融入翻译记忆库的法律领域神经机器翻译方法*
2023-10-07曾文颢张勇丙余正涛
曾文颢,张勇丙,余正涛,赖 华
(1.昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2.昆明理工大学 云南省人工智能重点实验室,云南 昆明 650500)
0 引言
近年来,随着深度学习的发展,神经机器翻译(NMT)在大量翻译任务上取得了巨大成功[1],面向法律领域的机器翻译也得到了领域内学者的大量关注。法律领域机器翻译在法律条款、合同文本和涉外公证文书等实际场景中也具有重要的应用价值。
目前融入外部信息是提升特定领域机器翻译的有效途径[2-5]。相较于传统的生成模型,引入外部信息可以让模型获得训练数据中没有的附加信息,降低文本生成的难度,减少对训练数据的依赖。现有的融入外部信息的方法主要分为三类:基于双语词典、基于翻译记忆和基于翻译模版。
基于双语词典的方法[6]用于解决低频词和术语翻译等问题,利用双语词典作为外部资源输入神经网络结构。Arthur 等人[7]提出一种通过使用离散词典来增强神经机器翻译系统的方法,以解决低频次翻译错误问题,这些词典可以有效地编码这些低频单词的翻译。
基于翻译记忆的方法主要分为以匹配片段为单位融合和以匹配句子为单位融合这两类方法,其中以句子为单位融合是现在的研究主流,通过融入翻译记忆可以让模型获取到更多的语义信息。Cao 等人[8]使用门控机制来平衡翻译记忆的影响。Gu 等人[9]和Xia 等人[10]使用辅助网络对翻译记忆库进行编码,然后将其集成到NMT 架构中。Bulte 和Tezcan 等人[11]及Xu 等人[12]利用数据扩充来训练神经机器翻译模型,该模型的训练实例是通过翻译记忆库扩充的双语句子。He 等人[2]针对现有的基于翻译记忆的方法缺乏普适性的问题,提出了一种高效且准确的融合翻译记忆的NMT 模型,它仅使用一个双语句子作为其翻译记忆。
基于翻译模版的方法是通过利用翻译模版蕴藏的句法结构信息约束译文结构的生成,以提升翻译模型性能。Kaji 等人[13]利用双语词典获取双语句子对的耦合单元,然后生成翻译模板。Liu 等人[14]提出了一种树到字符串算法,该算法利用单词对齐信息来对齐源解析树和目标序列,然后获得翻译模板。Shang 等人[15]通过使用带有特殊符号的源端和目标端选区解析树来屏蔽最大长度名词短语从而构建翻译模版库。
尽管上述的方法提升了翻译性能,但在翻译法律领域文本时,翻译效果还不理想,因为它们仅采用单一的融入策略。法律文本作为一种专业语言,具有用词准确、规范、结构严谨的特点,其文本的权威性、精确性不仅体现在选词、用词上,同样也体现在固定结构的使用上。如表达“禁止性”的程式化语言结构,中文的表达通常是“禁止”“不得”等,翻译成英文通常使用“be prohibited”“be not allowed”等词组,误用短语、词组会对立法文本的权威性、精确性产生影响。如图1 所示,待翻译的源句为表达“禁止性”的法律文本,正确的表达结构应为“shall be prohibited”,而翻译模型翻译为“is forbidden”。虽然融入翻译记忆可以让翻译模型学习到更多的语义信息,但生成的译文在句子结构上和法律语言正确的表述规范有一定差距。观察到法律领域的文本大多具有固定的表达结构,通过构建翻译模版并融入到翻译模型中,利用翻译模版蕴含的结构信息进一步约束译文结构的生成,可以使模型生成的译文更符合法律语言的表达规范。
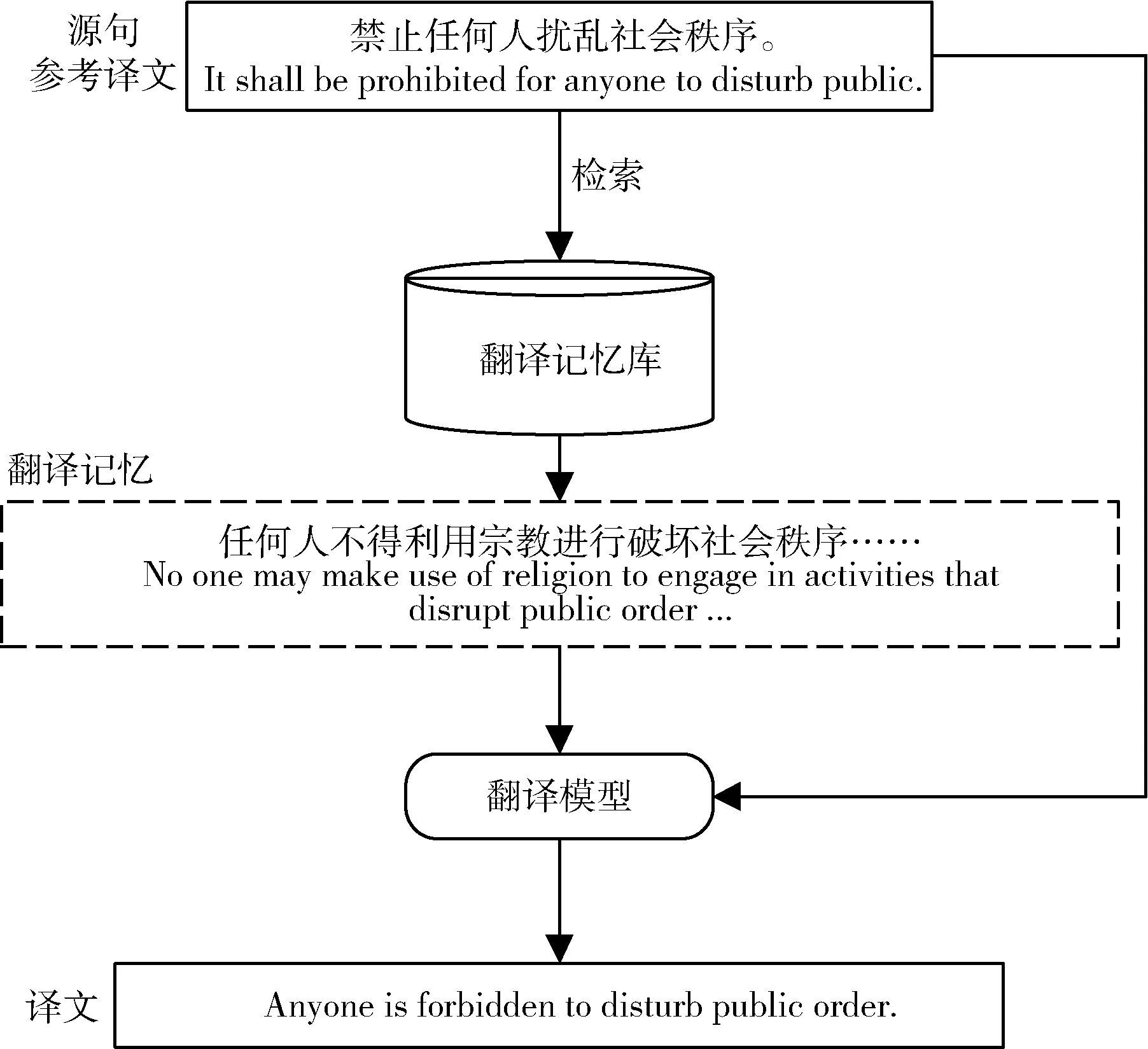
图1 融入翻译记忆的神经机器翻译示例
翻译记忆库通常由源语言-目标语言句对构建,由于法律领域公开的双语对齐语料有限,若利用源语言-目标语言句对构建法律领域翻译记忆库,模型可利用的外部资源并不丰富。目前在低资源语言机器翻译研究方面,单语语料是研究热点之一,研究表明单语语料的利用对于翻译性能的提升影响非常巨大。在法律领域,虽然公开的对齐语料有限,但互联网上具有大量的单语数据,若仅用目标语言数据构建翻译记忆库,可以大幅扩充翻译记忆库规模。
基于上述分析,针对在资源受限的场景下,现有的翻译模型在法律领域翻译任务中性能欠佳的问题,本文提出了一种融入翻译记忆库的法律领域神经机器翻译方法。为了验证方法的有效性,本文在MHLAW 和UNDOC 数据集上进行了实验,均取得好的翻译效果,翻译效果有所提升。本文的主要贡献如下:
(1)提出了一种新的领域翻译记忆库,在原有的翻译记忆库基础上,引入了具有法律特点的翻译模版。
(2)仅使用单语领域数据构建翻译记忆库,在一定程度上缓解了因双语语料稀缺限制翻译记忆库规模的问题。
1 翻译记忆库的法律领域神经机器翻译方法
1.1 翻译记忆
翻译记忆最初来源于专业翻译人员的翻译历史,它可以为翻译的源句提供最相似的源-目标句对。在最近的研究中也证实翻译记忆也可以用于改善神经机器翻译的性能,因为神经网络具有更好的拟合能力,能自动从句子中学习上下文知识。
在神经技巧翻译中,如何根据源句从翻译记忆库中检索最相似的翻译记忆以及如何将检索到的翻译记忆更好地融入到模型中都是重要的研究内容。
1.2 翻译模版构建
不同的法律规范在翻译时存在差异,为了使用翻译模版更加精确地指导模型翻译,首先需要对法律文本进行分类。本文在构建的数据集中挑选出一部分具有代表性的法律文本,按照禁止性规范、义务性规范和授权性规范对文本进行人工标记分类,训练分类模型,用于在后续训练过程中预测输入语句的类型。
翻译模版是对一个句子的抽象概括。在法律翻译任务中,最重要的是保留句子结构的完整性,动词、副词、连词和介词这些词性的词共同反映了整个句子的结构,所以在构建模版过程中需要对这些词性的单元进行保留。
首先,使用词性标注器对文本进行词性分析,对文本中的每个词语进行标注。然后对文本进行命名实体识别,识别出特殊词汇(如机构团体、地名等),并将这些特殊词汇使用标签进行替换(例如“证券交易管理委员会”被标签[ORGANIZATION]替换),其他普通名词使用

图2 翻译模版构建样例
2 模型
本文所提出的模型总体框架如图3 所示,包括检索模块和翻译模块两个部分。
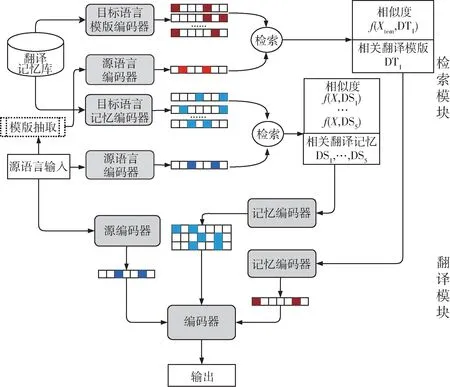
图3 融入翻译记忆库的法律领域神经机器翻译模型结构图
本文引入翻译模版对常规的翻译记忆库进行了拓展,因此构建的领域翻译记忆库包括翻译记忆和翻译模版。其中翻译记忆DS 是目标语言句子的集合,翻译模版DT 是目标语言翻译模版的集合。给定源语言输入X,得到X的句子模版Xtem,Xtem用于检索相关的目标语言翻译模版,检索模型根据检索函数在DS 和DT 中选择一些相关的翻译记忆{DSm}和翻译模版{DTn}。然后,翻译模型以检索到的翻译记忆,翻译模版和源语言输入X为条件,使用概率模型生成Y。为了激励翻译模型更多地关注相关性高的句子和模版,将相关性分数也输入到模型中。
2.1 基于语义和结构相似性的检索模型
检索模型负责从翻译记忆DS 和翻译模版DT 中为源句X选择最相关的句子和翻译模版。使用一个简单的三编码器框架来实现检索模型,将检索与源句最相关的句子和模版简化为最大内积搜索(MIPS),最后通过具有高性能的数据结构和搜索算法来完成检索。
将源语言输入X和候选句子DSm,X的模版Xtem和候选模版DTn的相关性分数分别定义为f(X,DSm)、f(Xtem,DTn):
其中,Esrc、Etgt_s和Etgt_t分别是将X、DSm和DTn映射到d维向量的源句编码器,目标句子编码器以及目标语言模版编码器。
在实际过程中,为了提升在实际情况下模型运行效率,使用FAISS[16]对所有翻译记忆和翻译模版进行预先计算和索引。
研究表明,当翻译记忆的候选数量大于1 时,模型翻译效果最好。Gu 等人[9]和Xia 等人[10]将优化后的候选数量设置为5,Zhang 等人[17]中甚至将其设定为100。但是随着候选数量的增加,模型翻译速度下降明显,因为计算复杂度与候选数量的大小线性相关。基于之前的研究,将翻译记忆的候选数量设置为5。由于翻译模版是用于约束句子结构,认为引入过多的翻译模版会干扰译文句子结构的生成,因此翻译模版的候选数量设置为1,在后面的实验会进行验证。
2.2 引入语义和结构信息的翻译模型
为了对检索端提供的目标语言翻译记忆和翻译模版编码,在标准的编码器-解码器框架上新增了记忆编码器,用于编码检索模型检索到的翻译记忆{DSm}和翻译模版{DTn},生成具有上下文信息的词嵌入,其中Lm和Ln是DSm和DTn的token 序列长度。首先对翻译记忆计算交叉注意力:
其中,αm,a是DSm中第a个token 的注意力分数,ct是翻译记忆嵌入的加权组合。解码器的隐状态ht通过翻译记忆嵌入的加权和来更新,ht=ht+ct。然后对翻译模版计算交叉注意力:
最后解码器的隐状态更新为:ht=ht+ctt。其中φ、ω是控制相关性得分权重的可训练标量,Wz、Wts、Wv和Wtt是可训练的权重矩阵。
2.3 训练策略
若直接初始化检索模型,这会导致检索到的翻译记忆DSm和翻译模版DTn与源句X的相关度非常低,以至于翻译模型在训练过程中习惯于直接忽略检索到的信息。因此首先在句子层面和token 层面进行交叉对齐任务来预训练检索模型。
句子层面的交叉对齐任务是在给定一组其他翻译的情况下为源句找到正确的翻译。在训练过程中,从训练集中随机抽取K对源-目标句对,M和N分别是由Esrc和Etgt_s编码器编码的源语言向量和目标语言向量的矩阵。R=MNT是关联度分数的矩阵,每行对应一句源句,每列对应一句目标句。当i=j时,每个源-目标句对(Mi,Nj)都应对齐。句子层面的交叉对齐任务的目标是沿矩阵对角线的分数最大化,损失函数公式为:
Token 层面的交叉对齐任务是为了在给定源语言表示的情况下预测目标语言中的token,反之亦然。对应的损失函数为:
其中,Xi和Yi表示第i个源句或目标句中的一组token 集合,token 的概率通过线性投影和softmax 函数计算。翻译模版也是采用同样的方式进行,最后预训练的联合损失为。预训练检索模型相当于对检索模型做了热启动工作,检索模型能检索到与源句相似性更高的翻译记忆和翻译模版,模型可以更好地学习如何捕获翻译记忆和翻译模版的信息来指导解码过程。
3 实验与分析
3.1 数据集
由于公开的法律领域双语数据有限,在进行实验前,在Bilingual Laws Information System(香港双语法例资料系统)和Westlaw China 网站上爬取了数据,在过滤筛选并结合人工校对后,获得16 万中英法律平行句对。为验证本文方法的泛化性,还在联合国正式文件系统上下载了文本数据,并随机抽取了20 万句对。中文句子不同于英语句子,句子中没有明显的词语间隔,本文使用Jieba 分词工具对中文语料进行分词。
将预处理好的平行语料拆分为训练集、验证集和测试集。将法律领域数据集命名为MHLAW,联合国正式文件系统下载的数据集命名为UNDOC。数据集划分情况如表1 所示。

表1 数据集
3.2 实验参数设置
检索相似性分数最高的5 句翻译记忆和1 句翻译模版,批次处理大小为512,学习率为0.004,词嵌入的维度为512,采用Adam[18]作为加快模型训练速度的优化器,每组实验训练10 万步。
3.3 基线模型
选 择Transformer[19]、Xia 等人[10]和He 等人[2]所提出的模型作为对比实验的基准模型,使用BLEU[20]来评测本文提出的法律领域机器翻译模型的性能。以下是对3种模型的介绍:
(1)Transformer:原始的Transformer 模型,参数设 置和本文保持一致。
(2)Xia 等人(2019):将检索的相关翻译记忆构建成一张图,在解码端融入,且在训练阶段使用微调来调整模型的相关参数设置。
(3)He 等人(2021):在标准Transformer 基础上,在编码端使用词对齐和相似度分数对检索到的目标端翻译记忆进行编码,并在解码端增加Example Layer 模块融入翻译记忆。
3.4 实验结果分析
为验证本文方法的有效性,本文分别在中-英、英-中两个翻译方向上使用MHLAW 数据集进行了实验。为了便于直观地观察和对比,保证实验结果的可靠性,每组实验结果的BLEU 值都采用相同的测试集计算。结果如表2 所示。
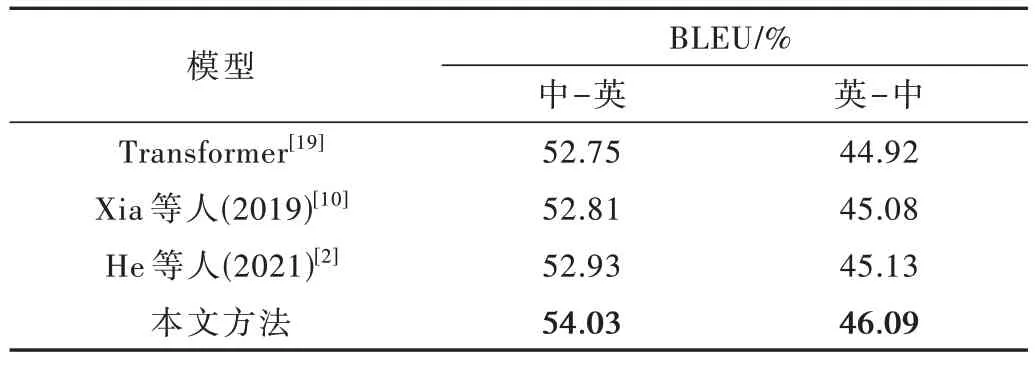
表2 本文方法与其他基线模型对比结果
根据表2 的实验结果可以看出,本文方法通过融入翻译记忆和翻译模版后BLEU 值有所提升,在中-英翻译方向下,比3 个基线模型翻译结果分别高出1.28、1.22 和1.10 个BLEU 值,在英-中翻译方向下分别高出1.17、1.01 和0.96 个BLEU 值。本文方法优于其他基线模型的原因在于本文方法不仅使用跨语言检索模型,相比于Xia 等人和He 等人使用的模糊匹配检索方式,跨语言检索模型与其下游翻译模型做为一个可学习的整体,可以针对翻译目标进行端到端的优化;而且还考虑到法律文本具有大量的固有结构,将翻译模版也融入到模型中,相比于仅融入翻译记忆的模型,本文的模型能进一步获得翻译模版所蕴藏的句子结构信息,并能很好地加以利用。因此证明本文方法对提升法律领域机器翻译效果的有效性。
为进一步探索本文方法是否能学习其他特定领域的知识,本文在联合国正式文件领域进行了实验,以验证本文方法在其他特定领域的翻译效果。由于本文并未对UNDOC 数据集的文本进行类似法律领域的文本分类,因此构建翻译模版的步骤与构建法律领域翻译模版相比省略了文本分类环节,其他构建流程一致。实验结果如表3 所示。
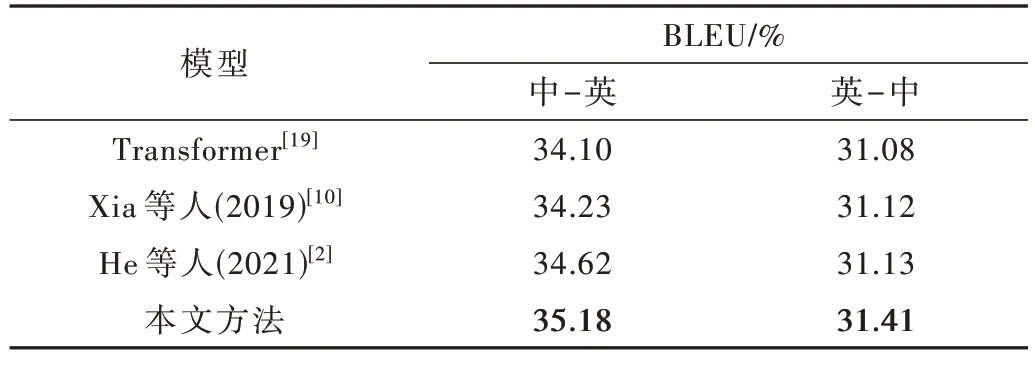
表3 使用UNDOC 数据集对比实验结果
从实验结果看,本文方法在中-英翻译方向上较两个基线模型分别提升1.08、0.95 和0.56 个BLEU 值,在英-中翻译方向上比两个基线模型提升0.33、0.29 和0.28 个BLEU 值。即使在法律领域以外的翻译任务上,本文所提出的方法同样能通过挖掘记忆模版库中的句法结构信息以及语义信息,学习到特定领域的知识,指导模型翻译出效果更好的译文。
通过以上实验可以看出,本文方法在MHLAW 和UNDOC 数据集上都较基线模型有所提升。由此也证明本文方法具有泛化性。
为测试使用不同双语语料规模预训练检索模型以及翻译记忆库规模对模型性能的影响,将MHLAW 和UNDOC 数据集随机切分为4 份相同规模的子数据集。实验设计为:分别使用第一个子数据集和第二个子数据集的双语数据预训练检索模型,在后续测试过程中使用其他子数据集的目标语言数据逐步扩充翻译记忆库。
实验结果如表4 所示。随着翻译记忆库数据的增加,模型的性能随之提升,翻译记忆库的扩增让模型接受到更多的外部信息。同时,在翻译记忆库规模相同的情况下,训练检索模型所使用的双语语料数据越多,模型的翻译效果越好,因为使用更大规模的语料训练检索模型,检索模型能更好地学习如何检索最匹配的目标语言信息。该实验不仅表明本文所提出的方法具有可插拔性,只需使用目标语言数据扩充翻译记忆库规模便能提升翻译性能,而且也验证了使用交叉对齐任务预热检索模型方式的必要性,相似性更高的翻译记忆对提升模型性能具有积极作用。

表4 不同语料库规模的实验结果
为进一步验证候选翻译模版数量对翻译效果的影响,本文在MHLAW 数据集上进行了实验。从表5 可以看出,候选翻译模版的数量对实验结果影响较大,随着翻译模版候选数量的增加,译文BLEU 值反而降低。尽管翻译模版所蕴藏的句法结构信息可用来约束译文结构的生成,但实验表明,过多的翻译模版反而干扰句子结构的生成,降低了翻译效果。

表5 翻译模版数量设置对模型性能影响的实验结果

表6 仅融入翻译模版的实验结果
3.5 消融实验
为了验证翻译模版对实验性能的影响,仅将翻译模版作为外部资源,单独融入到模型中,本文在MHLAW数据集上进行实验。实验结果如6 所示。
可以观察到单独融入翻译模版时,模型的BLEU 值相比同时融入翻译记忆和翻译模版时分别降低了0.82%和0.33%。实验表明,同时融入翻译记忆和翻译模版相比于单一的融入方式,对模型的约束更强,指导的效果更好,可以带来更大的收益。
3.6 翻译样例
表7 描述的是一个翻译样例,以证明本文方法的效果。待翻译源句“禁止任何组织或者个人扰乱社会经济秩序。”是一种禁止性规范,该句重点在于禁止破坏社会秩序,在英文翻译中表示强调的部分应当置于句首。而基线模型均将表示强调的部分置于句末,不能体现该法律条款的禁止性,不仅在结构上与参考译文有较大差别,而且在法律翻译中“秩序”通常翻译为“order”,基线模型却将其翻译为“programme”。与基线模型相比,本文方法生成的译文在句子结构和用词上都更加符合参考译文的表述。

表7 译文质量对比
4 结论
针对法律领域训练数据稀缺的问题,本文提出一种融入翻译记忆库的法律领域神经机器翻译方法。首先用目标端数据构建法律领域翻译记忆库,然后使用双语对齐语料预训练检索模型,进而利用检索模型从翻译记忆库中检索与源句相关的翻译记忆和翻译模版,最后将检索到的翻译记忆和翻译模版融入到模型中,借助翻译记忆的语义信息和翻译模版的句子结构信息指导模型翻译,提升法律领域机器翻译性能。实验结果表明,在资源受限的场景下本文方法能够有效提升法律领域机器翻译的性能。下一步,将探索利用知识图谱进一步提升法律领域机器翻译性能。
