基于GlobeLand30 的智能解译样本动态制备方法
2023-10-17何翔宇陈建胜陈静波邓毓弸张学华
陈 静,何翔宇,陈建胜,陈静波,邓毓弸,张学华
(1.中国科学院空天信息创新研究院,北京 100101;2.中国科学院大学电子电气与通信工程学院,北京 101400;3.军委后勤保障部工程质量监督中心,北京 100142;4.应急管理部国家减灾中心,北京 100124)
利用美国Landsat、欧盟Sentinel、中国环境减灾和高分系列等公益型中分辨率卫星遥感数据,开展全球土地覆盖/土地利用制图研究是卫星遥感应用的热点方向之一,可用来分析城市扩张特性及城市新增设施变化[1]、陆地生物群落划分[2]等。目前,典型 数 据 产 品 有30 m 地 表 覆 盖 数 据GlobeLand30[3]、10 m 地表覆盖数据FROM-GLC10[4]、30 m 不透水面覆盖数据MSMT-2015map[5]等。其中,GlobeLand30是发布时间较早、分辨率达30 m 的全要素地表覆盖数据产品,已经发布的V2000、V2010、V2020 3 个版本形成了时间序列数据,且最新发布的2020 版本产品,在10 个一级地物要素(耕地、林地、草地、灌木地、湿地、水体、苔原、人造地表、裸地、冰川永久积雪)中取得了高于80%的总体分类精度。作为中国向联合国提供的首个全球地理信息公共产品,GlobeLand30 为可持续发展、环境变化等相关研究提供基础信息。
为了兼顾全球地表覆盖制图的精度和效率,目前GlobeLand30 生产采用的是像素-对象-知识(POK)方法。基于30 m 空间分辨率的Landsat-8 和环境卫星数据,将自动分类器与人机交互操作进行结合,由分类和确认2 个阶段构成,分类阶段利用监督分类算法(最大似然、支持向量机等机器学习模型)得到像素级的单类分类结果,并与多尺度影像分割得到的同质对象相结合,以多数准则、辅助数据表达作为决策规则,自动或手工开展逐对象的类别标记;确认阶段则是在先验知识指导下确认分类结果,有效避免椒盐噪声等问题[6]。
相较于传统的随机森林、支持向量机等经典机器学习模型,以卷积神经网络(CNN)为代表的端到端深度学习模型,在遥感影像分类中具有更高的精度优势,越来越多的学者在大区域地表覆盖制图时,开始使用有监督的深度学习语义分割模型。然而,基于监督学习的深度学习模型训练需要地物多样、影像丰富、可扩展的样本数据作为支撑,应用场景多样、数量可扩展的样本集更能满足应用需求[7]。考虑到GlobeLand30 已经有V2000、V2010、V2020 3 个版本的历史数据,基于历史数据生成样本集,并用于训练适应新数据的模型,既能满足样本集的数量和质量要求,又能保证数据源和分类体系等任务属性的一致。
本研究面向GlobeLand30 数据产品智能化生产对样本集的需求,提出了根据待分类影像特征从历史数据产品中动态制作样本集的方法,利用深度学习模型快速实现遥感影像地物类别像素级划分,实现GlobeLand30 数据的快速、高效制作。
1 遥感智能解译研究现状
1.1 全球地表覆盖遥感智能解译
早期的全球地表覆盖产品[8]生产采用归一化植被指数(NDVI)、频率比(FR)等参数区分地物,但是生产所使用的遥感影像分辨率为300 m 至1 km,Herold 等[9]通过一致性试验证明,对于特征相近类别的分类需要更高分辨率的数据才能准确识别。
2013年,Yu等[10]基于Landsat TM和ETM+数据生产了第一份30 m分辨率的全球地表覆盖产品FROMGLC,经过支持向量机(SVM)算法优化后,总体分类精度为64.9%,并采用融合更高分辨率影像分割像素的方法,将FROM-GLC 产品精度提升至67.08%;2014 年,采用POK 算法将全要素数据产品30 m 地表覆盖数据GlobeLand30 的分类精度提升至80%。
近年来,随着深度学习语义分割方法发展及其在遥感影像分类中的精度优势,越来越多的研究开始使用深度学习语义分割代替传统机器学习,实现大区域地表覆盖制图。党宇等[11]利用AlexNet 深度卷积神经网络进行地表覆盖分类,在空间分辨率1 m 的光学遥感影像上,耕地、房屋2 类图斑的正确分类精度高达99%;朱明[12]以空间分辨率0.8 m 的光学遥感影像作为数据源,设计了地表覆盖分类卷积神经网络(LCC-CNN)来提取水面、建筑物等8 种地表类型,总体精度高于SVM 和随机森林算法。
相较于传统算法,深度学习算法不仅拥有更高的分类精度,而且减少了影像特征选择和人工调整阈值的复杂步骤。因此,在深度学习语义分割框架下研究中分辨率光学卫星影像的智能解译方法,是以较少人力成本实现GlobeLand30 周期性生产的必然需求。
1.2 遥感解译样本集制作
深度学习算法属于监督学习范畴,模型的性能高度依赖于大规模、高质量的样本数据,目前已经有大量开源的遥感影像语义分割数据集可用于不同模型性能比测、模型预训练等场景,如GID[13]、38-Cloud dataset[14]、SkyScapes[15]、SEN12MS[16]等。但是,现有开源数据集与GlobeLand30 的数据源、分类体系不同,不能直接用于GlobeLand30 产品的模型训练。
基于GlobeLand30 历史数据,生产用于模型训练的新数据,既能满足样本集的数量和质量要求,又能保证数据源和分类体系等任务属性的一致,是最可行的样本集制作策略。常规的样本制作思路为静态制作,即将全部历史数据制作成大规模的语义分割样本集用于模型训练。静态制作的样本集在全球地表覆盖类型分类时存在3 方面不足。①模型精度不高。样本集的数据分布特征决定了深度学习模型训练的优化方向,待分类影像与样本集数据分布差异大会导致模型分割结果精度降低[17]。②模型训练效率低。GlobeLand30-2020 覆盖了全球1.49 亿km2的陆地面积,即使不考虑样本重叠率、影像黑边等影响,也至少得到约100 万对512 px×512 px 的样本图像,大量数据集不仅需要耗费很多的内存进行存储与读取,还降低了检索和训练的效率。③样本集灵活度不足。语义分割模型骨干网络规模、结果拼接策略等重新设定时,样本集的输入尺寸、重叠率、波段组合等也会发生变化,预先生成的固定样本集难以适应多样性需求。
本研究面向GlobeLand30 数据智能生产需求,提出遥感数据集动态构建方法。区别于静态制作,动态制作无需在模型训练前将全部历史数据制备为样本集,只需要按当前任务需求实时选取相应的影像制作样本集。
2 方法
2.1 研究路线
动态样本集制作是根据当前任务的待分类影像,在历史影像中自动检索与待解译影像具有相似数据分布的历史影像,通过降低样本集和待分类影像间数据分布差异提高模型域适应能力及精度,基于相似区域规模适中的样本集提高模型训练效率,利用可配置的参数动态按需制作样本,从精度、效率、灵活性方面提高深度学习语义分割在Globe-Land30 数据生产中的应用能力。
数据集动态构建算法技术路线如图1 所示,从历史影像中检索出与待分类影像具有相似特征的数据,其问题的核心是影像相似度分析。首先,利用光谱相似度、纹理相似度和空间邻近度3 种低层特征相似度分析策略,迅速从历史数据中检索待分类影像的K 近邻相似影像;其次,动态制作样本集;最后,构建 以EfficientNet-B3[18]为 骨干网络的U-Net[19]模型,实现待分类影像的地物分类。
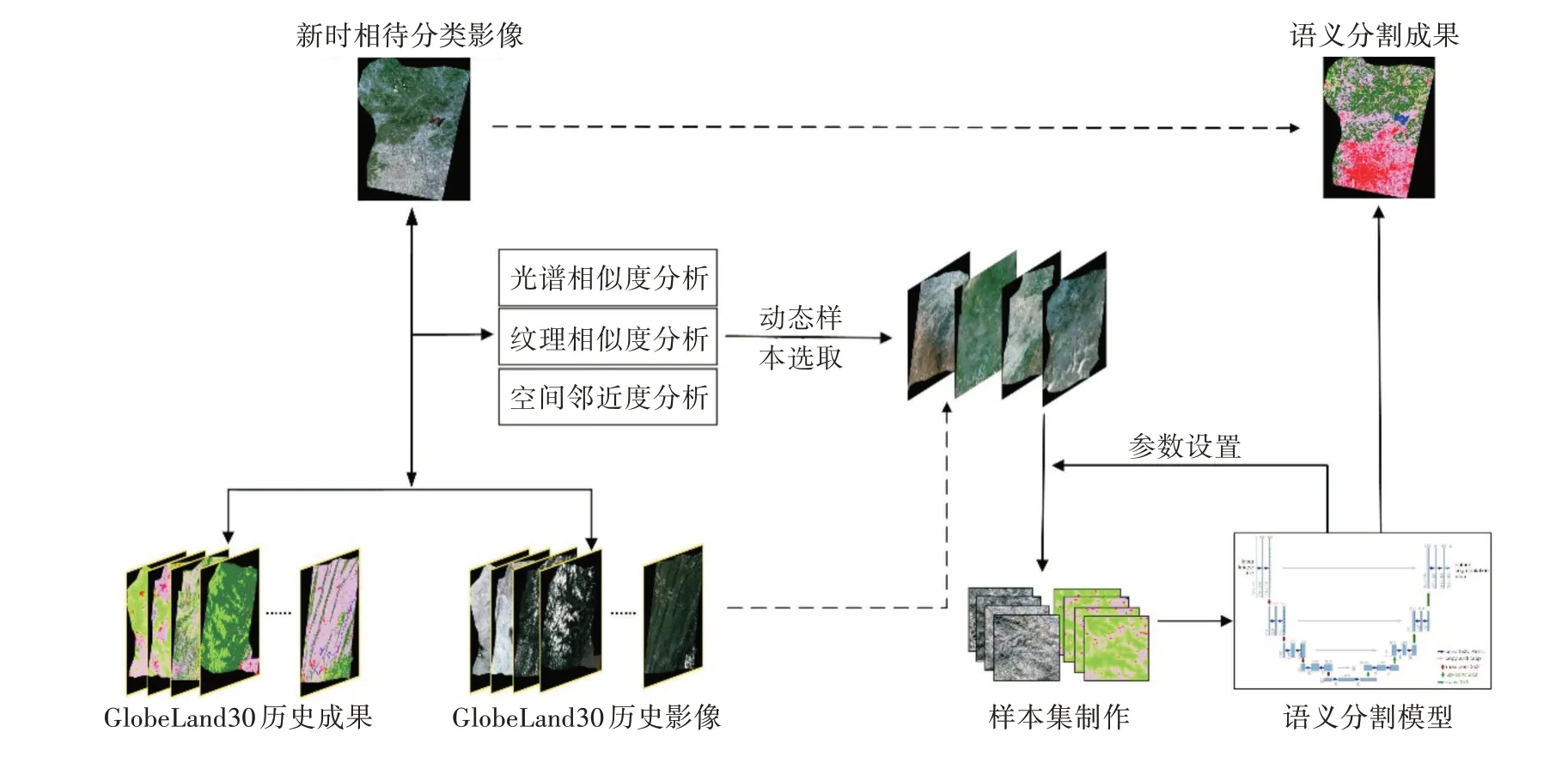
图1 数据集动态构建算法技术路线
2.2 数据自动选取
作为遥感数据集动态制作的关键步骤,训练集的选取质量直接决定了分割结果的精度。光谱和纹理是常用的低层次图像特征,虽然光谱、纹理特征是简单的特征,但它们描述了遥感图像最显著的信息;另外,依据空间自相关(Spatial autocorrelation)理论进行分析,地理数据由于受空间相互作用和空间扩散的影响,彼此之间可能不是独立的,而是相互关联的。所以,本研究在光谱距离、纹理距离和空间距离3 种测度下选取最近邻历史影像。
Landsat-8 卫星是2020 版GlobeLand30 数据生产的主要影像数据源,其携带的陆地成像仪(OLI)可以16 d 重新覆盖地球1 次,实现对地球南北纬81°以内地区的无缝影像覆盖[20]。Landsat-8 影像为16 bit Geotiff 格式,灰度级为0~65 535 级,在实际生产中,Landsat-8 影像仅保留可见光(红、绿、蓝)、近红外和2 个短红外共6 个波段信息。
设待分类影像集为X,历史影像集为Y,依次从影像集X中读取待检测影像,该影像的像素矩阵公式如下:
式中,I为Landsat-8 遥感影像的像素矩阵;xijk为影像第k个波段上第i行第j列的像素值;i=1,2,…,m;j=1,2,…,n;k=1,2,…,6。
基于不同的数据集选取方法,生成对应的特征向量a;然后基于同样的特征提取方式,获取影像集Y中所有影像的特征向量集{b,c,d,e…};最后从影像集Y中选取出与向量a相似度较高的前K个特征向量对应的遥感影像构建数据集。
2.2.1 基于影像光谱相似度选取方法 光谱特征是遥感图像重要的低层特征,通过遥感影像像元亮度值可反映遥感图像粗略的地物构成情况,而直方图是最常用的特征表达方式,亮度直方图越相近,遥感影像地物特征越相似。
但是由于遥感影像受时间、气候、成像角度等条件约束,同一地物在不同时间获取的高光谱遥感影像中光谱特征表现可能存在差异,导致同物异谱、同谱异物现象[21]。图2 为2 景遥感影像直方图对比,当设置较大的统计组数时,2 景影像的直方图数据分布差异较大,但是整体分布相似。因此,在计算2景遥感影像光谱相似度时,可以采用较小的统计组数,减少同物异谱、同谱异物现象。
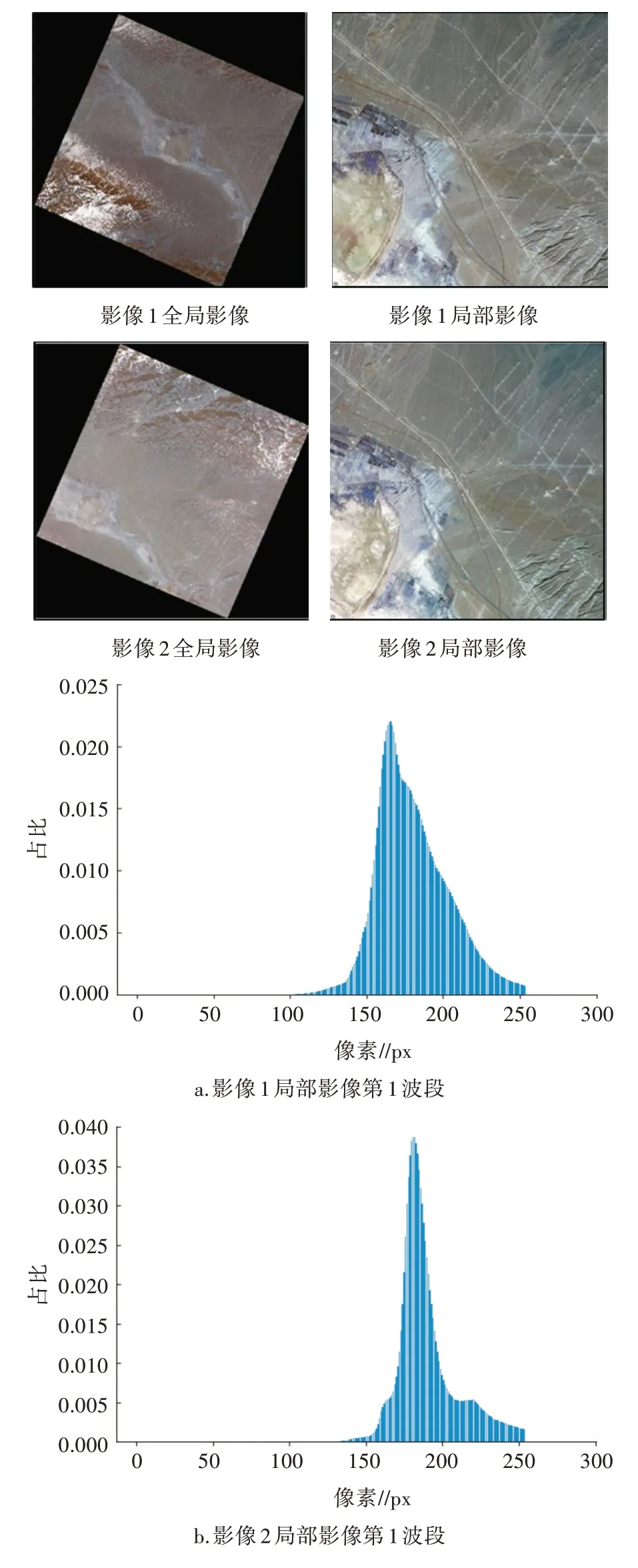
图2 同一区域2 景遥感影像直方图对比
设置统计组数为16,逐波段统计影像像素矩阵I的亮度分布情况,得到(6,16)维的特征变量H。
式中,hij表示Landsat-8 影像的第i波段在[(j-]区间内的像素点占比;i=1,2,…,6;j=1,2,…,16。
董晓莉等[22]证明了常用的向量距离测度欧氏距离在衡量相似性时具有2 个缺陷:不能辨别形状的相似性,不能反映趋势动态变化幅度的相似性。而余弦相似度不仅可以衡量2 个向量间距离,还可以描述其变化幅度差距,以此评估2 景影像光谱向量变化走向,距离越小,图像越相似。
获取2 景影像的特征向量后,将二维向量按行重组为96 维特征向量,以余弦相似度衡量2 景影像的光谱特征相似度,计算公式如下:
式中,similarspe为2 景影像的光谱特征相似度,阈值[0,1],similarspe越趋于0,2 景影像越相似;ai为影像1 的96 维光谱特征向量;bi为影像2 的96 维光谱特征向量。
2.2.2 基于影像纹理相似度选取方法 常见的哈希算法包括均值哈希(ahash)、感知哈希(phash)、差异值哈希(dhash)3 种。①均值哈希。将图像压缩为对应尺度(一般为8 px×8 px),再将压缩后影像灰度化,并计算灰度均值,比较每一个灰度值与均值的差异,大于或等于均值记为1,小于均值记为0,最终得到64 位的哈希值;②感知哈希。在均值哈希基础上加入离散余弦变换(Discrete cosine transform,DCT),对灰度化影像进行DCT 运算后,取8 px×8 px 的高频信息做均值哈希,得到感知哈希值;③差值哈希。对图像进行压缩后(一般为9 px×8 px),依次读取每一行的像素灰度值,两两作差共生成64 位的差值哈希值。
采用哈希算法将影像的像素值变化趋势与幅度以向量形式存储,用于分析计算2 景影像的纹理相似性。为减少地物在影像中分布位置、占比大小不同导致的影响,只分析地物纹理特征,本研究随机选取1 景遥感影像,并依次进行90°、180°、270°旋转,在1/3、1/2、2/3 处裁剪,生成6 景对比影像,确定适合Landsat-8 遥感影像的最优哈希算法。采用汉明距离(式4)计算原始影像哈希值hash1 与6 景对比影像哈希值hash2 的相似度,计算公式如下:
从哈希相似度对比结果(表1)可知,ahash算法在翻转影像上的相似度最高,说明ahash算法更容易从整体比较影像纹理特征变化,结果不易受地物分布位置影响,因此本研究选取ahash算法计算待分类影像与所有历史影像的纹理相似度。
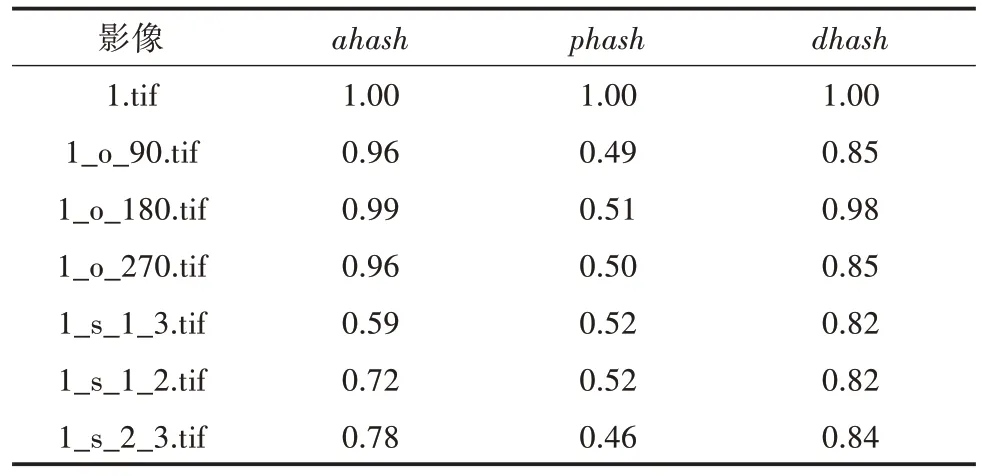
表1 哈希相似度对比
2.2.3 基于空间邻近度选取方法 Tobler[23]在1970提出地理学第一定律:任何东西与别的东西之间都是相关的,但近处的东西比远处的东西相关性更强,且Li 等[24]试验证明空间中选取邻近经纬度区域内的训练样本相较于全区域训练样本具有更高的分类精度。因此,本研究提出基于影像地理位置选取数据集的选取策略,从遥感影像数据库中选取邻近位置的数据构建动态数据库,距离越近,地物特征越相近。
Landsat-8 遥感影像在存储时统一命名为TN_ln_DATE.img,其中TN 为轨道号(Track number)的缩写,轨道号由条带号(Path)和行编号(Row)共同构成;ln 表示遥感影像来源于Landsat 系列第n颗卫星的数据;DATE 为遥感影像成像时间。如p015_r035_8_20170502.tif,表示该影像为2017 年5月2 日成像于轨道号为p015-r035 的Landsat 8 卫星遥感影像。基于Landsat-8 全球参考系统(Worldwide reference system,WRS)的行列号选取目标影像的8-邻域影像。
为了避免选取的遥感影像中存在模糊度高、噪声强的低质量影像数据,降低模型训练精度,首先选取定位精度高且对噪声敏感的Laplacian 算子,量化遥感影像的质量,筛选掉模糊度高的遥感影像。
首先采用高斯模糊技术平滑遥感影像,然后根据Laplacian 算子计算梯度值,生成模糊图blur,将模糊图的方差作为单波段模糊度blur,并取6 个波段模糊度均值作为该影像整体模糊度评价分数,计算公式如下:
式中,similarspa为2 景影像的质量评价分数,阈值(-∞,100],similarspa越趋于100,影像质量越高;xijk为进行平滑处理后的遥感影像在第k个波段上的像素矩阵;i=1,2,…,m;j=1,2,…,n;k=1,2,…,p;Laplacian()函数计算公式如式(6)所示。
式中,f(i,j,k)为Laplacian 算子处理前遥感影像在k个波段上第i行第j列的像素值;g(i,j,k)为Laplacian 算子处理后遥感影像在第k个波段上第i行第j列的像素值;i=1,2,…,m;j=1,2,…,n;k=1,2,…,p。
表2 为2 景Landsat-8 遥感影像及质量评价分数,第1 景遥感影像地物特征明显,第2 景遥感影像被厚云遮挡,并根据式(5)得到每景影像6 个波段的模糊图。利用边缘检测Laplacian 算子计算模糊度,筛选掉被厚云遮挡地物的低质量影像,保证构建数据集的遥感影像质量。
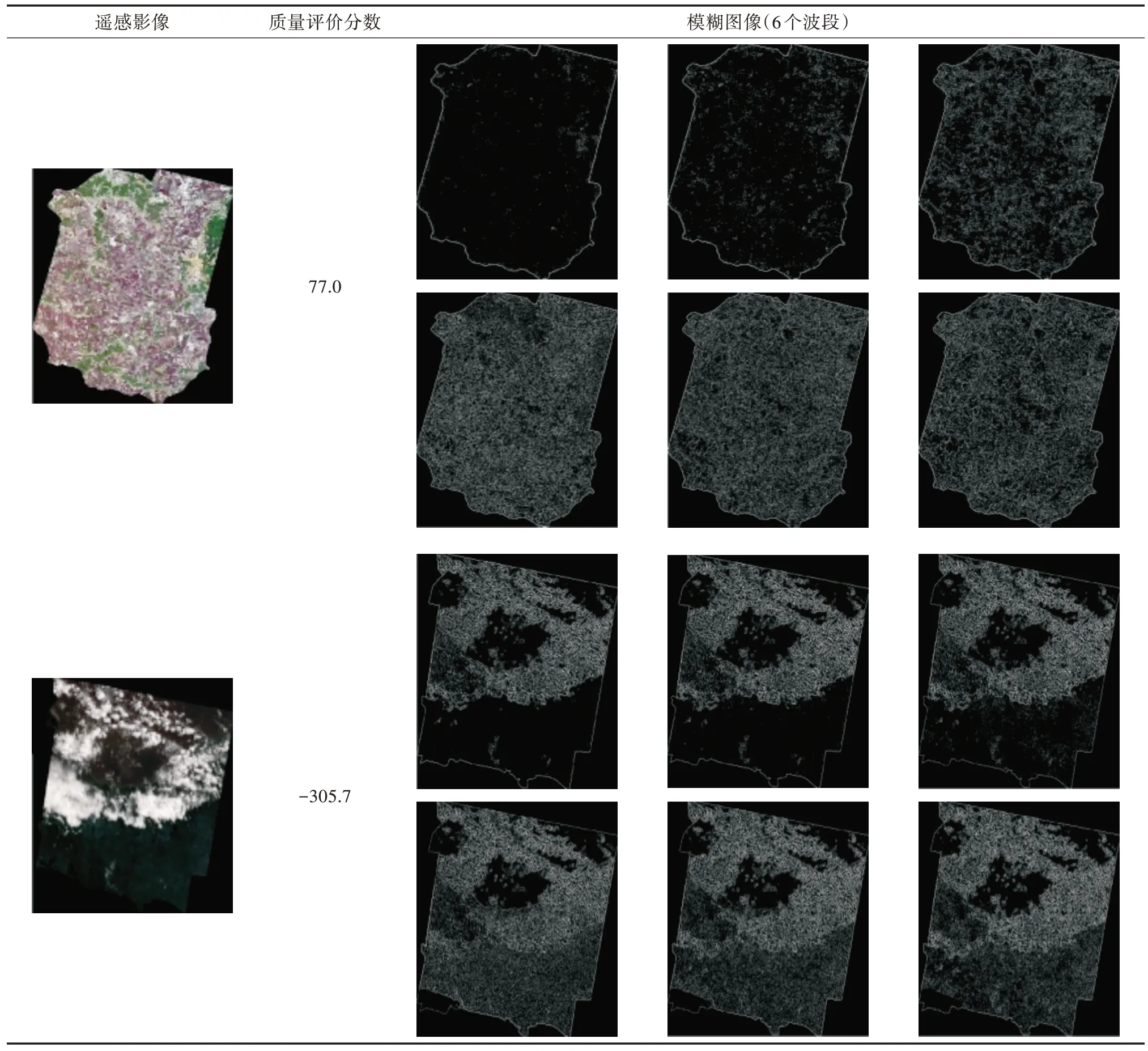
表2 2 景Landsat-8 遥感影像及质量评价分数
2.3 样本动态裁切
基于GlobeLand30 历史数据研究遥感数据集动态构建数据选取方法,实现自动化选取遥感影像与制作,减少人工解译时间,提升检测精度。
样本集动态制作流程如图3 所示,从数据库中读取已选取影像对应的真值影像,根据深度学习模型输入相应尺寸要求,修改裁切尺寸参数(样本宽度Width、样本高度Height、步长Stride、重叠率Overlap、影像中非背景像素占比下限Proportion、保存格式Suffix 等),快速实现影像与对应真值影像的自动裁剪。
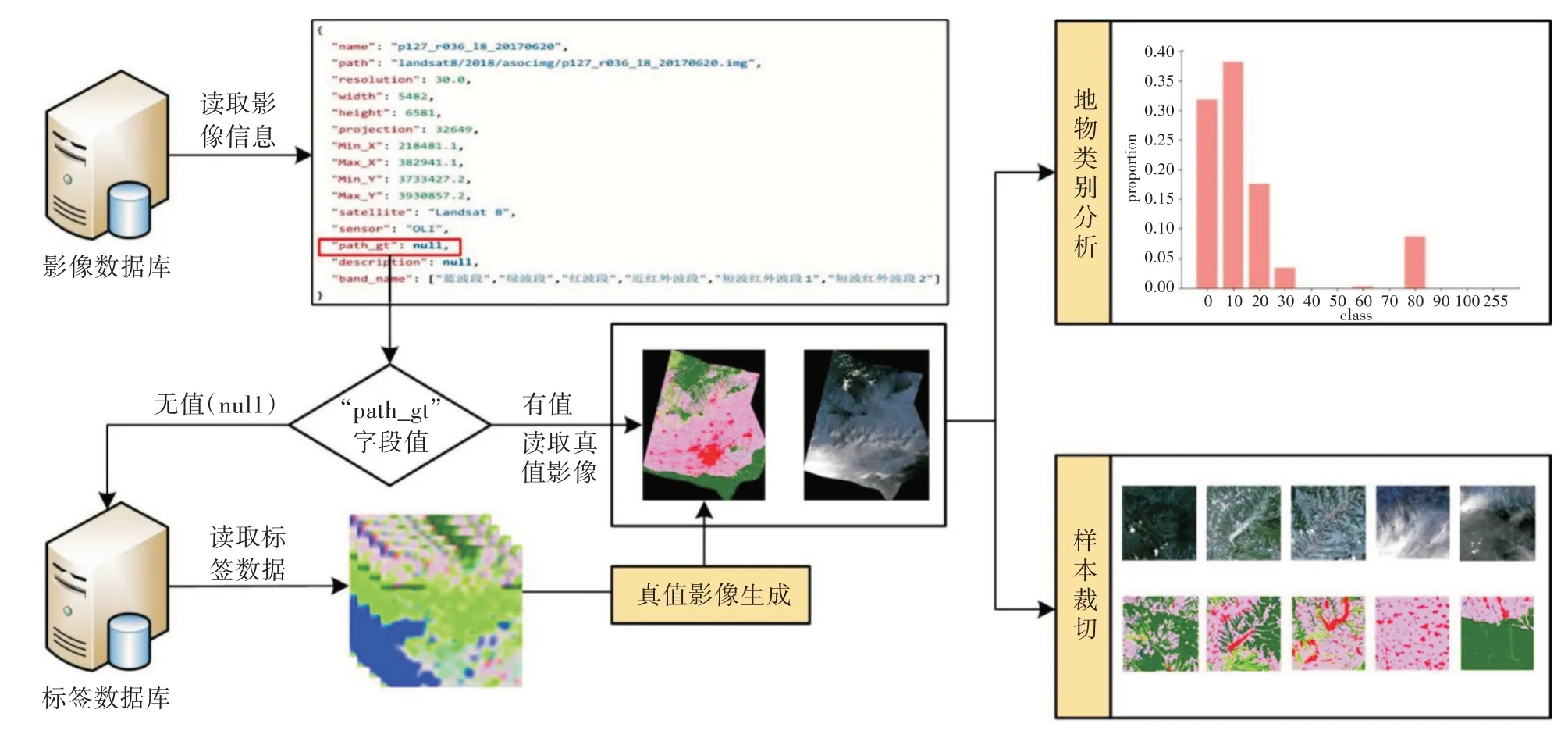
图3 样本集动态制作流程
3 结果与分析
本研究从精度和速度2 方面对比3 种数据集动态构建方法,首先,随机选取1 景遥感影像,比较3 种方法的运行效率;其次,选取多景遥感影像,比较3种方法的地物分类总体分类精度。所有算法全部基于表3 所示试验环境配置进行研究。

表3 试验环境配置
3.1 图像相似度策略效率对比
选取2017 年获取的1 景北京市Landsat-8 OLI遥感影像作为待分类影像(影像大小为4 580 px×5 923 px),将GlobeLand30 V2020 中与待分类影像对应区域的地表覆盖数据产品作为真值,将覆盖中国区域的其余608 景影像及地表覆盖数据作为历史数据。
数据集动态制作大致分为数据自动选取、样本动态裁切2 个步骤,由于样本动态裁剪所需时间与选择的影像数据、样本制作参数有关,因此效率分析主要是对不同图像相似度策略下数据自动选择的效率分析。将1 景待分类影像作为测试集,分别利用3种选择策略从历史数据中选择4 景相似影像,其中,相似度前3 的影像作为训练集,相似度第4 的影像为验证集。
整体流程运行时间对比如表4 所示,空间邻近度算法效率最高,每次选取用时不到1.00 min,主要原因是在影像选取时影像读取与特征提取耗时较长,而空间邻近度的8-邻域选取方法,一开始便根据影像名将对比影像从608 景迅速减少至8 景,减少了影像处理时间。

表4 图像相似度策略运行时间对比
将1 景待分类影像作为测试集,分别利用3 种方法从历史影像中选择4 景最相似的影像。影像选择结果如表5 所示。

表5 图像相似度策略选取结果
3.2 地物分类精度对比
为验证数据集动态构建方法在地表覆盖信息提取的可行性,在各省(市、区)内分别随机选取1 景Landsat-8 OLI 影像作为测试数据,每一景影像按照其主要覆盖的省(市、区)命名。对于每景测试影像的分类任务,首先,在研究区域内随机选取3 景影像作为训练集、1 景影像作为验证集;然后,分别根据光谱相似度、纹理相似度和空间邻近度方法为每景测试影像选取4 景相似影像,将其中最相似的3 景影像作为训练集,第4 景影像作为验证集;最后,将选取的影像制作为样本集,在深度学习模型上进行训练后,对比随机选取方法和3 种样本集动态制备方法的分类精度。
本研究选取遥感影像分类中常用的U-Net 语义分割模型进行训练与检测,并选取具有更好特征提取效果和更快特征提取效率的EfficientNet-B3 骨干网络替换U-Net网络的编码器。
模型均100 轮,利用训练完成的模型对待分类影像进行地表覆盖分类,以式(9)计算地表覆盖分类总体精度(Overall accuracy,OA),计算公式如下:
式中,ai为第i类地物的分类精度;i=1,2,…,n。
图4 以直方图形式显示各省份的测试影像分别在4 种不同选取方法下的总体精度,其中,94.1%的测试影像基于图像相似度策略选取样本集的检测精度,明显高于基于随机选取样本集检测精度,说明动态样本集制备方法有效;而在3 种动态构建方式中,空间邻近度算法在34 景测试影像上总体分类精度方差最小,是最稳定的动态构建算法。
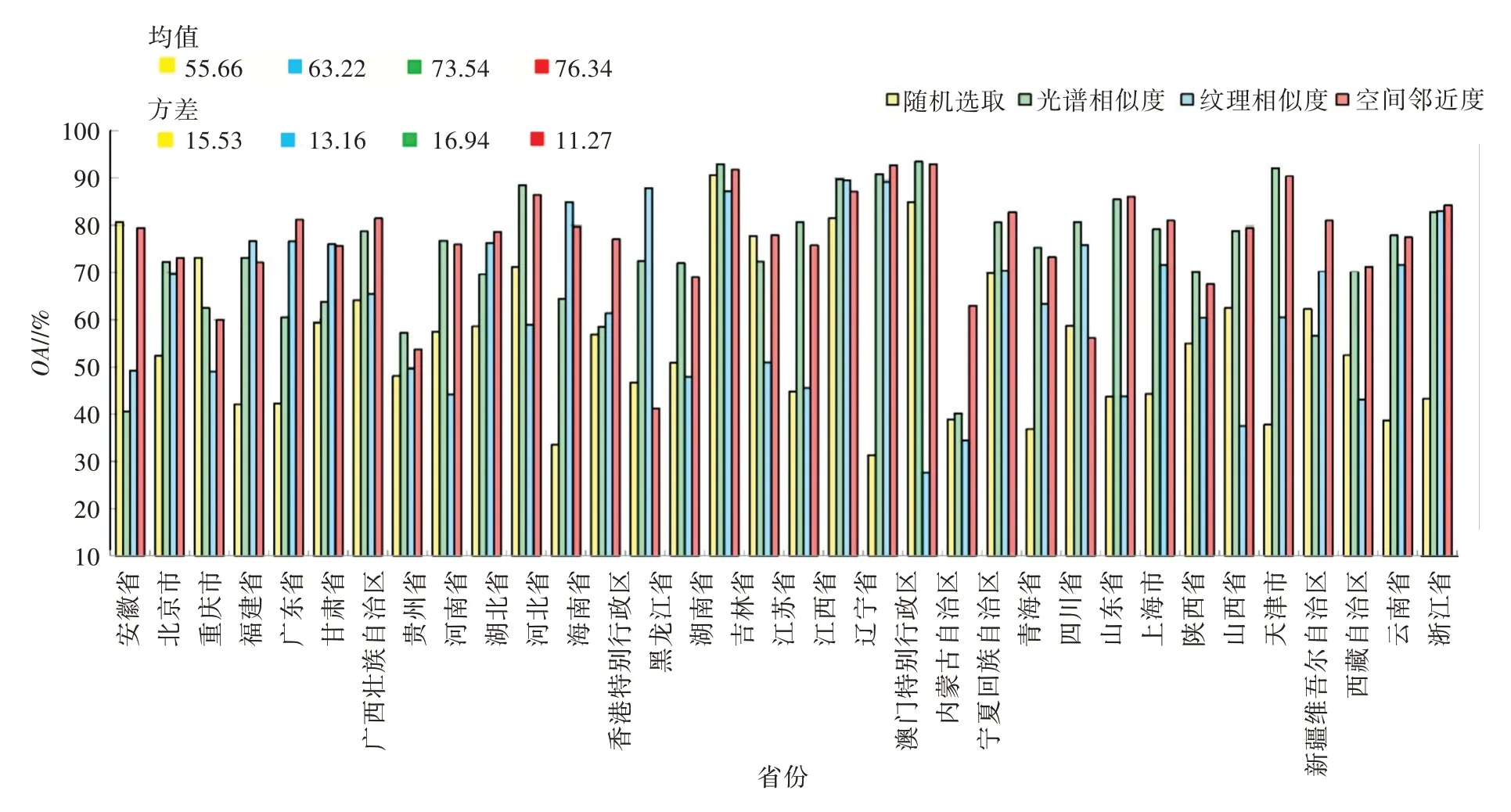
图4 基于图像相似度策略的试验结果直方图
图5、图6 分别为澳门特别行政区(总体分类精度最高)、宁夏回族自治区(总体检测精度最低)在不同样本集选取方法下的分类结果对比图,在2 景测试影像中空间邻近度算法分割精度均最高,随机选取方法大面积区域分类错误。图7 为宁夏回族自治区局部影像及其Globeland30 标注结果,目视解译无法匹配影像与标注,属于产品生产时标注错误。

图5 澳门特别行政区分类结果可视化

图6 宁夏回族自治区分类结果可视化

图7 宁夏回族自治区局部影像及其GlobeLand30 标注
对于基于深度学习语义分割的遥感影像分类而言,模型训练集的选取策略会对分类结果产生较大影响;从34 景测试影像的分类精度来看,34 景影像平均分类精度最高的为空间邻近度(76.34%),其次为光谱相似度(73.54%)和纹理相似度(63.22%),精度最差的为未考虑相似性的随机选取方法(55.6%),符合“近处的东西比远处的东西相关性更强”规则,但是并不一定是最近的影像一定产生最好的影响;空间邻近度是可取得较高精度的、算法相对稳定的动态样本集构建中相似影像检索策略;错误的历史标签会导致最终的分割结果异常,降低分割精度,因此样本动态选取方法还可用于检测异常历史数据。
4 小结
利用深度学习语义分割模型开展GlobeLand30地表覆盖数据智能生产时,为解决静态制作数据集存在的问题,从提升训练和测试数据分布一致性出发,研究了3 种基于影像相似性的样本动态制备方法,分别为基于灰度直方图余弦距离的光谱相似度、基于哈希纹理汉明距离的纹理相似度、基于影像质量评价的空间邻近度。选择与待分类影像相似的GlobeLand30 历史数据,用于训练语义分割模型,试验对比了随机选取样本集和3 种动态制备样本集在同一个语义分割网络下的总体分类情况,结果表明,基于影像数据的样本影像选择方法可显著提升地表覆盖数据智能生产精度;其中,基于空间近邻度选择是精度最高且最稳定的策略。
动态构建数据集的方法一方面将历史数据应用起来,并将产品生产过程自动化,节约了大量人力和时间;另一方面,对于标注异常的影像进行历史数据纠正。对于数据集构建的最优选取数量和基于景观相似度的数据集动态构建方法是下一步研究方向。
