基于ResNet-LSTM 的多类型伪装语音检测*
2023-10-15广州城市职业学院苏卓艺
广州城市职业学院 苏卓艺
现今,随着语音处理算法及相应工具的成熟,这给社会带来便利的同时,亦面临不少新的安全问题。其中,伪装语音便是亟待解决的重要安全问题之一。根据已有的研究记录表明:伪装语音能轻易骗过人耳及说话人识别系统,从而冒充他人或隐藏说话人身份,对人身、经济等领域均带来严重威胁。目前,针对伪装语音的检测研究已经有了一定的进展。但大多数的研究所都只针对一种类型的伪装语音进行研究和检测,在应对其他类型的伪装攻击时,往往检测率不高。而在实际应用场合中,一般不能提前知道伪装语音的类型。因此,本文研究了可以应对多种类型伪装语音的检测模型,提出了一种利用残差网络和长短时记忆网络相结合来检测伪装语音的方法。
1 伪装语音检测研究现状
近年来,自动说话人验证(Automatic Speech Verification,ASV)系统这种低成本的生物识别技术已被广泛地应用在许多场合。但随着自动语音处理算法的不断成熟,ASV系统很容易受到来自伪装语音的攻击。为此,2015 年首届ASV 欺骗挑战计划出现,目的是促进伪装语音的研究,为评估和比较欺骗对策提供一个通用平台。并且形成一个基于振幅、相位、线性预测残差和基于振幅-相位的联合对抗措施组成的伪装攻击检测系统[1-3]。
现有的关于伪装语音检测的研究主要集中在三种不同的伪装类型:
(1)语音转换(Voice Conversion,VC)和语音合成(Speech Synthesis,SS)方面:F.Hassan 等人提出了一种由频谱通量和频谱质心组成的融合特征向量用于分类识别的方法[4]。Muckenhirn 等人提出利用一阶和二阶谱作为特征的检测方法[5]。此外还有运用高斯混合模型(Gaussian Mixture Model,GMM)、动态时间规划(DTW)模型、卷积神经网络等其他方法的检测算法[6-10]。
(2)关于重播语音的研究,Patil 等人提出了采用倒谱均值和方差归一化(CMVN)的方法[11]。M.R.Kamble等人提出使用泰格能量算子(TEO)来计算重放与自然信号的子带能量并映射到MFCC 中用于检测识别[12]。G.P.Prajapati 等人提出基于能量分离算法(ESA)的特征以及高斯混合模型(GMM)作为模式分类器的方法[13]。R.Acharya 提出交叉能量倒数系数(CTECC)作为特征,高斯混合模型(GMM)和光卷积神经网络(LCNN)作为分类器的检测方法[14]。
(3)关于语音变形(Voice Transformation,VT)的研究,大多利用如频谱图、修改群延迟(MGD)和梅尔普倒谱系数(MFCC)作为特征再利用支持向量机(SVM)、隐含马尔柯夫模型(HMM)等分类器及深度学习的方法检测语音真伪[15,16]。
伪装语音检测的研究目前较为系统和丰富,但是这些检测方法大多都只适用一种伪装语音类型的检测识别上,当伪装语音的欺骗类型与所设计模型训练不一致时,效果往往不如意。因此,本文提出一种基于ResNet-LSTM 的伪装语音检测的模型,将语音数据转换成时频图的方式输入到设计好的ResNet-LSTM 的网络中输出判断结果。实验结果表明,该方法在多种类型的伪装语音检测上都有超过90%的识别精度,能应对各种不同时长及不同类型的伪装语音攻击。
2 多类型伪装语音检测系统
基于ResNet-LSTM 的伪装语音检测系统包括训练阶段和测试阶段,训练阶段分别利用ResNet 和LSTM获取语音片段时域特征和频域特征并用于训练和分类,ResNet 通过卷积操作获取语音在频谱上的空间特征,并通过引入短连接解决过拟合的问题,提高分类性能和准确度。LSTM 体系结构可以将长时段信息存储在其记忆块中,并通过窥视连接来学习语音的上下文依赖性,多类型的伪装语音检测系统如图1 所示。

图1 基于RseNet-LSTM 的伪装语音检测系统Fig.1 Spoofing speech detection system based on RseNet-LSTM
2.1 ResNet 残差网络
2.1.1 卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN)是一种备受关注的检测模型。近年来,CNN 已经成为许多研究领域的热门话题,特别是在语音识别、图像识别和自然语言处理领域。这是因为CNN 避免了对数据复杂的前期预处理操作,能够直接向网络输入原始数据,因此得到广泛重视。CNN 结构中的特征提取器,使得数据样本在卷积的过程中,特征不断地被提取以及压缩,并最终能得到比较高维度的特征。
总的来说,CNN 结构可以分为两部分,一部分是特征提取,一般包括卷积操作、激活函数以及池化;另一部分是全连接层的分类和识别。
2.1.2 残差网络
通常,为了提取更深层的特征用于模型分类,会设计一个层数更多的模型。但是,随着CNN 层数的增加,在训练过程中经过许多层后,网络梯度信号会慢慢消失。当训练到一定程度时,模型的训练精度虽然随着训练次数的增加而提高,但测试精度却降低,称为退化现象。残差网络[17]中提出了一种数据短路径的方法,使信号能够在输入层和输出层之间高速流通。该方法的核心思想是在网络的前一层和后一层之间建立一条短路径连接,对退化现象有很好的抑制作用。残差模块是由一系列残差块组成,如图2 所示,一个残差块可以用公式表示如式(1)所示:
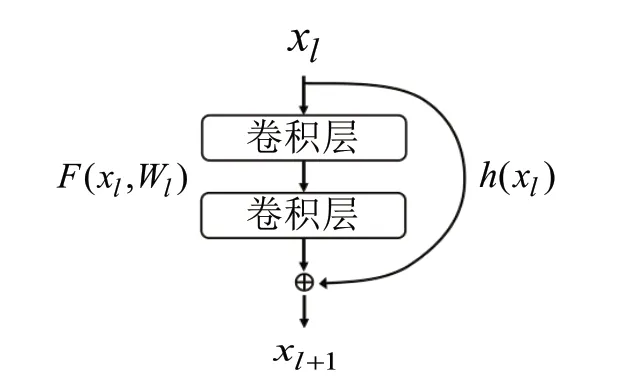
图2 残差模块结构图Fig.2 Residual module structure diagram
残差模块分为两部分:直接映射部分和残差部分。直接映射,体现在图2 中右侧曲线中;残差部分,一般由两个或者三个卷积操作组成,即图2 中左侧包含的卷积部分。
2.2 长短时记忆网络模型
2.2.1 循环神经网络
长短时记忆网络(Long Short-Term Memory networks,LSTM)是在循环神经网络(Recurrent Neural Network,RNN)基础上改进的。RNN 是一种具有短时记忆能力的神经网络,适合用于处理视频、语音、文本等与时间序列相关的问题。在常规的RNN 中,神经元既可以接收来自其他神经元的信息,也可以接收自身的信息,形成一个循环的网络结构。这使得RNN 可以共享不同时刻的参数,如图3 所示。RNN 的单个神经元包含一个反馈输入,网络中上一时刻神经元的“历史信息”将通过权值与下一时刻的神经元相连接。这样,RNN 在t时刻的输入与输出映射都参考了t时刻之前所有输入数据对网络的影响,形成了反馈网络结构,使RNN 中的参数在不同时刻共享。

图3 RNN 单个神经元结构图Fig.3 Single neuron structure of RNN
给定一个输入序列X1:T=(X1,X2,...,Xt,...,XT),RNN通过如式(2)所示的公式来更新带反馈的隐含层活性值ht:
其中h0=0,f(·)是一个非线性操作。但是常规的RNN 很难学到长期依赖,因此模型训练十分困难。
2.2.2 长短时记忆网络
LSTM 在常规RNN 的结构上做了改进,它的主体结构与RNN 相似。不同的是,常规RNN 中的神经元被LSTM 隐藏层中的记忆区块所代替。记忆区起到对信息的限制作用,里面的门结构对信息进行筛选和限制,使该记住的信息传递下去,不该记的信息被门限制住,这样的结构使得梯度不论传播多少层,都不可能真正消失。通过这种结构来解决长期依赖问题,使得网络能记住长期的信息,这样后期的早期信息也能对后面的网络输出起作用。相比于RNN 网络,LSTM 网络收敛性更好。研究表明,LSTM 网络是目前应用最好的循环神经网络结构之一,在处理时间序列问题上具有很好的效果。如语音识别、温度预测、发病率预测等。
LSTM 网络结构中每一层的神经元都含有3 个门来控制并保护结构状态,这3 个门分别是输入门、遗忘门、输出门,它们都包含在LSTM 网络记忆单元中,通过调节门的开关可以实现初始序列对最后结果的影响,具体的LSTM 网络记忆单元的网络结构如图4 所示,输入门控制新输入到记忆单元的强度,遗忘门控制记忆单元保持上一时间值的强度,输出门控制输出记忆单元的强度。图4 中it表示输入门,ft表示遗忘门,ot表示输出门,ct表示记忆单元的向量值。另外Sigmoid 激活函数作为门函数,其作用是通过记忆单元保持与上层特征的联系,增强记忆的时效性,输出0-1 的数值,从而决定有多少信息可以输入到记忆单。

图4 LSTM 记忆单元结构图Fig.4 LSTM memory unit structure diagram
LSTM 网络对序列数据xt按照如式(3)-式(8)所示的公式进行处理。
其中U1,W1,b1为线性关系的系数和偏置,σ为Sigmoid激活函数,⊗为Hadamard 积(对应位置相乘)。
2.3 ResNet-LSTM 网络
本文提出的ResNet-LSTM 结构如表1 所示。网络由一个初始卷积层、两个残差块、一个转换层和两个LSTM层组成。初始层包含64 个7×7 的卷积核,池化采用3×3的最大值池化,步长为2。残差块1 中包含3 个连续的1×1和3×3 卷积层,每层卷积核个数为64,池化采用2×2 的均值池化,步长为2。残差块2 与残差块1 结构基本一致,但每层卷积层的卷积核个数增加到128 个。经过转换层后,把输出特征图的通道铺平,变成6×6×128=4608 的一维张量,并输入到最后的两个LSTM 层中,两个LSTM 层分别包含4608 个神经元和100 个神经元。

表1 ResNet-LSTM 网络结构Tab.1 ResNet-LSTM network structure

表2 ASVspoof 2019 数据集分布Tab.2 ASVspoof 2019 data set distribution
ResNet-LSTM 检测网络的输入是96×96 大小的频谱图,通过卷积操作提取语音段时域和频域上的有效信息,利用池化层不断压缩特征图大小获取高纬度的深层特征。特征信息最终通过两层LSTM 结构对该特征序列进行处理并输出最终的分类结果,分类器采用Softmax。
3 实验设置与实验结果
3.1 实验数据和设置
ASVspoof 2019 语料库包含46 名男性和61 名女性在内的107 名说话人的真实语音,所有的真实语音均采用了相同的录音设备和环境,且没有信道和噪声的干扰。数据集中的伪装语音均是由获取的真实语音经过语音合成和语音转换得到,语音数据的采样率均为16kHz。
数据集包括3 个子集:训练集(Train)、验证集(Development)和测试集(Evaluation)。其中训练集和验证集中的伪装语音来自6 种相同且已知的语音伪装技术,用于对伪装语音检测系统进行训练和参数调整。而测试集中的伪装语音则包含上述2 种已知的攻击类型和11 种未知的攻击类型。
需要注意的是,由于伪装(负样本)语音的数量是真实(正样本)语音数量的大约9 倍。为了确保训练数据的平衡,本文对真实(正样本)语音的训练集和验证集进行了扩充,使正样本的数量与负样本的数量相等。
本文使用一个ADAM 优化器[18]训练提出的ResNet-LSTM 模型的损失函数,其中第一和第二的指数衰减率估计β1,β2 分别为0.9 和0.999。学习率设置为10-4,训练Epoch 为50 次,批量大小为32。
3.2 合成语音及转换语音检测结果
语音检测实验部分,本文采用的是1s 的极短时长的语音进行实验,认为1s 的语音段极具代表性,采用1s 的语音训练模型可以使得到的模型可以应用到几乎所有时长的伪装语音的检测中,不会出现因测试语音片段过短而导致测试结果不准确的情况。而ASVspoof2019 数据集中的语音段均为30~60s 的语音段,数据量较大,实际获取语音时未必能达到上述的要求。
所以本文在原始语音的基础上,将语音段切割成1s的多个短语音段并作为训练及测试数据应用到设计的ResNet-LSTM 网络中,并采用错误拒绝率与错误接受率去判断所提出方法的有效性。其中错误拒绝率指错误拒绝真实语音的概率,错误接受率是表示错误接受伪装语音的概率。一般是使用等错误率(Equal Error Rate,EER)来代表检测方法的性能,其表达式如式(9)所示:
其中,θEER是错误拒绝率Pmiss与错误接受率Pfa相等时的阈值。
本文把ASVspoof2019 中测试集中包含的13 种攻击类型的数据分别进行了实验,并计算等错误率,实验结果如表3 所示。
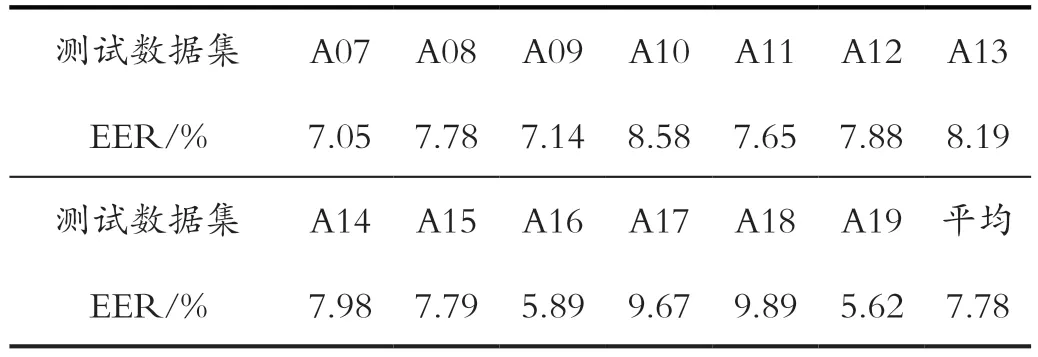
表3 跨数据库检测等错误率Tab.3 The equal error rate of cross-database speech
根据表3 的实验结果表明,ResNet-LSTM 网络在检测未知语音合成或语音转换的伪装攻击时,依然保持较低的等错误率。此外测试数据集中的A16 和A19 的检测结果要优于其他11 个测试数据集的结果,这是由于A16与A04,A19 与A06 是来自相同的伪装攻击算法,测试的等错误率相较于其他未知伪装攻击更低。
3.3 变形语音检测结果
在这一部分的实验中,本文还对语音变形的伪装语音进行了检测,以此验证该检测网络在应对其他类型的语音攻击时的效果。这部分实验数据包含3 个语料库,分别是Timit(630 个说话人,6300 段语音)、UME(202个说话人,4040 段语音)和NIST(356 个说话人,3560段语音)。语音数据为WAV 格式,采样率均为8kz。语料库的分组如下:
训练集:Timit-1(3000 段语音),UME-1(2040 段语音),NIST-1(2000 段语音);
测试集:Timit-2(3300 段语音),UME-2(2000 段语音),NIST-2(1560 段语音)。
实验的训练集和测试集来源于同一个语料库,实验结果对比了其语音检测的方法。实验采用如式(10)所示的公式中的检测精度方法来测量性能。
其中G和S为测试集中真实和伪装语音的数量,Ga和Sa分别为从G中正确检测到的真实片段和从S中正确检测到的伪装语音片段的数量。实验结果如表4 所示。
实验结果表明,本文提出的方法检测精度比Liang等人提出的检测方法[16]高1.79%,比Wu 等人提出的方法[15]高2.87%。本文提出的方法优于另外两种方法,是因为ResNet-LSTM 比普通的CNN 卷积层数更多,提取到更多更深层的特征用于分类。此外,普通CNN 的决策仅仅是由深层特征决定,但在ResNet-LSTM 引入了短路径的连接,并在分类时不仅可以参考深层特征,同时又参考了早期的浅层特征,从而提高检测精度。
4 总结
本文对多种不同类型的伪装语音分别进行了检测,提出了基于ResNet-LSTM 的多类型伪装语音检测模型。该模型通过对语音时频图卷积能自动提取语音特征,并利用残差模块的短连接实现同时保留语音的深层特征和浅层特征信息,并最终通过LSTM 的门结构过滤掉无效信息,留下有效特征,从而提高伪装语音的检测效果。实验的结果显示,ResNet-LSTM 在多种类型的伪装语音的检测效果均表现很好,检测精度均超过90%。
