法会产生冗余的表征导致学习效率低下。
为了解决上述问题,本文提出一种级联欠采样方法,并结合改进后的基于Transformer的分类模型(LLT)。LLT顺序多步地提取数据中有用的信息,提升模型对少数类样本的特征学习能力。本文的主要贡献如下:a)提出了一种级联采样的类别不均衡的数据处理方法,相较于原始的类别不均衡数据,可以让分类器模型更加有效地学习少数类数据的特征,减少类别不均衡对分类器的性能影响;b)通过在分类模型中添加注意力模块,更加有效地学习特征对类别标签的影响,评估特征之间的相关性,提取特征之间的高维信息,从而进行过滤,减少输入特征的维度,一定程度上提升了模型推理速度,提高了模型的分类精度。本文方法在广安门医院提供的RA数据集进行实验,与现有的量表分类模型和采样方法进行对比,性能指标优于现有方法,并通过可视化mask掩码机制分析各个特征对于分类性能的影响,挖掘影响RA的特征因素,对RA临床诊断具有较好的指导意义。
1 LLT方法
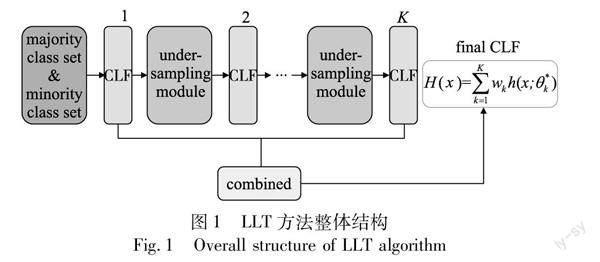
LLT方法通过分批定量删除分类器预测结果中正确分类的多数类样本,保留少数类样本和难分样本,然后将级联欠采样后的数据打包输入下一轮分类器训练,分层学习少数类以及难区分的数据样本规律。具体方法整体结构如图1所示。通过组合分类器,在每个分类器后连接一个欠采样模块,从多数类样本中随机剔除一定数量的样本,再传递给下一个分类器,并在分类模型中融入注意力机制,提取特征的多维信息,对数据进行降维。以此往复,直到进行完最后一轮学习,将之前的分类器权重进行整合加权,求得最终模型权重参数。
1.1 级联采样
欠采样是解决样本类别不均衡的常用方法之一,其核心思想是按照某种抽样法则,每次从多数类样本中抽取和少数类样本相同数量的样本,与少数类样本构成训练数据。由于常规欠采样方法抛弃了大量的多数类样本,导致丢失了原始数据信息,弱化了一些重要信息对模型的影响,最终结果使得预测模型有较大的偏差。过采样通过对少数类样本进行复制来均衡数据集,但会造成模型训练复杂度加大,另一方面也容易造成模型过拟合的问题,不利于分类器的泛化性能。本文提出的级联欠采样方法,通过从分类器预测结果中删除一定数量预测正确的多数类样本,处理后的数据重新传递给下一个分类器训练,最终组合分类器。级联欠采样方法结构如图2所示。
在级联欠采样方法中有两个主要过程:a)在随机采样过程中,对分类模型输出进行判断,统计被正确分类以及错误分类样本,蓝色和黄色分别表示分类正确的多数类(记为P)和少数类(记为Q),红色表示错误分类的样本,灰色线条表示分类器的分类边界H(x)(参见电子版),该过程抽取被正确分类的多数类样本(记为Pselected);b)在剔除多数类过程中,将所选择的样本从多数类别中删除,然后将剩余样本传入下一次分类器作为其输入数据。每次删除样本的数量为一个常数S,由多数类和少数类之间的样本数量差决定,其公式表示为
分类器为H(x),分类器参数以及权重为θk、wk,预测函数为h(xi,θk),最终的分类器公式表示为
由于被正确分类的样本被逐步剔除,一方面降低了数据类别不平衡的程度,另一方面使得难分样本被保留,可以进行更多轮的学习。靠前的训练次数可以利用更多的全局信息,靠后的训练次数可以学习更多的少数类样本的特征表达。本文方法通过不断地进行级联欠采样,删除被正确分类的多数类样本,最后使得输入样本中的少数类和多数类样本数量相等,达到平衡数据的目的。
1.2 分类器
TabNet[30]是基于Transformer的模型,原模型通过对linear layers(线性层)和batch normalization的不断堆叠,在取得不逊于传统算法性能的同时可以更加有效地编码多种数据类型,但随着特征维度和层数的增多,模型的参数会有明显上升。在此基础上,本文在原模型结构中加入注意力机制,并结合门控线性单元(gate linear unit,GLU)对每个step输入的特征进行降维,在降低每个step输入特征维度的同时提升了对数据的特征提取能力。分类器网络整体结构如图3所示。按照从左往右、自上向下的顺序,将整个预测过程分为多步。分类器网络整体结构由FT模块、AF模块与mask机制堆叠而成。数据首先经过网络模型中的GBN[31]层,GBN层的输出作为模型中后续阶段的输入features;通过重复的结构(step1、step2…),在每一轮step根据输入特征以及学习到的特征表变换和权重系数,得到当前step的输出向量;最终将多个step输出向量累加之后,利用全连接层做一次变换,得到最终的输出,即
如图4(a)所示,FT由四个相同的FT block模块组成,FT block由FC、MHA、GLU、GBN串联组成,负责将输入的特征进行线性层变换,提取数据信息。其中GBN为ghost batch normalization,与普通的batch normalization相比更具有鲁棒性;MHA为multi-head attention机制,在结构中和GLU串联,用来计算和过滤特征;GLU的变换公式为hl(X)=(XW+b)σ(XV+c)。融入多头注意力机制后有助于模型捕捉到更丰富的特征表示,计算数据中各个特征的依赖关系,最后将得到的多维信息进行集成,通过GLU进行特征的过滤、降维,从而缩短模型推理时间。以RA患者数据为例,多数患者存在关节疼痛与疼痛关节发热的问题,模型会分析特征之间的依赖性,若患者不存在关节疼痛,自然就不会出现疼痛关节发热的病症,模型会在当前step中将疼痛关节发热的特征过滤,减少输入特征的维度。各个block之间通过跳跃链接(skip-connection)相连,并乘以0.5,用来防止网络中输出的方差变换波动太大,造成学习过程的不稳定。图4(b)为AF结构,用来计算特征重要性。为了方便对模型内部进行可视化,在每个AF与FT模块之间并行mask,用于记录当前step对特征的关注点。对于样本的特征重
2 实验与结果分析
2.1 實验数据集及预处理
实验数据集由中国中医科学院广安门医院提供。数据总计条目27条,包括病人就诊时间、发病时间等基本信息,关节疼痛、关节肿胀等关节信息和相应化验指标共计26条,RA关节活动等级分类标签1条,分类级别由轻到重依次为缓解疾病活动、轻微疾病活动、中度疾病活动、重度疾病活动阶段,分别编码为0、1、2、3。数据样本共计10 514例,缓解疾病活动等级911例,轻微疾病活动等级749例,中度疾病活动等级3 713例,重度疾病活动等级5 141例,存在数据类别不平衡问题。对于原始RA数据样本,数据质量存在较大差别,如图5(a)(b)所示,其中,(a)所示特征具有良好区分性,特征应予以保留;(b)所示特征不具有区分性,应予以删除。再剔除与RA疾病等级分类明显无关的特征,如患者ID、发病时间等。对于缺失值采用前值填充法进行填充,删除了异常样本,最后采用one-hot编码对类别变量进行转换。处理后的数据保留了10 110例样本,每例样本包含14个特征,处理后的数据各类别占比如图5(c)所示。实验采用5折交叉验证,将预处理之后的数据等分成5份,在5轮实验中,取其中的4份用于训练,1份用于测试,并将最终的结果取均值作为最终的分类结果。实验流程如图6所示。
2.2 评价指标
对于分类任务,通常选择整体分类准确度(overall accuracy)作为对模型的评价指标,从模型预测的混淆矩阵中获取四个基本指标,分别是真阳性(TP)、假阳性(FP)、真阴性(TN)以及假阴性(FN),进而得到针对类别不均衡样本分类时常用的三个评估指标,即真阳性率(TPR)、真阴性率(TNR)以及G-mean。其中TPR即灵敏度(recall),衡量了分类器对正样本的识别程度,如果TPR值过小,表明分类器将大量的正样本预测为负样本,导致漏诊;TNR即特异性(specificity),衡量了分类器对负样本的识别程度,如果TNR值过小,表明分类器将大量负样本预测为正样本,导致误诊。因此,泛化性能较好的分类器需要同时具有较高的TPR和TNR值。G-mean常用来表示算法的平衡程度,该值越大说明模型的表现性能越好。本文实验中还用到了评估指标F1-score,该指标是精确度(precision)和recall的调和平均值。各模型评估指标定义如下:
2.3 实验结果及分析
1)采样方法对比 为了验证级联欠采样方法的有效性,本文采用改进后的分类器结合目前主流的采样方法进行对比,包括两种过采样方法SMOTE、ADASYN和一种欠采样方法NearMiss。衡量指标采用真阳性率(TPR)、真阴性率(TNR)和G-mean三种分类评估指标。实验结果如图7所示。相较于不进行采样处理的原始分类器,本文提出的级联采样方法能在保持原有的TNR不减退的前提下,对少数类样本的识别率由0.558提升到了0.619。与欠采样NearMiss方法相比,后者通过直接丢弃部分多数类样本而丢失过多的原有数据信息,最终
导致衡量指标的下降。与过采样方法SMOTE和ADASYN比较,过采样方法通过增加少数类样本使数据类别达到均衡,但新增样本会引入冗余信息增加噪声,同时也可能造成过拟合。虽然SMOTE过采样方法整体TPR和TNR指标略高,但在一定程度上都会改变样本原始分布,降低了原始模型对于轻微疾病类患者和中度疾病类患者的G-mean值,导致整体模型预测偏差,减弱了模型泛化能力。而本文提出的级联欠采样方法既能有效利用所有原始样本信息,保持了原始模型对于多数类类别的TNR指标,又能减少类别不均衡对模型分类的影响,因此三项评估指标均具有较高精度。
2)与典型分类模型性能对比 本文选取了九种主流的机器学习方法和神经网络展开对比实验,包括几种基于ML的分类方法,如人工神经网络中的多层感知机(MLP)、随机森林(RF)、XGBoost、GBDT、逻辑回归(LR)、支持向量机(SVM)等。表1为5折交叉验证的准确度结果。
图8依次为各模型的recall、precison以及F1-score的交叉验证结果,由图可见,本文方法在三个指标上均高于其他分类器。本实验还采用ROC和P-R曲线来可视化模型分类性能。图9给出了各分类器的ROC和P-R曲线。ROC反映的是真阳性率(TPR)随着假阳性率(FPR)的变化情况,同时兼顾了对正样例和负样例的预测情况;P-R曲线则反映的是precision随着recall的变化,只关注对正样例的预测情况。从图9可以看出,当前主流的机器学习分类模型虽然有着整体不错的最终分类准确度,但多数属于盲目将少数类归为多数类获得的虚高,反映在ROC与P-R上却并不理想。本文方法在ROC曲线的AUC值达到0.89,比次高的LR方法高出3%,对比当下流行的XGBoost和GBDT的AUC值分别高出7%和17%;与剩余方法分类器的AUC值相比也有不同程度的提升。本文方法的P-R曲线的mAP值达到0.79,比LR方法的mAP高出16%,并且大幅度高于其他分类方法的mAP值。这是由于改进后的分类模型融合了注意力机制,细化了模型的信息,提取了特征与特征之间的相关性,过滤了患者不重要的信息,提升了模型的性能;此外,通过级联欠采样方法,多次学习难分样本以及少数类样本规律,最后加权后的分类器对于少数类具有更出色的判别能力。
图10为本文方法最终分类效果展示,其中(a)为RA数据集中少数类样本病例1和难区分的病例2在主流分类器的分类结果与本文方法分类结果的对比。可以看出,对于病例1,主流的RF、XGB和改进前的TabNet由于同类数据样本少,无法学到合理的特征表达,最终没有预测到正确的结果,而LR方法分类正确;在本文方法中,靠前的分类器虽然没有预测对少数类样本,但随着级联欠采样次数的增加,数据集类别不平衡的程度得到了改善,靠后的分类器可以学习到难分样本和少数类样本规律做到正确分类,最后的分类器通过加权获得正确的分类结果。在病例2的测试中,RF、LR由于样本的区分度
不高,没能正确分类,XGB、TabNet和本文的LLT都预测正确,虽然本文方法中间的分类器2分类错误,但在最后通过对所有分类器权重加权后,最后的模型分類结果正确。图10(b)为本文方法的分类结果的混淆矩阵,虽然该方法对每类样本的分类结果没能达到完全正确,但却通过级联欠采样模块后加权融合改进后的分类器,做到有效地减弱了数据样本不均衡对分类器造成的影响。
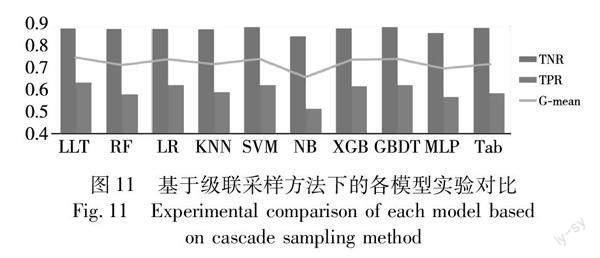
3)级联采样方法下不同模型对比 在基于本文提出的级联采样的方法中,结合上节对比的分类模型对RA数据进行实验,计算不同方法下的模型分类的TPR、TNR以及G-mean指标。实验结果如表2所示,粗体数据为最优值,其可视化如图11所示。
由表2可以看到在级联采样方法下的GBDT在TNR达到了0.882,虽然高于本文的LLT,但在TPR和G-mean指标上本文方法高于前者。这是因为GBDT是一种树模型,虽然每一次采样后降低了类别不均衡的程度,但GBDT也会生成更多的树,与之前的树进行合并,决策投票时会有更多的树投票给多数类,造成多数类检测率虚高;本文方法通过采样平衡数据不均衡程度,分类器再对样本进行特征转换,更好地学习少数类样本,因此有着更好的少数类检测率和G-mean指标。综上所述,对于不均衡数据,LLT方法具有更好的分类性能和综合指标,提出的级联欠采样方法也具有一定的通用性。
4)模型mask可视化 对本文模型的掩码模块进行可视化,探讨分析模型在每个step的关注点,结果如图12所示。图中共展示了50个样本,从上往下依次是样本顺序0~49,从左往右依次是14个特征条目(0:关节疼痛;1:关节肿胀;2:关节晨僵;3:疼痛关节发热;4:能否自己洗头;5:能自己使用筷子;6:能否端起盛满的杯子送到嘴边;7:能否伸手摘下衣架上的衣帽;8:能否上5级台阶么;9:神疲乏力;10:胃口如何;11:心烦不安;12:能否加做家务;13:失眠多梦),mask 0~2分别对应模型设置的3个step,颜色越亮,代表在该step下模型更关注此特征。
从掩码的可视化热力图可以看到,模型中的每一个step的关注特征都有所不同,第一个step更关注RA患者的第0、1、12个特征;第二个step更关注RA患者的第4~6个特征;第三个step更关注患者的第2~6、8、9个特征。临床研究表明,绝大多数RA患者都会出现关节疼痛发热、关节肿胀以及肢体活动受限,进而常常感觉身体疲劳的病症。本文的LLT模型分步分层地将更多的关注点放在了这些症状上,提高了模型的预测效果。模型的关注点与临床结论一致,充分说明改进后的方法具有良好的可信度。
3 結束语
量表数据因为其存在的数据类别不均衡以及常见的混合数据属性的问题,导致在深度学习领域没有得到充分的探索发展。本文提出了一种基于Transformer网络和级联采样方法的网络模型LLT并且应用于中医RA数据集。将注意力机制融合进原始模型细化特征之间的信息,提升了模型的精度,通过级联采样方法层层删减多数类样本以减缓样本不均衡对模型的影响,提升模型对少数类的识别率。与当前主流的针对量表型数据的RF、LR、XGBoost、GBDT等模型相比较,改进后的模型具有更好的精度和泛化性能。本文提出的级联采样方法能更好地学习少数类样本的特征,对于其他类别不均衡的采样方法,指标也有所提升,对临床诊断有着一定的指导作用。
在类别不均衡的量表数据研究领域,仍存在一些需要进一步研究的方法,如通过增量式学习方法,利用新数据更新模型或利用基于规则的处理策略,对特定的问题和场景设计出有效的类别不平衡策略等。未来研究会综合考虑以上因素,并更好地结合实际应用场景来设计和改良模型。
参考文献:
[1]李勇,刘战东,张海军.不平衡数据的集成分类算法综述[J].计算机应用研究,2014,31(5):1287-1291.(Li Yong, Liu Zhandong, Zhang Haijun. Review on ensemble algorithms for imbalanced data classification[J].Application Research of Computers,2014,31(5):1287-1291.)
[2]Herland M, Khoshgoftaar T M, Bauder R A. Big data fraud detection using multiple medicare data sources[J].Journal of Big Data,2018,5(1):article No.29.
[3]Mohd H A H, Marina Y, Azlinah M. Survey on highly imbalanced multi-class data[J/OL].International Journal of Advanced Computer Science and Applications,2022,13(6).http://dx.doi.org/10.14569/IJACSA.2022.0130627.
[4]Peng Lizhi, Zhang Haibo, Chen Yuehui, et al. Imbalanced traffic identification using an imbalanced data gravitation-based classification model[J].Computer Communications,2017,102(4):177-189.
[5]Chawla N V. Data mining for imbalanced datasets: an overview [M]// Data Mining and Knowledge Discovery Handbook. Boston, MA: Springer, 2010: 853-867.
[6]Mahdiyah U, Irawan M I, Imah E M. Integrating data selection and extreme learning machine for imbalanced data[J].Procedia Computer Science,2015,59:221-229.
[7]Tesfahun A, Bhaskari D L. Intrusion detection using random forests classifier with SMOTE and feature reduction [C]// Proc of International Conference on Cloud & Ubiquitous Computing & Emerging Technologies. Piscataway, NJ: IEEE Press, 2013: 127-132.
[8]Li Junnan, Zhu Qingsheng, Wu Quanwang, et al. A novel oversampling technique for class-imbalanced learning based on SMOTE and natural neighbors[J].Information Sciences,2021,565(7):438-455.
[9]Lin Weichao, Tsai C F, Hu Yahan, et al. Clustering-based undersampling in class-imbalanced data-ScienceDirect[J].Information Sciences,2017,409-410(10): 17-26.
[10]Hoyos-Osorio J, lvarez-Meza A, Daza-Santacoloma G, et al. Relevant information undersampling to support imbalanced data classification[J].Neurocomputing,2021,436(5):136-146.
[11]Koziarski M. Radial-based undersampling for imbalanced data classification[J].Pattern Recognition,2020,102(6):107262.
[12]Chawla N, Lazarevic A, Hall L O, et al. SMOTEBoost: improving prediction of the minority class in boosting [C]// Proc of the 7th European Conference on Principles and Practice of Knowledge Discovery in Databases. Berlin: Springer, 2003: 107-119.
[13]Liu Xuying, Wu Jianxin, Zhou Zhihua. Exploratory under-sampling for class-imbalance learning[J].IEEE Trans on Systems, Man,and Cybernetics,2009,39(2):539-550.
[14]Sun Yanmin, Kamel M S, Wong A K C, et al. Cost-sensitive boosting for classification of imbalanced data[J].Pattern Recognition,2007,40(12):3358-3378.
[15]Liu Yanli, Wang Yourong, Zhang Jian. New machine learning algorithm: random forest [C]// Proc of the 3rd International Conference Information Computing and Applications. Berlin: Springer, 2012: 246-252.
[16]Chen Tianqi, Guestrin C. XGBoost: a scalable tree boosting system [C]// Proc of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM Press, 2016: 785-794.
[17]Ke Guolin, Meng Qi, Finley T, et al. LightGBM: a highly efficient gradient boosting decision tree [C]// Proc of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 3149-3157.
[18]He Kaiming, Zhang Xiangyu, Ren Shaoqing, et al. Deep residual learning for image recognition [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Washington DC: IEEE Computer Society, 2016: 770-778.
[19]Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: transformers for image recognition at scale [EB/OL].(2021-06-03). https://arxiv.org/abs/2010.11929.
[20]Howard A, Sandler M, Chu G, et al. Searching for MobileNetV3 [EB/OL]. (2019-11-20). https://arxiv.org/abs/1905.02244.
[21]Shwartz-Ziv R, Armon A. Tabular data: deep learning is not all you need[J].Information Fusion,2022,81(5): 84-90.
[22]Hestness J, Narang S, Ardalani N, et al. Deep learning scaling is predictable, empirically [EB/OL]. (2017-12-01). https://arxiv.org/abs/1712.00409.
[23]Khanam J J, Foo S Y. A comparison of machine learning algorithms for diabetes prediction[J].ICT Express,2021,7(4):432-439.
[24]Islam M M F, Ferdousi R, Rahman S, et al. Likelihood prediction of diabetes at early stage using data mining techniques [C]// Proc of International Symposium on Computer Vision and Machine Intelligence in Medical Image Analysis. Singapore: Springer, 2019: 113-125.
[25]Best L, Foo E, Tian Hui. A hybrid approach: utilizing K-means clustering and naive Bayes for IoT anomaly detection [M]// Secure and Trusted Cyber Physical Systems. Cham: Springer, 2022: 177-214.
[26]Bredt L C, Peres L A B, Risso M, et al. Risk factors and prediction of acute kidney injury after liver transplantation:logistic regression and artificial neural network approaches[J].World Journal of Hepatology: English Edition,2022,14(3):570-582.
[27]Humbird K D, Peterson J L, McClarren R G. Deep neural network initialization with decision trees[J].IEEE Trans on Neural Networks and Learning Systems,2019,30(5):1286-1295.
[28]Cortes C, Gonzalvo X, Kuznetsov V, et al. AdaNet: adaptive structural learning of artificial neural networks [EB/OL]. (2017-02-28). https://arxiv.org/abs/1607.01097.
[29]Tanno R, Arulkumaran, K, Alexander D C, et al. Adaptive neural trees [EB/OL]. (2019-06-09). https://arxiv.org/abs/1807.06699.
[30]Arik S , Pfister T. TabNet: attentive interpretable tabular learning[J].Proceedings of the AAAI Conference on Artificial Intelligence,2021,35(8):6679-6687.
[31]Dimitriou N, Arandjelovic O. A new look at ghost normalization [EB/OL]. (2020-07-16). https://arxiv.org/abs/2007.08554.
[32]Zhao Puning, Lai Lifeng. Minimax rate optimal adaptive nearest neighbor classification and regression[J].IEEE Trans on Information Theory,2021,67(5):3155-3182.
[33]De Nogueira T O, Palacio G B A, Braga F D, et al. Imbalance classification in a scaled-down wind turbine using radial basis function kernel and support vector machines[J].Energy,2022,238(1):122064.
[34]Liu Wanan, Fan Hong, Xia Meng. Credit scoring based on tree-enhanced gradient boosting decision trees[J].Expert Systems with Application,2022,189(3):116034.
[35]Li Wenshuo, Chen Hanting, Guo Jianyuan, et al. Brain-inspired multilayer perceptron with spiking neurons [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 773-783.
收稿日期:2023-01-31;修回日期:2023-03-24
基金項目:国家自然科学基金资助项目(81973749);中国中医科学院科技创新工程项目(CI2021A01503)
作者简介:杨晶东(1973-),男,黑龙江齐齐哈尔人,副教授,硕导,博士,主要研究方向为人工智能、机器学习与大数据分析、机器视觉等;李熠伟(1997-),男(通信作者),江苏徐州人,硕士研究生,主要研究方向为人工智能、机器学习等(eerfriend@yeah.net);江彪(1998-),男,安徽宣城人,硕士研究生,主要研究方向为人工智能、机器学习等;姜泉(1961-),女,主任医师,博士,主要研究方向为风湿免疫病的中医、中西医结合临床及基础研究;韩曼(1984-),女,副主任医师,博士,主要研究方向为风湿免疫病的中医、中西医结合临床及基础研究;宋梦歌(1993-),女,博士研究生,主要研究方向为风湿免疫疾病的临床与基础研究.
