基于深度强化学习的无人播种机自动路径规划研究
2023-10-17程力
程 力
(鹤壁职业技术学院,河南 鹤壁 458030)
0 引言
近年来,我国农业生产还是采用传统的经验实现田间作业,需要大量的劳动力,而无人驾驶农机一直是科研人员研究的热门领域之一。随着硬件技术发展的突飞猛进,深度学习和强化学习都有较大的进展。为此,结合深度Q-learning和强化两种学习算法的基础理论,对无人播种机在未知环境下的自动路径规划进行了分析,旨在实现无人化的播种作业。
1 深度强化学习算法原理
1.1 强化学习算法
强化学习是一种将环境状态变化反映到实际行为上的学习,可以通过持续的反馈让后续的动作朝着奖励最大化靠近,在智能控制系统中应用非常广泛。强化学习与监督学习存在一定的差异,其不是采用正、反比例控制系统确定采取何种控制策略,而是将智能体Agent与环境(environment)联系起来,通过迭代的尝试获取奖励最大的工作。正常来说,执行的动作对当前奖励值、下一次奖励值以及整个过程的奖励值都会有影响。
1)Markov决策。按照一定顺序执行的强化学习策略,在处理过程中采用Markov决策建立强化学习模型。Markov决策包括环境状态集合(S)、动作集合(A)、状态转移函数(T)和回报函数(R)等4个方面。
在Markov决策中,智能体Agent与环境二者在进行交互中,先对环境进行实时判断st∈S;然后,根据策略执行当前动作at∈A;最后,根据此次动作的状态转移函数T:S×A→S及环境状态st+1,获得的当前动作奖励值r。Markov决策的原理是将当前环境状态和执行动作后获得的奖励值和此次环境状态和执行动作联系到一起比较,不去关心历史状态及动作引入的奖励值参数。
状态转移函数值V(s)是指利用特定的控制系统,对某一中间状态向目标状态转移过程中强化信号累积加权和的数学期望,其表达式为
(1)
其中,t为时间常量;γ∈[0,1]为折扣比例值域。Markov决策是指在众多策略中选择一个最优的策略,可让强化信号累积值最大化。在时间节点t环境状态s的函数表达式为
(2)
Markov决策算法中,其目的是找到最优解π*,得到过程中智能体Agent学习目标是找到最优策略解π*及最优的状态转移函数,即
(3)
2)强化学习模型。强化学习模型由Agent和环境两部分组成,结构如图1所示。
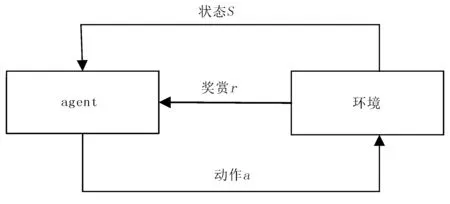
图1 强化学习模型的结构示意图Fig.1 The structure diagram of reinforcement learning model
为了对强化学习系统进行分析,采用三元组描述,其表达式为
(4)
其中,S和A分别为环境状态和动作集合;P为环境状态转移集合;t为时间。
在t和t+1两个时间节点,Agent通过与S的交互,分别获得状态函数变量st∈S和st+1∈S,执行动作为at∈A,获得的反馈奖励值为rt+1。强化系统的最优目标是找到略π*:S×A→S,从而获得最大的奖励值之和。奖励值之和的表达式为
(5)
其中,γ∈[0,1],表示在未来时间节点中奖励值较小的权值。
1.2 深度Q-learning算法
强化学习系统的决策能力有限,故在强化学习系统基础上引入深度Q-learning算法,将二者结合起来,提供无人播种机的感知能力和特征提取能力,从而提高路径规划精度。
深度Q-learning算法是一种在强化学习系统的基础上,引入基于Value-Based的深度学习方法,其通过学习研究对象状态s经过执行动作a后的价值,再根据不同动作的价值使得价值之和最大化,从而得到最优策略。
在无人播种机自动路径规划问题中,可将其周边环境变化看成Markov决策过程,采用五元组(S,A,P,γ,C)对其进行表示。其中,γ和C分别为折扣因子和奖赏值。为了求解最优策略,用值函数V代表策略动作带来的奖赏期望值,即
(6)
其中,E和ct分别为期望值和奖赏值。
采用递归方法对上式进行简化可得
(7)
其中,C(s,a)=E[C(s,a)]为c的平均值;Pss′(a)是状态s到s′之间转移的概率,则
(8)
基于最优策略π,可以得到Q-learning算法的表达式,即
(9)
其中,Qπ(s,a)为基于策略π情形下s到a的期望奖赏值。假设
Q*(s,a)=Qπ*(s)=C(s,a)+
(10)
若设定Q初始值为0,则可以得到Q-learning算法的准则为
(11)
其中,γ∈[0,1)为折扣因子;α为算法的学习效率,即
(12)
将Q-learning算法和无人播种机最优路径求解结合起来,设每组(s,a)值都可以随意变化得到多组奖赏值;若将α慢慢降成0,则Q也会逐渐向1收敛。那么,在无人播种机最优路径求解过程中,只需要不断跟新Q表,便能求得无人播种机路径规划最优解。
2 无人播种机自主路径规划设计
2.1 无人播种机运动模型
以无人播种机为研究对象,为了方便建立运动学模型,假设其由两个后轮和一个具有转向能力的前轮组成,属于具有两轮差分的运动模型。无人播种机实物如图2所示,运动学模型如图3所示。

图2 无人播种机实物图Fig.2 The physical drawing of unmanned planter
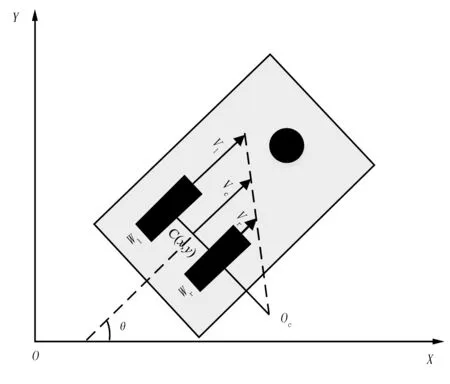
图3 无人播种机运动学模型Fig.3 The kinematic model of unmanned planter
(13)
(14)
将式(13)和式(14)联立起来求解,可得无人播种机的转动半径为
(15)
根据几何关系,可以得到无人播种机的运动学模型为
(16)
2.2 基于RRT算法的自主路径规划
为了实现无人播种机的自主路径规划,选择了强化学习中的快速遍历随机树算法(RRT),对自主路径规划进行改进。RRT算法是一种采用树形数据存储结构,可以在状态空间中建立模型,具有高效的搜索能力,适用于复杂情况下的路径规划。
因此,主要从以下几个变量讨论无人播种机的自主路径规划问题:
1)无人播种机的起始点xinit;
2)无人播种机的目标地点xgoal;
3)状态空间随机采样点的节点xrand;
4)搜索过程中离随机采样点最近的点xnearest;
5)选择随机树新节点xnew;
6)选择新节点的搜索步长ρ;
7)选择随机采样点的判定概率ρsearch。
RRT算法是从起始点开始,按照一定概率在作业周边环境中随机选择采样子节点,从而不断扩大搜索树的规模;当随机树中有子节点已经接近或到达目标点时,停止扩展随机树,此时依次从起始点连接父节点,便能够达到目标地点或者附近,从而获得一条可能的路径。
RRT算法从路径规划任务的起始点开始,以固定概率在环境空间中随机采样子节点,以此来不断扩大随机搜索树的规模;当随机树中的子节点到达了目标点或目标点附近时停止拓展随机树,此时从起始点开始依次连接父节点便可直接到达目标点或其附近,得到一条可行的规划路径。RRT算法结构示意如图4所示。
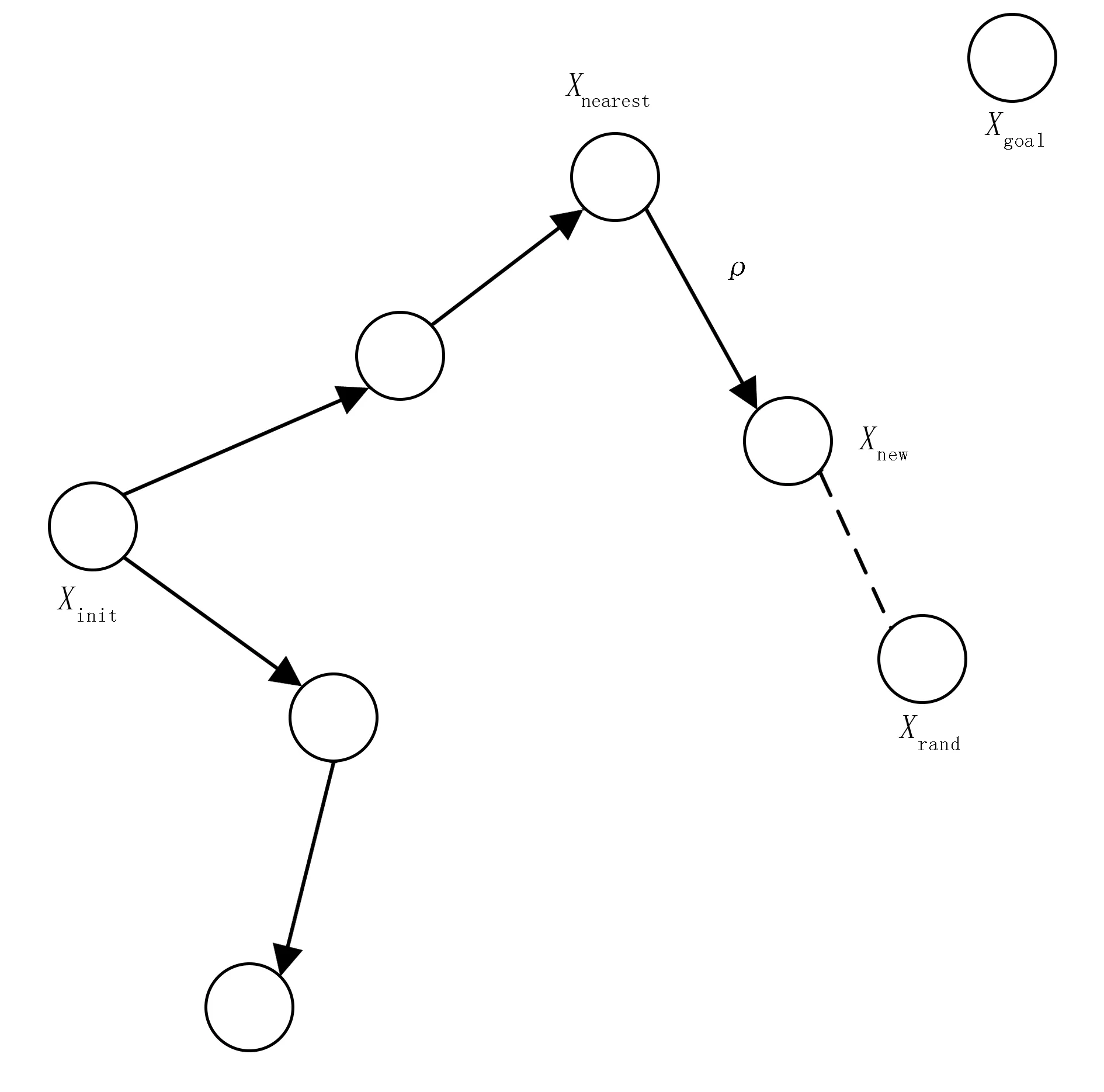
图4 RRT算法结构示意图Fig.4 The structure diagram of RRT algorithm
RRT算法的伪代码如下:
输入:子节点数M,路径规划任务的起点xinit和xgoal
输出:从xinit到xgoal的路径
初始化xinit、xgoal和环境障碍物
for I = 1 to n do
xrand<—Sample(M);
xnear<—Near(xrand,T);
xnear<—steer(xrand,xnear,StepSize);
Ei<—Edge(xnear,xnear);
If CollisionFree(M,Ei) then
T.addNode(xnew);
T.addEdge(Ei);
If xnew=xgoalthen
Success();
3 仿真研究分析
无人播种机的作业环境是固定的,在分析过程中为了便于建立模型和数据处理,将主要环境和无人播种机进行识别建模,对无人播种机作业环境建立栅格进行平面分析与研究。RRT算法的路径规划流程如图5所示。
图6和图7为10×10栅格环境下采用RRT算法对无人播种机的路径规划。在仿真过程中,黑色区域为障碍区域,RRT算法的迭代次数设置为100次。
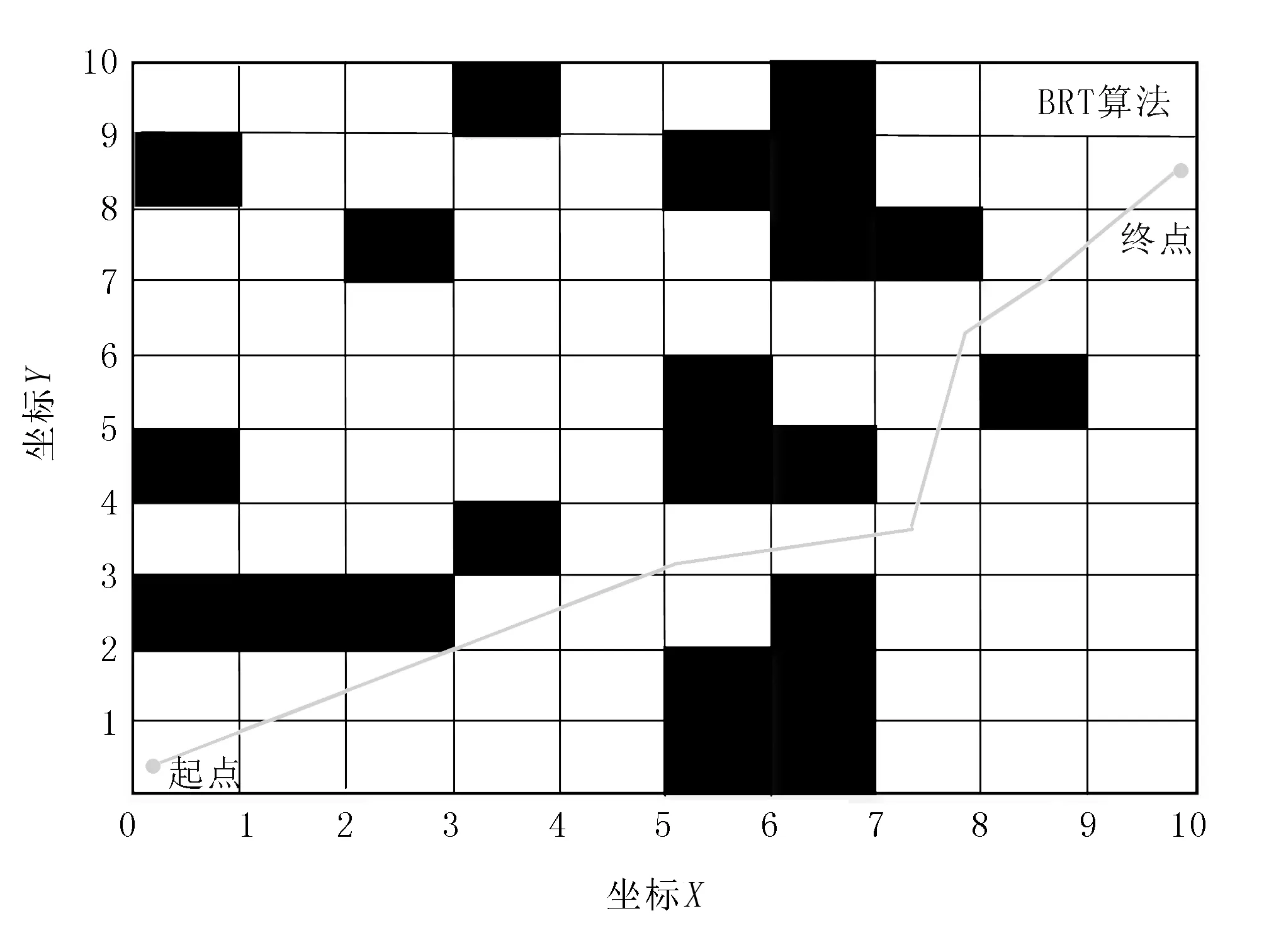
图6 无人播种机的路径规划图Fig.6 The path planning diagram of unmanned planter
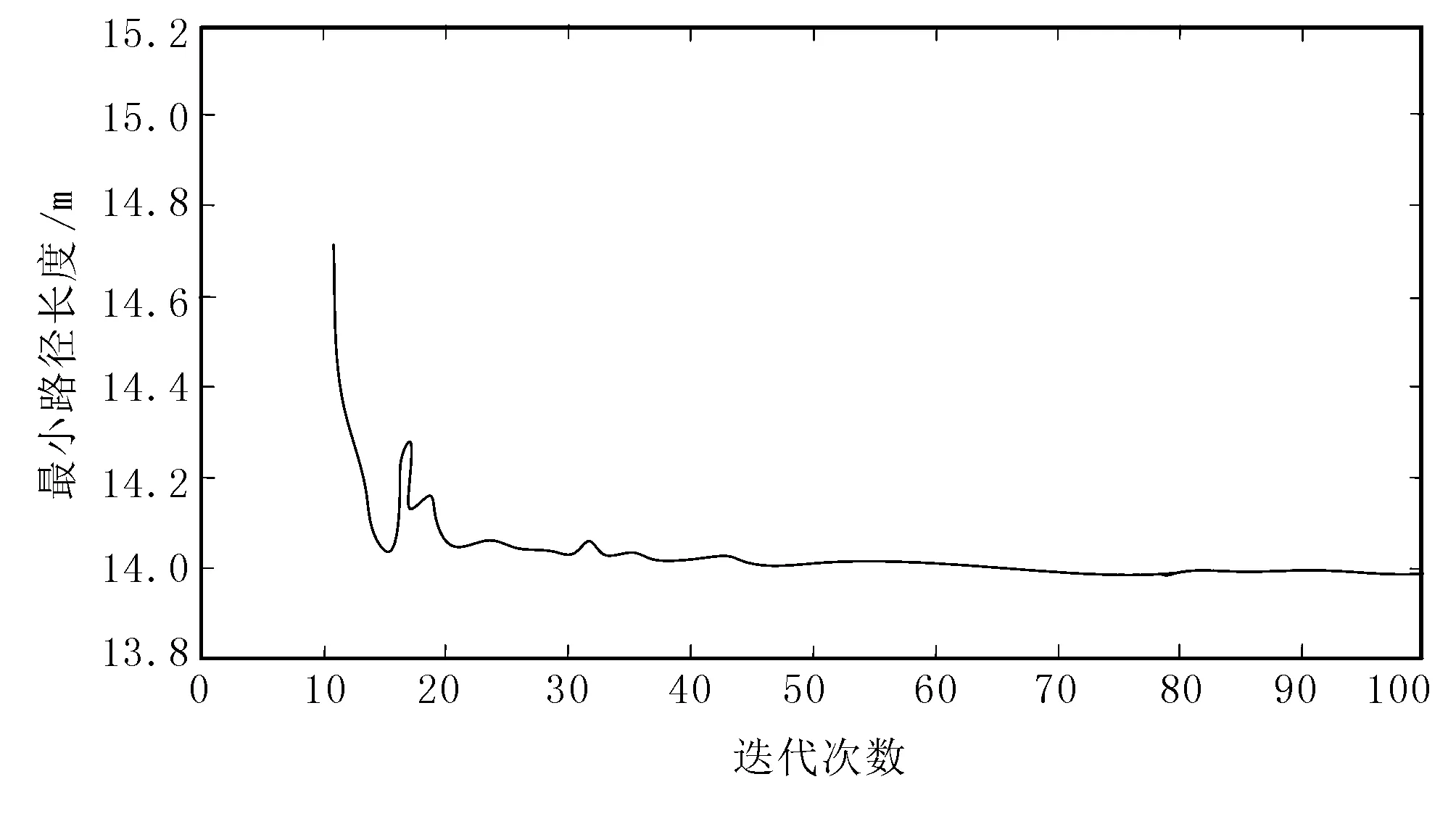
图7 无人播种机路径规划算法收敛图Fig.7 The convergence diagram of path planning algorithm for unmanned planter
由图6可以看出:无人播种机可以顺利避开障碍物从起点行驶到终点,且路径规划合理;由图7可以看出:RRT算法经过50次的测试后,逐渐趋于收敛,稳定性较好。综上所述,提出的RRT深度强化学习算法具有较快的路径规划速度,路径规划效果较优。
4 结论
结合无人播种机路径规划问题,介绍了强化学习和深度Q-Learning算法,并采用RRT深度强化学习算法,对无人播种机自动路径规划进行了研究。RRT深度强化学习算法的仿真试验结果表明:在复杂作业环境中,无人播种机能够在较小的迭代次数下完成最优作业路径的规划,表明算法具有可行性和可靠性。
