基于AM-SAC的无人机自主空战决策
2023-10-07李曾琳李波白双霞孟波波
李曾琳, 李波*, 白双霞, 孟波波
(1.西北工业大学 电子信息学院, 陕西 西安 710129; 2.西安现代控制技术研究所, 陕西 西安 710065)
0 引言
随着现代战场网络化、信息化、智能化发展,空中作战的反应时间大幅缩短,作战行动空前激烈,并逐渐超出人类的应对能力[1],在此情况下,无人机凭借其机动性能强、隐身性好、作战效率高、无人员伤亡等优势,在现代空战中逐渐呈现出替代有人驾驶战斗机的趋势。机动决策是空战过程中的核心环节,决定了空战的效率与能力。但目前为止,大部分无人机仍未实现真正的自主,依然需要人为直接或间接协助来完成任务,严重限制了无人机在战场上的优势。因此,实现无人机的智能化是未来重要的研究方向。
目前,无人机的智能机动决策方法主要包括以微分对策法[2-3]、矩阵对策法[4-5]、专家系统法[6-9]、影响图法[10]为代表的传统算法,以及以遗传算法[11-14]、强化学习算法[15-16]为代表的智能算法。传统算法不具备自主学习能力,存在计算量大、依赖人为设置规则、灵活性差等缺陷;遗传算法和强化学习算法虽然具有一定的自主性,但前者在使用遗传编码描述无人机飞行决策的过程中,其编码规则和进化方式依然对操作者的主观经验有着较强的依赖性,而后者通常适用于包含有限马尔可夫决策过程的决策问题,在连续空间问题中会出现难以收敛的情况。因此,对于无人机自主机动决策这类复杂的非线性问题,本文考虑将兼具深度学习感知和探索能力以及强化学习决策能力的深度强化学习算法[17-19]应用到机动决策问题中。
在诸多深度强化学习算法中,非确定性策略算法Soft Actor Critic(SAC)凭借其强探索性、高适应性等特点而被广泛应用于智能决策领域[20-22]。此外,在传统深度强化学习中,奖励函数的组成及各项奖励因素在总奖励中所占权重大小完全依赖于人类经验,且在训练过程中的每一个时刻,各个奖励因素的权重都是固定的,即不同的状态变量对当前奖励的影响程度始终不变,无法体现不同时刻、不同态势下不同状态变量的相对重要性。
为了降低奖励函数对人类经验的依赖程度,同时提高训练速度,本文将SAC算法与注意力机制(AM)结合,提出AM-SAC算法,实现了1对1(1V1)模式下的自主机动决策,最后通过仿真实验来验证该算法的可行性与优越性。
1 无人机空战模型
在作战过程中,将无人机视为刚体模型,并假设无人机受到的重力加速度、大气密度和无人机质量始终不变,忽略地球公转、自转、地球曲率以及风力等对无人机运动的影响。针对1V1模式下的作战环境,将无人机的状态参量定义在北天东坐标系中,以空战区域中心O作为坐标原点,X轴指向正北方向,Y轴指向竖直向上方向,Z轴根据右手定则指向正东方向。
1.1 无人机运动模型
用[X,Y,Z]描述无人机坐标位置,v表示速度大小,速度向量v与OXZ平面所成夹角为俯仰角θ,其变化范围为[-90°,90°],速度向量在OXZ平面的投影与X轴正向之间的夹角为航向角φ,变化范围为[-180°,180°]。则3自由度无人机运动方程如式(1)、式(2)所示:
(1)
(2)
式中:Xt、Yt、Zt分别为无人机当前时刻的坐标;dT表示无人机训练过程中的积分步长;vt为当前时刻的速度;θt、φt分别为当前时刻的俯仰角和航向角;dv为无人机加速度大小;dθ表示俯仰角变化率;dφ表示航向角变化率。
根据上述运动方程,可通过对dv、dθ、dφ的值进行合理设定,完成无人机在三维空间中的一系列机动过程。
1.2 无人机近距空战模型
针对1V1模式下的作战环境,构建无人机近距空战模型如图1所示。图1中,D表示敌方无人机相对我方无人机的位置矢量,方向由我方无人机指向敌方无人机,qt为敌方无人机速度矢量vt与相对位置矢量D反方向的夹角,表示我方无人机相对敌方无人机的相对方位角,θm为我方无人机的俯仰角,φm为我方无人机的航向角,qm为我方无人机速度矢量vm与D的夹角,表示敌方无人机相对我方无人机的相对方位角;根据前述假设内容,无人机可被视为质点,用红蓝点分别表示我方无人机和敌方无人机。
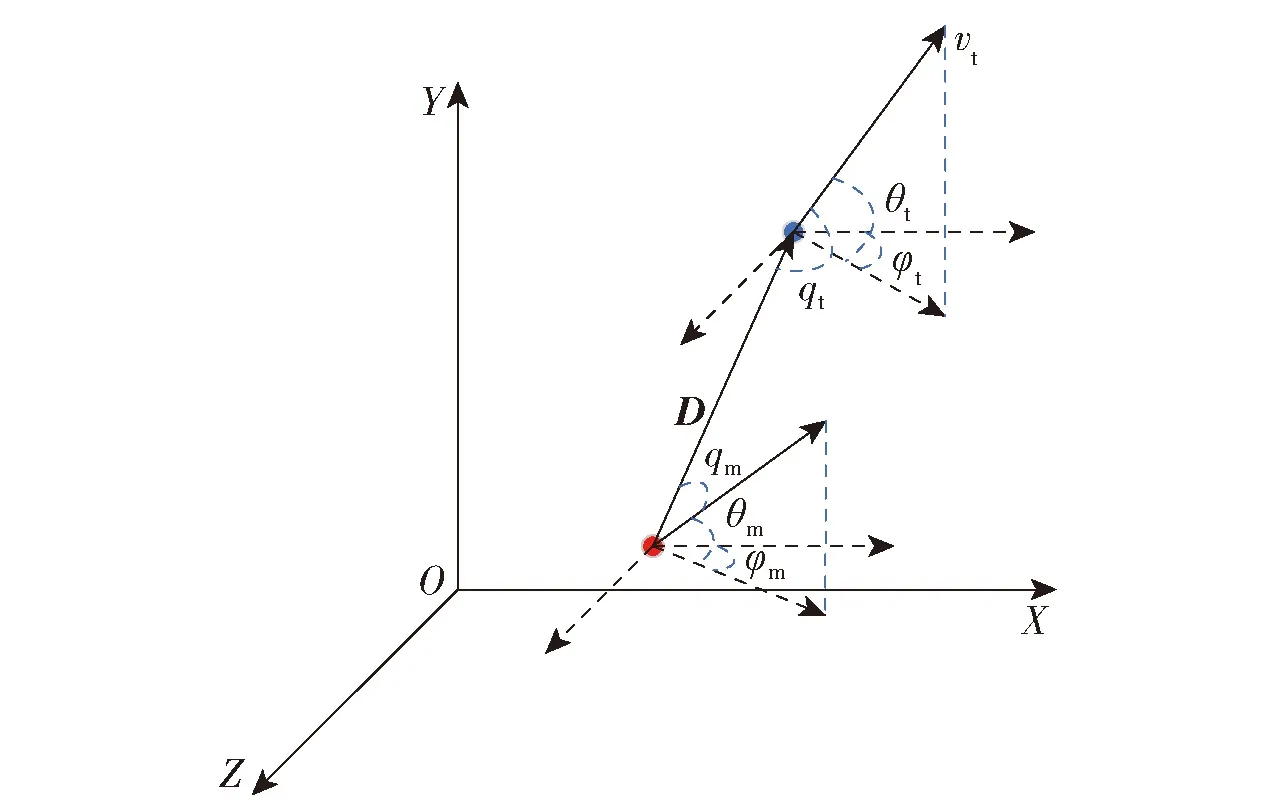
图1 空中对抗态势图
我方无人机的位置向量表示为Pm=(Xm,Ym,Zm),相应的速度向量表示为vm=(vmx,vmy,vmz);敌方无人机位置向量表示为Pt=(Xt,Yt,Zt),相应的速度向量表示为vt=(vtx,vty,vtz);d表示相对距离大小。D、d、qm和qt的计算公式分别如式(3)~式(6)所示:
D=(Xt-Xm,Yt-Ym,Zt-Zm)
(3)
(4)
(5)
(6)
1.3 攻击区模型
考虑到导弹性能对无人机作战能力的限制,选取以攻击机为中心的空空导弹攻击区来完成攻击区建模,如图2所示。图2中,dmax、dmin、qmax分别为空空导弹最大发射距离、最小发射距离和最大离轴发射角。

图2 导弹攻击区示意图
该攻击区仅由空空导弹最大发射距离dmax决定的远边界、最小发射距离dmin决定的近边界和导弹最大离轴发射角qmax决定的两条侧边界围成,与无人机速度、目标方位角等变量无关,且攻击区方位仅随无人机纵轴发生改变。此外,无人机从捕获目标到发射导弹,其间还需要经过获取目标信息、计算导弹发射诸元、加载数据等一系列过程。因此,要实现对目标的打击,需要同时满足距离、角度和时间条件,如式(7)所示:
(7)
式中:q为离轴发射角;tin为敌方无人机持续处于我方无人机攻击区内的时间;tshoot为我方无人机从捕获目标到发射导弹需要的时间。在实验中,不考虑导弹发射后的轨迹变化过程,因此当满足式(7)时,即认为我方无人机在当前时刻能够发射导弹,且该导弹能够将目标击毁,作战成功。
2 基于AM-SAC算法的无人机空战决策算法
2.1 问题描述
本文针对1V1作战模式,给定作战环境初始态势,其中目标无人机做随机运动,我方无人机根据不同时刻作战双方的相对态势信息自主生成决策,并执行机动动作,尽可能快速且持续地让敌方无人机落入我方无人机攻击区内。在此过程中,假设环境及态势信息完全可见,无人机通过不断与环境进行交互来获取相应奖励并更新状态,进而完成策略优化。
2.2 AM-SAC算法
机动决策是一种复杂的非线性问题,若训练过程中智能体对策略空间的探索不够全面,则会导致训练效果差甚至不收敛的情况。针对这一问题,相关学者提出了非确定性策略算法SAC[23],其最显著的特征是引入了最大熵原理。熵是一种衡量客观事物无序性的参数,熵值越大,事物越混乱,随机性越大,也就意味着智能体会进行更多的探索。SAC算法将奖励值与熵值共同作为优化目标,在最大化期望奖励的同时要求熵值最大化,通过增加策略熵的期望来增强智能体探索的能力,提升随机策略性能。
AM受启发于人类的选择性视觉注意力机制,当人们看待事物时,会选择性地把注意力集中在自己更关注的部分上。Query-Key-Value模型是目前最常用的一种AM模型,其结构如图3所示。图3中,WQ、WK、WV分别为3个可训练的参数矩阵,Q、K、V分别为输入X与WQ、WK、WV相乘后得到的矩阵。
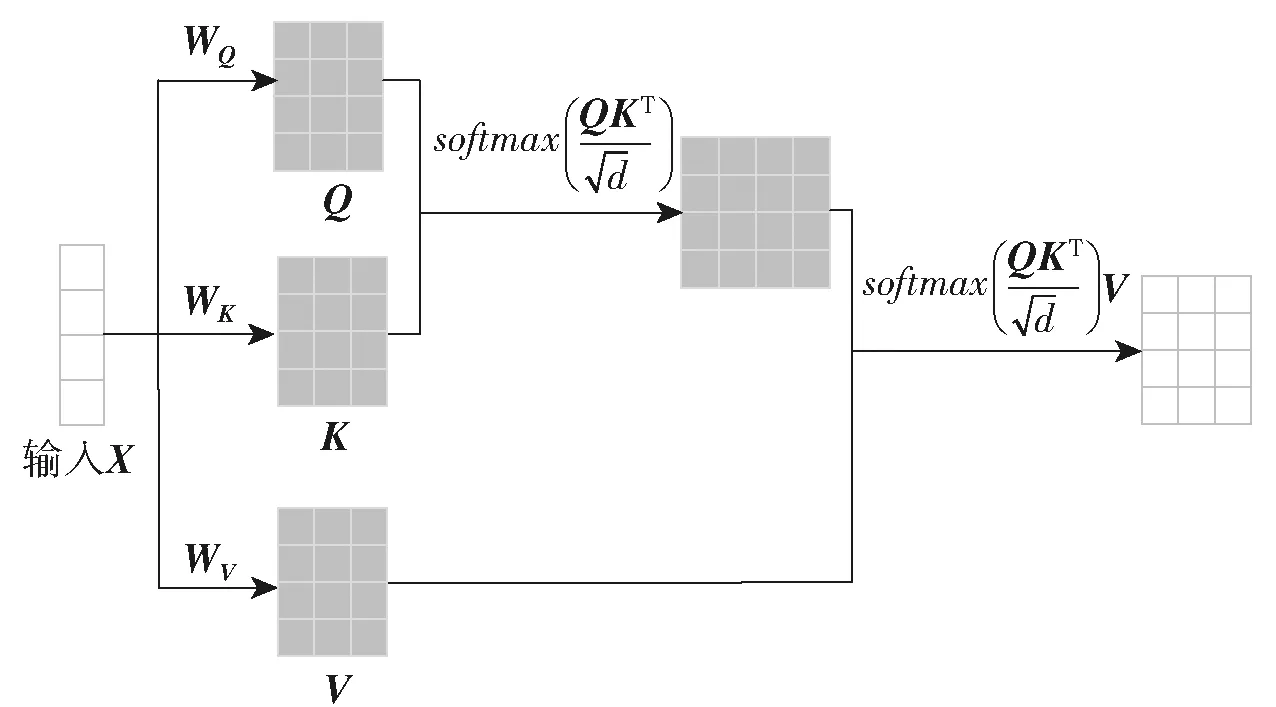
图3 Q、K、V模型示意图
AM-SAC算法将AM引入SAC算法,构建注意力网络,在训练过程中根据当前时刻的无人机状态及战场态势信息生成新的权重分布。算法结构如图4 所示。图4中,包含一个策略网络πθ(st,at)、两个Q网络Qφ1和Qφ2以及两个目标Q网络Qφ′1和Qφ′2(其中,st为当前时刻状态,at为当前策略下的动作值,θ、φ1、φ2、φ′1、φ′2表示对应网络的参数),w为更新后的权重分布,r为奖励值,st+1为下一时刻状态,Q1、Q2、Q′1、Q′2分别为两组Q网络和目标Q网络的状态-动作价值函数值。
AM-SAC算法包含一个注意力网络、一个策略网络和两组Q网络。其中,注意力网络根据当前状态信息输出奖励函数的权重分布w(st),两组目标Q网络计算不同的Q值,选取两个网络中最小的值来计算目标Q值,进而抑制对Q值的过高估计。策略网络πθ根据当前状态st输出两个值,分别定义为均值μ和方差σ,同时对标准正态分布采样得到噪声τ,二者共同决定动作at,如式(8)和式(9)所示:
μ,σ=πθ(st)
(8)
at=tanh(μ+τ·exp(σ))
(9)
在策略优化过程中,假设当前策略为π(·|st),则AM-SAC算法的累计奖励为
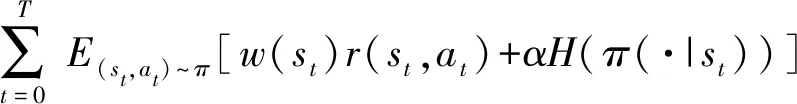
(10)
式中:T为一个回合内规定的最大训练步长;w(st)为当前时刻的权重分布;r(st,at)为当前奖励值;α为熵正则化系数,表示熵在奖励中所占比重,为了提高模型训练的稳定性,α采用自适应调整;H(π(·|st))为策略的熵,表示为
H(π(·|st))=E(-lgπ(·|st))
(11)
则AM-SAC算法的最优策略π*为
π*=argmaxJ(π)
(12)
AM-SAC算法中的状态-动作价值函数定义为
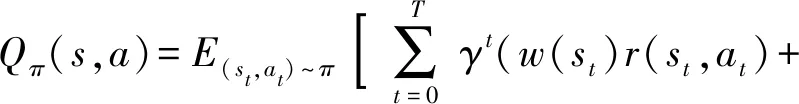
(13)
式中:γ为折扣因子。
参数更新时,策略网络通过最小化策略的KL散度实现,其损失函数为
(14)
式中:Zθ(st)为对数配分函数,用于归一化分布。
Q网络参数更新的损失函数为
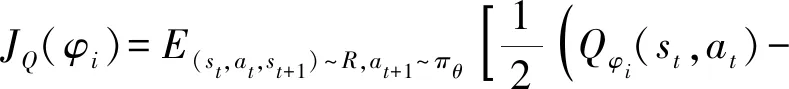
(15)
式中:R为经验池;Qφ′(st+1,at+1)=min(Q′1,Q′2)为目标Q值。
为了能够通过调整价值网络中奖励因子的权重从而使训练过程中的价值网络更好地贴近真实价值网络,将权重网络损失函数定义为
Jw(ω)=E(st,at)~π(lgπθ,ω(at|st)-Qθ,ω(st,at))
(16)
熵正则化系数α自适应调整损失函数为
J(α)=E[-αlgπt(at|πt)-αH0]
(17)
式中:H0为目标熵值。则AM-SAC算法具体步骤如图5所示。

图5 AM-SAC算法流程
图5中,episode为当前训练回合,m为最大训练回合数,step为当前回合内的训练步长。
2.3 算法设计
2.3.1 状态空间和动作空间
在空战过程中,我方无人机需要根据作战双方形成的相对态势信息来做出决策,因此状态空间需要同时包含敌我双方的状态信息。结合无人机近距空战模型,本文采用九元组来描述状态空间:
[X,Y,Z,v,θ,φ,d,qm,qt]
(18)
根据无人机运动方程,设置动作空间为
[dv,dθ,dφ]
(19)
2.3.2 奖励函数
奖励函数一定程度上反映了训练的目的,根据式(7),奖励函数从距离和相对方位角两方面进行设计。此外,为了避免稀疏奖励的问题同时保证训练速度与质量,每一项奖励均由连续奖励与稀疏奖励共同构成。距离奖励函数表示为
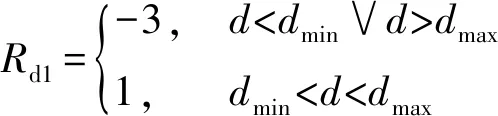
(20)
式中:Rd1为稀疏奖励;Rd2为连续奖励;dmin和dmax分别设置为1 km和3 km。
角度奖励包含qm和qt两项。敌方无人机相对我方无人机的相对方位角奖励为
Rqm1=1,qm
Rqm=Rqm1+Rqm2
(21)
式中:Rqm1为稀疏奖励;Rqm2为连续奖励。
我方无人机相对敌方无人机的相对方位角奖励为
Rqt1=-1,qt
Rqt=Rqt1+Rqt2
(22)
式中:Rqt1为稀疏奖励;Rqt2为连续奖励。
总奖励为
R=w1Rd+w2Rqm+w3Rqt
(23)
式中:wi(i∈{1,2,3})表示各奖励因素的权重,由注意力网络生成。
3 仿真结果及分析
共设计两个仿真实验,实验1将AM-SAC算法应用到给定初始态势的空战环境中,实现基于AM-SAC的智能空战决策任务,并与SAC算法进行对比,从奖励收敛速度、最大累计奖励值、作战轨迹以及各个状态量的变化过程等方面进行分析,进而得出两种算法的差异。实验2将算法应用到多个具有不同初始态势的环境中,对其在不同作战环境下的效果进行测试。实验中,敌方无人机做随机运动,我方无人机根据算法生成的决策完成机动。
3.1 单一环境测试及作战过程对比
3.1.1 实验参数
设计初始态势如表1所示的作战环境,用于决策实验。

表1 测试环境初始态势
作战双方初始位置、角度及速度等状态信息由表2给出。

表2 敌我双方初始化位置信息
3.1.2 实验结果
记录两种算法在训练过程中每一回合的累计奖励值,如图6所示。

图6 奖励曲线对比图
由图6可以看出:SAC算法和AM-SAC算法均能够收敛至对应的累计奖励最大值,但在此过程中,SAC算法在200步左右陷入局部最优,在1 500步左右经过探索跳出局部最优并收敛至最大值;AM-SAC算法在500步左右便收敛至最大值附近,且该最大奖励值略大于SAC算法,说明AM-SAC算法更加稳定,能更快地收敛至更优的策略。
对训练结果模型进行测试。图7展示了对抗过程中红蓝双方无人机的作战轨迹。

图7 作战轨迹对比图
初始时,敌我双方距离较远,敌方对我方相对方位角较大,由图7(a)中可以看出,为了使敌方无人机进入我方导弹攻击区内,两种算法均能够做出决策快速转变我方无人机航向,减小敌方对我方相对方位角,对敌机呈现尾后攻击的态势,之后缩短敌我双方相对距离,在水平面内达到满足导弹发射条件的攻击态势。
此外,作战双方之间具有初始高度差,为了提高导弹发射成功率,需要尽可能消除敌我之间的高度差异。图7(b)说明AM-SAC产生的策略能够让我方无人机更快地调整俯仰角,减小二者之间的高度差,并在之后与敌方无人机保持在同一高度水平上,确保敌方无人机持续处于无我方攻击区内。
图8所示为作战过程中两种算法下各个状态变量的变化曲线对比。
由图8可知:在作战开始后,为了快速调整我方无人机航向,敌我相对距离在前30步左右出现小幅度增加,我方对敌方相对方位角在前100步左右出现小幅度减小的情况;在100步之后,敌方对我方相对方位角基本稳定,此时敌我之间相对距离快速缩减,我方对敌方相对方位角也逐渐增大,使我方无人机处于最佳攻击状态;在200步以后,AM-SAC算法中敌方对我方相对方位角基本稳定在10°以内,SAC算法则在15°以内波动;在250步以后,相比于SAC算法,AM-SAC算法中我方对敌方相对方位角更快地增大。因此,AM-SAC的决策更加稳定,在实现空战攻击任务时更具有优势。
图8(d)和图8(e)描述了我方无人机作战过程中的姿态变化。在AM-SAC算法中,无人机的俯仰角变化范围为(-9°,3°),SAC算法中,无人机的俯仰角变化范围为(-13°,5°),且在作战后期,AM-SAC算法中的航向角波动明显小于SAC算法。结合作战轨迹,说明相较于SAC算法,AM-SAC算法能够以更小的机动稳定且快速地降低敌我双方之间的高度差异,并在完成姿态调整后朝着敌方无人机方向更稳定地飞行,更快实现作战目的。
由图8(f)可以看出,在作战前期和中期,两种算法都能够通过加速并保持在速度上限来快速缩小敌我之间的相对距离,在满足发射距离条件后,开始减速来避免双方距离太近,甚至小于导弹最小发射距离,从而对本机造成损失。但在后期,SAC算法中速度降低至0 m/s,不符合实际空战情况;AM-SAC则控制速度缓慢变化,将敌我相对距离始终保持在略大于最小发射距离(1 km)状态,更加合理且符合实际空战情况。
在作战过程中,AM-SAC算法中奖励函数的权重分布由注意力网络动态调整。记录训练过程中的权重分布变化如图9所示。

图9 权重分布变化图
权重分布初始值随机生成,在该环境下,敌方无人机随机运动过程中不会对我方无人机造成威胁,因此我方无人机无需进行过大机动来脱离敌方攻击区,我方对敌方相对方位角在奖励函数中所占权重减少;同时,我方无人机需要通过决策来缩小敌我之间的相对距离及敌方对我方的相对方位角,使敌机落入我方攻击区内,从而让我方无人机能够顺利发射导弹,获得作战胜利,因此相对距离权重和敌方对我方的相对方位角权重不断增大。
综上分析,SAC算法与AM-SAC算法均能在有限回合内完成训练,实现无人机空战过程的自主机动决策,并使我方无人机取得作战胜利。相较于SAC算法,AM-SAC算法生成的决策能够控制无人机更快地让战场态势满足导弹发射条件,实现作战任务,且无人机机动过程中稳定性和合理性更高,更加符合实际空战情况。同时,AM-SAC算法的收敛时间远早于SAC算法,极大地减少了训练所需时间。
3.2 多环境训练测试
为了测试AM-SAC算法能否在不同初始态势下实现智能空战决策任务,本文设计了4个不同的环境,其初始状态值如表3所示。
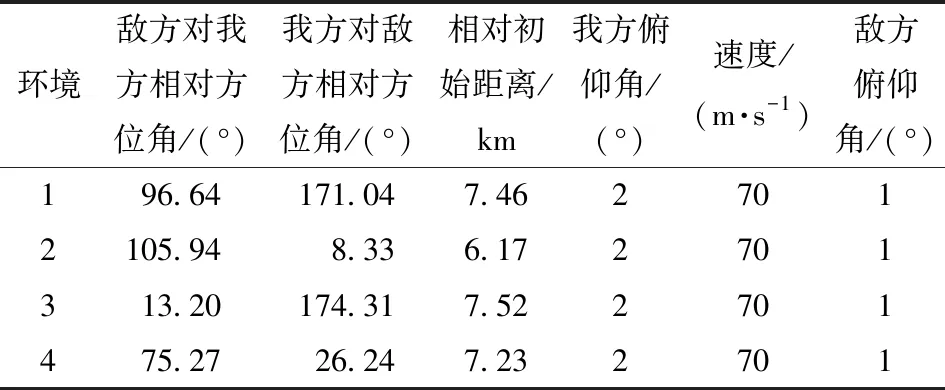
表3 多环境初始状态
环境1中敌方对我方相对方位角适中,我方对敌方相对方位角较大,整体呈现相互远离的状态;环境2中敌方对我方相对方位角较大,我方对敌方相对方位角较小,呈现出敌方无人机对我方无人机进行追击的状态;环境3中敌方对我方相对方位角较小,我方对敌方相对方位角较大,呈现为我方无人机对敌方无人机进行追击的状态;环境4中敌方对我方相对方位角适中,我方对敌方相对方位角较小,整体呈现相互接近的状态。在4个环境下分别进行实验,结果如表4所示。

表4 AM-SAC训练结果
从表4中可以看出,AM-SAC算法在4个作战环境下均能实现自主机动决策并获得作战胜利。环境2中由于敌我之间初始相对距离较小,比其他环境更早取得作战成功,但由于敌方对我方初始相对方位角较大,我方对敌方初始相对方位角较小,需要较大的机动才能改变态势,使我方无人机占据优势地位,因此奖励收敛慢于其他环境。图10更加直观地展示了整个作战过程。
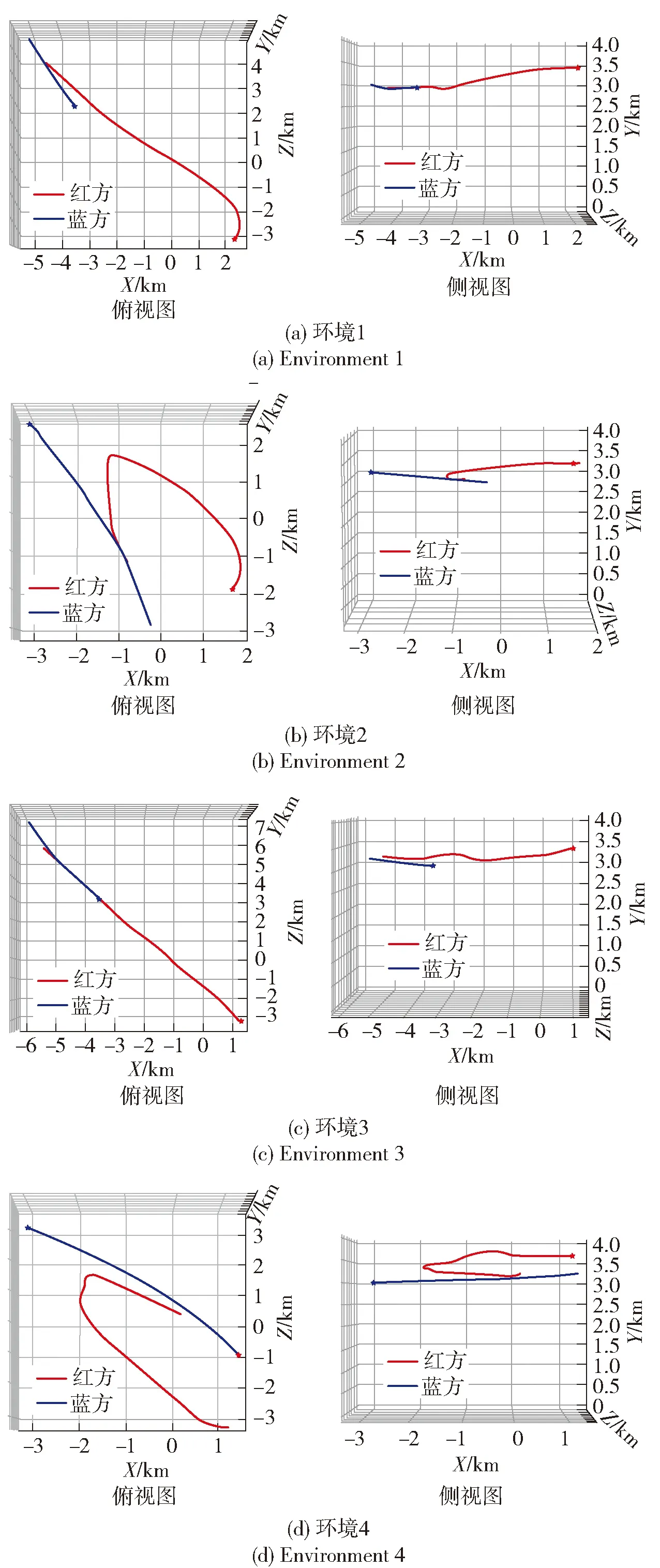
图10 作战轨迹示意图
由环境1和环境3的空战轨迹示意图可以看出,当我方无人机初始状态不处于敌方无人机攻击区内时,我方无人机受到威胁较小,仅需根据获取的敌方无人机位置信息改变航向角、调整自身姿态,然后朝敌方无人机方向机动;环境2和环境4中,我方无人机初始时受到敌方无人机威胁较大,因此需要先通过调整自身航向角,经过较大机动过程后,增大敌我之间相对距离和我方对敌方相对方位角,远离敌方无人机攻击区,确保自身安全,之后再向敌方无人机方向运动,减小敌我之间相对距离即敌方对我方相对方位角,使敌方无人机落入我方无人机攻击区内,完成作战任务。
4 结论
本文以1V1空战中的无人机智能决策为背景,贴合实际作战任务,建立了3自由度无人机运动模型、无人机近距空战模型和攻击区模型。在传统深度强化学习的基础上引入AM的概念,提出了基于AM-SAC算法的无人机智能空战决策方法。该方法根据当前的空战态势对奖励函数中各个奖励因素的权重值进行实时调整,并设计了两组实验进行测试和对比。得到主要结论如下:
1)相较于SAC算法,AM-SAC算法能够使无人机更快地占据作战优势,同时能够增强决策过程的机动稳定性,使无人机机动过程更加合理,更符合实际空战情况,体现了算法的可行性和优越性。
2)基于AM-SAC的智能空战决策算法在优势态势下能够快速实现对敌机的打击任务,在劣势态势下则能够及时调整自身姿态改变航向,充分保证本机安全的同时对敌机进行攻击,说明该算法适用于多种不同初始态势下的作战环境。
