基于大数据直觉模糊集的信息安全融合方法*
2023-10-07黄永生
黄永生
(合肥职业技术学院 现代教育技术中心,安徽 合肥 238000)
一、引言
信息安全融合是在信息融合过程中,现有信息改动做到最小,保证信息融合的安全[1]。随着信息在多领域的应用,模糊信息融合技术的发展,在信息描述不精确时提出一种模糊集,比模糊集多一种隶属度属性的集合称为直觉模糊集[2]。直觉模糊集用来描述信息的安全要素,由于直觉模糊集的信息规模大,在融合过程,常出现融合后的信息与原信息不接近,融合的不准确。因此研究直觉模糊集的信息安全融合方法具有重要意义。
许多相关学者对信息安全融合方法进行研究,如朱超平等[3]利用聚类分析算法进行信息的加权融合,该方法信息集难收敛,获得的融合信息易出现局部最优问题,聚类融合效果不好。陈彬等[4]依据配电网信息的时间和空间的特性,基于信息的关联性利用时空网络完成配电网多源信息的融合,该方法运用信息的特性进行融合,对于信息特征模糊的信息融合具有局限性。张红等[5]通过卷积神经网络的信息融合模型进行融合,该方法需把信息集归一化处理,不同规模的信息集无法在一起训练,具有局限性。
本文提出一种基于大数据直觉模糊集的信息安全融合方法,通过构建数字规划融合问题模型,利用调和平均数法融合信息,平均数算法利用全部的信息特征融合。实验结果表明,该方法误差平方和统计量小,与实际信息特征相近,推算过程简单。
二、大数据直觉模糊集信息安全融合
1.多值直觉模糊集
对大数据直觉模糊集的信息,从不同的角度出发,融合的方法也有所不同,例如,不同的人对一件事情的评价,评价结果也不相同,因此在大数据直觉模糊集的信息安全融合时,引入多值直觉模糊集。
设直觉模糊集的论域[6]Z上的多值直觉模糊集B公式表现为:
(1)

(2)
当Z是离散空间的情况下,Z={z1,z2,…,zM},多值直觉模糊集为:
(3)
多值直觉模糊集B可用B=〈z,ηB,φB〉及B=〈z,ηB,φB〉/z表示,其中,ηB和φB是n维隶属及非隶属值。
在Z中的所有直觉模糊子集,第y个直觉模糊指数可用公式为:
(4)
2.信息安全融合
在多值直觉模糊集中,对其隶属度和非隶属度的信息进行融合[9],将多值直觉模糊集B转化成直觉模糊集A={〈z,ηA(z),φA(z)〉|z∈Z},结合调节平均数算法实现大数据直觉模糊集的信息安全融合。利用数字规划方法,保证信息安全融合。
(1)数字融合规划方法

当Z是连续空间时,模型表示为:
(5)
s.t.0≤ηA(z)+φA(z)≤1
0≤ηA(z)≤1
0≤φA(z)≤1
z∈Z
(6)

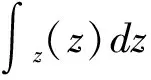
基于概率论的原理,数学期望Q(α)表达式为:
(7)
在Z内有y个随机数z1,z2,…,zl,优化融合模型转变为:
(8)
s.t.0≤ηA(zj)+φA(zj)≤1
0≤ηA(zj)≤1
0≤φA(zj)≤1
(j=1,2…,Y)
(9)
通过以上公式(5)及(9)求解,获取函数和的各参数ηA(z)和φA(z)的预估值。
(2)平均数信息融合算法
为解决直觉模糊集信息融合出现的问题,直觉模糊集融合前,需将多值直觉模糊集转化为直觉模糊集,多值直觉模糊集转化为直觉模糊集公式为:
(10)
(11)
信息融合算法是通过计算平均数的演变而来,表现为位置及变量对称的区别。推算表达式为:
(12)
(13)
信息融合算法优化通过优化加权算法平均数完成[11],优化后的算法表现为变量、权数、及推算位置对称的区别。优化公式表达为:
(14)
(15)

3.信息安全融合的遗传算法求解
利用遗传算法对融合规划求解[12,13],在运用遗传算法之前,考虑融合的变量过多,其取值范围大,利用浮点数进行编码。
(1)适应度函数
区分大数据直觉模糊集的信息安全融合用适应度来衡量,信息安全融合的适应度值越大,说明直觉模糊的信息融合得越安全。本文运用线性排序的适应度函数[14],降序目标函数值的排列,根据目标函数在种群的位置G可求解适应度值,适应度函数公式为:
(16)
其中,G表示个体在种群序列中所处位置,Nind为种群个体数量。
(2)选择算子
为加快遗传算法的计算效率及其收敛性,操作轮盘赌选择算子,所有个体投入到下一代的概率是信息融合安全的适应度值和个体适应度和的比值,信息融合安全适应度和算子被选择的概率成正比,适应度值越大,进入下一代的概率越大。
(3)交叉算子

(17)
(18)
其中,ε是[0,1]的任意数。
(4)变异算子处理
变异处理可以辅助新个体产生,该处理影响GA的部分搜寻性能,因此运用非均匀变异,随机扰动原有的基因值,基因变异处理后的两种选择可表达为:
(19)
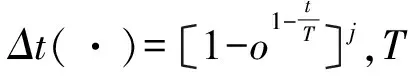
最优保存是在信息安全融合适用度最高的个体未进行交叉和变异操作,用适用度高的个体代替操作后出现适应度低的个体。
三、实验分析
以某地区电力企业为实验对象,该企业占地面积50m2,年均发电量可达600万度,该企业管理范围内配电网系统样本信息集为6个,编号1-6。为验证本文方法的信息安全融合效果,分别从电力项目评估信息融合、配电网高压电线环境监测信息融合、各系统节点电压及其功率信息融合三个角度出发,验证本文方法信息融合优势。
以该企业新开展的电力项目为实验对象,并将实验样本信息集标记为1号,验证本文方法融合效果。该企业筛选出4个备选项目方案,通过4位评估人员进行项目评估,统计4位评估人员的评估结果,项目评估信息结果如表1所示。

表1 项目评估信息
将4位评估人评估结果通过多值直觉模糊集可描述为:
用本文方法进行融合,融合结果表示为:
为测试大数据直觉模糊的信息安全融合的效率,以配电网监测信息为实验对象,实验样本信息集为3号,配电网的高压电线环境监测信息为样本信息,利用传感器每4s采集监测信息,统计监测目标的信息量,统计结果如表2所示。

表2 监测目标信息量
把表2的信息分别用本文方法、文献[4]和文献[5]方法进行融合,观察融合的时间变化,3种融合方法融合时间变化如图1所示。
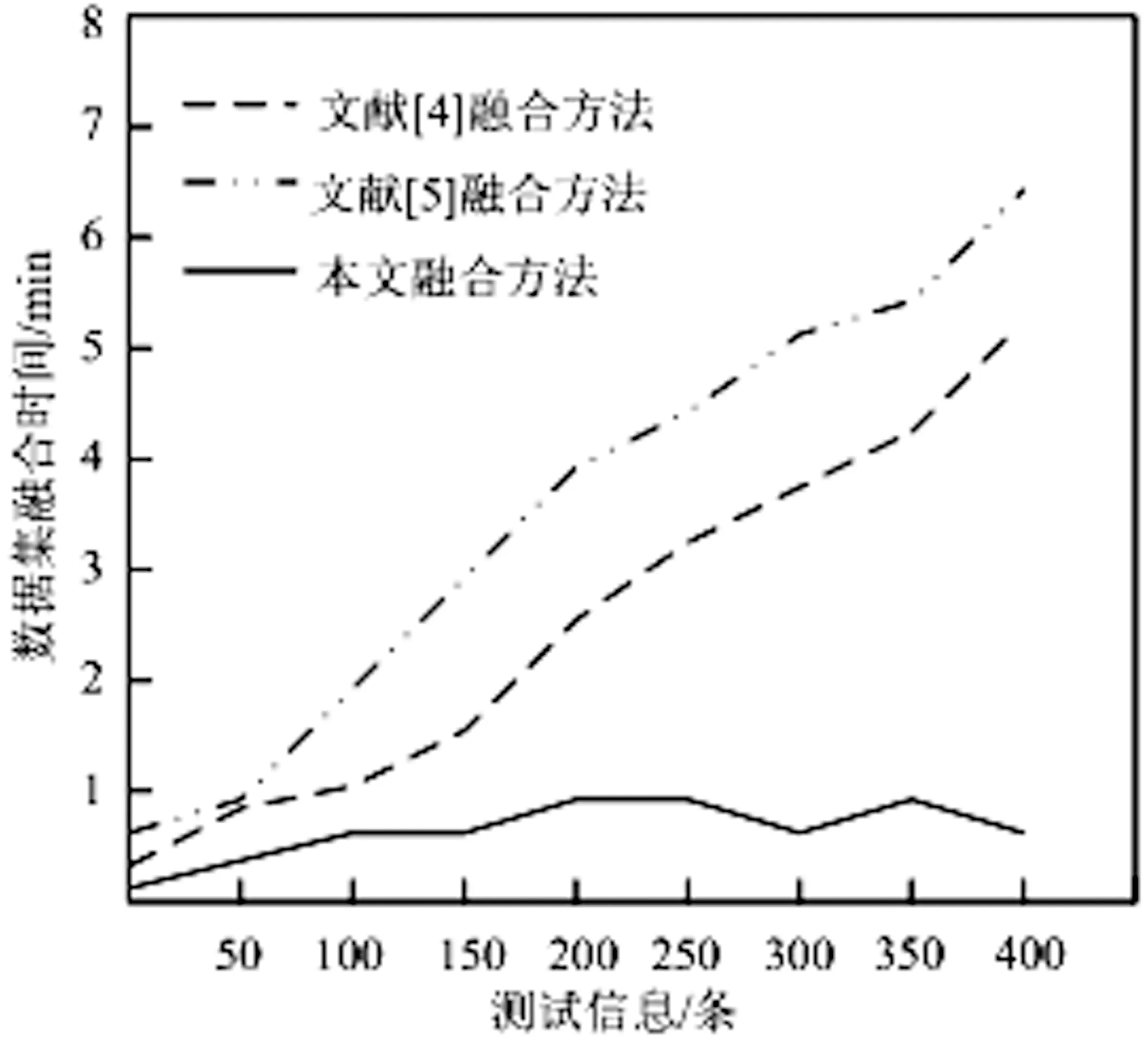
图1 3种融合方法融合时间变化图
由图1可知,在融合信息数量较少时,本文方法、文献[4]和文献[5]融合方法融合信息时间差距较小。随着融合的信息数量不断增加,文献[4]和文献[5]方法融合的耗费时间长,呈快速增长趋势,融合效率降低。本文方法随着测试信息的增加,融合时间保持在1min之内,融合时间不受融合信息的数量的影响。实验结果表明,本文方法可应用于大量信息的融合,且融合速度快,效率高。
为测试本文方法融合后信息的有效性,统计表2利用本文方法、文献[4]和文献[5]方法融合后的有效监测信息的残差率,残差率统计结果如图2所示。

图2 3种融合方法残差率变化图
由图2可知,随着测试信息集的不断增加,本文融合方法的信息残差率均比文献[4]和文献[5]融合方法的残差率低。本文融合方法信息残差率在15%-30%区间缓慢增长,而文献[4]和文献[5]融合方法信息残差率在20%-60%区间快速增长,随着信息集的信息量增多,信息融合的比例降低,信息冗余度较高。实验结果表明本文融合方法可以降低信息的冗余度,更接近实际的有效信息值,减少资源耗损。
以该配电网的生产管理、电力营销、调度、用电信息、自动化及电网监测系统的信息集为实验对象,验证本文方法信息融合各系统节点电压及功率的效果,配电网6个系统信息来源如表3所示。

表3 配电网信息集
用本文方法进行信息融合,为验证本文方法融合的效果,统计各系统节点电压及其功率信息融合后的信息,与原信息进行对比,观察融合后节点电压和功率信息的误差率,实验结果如图3所示。

图3 融合后各系统电压及功率信息的误差率
由图3可知,配电网管理系统的6个信息集用本文方法融合时,节点电压信息融合误差率保持在0.03%-0.04%之间,误差较小且稳定,节点功率误差变化也是如此,未有较大的误差率出现。实验结果表明,本文融合方法融合误差率0.03%-0.04%,误差率小,且融合误差率稳定性,无较大的信息融合误差值,为配电网的运行提供准确的数据支撑。
在配电网系统中运用本文融合方法,将配电网生产管理、电力营销、调度、用电及电网监测等信息进行融合,融合后的信息占比情况如图4所示。

图4 配电网信息融合占比图
如图4所示,配电网生产管理、电力营销、调度、用电、自动化及电网监测信息融合后占比分别为30%、3%、15%、2%、1%及49%,与实际配电网信息占比误差为0,实验结果表明本文方法融合的信息与实际信息情况一致,融合效果好,获取准确的配电网信息。
四、结论
本文研究大数据直觉模糊集的信息安全融合方法,基于直觉模糊集,以现有信息改动做到最小为安全融合目标,构建安全融合问题优化模型,将多值直觉模糊集隶属度和非隶属度的信息通过调节平均数信息融合方法进行融合。利用遗传算法求解优化融合问题。实验结果表明,调节平均数的信息融合方法不仅融合信息的效率高,融合后的信息接近实际的信息值,保障实际信息的安全,且融合稳定性高,误差率小。本实验主要以配电网的信息为实验对象,下一步应对多种类型的行业信息展开实验。
