基于集成学习后融合神经网络算法构建肝硬化代偿期中医智能辨证模型的探讨
2023-10-10张明琪邓鑫
张明琪,邓鑫
(广西中医药大学,广西南宁 530001)
肝硬化是一种因感染性、毒性或药物诱导(主要是酒精诱导)、代谢性、胆汁淤积或自身免疫性损伤等各种因素所导致的弥漫性肝损害,其肝损害以肝脏弥漫性纤维化、假小叶形成、肝内外血管增殖为病理特征[1-2]。肝硬化常呈隐匿性起病,代偿期可无明显临床症状,随着疾病进展可发展为失代偿期,出现多种并发症,甚则癌变及死亡。因此,延缓代偿期肝硬化进入失代偿期、预防肝细胞癌变及减少并发症是肝硬化的治疗目标。病因治疗及抗炎抗肝纤维化治疗是现代医学治疗肝硬化代偿期最主要的方法。然而目前尚无抗纤维化的特效西药[2]。代偿期肝硬化可归属于中医“积聚”范畴[3]。中医药抗肝纤维化治疗有显著的疗效,且副作用较少[4]。“辨证论治”是中医学理论体系的主要特点之一,中医辨证的精准性决定了论治的有效性,但现行中医的辨证方法众多,证型分类不规范,易受个人主观因素的影响[5],中医辨证有待进一步客观化、标准化。
近年来,随着人工神经网络架构和算法的不断发展,以及计算能力的不断增强,人工智能技术在中医临床的疾病诊断、辅助治疗及经验传承等多方面取得了较大的发展[6-8]。其中,中医数字化辨证一直是人工智能在中医领域研究的热点课题[9]。统一规范的中医辨证模式是中医辨证智能化的基础,同时也是中医药现代化的重要内容之一[10]。目前机器学习领域有较多经典的算法,如决策树、支持向量机、K最近邻、随机梯度下降法、随机森林、极端梯度增强法等,这些算法基于不同的数学原理,具有各自的优缺点,均可运用于中医药领域的研究。本研究采用集成学习的方法研究肝硬化代偿期中医辨证模型,将这些算法输出的概率进行后融合,通过后融合的方法弥补各个模型的不足,发挥其长处,达到取长补短的目的,用BP 神经网络作为最终的元学习器,输出最终的预测概率,以期为中医辨证智能化和客观化提供借鉴,并为肝硬化代偿期的中医临床诊疗提供参考。
1 资料与方法
1.1 病历资料来源及筛选收集2016 年1 月至2022 年10 月期间在广西中医药大学附属瑞康医院就诊(包括门诊及住院)的肝硬化代偿期(首次就诊)的病历数据。收集的病历资料包含中医症状、体征、舌象、脉象等详细信息,不记录其他个人信息。对患者的性别、年龄、职业、病程、原发疾病、用药情况不做特殊限制。
纳入以下病历资料:①患者符合《肝硬化诊治指南》[2]中的肝硬化代偿期诊断标准;②患者以肝硬化代偿期为主要诊断;③患者无其他重大疾病。排除以下病历资料:①患者有严重心、肾等并发症,或合并有其他严重原发性疾病;②患者以其他疾病为主要诊断,而肝硬化代偿期为次要诊断;③患者为肝硬化失代偿期;④临床记录有缺陷而无法使用的病历记录。
1.2 证候分型标准参考《积聚(肝硬化代偿期)中医诊疗方案》[11],将本病的证候确定为5 个证型,即湿热瘀阻证、气滞瘀阻证、肝郁脾虚血结证、阴虚血阻证、气虚血瘀证。
1.3 数据录入与预处理获得上述病历样本的数据信息,将规范后的数据与证型(包括患者的症状和体征及所对应的证型)录入到Excel中,并以此作为原始数据库(录入格式:医案编号;证型;症状和体征)。
以患者的临床表现作为特征值,参考《肝硬化医生报告结局量表研制》[12]中的症状和体征,将获得的数据进行规范化。患者的临床特征(症状、体征、舌象和脉象)包括肝区疼痛、腹部疼痛、腹部胀满不适、情志抑郁、烦躁易怒、乳房胀痛或结块、疲倦乏力、视物模糊、嗳气、腰痛、头痛、咳嗽、咽部异物感、目干涩、头晕、难以入睡、口干、口苦、口臭、纳差、盗汗、五心烦热、恶心不适、肢体困重、牙龈出血、耳鸣耳聋、腰膝酸软、皮肤瘙痒、小便黄、尿频、呕吐、胸闷气喘、大便干结、小便少、遗精、月经量少、闭经、下肢水肿、蜘蛛痣、毛细血管扩张、肝掌、面色晦暗、面色黧黑、面色萎黄、唇色紫暗、黄染、消瘦、贫血貌、舌淡红、舌紫、舌淡紫、舌质暗、舌有瘀斑或瘀点、苔薄白、苔薄黄、舌苔白腻、舌苔黄腻、舌苔少、舌少津、舌边有齿痕、舌胖大、舌质红、舌下络脉显露、裂纹舌、脉弦、脉细、脉滑、脉无力、脉数、脉涩、脉沉等共72项。采用“0-1”编码对各临床特征进行赋值,即出现该特征计为“1”,未出现该特征计为“0”。然后以原始数据库中每个样本所对应的证型作为目标值,以此建立符合方案的数据集(PPS 数据集格式包括患者编号、目标值、特征值)。
1.4 数据集建立及实验开发环境与框架通过Scikit-learn 机器学习库中的标签编码(label encoding)对目标值下的中医证型进行处理,将文本信息映射为数值,将气虚血瘀证、气滞血瘀证、湿热瘀阻证、阴虚血阻证、肝郁脾虚血结证分别编码为0、1、2、3、4。利用Python 将数据集以8∶2随机划分为训练集和测试集,通过设置参数stratify=y使得训练集和测试集的各个证型数据的比例与原PPS数据集保持相同的比例,然后通过设置参数random state=0 保证每次实验都使用相同的训练集和测试集,并增加实验的可重现性。
本研究的开发环境为Anaconda 4.10.3,采用决策 树(decision tree,DT)、K最近邻(K-nearest neighbor,KNN)、支持向量机(support vector machine,SVM)、随机梯度下降法(stochastic gradient descent,SGD)、随机森林(random forest,RF)、极端梯度增强(extreme gradient boosting,XGBoost)等算法。算法采用的框架为Scikit-learn(0.24.2)。Scikitlearn 是Python 第三方提供的机器学习框架,支持分类、聚类、降维、回归四大算法以及特征提取、数据处理、模型评估三大模块[13]。BP 神经网络采用的框架为PyTorch(1.12.0+cpu)。PyTorch 是以Python 优先的深度学习框架,它仅支持自动求导功能,而且设计简洁,较其他深度学习框架具有灵活性强、运行速度快等优点[14]。模型解释采用的框架为SHAP(0.40.0),使用SHAP 值解释机器学习模型和特征的重要性[15]。
1.5 模型构建方法
1.5.1 初级学习器之传统机器学习算法 不同的机器学习模型是基于不同的数学算法原理,究竟何种机器学习模型更具优势还不明确,因此选择多个机器学习模型共同参与肝硬化代偿期诊断模型的构建,有助于模型之间的优势互补,弥补其不足,提高最终模型的性能表现。研究过程中可融合多种传统机器学习算法构建模型,以提高模型准确度。本研究所涉及的主要算法有6种,即决策树(DT)、K最近邻(KNN)、支持向量机(SVM)、随机梯度下降法(SGD)、随机森林(RF)、极端梯度增强法(XGBoost)。各算法原理及优缺点如下:
DT 是一种被广泛应用于数据处理的分类器,主要根据数据特征属性值进行排序及分组。DT 由节点和分支组成,节点则由根节点、叶子节点和若干内部节点构成[16]。DT 决策的过程就是从顶端的根节点开始,通过测试待分类项中相应的特征属性进行节点分裂,直到到达叶子节点停止分裂,叶子节点的类别代表分类决策最终结果[17]。其优点是具有简单高效、便于理解、易于评测,也存在易于过拟合的固有缺陷。
KNN 分类器代表了一种简单通用的分类方法,其相对性能与距离度量或相似度量的选择密切相关。其核心工作原理是计算待分类样本与K个邻居样本的距离,寻找与待分类样本距离最近的K个样本,由这K个样本中数量最多的类别决定待分类样本的类别,使用少数服从多数的原则[18]。KNN分类器具有对数据分布要求较低、对噪声有一定容忍度的特点,是最懒惰的学习方法之一。
SVM 最早应用在二分类问题上,用于寻找能将二类样本分开且分类间隔最大的一个最优超平面[19]。其基本思想在于引用核函数将输入的非线性样本空间映射到高维特征空间,以构建线性函数判别。SVM 适用于回归分析和分类问题等领域,具有结构简单、适应性好、训练速度快和良好泛化能力等优势[20]。
RF 是基于决策树基础上的一种集成算法,随机性是其区别于决策树的重要属性。这种随机性体现在Bagging 技术上可实现对样本的重采样,有利于降低决策树模型之间的相关性、增加RF 的精度。RF 具有简单、计算量小、可以降低决策树容易过于拟合等诸多优势[21]。
SGD 是基于全梯度下降方法(GD)的一种优化形式。GD 每次迭代时需使用全部的训练集样本以更新模型参数,而SGD 每次更新训练则只需在训练集随机抽取一个样本计算梯度。相较而言,GD有较高的精度,但也存在计算量过大,耗时明显,且容易陷入局部极值点的问题;SGD 虽然计算量小,速度快,但精度稍逊GD[21]。
XGBoost 同样以DT 作为基学习器,通过弱分类器的多轮迭代计算以降低偏差、实现最优分类效果[22-23]。通常以分类回归树作为弱分类器,每次训练所得弱分类器需要经过加权求和,最终生成总的分类器。XGBoost 主要利用二阶泰勒损失函数进行运算,并用正则项得到最优解,能够充分利用多核CPU 并行计算的优势,实现更快的模型探索[24]。
1.5.2 集成学习后融合 融合是将相同数据的不同模型预测结果进行有机整合后以刻画结果的过程。一般情况下,融合分为前融合、后融合,后融合是结果层面的融合。stacking 概率后融合是经典的集合算法。本研究使用stacking 后端概率融合模式将训练好的机器学习分类器预测概率输出,再结合原始影像组学特征以及深度学习特征输入到BP 人工神经网络(backpropagation neural network)进行融合,其中,6 种传统机器学习模型作为初级学习器,而BP神经网络则属于元学习器。
元分类器之深度学习网络通过BP 人工神经网络算法实现,它由输入层、隐藏层和输出层三部分组成[25]。其工作原理如下:首先,向输入层神经元输入信号,再把信号一层层向前传递,直至输出层结果生成为止;接着对输出层进行误差计算,将得到的误差反向扩散到隐层神经元上;最后,基于隐层神经元误差调整连接权与阈值,直到满足停止条件,最终获得具有较好泛化能力的模型[25]。整个研究利用torch 模块完成,使用交叉熵损失函数(cross entropy loss)对特征进行分类;优化器选择Adam 优化器。分类结果设置为5,隐藏层设定为100。基于集成学习后融合神经网络算法构建肝硬化代偿期中医智能辨证模型的建模流程如图1所示。
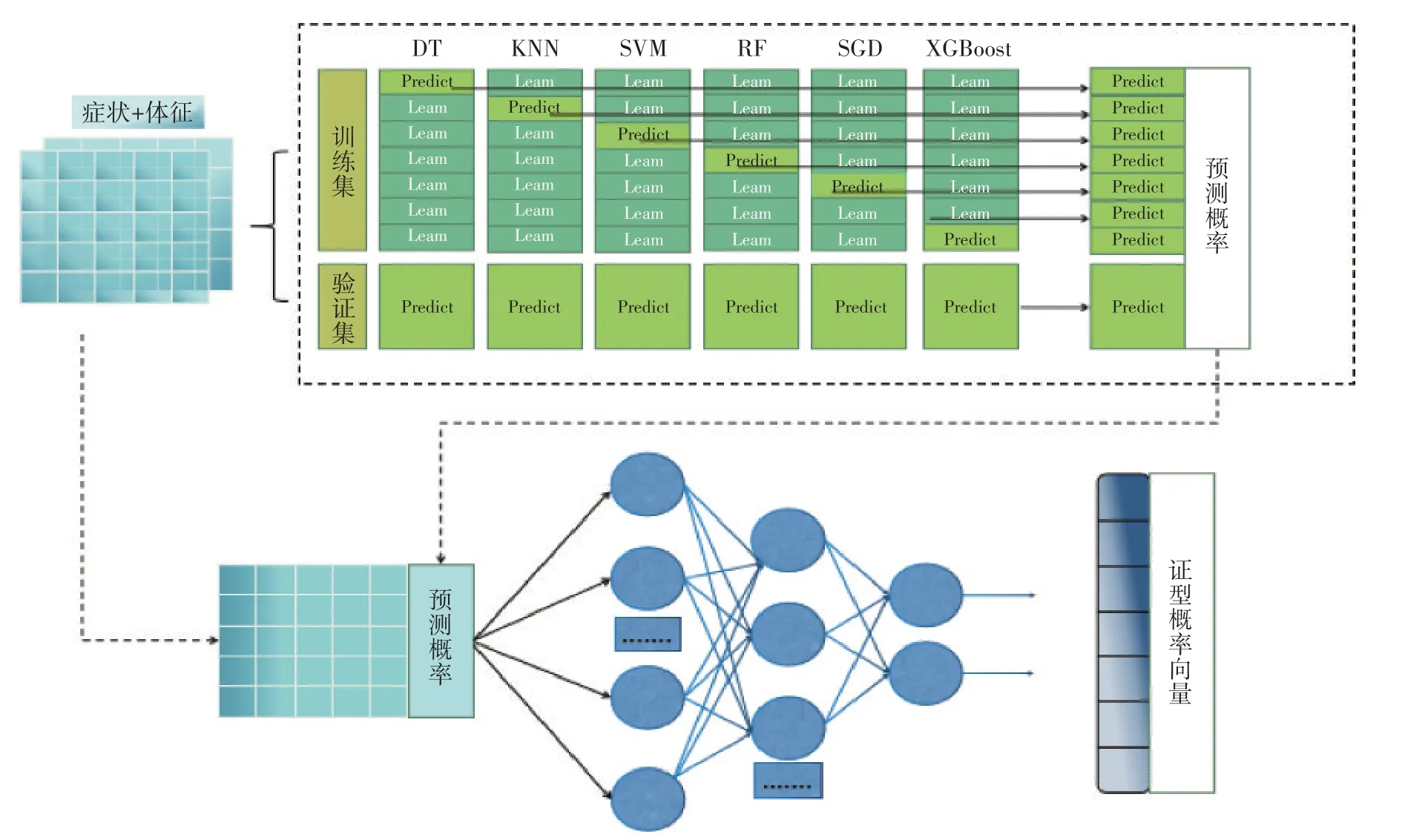
图1 基于集成学习后融合神经网络算法构建肝硬化代偿期中医智能辨证模型的建模流程图Figure 1 Modeling flow chart for the construction of TCM intelligent syndrome differentiation model of compensated liver cirrhosis based on integrated learning and late-fusion neural network algorithm
1.6 参数调优及模型评价决策树(DT)、K最近邻(KNN)、支持向量机(SVM)、随机梯度下降法(SGD)、随机森林(RF)、极端梯度增强法(XGBoost)采用GridSearchCV 模块通过参数列表param_grid 寻找最优模型的超参数组合,使用分层K(K=5)折交叉验证。人工神经网络在Optuna 框架下创建目标函数(objective),目标函数的评估指标设置为准确率(accuracy),进行100 次试验(epoches=100),并在试验完成后从study 项下选择最优的超参数组合。以上模型均使用准确率、精确率(precsion)、召回率(recall)、F1分数(F1 score)、混淆矩阵、受试者工作特征曲线(ROC 曲线)以及ROC 曲线下面积(AUC)值评估模型的性能。各模型最优超参数组合见表1。

表1 各模型的最优超参数组合Table 1 The optimal hyperparameter combination for various models
2 结果
初步搜集得到928例肝硬化代偿期患者的病历资料,经筛选后可供录入的病历资料(包含了中医症状、体征、舌象、脉象等证候详细信息)为912 份。912 例患者的原发病主要为病毒性肝炎、酒精性脂肪肝、非酒精性脂肪肝以及原发性胆汁性肝硬化等,其中气虚血瘀证108例,气滞瘀阻证95例,湿热瘀阻证168例,阴虚血阻证95例,肝郁脾虚血结证446 例。构建肝硬化代偿期中医智能辨证模型的病历数据处理流程如图2所示。
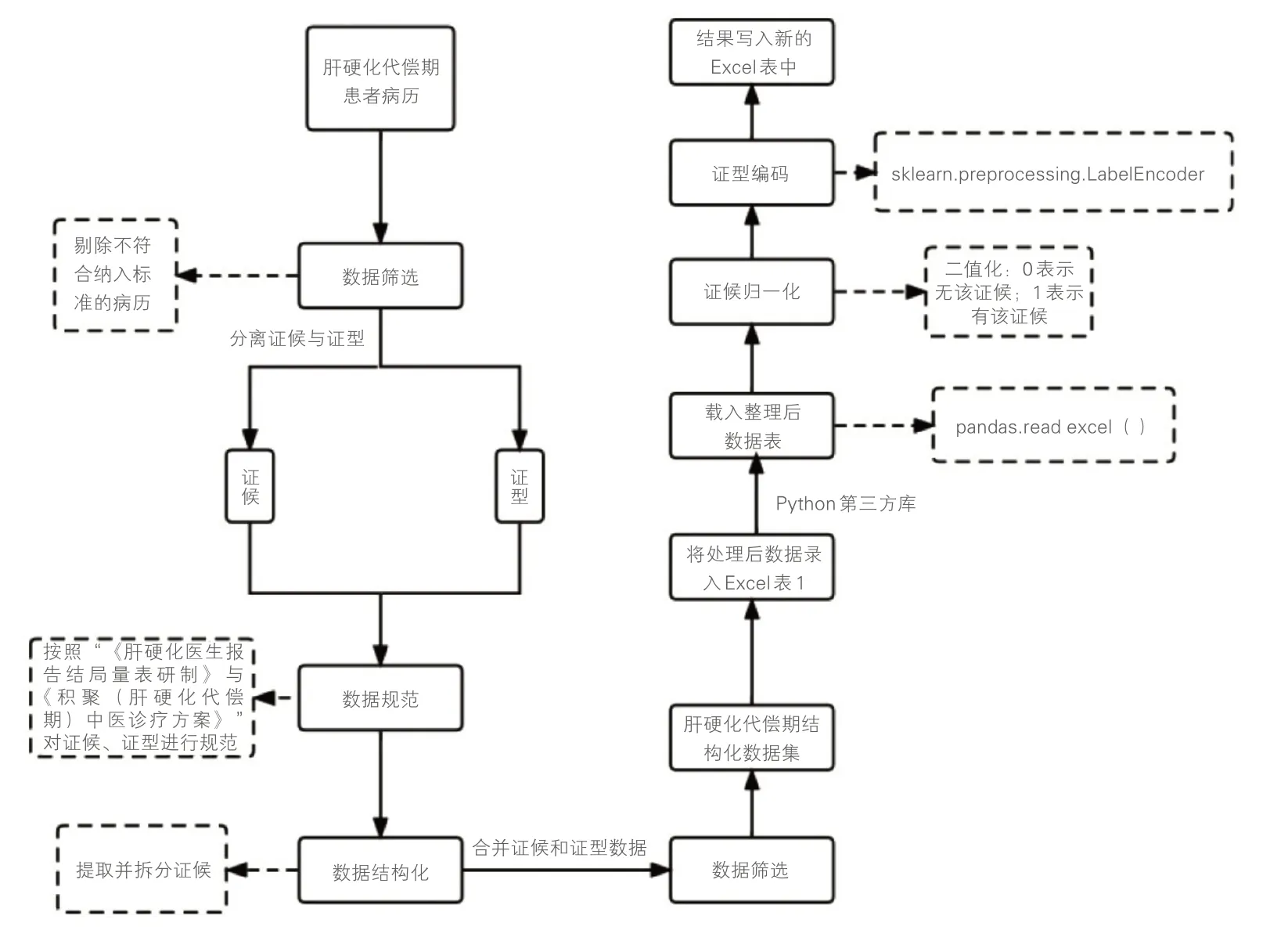
图2 构建肝硬化代偿期中医智能辨证模型的病历数据处理流程图Figure 2 Flow chart for the process of medical record data for constructing TCM intelligent syndrome differentiation model of compensated liver cirrhosis
2.1 模型评价结果将912 例患者的证型数据按8∶2划分为训练集(共730例,以上各证型的例数分别为83、78、135、77、357 例)和测试集,采用不同算法进行训练,其训练结果如下:
2.1.1 决策树模型 通过决策树建模后输出的肝硬化代偿期各证型的ROC 曲线和混淆矩阵如图3所示。决策树在各个证型的分类正确率都很高,对肝硬化代偿期证型预测较为理想。
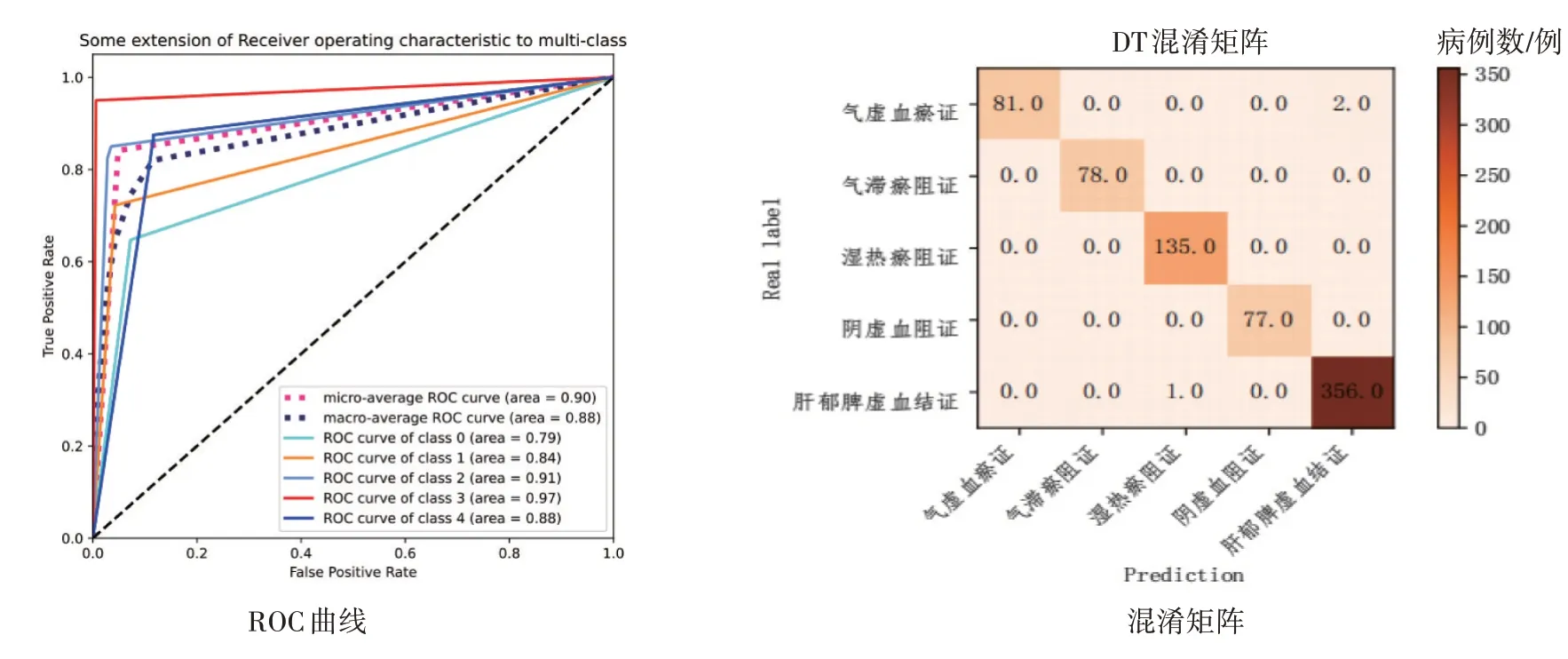
图3 肝硬化代偿期各证型的决策树(DT)模型的ROC曲线与混淆矩阵Figure 3 The ROC curve and confusion matrix of decision tree(DT)model for compensated liver cirrhosis of various syndrome types
2.1.2 支持向量机模型 通过支持向量机建模后输出的肝硬化代偿期各证型的ROC 曲线和混淆矩阵如图4 所示。支持向量机未能较好地区分气虚血瘀证和肝郁脾虚血结证,在83 例气虚血瘀证中,有40例被误分类为肝郁脾虚血结证。
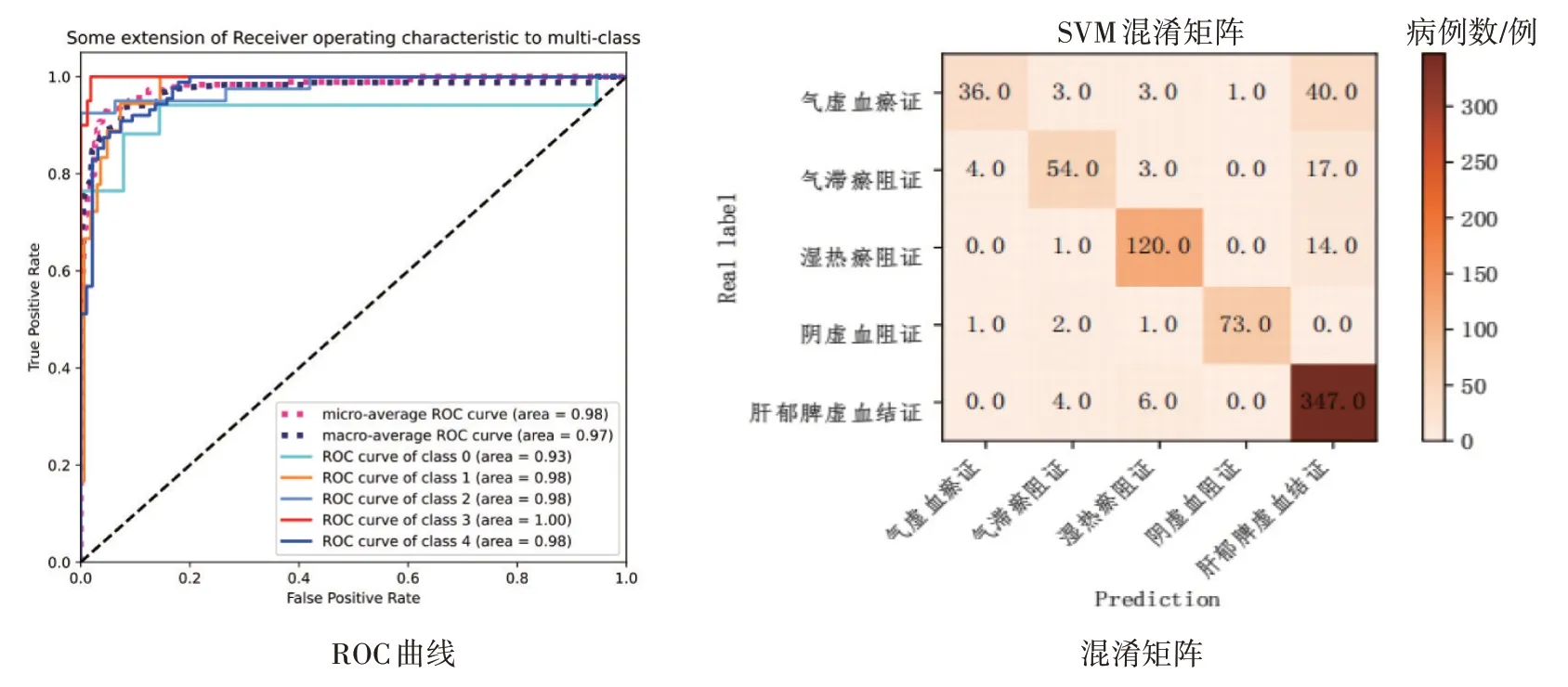
图4 肝硬化代偿期各证型的支持向量机(SVM)模型的ROC曲线与混淆矩阵Figure 4 The ROC curve and confusion matrix of support vector machine(SVM)model for compensated liver cirrhosis of various syndrome types
2.1.3K最近邻模型 通过K最近邻建模后输出的肝硬化代偿期各证型的ROC 曲线和混淆矩阵如图5 所示。K最近邻在预测气虚血瘀证的分类上的表现也不尽人意,83 例气虚血瘀证仅有54 例分类正确。
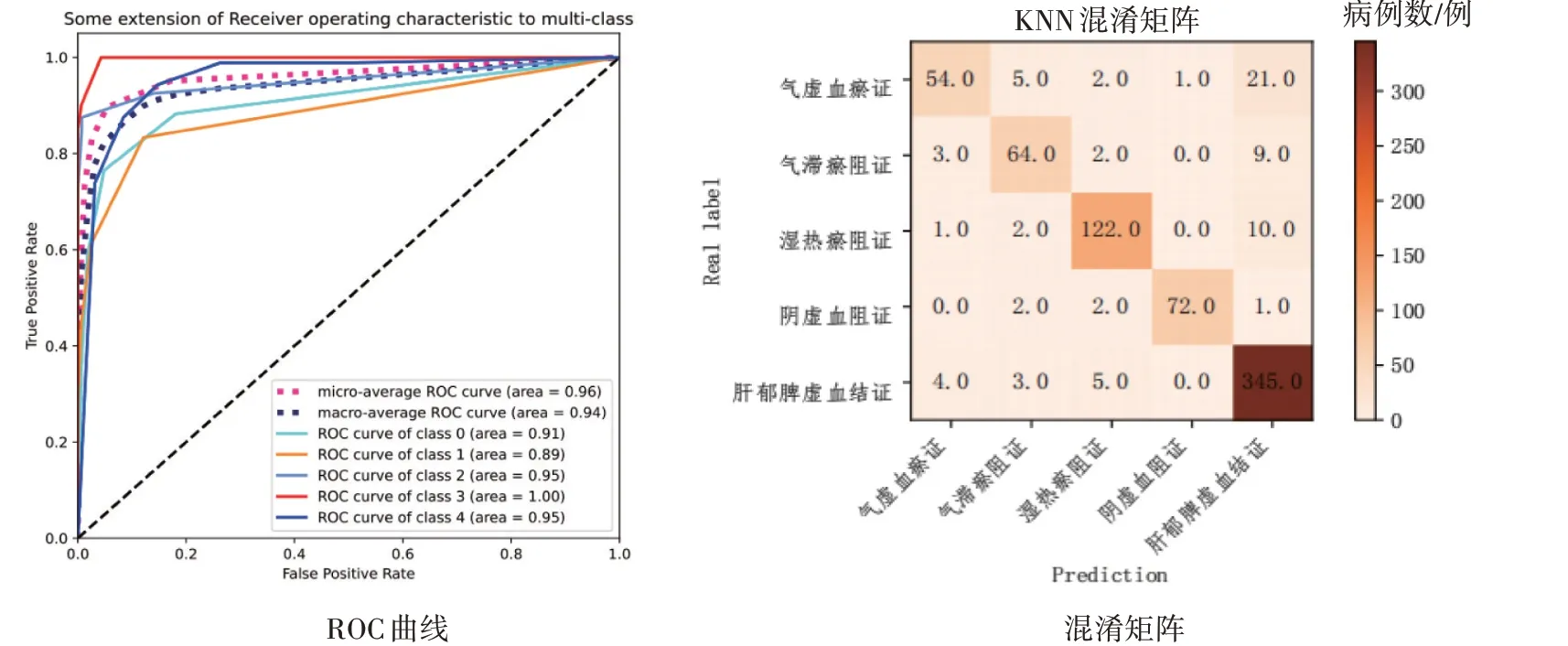
图5 肝硬化代偿期各证型的K最近邻(KNN)模型的ROC曲线与混淆矩阵Figure 5 The ROC curve and confusion matrix of K-nearest neighbor(KNN)model for compensated liver cirrhosis of various syndrome types
2.1.4 随机梯度下降法模型 通过随机梯度下降法建模后输出的肝硬化代偿期各证型的ROC 曲线和混淆矩阵如图6所示。随机梯度下降法预测阴虚血阻证的分类结果尚可,77 例阴虚血阻证中有76 例分类预测正确,但对其他证的预测能力则较弱。
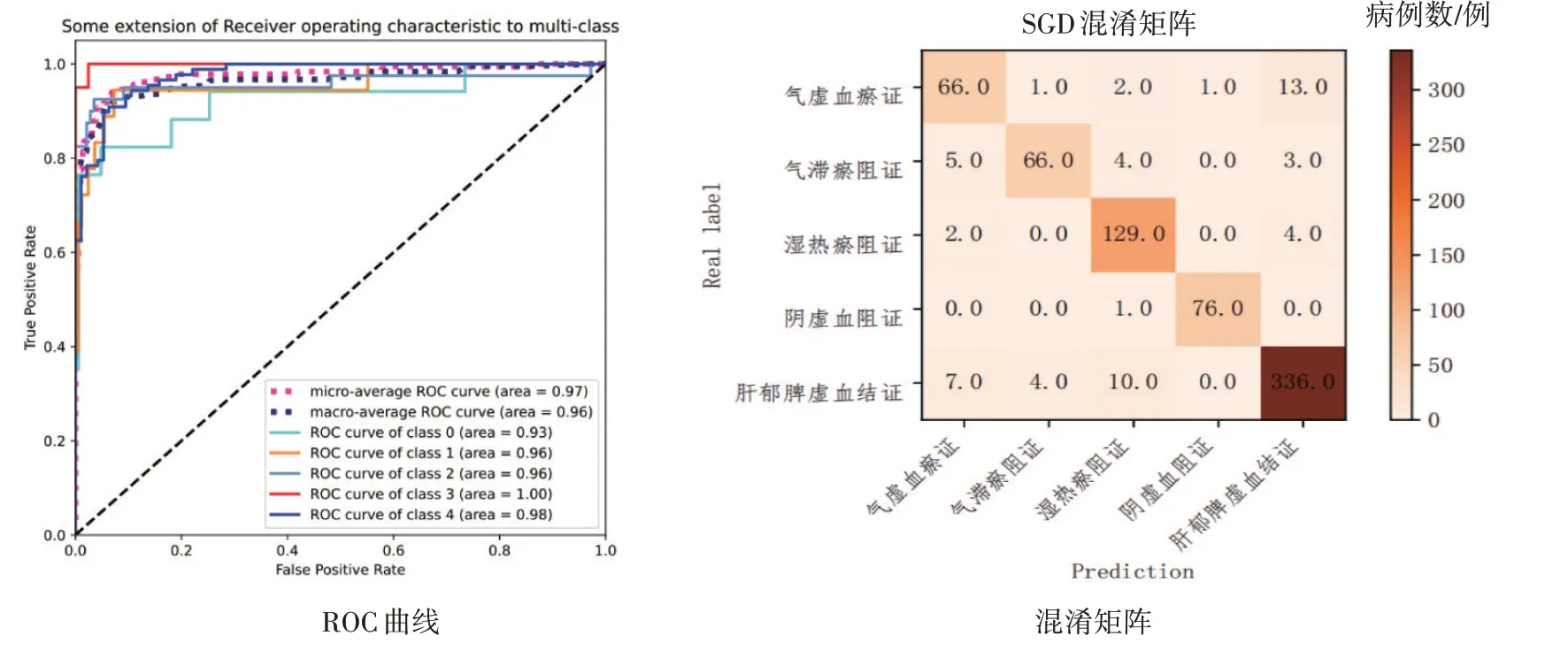
图6 肝硬化代偿期各证型的随机梯度下降法(SGD)模型的ROC曲线与混淆矩阵Figure 6 The ROC curve and confusion matrix of stochastic gradient descent(SGD)model for compensated liver cirrhosis of various syndrome types
2.1.5 随机森林模型 通过随机森林建模后输出的肝硬化代偿期各证型的ROC 曲线和混淆矩阵如图7所示。随机森林在阴虚血阻证的分类上表现最佳,在其余证型的预测上表现也尚可。
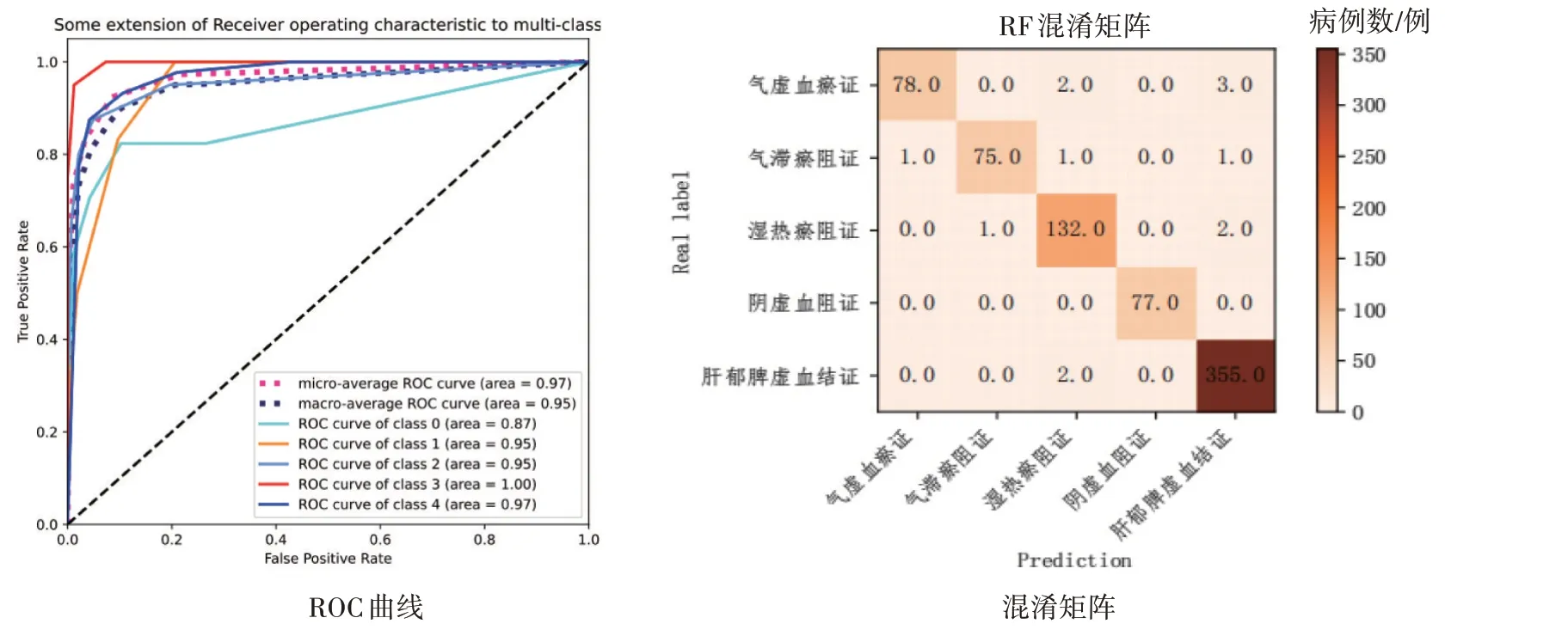
图7 肝硬化代偿期各证型的随机森林(RF)模型的ROC曲线与混淆矩阵Figure 7 The ROC curve and confusion matrix of random forest(RF)model for compensated liver cirrhosis of various syndrome types
2.1.6 极端梯度增强法模型 通过极端梯度增强法(XGBoost)建模后输出的肝硬化代偿期各证型的ROC 曲线和混淆矩阵如图8 所示。XGBoost 对阴虚血阻证的预测结果尚可,77 例阴虚血阻证中仅有2 例被预测错误,分别被误归类为湿热瘀阻证和肝郁脾虚血结证,但在其他证型的预测方面则表现一般。
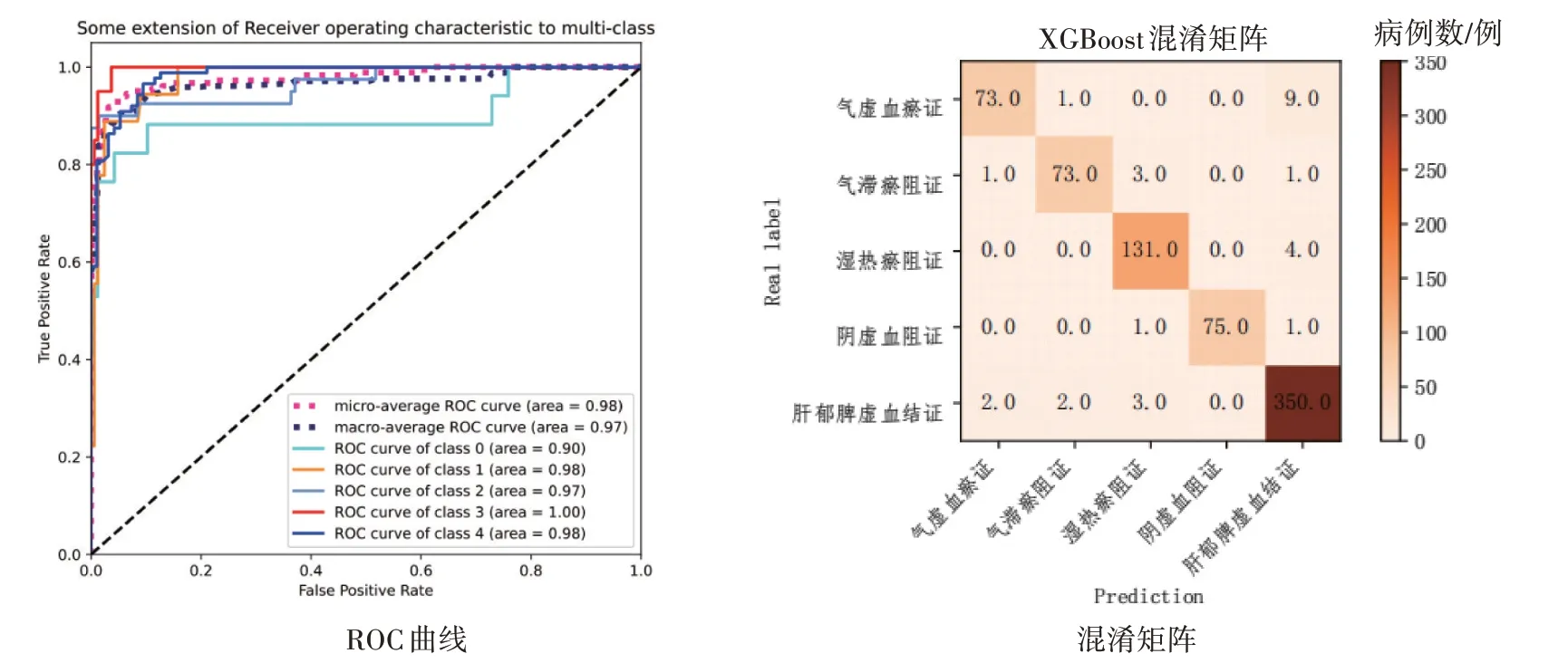
图8 肝硬化代偿期各证型的极端梯度增强法(XGBoost)模型的ROC曲线与混淆矩阵Figure 8 The ROC curve and confusion matrix of extreme gradient boosting(XGBoost)model for compensated liver cirrhosis of various syndrome types
2.1.7 BP 神经网络模型 通过BP 神经网络建模的准确率-损失(accuracy-loss)曲线见图9。x轴代表迭代周期(epoch),y轴代表准确率和损失。随着迭代次数增加,准确率逐渐上升,损失逐渐下降。迭代周期为65 的曲线趋平缓,达到收敛。BP神经网络输出的肝硬化代偿期各证型的ROC 曲线和混淆矩阵见图10。
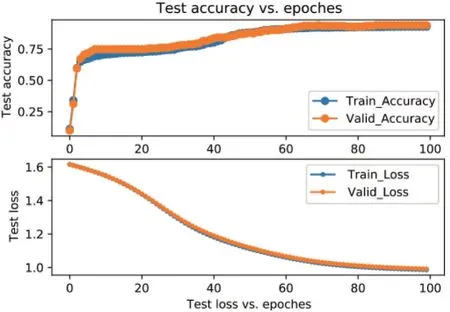
图9 BP神经网络训练过程的准确率-损失(accuracyloss)曲线Figure 9 The accuracy-loss curve of backpropagation neural network training process
图10 肝硬化代偿期各证型的BP神经网络模型的ROC曲线与混淆矩阵Figure 10 The ROC curve and confusion matrix of backpropagation neural network model for compensated liver cirrhosis of various syndrome types
2.2 各类模型的性能比较在相同测试集下各分类模型的准确率(accuracy)、精确率(precsion)、召回率(recall)、F1 分数以及AUC 值如表1 所示。F1值是对精确率与召回率的调和平均,优点在于能赋予精确率和召回率相同的权重以平衡两者,F1值越高,说明精确率和召回率都较高,算法的性能越好。从表2 可知,F1 值最高为BP 神经网络模型,最低为支持向量机。
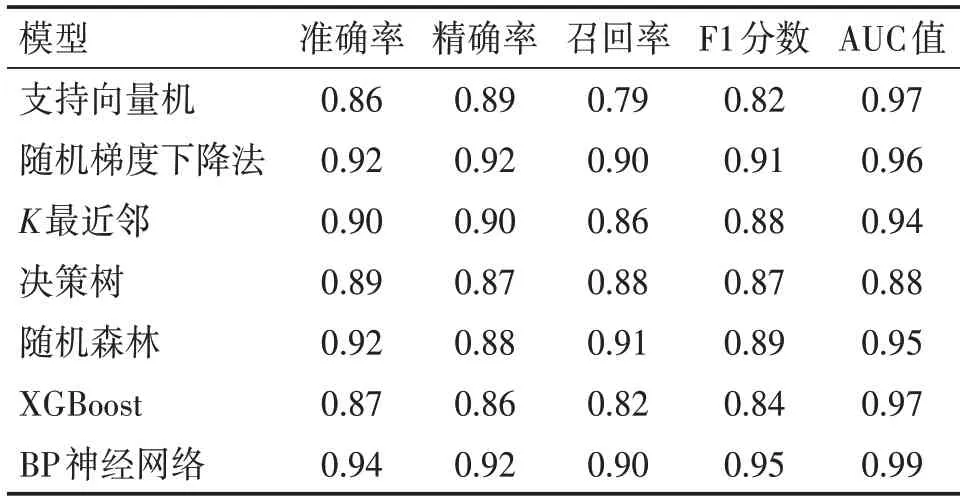
表2 构建肝硬化代偿期中医智能辨证模型的各算法模型的性能指标比较Table 2 Comparison of the performace indicators of various models using for constructing TCM intelligent syndrome differentiation model of compensated liver cirrhosis
2.3 模型解释医学领域中,模型可解释性的重要性与模型的性能同样重要,这些具有高准确度预测结果的模型要让人们(尤其是专业医生)信服,就必须更进一步提供模型做出预测的依据[26]。SHAP(Shapley additive explanations)值是Lundberg S M等在2017年提出的一种基于博弈论的模型解释方法[27],该方法量化了模型中每个特征对观察结果最终预测的贡献,采用基于所有可能的特征子集组合(包括给定特征)预测模型[28]。本研究按照证型分类求得每个样本特征对应的SHAP值,并采用SHAP 值的平均值作为该特征的重要性值,从而得到全局解释,以此来阐明模型中贡献度较大的特征。通过模型性能指标的比较可知,BP 神经网络模型和随机梯度下降法的各项评估指标均超过0.90,但BP 神经网络模型的维度太高,无法使用SHAP 进行研究。因此本研究在随机梯度下降法的基础上,调用SHAP 库的Explainer API 降序输出肝硬化代偿期各证型的PPS 数据集的特征重要性(排前20位),结果见图11。
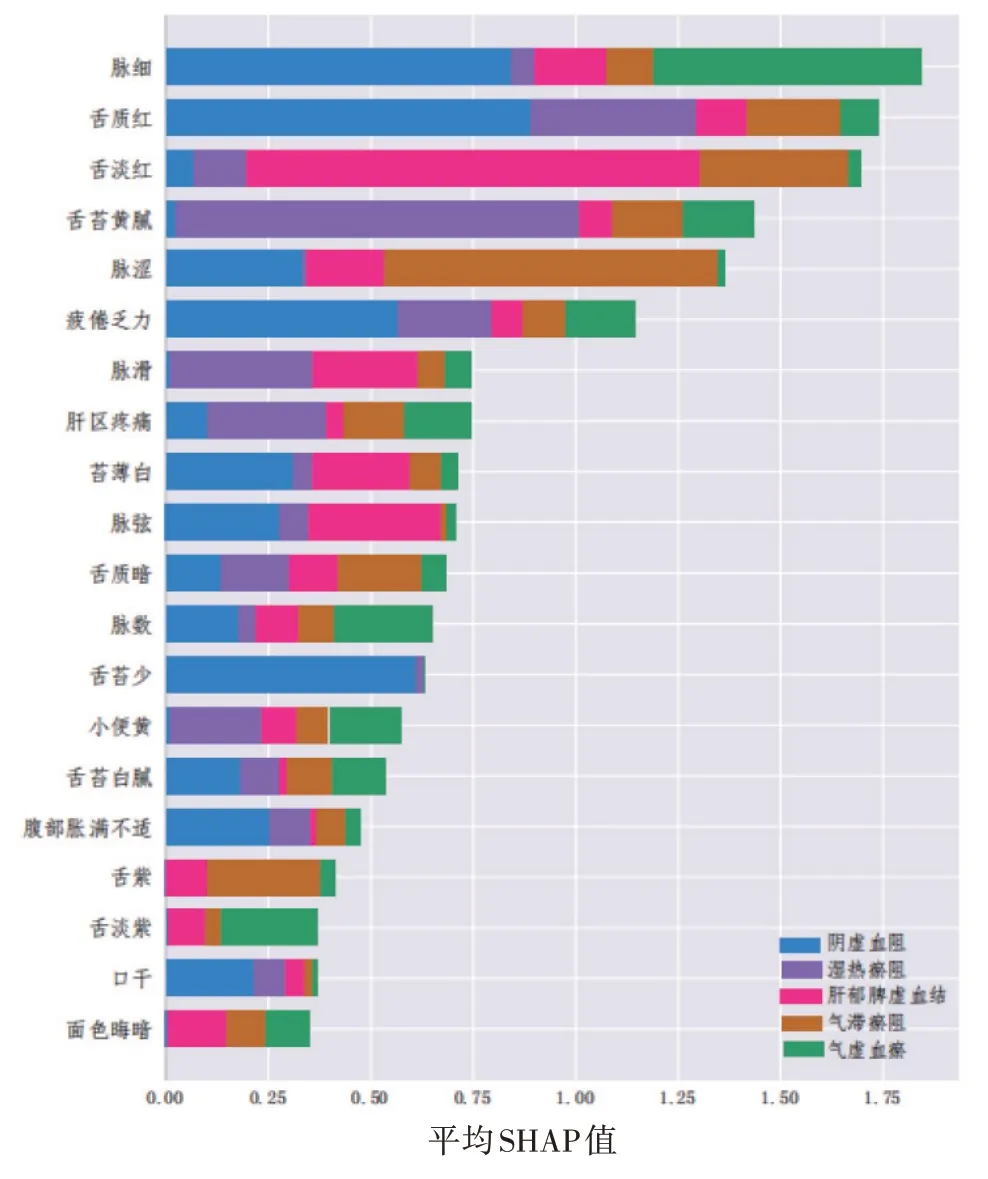
图11 肝硬化代偿期各证型中特征贡献度排前20位的符合方案数据集(PPS)Figure 11 The per protocol set(PPS)with the leading 20 feature contribution degree for compensated liver cirrhosis of various syndrome types
由图11 中可知,对于阴虚血阻证而言,疲倦乏力、舌质红、舌苔少、脉细等特征有着较高的贡献度;舌苔黄腻、舌质红、脉滑等特征对湿热瘀阻证有着较高的贡献度;舌淡红、苔薄白、脉弦等特征对肝郁脾虚血结证有着较高的贡献度;脉涩、舌紫、舌质暗等特征对气滞瘀阻证有着较高的贡献度;脉细、疲倦乏力、舌淡紫等特征对气虚血瘀证有着较高的贡献度。
3 讨论
目前,阻碍中医药客观化与规范化的主要原因是中医语言的模糊性、理论知识的难理解性、治疗思维的抽象性以及中医医案的繁杂性。机器学习能将中医药内部复杂的联系转化为不同变量在隐层空间的数学关系,将中医模糊用词进行规范,降低主观性,提高客观性,有益于中医药理论体系的理解,可为中医药理论的传承与创新以及中医循证医学的发展做出贡献。
本研究基于决策树、支持向量机、K最近邻、随机梯度下降法、随机森林、XGBoost 等机器学习算法和集成学习后融合的算法,通过病历数据对肝硬化代偿期的中医智能辨证进行了深入分析和探索。实验结果表明,在模型性能评估指标中,BP 神经网络模型的召回率为0.90,略低于随机森林的0.91,但BP 神经网络模型其他各项评估指标均大于0.90 并优于其他分类器模型。可见,与机器学习相比,BP 神经网络对肝硬化代偿期中医证型预测具有更好的准确性、精确性,其各项指标具有更好的均衡性。
本研究使用了集成学习后融合的方法,该方法类似于医院的临床科室会诊制度,各个科室的住院医师(机器学习模型)对同一份病例(搜集的数据资料)提出各自的意见(机器模型预测结果),将这些意见提交给副主任医师(BP 神经网络)后,副主任医师综合这些意见得出最准确、最综合、最全面的结果(BP 神经网络预测结果)。BP 神经网络具有良好的容错性、自组织适应性和学习能力,在疾病诊断、预后判断等方面有着广泛的应用[29]。刘丽蓉等[30]通过BP 神经网络构建荨麻疹证候预测模型,其预测的准确率为83.13%,表明利用BP 神经网络进行荨麻疹证候分类取得较好的结果。刘秀峰等[31]将遗传算法降维优化后的BP 神经网络(GABP)诊断模型用于大肠癌虚实证型的分类研究,并与传统的未经优化的BP 诊断模型进行比较,结果发现优化后的神经网络模型建模所需时间明显减少,证型正判率都较前显著提高,表明基于GABP 的神经网络泛化能力更好,分类效果更佳。辛基梁等[32]比较了机器学习和BP-MLL 神经网络构建的中医健康状态辨识的分类预测模型的平均精度,结果显示BP-MLL神经网络预测模型的平均精度最高,性能最优。综上可见,以往的研究多使用单一的模型进行中医疾病证型的预测,然而单个模型的泛化能力单薄,在解决所研究的问题上能力较出色,但在解决其他问题时结果却不尽人意。本文所研究的集成学习后融合BP 神经网络的方法可以提高模型对未知问题的泛化能力,避免算法失误,通过结合多个模型的优点,实现优势互补,提升模型的预测精度。
本研究所搭建的集成学习后融合的神经网络肝硬化代偿期中医辨证模型,将多个机器学习模型的预测结果进行相互补充结合,保证了各模型的多样性,克服了不同模型的劣势,具有性能全面、指标均衡、预测结果客观可靠等优势。集成学习后融合的神经网络肝硬化代偿期中医辨证模型所输出的肝硬化代偿期各证型的PPS数据集,可提高临床医生对肝硬化代偿期中医辨证的速度和准确率,提高对患者的诊疗质量。
