基于AE-RCNN的洪水分级智能预报方法研究
2023-10-17苑希民田福昌何立新王秀杰郭立兵
苑希民,李 达,田福昌,何立新,王秀杰,郭立兵
(1.天津大学 水利工程仿真与安全国家重点实验室,天津 300350;2.天津大学 建筑工程学院,天津 300350;3.河北工程大学 水利水电学院,河北 邯郸 075000;4.宁夏回族自治区水旱灾害防御中心,宁夏 银川 750002)
1 研究背景
在气候变化背景下,过去几十年来全球极端降水强度和频率显著上升,引发的洪涝灾害造成每年300亿美元以上的经济损失,给人类社会带来了严重危害[1-2]。洪水预报作为应对洪涝灾害的重要非工程措施之一,对水库调度、防洪预警、城市规划等具有重要指导作用。当前应用广泛的洪水预报模型主要包括概念性水文模型和数据驱动模型。概念性水文模型使用物理和经验参数来概括径流的形成过程,常用的概念性水文模型包括集总式的Tank模型、新安江模型和分布式的TOPKAPI模型、SWAT模型等[3-6]。概念性水文模型应用广泛,在很多流域取得了较好的模拟效果,但其内部不同意义的水文参数相互作用复杂,导致其有很强的不确定性,往往需要大量流域自然地理数据,或借助敏感性分析和优化算法辅助确定参数[7-8]。
数据驱动的洪水预报模型通过挖掘历史数据中驱动因子与目标值之间的关系来预测径流[9],其内部的大量参数通过误差反向传播的方式自动更新,极大减小了率定难度,近年来取得了长足发展。熊怡等[10]提出一种基于自适应变分模态分解和长短期记忆网络的分解-预测-集成月径流预测混合模型,提升了金沙江上游石鼓水文站月径流预报精度。刘媛媛等[11]将数值模型与BP神经网络相结合,提出了一种快速预测城市内涝风险的新方法。Yuan等[12]将ANN模型与Muskingum-Cunge方法相结合,提出一种应用于数据稀缺干旱山区的洪水预报智能模型。Chen等[13]应用CNN神经网络,结合DEM地理特征和历史径流过程对洪水过程进行预测,在洪峰和到达时间方面表现出了更好的准确性。数据驱动模型的效果主要受训练数据和模型结构影响,当输入数据与目标数据相关性不显著时可能会出现模型难以收敛的情况,而模型复杂度较高时则可能出现梯度消失的问题。
当研究区域的产汇流特性较为复杂时,洪水预报模型使用一套参数往往难以实现对洪水过程的准确模拟,此时可对降雨径流数据进行分级处理,数据特征相近的洪水共用一套模型参数以提高洪水预报的准确性[14-16]。李志超等[17]利用径向基函数神经网络和降雨方差对洪水进行分级预报,提高了模型在四川省寿溪流域和陕西省青阳岔流域洪水预报的准确性。Xu等[18]根据降水的时空分布、降水强度的时间方差和其他水文因子,对历史洪水进行K均值聚类,并采用粗糙集提取实时洪水预报的识别规则,提高了洪水预报准确性。郑彦辰等[19]将降雨时空分布特征作为洪水分类依据,聚类得到的不同洪水类型特征显著。以上研究使用不同聚类算法进行了洪水分级,但面对复杂的降雨流量序列,原始数据包含大量冗余信息,直接进行聚类计算量过大,通常是选取特定的数据特征进行聚类。其中数据特征的选择往往依赖于研究人员的自身经验,选定数据特征对原始数据的描述效果亦难以评定,可能丢失大量有效信息。
因此,本文提出一种结合自编码器(Autoencoder,AE)与残差卷积神经网络(RCNN)的洪水分级智能预报方法,使用自编码器实现原始降雨径流数据的自动降维,再将降维后的数据通过K均值聚类算法进行洪水分级,最后利用残差卷积神经网络进行洪水预报。将AE-RCNN模型应用于小清河流域上游黄台桥水文站的洪水预报,并与使用未分级数据训练的CNN、RCNN模型,以及应用降雨数据进行分级训练的RCNN模型进行对比,验证了AE-RCNN模型的聚类和预报效果。
2 研究区域概况
黄台桥水文站位于济南市历城区华山镇前进桥,控制流域面积321 km2,是泰沂山北漏水区区域代表站,还是济南市重要防洪除涝河道小清河干流上的省级重点水文站(如图1),属于华北暖温带半湿润季风型大陆性气候,年内四季分明,温差变化大;夏季炎热,气温较高,暖空气活动较频繁,雨量较多。2007年7月18日,济南市发生强降雨,降雨集中、汇流迅速,最大点雨量高达182.7 mm,平均降雨82.3 mm,导致径流峰高量大,黄台桥水文站超警戒水位1.04 m,最终济南市直接经济损失达12.3亿元。针对黄台桥水文站展开洪水预报研究对于小清河干流与济南市城区防洪排涝具有重要意义。

图1 研究区域示意图
本次研究收集了流域内1987—2019年间部分年份的降雨数据与黄台桥水文站流量数据。通过对降雨数据进行反距离权重插值得到黄台桥汇水区形心降雨量,与黄台桥水文站流量数据结合得到27场洪水的逐时降雨径流数据。
3 研究方法
3.1 数据降维模型自编码器(AE)是一种自监督学习的神经网络架构(如图2),通过将原始数据输入一个编码器网络编码成一个固定维度的隐藏变量,然后使用一个解码器网络对这个隐藏变量进行解码,从而得到输出数据。自编码器的目标是使得输出数据与原始数据之间的误差最小化,可以用于多种任务,例如数据去噪、降维、生成式模型等[20]。编码器网络在将原始数据映射到低维隐藏向量后,可以通过解码器网络得到与原始数据相似的输出,这表示隐藏向量中保留了原始数据的基本特征,因此将降维后的隐藏向量应用于聚类算法能够在大幅降低计算复杂度的同时实现对原始数据的聚类,这也避免了传统聚类算法人为选择数据特征带来的不确定性。
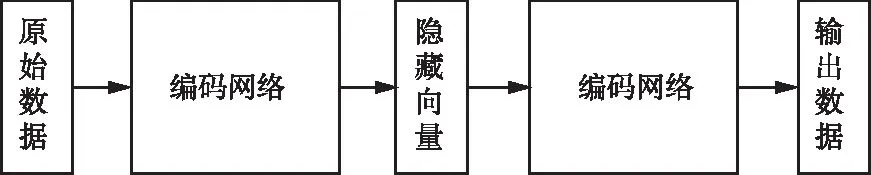
图2 自编码器结构示意图
3.2 洪水分级模型K均值聚类算法是一种广泛应用的无监督学习算法,可以将集中的数据分成K个不同的簇(类别),具有简单易懂、计算效率高的特点[21]。该算法的核心思想是通过计算数据点之间的距离来将它们划分为K个簇,使得同一簇内的数据点彼此相似度较高,而不同簇之间的数据点差异较大。具体来说,K均值聚类算法首先随机初始化K个聚类中心,然后将每个数据点分配到与其最近的聚类中心所在的簇,接着更新每个簇的聚类中心,直到达到收敛条件为止。
3.3 洪水预报模型卷积神经网络(Convolutional Neural Network,CNN)是一种广泛应用于图像识别和语言处理的前馈神经网络,其内部的卷积运算可以提取输入数据的局部特征,根据输入数据的维度不同可分为Conv1d、Conv2d、Conv3d等。水文预报的时序数据可近似理解为自然语言处理中的一个句子,仅包含沿时间的一个维度,因此采用Conv1d进行预报。一维卷积的计算过程如图3所示,通过卷积核在输入数据上的移动提取局部信息,padding用于填补数据两侧的空缺,stride为卷积核移动的步长,具体计算公式如下[22]:
(1)
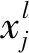
在卷积神经网络中,随着模型隐藏层和通道数量增加,可产生大量模型参数学习到更多信息特征,但这样也容易造成梯度消失等问题。残差网络(Residual Network)是一种针对梯度消失问题的特殊网络结构,能够极大提高模型的有效训练深度。传统神经网络的信息通过层层递进的方式向前传播,而残差网络通过跳层连接实现了信息从低层到高层的直接传播,以此达到缓解梯度消失的目的[23]。如图4所示,残差网络将上层输入的x跳层与卷积运算后得到的F(x)进行相加作为输出H(x),当F(x)=0时,H(x)=x,形成恒定映射,以保留上层输入特征,避免梯度消失问题。
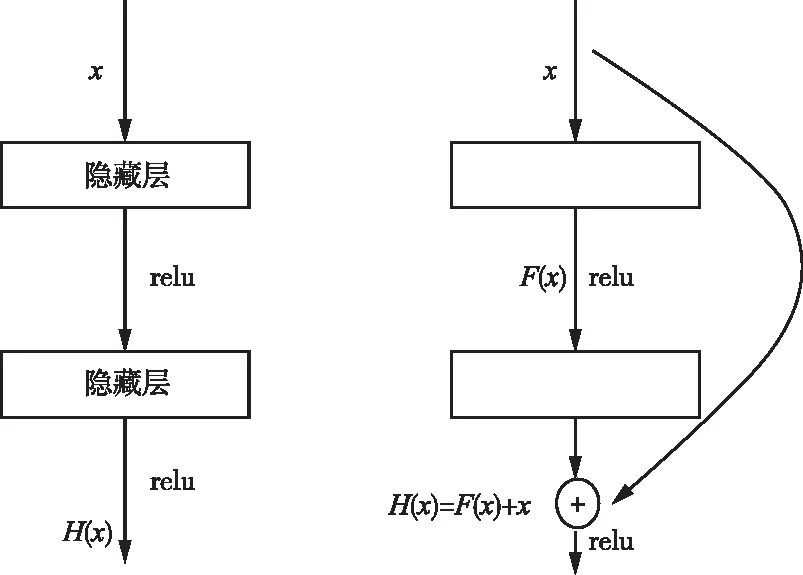
图4 传统网络与残差网络对比图
3.4 AE-RCNN洪水分级智能预报方法综合上述理论方法,本文提出的AE-RCNN洪水分级智能预报方法训练流程如图5所示,其主要训练步骤包括:①将原始的降雨流量数据分别归一化至[0,1]区间内,输入到AE数据降维模型中进行数据重构,以重构数据的误差作为损失函数进行网络训练,待训练完成得到原始数据在AE数据降维模型中的隐藏向量;②对步骤1中得到的隐藏向量进行K均值聚类,根据聚类结果对原始数据进行分类,并将隐藏向量的聚类中心输入AE数据降维模型的解码器得到原始数据的聚类中心,作为后续实际应用时进行洪水分级的依据;③按照步骤2中的洪水分级结果分别进行RCNN洪水预报模型的训练,保存生成的K类模型参数。
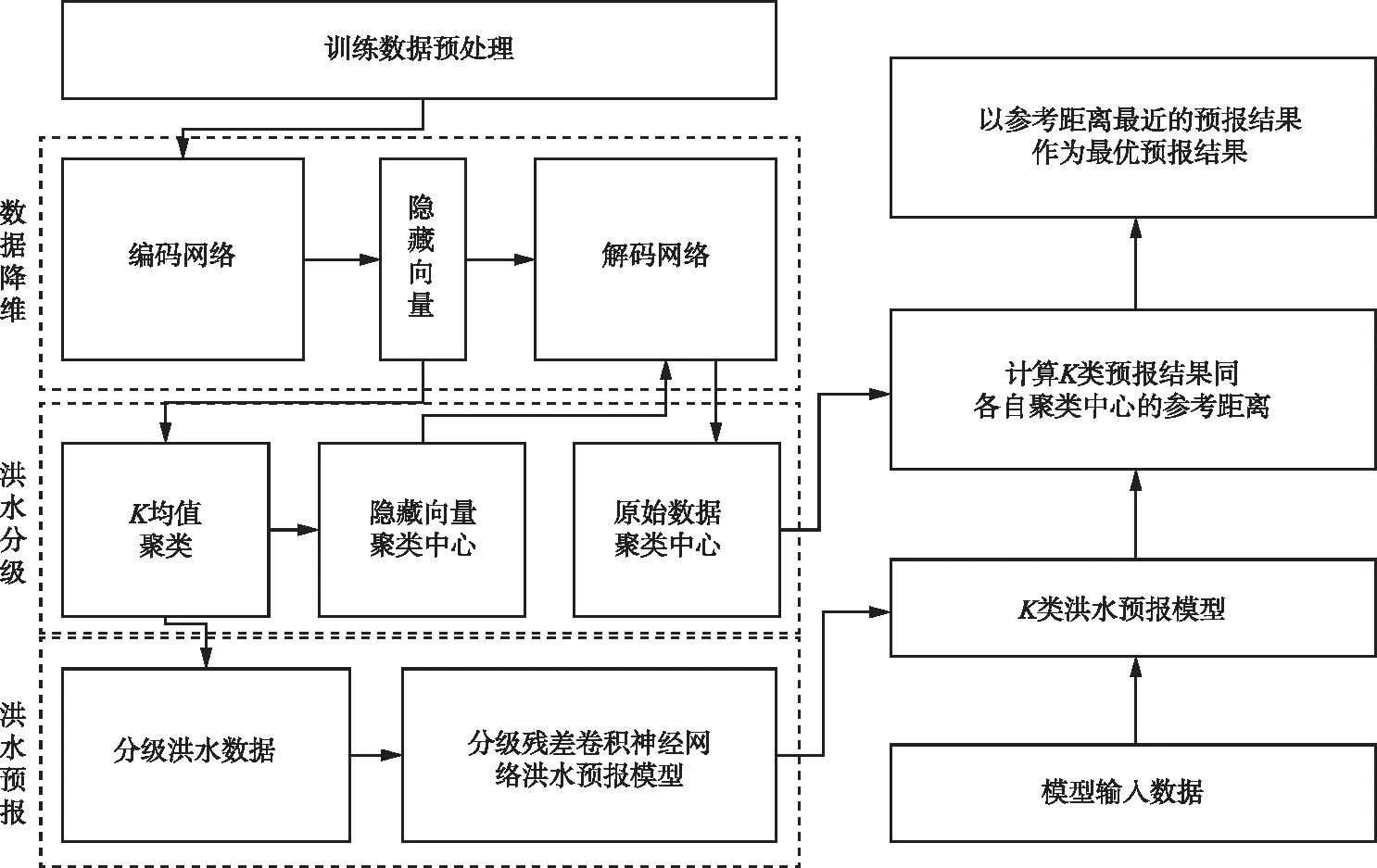
图5 AE-RCNN模型训练预报流程图
在应用训练好的模型进行洪水预报时,需要将数据分别输入K类RCNN洪水预报模型中得到K类预报结果,再将预报结果和各自聚类中心按洪峰时刻对齐,计算二者交集的欧氏距离作为参考,以参考距离最近的预报结果作为最优预报结果,参考距离的具体计算公式如下:
(2)
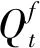
3.5 模型评价指标选取误差平方和(SSE)与轮廓系数(Silhouette Coefficient,SC)作为聚类效果的评价指标[24],主要用于确定K均值聚类算法的聚类中心数量和评估聚类效果,具体计算公式如下。
(3)
式中:Sj为第j个聚类;cj为第j个聚类中心;x为属于第j个聚类的数据点;K为聚类中心数量。
(4)
(5)
式中:ai为数据点xi与所属簇内其它样本的平均距离,若簇内仅一个样本,则令SCi=0;bi为数据点xi与其它簇的样本平均距离的最小值;N为全部数据点的数量。
选取平均绝对误差(MAE)、均方根误差(RMSE)和纳什效率系数(NSE)作为洪水预报效果评价指标,具体计算公式如下。
(6)
(7)
(8)
4 结果分析
4.1 模型构建通过调整模型不同隐藏层卷积核的数量、大小、步长和填充参数,减小数据的时间分辨率(序列长度)并增加数据的通道深度,以提高模型对数据全局特征的学习能力。同时选用LeakyReLU作为激活函数,LeakyReLU解决了Sigmoid容易梯度消失和ReLU神经元死亡的问题,且相比ELU在训练中速度更快[25]。选用SmoothL1Loss作为损失函数,SmoothL1Loss与平均绝对误差L1Loss相比平滑了趋近于0时的误差,与均方误差MSE相比对离群点更不敏感,增加了训练过程的稳定性[26]。
结合黄台桥水文站汇水区域特点与历史洪水资料,选取洪峰前后各24 h的降雨数据48维、流量数据48维共计96维向量作为AE数据降维模型的编码器输入,输出5维隐藏向量到解码器中进行数据重构。选取预报时刻前12 h的降雨流量数据和预见期(24 h)内的降雨数据作为洪水预报模型输入,通过两个RCNN网络提取前期降雨流量特征和预见期内降雨特征,将两类特征拼接后通过反卷积层实现对预见期内流量过程的预报。具体模型结构参数如表1、表2所示。
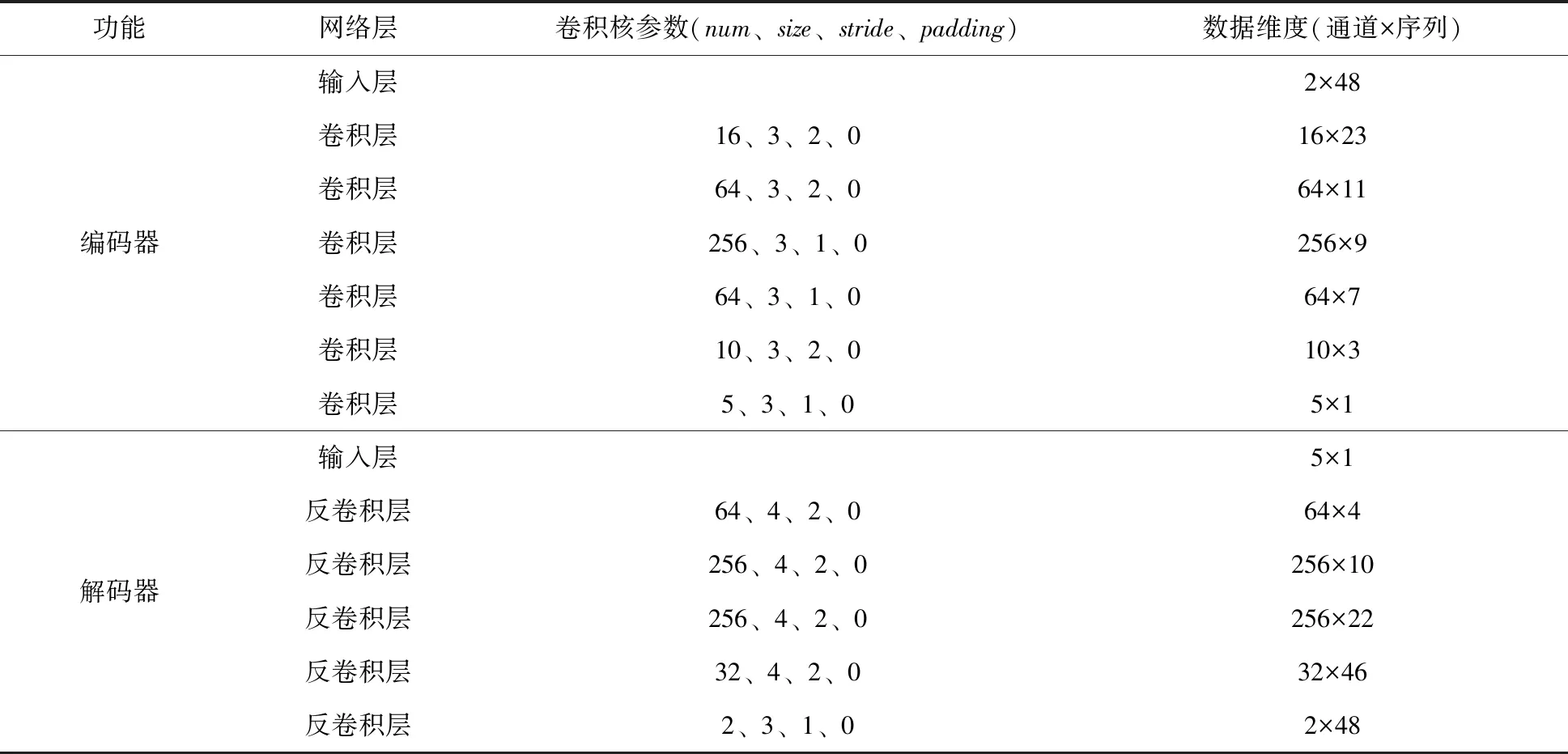
表1 AE数据降维模型结构参数
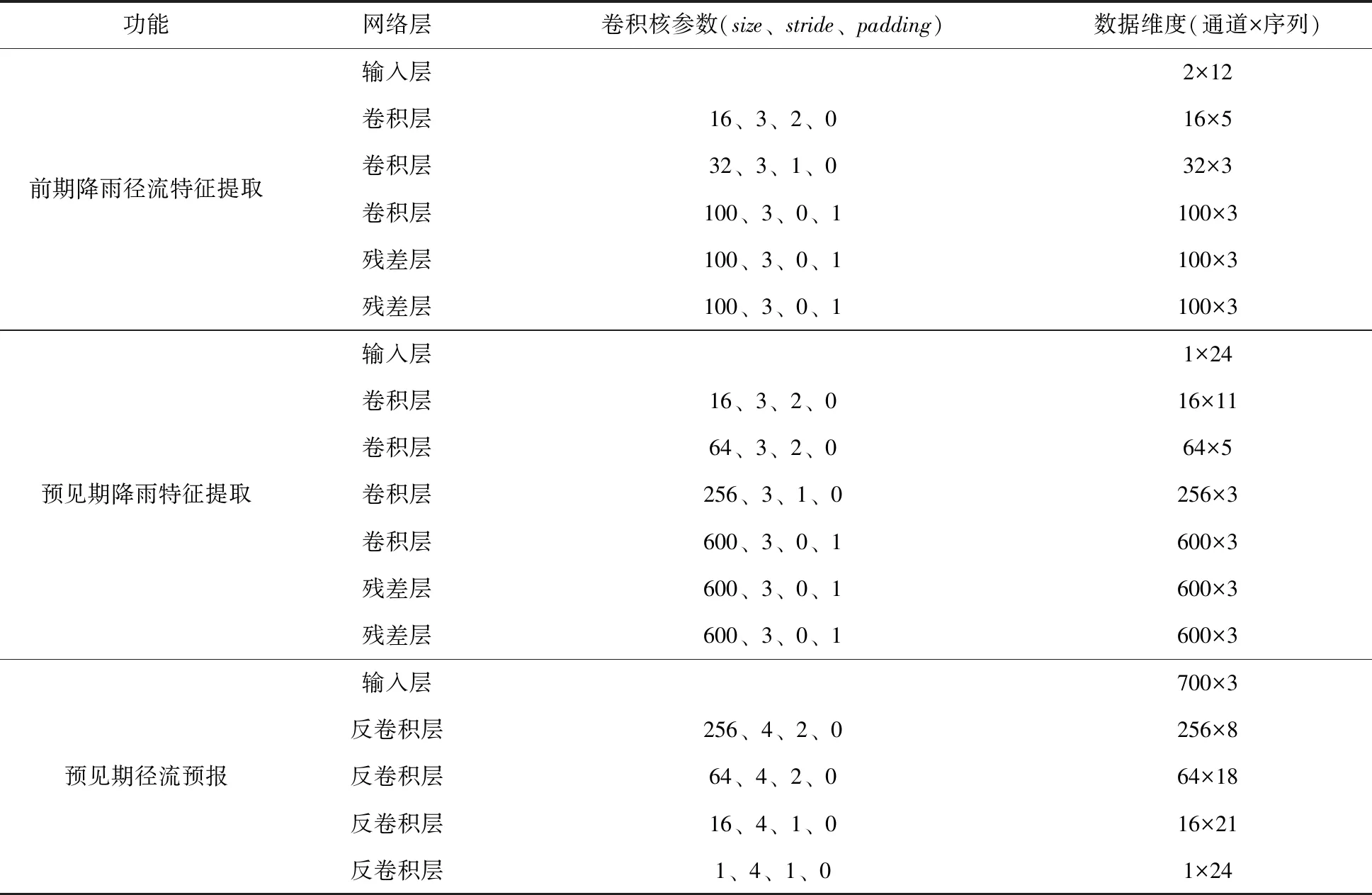
表2 RCNN洪水预报模型结构参数
4.2 数据降维结果分析在对构建的AE数据降维模型进行500次训练后,通过5维隐藏向量解码得到的重构流量数据误差为8%,重构降雨数据误差为11%,部分重构降雨流量数据与原始数据对比如图6所示,其中重构流量数据能够反映原始数据的整体趋势,且在散点图中不同量级流量条件下表现出较为一致的重构效果。而重构降雨数据能够基本还原主要降雨过程,但降雨量较小时的重构效果略显不佳,其散点图也表现出相同的特点,部分较小的降雨存在重构值等于0的情况,但仍能保留原始数据大部分的降雨特征。由此可见,AE数据降维模型能够利用编码器得到的隐藏向量实现对原始降雨流量数据的基本还原,可以使用隐藏向量作为降维后的原始数据进行聚类分析。
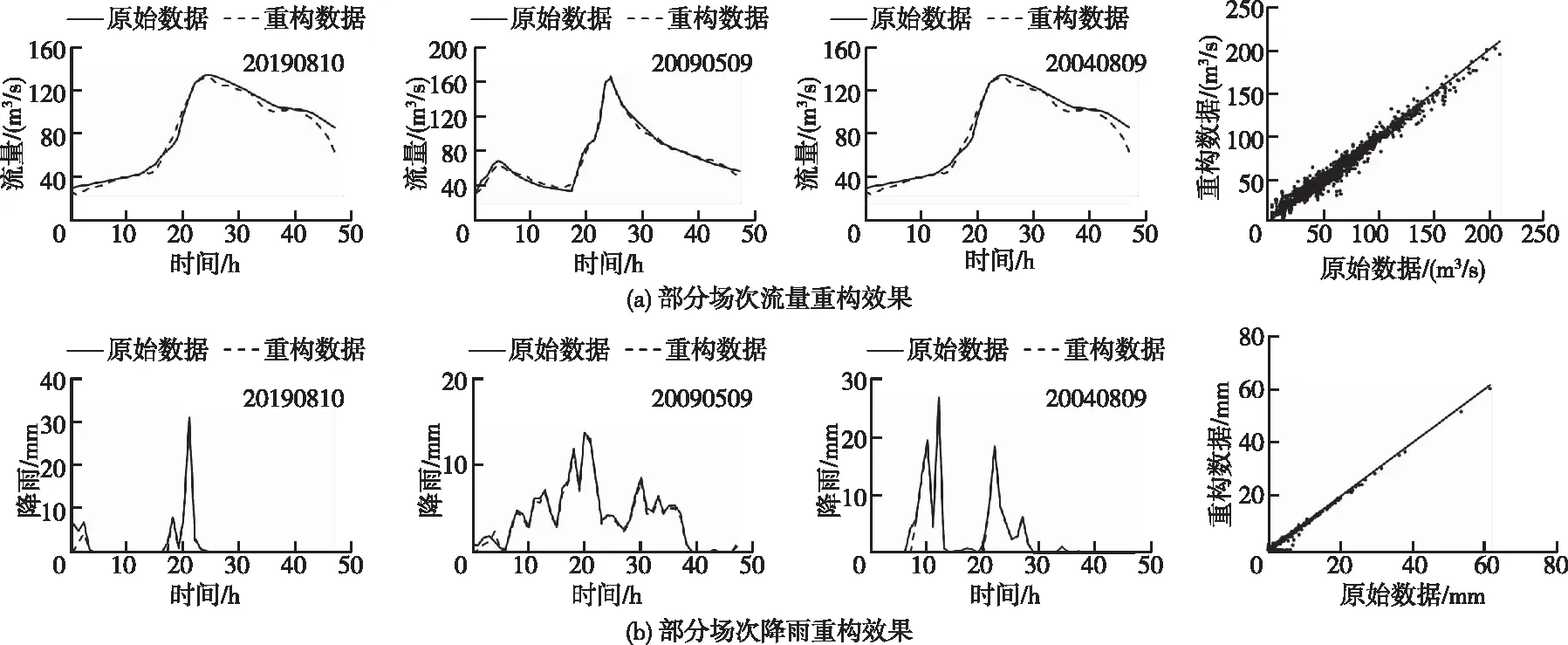
图6 AE数据降维模型重构数据效果
4.3 洪水聚类结果分析对AE数据降维模型中编码器得到的隐藏向量进行不同数量聚类中心的K均值聚类,计算其SSE和SC,并将SC同直接应用原始降雨数据的聚类结果进行对比,如图7所示。其中SSE下降速度突然变缓的拐点处对应的聚类中心数量被认为具有更好的聚类效果(肘部法则),SC则用于描述聚类后的轮廓清晰度,SC>0即代表聚类结果是相对紧凑的,SC越大则轮廓越清晰。在不同聚类中心数下,SC1均大于SC2,表明应用AE降维数据的聚类效果优于直接应用原始降雨数据。且当聚类中心为3时,SSE下降速度突然变缓且SC1最大,因此确定聚类中心K为3。
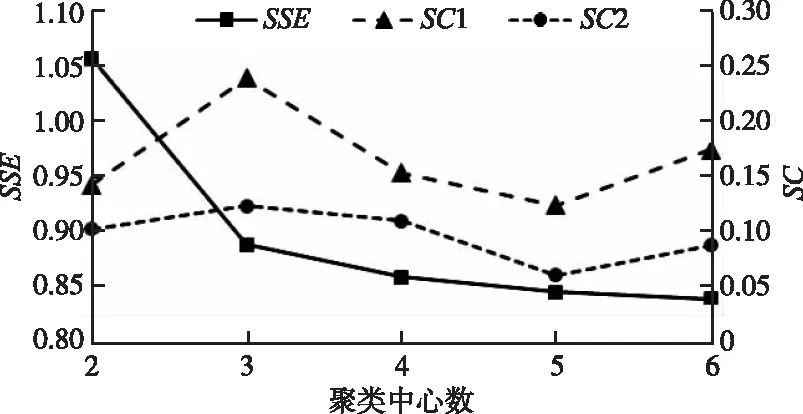
(图中SSE、SC1为应用AE降维数据的聚类结果,SC2为应用原始降雨数据的聚类结果)图7 SSE、SC随聚类中心数变化图
最终隐藏向量被分为3类,各类分别包含6、7、13场洪水,将各隐藏向量聚类中心输入到AE数据降维模型的解码器中得到原始数据聚类中心如图8所示,类别1的洪峰流量为134.81 m3/s,最大24 h洪量为867.95万m3,最大3 h降雨量为29.67 mm,最大24 h降雨量为104.95 mm;类别2的洪峰流量为138.29 m3/s,最大24 h洪量为718.13万m3,最大3 h降雨量为45.99 mm,最大24 h降雨量为69.23 mm;类别3的洪峰流量为112.32 m3/s,最大24 h洪量为506.28万m3,最大3 h降雨量为32.10 mm,最大24 h降雨量为50.62 mm。其中类别1的降雨持续时间较长,最大24 h降雨量最高,且最大24 h洪量也更多。类别2与类别3的最大3 h降雨量更高,但类别2的降雨量级比类别3大,对应的洪峰流量也更高。三种类别洪水的聚类中心存在明显差异,聚类结果可信度高。
4.4 洪水预报结果分析将洪水数据按AE降维数据的聚类结果进行分级RCNN洪水预报模型训练,选取15%的洪水数据作为测试集,以CNN、RCNN模型和降雨聚类RCNN模型作为对比,最终预报效果评价指标如表3、表4所示。RCNN模型在训练集和测试集中的模拟效果均优于CNN模型,表明RCNN模型中的残差网络结构能够提升CNN的预报精度,更好地挖掘数据特征。AE-RCNN模型预报结果的评价指标优于作为对比的其他三种模型。在测试集的洪水模拟中,AE-RCNN模型的平均MAE、RMSE和NSE指标分别为5.04、7.91和0.92,较CNN模型分别提高了48.23%、43.94%和22.32%;较RCNN模型分别提高了35.06%、34.70%和11.72%;较降雨聚类RCNN模型分别提高了26.45%、30.58%和11.29%。同时在将测试集输入到K类AE-RCNN模型后的预报结果中,参考距离最小的预报结果模拟效果也最好,因此本文所提出通过参考距离判断未来洪水类别的方法是合理可行的。
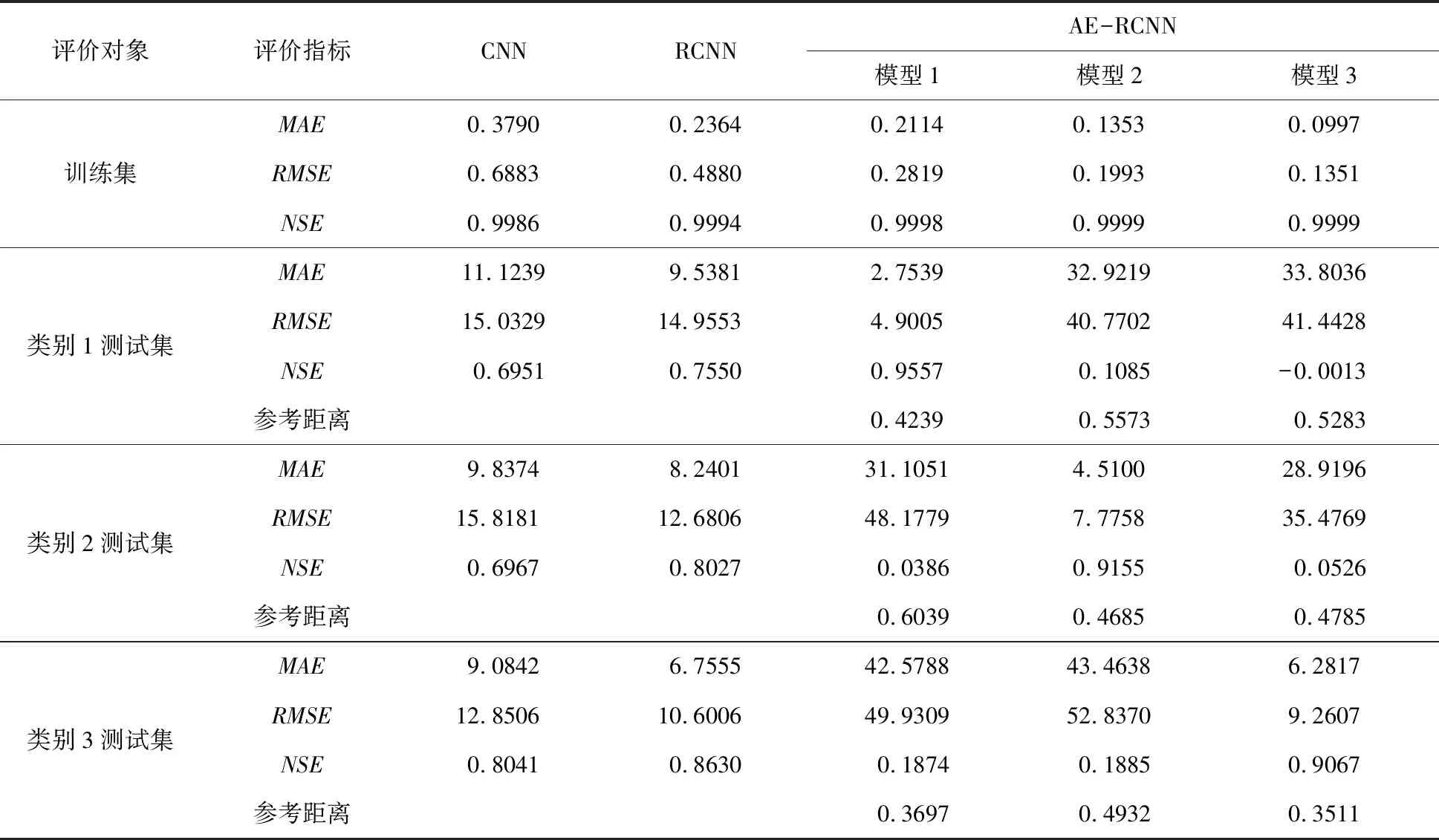
表3 CNN、RCNN、AE-RCNN模型洪水预报效果评价指标对比

表4 降雨聚类RCNN模型洪水预报效果评价指标
不同模型对测试集洪水的模拟效果如图9所示,其中AE-RCNN模型的模拟结果与实测洪水过程最为接近,散点图也距离标准线更为紧密。综上可得,AE数据降维模型能够通过对不同产汇流特性洪水的特征提取与快速聚类,使输入RCNN的数据特征更为清晰,进而达到更好的模拟效果。

图9 部分场次模拟洪水过程与整体测试集模拟结果散点图对比
5 结论与展望
本文提出一种基于AE-RCNN的洪水分级智能预报方法,通过自编码器(AE)重构降雨径流数据实现对其自动降维,再结合K均值聚类算法进行洪水分级,对分级后的洪水使用残差卷积神经网络(RCNN)进行洪水预报。将该方法应用于小清河上游黄台桥水文站的洪水预报中,分析其聚类效果和洪水预报能力。主要结论如下:
(1)AE数据降维模型的编码器可将降雨、流量数据共96维输入向量提取为5维向量,经解码器还原后与原始数据的降雨径流过程基本一致,实现对洪水数据的自动降维,避免人工挑选数据特征对工作人员经验的依赖性。应用AE降维数据的聚类效果优于直接应用原始降雨数据,可将洪水分为特征明显的三类。
(2)对比应用降维数据进行洪水分级的AE-RCNN模型和CNN模型、RCNN模型、降雨聚类RCNN模型,AE-RCNN模型在训练集和测试集中的各项评价指标均为最优。其测试集洪水模拟的平均MAE指标、RMSE指标、NSE指标分别为5.04、7.91、0.92,较CNN模型分别提高了48.23%、43.94%和22.32%,较RCNN模型分别提高了35.06%、34.70%和11.72%,较降雨聚类RCNN模型分别提高了26.45%、30.58%和11.29%。
(3)本文提出的AE-RCNN洪水分级智能预报方法主要应用了自编码器的降维功能,后续可考虑自编码器的变种VAE、VAE-GAN等数据生成模型,使模型在重构提取数据特征的同时,能够生成具备原始数据基本特征但又有一定差异的新数据,对训练集进行扩充以进一步提高模拟效果。
