基于YOLOv5的增强多尺度目标检测方法
2023-10-07惠康华杨卫刘浩翰张智郑锦百晓
惠康华, 杨卫, 刘浩翰, 张智*, 郑锦, 百晓
(1.中国民航大学 计算机科学与技术学院, 天津 300300; 2.北京航空航天大学 计算机学院, 北京 100191)
0 引言
目标检测旨在判别当前输入图像中目标的位置及目标所属类别,一直以来都是计算机视觉领域的热门研究方向之一,被广泛应用在军事[1-2]、交通、航空航天、工业、自动驾驶等领域。Viola等[3]通过采用滑动窗口的方式检查目标是否存在窗口之中,在检测器中使用积分图、AdaBoost以及级联结构,获得了较好的检测效果。Dalal等[4]为平衡特征不变性和非线性,在均匀间隔单元的密集网格上计算重叠的局部对比度归一化,实现在目标局部变形和受光照影响下的检测稳定性。Felzenszwalb等[5]针对检测速度慢、物体形变敏感的问题,提出DMP(Dynamic Movement Primitives)算法,通过硬负挖掘、边框回归和上下文启动等技术,在PASCAL VOC-07数据集上mAP达到33.7%。以上基于手工设计特征的传统方法在早期的目标检测中至关重要,但随着数据规模的增长和检测场景的复杂化,所提取到的特征信息难以满足精度需求。
2012年AlexNet[6]在图像识别领域取得巨大成功,如何将卷积神经网络(CNN)引入目标检测领域中成为重要的研究内容。2014年,Girshick等[7]提出RCNN算法,首次将CNN应用到目标检测领域,在PASCAL VOC-07数据集上mAP达到58.5%,检测效果远超传统算法。在此基础上,学者们提出SPPNet[8]、Fast RCNN[9]、Faster RCNN[10]等2阶段检测算法。相较于传统算法,卷积网络的方式能够提取到更加丰富的图像特征信息,自主生成预设多尺度锚框的方式也更有利于模型捕捉目标,精度和速度都获得大幅度提升,但两阶段的图像处理方式仍是一个较耗时的工作,难以满足当下检测实时性要求。
2016年,Redmon等[11]提出单阶段检测模型YOLOv1,直接将图像输入模型进行特征提取,并在输出特征图上应用初始锚框捕捉目标,最后输出检测结果,形成统一的端到端模型,达到实时检测的要求。此后,单阶段检测模型开始成为学者们的热点研究内容。RetinaNet[12]针对小目标物体难以检测的问题,提出特征金字塔结构,将不同阶段特征图进行特征融合,增强多尺度表征能力,并在不同尺度特征图上分别进行物体的检测,有效提升了小目标的检测精度。CornerNet[13]将目标检测分为图像分类和目标定位两个子任务,通过网络分支实现高效准确的目标检测,解决了遮挡和多目标问题。FCOS[14]将目标检测视为回归问题,使用全卷积网络,在特征图上预测每个像素点是否属于目标和边界框位置,实现了高效训练并获得了较好的检测性能。Swin Transformer将卷积模块替换为基于self-attention的swin block,实现更快地捕捉大量数据中的关键信息,从而提高模型泛化能力,获得较好的检测效果[15]。FGKD提出一种新的目标检测模型压缩方法,提取全局和关注区域的特征信息,并使用蒸馏技术传递给小型网络,既保持了模型检测精度又显著降低了模型大小[16]。
随着特征提取网络及目标框回归工作的不断优化改进,衍生出了SSD[17]、YOLO[18-20]等一系列优秀的单阶段检测模型。其中YOLOv5为当前使用最广泛也是效果最好的目标检测模型之一。但检测过程中,YOLOv5初始锚框的不同会使得模型整体检测性能差距较大,并且在检测复杂场景下的多尺度目标时由于缺少丰富的多尺度特征信息,存在错检或漏检现象。为解决上述问题,本文基于YOLOv5提出一种增强多尺度目标检测模型:
1)多尺度自适应锚框初始化。通过Kmeans++聚类算法,获得适应当前检测场景的多尺度初始锚框,使网络更容易捕捉到不同尺度目标,有利于目标边界框的回归,提升模型检测精度。
2)增强多尺度C3结构(EM-C3)。在YOLOv5默认的C3结构基础上,增加多条不同尺度的并行卷积支路,在保留原有特征信息的同时,提取并融合多尺度的特征信息,增强模型的全局感知能力。
1 EM-YOLOv5模型
1.1 YOLOv5
YOLOv5针对差异化的硬件提供YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x共4个不同尺寸的模型,各模型仅在深度和宽度上有所不同,基本结构均由输入端、骨干网络、颈部和头部四部分组成。输入端通过自适应锚框计算、自适应图像缩放和Mosaic数据增强等策略对输入图像进行预处理;骨干网络通过Conv结构、C3结构对输入图像进行特征提取;颈部通过FPN模块和PAN模块进行特征的多尺度融合,实现不同尺度目标特征之间的信息传递;头部采用分类、目标框回归和置信度损失进行损失计算,并完成目标框的预测及调整。
1.2 EM-YOLOv5结构
本文基于YOLOv5模型,在输入端,改进初始锚框生成策略,使用Kmeans++聚类算法,获取适应当前检测场景下的多尺度初始化锚框,增强模型对多尺度目标的捕捉能力;在Bottleneck结构中增加多条不同尺度的并行卷积支路,获得更加丰富的多尺度特征信息,增强网络的全局感知能力。以上述改进策略为基础,提出改进的EM-YOLOv5模型。以EM-YOLOv5s为例,其网络结构如图1所示。

图1 增强多尺度YOLOv5s网络结构
1.3 多尺度自适应锚框初始化
目标检测算法中,锚框是算法预定义的多个不同长宽比的先验框。训练过程中,在初始锚框的基础上输出预测框,进而与Ground Truth比较,计算损失并反向更新锚框,迭代网络参数。
检测过程中,不同层次特征图包含不同的图像特征,浅层的特征图包含丰富的初级语义信息,对位置信息敏感,有助于小尺度目标的检测。深层的特征图包含图像的高级语义信息,侧重于表达图像的复杂特征,对位置信息不敏感,适合大尺度目标的检测。基于上述特性,通常在浅层特征图上预设小尺度锚框,在深层特征图上预设大尺度锚框,使得网络更容易匹配不同尺度目标。
此外,在复杂多尺度检测场景下,存在初始锚框包含目标不全或包含噪声的现象,增加了模型检测难度。如图2(a)所示,马的初始锚框大于目标尺度,并且人也包含在其中,增加了特征噪声信息,不仅增大了目标分类难度,而且干扰目标框回归。在图2(b)中,马的初始锚框小于目标尺度,特征信息丢失严重,模型难以较好地完成检测任务。在图2(c)中,初始锚框框定多个目标,模型很难区分检测目标,容易引起漏检。同时,由于大尺度目标分辨率大,对锚框偏移感知较弱。而小目标分辨率较小,对位置信息敏感,锚框偏移较小的幅度,对小目标检测影响都是巨大的。

图2 初始锚框设定
综上所述,为检测目标提供更匹配的锚框,对模型检测性能的提升具有重要意义。
YOLOv5模型在训练开始前,将数据集通过Kmeans聚类算法随机生成n个原始锚框,然后计算各个锚框之间的距离,迭代生成数据集的初始锚框,并以此为输入,最终生成模型的预测框。
王千等[21]指出,在Kmeans算法中,采用随机初始化聚类中心的方式,容易在迭代优化聚类中心的过程中造成局部最优解的情况。不同的聚类中心可能导致完全不同的聚类结果,造成生成的初始锚框难以合理匹配目标大小,增加目标框回归的难度,最终导致模型收敛不理想。伍育红[22]指出Kmeans聚类算法对于噪声和异常点敏感,使锚框在学习过程中向非目标方向靠拢,生成的锚框匹配程度不高。
Kmeans算法是随机选择K个初始聚类中心,当随机聚类中心接近且聚类中心陷入局部最优解时,多个锚框只适应局部数据分布,导致聚类锚框不适应整体数据分布,最终影响模型检测性能。Kmeans++聚类算法则是生成一个聚类中心,其他聚类中心以此为基础计算得出。通过在初始化时就拉大各聚类中心之间的距离,一定程度上缓解了上述存在的问题。其具体算法流程如下。
输入:一组P={P1,P2,…,Pk,…,Pn}⊆Rd点集合,k为聚类中心编号,n为数据集样本数量,d为维度。
步骤1从数据集中随机选取1个样本点作为初始聚类中心C1。
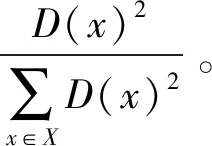
步骤3重复步骤2,选出K个初始聚类中心。
步骤4针对数据集中的每个样本pk,计算它到K个聚类中心的距离,并将其分到距离最小的聚类中心所对应的类中。

步骤6重复步骤4和步骤5,直到聚类中心的位置不再变化。
输出:K个聚类中心{C1,…,CK}。
Kmeans++聚类算法,在各步骤下最大程度地保证了初始锚框之间的差距,生成多尺度锚框,不仅减少了锚框之间的性能冗余,也有利于多尺度目标的捕捉,降低模型出现漏检现象概率。文献[23-24]验证了Kmeans++在其他目标检测模型下的适配性,通过合理的初始锚框选择提升了模型检测性能。
基于上述考虑,在获取初始化锚框时,为保证初始化聚类中心符合数据集的整体分布,使聚类结果更适应多尺度的检测需求,本文采用Kmeans++聚类算法来获取多尺度初始化锚框。
1.4 增强多尺度C3结构
1.4.1 C3模块
Conv作为复合卷积模块,是YOLOv5模型中的基本组成结构,如图3所示,由一个卷积层、BN层以及激活函数层组成,用于提取图像特征信息。Bottleneck是残差模块,通过多次堆叠集成在C3模块中,其结构如图4所示,用于获取更高级含义的图像语义特征信息。其中,图4(a)结构使用在骨干网络中,图4(b)使用在颈部网络中。

图3 Conv结构
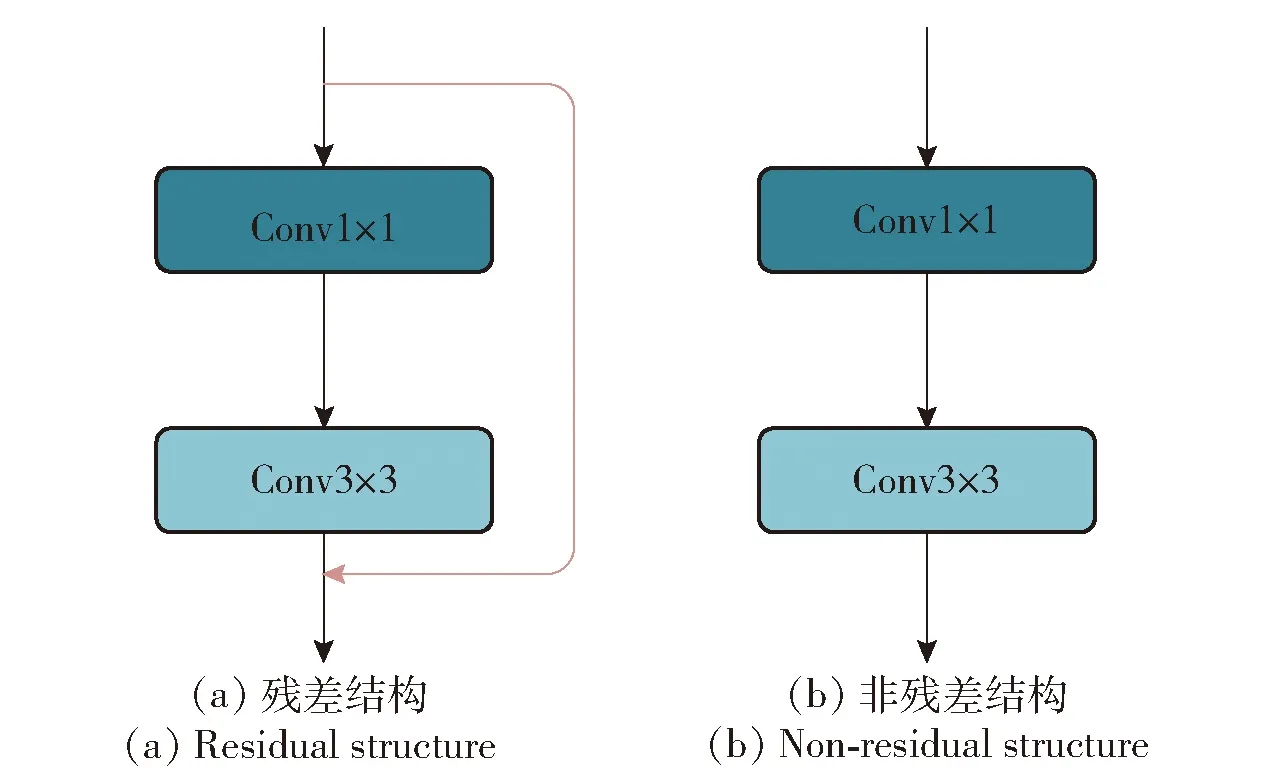
图4 Bottleneck结构
C3是骨干网络的核心模块,由2个并联的分支组成,结构如图5所示。在第1个分支中输入特征图先经过一个Conv模块,然后通过堆叠的n个Bottleneck模块,提取高级语义信息。第2个分支通过1个Conv层后与第1个分支的输出拼接之后,再通过1个Conv层进行特征融合后输出。
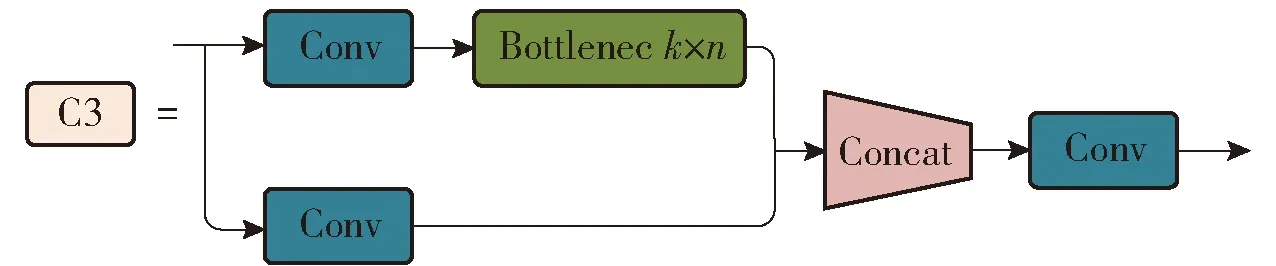
图5 C3结构
1.4.2 增强多尺度C3模块
借鉴VGG[25]、GoogleNet[26]和CSPNet[27]的设计思想,C3模块将输入信息分别通过两条支路,一条支路通过堆叠的Bottleneck结构,获得高级的语义特征信息,另一条支路是过Conv模块的shortcut连接,保留原始的特征信息。最后,两条并行卷积支路进行特征融合,强化特征信息。因此提取特征的核心在于Bottleneck结构的设计。
要提升模型的特征提取能力,通常采用更深的网络结构或更多的卷积核加深网络宽度以获得更丰富且复杂的特征信息。为增强模型的特征信息提取能力,本文在Bottleneck结构的基础上,横向增加3个Conv卷积模块,用于提升模型对高级语义特征的提取能力。为增强模型对多尺度特征的感知能力,3个Conv模块的卷积核大小分别设置为3×3、5×5、7×7且以并行的方式进行各尺度特征的提取。最后,3条支路与模块输入的恒等映射和第1个3×3卷积的恒等映射进行特征的深度融合,其结构称为增强多尺度Bottleneck(EM-Bottleneck)。EM-Bottleneck不仅增加了多尺度特征信息,残差结构也最大程度保留原始特征信息,减少浅层特征丢失,提升了模型的特征提取能力。如图6所示,在backbone中同时存在shortcut 1和shortcut 2分支,称之为EM-Bottleneck_1;在neck中,只存在shortcut 2分支,称之为EM-Bottleneck_2。
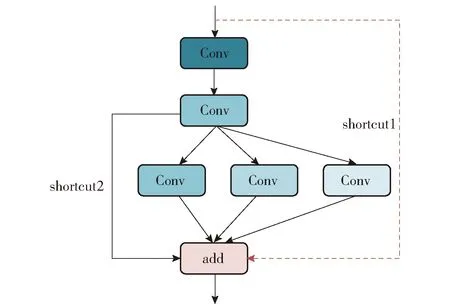
图6 增强多尺度Bottleneck结构
在原有的C3结构中,一条支路通过堆叠多个Bottleneck进行特征提取,将改进的EM-Bottleneck结构替换原有的Bottleneck结构得到改进的EM-C3_m_n模块。当m=1时,EM-Bottleneck选用EM-Bottleneck_1,反之选用EM-Bottleneck_2,n表示EM-Bottleneck串行堆叠次数,结构如图7所示。
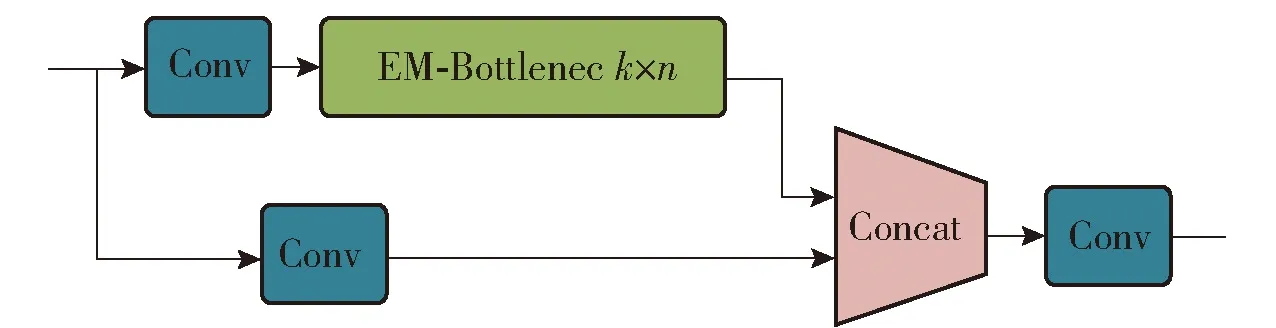
图7 EM-C3结构
2 实验结果与分析
2.1 实验数据集介绍
本文实验使用VOC2012[28]、COCO[29]和VisDrone2019[30](VisDrone)3个通用的目标检测数据集对模型进行性能验证。VOC2012数据集有20个类别,训练集选用VOC2012的train+val部分,共有16 551张图像,测试集选用VOC2007的test部分,包含4 952张图像。COCO2017数据集包含80个类别共20万张图像,目标标注超过50万个,是目标检测领域最广泛公开的目标检测数据集。VisDrone2019包含10个类别,训练集有19 471张图像,验证集共1 648张图像,测试集中包含4 833张图像。VisDrone是一个无人机视角的大型数据集,共有260万个标注框,每张图像包含大量的小目标,考验模型的小目标检测能力。
2.2 实验环境
本文实验的操作系统为Ubuntu18.04.5,CPU型号为Intel(R) Xeon(R) Gold 6230 CPU@2.10 GHz,运行内存64GB,GPU型号NVIDIA Corporation GV100GL[Quadro GV100],显存大小为32 GB。模型基于Pytorch1.7.1深度学习框架实现,编程语言为Python,使用CUDA11.4进行GPU加速。
本文算法使用的初始化训练参数设定为:batch_size大小为32,输入图像尺寸为640×640,采用随机梯度下降优化器SGD,并使用余弦学习率衰减策略来训练网络,初始学习率为0.01,权重衰减率为0.000 5,动量因子设置为0.937。
2.3 评价指标
本文使用以下指标作为评价标准:1)mAP@0.5,表示模型在IOU阈值为0.5时的平均精度;2)mAP@0.5∶0.95,表示IOU阈值从0.5到0.95,步长为0.05时各个AP的平均值,其中AP值是指P-R曲线上的精度值沿召回率从0到1变化时的平均值;3)精度P,表示模型预测的所有目标中预测正确的比例,也称为查准率;4)召回率R,表示在所有真实目标中预测正确的目标比例,也称为查全率;5)推理时间表示模型检测一张图像所需要的时间。相关计算公式如下:
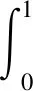
(1)
(2)
(3)
式中:P(R)表示P-R曲线,即在不同IOU阈值下计算精度和召回率的值,并在二维坐标系上得到的曲线;TP表示样本的真实类别是正例,并且模型预测的结果也是正例;FP表示样本的真实类别是负例,但是模型将其预测为正例,预测错误;AD表示所有的预测框;FN表示样本的真实类别是正例,但是模型预测为负;AGT表示所有的先验框。
2.4 实验结果和分析
2.4.1 多尺度自适应锚框实验及分析
为验证相比于其他聚类算法,采用Kmeans++算法获取的初始化锚框更有助于模型提升检测性能,本文在3个通用目标检测数据集上做了对比实验,其结果如表1所示。
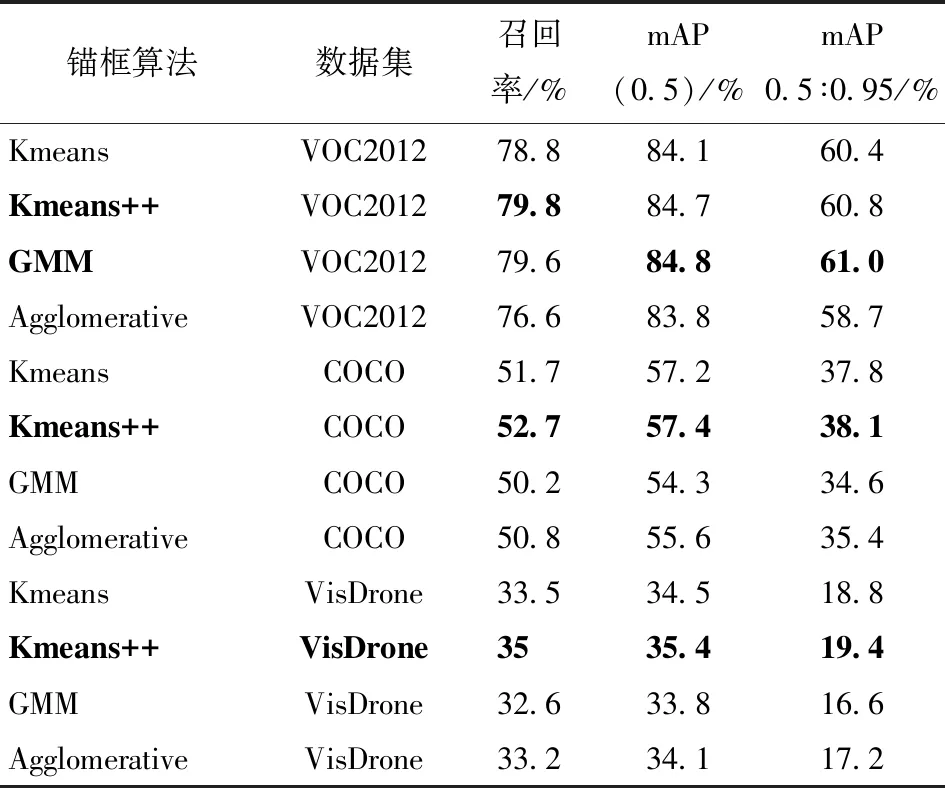
表1 初始锚框对比
由表1可以看出,采用Kmeans++算法得到的初始锚框在3个数据集中的各项评价指标相较Kmeans算法均有提升。在VOC和COCO数据集中,检测目标通常为常规尺度,对初始锚框的偏移感知较弱,检测性能略有提升。值得注意的是,在VisDrone小目标数据集上的效果提升较为显著。由于小目标易受环境干扰,锚框偏移较小幅度对其影响都是巨大的,如果在初始锚框的匹配上就存在位置偏移,则将对检测产生消极影响。Kmeans++通过改变初始聚类中心的生成方式,增大初始锚框之间差距,使锚框更适应整体数据分布,得到了匹配度更好的多尺度锚框,进而提升了模型的检测性能。
进一步地,为探究聚类算法生成的初始锚框与目标尺度的匹配程度。本文在现有Kmeans和Kmeans++算法基础上,增加了两个常用、易实现的Agglomerative层次聚类算法[31]和高斯混合模型(GMM)聚类算法[32]。并在VOC2012数据集上进行聚类,计算生成不同数量锚框下的Avg IOU值,结果如图8所示。
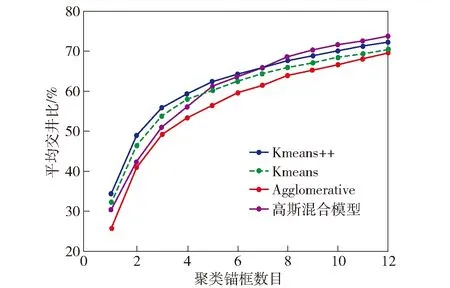
图8 4种算法在VOC数据集上的聚类结果
其中Avg IOU用来反映聚类锚框和目标锚框的之间的匹配程度,值越大,说明聚类得到的锚框和目标锚框在尺度上的匹配效果越好。
由图8可以看出,Kmeans++算法与GMM算法整体检测性能相当,好于Kmeans和Agglomerative算法。但GMM聚类对初始参数的依赖性很高,需要根据数据集分布,设定初始高斯分布参数,且在不同数据集下性能不稳定、计算复杂度高。由表1可知,相较于Kmeans++,GMM在VOC2012数据集上mAP@0.5提升0.1%,但在VisDrone上mAP@0.5下降1.6%。综合稳定性、计算复杂度、初始参数设置等因素,Kmeans++更适用于多尺度检测场景。
Agglomerative基于贪心策略进行聚类,VOC数据集中存在极大或极小尺度的离群点,易导致算法陷入局部最优解。由于距离策略的选择,也可能出现大簇合并小簇,而不是合并较近的点。使得Agglomerative算法没有完全释放性能,在计算复杂度增大同时,检测性能更差。
综上所述,从数据分布的适配程度、计算复杂度、初始参数多个维度进行考虑,本文选择Kmeans++算法用于初始锚框的生成。
2.4.2 增强多尺度C3结构实验及分析
为验证增强多尺度C3结构与模型的契合度,设计两组实验。第1组实验将YOLOv5s模型 backbone中C3结构替换为EM-C3结构,测试其在不同数据集上的检测性能,结果如表2所示。
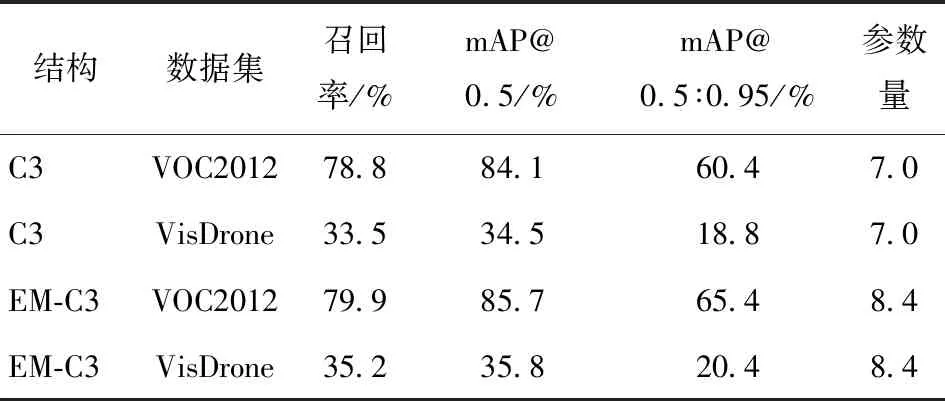
表2 EM-C3与C3结构在不同数据集上对比结果
C3表示在YOLOv5s中采用标准的C3模块,EM-C3表示在YOLOv5s中采用EM-C3模块。由表2 可知,采用优化后的EM-C3结构在VisDrone数据集性能略有提升,而在VOC2012数据集上检测精度提升显著,其中mAP@0.5∶0.95提升5%。其原因在于,EM-C3结构通过增加3×3、5×5和7×7共3条并行卷积支路分别提取图像的不同尺度特征。在EM-C3模块视角下,增加的多尺度特征都基于更大感受野,细节信息新增不明显。而从模型角度,浅层EM-C3为深层EM-C3提供了丰富的细节多尺度特征信息,且目标尺度越大,特征信息受益越多。
进一步地,针对YOLOv5s的C3结构和EM-C3结构,生成样例图像检测的热力图,改进前后的模型均检测出全部4个先验目标,如图9所示。在引入多条并行多尺度卷积支路后,常规尺度和大尺度的待检测目标,在类别预测准确率上均有提升。值得关注的是,在第1组热力图中,车的目标框中包含了人,而人的信息在检测中属于噪声。EM-C3经过多尺度特征信息融合,能更好地识别出不同目标特征之间差异。通过淡化非目标特征的方式,专注于当前目标的检测,使模型获得了更准确的目标类别预测概率和目标框。在第2组检测热力图中,右侧的人存在信息丢失。C3模型仅关注人腹部信息,EM-C3结构模型则利用多尺度特征信息向外扩展,得到人更全面的特征信息。与此同时,模型也获得窗户等在内的环境信息。但在特征融合中,通过多尺度目标特征之间的充分融合,获得了更强的目标信息表征,并间接降低了环境信息的影响。因此,模型获得更高的目标预测准确率且没有出现误检。在第3、4组热力图中,由于待检测目标位于图像前景,尺度较大,不受遮挡,信息较充分,模型在特征融合中,更有效地抑制了环境等冗余特征,使得关注点只在目标区域内有所扩大。
第2组实验将YOLOv5s、YOLOv5m、YOLOv5l3个模型backbone中的C3结构替换为EM-C3结构,在VOC2012数据集上验证其检测性能。表3为EM-C3与C3结构在不同规模模型上对比结果。
由表3可知,在不同规模模型下,采用EM-C3结构模型相比原模型检测性能均有不同程度的提升。其中YOLOv5s-EM_C3提升幅度明显,在评价指标mAP@0.5∶0.95上提升5个百分点。在计算资源受限且小目标多的场景下,由于小目标难以提取到具有鉴别力的特征且易聚集,但又不能盲目部署大模型,使得此类情形下检测难度加大。改进后的EM-YOLOv5s模型可以较好地适用于此检测场景。其原因在于,EM-C3通过增加多条不同尺度的并行卷积支路,在保留原有特征信息的同时,获得了更多不同尺度的特征信息。在经过特征融合之后,模型对图像信息的捕捉和理解也更好,能够分辨目标之间更细微的特征差异。一方面可以提升检测目标的预测概率,另外一方面也可以帮助区分不同目标特征差异,减少错检。检测精度上相比YOLOv5s提升较大,且新增参数量较少。同时,随着模型的增大,更多的卷积层数和卷积核个数会弥补并行支路带来的多尺度特征增强。
为验证模型的收敛能力,将日志数据加以处理,绘制YOLOv5s和EM-YOLOv5s模型loss曲线对比图。其中loss值为box_loss、obj_loss和cls_loss总损失之和,结果如图10所示,从中可见在引入EM-C3结构之后,函数收敛更快,损失值更小;与图9中模型改进前后热力图检测效果对比相对应,从数据和检测效果两个维度表明,在增加多条并行卷积支路后,更多尺度的特征信息,使得模型的关注点更多,感受野更大,从而提升了模型的检测能力。
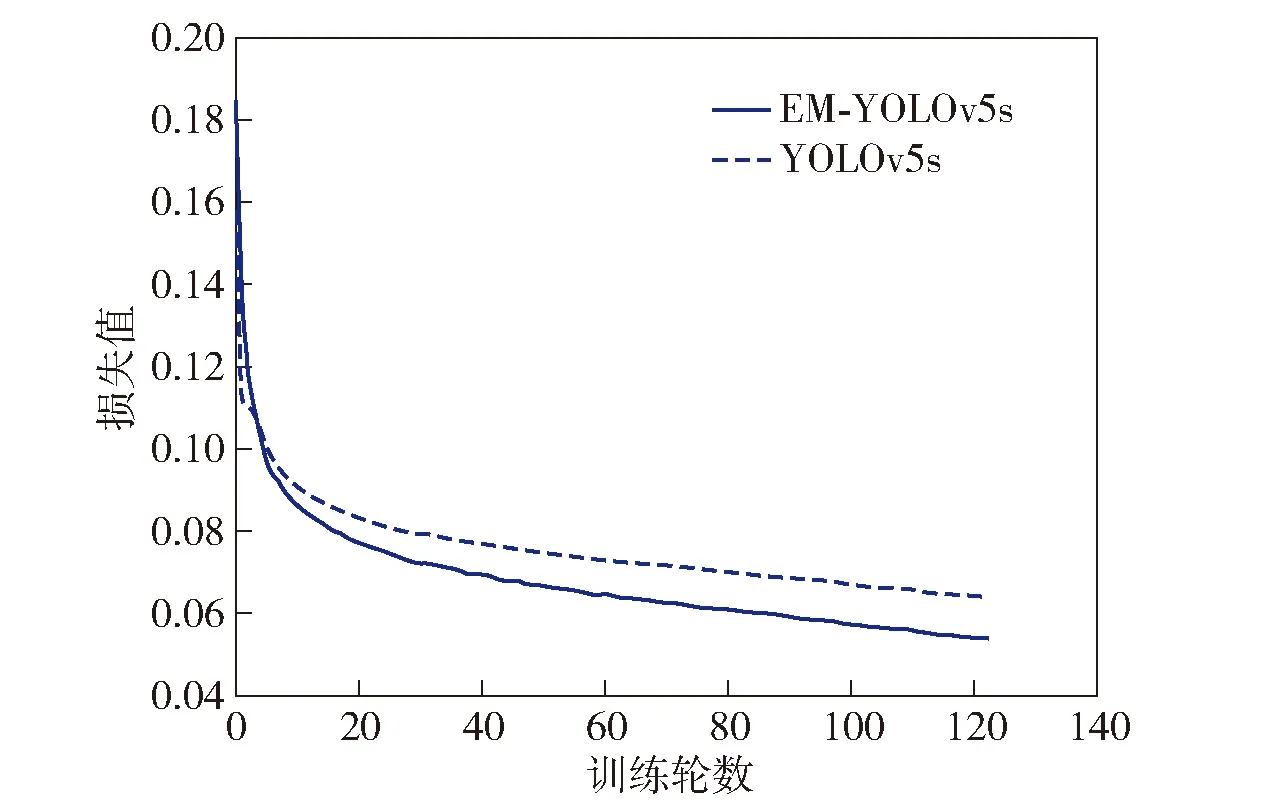
图10 Loss对比图
本文还将各模型数据在训练轮数和mAP@0.5维度上进行统计,结果如图11所示。由图11可见,改进后模型在第40个epoch时检测性能曲线开始趋于平缓,并且得益于多条不同尺度并行支路的设计,多个改进模型均在训练的相同阶段获得了相比原模型更丰富的特征信息,使得检测精度有所提升。
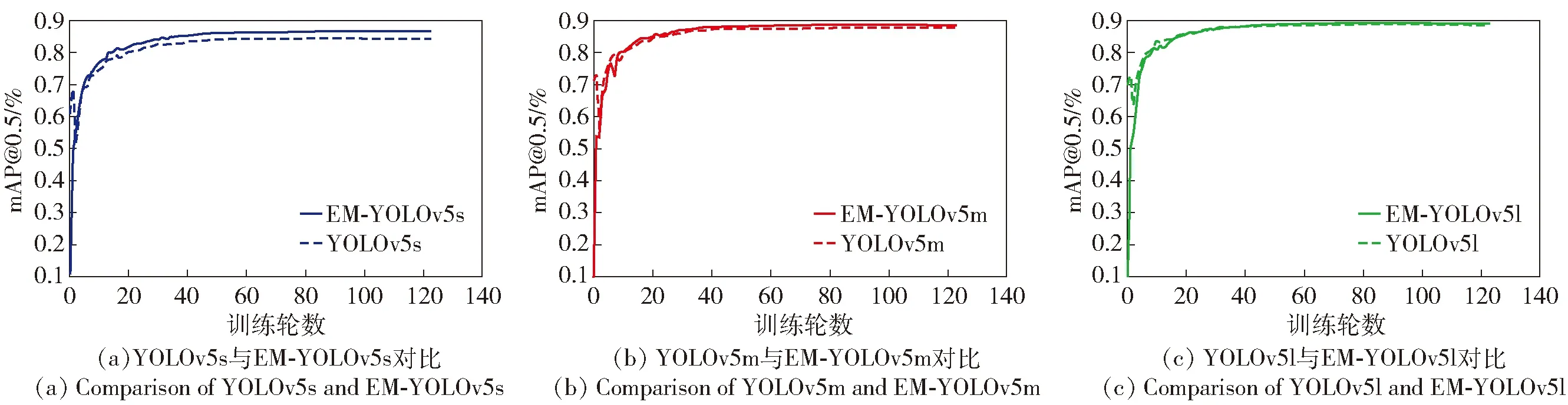
图11 不同规模模型检测性能对比图
2.4.3 EM-YOLOv5检测效果及分析
为直观地展示改进前后模型检测效果差异,本文用YOLOv5s模型与EM-YOLOv5s模型对VOC2012数据集中3组不同场景下的图像实例进行检测,实验结果如图12所示。
由图12可见:第1组图像中,YOLOv5s将昆虫错检为鸟类,而EM-YOLOv5s与图像先验信息一致;第2组图像在多目标的检测场景下,YOLOv5s模型漏检狗目标,EM-YOLOv5s则进行了准确预测和目标框定;第3组图像两个模型都检测出目标,但是在分类置信度上,EM-YOLOv5s表现更好。其原因在于,EM-YOLOv5s在经过多尺度特征融合之后,对图像的语义信息有了更深层次的理解。针对特征信息相似的目标,可以分辨目标之间的细微特征差异,降低模型错检概率,也能减少特征被视为属于同一物体的情况,防止出现漏检,并且对目标的位置及类别可以进行更加准确的判断。
2.4.4 与主流模型对比实验及分析
为验证EM-YOLOv5模型的有效性,在VOC2012数据集上,将其与主流的单阶段和两阶段目标检测算法进行对比实验,结果如表4所示。
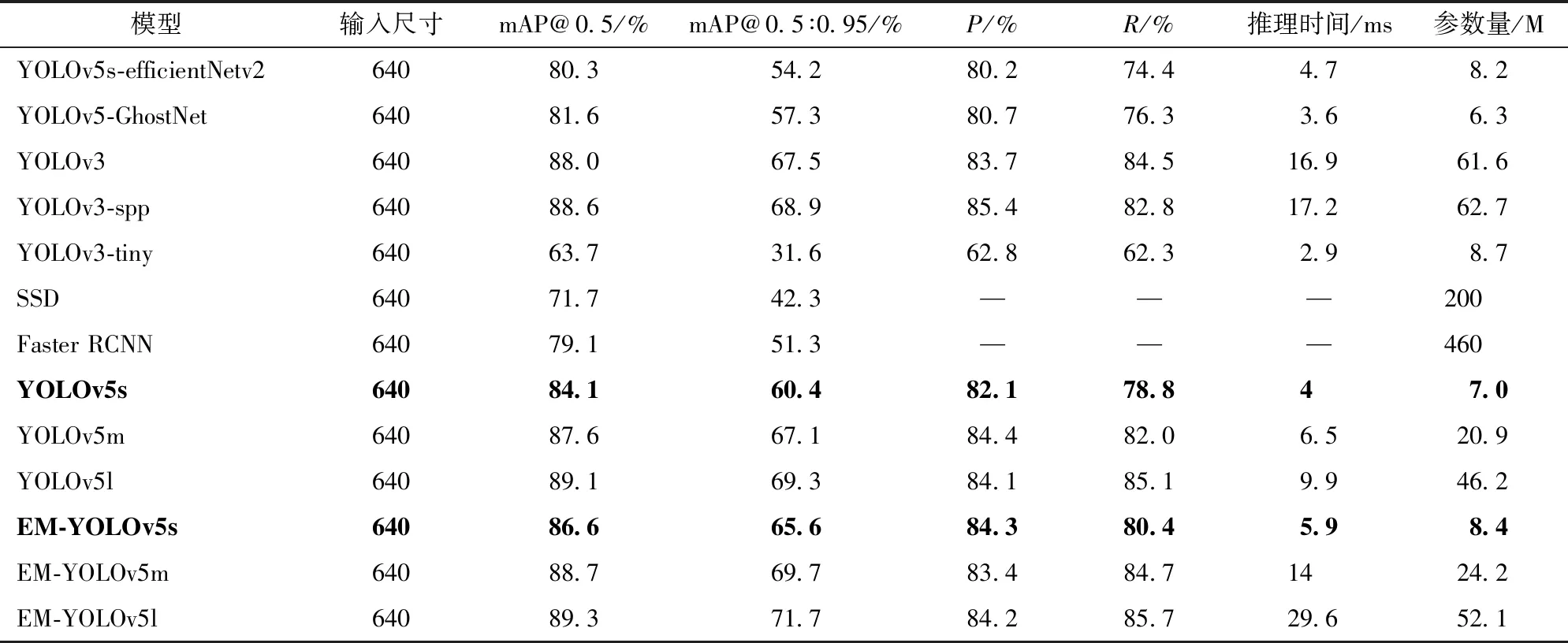
表4 EM-YOLOv5与主流检测模型对比实验
由表4可知:
1)EM-YOLOv5模型的检测性能比YOLOv5模型均有较大提升,且在小模型上提升效果更为明显。其中EM-YOLOv5s相比于YOLOv5s在模型评价指标mAP@0.5∶0.95上提高5.2%。对比YOLOv5s与EM-YOLOv5s、YOLOv5m与EM-YOLOv5m、YOLOv5l与EM-YOLOv5l模型,发现各模型在更严格的评价指标mAP@0.5∶0.95上的提升幅度要大于mAP@0.5。采用自适应锚框策略和EM-C3结构之后,各模型在合理的初始锚框和多尺度特征融合背景下,能更好地捕获不同尺度目标并提取丰富的多尺度语义信息,从而实现更准确的目标框回归和分类任务。因此,在面对更加严格的评价指标时,模型仍然具有出色的检测性能。由于多条并行卷积支路的引入,模型的复杂度也有所提升,在检测时间上EM-YOLOv5s相较YOLOv5s增加1.9 ms,但5.9 ms的检测时间在众多模型中仍然处于较好的水平。
2)在对比轻量化模型方面,将YOLOv5的初始backbone结构替换为轻量化的EfficientNetV2[33]、GhostNet[34]获得了称之为YOLOv5-EfficientNetV2、YOLOv5-GhostNet的检测模型。二者在检测速度上均优于EM-YOLOv5s,但在检测性能上仍然存在较大差距,其中mAP@0.5∶0.95最大相差11.4个百分点,较差的检测性能,使其难以应对较高精度要求的检测场景。
3)将EM-YOLOv5模型与之前的主流模型如YOLOv3、YOLOv3-spp、YOLOv3-tiny、SSD和Faster RCNN进行对比。其中,YOLOv3-tiny获得了最佳的2.9 ms检测时间,但mAP@0.5∶0.95为31.6%的检测性能与其余模型差距巨大,难以应对精度要求较高的检测需求。YOLOv3-spp为其余主流模型中检测性能最好,超过EM-YOLOv5s,但相比于EM-YOLOv5m,精度和速度上均有差距。
相比于2阶段检测模型,单阶段检测模型在同时兼顾检测精度和实时性上更具优势。本文在YOLOv5模型的基础上,通过自适应锚框和增强多尺度C3结构的改进,检测精度得到了进一步的提高。总体而言,EM-YOLOv5是一种适用于目标尺度不一检测场景的高性能检测模型。
3 结论
本文在YOLOv5的基础上提出一种增强多尺度的目标检测算法,解决了原模型初始锚框难以匹配检测目标及多尺度检测能力不强的问题。
实验结果表明,本文提出的EM-YOLOv5模型相比于YOLOv5和其他主流目标检测模型在检测精度方面有较大提升,适合对精度要求较高的多尺度的检测场景。相较轻量化的目标检测模型,本文在速度方面仍有继续提升的空间,这也是后续的研究方向之一。
