基于光流和自编码器的微表情检测方法
2023-10-09黄树成罗德广
黄树成 罗德广
(江苏科技大学计算机学院 江苏 镇江 212003)
0 引 言
面部表情是日常社会交往的主要方式,也是察觉个人的情绪和心理状态的最重要的外在指标之一。随着心理学的日益成熟,研究发现人们可以通过控制自己的面部表情,产生自主的假表情去欺骗观察者,所以通过表情往往不能反映人的真实情绪[1],针对这类现象Haggard等[2]发现一种新的情绪表达机制——微表情。微表情具有持续时间短并且出现强度弱的特点,但通常能反映出人真实的情绪,但这种微小的运动变化和瞬时性对人的肉眼来说是巨大的挑战[3]。微表情出现在高风险的环境下,试图去隐藏所在经历的情感时所流露出的非自主的脸部肌肉运动,微表情由自然状态到顶峰状态再恢复到自然状态下的时间少于500 ms[4]。由于微表情的不可欺骗性,微表情检测被广泛应用在例如公共安全[5]、刑侦心理学[6]、政治心理学[7]、教育心理学[8]等地方。
为了编码微表情,人脸动作编码系统(FACS)被广泛地应用到微表情的研究之中,FACS的产生建立了人脸肌肉和情绪表达之间的关系,而动作单元(AUs)就是FACS中必不可少的组成部分,每一个AUs代表着局部的人脸肌肉运动。通过观察人脸的AUs去判断微表情(ME)所产生的区域,大大提高了标注的准确度。
研究微表情需要从可用数据集开始,然而可供研究的自发微表情数据集很少,目前可用的自发性微表情数据集有:SMIC[9],CASME[10]、CASME II[11]、CAS(ME)2[12]和SAMM[13]。然而通过AUs标注了的数据集只有SAMM和CASME数据集。
近年来,微表情的研究方向更多的在于微表情识别方向,而微表情检测很少。为了提高检测的准确性,不同的特征被用于来做微表情检测任务,从ME的产生开始,人脸的局部运动变化变得可以捕捉,LBP模式[14]是目前常见的特征分析方法,用于提取局部纹理变化信息。随着光流的算法被广泛地利用,光流特征逐渐被用作为微表情检测的特征。Liu等[15]提出的主方向平均光流加入了微表情的研究之中。2018年Li等[16]提出了一种视频微表情检测的改进光流算法,针对人为识别的困难性,提出改进光流的HS光流算法,用于自动的微表情检测,取得不错的效果。随着数据集的逐渐完善,一开始Li等[17]提出的LTP-ML方法使得微表情检测的准确度达到了75%,到Li等[18]提出的一种基于深度学习下的微表情时许检测方法,微表情检测的准确率在一直提高。即使ME在被控制的严格环境下被采集,也还有许多如头动和眨眼等外界因素的干扰,使得微表情检测的准确度受到了影响,所以缺少自发性带标注的微表情数据集成为了微表情检测的主要挑战。为了克服数据集标注所带来的阻碍,通过大量的摄像头来采集实验场景下的微表情的方法,在采集到微表情后需要标注出起始帧、顶峰帧和结束帧,这就带来了一个另外挑战——因为标注所带来的巨大成本。目前为止,标注过程都是通过人在低速下观察每个采集到的微表情视频片段进行标注,然而标注者可能在很长的视频中标注只含有几个微表情变化的片段。为了解决这个问题,需要一种方法能去除长视频中不包含微表情变化的片段,因此需要带有标注的长视频。
现有的数据集中只有CAS(ME)2和SAMM数据集包含了这样的长视频,而其他的数据集只是带有一个微表情片段的预训练短视频。如图1的例子所示。
本文提出一种利用自编码器学习光流特征去识别微表情长视频的方法,提取指定区域的稠密光流特征,然后传递给自编码器学习后再去做检测的任务。相比于用传统的神经网络模型,由于微表情数据集的label量大且是人工标注,容易导致训练的准确率不高,自编码器(Autoencoder)模型特点是无监督学习,不需要标签值,使得网络模型学习到的特征更加精确。在实验预处理中将采集的微表情视频转换为图片,再通过Dlib数据库中的人脸检测算法捕捉到人脸,提取出兴趣区域后做人脸对齐,很大程度上减少了物理干扰。本文所提出的方法最大的贡献就是在微表情检测中引入了自编码器模型,降低了无标签所带来的不足。
近年来,深度学习成为了研究中必不可少的主要技术,通过深度学习的方法提取的特征更加的精确。近两年中在CV(Computer Vision,CV)方向发现,基本所有的比赛中都加入了如CNN(Convolution Neural Network),RNN(Recurrent Neural Network)等技术,结果都在往越来越好的趋势发展。本文将结合自编码器技术和光流算法。
1 相关理论与技术
1.1 ROIs区域提取
ROIs(Region Of Interest)区域的提取是对微表情预处理中最常见的方法之一,选取区域的优势在于消除了物理因素对微表情检测所带来的误差。
ROIs最早是由Liong等[19]所提出用于提取出微表情序列中的顶峰帧,最早提出时所选择的区域为“右眼和右边眉毛”“左眼和左边眉毛”“嘴巴”这三个区域,然后由Liong等[20]研究改进后发现在微表情检测中眨眼对检测的准确度有大的影响,所以将眼睛区域的区域去掉。
Davison等[21]而后提出了在FACS(Facial Action Coding System,FACS)的基础上建立提取区域,这种方法所提取的区域是根据人脸的一些特定的AUs(Action Units,AUs)的运动去提取出检测区域,很大程度上结合了人脸肌肉运动与微表情产生之间的联系。
1.2 微表情发现方法
早期Moilanen等[22]引入一种从外观特征的差异去点注微表情的方法,首次提出了用一个大小为N的滑动窗口去做检测,其中N的大小为微表情出现的周期,而本文将采用稠密光流场算法去发现微表情变化。光流(optical flow)法有两个基本的假设条件,一个是亮度保持基本的不变性,第二就是时间是连续的或者运动是非常小的,其公式如下:
I(x,y,t)=I(x+dx,y+dy,t+dt)
(1)
式中:I表示t时刻的光流;dx和dy表示t时间内,x和y的偏移量。
将式(1)做泰勒展开(ε为二阶无穷小,可忽略),得到式(2)。
(2)
结合式(1)与式(2)可得:
(3)
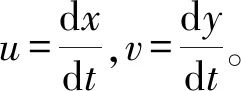
1.3 自编码器
随着深度学习应用的不断成熟,从最早的CNN、RNN到现在的自编码器、GNN,深度学习的框架不断地受到了重视,深度学习的学习方式包括有监督学习、无监督学习、自监督学习。所谓的有监督学习就是在输入数据进入模型训练时,每组需要训练的数据都有自己的label值,再通过模型产生的预测值与训练数据的真实标签进行比较,不断地优化过程。而无监督学习就是在没有label的输入下对输入数据寻找变化的特征,常见用于对数据的可视化,去噪或者降维下使用。而自监督就是监督学习中的一个特例,训练过程中没有人工的标注,通常可以看作无人工标注下的监督学习。自编码器就是采用了自监督学习的方式,自编码器最早由Lecun等提出,因为自编码器独有的特征使得这类网络模型受到了大数的微表情研究者们的喜爱。对于标注数据不足的微表情数据集而言,采用自编码器模型大大地减少了对数据集标注的依赖。自编码器分为encoder和decoder层,通常采用自编码器的encoder层对输入的图片数据进行训练,对特征进行不断地学习,图2为卷积自编码器模型图。
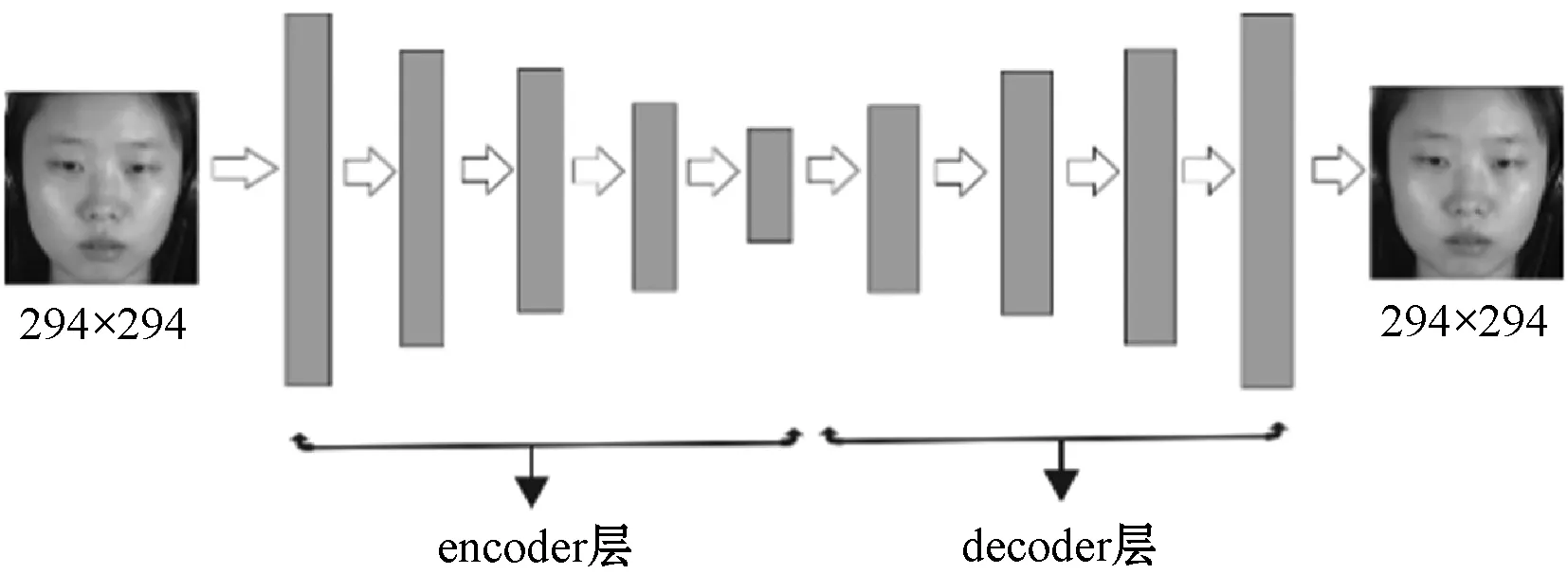
图2 卷积自编码器模型图
2 检测方法设计
提出的方法主要包括了四个主要的步骤:图像预处理、光流场计算、自编码器模型训练、SVM分类检测微表情。第一步就是将微表情视频处理为图片后,对图片进行预处理操作,主要包括了对图像的人脸检测、裁剪以及对齐,对齐之后选取关键的ROIs区域。第二步就是对图像进行光流的计算,得到光流特征,将光流特征作为自编码器的输入进行训练,截取出encoder层的结果,通过SVM分类器中做二分类操作。
2.1 预处理
预处理中首先通过Dlib[24]库中的人脸检测器对人脸进行检测,通过检测之后可以得到一个框出了人脸的矩形框,然后对人脸进行裁剪,如图3的上半部分所示。第二步,采用了Dlib库中的人脸68特征点标注的函数对人脸进行定位,然后通过计算两眼的角度,利用opencv[25]中的图像旋转方法对图像进行对齐,使得两眼处于同一水平线上,对齐以后再对图像进行landmarks检测与定位,如图3的下半部分所示。
2.2 光流计算
通过对图片的预处理部分可以得到经过了对齐以后的人脸图片,接下来就是提取图片的稠密光流运动特征,通过计算两图之间各像素点的运动信息来保存微表情信息,这部分是实验中必要的部分,因为训练自编码器时,深度学习模型从图片学习的特征不定,通过光流处理后,保存的运动信息可以让模型更好地学习输入数据。如图4所示,光流特征提取及光流有无累加进行了比较。对齐以后的光流再进行了光流累加的效果,使得光流图特征更加完善。

(b) 直接计算Deepflow
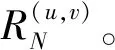
(4)
(a) (b)
2.3 自编码器模型
2.3.1编码层网络结构
编码层中我们主要采用了卷积层、池化层、BN层、激活函数层。
(1) 卷积层:是由所设定的卷积层层数组成,每个卷积单元的参数都是通过不断训练网络利用反向传播算法最佳化所得的,卷积操作的引入目的是提取出网络输入中的不同特征,添加多层的网路能从网络中学习到更加复杂的特征。
(2) BN层:训练网络时,除了输入层数据进行了归一化的操作保证了输入数据分布一致以外,每层训练中网络的输入数据分布不一致,使得网络不得不适应新的数据分布,导致了训练网络所花费的时间增加,网络收敛速度慢,于是就引入了BN层。和网络的激活函数层、卷积层一样,BN(Batch Normalization)层也属于网络的结构之一。引入BN层可以改变原始数据存在的杂乱无章,使得数据分布具有一定的规律,加快了收敛速度。
(3) 激活函数层:常见使用线性整流(Rectified Linear Units,ReLU) f(x)=max(0,x)作为神经网络的激活函数。常见的激活函数还包括双曲正切函数、Sigmoid函数,但是ReLU激活函数更受青睐,因为在训练过程中使用ReLU激活函数可以提升模型的训练速度,却不影响模型的泛化性。
(4) 池化层:池化(Pooling)是卷积网络类型一个重要的操作,它实际上是一种降采样的方式,常见的有两种池化方式:最大池化、平均池化。最大池化就是将输入图像划分为若干个区域,选取区域中的最大值。而平均池化为选取区域的平均数。池化过程可以减少数据的空间大小,使得训练的参数以及计算量下降。
2.3.2解码层网络结构
解码层中我们首先将编码层中的图上采样为指定大小后利用反卷积操作得到与原图大小一致的图片。
3 方法模型设计及训练
本文提出的网络模型如图6所示。训练时,选择batch-size为32,学习率为0.025,训练迭代次数为300次,每层深度模型中加入了Dropout层来防止过拟合,大大提高了模型的泛化性。训练过程中首先对微表情数据集进行了裁剪以及对齐的方法处理微表情视频帧,得到了N帧源图,通过稠密光流计算得到光流图,将光流特征传入自编码器中,自编码器网络模型为:encoder层使用4层卷积,分别为Conv1_1(16个卷积核大小为3×3,stride为1),Maxpool2D,Activation(主要使用ReLU函数);Conv2_1(32个大小为3×3卷积核,stride为1),Maxpool2D,Activation;Conv3_1(64个大小为3×3的卷积核),Maxpool2D,Activation;Conv4_1(128个大小为3×3的卷积核),Maxpool2D,Activation。从encoder层中出来的特征为(h,w,128)大小的特征数,decoder层使用向上采样的方式进行反卷积操作,使用AdamOptimizer进行优化。再将学到的特征扁平到2维,格式如[num_iamge,nums_feature],其中num_image为图片数,nums_feature为每幅图的特征数,通过机器学习SVM分类器对数据进行标签处理,再与源数据的标签进行比较计算准确率。
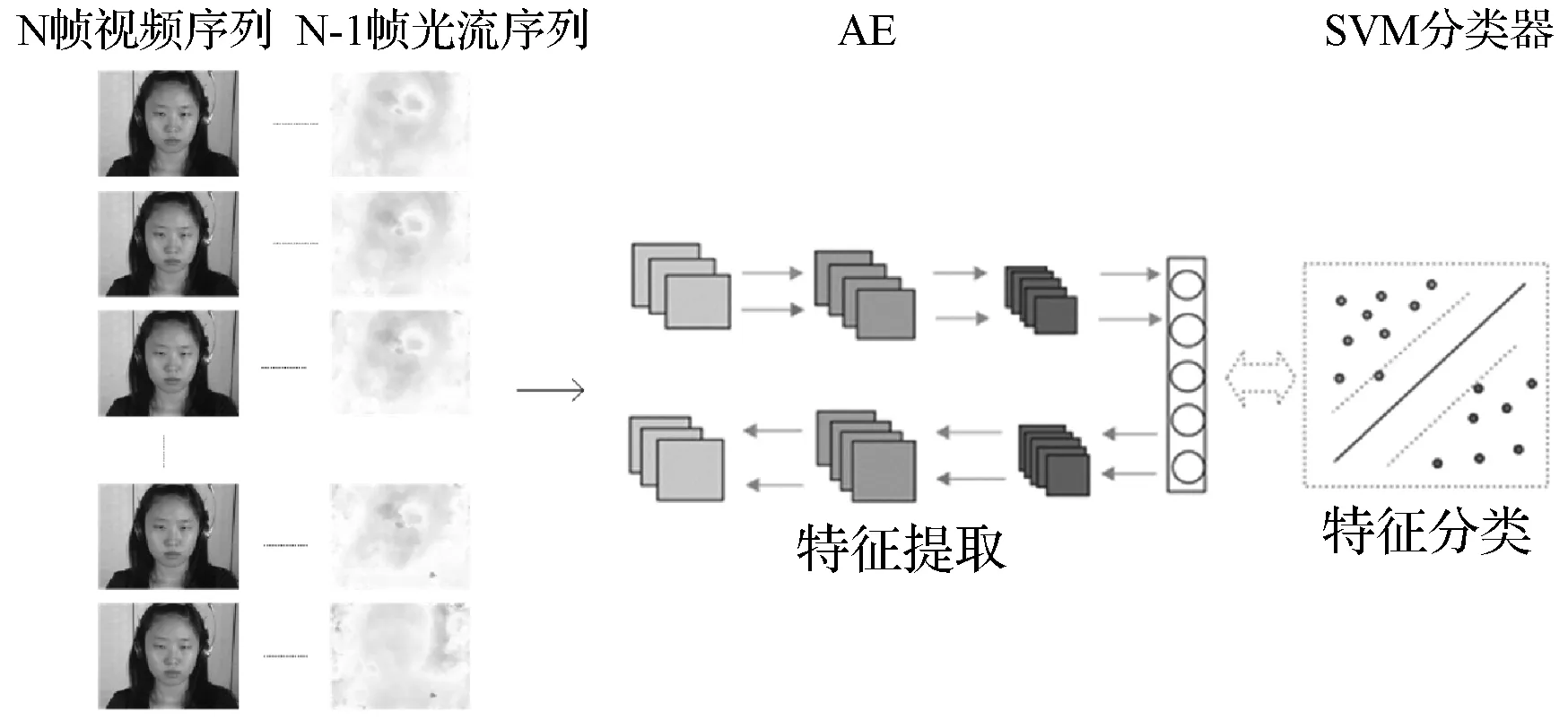
图6 本文提出的网络模型
4 实验结果与分析
本文的实验在Windows下,使用TensorFlow深度学习框架进行的,TensorFlow提供了完善的神经网络搭建方式,是目前深度学习框架最为实用与简便的框架之一。
本文中通过预处理微表情视频的图片,对有微表情的图片通过光流计算以及消除头部以及眨眼的过程,将所有处理之后的数据作为卷积自编码器的训练数据集,设定了一些超参数如Batch-size、学习率,为了防止过拟合,在训练训练集时通过dropout算法来处理,迭代300次,图7为训练的loss曲线。
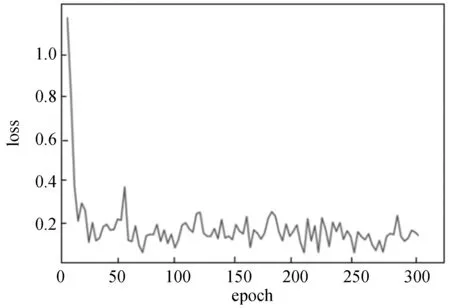
图7 训练的loss曲线
通过图7发现,迭代了300次以后,网络模型基本处于稳定状态。再将特征放入SVM分类器中,通过给每幅特征图进行编入标签(0,1),与原数据集中的标签值进行比较,达到了75.58%,如表1所示。相比于LBP-TOP-SVM[11]、VGGNet、RESNET、LEARNET,本文提出的方法得到了优化,虽然相比于LEARNET在检测的准确率上不足,但是,从网络参数量、占用资源、运行深度模型所需时间相比减少许多。
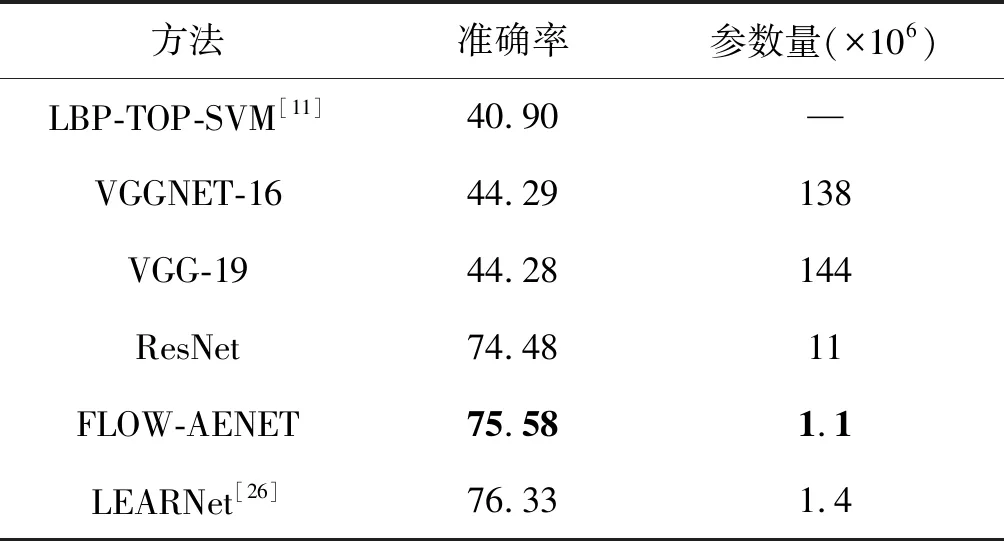
表1 方法比较
5 结 语
本文提出了一种基于传统光流方法与深度学习自编码器结合的微表情检测算法,在一定程度上克服了传统方法的不足。使用传统光流时做了对齐以及累加的改进,使得光流图效果以及特征更加完善。在深度学习方面,本文引入了较为成熟的自编码器模型,并且在模型中进行了改善,加入了归一化以及Dropout层防止过拟合的出现,利用4层卷积操作,解码层采用上采样的方式,大大减少了训练所需的时间,提高了方法的性能。针对微表情检测时出现的几种常见的影响因素,分别给出了相应的解决办法。实验表明,检测的准确率有所提高。
然而,由于采用深度学习以及光流方式来研究,微表情出现的微弱以及数据量的不足还是导致微表情检测率不高的主要因素,加上人工标注时所带来的误差使得检测准确率受到了一定程度的影响。在以后的工作中,可以建立更加合理的微表情数据集来进行操作,促进微表情研究的发展。
