基于链路质量与节点负载估计的Q学习UANET路由协议
2023-10-10王柄焱郑向平贾文杰李大鹏
王柄焱,郑向平,贾文杰,李大鹏
(1.南京邮电大学通信与信息工程学院,江苏 南京 210003;2.江苏永丰机械有限责任公司,江苏 南京 210094;3.重庆理工大学计算机科学与工程学院,重庆 400054)
0 引言
移动自组网(Mobile Ad Hoc Networks,MANET)是一种自组织、无中心、多跳传输的无线网络,与传统中心控制的无线网络相比,移动自组网不依赖任何中央基础设施,可以实现低成本,快速的网络部署,同时也便于扩展和维护,近年来得到了广泛的应用[1-2]。无人机自组网(Unmanned Aerial Vehicles Ad Hoc Networks,UANET)是MANET 在无人机领域的扩展应用,有动态性高、链路长、资源有限、数据交互频繁的特点,这给执行任务带来了多样性与灵活性,但也给路由协议的设计带来了很大的挑战[3-5]。
目前,OLSR(Optimized Link State Routing)协议是应用比较广泛的主动式路由协议[6],相比于以AODV(Ad hoc On-Demand Distance Vector Routing)为代表的被动式路由协议,OLSR 协议中的节点会周期性地交互路由测度信息,更新路由表,当要发送业务时,可以直接查询已经建立的路由,而被动式路由协议采用的是一种有业务发送时才开启路由建立的执行方式,所以,在对实时性要求较高的无人机网络场景中,OLSR 协议更有优势[7]。
OLSR 协议中的节点通过广播Hello 分组来完成链路探测与邻居发现,通过广播拓扑控制(TC,Topology Control)分组来共享网络拓扑信息,同时通过多点中继技术(MPR,Multi-Point Relay),在一定程度上减少了路由维护开销[8-10]。但传统的OLSR 协议仅使用跳数作为路由的决策准则,选择的标准过于单一,难以适应真实的UANET 场景。
针对网络拓扑变化频繁的场景,王旭东等人[11]提出了一种基于位置信息的速度加权SW-OLSR 协议,通过预估计算一个ETX 值来度量无线链路的链路质量,进而辅助路由决策。周长家等人[12]针对UANET 的动态性和能量受限的特点提出了一种适用于UANET 的UAV-OLSR协议,通过感知在发送Hello 消息间隔内的邻居变动状况以及发送TC 消息间隔内的拓扑变动状况动态调整两种控制信息的发送周期,同时通过评估节点能量优化了MPR机制;姚玉坤等人[13]提出在选取MPR 节点集时,加入链路稳定性和链路存在时间这两个链路状态指标,使得选取的MPR 节点集更稳定、合理,同时结合Q-learning算法实现了对TC 消息发送间隔的动态调整,在一定程度上降低了路由控制开销。实际上,上述改进协议都针对运动拓扑对OLSR 协议进行了优化,但缺少对节点负载的考量。王靖等人[14]采用跨层协议设计理论,通过对节点负载、链路投递率和链路可用性等信息进行感知,并以此为依据来推理链路质量,进一步优化了路由选择,保证了网络的负载均衡,有效地提高了协议的可靠性。但该协议引入了较大的控制开销,难以适用于节点能量有限的UANET。
针对OLSR 协议路由选择指标单一的问题,本文提出了在无人机自组网场景中,基于链路质量与节点负载估计的Q 学习OLSR 协议(UQL-OLSR,Q-learning OLSR Based on Link Quality and Node Load Estimation for UANET),主要内容包括:1)针对高动态和高吞吐两种网络场景,分别定义了链路质量和节点负载两个参数,并提供了相应的估计方法;2)基于Q 学习算法,结合OLSR 协议控制信息的交互过程,设计了基于跳数、链路质量、节点负载三方面的奖励函数,并提供了路由建立过程中Q 值表与路由表的更新方法,用于指导在多因素影响下的路由决策。该协议已在某网络仿真环境中实现,实验结果表明,优化后的协议更加适用于高动态、高负载环境下的无人机自组网。
1 系统模型与问题分析
1.1 系统模型
本文使用Q 学习算法对OLSR 协议在UANET 场景下的路由选择与路由建立过程建立模型。Q 学习是一种基于值函数的无模型强化学习(Reinforcement Learning,RL)算法[15],它能够将学习任务分散到每一个网络节点中,通过周期性的与邻居交互控制信息来动态更新路由表,这意味着网络中的节点可以根据它们的互动经验不断改善路由决策,以提高网络性能和可靠性。这种方法有助于优化数据传输,使网络更有效地工作。
图1 为Q 学习的基本模型,以马尔可夫决策过程(Markov Decision Process,MDP)为理论基础。在MDP 中,智能体(Agent)处于一个由状态(State)、动作(Action)和奖励(Reward)组成的环境中,假设在t时刻智能体的状态为St,在收到基于上一次动作环境反馈的奖励值Rt之后,经过决策执行最优动作At并进入状态St+1,智能体循环执行以上操作,经过了动作带来奖励后又反过来影响动作决策的过程,以达到在特定的环境中选择最优决策的问题[16]。
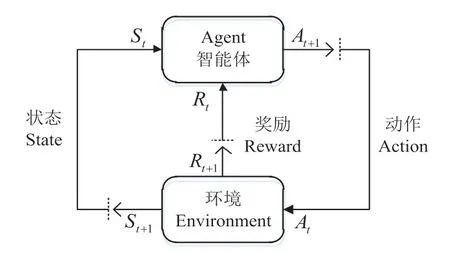
图1 Q学习的基本模型
Q 学习算法通过Q 值来评估状态行动的价值,其中Q 值的更新规则如下:
式中Q(st,at) 是状态-动作对(s,a) 的值函数,表示在状态s下采取动作a所能获得的奖励期望,α∈(0,1)为学习率,用于控制学习的速度,γ∈(0,1)为折扣因子,用于控制长期奖励的重要性。
为了让网络中的节点能够自主学习,及时感知拓扑结构与节点状态,将Q 学习算法与OLSR 协议结合,定义智能体Agent 为网络中的节点,学习环境为整个UANET。
定义三元组(A,S,R)如下:
1)动作(A):节点通过感知邻居与拓扑变化,新增或更新本地路由表项,从一跳邻居集N={N1,N2,…,Nn}中选取一个节点作为相应目的的下一跳。
2)状态(S):节点的本地路由信息及状态统计信息,包括跳数hop、节点地理位置 (x,y)、数据接收速率R等,反应节点当前的情况,用于指导路由决策。
3)奖励(R):整个网络对节点的即时反馈值,可以根据网络性能的需求,将跳数、时延、负载、能耗等指标映射到奖励R中,使节点能够适应动态的网络环境。
在路由建立过程中,网络中的每个节点都维护一张Q 值表,表中的列表示经过本节点的目的节点ID,行表示本节点的一跳邻居节点ID,用来记录当前节点在指定目的节点的情况下,选择某个邻居节点作为下一跳可以得到的累积奖励期望值,节点会选择Q 值最大的邻居作为下一跳节点。Q 值表的具体格式如表1 所示。

表1 节点维护的Q值表格式
基于该路由策略,参考公式(1),以D作为目的节点,源节点S将邻居节点N作为下一跳的质量评估值,即对应Q 值的更新公式变为:
其中α为学习率,γ为折扣因子,Ns为源节点S 的一跳邻居集。
Q 学习作为一种无模型算法,其复杂度可以表示为O(SAH),其中S表示状态空间的大小,A表示动作空间的大小,H表示每一次执行所走的步长[17]。S的大小受到网络规模的影响,节点越多,需要统计的状态参量相应增加;A的大小则与网络节点的一跳邻居集大小相关,具体的,节点可供选择的下一跳节点数量越多,动作空间越大;同时,由于每次执行动作只会新增或更新一行路由表项,因此步长H可视为1。综上,通过Q 学习实现路由建立的复杂度受到网络规模与节点密集程度的影响,设置合理的节点总数与拓扑结构可以显著降低算法的复杂度。
1.2 问题分析
传统的OLSR 协议仅基于跳数,使用Dijkstra 算法计算路径,生成路由。选择路由的标准过于单一,难以适应网络拓扑的快速变化,会导致链路易断裂,路由更新不及时等问题[18],同时,在业务量较大的场景中,MPR 节点的负载加重,业务发生拥塞的可能性增加,进而也会降低网络的性能[19],因此:
1)考虑到无人机节点的移动性:在制定路由转发策略时,选择质量更高,稳定性更好的下一跳节点,能够延长路径生存时间,减少链路断裂,提高路由质量和数据传输的可靠性。
2)考虑到高负载情况下的数据拥塞问题:在路由选择时,选择负载较小,空闲度较大的转发节点可以减少这种问题的发生,降低网络的时延[20]。
综合考虑以上2 个问题,同时也保留对跳数的考量,定义跳数因子HF、链路质量因子QF和节点空闲度因子LF,共同构成Q 学习中对节点的即时奖励R(奖励函数的设计见2.1 节),用于指导节点在多因素影响下的路由决策。
2 基于链路质量与节点负载估计的Q学习路由协议
2.1 奖励函数设计
(1)最小跳数
在OLSR 协议中,采用Dijkstra 算法计算路由最小跳数,以节点i为例,每个节点获取其到达其他节点的最小跳数的核心步骤如下:
①节点通过交互Hello 分组和TC 分组分别维护一个邻居表和一个拓扑表;
②根据拓扑表中的表项初始化节点i中的一个二维数组min_h,其中min_h[i][j]表示节点i到节点j的最小跳数;
③节点i找到未访问节点中离本节点最近(跳数最小)的节点ni,判断节点ni是否可以使得节点i到其他所有节点的跳数变小,若满足,更新min_h;
④节点i根据二维数组min_h记录到其他节点的最小跳数hopmin;
⑤重复③④直到网络中的每个节点都获取到达其他节点的最小跳数。
定义跳数因子HF 如下:
其中hopmin为通过Dijkstra 算法计算的路由最小跳数,hopmax为路由最大跳数,默认为16。
(2)链路质量
定义链路质量因子QF来估计两节点之间的链路质量。
定义t时刻,节点i和节点j之间的直线距离为:
其中节点i的地理位置为,节点j的地理位置为。
在时间间隔T内,两个节点的相对移动距离如下:
定义节点i相对于节点j的质量因子为:
其中,Rd为无人机节点的最大通信距离,单位时间内两节点相对移动距离越小,则认为两节点间的链路质量越好。
为了避免在节点剧烈运动的场景下,节点相对移动距离Δd变化过大,进而导致质量因子QF剧烈变动的情况,使用指数移动平均(EMA)对链路质量因子做平滑处理:
其中,β∈(0,1),为平滑因子,表示当前数据点的权重,经过仿真测试,本文β取0.75。
(3)节点负载
借用文献[20] 中使用网络节点内数据包的排队时延来评估节点负载的思路,采用M/M/1 排队模型对网络层队列进行建模,网络层队列中数据包数量的期望值为:
其中,pi表示队列中数据包个数为i的概率,λ表示节点接收数据包的速率,μ表示节点处理数据包的速率。
进一步,数据包的平均排队时延为:
这样在每个节点处理数据包的速率μ一定的情况下,节点接收数据包的速率越大,则数据包的排队时延越长,此节点的负载越高。因此,可以使用节点接收速率λ来衡量网络节点的负载量。定义网络中某节点相对于其邻居节点i的空闲度因子估计值如下:
其中Ri为邻居节点i的瞬时接收速率,Rmax为该节点所有邻居接收速率的最大值。
(4)奖励函数
根据前文对节点跳数因子、质量因子、空闲度因子的定义可知,HF∈[0,1],QF∈[0,1],LF∈[0,1],定义当前节点c从节点i获取的瞬时奖励R(c,i)为:
其中:ωH,ωQ和ωL分别为路径跳数、链路质量、节点空闲度的权重因子,满足ωH+ωQ+ωL=1。
2.2 路由方案设计
(1)路由建立过程
在路由建立的过程中,每个节点都会周期性广播Hello 分组用于探测邻居节点,为了判断应该转发来自哪些节点的广播消息,节点会在本地维护一张MPR_S(MPR Selector)集合。节点将MPR_S 集合中的信息加入TC分组后,向全网洪泛TC 分组用于交互网络的拓扑信息,由MPR 节点进行处理和转发,参考1.1 节中对Q 表的定义,网络中的节点通过交互Hello 和TC 分组维护一张Q值表,更新路由时,选择Q 值最大的邻居节点作为下一跳节点,无人机节点维护Q 表的示意图如图2 所示:
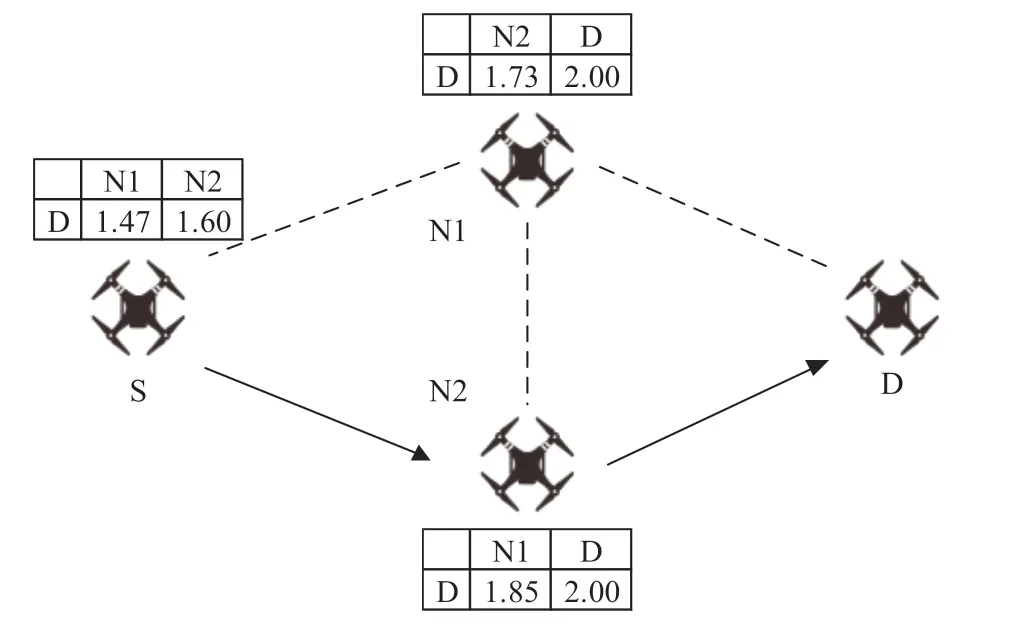
图2 无人机节点维护Q表示意图
为了计算本节点到对应目的节点的Q 值,节点首先会收集并计算本地路由与状态测度信息,再将这些信息添加到Hello 分组中,并定期地将这些数据共享给邻居节点,MPR 节点接收到邻居的测度信息后,会将这些信息添加到TC 分组中,向全网广播。在开始阶段,每个节点Q 表的初始值都设为0,当节点接收到邻居节点发送来的TC 分组后,将在本地维护一个拓扑表,提取其中记录的目的地址Dt、TC 分组中的上一跳地址Pt、节点地理位置、接收速率等相关信息,按照公式(11) 计算奖励值R,然后将Dt作为Q 值参数的目的节点Di,Pt作为邻居节点Ni,按公式(2) 更新本地Q 值表。经过这一过程,就更新了当前节点以MPR_S 集合中的节点为目的,上一跳节点为邻居的Q 值。更新完成后,如果当前节点是MPR 节点,则将上一跳地址设为自己,再以单跳广播的方式向全网转发该TC 分组。同理,收到其他邻居节点发来的TC 分组也如此处理,经过一段时间的算法收敛,以全网中其他节点为目的的Q 值都得到更新。
UQL-OLSR 协议的路由建立流程如图3 所示。

图3 UQL-OLSR协议路由建立流程
(2)路由维护过程
在路由建立的过程中,为了应对高动态场景中节点入网,退网的场景,制定了Q 值表中节点的有效时间,在这个有效时间内,如果某个节点的Q 值没有被更新,系统会将该目的节点视为下线,并清除相应行的数据。同时,需要根据网络规模设置TC 报文的生存时间(TTL),在确保全网能够感知拓扑信息的情况下,减少控制信息的冗余。
由于Q 学习算法需要需要一定时间才能收敛,在当前节点到所有其他节点的Q 值都收敛时,更新后的路由才能逐渐趋近最佳。然而,在更新路由表时,Q 值可能与稳态值存在较大偏差。为了尽快达到Q 值收敛,特别是在动态性较高的网络中,需要适度降低Hello 报文和TC报文的发送间隔,以促进Q 值的快速更新。同时为了减少控制信息在网络中的竞争和碰撞,实验过程中设定控制信息的发送时延为γT,其中γ为[0,1] 之间的随机数,T为控制报文的发送间隔,每个节点错开控制信息的发送时间,确保网络中的消息传输更均匀,保证在路由建立过程中控制信息的接收速率和占用的带宽基本保持恒定。
3 仿真与分析
本文使用某网络仿真平台对UQL-OLSR 协议进行仿真验证,将其与集成的标准版OLSR 协议以及文献[11]中的基于位置信息的速度加权OLSR 协议(SW-OLSR)进行对比分析,并分别设计了如下仿真实验:
1)预估UQL-OLSR 协议的路由建立时间,通过获得业务源节点本地Q 表中最大Q 值的收敛时间来估计;
2)验证节点吞吐量一致的情况下,网络拓扑变化频繁程度对时延和分组投递率的影响;
3)验证网络拓扑变化程度一致的情况下,节点吞吐量的变化对时延和分组投递率的影响。
实验中设置最小跳数、链路稳定性和节点空闲度的权重因子分别为0.3、0.4 和0.3,场景规模为2 km×2 km;节点的移动方式采用随机移动(Random WayPoint),整体实验仿真参数如表2 所示:

表2 仿真参数配置
3.1 路由建立时间分析
在2.2 节中提到,只有当节点的Q 值都达到收敛状态时,更新后的路由才会逐渐接近最佳路由,所以为了评估UQLOLSR 协议的性能,需要保证在传输业务数据时,节点维护的Q 值都达到收敛状态。在路由选择时,节点选择Q 值最大的邻居作为下一跳节点,因此可以通过最大Q 值的收敛时间来预估学习过程的收敛时间和路由建立的时间。
设置场景中节点的最大移动速度为5 m/s,设置5 条端到端业务,发送速率为4 kbps,随机选取实验场景中的一条端到端业务,源节点的Qmax值随仿真时间的收敛过程如图4 所示。

图4 源节点Qmax随仿真时间的变化情况
在仿真的开始阶段,Qmax增加迅速,随着时间的增加增幅逐渐变缓,并在20 s 左右趋于稳定,这说明在协议运行期间,源节点从网络中学习最小跳数、网络拓扑变化情况以及链路空闲程度信息,这些信息最终反应在Q值的大小上。随着节点的运动和网络中业务负载的变化,Qmax也可能小幅度波动,但不会像路由建立初期那样剧烈变化。可以认为,在按照表2 配置的仿真参数下,路由建立的时间为20 s 左右,因此为了避免误差,业务数据的传输应该设置在网络启动运行20 s 之后。
3.2 性能分析
为了测试网络拓扑运动的剧烈程度对协议性能的影响,设置业务源节点的发送速率一致,均为4 kbps。无人机最大移动速度在0~25 m/s 时的端到端时延和分组投递率变化情况分别如图5 和图6 所示,可以看到,节点的移动速度越快,端到端时延逐渐增加,分组投递率逐渐降低,在无人机移动速度较低时,拓扑结构的变化不大,三种协议的端到端时延和分组投递率基本保持一致,当无人机最大速度上升到25 m/s 时,SW-OLSR 通过引入速度加权的ETX 和节点位置信息,UQL-OLSR 通过加入对链路质量和节点负载的评估和Q-learning 奖励机制,在时延上相比OLSR 分别降低了9.8% 和13.5%,在分组投递率上分别提高了46.2%和51.8%。两种优化OLSR 协议都考虑了拓扑结构变化对数据传输的影响,能够选择稳定性更高的下一跳节点,减少了网络中链路断裂的情况。
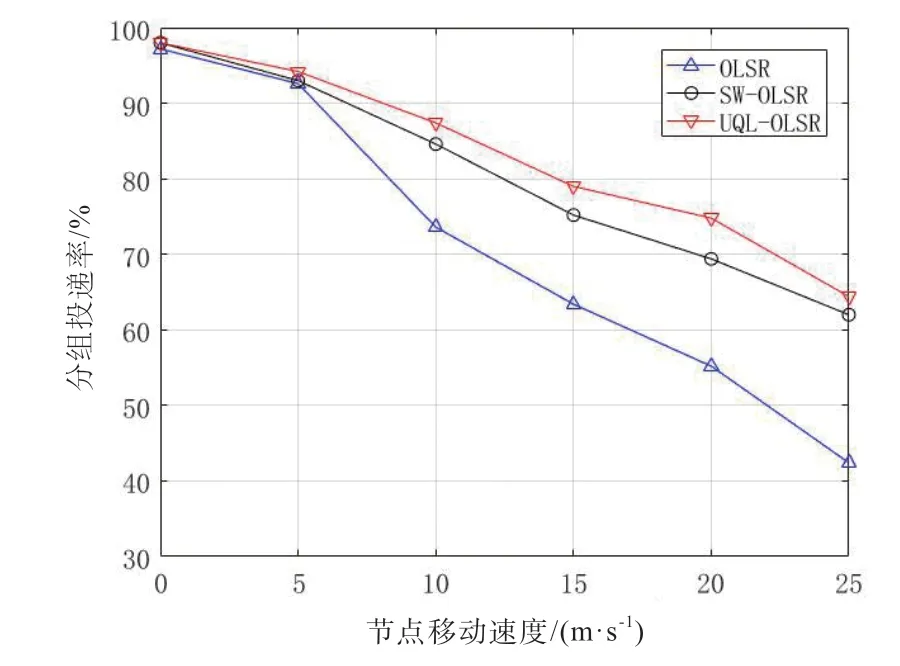
图6 分组投递率随节点移动速度的变化情况
同时,为了测试节点吞吐量对协议性能的影响,统一设置节点的最大移动速度为5 m/s,在场景中随机添加5 条端到端业务,统计业务速率在100 kbps~500 kbps 下的端到端时延和分组投递率变化情况。如图7 和图8 所示,随着业务速率的提高,网络中的节点负载增加,端到端时延提高,分组投递率降低。同样,发送速率较低时三种协议的端到端时延和分组投递率没有明显区别,但当发送速率相对较大,为500 kbps 时,SW-OLSR 协议由于考虑了无人机节点运动的因素,在时延和分组投递率上分别进步了17.0% 和21.2%,但UQL-OLSR 协议同时还考虑了节点邻居的负载程度,优先选择负载较小的下一跳邻居,因此,在业务速率较大的场景下,时延和分组投递率进一步优化了7.4% 和12.1%。

图8 分组投递率随业务发送速率的变化情况
4 结束语
传统OLSR 协议在更新路由时仅使用路径跳数作为判决准则,无法适应现今无人机自组网中高动态、高负载的场景,针对这个问题,本文以Q 学习框架为基础,将路径跳数、链路质量和节点负载三个因子作为路由测度,设计了UQL-OLSR 协议,在协议的工作过程中,节点通过广播Hello 和TC 分组交互路由测度信息,网络节点通过维护一个Q 值表实现动态的路由更新。实验结果表明,UQL-OLSR 协议相比OLSR 协议在平均端到端时延和分组投递率上有明显优势,更加适用于节点高速移动,数据交互频繁的无人机自组网场景。
