融合序列影像相关区域信息的光流估计网络
2023-10-13安彤贾迪张家宝蔡鹏
安彤, 贾迪,2*, 张家宝, 蔡鹏
(1.辽宁工程技术大学 电子与信息工程学院, 辽宁 葫芦岛 125105;2.辽宁工程技术大学 电气与控制工程学院, 辽宁 葫芦岛 125105)
1 引言
光流估计是计算机视觉的核心问题之一,在视频理解[1]、动作识别[2]、目标跟踪[3]、全景拼接[4]等领域具有重要的应用,在各类视频分析任务中可以更好地反映目标的运动信息,被认为是一种重要的视觉线索。然而,目前的光流估计网络仍存在过度平滑、缺乏细粒度、无纹理曲面难以准确估计的问题。
传统光流估计方法常基于亮度一致性和空间平滑度能量最小化的方式获得光流估计结果。Horn等[5]采用全局方法估计图像的稠密光流场,基于亮度恒定与光流场平滑假设构造能量函数提出一种光流变分框架。Black等[6]提出一种鲁棒的光流估计框架,对违反空间平滑和亮度恒定这两个约束条件进行统一处理。为了解决二次方惩罚项偏差较大的问题,TV-L1[7]采用替换L1数据项和总变差正则化较好地剔除了异常值。一些学者又通过结合能量最小化以及描述符匹配策略建立区域层次结构[8],引入新的高阶正则化项解决了该框架中的相关问题。
近年来,基于深度学习的光流估计方法取得了快速进展。可通过训练好的神经网络直接对帧间光流进行预测,缺点是会产生局部噪声和模糊结果。针对该问题,Simonyan等[9]采用变分法、Ilg[10]等采用叠加多网络的思想来进行改进,较好地解决了该问题。此后,Ranjan等[11]结合传统算法中的金字塔理念提出SpyNet网络,由粗到精地完成了光流估计,更好地处理了光流算法中的大位移问题。Sun等[12]提出PWC-Net网络同样采用了由粗到精的金字塔思想,引入经典算法中的相关体处理(Cost Volume),以端到端的训练方式完成了网络性能的提升。Yang等[13]提出的VCN网络进一步改进了相关体处理方法,通过引入4D卷积提高了光流估计的准确性。这些方法均采用由粗到精的金字塔处理方式进行迭代优化,并在迭代中不共享权重。
与以上方法相比,建立在FlownetS和PWC网络架构基础上的IRR[14]网络能够细化网络间的共享权重,但由于该网络过大(38M参数),只能完成5次迭代。Devon等[15]给出一种更加精细的模块设计(2.7M参数),在推理过程中可以进行上百次迭代,获得更加精确的结果。
随着深度学习的发展,许多工作将视觉问题转化为优化问题,将优化的思想融入到网络体系结构中。Amos等[16]提出的OptNet网络将优化问题作为单个层嵌入到深度网络中,并提供了更好的反向传播功能,使该网络具备较强的学习能力。Agrawal等[17]在求解优化过程中引入更为严格的参数化编程,较好地避免了可微应用中使用凸优化存在的问题。Zachary Teed等[18]提出一种光流估计网络(RAFT),结合以上算法思想,提取像素级特征,为所有像素建立多尺度4D关联信息,循环迭代更新光流场,有效提高了光流估计的准确率。但RAFT也存在着一些待解决的问题:首先,由于RAFT在高分辨率和低分辨率的条件下为所有特征对都建立了相关体积,每次更新都需要获得全像素位移的信息导致引入过多误差信息,降低了后续光流估计的准确率。其次,在迭代更新模块部分,RAFT依赖于静态滤波器融合光流和相关体积,这也使得最终的光流预测图产生过于平滑的结果。
为了解决上述RAFT中存在的问题,本文在构建4D相关体前,对输入的连续两帧特征图进行分区处理,以强弱相关的方式计算稠密的视觉相似度,以此计算建立更为精细的4D相关体积。在迭代更新阶段,本文在卷积门循环单元(ConvGRU)模块的基础上加入了残差卷积滤波器和细粒度模块,在融合光流信息和相关体信息前尽可能地保留更多的局部小位移信息。
本文通过特征提取模块、计算视觉相似度模块和光流迭代更新模块获得最终的光流估计结果,本文的主要贡献如下:
(1)提出采用分区处理强弱相关信息的方法,能够较好地剔除误差,建立更为精细的4D相关体,从而获得更加准确的相关体信息;
(2)引入残差卷积滤波器,使光流信息不会随着卷积滤波器的迭代加深而出现过于平滑的结果;
(3)采用细粒度模块,在尽可能扩大感受野的同时,使模块更加关注局部小位移的特征信息。
2 本文方法
图1为本文给出的光流估计网络结构,由特征提取模块、视觉相似度计算模块和迭代更新模块3部分构成。

图1 光流估计网络结构Fig.1 Optical flow estimation network structure
特征提取器模块由特征编码器和全局编码器两部分构成。输入的前后帧图片经过特征提取器模块分别提取下采样8倍的特征图和上下文信息。视觉相似度计算模块由分区强弱相关计算和相关金字塔构成。分区强弱相关计算会对特征图进行特征权重的空间重构,并通过相关金字塔得到不同尺度的相关体积。迭代更新模块由基准移动编码模块和卷积门控循环单元构成。光流信息会通过对不同尺度的相关体积进行按位查询,得到与预测光流位移相对应的相关体,查询得到的相关体和光流位移经过基准移动编码模块(图1中B标识模块)进行信息的融合。最终,输出融合结果将与上下文信息一起作为卷积门控循环单元的输入,迭代12次后得到更为精细的光流预测图。
对给定的输入连续两帧图像,分别表示为Ia与Ib。输入图像的宽和高分别记为H和W。
2.1 特征提取模块
特征提取模块由特征编码器和全局编码器两部分构成。特征编码器以权重共享的方式作用于Ia与Ib,并以1/8的分辨率输出编码后的特征Fa、Fb∈RH/8×W/8×D,其中Fa、Fb分别为图像Ia、Ib的输出,D为特征图的维度。
此外,全局编码器网络的体系结构与特征编码器网络相同。它将从第一张输入图像Ia上提取特征,并输出编码后的特征Fc∈RH/8×W/8×D。编码器的网络设计如图2所示。

图2 编码器结构Fig.2 Encoder structure
2.2 视觉相似度计算模块
计算视觉相似度是光流估计中的一个核心步骤,在整体结构中起到了至关重要的作用,但之前的许多工作并没有在这一步投入太多关注,计算方式大多以直接做全局特征向量的內积为主。全局的特征匹配往往是直接对两张特征图以像素点为单位计算点积,即取所有特征向量对之间的点积形成相关体。当给定特征图Fa的像素坐标(u,v)和特征图Fb的像素坐标(x,y),相关体积C即可通过矩阵运算获得:
在光流估计任务中,连续两帧图像间,大位移的像素点占比极少,远距离的像素相关性较小,即第一帧图像中位于上方的像素通常情况下不会位移到第二帧图像的下方。在这种情况下,做全局的相关计算就会引入许多误差信息。但若直接忽略远距离的特征点,一些大位移像素的相关关系将被完全清零,这可能导致一些更致命的误差。经过上述的分析,本文提出了基于分区思想的强弱相关计算方法。该方法可以在构建相关金字塔的基础上,强化对局部区域的关注度,从而减少对全局信息的错误判断。
如图3所示,输入的特征图会被横向切分成2n个区域(Region),通过区域间的范围阈值来设定两帧间像素的映射。在本文中,分条区域的个数被设置成偶数,这种做法的原因是当对图片进行分区处理时,选择偶数计算更为方便。对特征提取模块求出的特征图Fa和Fb,分区(Region)的表达方式如式(2)所示:

图3 横向切分做边缘区域点映射的强-弱相关与中心区域点映射的强-弱相关(以分条颜色的深浅表示相关的强度,对应位置区域认定为强相关,相关因子置1,其余颜色越弱,相关性越弱)。Fig.3 Strength-weakness correlation of the edge-region point mapping with the center-region point mapping done by the horizontal cut (The strength of the correlation is indicated by the shade of the color of the bars, The correlation factor is set to 1 when the corresponding position area is identified as strong correlation. The weaker the rest of the color,the weaker the correlation).
其中,i和j分别表示Fa和Fb的分条区域索引。
对于不同映射关系的像素点,本文通过设置相应的可学习相关因子来强化两帧区域内的强弱相关性。这种方法的好处在于既能获得全像素对的相关信息,降低对大位移像素离群值的敏感性,又能极大程度地减少区域外的误相关带来的误差。加入强弱关系后的相关体积Cfinal的计算方式如式(3)和式(4)所示:
其中:h(·)表示帧间各个分条区域间的映射关系,与之对应的λj是可学习的自适应相关因子,用来表示不同程度的相关性;⊗为帧间对应区域内像素的点积;C′ij表示区域i和区域j加入强弱关系后的相关体积。本模型利用sigmoid函数将λj的取值范围约束在0~1之间。
至此,对于Fa中的每一个特征点,均计算出Fb中所有特征点与它的相关关系,即相关体积Cfinal,其维度为w×h×w×h。需要说明的是这里的w和h是原始图片的下采样8倍后的宽和高,即之后本文采用4个不同大小(卷积步长分别为1,2,4,8)的卷积核对相关体积的后两个维度进行降采样得到4层金字塔相关金字塔标号q与其维度的关系如式(5)所示:
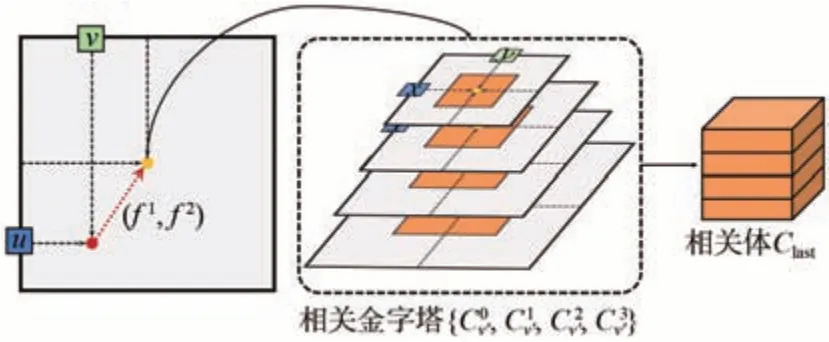
图4 基于相关金字塔的查询操作。橙色部分为不同尺度下的查询点的邻域点集。Fig.4 Lookup operator based on correlation pyramid. The orange part is the neighborhood dot product of the query points at different scales.
其中:dp为查找范围且取整数;r为搜索半径,设定为4像素;Z为正整数集。将该邻域内的所有点看作是Ia中像素点p在Ib上的潜在位置。后续在迭代更新光流的过程中,可借助插值查询操作从相关金字塔中索引得到像素级别的相关特征信息,最后将不同金字塔层的查询结果在特征维度上进行合并,得到最终的相关体Clast。
综上所述,本文以分条区域做强弱相关的方式计算视觉相似度,其好处在于既能获得全像素对的相关信息,又能极大减少由全局匹配所引入的错误信息,进而获得更加准确的相关体信息,为后续光流场迭代更新计算提供支持。
2.3 迭代更新模块
本文主要通过迭代更新模块中的光流序列{f1,…,fN}完成光流估计,其迭代更新过程可以描述为:
其中:Δfk为每次迭代后的更新量,fk为当前光流,fk+1为更新后的光流,k为迭代更新次数。
迭代更新模块主要由基准移动编码模块和卷积门控循环单元(ConvGRU)构成。本文使用卷积门控循环单元对上下文信息和光流信息进行迭代更新,并且提出了基准移动编码模块来增强光流预测图的细粒度。
如图5所示,在基准移动编码模块中,输入为:(1)根据当前光流位移(fk)在相关金字塔中检索出的相关体Clast;(2)当前光流位移(fk)。

图5 基准移动编码模块结构设计Fig.5 Basic motion encoder module structure design
相关体Clast经过卷积滤波器来融合不同相关金字塔层的信息,但基于卷积的基准移动编码模块会产生过于平滑的结果。为了缓解小位移运动在卷积堆叠运算后难以维持局部细致化的问题,本文在卷积滤波器的基础上加入了残差连接(图5中的红色线),用于修正局部的小位移运动,增强最终光流预测图的细粒度。最终卷积滤波器的输出Coutput计算方式如式(8)所示:
此外,对当前光流位移(fk)采用细粒度模块进行处理。细粒度模块由3个核大小为3的卷积核并行构成。并行3个小卷积核不仅弥补了感受野小的不足,同时使得模块更加关注局部的小运动特征。具体处理方法如式(9)和式(10)所示:
其中:flow_i(i=1 , 2 , 3)为光流位移(fk)由3个并行的3×3卷积核经不同输出通道处理获得的光流特征,Foutput为光流特征拼接结果,cat(·)为拼接操作,relu为激活函数。卷积滤波器的输出Coutput和细颗粒模块的输出Foutput在特征维度上进行拼接,成为基准移动编码模块的输出Boutput。
ConvGRU是门控激活单元(GRU)中的全连接层被卷积代替而形成的,同时也是迭代更新的核心算子。采用ConvGRU完成光流估计的主要过程如下:首先输入上一时刻的隐藏状态ht-1(初始化为0)和当前时刻信息xt,之后经过重置门和更新门,最终输出当前时刻的隐藏状态ht,将该隐藏状态ht经过两层卷积即可得到Δf,完成光流的更新操作。具体如式(11)~(14)所示:
其中:xt为第t时刻的基准移动编码模块的输出Boutput和上下文信息Fc在特征维度合并的结果,ht-1为t-1时刻的隐藏状态,ht为t时刻的隐藏状态,h′为t时刻的候选隐藏状态,r为重置门,rt表示t时刻重置门状态,z为更新门,zt表示t时刻更新门状态,W为权重,σ(·)为激活函数,tanh为非线性激活函数。
在ConvGRU的基础上融合基准移动编码模块可以捕获更多的细粒度特征,使结果更加有效地逼近真实光流,最终输出更为准确和精细的光流场。此外,由于在特征提取阶段输出的是1/8分辨率的特征图,因此,迭代更新部分得到的初始光流预测图的分辨率也是原图的1/8。本文通过上采样操作得出与原图相同分辨率的光流场景,与此同时,ConvGRU利用了卷积操作学习上采样的权值。在上采样之后的光流结果中,每一个像素点的值都是其9个粗分辨率邻接区域的凸组合。
3 实验与分析
3.1 实验设计
3.1.1 数据集
KITTI-2015数据集[19]是在真实的交通环境下的街景数据集,其中包含394组训练数据集,395组测试数据集。
MPI-Sintel光流数据集[20]是一个基于动画电影的合成数据集,该数据库分为Clean和Final两个数据集。Clean数据集包括大位移、弱纹理、非刚性大形变等困难场景;Final数据集添加运动模糊、雾化效果以及图像噪声更加贴近现实场景。MPI-Sintel光流数据集包含1 041组训练数据集,552组测试数据集。
3.1.2 评价指标
在KITTI-2015数据集上,采用两种指标评估光流估计结果,分别为光流估计中的标准误差度量(EPE)和光流异常值百分比(Fl)。端点误差(end-point-error,EPE)是光流估计中标准的误差度量,表示所有像素点的真实标签值和预测出来的光流之间差别距离(欧氏距离)的平均值,公式如式(15)所示:
其中:Fi表示预测的光流值,Fgi表示地面真实值。同时,Fl是KITTI-2015数据集中图像整体区域中光流异常值(>3 px或>5%误差)的比率。
在MPI-Sintel数据集上,以EPE和1,3,5 px为性能度量,其中1,3,5 px分别表示整幅图像中EPE<1、EPE<3、EPE<5的像素所占的比例。
3.1.3 训练
本文网络采用端到端方式,对数据集进行常规数据增强(添加随机噪声、随机翻转等),并通过一次性训练构造样本集。运行环境采用PyTorch和Adamw优化器,令Adamw优化器的参数值wdecay为0.000 01,显卡为NVIDIA3090,批量大小为5,对KITTI-2015数据集进行50 000轮训练、MPI Sintel数据集进行120 000轮训练,初始学习率为0.000 1,每5 000轮学习率减少0.000 01。
通过预测值和地面真实流之间的l1距离来监督网络,损失函数如公式(16)所示:
其中:T为12表示迭代次数,初始化光流f0=0,fi为光流序列即{f1,...,fN},Fg为地面真实流,γ初始权重设置为0.8,由公式(16)可得权重随着迭代次数呈指数增长。
3.2 实验结果
3.2.1 KITTI-2015数据集的实验结果
在KITTI-2015数据集上的评估结果如表1所示,其中4分条和6分条分别在EPE和Fl上表现较好。相较于先前结果最好的RAFT(Zachary Teed 等人,2020),通过公式(17)、(18)计算可得,本文方法在EPE指标上降低了8.2%,在Fl指标上降低了0.14%。

表1 不同方法在KITTI-2015测试集上的光流估计性能(↓:数值越小,表现越好)Tab.1 Optical flow estimation performance of different methods on KITTI-2015 test set (↓:The smaller the value, the better the performance)
其中:ηEPE表示EPE降低的比率,EPERAFT表示RAFT的EPE数值,EPEOur(n)表示n分条时EPE数值,F1Our(n)表示n分条的Fl数值,n取4,6,8。PCTFl表示Fl降低的百分点,FlRAFT表示RAFT的Fl数值。
本文记录了KITTI-2015数据集训练过程中EPE指标和Fl指标的收敛曲线。以8分条方法为例,如图6所示,模型的EPE和Fl指标在分别迭代36 k和46 k个Epoches后超过了RAFT,并在训练结束时分别达到0.707 347和1.862 571。

图6 KITTI-2015上的收敛曲线。(a)EPE指标收敛曲线;(b)Fl指标收敛曲线。Fig.6 Convergence curve on KITTI-2015.(a) Convergence curve on EPE index; (b) Convergence curve on Fl index.
图7为在KITTI-2015验证集上的光流预测结果。由图7中的第二行图像可见,RAFT仅构建出栏杆的大致轮廓,而本文方法清晰地构建出栏杆处的细节,如图中红框所示。此外,由图7中的后三行图像可见,在RAFT构建的光流图中,车的整体轮廓和边缘处均有缺陷,而本文方法预测得到的光流图无论是车身,还是车的细节方面均更贴近真实图像,且更为清晰、完整。
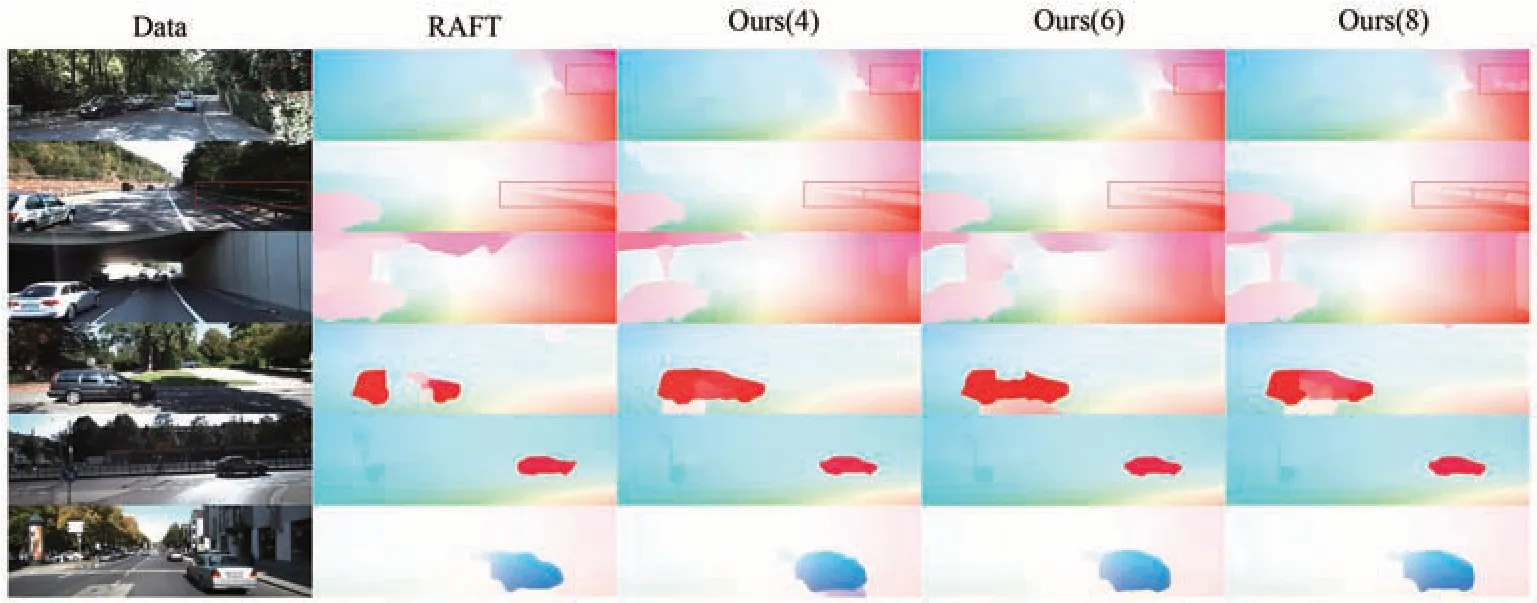
图7 KITTI验证集上的光流估计结果(4,6,8分别为本文提出的4分条区域、6分条区域、8分条区域)。Fig.7 Optical flow estimation results on the KITTI validation set (4, 6, and 8 are the 4-point, 6-point, and 8-point methods proposed in this paper, respectively).
3.2.2 MPI-Sintel数据集的实验结果
在MPI-Sintel数据集上的评估结果如表2所示,其中8分条和4分条分别在MPI-Sintel(Clean)和MPI-Sintel(Final)上的EPE数值较好,相较于先前结果最好的RAFT,通过公式(17)计算可得,EPE分别降低了6.15%和5.87%。除此之外,本文分条策略中的1,3,5 px相较于基准方法均有所提高,从性能度量上来看,本文得到的结果中小误差占比更大。从这个角度分析,本文方法得到的结果鲁棒性更强且在处理局部细粒特征时具有更强的竞争力。
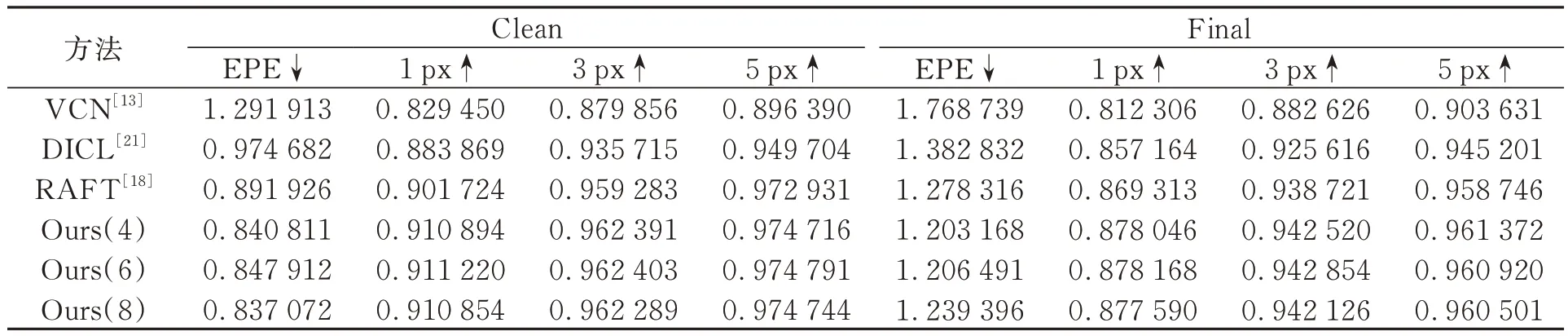
表2 不同方法在MPI-Sintel测试集上的光流估计性能(↓:数值越小,表现越好;↑:数值越大,表现越好)Tab.2 Optical flow estimation performance of different methods on MPI-Sintel test set (↓:The smaller the value, the better the performance; ↑:The greater the value, the better the performance)
在MPI-Sintel(Final)数据集中,本文记录了训练过程中8分条方法的EPE,1,3,5 px指标的收敛曲线如图8所示。为了便于描绘指标的变化趋势,图8中红色阴影部分为实际记录的指标数据,红色折线则为局部平滑后的结果。模型在整个训练过程中逐步收敛,在78k个Epoches后,EPE指标超过RAFT,并在训练结束时达到0.877 59。
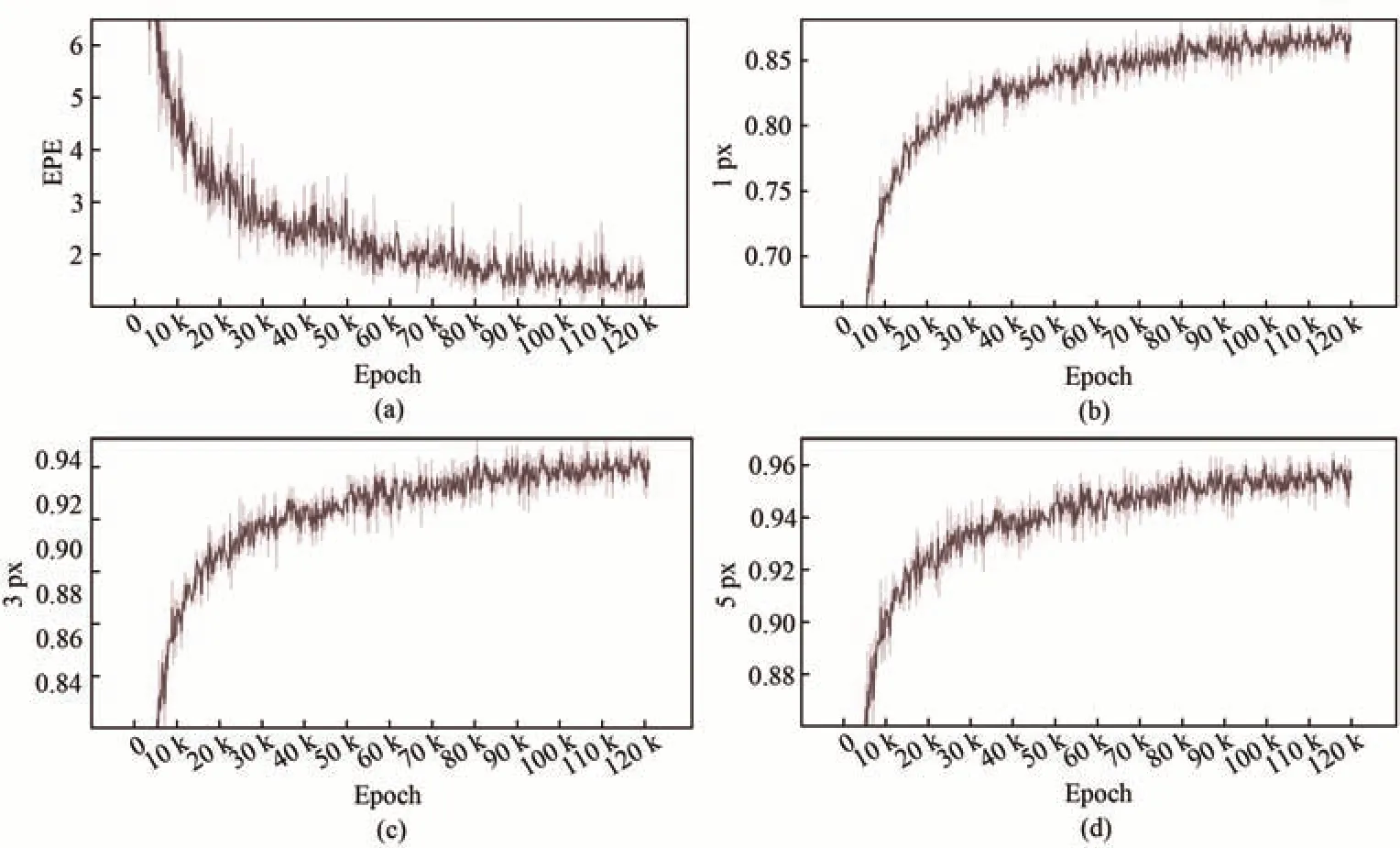
图8 MPI-Sintel上的收敛曲线。(a)EPE指标收敛曲线;(b)1 px指标收敛曲线;(c)3 px指标收敛曲线;(d)5 px指标收敛曲线。Fig.8 Convergence curve on MPI-Sintel. (a) Convergence curve on EPE index; (b) Convergence curve on 1 px index;(c) Convergence curve on 3 px index; (d) Convergence curve on 5 px index.
在MPI-Sintel验证集上预测得到光流结果如图9所示。其中前五行为Clean数据,由图9可见,本文方法在手臂轮廓、腿部轮廓等边缘细节处结果明显优于RAFT,尤其是第五行中RAFT未捕捉到空中两只鸟的光流信息,而本文方法所捕获的鸟边缘信息更为准确。此外,由后两行的Final数据集的预测结果可见,即使面对带有运动模糊的场景,本文方法依然可以很好地将武器以及手部边缘光流信息完整地预测。

图9 MPI-Sintel验证集上的光流估计结果(4,6,8分别为本文提出的4分条区域、6分条区域、8分条区域)。Fig.9 Optical flow estimation results on the MPI- Sintel validation set (4, 6, and 8 are the 4-point, 6-point, and 8-point methods proposed in this paper, respectively).
3.3 消融实验
通过消融实验验证本文提出的各部分模块的有效性,包括分区强弱相关计算、细粒度模块以及残差卷积滤波器,分别采用MPI-Sintel和KITTI-2015数据集进行消融实验。在消融实验中,所有不同的方法组合均采取了相同的训练参数设置和训练轮数。令A(4)、A(6)、A(8)代表4分条区域、6分条区域、8分条区域,B代表使用细粒度模块,C代表使用残差卷积滤波器。实验结果如表3所示,其中BC代表模型使用细粒度模块和残差卷积滤波器的组合,BA(n)表示使用细粒度模块和强弱相关计算方法的组合,CA(n)表示使用残差卷积滤波器和强弱相关计算方法的组合,n取4,6,8。

表3 在KITTI-2015和 MPI-Sintel数据集上的消融实验Tab.3 Ablation experiments on KITTI-2015 and MPI-Sintel datasets
表3中,在使用不同方法的组合进行训练的情况下,使用细粒度模块和残差卷积滤波器的组合构建的光流预测结果获得了最佳的表现。这表明细粒度模块和残差卷积滤波器不仅优化了后期光流和相关体的信息融合过程,并且保留了更多的光流局部的细粒度,使最终的光流预测图在局部小物体中表现得更好,如图7和图9所示。在细粒度模块和残差卷积滤波器组合的基础上,加入8分条的强弱相关计算较为明显地降低了端点误差,并且也获得了最多的最优指标。在KITTI数据集中,BA(6)与BCA(8)的实验结果相差最大,证明残差卷积滤波器在获得更精准的光流信息方面起到了重要的作用,其余实验结果相近。综上,在本文给出的3种方法和模块共同作用下,可以更好地完成光流图的构建。
4 结论
本文融合序列影像相关区域信息给出一种光流估计网络模型,其中计算相似度模块采用分区处理强弱相关信息的方法,能够剔除大量误差信息;迭代更新模块采取了残差卷积滤波器和细粒度模块,缓解了光流结果缺乏局部细粒度的问题。在KITTI-2015和MPI-Sintel光流数据集的实验表明,本文提出的网络模型能够有效提高光流估计的准确率,较好地解决了过度平滑、缺乏细粒度和小物体快速运动估计不够准确的问题。未来的工作将集中在优化模型的运行时间成本和减少参数量方面。
