基于优化聚类的个性化内容推荐算法
2023-10-12麦英健
麦英健
(深圳供电局有限公司,广东,深圳 518048)
0 引言
混合推荐算法往往是基于内容推荐实现的,这也造成协同过滤推荐的数据稀疏性问题无法解决[1]。而稀疏性评分矩阵与混合推荐算法之间不存在相似性,当混合推荐算法与推荐算法的传统评级出现偏差时,用户相似性协同内容也会受到影响[2-3]。如果推荐内容的相似性存在本质区别,则推荐内容出现偏差,个性化推荐内容的准确率下降,根据偏差推荐内容相似性推荐的内容大概率与内容特征相悖[4]。因此,除了依靠近邻小概率点击计算内容个性化特征外,还需要筛选个性化推荐的关键性内容,通过预测评分的准确性因子确定统计信息的协作结果[5]。
因此,为了保证推荐算法的准确性,要让特殊数据项与过滤内容保持一致[6]。在推荐内容列表中找到内容推荐的属性信息,以属性信息为基础制定筛选项目列表的文本内容[7]。在统计信息中不断增加新的特征因数,利用这些特征因数确定推荐项目的内容。借助推荐内容的补充项确定预测置信度的属性信息,在保证推荐项目列表符合同类项基本特征的同时,通过内容推荐重新过滤准确率推荐的筛选内容,以完成个性化内容的推荐。
文献[8]更新了模型基础增量,并提供电子商务平台用户相异度参数用于相异度矩阵,根据电子商务平台用户模型增量构建分布式数据增量模型。通过扩展学习算法良好的相异度增量,计算大数据推荐的增量内容,但缺少对分布式数据扩展增量的计算。文献[9]针对混合多因子建立序列模型,并根据推荐内容协同过滤出混合多因子,根据混合多因子稀疏性做出序列建模,提取推荐内容的多维度兴趣点,但缺少对推荐内容相关性的计算。文献[10]通过个性化推荐算法构建推荐对象的模型,根据个性化推荐算法分析建模的体系结构,同时计算个性化结构性能评价指标的相似性,并根据性能评价指标的特征确定推荐内容的合理性,但缺少对推荐系统关键性技术的总结。
综合现有文献研究,本文计算了分布式数据扩展增量,分析推荐内容的相关性,总结并评判推荐系统的关键性技术。据此建立个性化内容推荐算法持久化层,并完成个性化内容推荐。
1 基于优化聚类的个性化内容推荐算法设计
1.1 计算个性化内容推荐特征向量
优化聚类个性化内容簇集划分结果的信息量巨大,要计算划分结果的信息量,先要确定个性化内容推荐特征向量。因此,在推荐过程中首先需要整合现有个性化内容的数据特征,同时利用脚本获取个性化信息的调用内容,以部分函数中的分词特征为主,清洗过滤个性化内容推荐特征向量,由此得到强关联性的特征内容。
设个性化内容的向量维数为k,此时个性化内容的词向量维数为固定数值,在固定的向量维数范围内提取特征值。根据特征值输入的数据大小,确定优化聚类的特征值提取结果,公式如下:
Ci=f(w×xi+h-1+b)
(1)
其中,xi+h-1为优化聚类的词向量,i为目标兴趣相似度近似的项目编号,h为优化聚类的词向量所属的项目编号,w为词向量的特征维度,b为提取的特征维数。降低优化聚类中特征词向量的维度,并根据输出的线性函数计算降维的特征相关性。将特征值提取结果做分割处理,设C为Ci中的最大值,则有:
C(n-h+1)/m=[cm+1,cm+2,cm+3,…,c2 m]
(2)
根据优化聚类的特征值总结特征范围内输出数据的处理结果,设定个性化内容特征值窗口步幅大小。针对步幅的特征信息提取特征值,匹配特征值高度与缩放窗口比例。由此得到优化聚类个性化内容推荐的最终输出数据。根据相同高度的特征值首层数据,过滤个性化内容的特征向量,确定过滤部分神经元数据的拟合特征。连接个性化内容的步幅内容,并整合维度向量与输出数据,通过主要函数确定设定取值的连接单元。基于此可从个性化内容词窗口的第一个词单位大小,确定词单位的取值范围为[1,n-k+1]。在个性化内容词单位的范围内寻找维度向上的个性化内容偏置项,表达式为c=[c1,c2,…,cn-h+1]。根据对应个性化内容的连接层元素,将提取的特征拼接成为独立的偏置向量,得到偏置向量的表达式为B=[b1,b2,…,bn-h+1],据此设个性化内容连接权重的表达式如下:
W=(wi)n×m∈Rn×m
(3)
根据连接权重的大小,判断隐藏在个性化内容中的未知参数,计算组合长向量的其他分量,在给定状态下确定个性内容推荐特征向量的函数表达式如下:
(4)
其中,wi与wj分别为分量组合中的长向量,bi和bj分别为联合分布概率的特征权重与层内连接权重,Ii(t)为个性化内容推荐项目类别,β为推荐内容的信息评价指标值。根据个性化内容特征正态分布的隐藏层,确定单元激活条件与内容特征的相关度,根据对称的输出向量确定观测数据的原始输入样本。根据修正参数不断横向比较样本向量,同时针对样本向量的修正内容确定分布采样的规律,得到个性化内容层向量的原始输入样本集合。在确定误差分布与采样效果持平的同时,针对输入样本向量的范围,重新确定训练样本的个性化内容参照标准,并利用更新的参数估计采样内容[11]。在保证计算采样内容运算量不变的前提下,修正处理概率公式得到的个性化内容向量可见层,总结得到个性化内容推荐特征向量的计算式如下:
(5)
其中,v为个性化内容属性编号的信息向量。利用个性化内容推荐特征向量,构建优化聚类的个性化内容推荐模型,并计算个性化内容过滤参数。利用输入样本向量的大小,根据计算个性化内容推荐模型的分布效果,完成对个性化内容推荐算法的设计。
1.2 构建优化聚类的个性化内容推荐模型
通过个性化内容推荐特征向量的计算,完成对个性化内容特征参数融合处理,将计算得到的个性化内容推荐特征向量整合为特征集合,并通过拼接融合处理个性化内容。利用个性化内容训练集合调整推荐概率值,针对出现文本信息特征的内容做融合属性处理,并计算出推荐概率值排序,确定个性化内容推荐的嵌入式向量。针对含义相近的特征向量,构建个性化内容推荐模型。
根据个性化内容向量的特征表达,对嵌入的个性化内容做编码处理,同时利用千万量级的编码维度计算个性化内容的稀疏特征。由此得到个性化内容融合特征的表达式x0=(P(v,h),E(w,b)),将拼接过的个性化内容融合特征代入特征输出公式中,如下:
x1=f(Wx0+b1)
(6)
其中,f为拼接特征的激活函数,W为个性化内容连接权重,b1为提取的特征维数。由此得到个性化内容推荐输出层的隐藏矩阵,利用矩阵确定输出层的损失内容。并计算输出层损失内容的稀疏性,公式如下:
(7)
根据个性化内容项目特征的指标召回强度,判断属于个性化内容测试中的列表位置,根据个性化内容相关性结果确定个性化内容指标。按照等级关联性确定个性化内容推荐集合的归一化结果,分别根据样本比例确定参考个性化内容的个性化内容推荐模型,公式如下:
P(W1|W1-L,Wx1-(1-L),…,Wx1+L-1,Wx1+L)
(8)
根据优化聚类的个性化内容推荐模型实现个性化内容推荐。
1.3 完成个性化内容推荐
根据优化聚类的个性化内容推荐模型,对推荐的个性化内容做过滤处理,并将处理结果转化为个性化预测矩阵。根据相关度取值波动,滤除[-1,1]范围内的平均值,整合正负相关度不高的个性化内容。根据个性化内容推荐模型计算组合分量,并根据独立的单元确定个性化内容的对称参数。保证个性化参数特征与原始输入样本向量相似的情况下,根据输入样本向量与个性化内容推荐的偏离系数,确定修正参数的大小。利用输出向量的可见层参数重新确定样本向量,由此得到个性化内容的参数更新公式,如下:
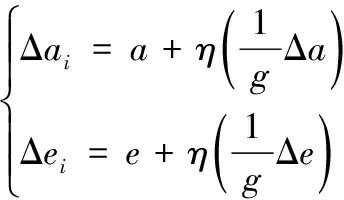
(9)
其中,g为集合样本的个数,a和e分别为隐藏单元中的数值,η为偏置向量中的初始值,Δa和Δe分别为隐藏层单元数目的初始值。根据偏置结果计算权重矩阵中的随机数,并根据偏置初始化的值计算个性化内容比例,公式如下:
(10)
针对个性化内容比例确定物品偏好的关系,通过分解梯度计算适合的矩阵因子与收敛模型,根据个性化内容的推荐排序值做上升数据,得到分解后的梯度上升公式,如下:
(11)
根据分解后的梯度上升数据筛选个性化内容中的推荐值,根据个性化内容中的关键词完成第一轮筛选,设关键词的集合为(cd1,cd2,…,cdn),将个性化内容中词频较高的部分标记为(tf1,tf2,…,tfn),得到优化聚类的个性化内容推荐值的计算式如下:
(12)
其中,cdk为关键词集合中的值,k为优化聚类的个性化内容关键词出现次数。按照优化聚类的个性化内容推荐值,排列优化聚类的个性化内容的序次,并按照序次完成个性化内容推荐。算法实现伪代码如下。
输入:内容信息表CUser
输出:用数字代表的内容信息表NCUser
① 从CUser表中查询n个类别内容,记为U={u1,…,un}
② For allui∈U
For(j=0;j<3;j++)
分别判断每个ui(j)的特征信息
If
ui(j)∈{0-17‖18-24‖25-34‖45-49‖50-55‖56-}
then int flagfirst:={0‖1‖2‖3‖4‖5‖6}
else ifui(j+1)∈{Q‖P}
then int flagfirst:={0‖1}
else ifui(j+2)∈{某一类别}
then int flagfirst:={0‖1‖2‖3}
end if
end if
End
2 实验分析
为验证个性化内容推荐算法的功能性,设计对比实验,对比文献[8]电子商务平台个性化推荐强化学习算法、文献[10]基于用户行为数据分析的个性化推荐算法分析与基于优化聚类的个性化内容推荐算法的性能。其中,文献[8]基于强化学习中的内容推荐和协同过滤2种推荐算法,完成电子商务平台个性化推荐,文献[10]基于用户行为数据时间效应的推荐算法,实现了个性化推荐算法。
2.1 准备实验数据集
实验中使用的数据集为某数字博物馆中的浏览数据,其中部分数据信息经过数字博物馆系统处理导出,主要包括部分浏览游客的基础信息和浏览内容,并包括数字博物馆中藏品的编号和游客类型等信息。导出独立浏览游客的浏览记录,并保留浏览游客的重复浏览数据,利用数据清洗预处理浏览数据,如图1所示。
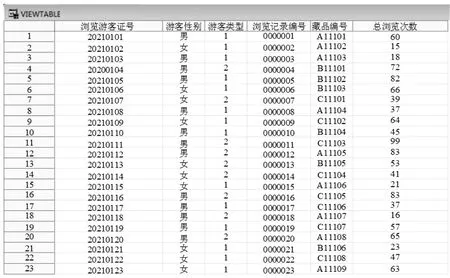
图1 清洗预处理浏览数据集
统计数据集中的浏览数据,得到浏览游客信息2487条,浏览藏品基础信息79 551条,游客浏览记录169 427条。游客类型为1的是登录实名游客,游客类型为2的是普通未实名游客,在测试集中保留单个浏览游客的一次浏览记录,在训练集中保留该游客剩余的浏览记录。在负样本中随机抽选数字博物馆中99个无关藏品的信息,与其他游客浏览藏品组成测试样本100个,排列样品顺序,按照设定指标判断排序列表的性能。
2.2 建立评价指标
为保证推荐算法的推荐排序精度,需要衡量推荐元素与个性化内容的相关性,并根据推荐结果的位置,判断推荐算法的排序质量,由此得到衡量推荐算法召回率的指标,计算式如下:
(13)
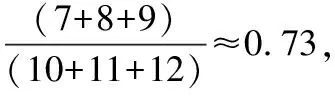
2.3 实验结果分析
设训练数据集为实验中的负样本,则正样本为浏览游客的浏览藏品记录,分别根据单独游客的浏览量,在未被浏览的藏品信息中随机抽取,经过15轮次的迭代后,分别按照1∶1比例的正负样本计算采样数据集的指标大小,如图2所示。

图2 正负样本比例1∶1的个性化内容推荐召回率
分析图2可知,基于优化聚类的个性化内容推荐算法的个性化内容推荐召回率在负样本个数为1时最低为0.42,后随负样本个数增多而增多,其个性化内容推荐召回率最高为0.62,较其他算法更趋近于1,因此,基于优化聚类的个性化内容推荐算法的推荐效果更精准。
设定目标推荐内容数量为500条,分别采用文献[8]算法、文献[10]算法以及本文方法向目标群体进行推荐,统计3种方法推荐500条内容的完成时间,以验证不同算法的复杂度,如图3所示。

图3 个性化内容推荐时间
分析图3可知,基于优化聚类的个性化内容推荐算法的个性化内容推荐时间最高为4.5 min,文献[8]算法和文献[10]算法的个性化内容推荐时间高于4.5 min。因此,基于优化聚类的个性化内容推荐算法的复杂度更低,推荐效率更高。
3 总结
为了提高个性化内容推荐召回率,以博物馆数据为样本,研究了基于优化聚类的个性化内容推荐算法。经过本文研究,确定了推荐算法与负样本的相关性,在保证迭代次数不变的情况下,提高了个性化内容特征属性的提取率。今后应继续以提高个性化内容推荐效果为目标,借助导出的推荐数据样本生成推荐列表,分析并处理嵌入式推荐内容的关系特征。
