基于YOLOv5s的航拍小目标检测改进算法研究
2023-10-12刘展威陈慈发董方敏
刘展威,陈慈发*,董方敏
(1.三峡大学 计算机与信息学院,湖北 宜昌 443002;2.三峡大学 湖北省建筑质量检测装备工程技术研究中心,湖北 宜昌 443002)
0 引言
随着基于深度学习的目标检测技术的快速发展,“无人机航拍+目标检测”方法的使用越来越普遍,如森林防火、电路巡检和农业监管等。目前针对“小目标”的定义主要有2种:一种是绝对尺寸,尺寸小于32 pixel×32 pixel的目标被认为是小目标;另一种是相对尺寸,根据国际光电工程学会定义,小目标为256 pixel×256 pixel的图像中成像面积小于80 pixel的目标,即目标的尺寸小于原图的0.12%则可被认为是小目标[1],因此研究出一个针对航拍小目标检测的算法模型成为关键的研究内容之一。
目标检测从早期的传统方法到如今基于深度学习的方法,发展已有21年。当前基于深度学习的目标检测算法有2种:第1种是以Faster R-CNN[2]为代表的双阶段检测算法等,利用算法生成预选框,再使用深度卷积网络对预选框进行检测类别的分类,双阶段检测算法的精度更高,但速度过慢,不能满足实时性要求较高的场合;第2种是以YOLO[3]、YOLOv3[4]、YOLOv4[5]、YOLOv5以及SSD[6]为代表的单阶段检测算法,将检测框的定位和分类任务结合,能够快速检测出目标位置,通过适当地改进可同时具有更好的实时性与检测精度。韩玉洁等[7]在YOLO上进行数据增强,修改激活函数,添加CIoU,修改后模型精度有所提升,但模型内存占用过大。丁田等[8]加入注意力以及CIoU,加快了模型收敛速度,增加检测准确率,但同时也增加了计算成本。肖粲俊等[9]加入注意力机制,并引入自适应特征模块,增强了网络特征提取能力,但精度提升幅度较小且漏检率过大。目前改进方法主要通过添加模块来提升检测精度,但同时增加了计算成本。因此本文不局限于模块添加,将在网络结构上进一步改进。
目前无人机航拍检测任务主要有以下难题:
① 不同于普通目标检测,航拍所检测对象大多数是小目标,可以提取到有用的特征过少,绝大多数算法都存在对小目标检测的漏检、误检问题。
② 现实场景中目标繁多,图片中背景复杂,常常混杂许多其他干扰性较大的目标。
③ 由于飞行高度问题,各个目标之间大小不同,存在着尺度不一致的问题,导致检测效果不佳。
为提高无人机航拍目标的检测精度,结合应用场景的限制,本文提出一种基于YOLOv5s的航拍小目标改进算法VA-YOLO。该算法主要改进与创新有:
① 融入模块来重新构建主干网络,提升对小目标的检测精度。
② 通过添加小目标检测层与加权双向金字塔(Bidirectional Feature Pyramid Network,BiFPN)[10]将深层语义跟浅层语义进行多尺度特征融合,解决尺度不一、特征信息利用不充分的问题。
③ 将损失函数改为Varifocal loss与EIoU,解决检测精度低与背景干扰过大的问题,使得算法对小目标取得更好的检测效果。
1 YOLOv5s算法
YOLOv5是一种单阶段的目标检测算法,相比较前一代,它汲取了许多优秀网络结构的优点,精度更高、速度也更快,已经能够做到实时地检测目标。YOLOv5一共有4个版本:YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x四种,其网络深度和宽度逐渐加大。考虑到应用场景,相比其他3个版本,YOLOv5s的网络结构最简洁,运行速度最快,计算资源消耗最少,同时也更容易移植到其他平台,本研究选择使用模型深度与宽度最浅的YOLOv5s模型。其网络结构如图1所示。
YOLOv5s模型主要包括图片输入端、Backbone网络、Neck网络和Head输出层四部分。
输入端会对输入的图片进行预处理。首先,对几张图片进行随机裁剪拼接,不仅可以充分利用数据集,还能提升训练速度;其次,在模型训练中,YOLOv5s算法根据数据集自适应地计算出最佳锚点框,考虑到无人机航拍检测对象绝大部分为小目标,本文将锚框调整为[3,4,4,8,6,6]、[6,12,12,9,11,17]、[21,11,17,22,36,18]或[26,34,54,41,100,85];最后,将图片调整到统一大小后输入到Backbone网络中。
YOLOv5s(6.0)[11]的Backbone网络由特征提取模块CSP[12]、卷积模块CBL与空间金字塔池化(Spatial Pyramid Pooling-Fast,SPPF)模块组成。CSP结构分为2类,如图2所示。SPPF模块不再使用1×1、5×5、9×9、13×13的最大池化,而是通过多个5×5的MaxPool2d取代原有的池化层,例如2个5×5卷积操作代替一个9×9的卷积操作,用以提高效率。CBL由Conv、BN归一层和Leaky ReLU激活函数组成,如图2所示。
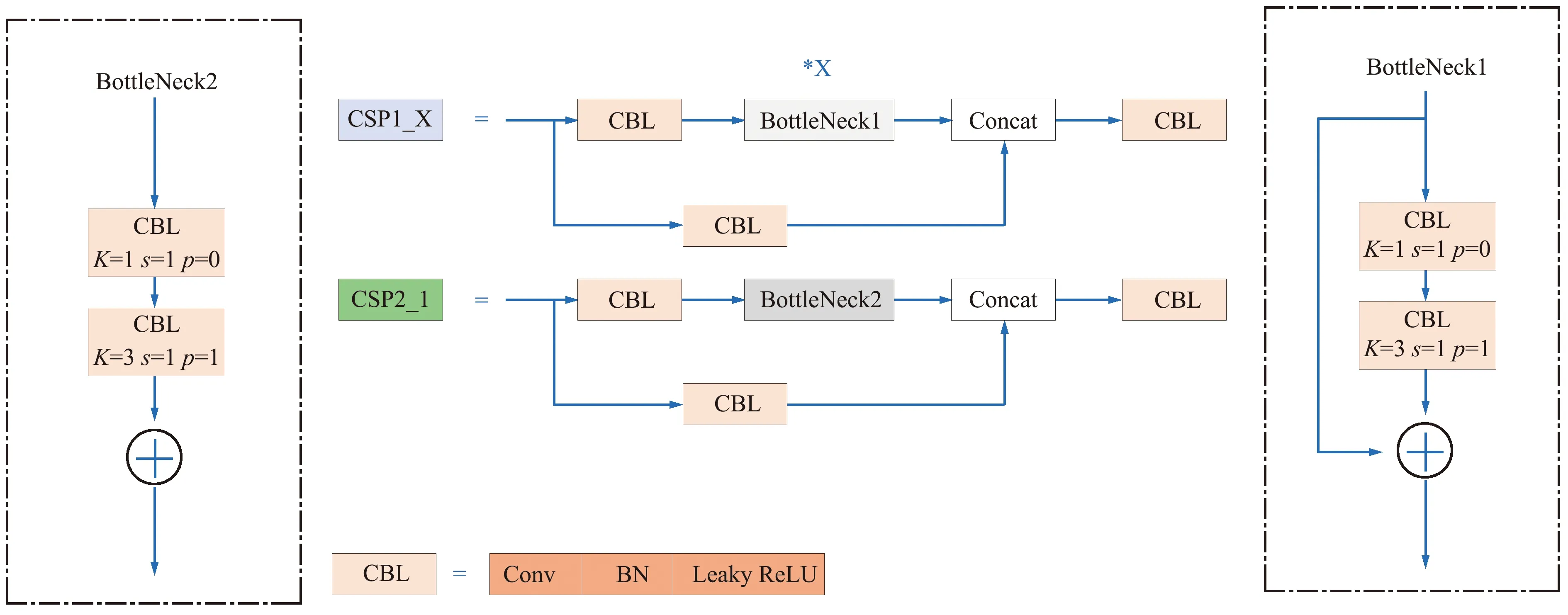
图2 CSP和CBL结构Fig.2 Structure of CSP and CBL
Neck由特征金字塔网络(Feature Pyramid Networks,FPN)[13]和路径聚合网络(Path Aggregation Network,PAN)[14]构成。FPN自上而下用来强化语义特征,PAN自下而上用来强化位置特征,二者将不同阶段特征图进行特征融合,提高对主干网络输出特征的利用率,从而提升对小目标检测精度。
Head输出层主要是对Neck层的3个输出进行卷积操作,并在大小为20×20、40×40、80×80的特征图上生成对应的预测边界框。
2 VA-YOLO算法
YOLOv5s具有较好的检测效果,但其平均检测精度(mean Average Precision,mAP)与YOLOv3、ClusDet[15]等主流算法相比仍有较大差距,因此,本文将从Backbone网络、Neck网络与Head输出层、损失函数三方面对YOLOv5s进行改进,力求在不增加运算资源消耗的同时提高精度。
2.1 Backbone网络的改进
YOLOv5s在进行航拍目标检测时,往往检测的对象过小,检测过程中容易丢失特征信息,导致检测效果不佳。因此本文加入Coordinate Attention(CA)[16]注意力机制,可以让算法模型集中在需要关注的区域,有效提升对小目标检测的精度。与Squeeze-and-Excitation(SE)[17]注意力机制使用2D全局池化转变成单个特征向量不同的是,CA将其分成了2个不同方向聚合特征的ID编码,既可以获得空间方向的长程依赖,同时也不会缺少位置信息。CA结构如图3所示。

图3 CA结构Fig.3 CA structure
首先在输入端使用2个池化核向水平方向和竖直方向进行池化,得到高度为h,宽度为w的输出。然后将输出的特征图进行融合拼接后使用1×1大小的卷积核进行卷积,生成过渡特征图。其次,将过渡特征图分解为单独的特征图,再使用1×1大小的卷积核进行卷积,得到与输入一致的通道数量。最后使用激活函数,将结果与输入进行相乘输出,从而达到强化特征的目的。
为同时确保检测网络的大小与精度,经过实验,选择在Backbone网络中将原有的一个CSP模块替换为CA模块,不仅计算资源开销更低效果也更为明显,实验对比结果如图4所示。图4(a)为未更改的YOLOv5s检测情况,图4(b)为将CSP替换为CA的检测效果图。可以看到图片下方不仅检测出多个漏掉的行人以及摩托目标,而且准确率也有所提升。实验结果表明,加入注意力机制后,在检测小目标上模型效果得到显著提升的同时也具有较好的鲁棒性。

(b)替换为CA的检测效果图4 检测效果对比Fig.4 Comparison of detection effects
2.2 Neck网络与Head输出层的改进
通常来讲,无人机航拍图像检测都是小目标,目标的类别以及位置尤为重要,对于较浅层分辨率较高的特征图,往往能够保留更加全面的小目标位置信息;较深层的分辨率较低的特征图,往往保留大目标特征复杂的语义信息。因此,本文在YOLOv5s原有基础上,通过添加小目标检测层来继续上采样扩大特征图,进而增强多尺度之间的特征图的关联,让更为浅层的位置信息与深层的语义信息进一步结合,提升对小目标信息的利用率。
YOLOv5s中Neck网络部分使用的是FPN+PAN结构,主要是为了解决检测小目标精度不佳的情况,通过FPN结构将浅层特征图的位置信息进行向下的递增,再使用PAN结构做向上的语义信息的递增,达到融合多层特征信息特征图的效果。但这种方式只能进行相同尺寸特征图之间的融合,未利用到不同尺寸的特征图信息。因此,本文引入了新的BiFPN特征图融合网络结构。首先,将单个特征图输入的节点去除,由于该节点融合的特征信息过少,去掉可以避免不必要的运算;其次,融合同一尺度但更浅层的特征图,强化了特征图的丰富性;最后,不限于自顶向下或者自底向上的路径,将删除节点的输入特征图输出到下一级特征图中,形成新的BiFPN结构,如图5所示。P1、P2、P3、P4为经过主干网络的特征图,F1、F2、F3、F4为经过BiFPN处理后的特征图。
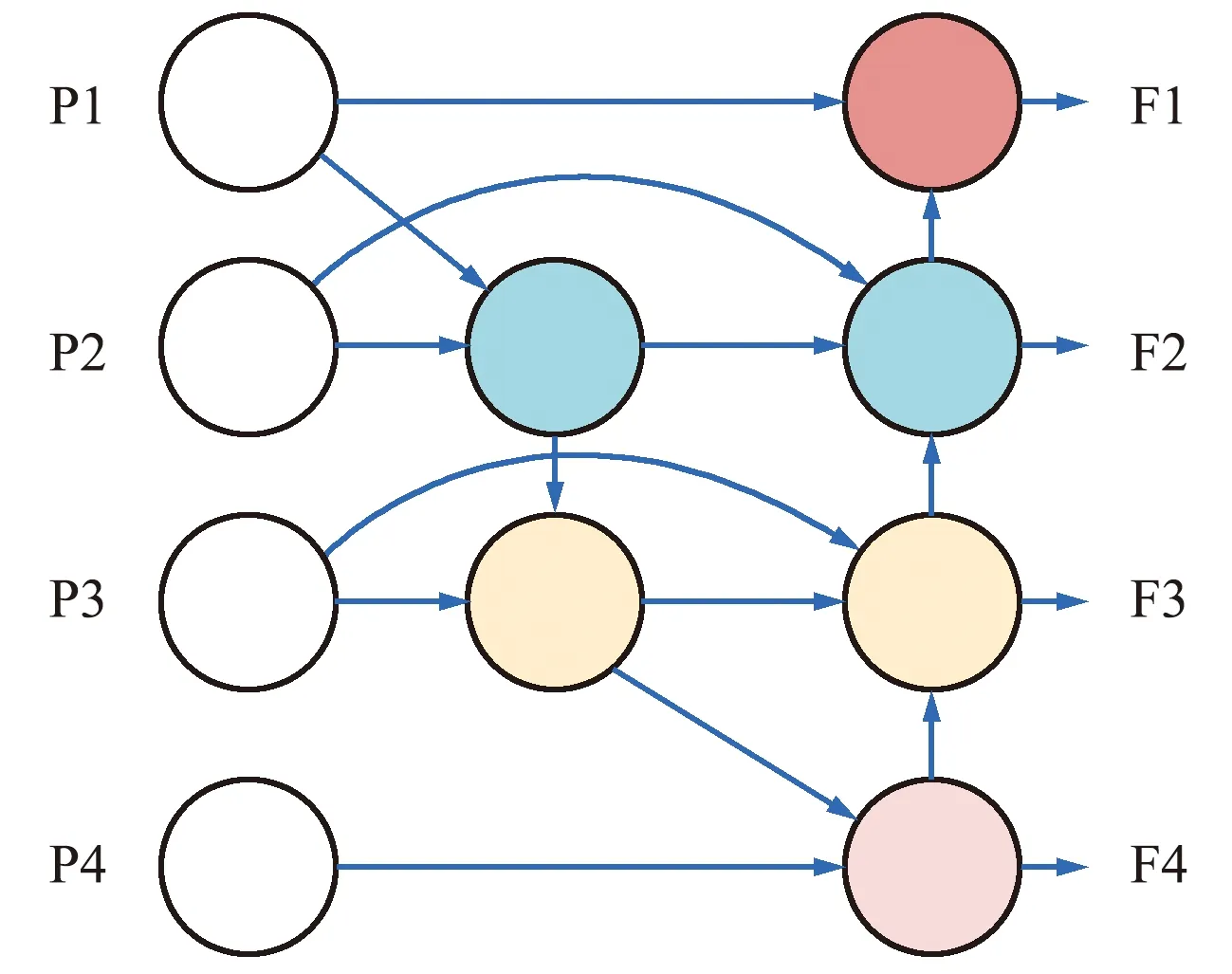
图5 BiFPN结构Fig.5 BiFPN structure
BiFPN使用加权融合,通过权值来控制对不同特征信息的学习程度,这里BiFPN使用快速归一化法,即:
(1)
式中:ωi为经过网络训练的权重,由激活函数确保其大于等于零,ε用来保持整体结果的稳定性,为常数,Ii表示输入图片的特征,Out表示融合结果。经过改进后,BiFPN从Backbone网络中提取不同尺度的特征图进行加权特征融合。
增加小目标检测层后,其对应检测层输出也比原有多了一个,分别为160×160、80×80、40×40、20×20,其中最大的特征图为添加的小目标检测层。例如,在17层过后,增加上采样的同时,在20层与Backbone层中的第2层特征图进行拼接融合,由此获得更大的特征图用以进行小目标检测。
2.3 损失函数的改进
YOLOv5s的损失计算主要有矩形框损失(box_loss)、置信度损失(obj_loss)和分类损失(cls_loss)三种,YOLOv5s使用CIoU_LOSS[18]作为衡量矩形框的损失。矩形框损失函数为:
(2)
(3)
式中:IoU为预测的物体框和真实的物体框的交集的面积与并集的面积之比,b、bgt分别表示预测框和真实框的中心点,ρ2(b,bgt)为计算2个中心点的欧式距离,c为能同时包含预测框和真实框的最小闭包区域的对角线距离,α为权重函数,υ用来度量长宽比的相似性,w为宽,h为高,gt为真实框,p为预测框。
CIoU同时考虑了边界框的重叠面积、中心点距离以及长宽比,但长宽比v是一个模糊值,并不精确,并且CIoU未能很好地平衡正负样本的问题。所以本文选用EIoU[19]作为矩形框回归的损失函数,EIoU_Loss函数为:
(4)
式中:EIoU Loss总共包含3个损失,即重叠损失、中心距离损失和宽高损失,前半部分参数与CIoU一致,Cw与Ch为覆盖2个边界框的最小外接框的宽度与长度。EIoU在CIoU基础上将宽高比进一步细节化,解决了宽高比过于模糊的问题,有效提升了回归框的精度。
YOLOv5s的置信度与分类损失使用BCEWithLogitsLoss损失函数,该损失函数将sigmoid与BCELoss整合到一起,在输入之前自动进行sigmoid激活操作映射到(0,1),然后再对输出和target进行BCELoss处理。其BCEWithLogitsLoss计算公式为:
(5)
ln=-ω[yn·lnxn+(1-yn)·ln(1-xn)],
(6)
式中:N为样本数量,ln为第n个样本对应的loss,xn为对应样本的预测概率,由sigmoid激活处理,yn为对应样本类别的真实概率,取0或1,ω为超参数,表示样本真实类别。sigmoid函数为:
(7)
BCEWithLogitsLoss通常用于检测较为明显的样本,但对于无人机航拍的小目标样本而言,存在着大量负样本,类别极其不均衡,且占比大容易对训练结果产生影响,从而降低模型检测目标的精度。因此,本文引入置信度与定位精度的IoU感知分类评分(IoU-Aware Classification Score,IACS),该评分可以同时表示物体样本置信度与位置精度,从而在密集小目标中生成更为优秀的检测排序。在此基础上引入了Varifocal loss,该函数由Focal Loss[20]改进而来,Varifocal loss函数定义为:
(8)
式中:p为前景类的预测概率,q为目标IoU得分。在训练的正样本中,将p设置为生成的预测框和真实框之间的IoU;而在训练的负样本中,所有类别的训练目标q均为0。
本文借鉴了Focal Loss利用加权的方法解决样本不平衡的问题,Focal Loss选择平等地对待正负样本,但本文选择有所重点地对待它们。Varifocal loss首先预测IACS评分,再通过p的γ次方人为地降低负样本的权重,正样本保持不变。再通过q的IoU得分提升正样本的权重,由此实现将训练重点放在高质量的样本上。同时,为了让正负样本的比例更加合理,在上述公式中添加了α因子来进行平衡。
2.4 VA-YOLO网络结构
根据上述改进方法,可以得到本文的VA-YOLO算法,其网络结构如表1所示。
3 实验与结果分析
实验环境配置:CPU为AMD Ryzen 7 5800H with Radeon Graphics 3.20 GHz,GPU为NVIDIA RTX3060 6 GB显存,操作系统为Windows 11,学习框架为Pytorch1.9.0。
3.1 数据集
本文所使用的数据集是VisDrone2019-DET[21],共包含8 599 张静态图像,其中6 471 张用于训练,548 张用于验证,1 580 张用于测试。类别主要包含行人、人、汽车、面包车、巴士、卡车、摩托车、自行车、遮阳棚三轮车和三轮车。
3.2 消融实验
使用单类别平均精度(Average Precision,AP)、多类别mAP、精准率(Precision)、模型权重和检测速度(Frame per Second,FPS)作为评价指标。共设置了以下几组不同情况下的实验:YOLOv5s、替换为CA模块的YOLOv5s、网络结构更改后的YOLOv5s、损失函数改进后的YOLOv5s、VA-YOLO,以此来验证各个模块的提升效果。实验结果如表2所示。
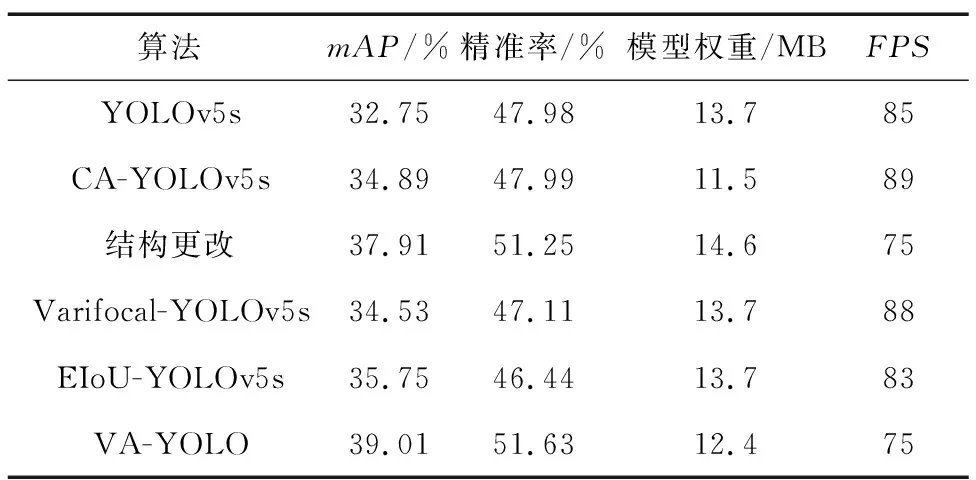
表2 消融实验结果Tab.2 Results of ablation experiments
表2中的结果表明,加入CA注意力机制后,mAP提升了2.14%,模型权重减少2.2 MB,这是因为将CSP替换为更轻量化的CA后,整体网络层数减少了13层,从而训练生成的模型权重也略微降低;结构更改后mAP提升了5.16%,但模型权重增加0.9 MB;Varifocal loss的引入带来精度的小幅度提升,同时不会导致模型体积的增加;损失函数的改进在保证模型权重不变的情况下,mAP分别提高了1.78%、3%。综上所述,VA-YOLO的绝大多数指标有优势,其中mAP提升了6.26%,且模型权重也有所下降,仅只有PFS低于其他模型。由此可见,改进后的算法对网络性能的提升起到了明显作用。
3.3 对比试验
为了验证本文算法较其他算法的优势,本文与各种主流算法进行对比,结果如表3所示。其中mAP相比Mixed YOLOv3-LITE提升了10.5%,相比次高位提升了6.2%。而在行人、人、汽车、面包车、巴士、摩托车和自行车这7个类别的AP都达到了最优检测效果,各自取得了48.2%、37.4%、81.2%、40.8%、51.4%、44.8%、14.8%。本文算法经过改进后对小目标关注度更多,提升了对其特征信息的利用,同时融合多个尺度的特征图,减少特征信息的丢失,提升了对小目标的检测效果。根据实验可知,本文算法在检测种类繁杂、检测对象过小时,依然能够充分利用特征图中的小目标信息,在进行航拍图像小目标检测时拥有更大优势。
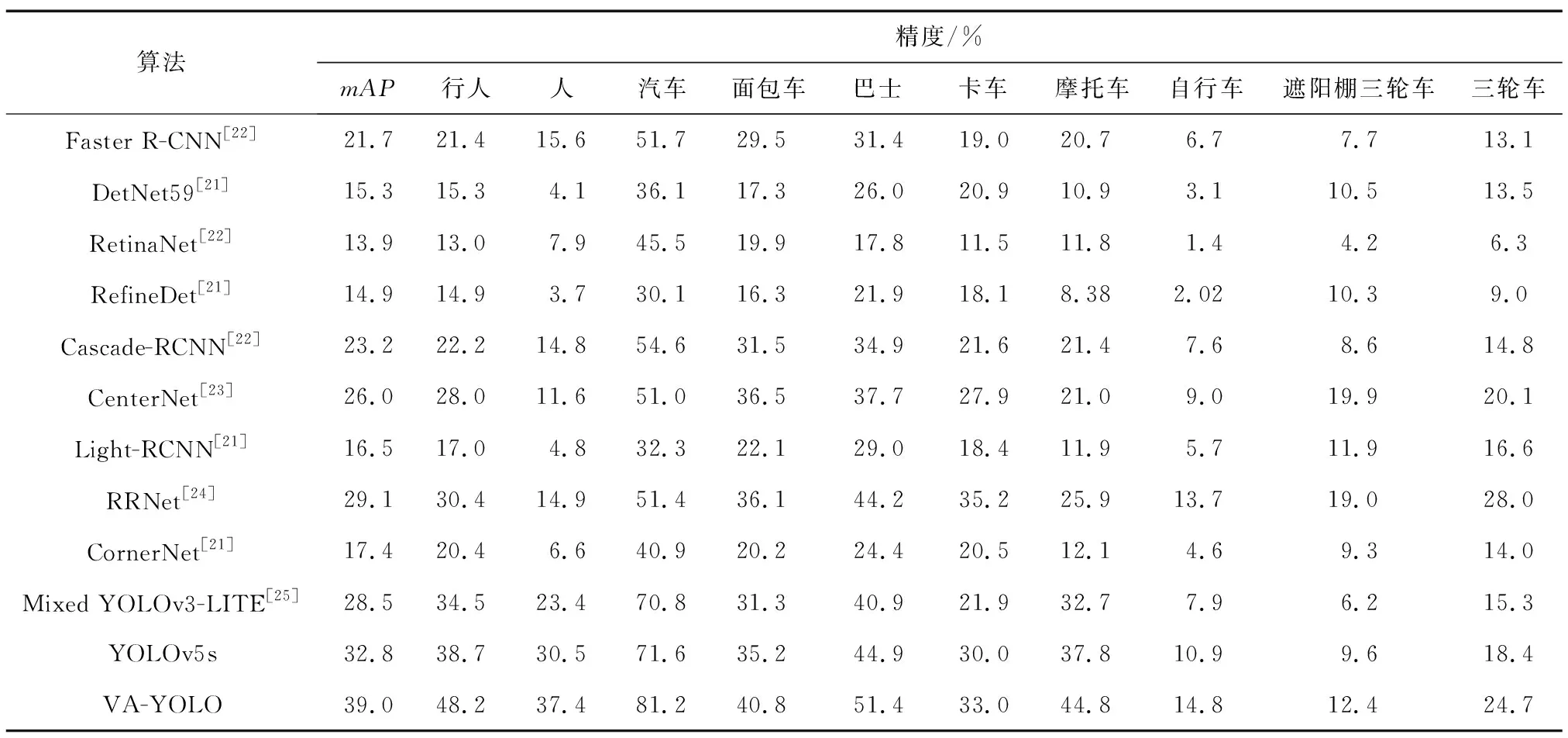
表3 对比试验结果Tab.3 Comparative experiment results
3.4 算法效果与分析
为了进一步验证本文算法在实际场景中的效果,选取测试集中具有挑战性的图片进行可视化对比,类型分别为:密集人群小目标、复杂干扰背景小目标、高空车辆小目标、远距离多尺度小目标。检测结果如图6所示,左侧为本文算法实验效果,右侧为未经更改的YOLOv5s实验效果。经过改进后的算法融合了不同尺度下小目标的语义信息,强化了对小目标的特征信息利用,同时也减少对目标的误检、漏检问题。例如在夜间密集人群环境下,本文算法能够检测更多行人目标与车辆目标,且受到光照等背景因素影响的可能性也更小,有效降低了误检率与漏检率。综上所述,本文改进后的算法对比未经更改的YOLOv5s算法具有显著的优势,检测准确率更高、抗干扰更强,对于常见环境下密集小目标检测的特征信息提取均有明显提升。





4 结束语
本文提出的基于YOLOv5s的无人机目标检测算法,针对航拍目标对象大小不一致、类别繁多且易受背景干扰的问题,首先用CA模块替换掉Backbone网络中的一个CSP模块,在能够小幅提升检测精度同时,还能降低模型参数量与模型权重,并对密集小目标更有兴趣。其次更改网络结构,将YOLOv5s中未被利用到的浅层特征图与已有的深层特征图进行融合,并添加小目标检测层来对小目标进行针对性的检测,有效减少语义与位置信息的丢失。接着改进损失函数,引入了Varifocal loss与EIoU函数,降低负样本权重并提高正样本权重的同时提升回归框的准确性。最后同几种主流算法进行对比实验,实验证明,本文算法的精度在VisDrone2019-DET数据集上同其他算法相比具有一定优势,但由于网络结构的更改,一定程度上增加了训练之后模型推理的时间开销,因此后续工作重点将优化模型参数,在保证速度的同时使其能够更好地应用于不同环境。
