基于图卷积网络融合依存信息的事件检测方法
2023-10-17张紫月王羽徐建
张紫月 王羽 徐建

摘 要:句子级别细粒度的事件检测任务旨在对触发词进行识别与分类。针对现有事件检测方法中存在的过度平滑及缺乏依存类型信息的问题,提出了一种基于图卷积网络融合依存信息的事件检测方法。该模型首先使用双向长短期记忆网络对句子进行编码,同时根据依存分析构建多阶句法图和依存句法图;然后利用图卷积网络融合句子的依存信息,从而有效地利用多跳信息和依存标签信息。在自动文本抽取数据集上进行实验,在触发词识别和分类这两个子任务中分别取得了81.7%和78.6%的F1值。结果显示,提出的方法能更加有效地捕获句子中的事件信息,提升了事件检测的效果。
关键词:依存信息; 图卷积网络; 事件检测; 多阶句法图; 依存句法图
中图分类号:TP391.1 文献标志码:A 文章编号:1001-3695(2023)10-013-2967-05
doi:10.19734/j.issn.1001-3695.2023.03.0097
Event detection based on dependency information and graph convolutional network
Zhang Ziyue1, Wang Yu2,3, Xu Jian1
(1.School of Computer Science & Engineering, Nanjing University of Science & Technology, Nanjing 210094, China; 2.Science & Technology on Information Systems Engineering Laboratory, National University of Defense Technology, Changsha 410003, China; 3.The 28th Research Institute of China Electronics Technology Group Corporation, Nanjing 210007, China)
Abstract:The fine-grained event detection task at the sentence level aims at identifying and classifying triggers. To solve the problem of over-smoothing and lack of dependency type information in existing event detection methods, this paper proposed an event detection method based on dependency information and graph convolutional network(GCN). This method firstly used bi-directional long short-term memory(Bi-LSTM) networks to encode the sentence, and constructed a multi-order syntactic graph and a dependent syntactic graph based on the dependency analysis. Then it used GCN to aggregate the sentences dependency information, which effectively utilized the multi-hop information and the dependent type information. On automatic content extraction (ACE) dataset, the proposed method achieved 81.7% and 78.6% F1 values in the two subtasks of trigger identification and classification. Results show that the proposed method can capture event information in sentences more effectively, and improve the effect of event detection.
Key words:dependency information; GCN; event detection; multi-order syntactic graph; dependent syntactic graph
0 引言
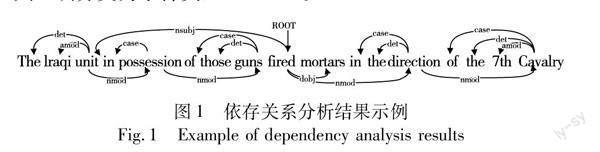
隨着信息技术的飞速发展,每日产生的数据和信息的数量都呈指数级爆炸式增长,而且这些数据和信息大多趋向于非结构化或者半结构化。如果没有任何文本自动化处理技术的支持,想要高效率地利用这些非结构化的数据是很非常困难的。事件抽取作为信息抽取[1]的一种特殊形式,因其能够自动从人类语言中提取事件而受到越来越多的关注。在需求和质量不断提高的今天,各领域的事件抽取可以帮助相关人员从海量信息中快速抽取相关内容,提高工作时效性,为定量分析提供技术支持。事件抽取任务研究的是从非结构化文本中将事件信息提取为结构化形式,结构化形式主要描述发生的现实世界事件的“谁、何时、何地、什么、为什么”和“如何”。根据ACE2005中的事件抽取任务定义,事件是指在特定的时间和地点,由一个或多个角色参与的某件事的特定发生或者状态的改变[2]。事件抽取任务可以分为事件检测(event detection,ED)和事件论元抽取(event argument extraction,EAE) 两个子任务。本文主要研究的是第一个子任务——事件检测,旨在识别出句子中的触发词并对其事件类型进行分类。如图1所示,事件检测系统需要识别出该句子中存在的触发词“fired”,并将其正确分类为事件类型“Attack”。
依存句法分析可以反映句子中词之间的依存关系,是自然语言处理的基础任务。依存句法树包含了丰富的结构信息,对事件检测任务有着十分重要的帮助[3~8]。ACE2005数据集中,“nsubj”“dobj”和“nmod”占触发相关依赖标签的32.2%(在所有40个依赖关系中,每个关系平均占2.5%)[8],这意味着同时建模句法结构和依存类型标签对于充分利用依存分析树来进一步提高事件检测任务的性能至关重要。在现有的事件检测方法中,与基于序列的方法[6,7]相比,基于依存句法树构建图卷积网络(GCN)的方法[3~5,8]能够更好地捕获每个候选触发词与其相关实体或其他触发词之间的关系,获得更好的性能。
尽管这些基于依存句法分析的方法取得了巨大成功,但仍然存在两个问题:
a)过度平滑问题。通常对于给定的候选触发词,其相关单词通常是多跳的,例如图1所示的句子,触发词“fired”可以被分类为“End-Position”类型或“Attack”类型。观察单词“fired”的依存关系,路径“guns-possession-unit-fired-mortars”可提供有效信息将该事件更大概率判断为“Attack”类型而不是“End-Position”类型。文献[5]统计超过一半的事件相关实体需要一次以上的跳跃才能到达相应的触发词。为了捕获多跳关系,大多数方法[3,8]均采用堆叠多个GCN层来达到效果,但是会导致过度平滑的问题,层数太多相邻节点的表示会趋于一致。
b)缺乏依存类型信息。依存类型标签可以作为预测单词是否为触发词的重要参考信息,如图1所示,依存类型“nsubj”(名词主语)和“dobj”(直接宾语)表示单词“unit”和“mortars”分别是“fired”的主语和宾语,且与“fired”具有依存关系“nmod”(名词复合修饰语)的单词表示该事件所袭击的目标。根据依存类型标签信息可以判断出“fired”为该句子的事件触发词,并且预测出其事件类型为“Attack”。然而现有的大多数基于GCN的事件检测方法[3~5]只考虑依存句法树中的路径,忽略掉其依存类型标签信息。
为解决上述问题,本文提出一种基于图卷积网络融合依存信息的事件检测方法(event detection based on dependency information and graph convolutional network,DIGCN)。首先根据输入句子的依存句法树分别生成多阶句法图和依存句法图,采用双向長短期记忆网络(bidirectional long short-term memory,Bi-LSTM)[9]对句子进行编码来获取句子的语义表示,为捕捉长距离依赖关系,使用图卷积网络融合依存信息进行建模。在ACE2005基准数据集上对DIGCN模型进行评估,实验结果显示了DIGCN模型在事件检测任务上的有效性。本文的贡献如下:a)构建了依存信息的增强表示模块,将依存类型标签信息引入GCN模型;b)提出了一个基于图卷积网络的事件检测模型DIGCN,可以更好地将多跳信息和依存类型标签信息融合,对句子中的事件触发词进行识别和分类。
1 相关工作
早期对于事件抽取的研究多利用人工构造事件模式和文本特征,如词汇特征、句法特征和语义特征[10]。然而,设计这些特征非常耗时,而且不容易适应其他任务或新领域。
随着神经网络的快速发展,由于其可以捕获复杂的语义关系并显著改进事件检测任务的效果,越来越多的研究集中于神经网络模型。Chen等人[6]提出了一种动态多池卷积神经网络(DMCNN),通过动态多池层来评估句子的每个部分。单词之间的句法依赖信息也可以用于增强基本的RNN结构,例如Sha等人[11]设计了dbRNN模型,引入句法信息。
一个句子中存在多个事件,一个事件的论元存在于不同的句子或者文档级别的事件抽取任务都面临同一个挑战,即长期依赖性,最普遍的解决办法就是利用依存句法分析。图卷积网络的节点表示单词,边表示有向句法弧,有助于缓解这一挑战。Nguyen等人[3]首次将GCN应用于事件检测任务,研究了基于句法依存树的卷积神经网络来进行事件检测任务。为了处理同一句子中存在多个事件的挑战,Liu等人[4]提出了一种联合多事件抽取框架JMEE,通过引入基于注意力的GCN来建模依存图信息,联合提取多个事件触发词和论元。Ahmad等人[12]使用图形注意力转换编码器(GATE)学习长程依存关系,并将其应用于跨语言关系和事件抽取任务。
对于给定的候选触发词,其相关实体通常是多跳的。有两种方式可以捕获多跳信息,一种方法是堆叠多个GCN层[8,13],另一种方法则是将一阶图扩展到高阶图[5]。Yan等人[5]提出MOGANED模型,将一阶句法图扩展到高阶句法图,并使用图注意力网络以克服堆叠多个图卷积层时的过度平滑问题。Cui等人[8]考虑到依存类型标签对于触发词检测可能很重要,提出关系感知图卷积网络EE-GCN。Liu等人[13]使用注意力机制融合句法结构和潜在依赖关系,在提高事件检测任务性能的同时使用残差连接解决图信息消失问题。Xie等人[14]提出了一种基于自适应图生成的事件检测方法AGGED,具有自适应图生成模块和门控多信道图卷积机制,且使用单个图卷积层来聚集用于事件检测的信息。Mi等人[15]提出一种简单有效的模型DualGAT,利用句法和语义关系的互补性来缓解利用句法关系带来的冗余问题。
2 DIGCN模型
2.1 问题描述
事件检测任务可以被建模为一个序列标注任务。给定一个长度为n的句子W={w1,w2,…,wn},其中wi表示该句的第i个单词。由于事件触发词可能包含多个单词,采用BIO(begin,inside,outside)标注模式进行序列标注,将每个元素标注为“B-X”“I-X”或者“O”,其中“X”代表事件类型,“O”表示元素不属于X类型,“B”和“I”表示元素在触发词中的位置,例如触发词“go off”属于“Attack”类型的事件,则将其标记为“B-Attack I-Attack”来解决触发词由多个单词构成的问题。由于触发词的类型标签是事先定义好的,根据BIO标注格式和NONE标签,可将标签的数量记为2L+1,其中L是预定义事件类型的数量。
2.2 模型框架
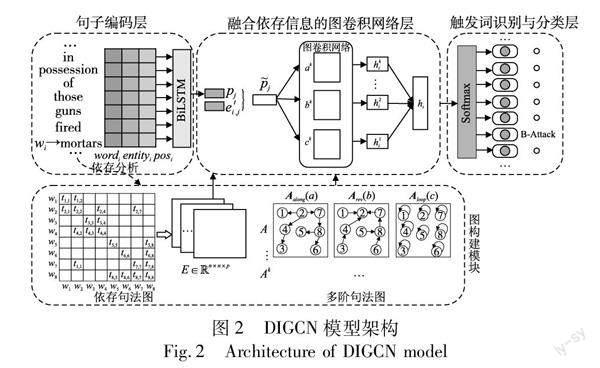
本文提出的基于图卷积网络融合依存信息的事件检测模型框架如图2所示。该模型分为句子编码层、图构建模块、融合依存信息的图卷积网络层和触发词识别与分类层四个模块。
a)词向量使用skip-gram模型预训练,该层结合词汇特征表示输入句子的编码,将句子中每一个单词转换为固定长度的实值向量。
b)图构建模块对句子的句法依赖树分别构建多阶句法图和依存句法图,将句子中的单词token作为节点,将单词之间的句法弧作为边。
c)将句子编码层输出的句子编码和图构建模块的输出送入图卷积网络进行建模,经过图卷积之后的输出融合了依存标签信息和多跳信息。
d)在触发词识别与分类层,将融合依存信息的图卷积网络层得到的最终句子表示向量输入前馈神经网络,结合softmax对句子中的每一个单词进行分类,识别句子中的触发词并对其事件类型进行分类。
2.3 句子编码模块
句子编码模块的输入为目标句子W={w1,w2,…,wn},句子固定长度n以截断或填补的方式来确定。为了补充输入特征,句子编码模块利用词性特征、实体信息以及上下文特征来克服独立分析句子的不足,通过连接以下向量将每个单词wi转换为实值向量xi:
a)wi的词嵌入向量。与之前的研究工作[5,16]相同,本文使用在NYT語料库上利用skip-gram模型预训练的词嵌入,得到wordi。
b)wi的实体类型嵌入向量。句子中的实体用BIO模式标注,通过查找嵌入表将每个实体类型标签映射到一个实值嵌入,得到对应的实体类型向量entityi。
c)wi的词性标注(part-of-speech tagging,POS)嵌入向量。与实体类型向量相同,查找随机初始化的POS嵌入矩阵生成,得到对应的POS嵌入向量posi。
根据上述特征表示,wi的输入嵌入可定义为
其中:dword、dentity和dpos分别表示词嵌入、实体类型嵌入和POS标签嵌入维数。输入句子W转换成实值向量序列X=[x1,x2,…,xn],然后采用Bi-LSTM网络捕获每个单词的上下文信息,将单词表示编码为
其中:LSTM 和LSTM 分别表示正向LSTM和反向LSTM;[,]表示连接操作。经过Bi-LSTM编码后得到上下文向量序列P=[p1,p2,…,pn]作为图卷积网络层的输入。
2.4 图构建模块
对于一个长度为n的句子W={w1,w2,…,wn},进行依存句法分析得到依存句法树。将句子中每一个单词作为一个节点,根据依存关系构造该句子的依存句法图,记为G={V,E}。其中V={v1,v2,…,vn}包含了n个节点,每个节点vi对应一个单词wi,E表示每个节点间边的集合。若节点vi与vj之间有依存关系,则存在边(vi,vj)∈E为节点vi到vj的正向句法边,记该句法边(vi,vj)标签类型为K(vi,vj);为了保证信息的反向传输,同时添加标签类型为K′(vi,vj)的反向句法边(vj,vi)。在此基础上为每个节点添加一个自环(vi,vi)引入节点自身的信息,然后通过句子的依存句法图分别构建多阶句法图和依存句法图。
1)多阶句法图
每个依存句法树都可以用一个邻接矩阵表示为一阶句法图。设A为一阶句法图的邻接矩阵,由句子W的依存句法树生成。A包含三个维数均为n×n的子矩阵,分别为上述正向、反向及自循环边构成的Aalong(a)、Arev(b)和Aloop(c)[17]。
在多阶句法图中,随着阶数越来越高,句法边所对应的依存类型标签数量将剧增。为减少模型训练时的参数量,本文在构建多阶句法图时将类型标签K(vi,vj)的定义简化为
即多阶句法图中的类型标签K(vi,vj)仅具有三个类型。为方便计算,如果依存句法树中存在从wi到wj的句法边,则直接令正向句法图Aalong中对应元素ai,j=1,否则为0;同理构建反向句法图Arev为Aalong的转置矩阵,即Arev=ATalong 。Aloop则为一个单位矩阵。对于多阶句法图,设K阶句法图的邻接矩阵为AKsubg=(Asubg)K,其中subg∈{along,rev,loop}。
如图3所示,AKsubg记录了Asubg中的K跳路径。由于Aloop是一个单位矩阵,所以AKloop=Aloop。为了描述方便,在下文中使用aK、bK、cK分别表示AKalong、AKrev和AKloop。由依存句法树生成的这些二进制邻接矩阵作为后续图卷积模块的输入。
2)依存句法图
与普通一阶句法图不同的是依存句法图中类型标签K(vi,vj)的定义。在实验中,对句子进行依存分析得到的句法分析树中包含约50种不同的语法关系,为引入关系类型信息,根据语法关系来初始化一个类型标签映射表。如果句法图中存在从wi到wj的句法边,且依存类型标签K(vi,vj)=ti,j,其中ti,j点wi指向节点wj的正向句法边的依存类型,则反向句法边(vj,vi)依存类型标签可记为tj,i,例如,如果ti,j为nmod,则tj,i记为#nmod。随后查找类型标签映射表将依存类型ti,j映射为实值向量eti,j∈Euclid Math TwoRApp,即一个p维向量。不同于句法图的二进制邻接矩阵,最终得到包含依存关系标签信息的邻接张量E∈Euclid Math TwoRApn×n×p。
2.5 融合依存信息的图卷积网络模块
为了更好地融合语句的语义特征和句法特征,充分利用将多跳信息与句法类型标签信息,该模块以句子编码层输出的语句上下文编码序列P=[p1,p2,…,pn] 、图构建模块输出的多阶句法图AKsubg 和依存句法图生成的邻接张量E作为GCN层的输入。
首先,对句子编码层生成的序列P添加所对应单词的依存关系标签信息。其中WT将依存类型的实值嵌入向量eti,j映射为与其对应编码pj相同维度的向量,最后将两个向量拼接起来作为单词wj依存信息的增强表示:
得到融合依存关系标签信息的特征表示j后,根据文献[18]中的图卷积方法,对节点特征信息进行卷积操作,其计算为
其中:W和b为权重矩阵和偏置;aki,j为k阶句法图中正向弧所构建的矩阵中所对应的元素;σ表示激活函数。
对于k阶句法图Ak,其包含三个维数均为n×n的子矩阵ak、bk和ck,为充分利用句法图的特征表示,通过式(7)得到对应于阶句法图的三个子矩阵的特征:
其中:⊕表示进行元素级别的相加操作,计算得到每个候选触发词wi的一组k阶的特征表示hki。最后聚合每个单词wi的多阶表示hki得到最终融合多跳信息的特征表示,如式(9)所示。
2.6 触发词识别与分类模块
从融合依存信息的图卷积模块中得到所有单词的表示之后,将其送入全连接层中,完成最终的触发词识别和分类。
其中:Wt将单词表示h转换成了针对每个事件标签的分值,bt是偏置项。sotfmax函数常用于多分类问题,代表了某个元素被取到的概率,本文选择条件概率最高的事件类型为相对应的候选触发词的预测结果。
2.7 損失函数
由于数据中“O”标签的数量远远大于事件标签的数量,参考文献[5,16]在训练过程中使用偏差损失函数来增强事件类型标签的影响。偏差损失函数公式如下:
其中:Ns是句子的数量;ni是第i句中的字数;I(O)是区分标签“O”和事件类型标签的切换函数。定义如下:
其中:α为偏置权重。α越大,事件类型标签对模型的影响越大。
3 实验及分析
3.1 数据集
在实验中,本文使用了英文基准数据集ACE2005EN(ACE05),对于ACE05,其包含了599个文档,预定义了33种事件类型。遵循之前的研究[5~8,16]对其进行预处理,将文档分为训练集、开发集和测试集,分别包含529、30和40篇文档。
3.2 评价指标
本文采用事件抽取领域中最常用的精确率(precision,P),召回率(recall,R)和F1值测度(F1-score)作为评价指标。
将事件检测分为触发词识别和触发词分类两个步骤分别进行评估。对于模型预测结果,被预测为正的样本中实际为正的比例叫做精确率;被预测为正的样本占全部正样本的比例叫做召回率,而F1值是精确值和召回率的调和均值。
其中:TP是将正类预测为正类的数目;FP是将负类预测为正类的错误预测数;FN是将正类预测为负类的错误预测数。
3.3 实验设置
本文模型使用StanfordCoreNLP工具包来预处理数据,获取句子分词、词性标注及依存句法分析树。单词表示模块采用在NYT语料库上使用skip-gram算法预训练的单词嵌入,维数为100;词性标注标签、实体类型和依赖项标签嵌入都是随机初始化的;分别用25维和50维向量随机初始化词性标注标签、实体类型和依赖标签嵌入;Bi-LSTM和DIGCN的隐藏状态大小分别设置为100和150;参数优化采用SGD进行,学习率为0.1,批处理大小为30。使用参数为1E-5的L2正则化,以避免过拟合,dropout率应用于单词嵌入和隐藏状态为0.6。通过填充较短的句子和删除较长的句子,将句子的最大长度设置为50,将多阶句法图的最高阶K设为2。
3.4 实验结果与分析
为了全面评估本文提出的模型,将其与一系列基线和最先进的模型在触发词识别和触发词分类任务上的表现进行比较。
a)GCN-ED [3],首次将GCN引入事件检测任务。
b)JMEE [4],引入句法弧代替句子级别的顺序建模,增强信息流,并使用自注意力机制增强GCN模型。
c)MOGANED [5],利用多阶句法表示和分层注意力网络来进行事件检测。
d)EE-GCN [8],利用了句法依存关系标签并建模了单词间的关系,提出关系感知的聚合模块和上下文感知的关系更新模块。
e)Gated-GCN [19],提出通过门控机制过滤噪声信息,更好地利用依存信息。
f)SA-GRCN [13],引入了一种自我关注机制,以更好地建模单词相关性。
g)MHGEE [20],使用异构图神经网络来聚集相关事件的信息,从而捕获事件之间的相关性。
表1显示了不同方法之间的性能比较。可以观察到,本文的DIGCN模型在触发词识别和分类任务上都有着最高的F1值和召回率。与最佳基线模型相比,在触发词识别任务上召回率和F1值分别提高了2.1%和1.2%,触发词分类任务上召回率和F1值分别提高了2.9%和0.7%。
对于仅使用依存句法结构信息的方法,如GCN-ED、JMEE、MOGANED、MHGEE,表现明显低于其他方法,说明依存标签的类型能够为事件检测提供关键信息,同时MOGANED利用GAT作为基本编码器,在精度方面有所提升,注意力机制有助于句法结构信息的利用,但还是存在细粒度信息不足的问题。DIGCN引入依存类型标签对单词进行增强表示,可以更好地捕获细粒度的触发词相关特征信息,检测到更多的触发词,体现出合理使用句法结构的依存类型标签信息可以提高事件检测的性能。对于通过堆叠多层GCN来捕获多跳信息的方法,如EE-GCN、SA-GRCN,表现好于仅使用句法结构的方法,但不如DIGCN,原因在于本文方法通过构建高阶句法图引入GCN模型来获取多跳信息,克服了过度平滑问题,显示了多阶句法结构的有效性。
3.5 消融实验
本文的DIGCN模型主要由依存信息增强和基于多跳关系的GCN模块组成。为证明每个模块的有效性,针对ACE2005数据集进行消融实验分别验证依存类型标签和多跳信息是否有助于事件检测任务的性能改进。实验结果如表2所示。
a)依存类型标签信息增强(TYPE)。为了研究依存类型标签是否有助于性能改进,取消信息增强表示,类型化的依存类型标签信息被移除。结果F1值下降了1%,表明类型依存标签信息在DIGCN中起着重要作用。
b)多跳信息(multi-hop,MH)。删除多跳信息表示模块,即仅使用一阶句法图来进行实验,会对结果造成F1值的0.8%影响,验证了多阶表示提供的多跳信息为事件检测任务提供了更多的信息。
c)TYPE&MH。同时删除了依存类型标签信息增强模块和多跳信息模块,然后模型退化为普通GCN。可以观察到性能降低了4.8%,再次证实了DIGCN模型的有效性。
d)Bi-LSTM。删除Bi-LSTM模块,模型在两个任务上性能都明显下降许多,说明Bi-LSTM在GCN模型之前可以捕获一些重要的上下文信息,以提高模型在事件检测任务上的性能。
3.6 多阶表示对模型影响
本实验旨在验证多阶表示的阶数及平面结构对于DIGCN模型的影响,分别验证了阶数K在1~3阶及K=1阶时通过叠加GCN层数L获取多跳信息,以及模型在ACE2005数据集上F1性能的变化。
实验结果如表3所示。为了验证阶数K对模型的影响,在对比实验中保持L=1,即本文方法所使用的平面结构。可以发现其他实验结果都低于阶数K=2时的表现,在K=1时的性能最差,表明一阶句法不足以表示上下文的深层语义信息,高阶句法关系在事件检测中发挥着重要作用。性能存在先升后降的趋势,并在K=2时达到峰值,因为大多数高阶路径都是无用的,并且会大大加剧路径稀疏性问题。
为了验证平面结构的有效性,在对比实验中设置阶数K=1,即使用一阶句法图,然后将其变为普通GCN模型,通过叠加GCN层数L来达到捕获多跳信息的效果。观察表3可知,DIGCNK=1,L=2时效果最好,但在触发词分类任务上F1分数较DIGCNK=2,L=1方法低0.8%,说明通过多阶句法图来捕获多跳信息更为有效,同时说明了平面结构的有效性。
3.7 案例分析
为了进一步阐明DIGCN模型性能的优越性,本节给出具体案例的实验结果,比较不同模型对同一个句子的触发词识别与分类的结果。对于此测试中选取的案例如表4所示。
对于第一句话,由于比较简短,Bi-LSTM方法无法提取有效信息,将单词“Explosions”识别为“Attack”类型的触发词;而基于GCN的方法可以根据句法关系判断出单词“Explosions”没有目标,并不是事件的触发词。第二句中“talks”属于出现频率较高的单词,使得事件检测模型无法检测到由“talks”触发的“Meet”类型事件;然而,本文方法考虑了“talks”和其他实体之间的依存标签信息,实现了正确的分类。第三句,普通的基于GCN的方法将其进行了错误归类,可能原因在于单词“Prison”误导,将“taken”归类为“Arrest”类型的触发词;由于本文方法考虑了多跳信息及依存类型,通过路径“taken-given-authorities”和标签(advcl:to,nsubj,compound)的信息對其进行了正确的分类。从以上实验结果可以看出,DIGCN模型不仅能够捕获细粒度的触发词相关特征信息,对具有歧义性的触发词分类也具有明显优势,因此能够更好地完成事件检测任务。
4 结束语
针对句子级别细粒度的事件检测任务,本文提出了一种基于图卷积网络融合依存信息的事件检测模型,使用依存关系标签增强特征表示并引入图卷积网络结合多跳信息。在ACE2005数据集上进行实验,证明了DIGCN模型在事件检测任务上的有效性。在未来的工作中,将考虑将本文工作应用于信息抽取相关的任务上。
参考文献:
[1]陈烨,周刚,卢记仓.多模态知识图谱构建与应用研究综述[J].计算机应用研究,2021,38(12):3535-3543.(Chen Ye, Zhou Gang, Lu Jicang. Survey on construction and application research for multi-modal knowledge graphs[J].Application Research of Computers,2021,38(12):3535-3543.)
[2]Doddington G, Mitchell A, Przybocki M, et al. The automatic content extraction (ACE) program-tasks, data, and evaluation[C]//Proc of the 4th International Conference on Language Resources and Revaluation.Lisbon,Portugal:European Language Resources Association,2004:837-840.
[3]Nguyen T H, Grishman R. Graph convolutional networks with argument-aware pooling for event detection[C]//Proc of the 32nd AAAI Conference on Artificial Intelligence.Palo Alto,CA:AAAI Press,2018:5900-5907.
[4]Liu Xiao, Luo Zhunchen, Huang Heyan. Jointly multiple events extraction via attention-based graph information aggregation[C]//Proc of Conference on Empirical Methods in Natural Language Processing.Stroudsburg,PA:Association for Computational Linguistics,2018:1247-1256.
[5]Yan Haoran, Jin Xiaolong, Meng Xiangbin, et al. Event detection with multi-order graph convolution and aggregated attention[C]//Proc of Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing.Stroudsburg,PA:Association for Computational Linguistics,2019:5766-5770.
[6]Chen Yubo, Xu Liheng, Liu Kang, et al. Event extraction via dynamic multi-pooling convolutional neural networks[C]//Proc of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing.Stroudsburg,PA:Association for Computational Linguistics,2015:167-176.
[7]Nguyen T H, Cho K, Grishman R. Joint event extraction via recurrent neural networks[C]//Proc of Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies.Stroudsburg,PA:Association for Computational Linguistics,2016:300-309.
[8]Cui Shiyao, Yu Bowen, Liu Tingwen, et al. Edge-enhanced graph convolution networks for event detection with syntactic relation[C]//Findings of the Association for Computational Linguistics.Stroudsburg,PA:Association for Computational Linguistics,2020:2329-2339.
[9]Schuster M, Paliwal K. Bidirectional recurrent neural networks[J].IEEE Trans on Signal Processing,1997,45(11):2673-2681.
[10]Hong Yu, Zhang Jianfeng, Ma Bin, et al. Using cross-entity infe-rence to improve event extraction[C]//Proc of the 49th Annual Mee-ting of the Association for Computational Linguistics:Human Language Technologies.Stroudsburg,PA:Association for Computational Linguistics,2011:1127-1136.
[11]Sha Lei, Qian Feng, Chang Baobao, et al. Jointly extracting event triggers and arguments by dependency-bridge RNN and tensor-based argument interaction[C]//Proc of the 32nd AAAI Conference on Artificial Intelligence.Palo Alto,CA:AAAI Press,2018:5916-5923.
[12]Ahmad W U, Peng Nanyun, Chang Kaiwei. GATE: graph attention transformer encoder for cross-lingual relation and event extraction[C]//Proc of AAAI Conference on Artificial Intelligence.2021:12462-12470.
[13]Liu Anan, Xu Ning, Liu Haozhe. Self-attention graph residual convolutional networks for event detection with dependency relations[C]//Findings of the Association for Computational Linguistics.Stroudsburg,PA:Association for Computational Linguistics,2021:302-311.
[14]Xie Zhipeng, Tu Yumin. A graph convolutional network with adaptive graph generation and channel selection for event detection[C]//Proc of AAAI Conference on Artificial Intelligence.2022:11522-11529.
[15]Mi Jiaxin, Hu Po, Li Peng. Event detection with dual relational graph attention networks[C]//Proc of the 29th International Confe-rence on Computational Linguistics.[S.l.]:International Committee on Computational Linguistics,2022:1979-1989.
[16]Chen Yubo, Yang Hang, Liu Kang, et al. Collective event detection via a hierarchical and bias tagging networks with gated multi-level attention mechanisms[C]//Proc of Conference on Empirical Methods in Natural Language Processing.Stroudsburg,PA:Association for Computational Linguistics,2018:1267-1276.
[17]Marcheggiani D, Titov I. Encoding sentences with graph convolutional networks for semantic role labeling[C]//Proc of Conference on Empirical Methods in Natural Language Processing.Stroudsburg,PA:Association for Computational Linguistics,2017:1506-1515.
[18]Kipf T N, Welling M. Semi-supervised classification with graph con-volutional networks[EB/OL].(2017-02-22).https://arxiv.org/pdf/1609.02907.pdf.
[19]Lai V D, Nguyen T N, Nguyen T H. Event detection: gate diversity and syntactic importance scores for graph convolution neural networks[C]//Proc of Conference on Empirical Methods in Natural Language Processing.Stroudsburg,PA:Association for Computational Linguistics,2020:5405-5411.
[20]Zhang Mingyu, Fang Fang, Li Hao, et al. MHGEE: event extraction via multi-granularity heterogeneous graph[C]//Proc of the 22nd International Conference on Computational Science.Cham:Springer,2022:473-487.
[21]Mikolov T, Chen Kai, Corrado G, et al. Efficient estimation of word repre-sentations in vector space[EB/OL].(2013-09-07).https://arxiv.org/pdf/1301.3781.pdf.
收稿日期:2023-03-29;修回日期:2023-05-10
基金項目:国防基础科研计划国防科技重点实验室稳定支持项目;国家自然科学基金资助项目
作者简介:张紫月(1999-),女,湖北襄阳人,硕士研究生,主要研究方向为自然语言处理、事件抽取;王羽(1989-),男,江苏扬州人,工程师,硕士,主要研究方向为自然语言处理;徐建(1979-),男(通信作者),江苏江阴人,教授,博导,博士,主要研究方向为数据挖掘、知识图谱(dolphin.xu@njust.edu.cn).
