基于弱监督的改进Transformer在人群定位中的应用
2023-10-10邓淼磊赵文君陈法权张德贤
高 辉,邓淼磊,赵文君,陈法权,张德贤
1.河南工业大学 机电工程学院,郑州 450001
2.河南省粮食信息处理国际联合实验室,郑州 450001
3.河南工业大学 信息科学与工程学院,郑州 450001
人群定位旨在预测头部,获得视频图像中每个目标的位置,是人群分析的一项重要研究内容。主流人群定位方法大致可分为基于检测、基于回归和基于密度图的方法。基于检测的方法[1-3]主要遵循Faster RCNN[4]的路线,利用最近邻头部距离来初始化伪真值(ground truth,GT)边界框。它们通常遵循两步探测原则,头部位置等于预测边界框的中心。然而,伪GT 值并不能精确表示头部尺寸,导致检测性能差。此外,手动设计的非最大抑制(non-maximum suppression,NMS)算子可以消除负面预测。Ⅰdress等[5]和Gao等[6]利用了小型高斯核密度图,头部位置等于密度图的最大值。尽管使用小内核可以生成清晰的密度图,但在极度密集的区域仍然存在重叠,使得头部位置无法区分。因为位置图需要经过精心设计,从而基于密度图的方法具有相对较高的定位精度,所以大多数人群定位方法是基于密度图的,如距离标签图[7]、焦点反变换图(focal inverse distance transform map,FⅠDTM)[8]和独立实例图(independent instance map,ⅠⅠM)[9]。然而,基于密度图的方法需要复杂且不可微分的后处理来提取头部位置,例如“查找最大值”。
此外,基于密度图的方法依靠高分辨率表示生成清晰的地图,以便更好地找到局部最大值,这意味着需要多尺度特征映射。相比之下,基于回归的方法比基于检测和基于密度图的方法更简单,原因可以概括为两个方面:(1)训练简单,既不需要预处理,如生成伪GT框或本地化地图,也无须进行后处理,如NMS 或“查找最大值”。(2)不依赖于高分辨率表示,如复杂的多尺度融合或上采样机制。Song 等[10]是通过对大量提案定义替代回归来实现的,该模型依赖于预处理,例如生成8×W×H点提案。
随着深度学习的发展,Transformer在计算机视觉中迅速传播开来[11-16]。具体而言,Carion 等[11]提出一种没有NMS 的端到端可训练检测器detector Transformer(DETR),利用Transformer解码器在端到端管道中对目标检测进行建模,并仅使用一个单级特征映射成功地消除了后处理的需要,实现具有竞争力的性能。然而,DETR主要依赖带有类置信度的L1距离,即在没有上下文的情况下为每个GT 分配每个独立匹配可能导致错误,且与目标检测不同的是人群图像只包含人头一个类别,而密集的人头的纹理都相似,所以预测的可信度很高,从而造成大大降低算法的定位效果。在DETR的基础上,Meng 等[12]提出一种用于快速DETR 训练的条件交叉注意机制,加速了DETR 的收敛。在人群分析中,Liang 等[15]提出了TransCrowd,它从基于ViT 的序列计数的角度重新表述了弱监督人群计数问题。TransCrowd能够利用ViT 的自注意力机制有效地提取语义人群信息。此外,这是研究人员首次采用ViT进行人群计数研究,并且取得显著效果。Sun 等[17]展示了点监督人群计数设置中Transformer的功效。但他们都只关注人群计数任务,而不是人群定位任务。
只有少数方法专注于计数,缺乏标记数据。传统方法[18]依赖于手工制作的特征,如GLCM 和边缘方向,对于这种弱监督的计数任务,这些特征是次优的。Lei等[19]从少量的点级注释(完全监督)和大量的计数级注释(弱监督)学习模型。Borstel 等[20]提出了一种基于高斯过程的弱监督解,用于人群密度估计。类似地,Yang等[21]提出了一种软标签排序网络,可以直接回归人群数量,而无须任何位置监控。然而,这些计数级弱监督计数方法的计数性能仍然没有达到与完全监督计数方法相当的结果,存在大量退化,限制了弱监督方法在现实世界中的应用。因此,基于ViT的架构采用了弱监督方法。其中,Tian等[22]借鉴了Chu等[23]提出的Twins SVT,包括骨干网络和一个复杂的解码器,它既可以执行完全监督的人群计数,也可以执行弱监督的人群计数。在密集场景中,由于对每个头部标注边界框既费时又费力,因此一般用头部的中心点表示目标的位置,而且当前大多数数据集仅提供点级标注。因此,设计一种准确的人群定位算法可以提高人群跟踪和人群计数性能。
1 改进的人群定位网络
本文旨在探索将纯Transformer 模型用于人群定位,建立一个基于弱监督的改进Transformer框架Local-Former,如图1所示。该方法无须额外的预处理和后处理即可直接预测所有实例子,包含特征提取网络Backbone、编码器-解码器网络与预测器。具体来说,该方法首先使用预先训练的Transformer骨干网络从输入图像中提取多尺度特征,并将来自不同阶段的特征通过全局最大池化(global max pooling,GMP)操作后,再经过聚合模块得到组合特征F。其次,在编码器-解码器网络中,将组合特征进行位置嵌入后的特征Fp输入编码器,输出编码特征Fe,再将Fe输入解码器,且每个解码器层采用一组可训练嵌入作为查询,并将编码器最后一层的视觉特征作为键和值,输出解码特征Fd用于预测置信度得分。最后,将Fd和置信度得分送入二值化模块自适应优化阈值学习器,精确地二值化置信度图,从而得到人头中心位置。

图1 LocalFormer网络结构图Fig.1 Network structure diagram of LocalFormer
1.1 Transformer骨干网络
本文提出的LocalFormer 使用金字塔vision Transformer 作为特征提取骨干网络,在此参考PVTv2[24]的“PVTv2 B5”版本,如表1 所示。它有4 个阶段,每个阶段生成不同比例的特征图。每个阶段的架构包括重叠的补丁嵌入层和变压器编码器层的Li数,即第i阶段的Li编码器层。PVTv2 利用重叠的补丁嵌入来标记图像。生成补丁时,相邻窗口的重叠面积为其面积的一半。重叠补丁嵌入是通过应用零填充卷积和适当的步长来实现的。具体来说,对于大小为W×H×C的输入,卷积层的内核大小为2S-1,零填充为S-1,步长S,内核数C被用于生成一个尺寸为×C的输出。第一阶段生成补丁的卷积步长为S=4 ,其余阶段为S=2。因此,从第i阶段获得一组特征图,与输入图像的大小相比,尺寸缩小了2(i+1)。

表1 LocalFormer骨干网络参数配置Table 1 Parameters setting of LocalFormer backbone network
标准Transformer 层由multi-head attention 和MLP块组成,同时采用了层归一化(layer norm,LN)和残差连接,如图2 所示。在第一阶段开始时,输入被均匀地划分为大小相等的重叠补丁,每个补丁被展平并投影到Ci 维嵌入中。第1、2、3 和4 阶段嵌入维度分别为64、128、320 和512,这些补丁嵌入然后通过Transformer 编码器。每个编码器由一个自我注意机制和一个前馈神经网络组成,位置编码在前馈神经网络中完成。在LocalFormer中,输入图像大小为384×384×3像素,第一阶段的补丁大小为7×7×3 和3×3×Ci,其中Ci是第i阶段的嵌入维度。如前所述,C2=64、C3=128 和C4=320。因此,得到的输出特征的尺寸分别为96×96×64、48×48×128、24×24×320和12×12×512。

图2 标准Transformer层Fig.2 Standard Transformer layer
通过实验,在Transformer 骨干网络前三阶段使用全局最大池化锐化提取特征,去除无效信息。在第四阶段使用全局平均池化(global avg pooling,GAP)来获取全局上下文信息,找到所有的目标可区分区域。因此,从每个阶段获取特征映射,执行全局池化操作以获得64、128、320和512维的一维序列,并将这些序列中的每一个投影到长度为6 912的一维序列中。
1.2 Transformer编码器-解码器
1.2.1 编码器
由于Transformer 编码器采用1D 序列作为输入,本文在Transformer 骨干网络提取的特征Fp可以直接送入Transformer 编码器层,以生成编码特征Fe。这里,编码器包含许多编码器层,每一层包括一个自注意力(self-attention,SA)层和一个前馈(feed-forward,FF)层。SA由3个输入组成,包括查询(query,Q)、键(key,K)和值(value,V),定义如下:
其中,Q、K和V从相同的输入Z获得(例如,Q=ZWQ)。特别是,使用多头自注意力(multi self-attention,MSA)来建模复杂的特征关系,这是多个独立SA模块的扩展:MSA=[SA1,SA2,…,SAm]W,其中W是重投影矩阵,m是设置为8的注意头数。
1.2.2 解码器
Transformer解码器由多个解码器层组成,每一层由3 个子层组成:(1)一个自我注意力(SA)层。(2)交叉注意(cross attention,CA)层。(3)前馈(FF)层。SA和FF与编码器相同。CA模块将两个不同的嵌入作为输入,而不是SA中的相同输入。将两个嵌入表示为X和Y,CA可以写为CA=SA(Q=XWQ,K=YWK,V=YWV)。
本文中,每个解码器采用一组可训练嵌入作为查询query,最后一个编码器层的视觉特征作为键和值。解码器输出解码后的特征Fd,用于预测人头的点坐标(point coordinate)及其置信度得分(confidence score),从而得出场景中的人数和人群定位。
1.3 二值化模块
许多主流方法利用热图进行目标定位,通常设置阈值以从预测的热图中过滤位置信息。大多数启发式人群定位方法[2-3,8,25]在数据集上用单个阈值提取头部点。显然,这不是最佳选择,因为低置信度和高置信度之间的置信度响应不同。为了缓解这个问题,ⅠⅠM提出学习一个像素级阈值图来分割置信度图[9],这可以有效提升捕获更多较低响应头并消除相邻头中的重叠。但也存在两个问题:(1)阈值学习器在训练过程中可能会诱发NaN(not a number)现象。(2)预测的阈值图相对粗糙。因此,考虑重新设计二值化模块来解决这两个问题。
如图3 所示,置信度预测值被馈送到阈值学习器中,用于解码像素级阈值映射。这里,进行像素级的注意过滤器操作,而不是直接传递特征映射Fd。注意过滤器是解码特征Fd和置信度预测C之间的点积操作,其可表示为:
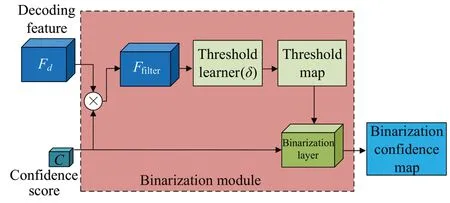
图3 二值化模块流程图Fig.3 Flowchart of binarization module
二值化模块的核心组件是阈值学习器和二值化层。前者从过滤器学习像素级阈值映射T,后者将置信度映射C二值化为二值映射B。其中,阈值学习器由5个卷积层组成:前三层以3×3的内核大小逐步减少特征通道,每一层后面都有一个批量归一化和ReLU激活函数。最后两层的内核大小分别为3×3 和1×1,然后是批处理规范化、ReLU 和平均池层。添加窗口大小为9×9的平均池层来平滑阈值图。最后,引入了一个定制的激活函数来解决NaN现象,其定义如下:
等式(3)将Ti,j的范围限制为[0.25,0.90]。与压缩的Sigmoid激活函数相比,它不会强制最后一层输出±∞等无意义值,因此,它增加了数值计算的稳定性。为了确保在训练过程中适当优化阈值,规定了公式(4)的推导规则。
阈值学习器定义为δ,参数θt,其输出阈值映射如公式(5)所示:
现在,通过将置信度映射C和阈值映射T转发到可微二值化层,得到了具有函数ø(C,T)的二值映射B,其公式如下:
1.4 损失函数
在获得一对一匹配结果后,需要计算反向传播的损失。由于不同图像的人群数量差异很大,而且L1损失[23]对异常值非常敏感,所以使用平滑的Ls损失,而不是L1损失。平滑Ls损失定义如下:
公式(7)可以看出,当 |Prei-Gti|>β时,平滑Ls损失作为L1损失。|Prei-Gti|≤β时,平滑Ls损失作为L2损失。β是一个超参数,Prei和Gti分别代表给定图像中的预测人数和真实人数。
2 实验
2.1 数据集
在3个具有挑战性的数据集上评估本文方法,每个数据集详细情况如下:
ShanghaiTech[26]是前几年最大的大规模人群统计数据集之一,由1 198幅图像和330 165条注释组成。根据密度分布的不同,将数据集分为两部分:A 部分和B 部分。A 部分由300 张训练图像和182 张测试图像组成。B部分包括400张训练图像和316张测试图像。A 部分是从互联网上随机选取的图片,B部分是从上海一个大都市的繁忙街道上拍摄的图片。A 部分中的密度比B部分中的密度大得多。该数据集所呈现的规模变化和视角扭曲为许多基于CNN的网络的设计提供了新的挑战和机遇。
UCF-QNRF[5]是一个密集的数据集,包含1 535幅图像(1 201 幅用于训练,334 幅用于测试)和1 251 642 个注释。每幅图像的平均行人数量为815人,最大人数达到了12 865人。此数据集中的图像具有更广泛的场景,并包含最多样化的视点集、密度和照明变化。
NWPU-Crowd[27]是从各种场景收集的大规模数据集,共包含5 109 幅图像,总共包含2 133 238 个带注释的实例。这些图像随机分为训练集、验证集和测试集,分别包含3 109、500 和1 500 幅图像。与现实世界中以前的数据集相比,除了数据量之外,还有一些其他优点,包括负样本、公平评估、更高的分辨率和较大的外观变化。此数据集提供点级和框级注释。
2.2 训练环境
对于上述数据集,使用原始大小的图像随机水平翻转、缩放(0.8~1.2 倍)和裁剪(768×1 024)来增加训练数据。批处理大小为8,二值化模块学习率设置为1E-5,其余可学习模块的学习率初始化为1E-6。在训练期间,通过衰减策略更新学习率,衰减率为0.9,Adam[28]算法用于优化框架,选择验证集中性能最好的模型来进行测试和评估本文模型,将10%的训练数据集划分为一个验证集。在测试阶段,在验证集上选择性能最好的模型来评估测试集上的性能,执行端到端预测,无须多尺度预测融合和参数搜索。
2.3 评估指标
在这项工作中,使用精度(precision,Pre)、召回率(recall,Rec)和F1 值(F1-measure,F1)作为人群定位的评估指标,具体计算如下所示:
其中,TP表示预测为1,实际为1,预测正确;FP表示预测为1,实际为0,预测错误;FN表示预测为0,实际为1,预测错误。
预测点和ground truth遵循一对一匹配。如果匹配对中的距离小于距离阈值σ,则相应的预测点被视为人头中心点的位置。对于ShanghaiTech数据集,使用两个固定阈值,包括σ=4 和σ=8。对于UCF-QNRF,使用[1,2,…,100]中的各种阈值范围,类似于CL[5]。对于提供框级注释的NWPU群组数据集,σ设置为/2,其中w和h分别是每个头部的宽度和高度。
2.4 消融实验
2.4.1 全局池化影响
首先研究GMP和GAP的影响。当删除GMP时,观察到人群定位的性能显著下降,精度从74.9%降至72.6%。而删除GAP 时,精度从74.9%降至73.2%。全局池化对算法的消融实验,结果如表2所示。
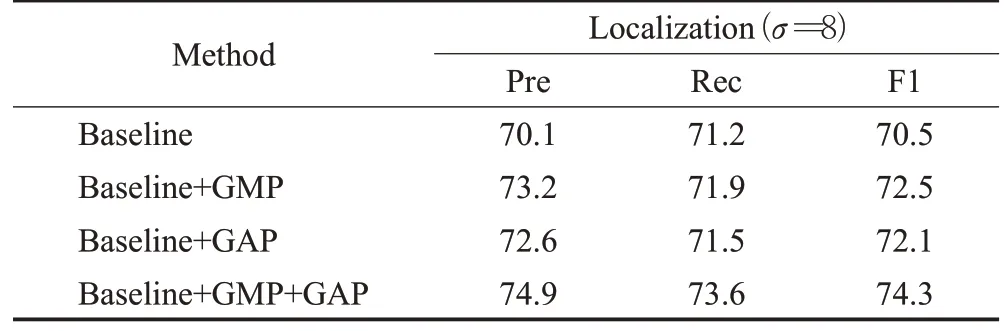
表2 全局池化消融实验结果Table 2 Results of global pooling ablation experiment单位:%
2.4.2 Transformer大小消融
接下来,研究了改变Transformer 大小的影响,包括编码器/解码器层的数量和可训练的实例查询。如表3所示,当层和查询数设置为6 和500 时,LocalFormer 实现了最佳性能。当查询数为300时,所提出的方法的精度降至74.5%。当查询数更改为700 时,所提出方法的精度降至74.3%。因此,查询数量过多或者过少都会影响所提出算法的性能。
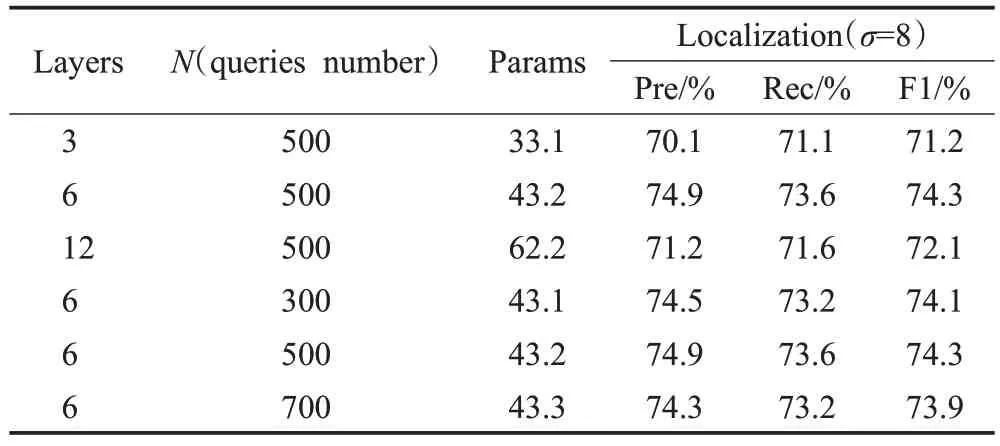
表3 Transformer 尺寸的影响Table 3 Effect of Transformer size
3 结果及讨论
首先使用一些最先进的本地化方法来评估本地化性能。对于NWPU人群,如表4所示,一个大型数据集,本文提出的LocalFormer 在验证集上的F1 值优于Auto-Scale[7],为4.0个百分点。值得注意的是,该数据集提供了精确的框级注释。尽管本文方法只是基于点注释,这是一种更弱的标记机制,但它仍然可以在NWPU-Crowd测试集上实现有优势的竞争性能。对于密集数据集UCF-QNRF(见表5),本文方法实现了最佳的召回率和F1 值。对于ShanghaiTech PartA(见表6),一个稀疏的数据集,本文的LocalFormer将最先进的方法TopoCount的F1 值改进了1.1 个百分点,用于严格的设置(σ=4),并且在不太严格的设置(σ=8)中仍然领先。这些结果表明,该方法可以处理各种场景,包括大规模、密集和稀疏场景。
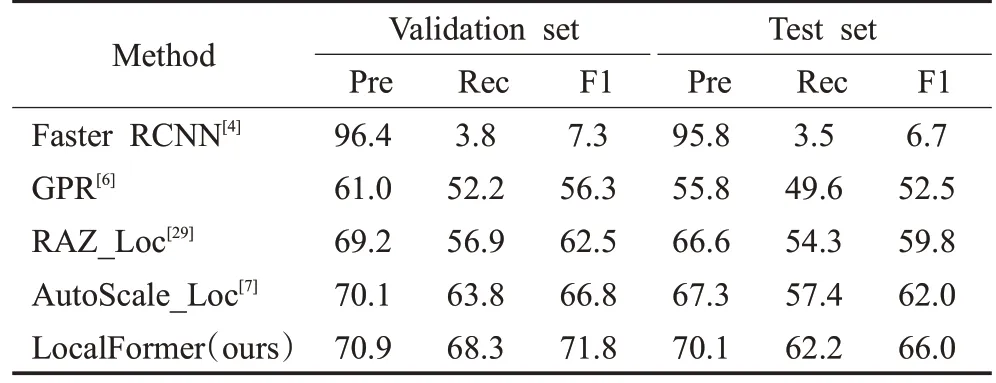
表4 NWPU-Crowd数据集的人群定位性能Table 4 Crowd localization performance on NWPU-Crowd dataset 单位:%

表5 UCF-QNRF数据集的人群定位性能Table 5 Crowd localization performance on UCF-QNRF dataset 单位:%
本文方法的人群定位结果可视化如图4所示,第一行为3 个数据集上的4 张人群样本图,第二行为人群定位效果图。其中,图4(a)和4(b)分别来自ShanghaiTech数据集PartA 和PartB,图4(c)来自NWPU-Crowd 数据集,图4(d)来自UCF_QNRF数据集。

图4 人群定位可视化结果Fig.4 Visualization results of crowd localization
4 结论
本文提出一种基于视觉Transformer 的人群定位算法LocalFormer,实现了在密集场景下人群定位。该算法基于弱监督学习,将纯Transformer 网络用于人群定位,并进行了改进。通过在Transformer 每一层之后加入全局最大池化操作提高骨干网络的特征提取能力。在编码器-解码器层,将聚合特征嵌入位置信息,并通过二值化模块自适应优化阈值学习器,大幅提升了人群定位模型性能。在三个具有挑战性的数据集上的实验证明本文方法简单而有效。下一步,将结合目标检测等,探索轻量化的人群定位模型,提高人群分析效率。
